ملاحظة perev. : جاء هذا المقال الصغير (ولكنه واسع!) الذي كتبه مايكل Hausenblas من فريق OpenShift في Red Hat إلى إعجابنا لدرجة أنه تمت إضافته إلى قاعدة معارفنا الداخلية Kubernetes مباشرة بعد اكتشافه. وبما أن المعلومات الواردة فيه ستكون مفيدة بشكل واضح لمجتمع تكنولوجيا المعلومات الأوسع ناطقًا بالروسية ، يسعدنا نشر ترجمتها.
كما كنت قد خمنت ، عنوان هذا المنشور هو إشارة إلى الرسوم المتحركة بيكسار 1998 "حياة حشرة"
(في شباك التذاكر الروسية كان يطلق عليه "مغامرات فليك" أو "حياة حشرة" - ترجمة تقريبا ) ، والواقع: بين النملة تشترك Kubernetes كثيرًا مع العمال والمداخن. سننظر بعناية في دورة الحياة الكاملة للموقد من وجهة نظر عملية - على وجه الخصوص ، الطرق التي يمكنك من خلالها التأثير على السلوك عند بدء التشغيل وإغلاقه ، بالإضافة إلى الأساليب الصحيحة للتحقق من حالة التطبيق.
بغض النظر عما إذا كنت قد قمت بإنشائه تحت نفسك أو ، بشكل أفضل ، من خلال وحدة تحكم مثل
النشر أو
DaemonSet أو
StatefulSet ، يمكن أن تكون تحت إحدى المراحل التالية:
- في انتظار المراجعة : أنشأ خادم API موردًا للقرص وحفظه في etcd ، ولكن لم يتم التخطيط له بعد ، ولم يتم استلام صور حاوياته من التسجيل ؛
- الجري (يعمل): تم تعيين تحت إلى العقدة وتم إنشاء جميع الحاويات بواسطة kubelet ؛
- نجحت (اكتملت بنجاح): تم الانتهاء من تشغيل جميع حاويات الموقد بنجاح ولن يتم إعادة تشغيلها ؛
- فشل : توقفت جميع الحاويات في الموقد عن العمل وفشلت واحدة على الأقل من الحاويات ؛
- غير معروف : تعذر على خادم API الاستعلام عن حالة الموقد ، عادة بسبب خطأ في التفاعل مع kubelet .
عند تنفيذ
kubectl get pod ، لاحظ أن عمود
STATUS يمكن أن يعرض رسائل أخرى (باستثناء هذه الخمس) - على سبيل المثال ،
Init:0/1 أو
CrashLoopBackOff . هذا لأن المرحلة ليست سوى جزء من الحالة العامة للموقد. طريقة جيدة لمعرفة ما حدث بالضبط هو تشغيل
kubectl describe pod/$PODNAME وإلقاء نظرة على إدخال
kubectl describe pod/$PODNAME Events: أدناه. وهي تعرض قائمة بالإجراءات ذات الصلة: حيث تم استلام صورة الحاوية ، والمخطط لها ، والحاوية في حالة "
غير صحية" .
ألقِ نظرة الآن على مثال محدد لدورة حياة الموقد من البداية إلى النهاية ، كما هو موضح في الرسم البياني التالي:
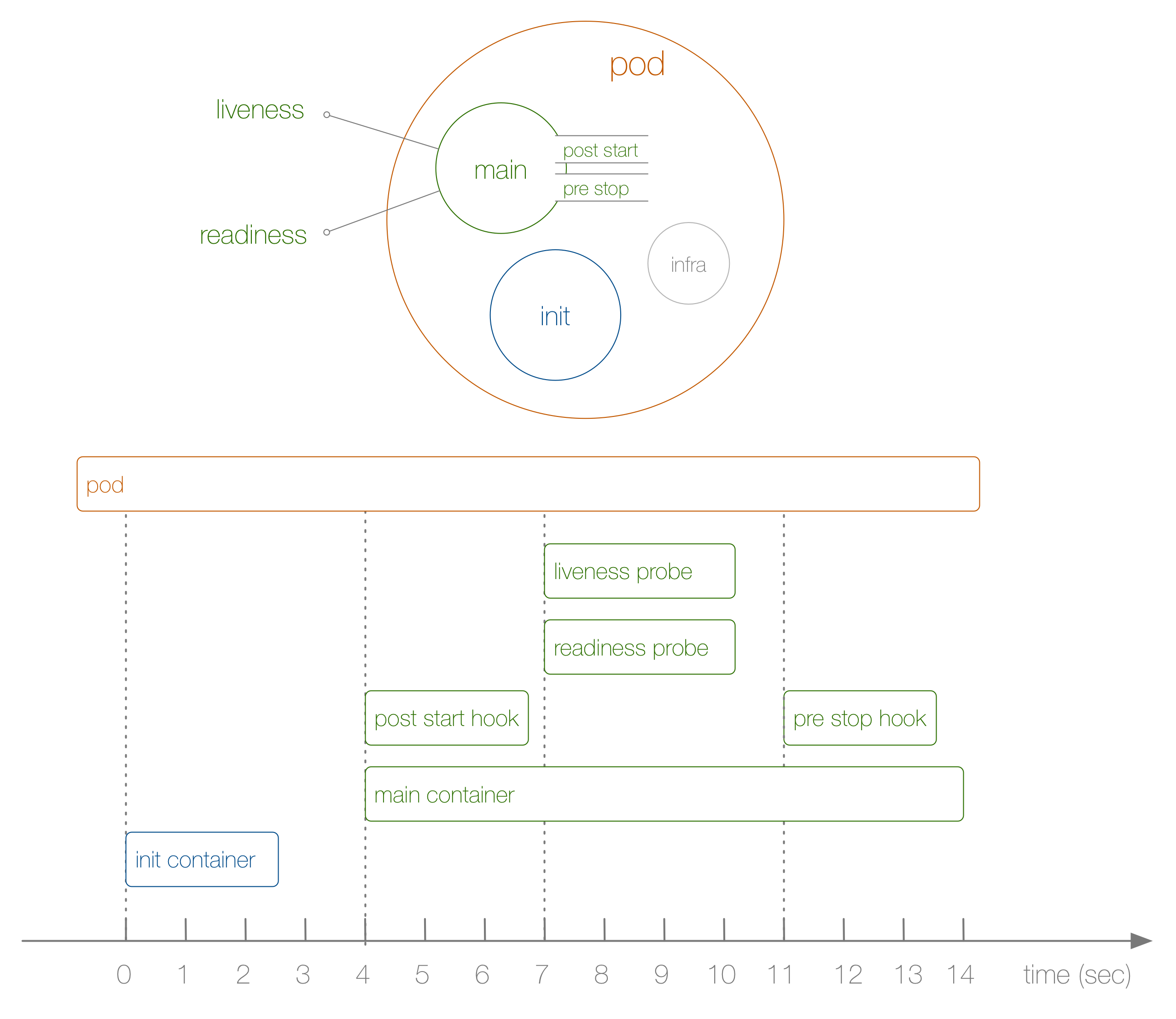
ماذا حدث هنا؟ الخطوات كالتالي:
- لا يتم عرض هذا في الرسم التخطيطي ، ولكن في البداية يتم إطلاق حاوية داخلية خاصة وتقوم بإعداد مساحات الأسماء التي تنضم إليها الحاويات المتبقية.
- أول حاوية يحددها المستخدم تبدأ هي حاوية التهيئة ؛ يمكن استخدامه لمهام التهيئة.
- بعد ذلك ، يتم إطلاق الحاوية الرئيسية وخطاف ما بعد البدء في وقت واحد ؛ في حالتنا ، يحدث هذا بعد 4 ثوان. يتم تعريف الخطافات لكل حاوية.
- ثم ، في الثانية السابعة ، يتم تشغيل اختبارات الاستعداد والجاهزية ، مرة أخرى لكل حاوية.
- في الثانية عشرة ، عندما يقتل تحت ، يتم تشغيل خطاف ما قبل التوقف ويتم قتل الحاوية الرئيسية بعد فترة سماح . يرجى ملاحظة أنه في الواقع ، عملية إتمام الجراب أكثر تعقيدًا إلى حد ما.
كيف جئت إلى التسلسل أعلاه وتوقيته؟ للقيام بذلك ، استخدمنا
النشر التالي ، الذي تم إنشاؤه خصيصًا لتتبع ترتيب الأحداث (ليس مفيدًا في حد ذاته):
kind: Deployment apiVersion: apps/v1beta1 metadata: name: loap spec: replicas: 1 template: metadata: labels: app: loap spec: initContainers: - name: init image: busybox command: ['sh', '-c', 'echo $(date +%s): INIT >> /loap/timing'] volumeMounts: - mountPath: /loap name: timing containers: - name: main image: busybox command: ['sh', '-c', 'echo $(date +%s): START >> /loap/timing; sleep 10; echo $(date +%s): END >> /loap/timing;'] volumeMounts: - mountPath: /loap name: timing livenessProbe: exec: command: ['sh', '-c', 'echo $(date +%s): LIVENESS >> /loap/timing'] readinessProbe: exec: command: ['sh', '-c', 'echo $(date +%s): READINESS >> /loap/timing'] lifecycle: postStart: exec: command: ['sh', '-c', 'echo $(date +%s): POST-START >> /loap/timing'] preStop: exec: command: ['sh', '-c', 'echo $(date +%s): PRE-HOOK >> /loap/timing'] volumes: - name: timing hostPath: path: /tmp/loap
لاحظ أنه من أجل إغلاق البودرة بقوة عندما كانت الحاوية الرئيسية تعمل ، قمت بتشغيل الأمر التالي:
$ kubectl scale deployment loap --replicas=0
نظرنا إلى تسلسل معين من الأحداث أثناء العمل ، ونحن الآن على استعداد للمضي قدمًا - في الممارسات في مجال إدارة دورة حياة الموقد. هم كما يلي:
- استخدم حاويات التهيئة لإعداد الموقد للتشغيل العادي. على سبيل المثال ، للحصول على بيانات خارجية ، قم بإنشاء جداول في قاعدة البيانات ، أو لانتظار توفر الخدمة التي تعتمد عليها. إذا لزم الأمر ، يمكنك إنشاء العديد من حاويات التهيئة ، ويجب أن تكتمل جميعها بنجاح قبل إطلاق الحاويات العادية.
- أضف دائمًا
livenessProbe readinessProbe livenessProbe . يتم استخدام الأول من قبل kubelet 'ohm لفهم ما إذا كانت الحاوية ومتى سيتم إعادة تشغيلها ، ونشر ' ohm لتحديد ما إذا كان التحديث المتداول ناجحًا. يتم استخدام الثاني من قبل الخدمة لتحديد اتجاه حركة المرور إلى الباطن. إذا لم يتم تحديد هذه العينات ، يفترض kubelet لكلاهما أنه تم الانتهاء بنجاح. يؤدي هذا إلى نتيجتين: أ) لا يمكن تطبيق سياسة إعادة التشغيل ، ب) تتلقى الحاويات في الموقد على الفور حركة مرور من الخدمة التي تواجهها ، وحتى إذا كانت لا تزال مشغولة بعملية بدء التشغيل. - استخدم الخطافات لتهيئة الحاوية بشكل صحيح وتدميرها تمامًا. على سبيل المثال ، يكون هذا مفيدًا في حالة عمل تطبيق لا يمكنك الوصول إلى كود المصدر الخاص به أو لا يمكنك تعديله ، ولكنه يتطلب بعض التهيئة أو التحضير للإكمال - على سبيل المثال ، مسح اتصالات قاعدة البيانات. لاحظ أنه عند استخدام الخدمة ، قد يستغرق إغلاق خادم API ، ووحدة تحكم نقطة النهاية ، و kube-proxy بعض الوقت (على سبيل المثال ، حذف الإدخالات المقابلة من iptables). لذلك ، قد يؤثر إنهاء عملك بموجب طلبات التقديم. في كثير من الأحيان ، لحل هذه المشكلة ، يكفي ربط بسيط مع مكالمة نوم.
- لاحتياجات تصحيح الأخطاء وفهم بشكل عام لماذا توقف عن العمل ، يمكن للتطبيق الكتابة إلى
/dev/termination-log ، ويمكنك عرض الرسائل باستخدام kubectl describe pod … يتم تغيير هذه الإعدادات الافتراضية من خلال terminationMessagePath و / أو باستخدام terminationMessagePolicy في المواصفات الفرعية - راجع مرجع API لمزيد من التفاصيل.
لا يناقش هذا المنشور
المُهيئون (يمكن العثور على بعض التفاصيل المتعلقة بهم في نهاية هذه المادة - ترجمة تقريبًا ) . هذا مفهوم جديد تمامًا تم تقديمه في Kubernetes 1.7. تعمل أدوات التهيئة داخل مستوى التحكم (خادم API) بدلاً من أن تكون في سياق
kubelet ، ويمكن استخدامها لإثراء المداخن ، على سبيل المثال ، بالحاويات الجانبية أو فرض سياسات الأمان. بالإضافة إلى ذلك ، لم يتم النظر في
PodPresets ، والتي يمكن استبدالها في المستقبل بمفهوم أكثر مرونة
للمبدئي .
ملاحظة من المترجم
اقرأ أيضا في مدونتنا: