في الآونة الأخيرة ، بحثنا عن عالم بيانات في الفريق (ووجدنا - مرحبًا
ونيكسون وأرسيني !). أثناء التحدث مع المرشحين ، أدركنا أن العديد من الأشخاص يريدون تغيير وظائفهم لأنهم يفعلون شيئًا "على الطاولة".
على سبيل المثال ، يأخذون التوقعات المعقدة التي اقترحها الرأس ، لكن المشروع يتوقف لأن الشركة لا تفهم ماذا وكيف يتم تضمينه في الإنتاج ، وكيفية تحقيق الربح ، وكيفية "استعادة" الموارد التي تم إنفاقها على النموذج الجديد.

لا يمتلك HeadHunter قوة حوسبة كبيرة ، مثل Yandex أو Google. نحن نتفهم مدى صعوبة إدخال ML المعقد في الإنتاج. لذلك ، تركز العديد من الشركات على حقيقة أن أبسط النماذج الخطية يتم إدخالها في الإنتاج.
في عملية التنفيذ التالي ل ML في نظام التوصيات وفي البحث عن الوظائف الشاغرة ، واجهنا عددًا من "أشعل النار" الكلاسيكية. انتبه لهم إذا كنت تنوي تطبيق ML في المنزل: ربما ستساعدك هذه القائمة على عدم الذهاب إليها
والعثور على أشعل النار الخاص بك .
أشعل النار رقم 1: عالم البيانات - فنان حر
في كل شركة تبدأ في إدخال التعلم الآلي ، بما في ذلك الشبكات العصبية ، في عملها ، هناك فجوة بين ما يريد عالم البيانات القيام به وما يفيد الإنتاج. بما في ذلك لأن الأعمال التجارية لا يمكنها دائمًا تفسير الفائدة وكيف يمكنها المساعدة.
نتعامل مع هذا بالطريقة التالية: نناقش جميع الأفكار الناشئة ، ولكن فقط تنفيذ ما سيفيد الشركة - الآن أو في المستقبل. نحن لا نقوم بالبحث في الفراغ.
بعد كل تنفيذ أو تجربة ، نأخذ في الاعتبار الجودة والموارد والآثار الاقتصادية وتحديث خططنا.
أشعل النار رقم 2: تحديث المكتبات
تحدث هذه المشكلة في كثير. تظهر العديد من المكتبات الجديدة والمريحة التي لم يسمع بها أحد منذ بضع سنوات ، أو لم يسمع عنها شيء على الإطلاق. أود استخدام أحدث المكتبات لأنها أكثر ملاءمة.
ولكن هناك عدة عقبات:
1. إذا كان المنتج يستخدم ، على سبيل المثال ، الـ 14 من Ubuntu ، فمن الأرجح أنه لا توجد مكتبات جديدة فيه. الحل هو نقل الخدمة إلى عامل إرساء وتثبيت مكتبات Python باستخدام النقطة (بدلاً من حزم deb).
2. إذا تم استخدام تنسيق يعتمد على التعليمات البرمجية لتخزين البيانات (مثل المخلل) ، فإن هذا يجمد المكتبات المستخدمة. أي أنه عندما تم الحصول على نموذج التعلم الآلي باستخدام مكتبة الإصدار 15 من scikit-learn وحفظها في شكل مخلل ، فستكون هناك حاجة إلى الإصدار الخامس عشر من مكتبة التعلم والتعلم لاستعادة النموذج الصحيح. لا يمكنك الترقية إلى أحدث إصدار ، وهذا فخ أكثر خبثًا مما هو موضح في الفقرة 1.
هناك طريقتان للخروج منه:
- استخدم تنسيقًا مستقلاً عن الرمز لتخزين النماذج
- القدرة دائمًا على إعادة تدريب أي نموذج. ثم عند تحديث المكتبة سيكون من الضروري تدريب جميع النماذج وحفظها مع الإصدار الجديد للمكتبة.
لقد اخترنا المسار الثاني.
أشعل النار رقم 3: العمل مع الموديلات القديمة
إن القيام بشيء جديد في نموذج قديم متعلم أقل فائدة من القيام بشيء بسيط في نموذج جديد. غالبًا ما يتضح في النهاية أن إدخال نماذج أبسط ولكن أعذب أكثر فائدة ، ومقدار الجهد أقل. من المهم أن تتذكر هذا وأن تأخذ دائمًا بعين الاعتبار مقدار الجهود المشتركة في البحث عن الأنماط.
أشعل النار رقم 4: التجارب المحلية فقط
يحب العديد من خبراء علوم البيانات إجراء التجارب محليًا على خوادم التعلم الآلي الخاصة بهم. لا تمتلك هذه المنتجات فقط مثل هذه المرونة: ونتيجة لذلك ، تم الكشف عن مجموعة من الأسباب التي من المستحيل جر هذه التجارب إلى الإنتاج.
من المهم تكوين الاتصال بين أخصائي DS ومهندسي المبيعات لفهم مشترك - كيف سيعمل هذا النموذج أو ذاك في الإنتاج ، سواء كانت هناك القوة اللازمة والقدرة المادية لطرحه. بالإضافة إلى ذلك ، كلما كانت النماذج والعوامل أكثر تعقيدًا ، زادت صعوبة جعلها موثوقة والقدرة على تدريبها مرة أخرى في أي وقت. على عكس مسابقات Kaggle ، في الإنتاج ، غالبًا ما يكون من الأفضل التضحية بعشرة آلاف من المقاييس المحلية وحتى القليل من مؤشرات الأداء الرئيسية عبر الإنترنت ، ولكن تنفيذ نسخة من النماذج هو أبسط بكثير ومستقر في النتائج وسهل في موارد الحوسبة.
الملكية المشتركة للشفرة (المطورين وعلماء البيانات يعرفون كيف يعمل الرمز المكتوب من قبل المطورين الآخرين) ، وإعادة استخدام العلامات والسمات التعريفية في نماذج مختلفة سواء في عملية التعلم وعند العمل في همز (يساعدنا us framework) ، والوحدات ، والاختبارات التلقائية ، التي ندفعها كثيرًا ، تكامل الكود مع إعادة الاختبار. نضع النماذج النهائية في مستودعات git ونستخدمها في الإنتاج أيضًا.
أشعل النار رقم 5: اختبار همز فقط
لكل من مطورينا وعلماء البيانات لدينا منصة اختبار خاصة بهم ، وأحيانًا لا يوجد منها. يتم نشر المكونات الرئيسية للإنتاج HH عليها. إنه مكلف ، لكنه يدفع مقابل الجودة وسرعة التطور. إنها ضرورية ، لكنها ليست كافية. نحن لا نحمّل النماذج الموجودة بالفعل في الإنتاج فحسب ، بل نحمّل أيضًا النماذج التي ستتوفر قريبًا. يساعد هذا على الفهم في الوقت المناسب بأن النماذج التي تعمل بشكل مثالي على الأجهزة المحلية ، أو مقاعد الاختبار أو في الإنتاج لـ 5٪ من المستخدمين ، وعندما يتم تشغيلها بنسبة 100٪ ، تكون ثقيلة جدًا.
نستخدم عدة مراحل من الاختبار. نتحقق من الشفرة بسرعة كبيرة (هذه هي النقطة الأساسية) - عند إضافة المكونات أو تغييرها في المستودع ، يتم جمع الشفرة ، ويتم تشغيل الوحدة والاختبارات التلقائية على المكونات المقابلة ، إذا لزم الأمر ، نقوم أيضًا بإعادة اختبارها يدويًا - وإذا كان هناك خطأ ما ، فأجب عن إجابة "لك مكسورة ، تقرر".
أشعل النار رقم 6: حسابات طويلة وفقدان التركيز
إذا كان النموذج يتطلب ، على سبيل المثال ، أسبوعًا للتدريب ، فمن السهل أن تفقد التركيز على المهمة بسبب التحول إلى مشروع آخر. نحاول ألا نمنح المطورين وعلماء البيانات أكثر من مهمتين في يد واحدة. ولا يوجد أكثر من واحد عاجل حتى تتمكن من التبديل إليه بمجرد الانتهاء من العمليات الحسابية أو تجارب A / B لذلك. هذه القاعدة ضرورية حتى لا تفقد التركيز ، وبسبب المخاوف من أن بعض هذه المهام عادة ما تتعرض لخطر الضياع ، وجزء آخر يتم طرحه في وقت متأخر جدًا عن اللازم.
داسنا على أشعل النار لكننا لم نستسلم
أكملنا مؤخرًا تجربة حول إدخال الشبكات العصبية في نظام التوصية. بدأ بحقيقة أن الهاكاثون الداخلي كتب في يومين نموذجًا للتنبؤ بالاستجابات من خلال السيرة الذاتية ، مما سهل إلى حد كبير البحث عن الوظائف الشاغرة المناسبة.
لكننا تعلمنا لاحقًا: لكي نبدأ في الإنتاج ، تحتاج إلى تحديث كل شيء تقريبًا - على سبيل المثال ، نقل نظام الاستخدام المزدوج ، الذي يأخذ في الاعتبار الإشارات ويعلم النماذج ، إلى عامل الإرساء ، وكذلك تحديث مكتبات التعلم الآلي.
كيف كان ذلك
استخدمنا نموذج DSSM مع شبكة عصبية أحادية الطبقة. في مقال Microsoft الأصلي ، تم استخدام شبكة عصبية ثلاثية الطبقات ، لكننا لم نلاحظ تحسينات في الجودة مع زيادة في عدد الطبقات ، لذلك استقرنا على طبقة واحدة.

باختصار:
- يتم تحويل نص الاستعلام ورأس الوظيفة الشاغرة إلى متجهي رمز مثلث. نحن نستخدم 20،000 مثلث الأحرف.
- يتم تغذية ناقل الزناد إلى مدخل الشبكة العصبية أحادية الطبقة. عند إدخال طبقة الشبكة العصبية ، هناك 20000 رقم ، عند الإخراج ، 64. بشكل أساسي ، الشبكة العصبية هي مصفوفة 20000 × 64 يتم من خلالها ضرب متجه الزناد المدخل للبعد 1 × 20000. يتم إضافة ناقل ثابت للبعد 1 × 64 إلى نتيجة الضرب. يتوافق ناتج هذه الشبكة العصبية مع الطلب (أو عنوان الوظيفة الشاغرة).
- يتم حساب المنتج القياسي لمتجه dssm الاستعلام ومتجه dssm لرأس الوظيفة الشاغرة. يتم تطبيق وظيفة السيني على العمل. والنتيجة النهائية هي العلامة الوصفية dssm.
عندما حاولنا تضمين هذا النموذج لأول مرة ، أصبحت المقاييس المحلية أفضل ، ولكن عندما حاولنا طرحه في اختبار أ / ب ، رأينا أنه لم يكن هناك أي تحسن.
بعد ذلك ، حاولنا زيادة الطبقة الثانية من الخلايا العصبية إلى 256 - تم طرحها بنسبة 5 ٪ من المستخدمين: اتضح أن نظام التوصيات والبحث أصبح أفضل ، ولكن عندما قمت بتشغيل النموذج 100 ٪ ، اتضح فجأة أنه ثقيل جدًا.
قمنا بتحليل سبب ثقل النموذج ، وإزالة الجذع ، وتجريب هذه الشبكة العصبية مرة أخرى. وفقط بعد ذلك ، بعد أن قطعوا الطريق مرة أخرى ، اكتشفوا أن النموذج مفيد: زاد عدد الردود في نظام التوصيات بمقدار 700 يوميًا ، وفي البحث ، بعد كل عمليات إعادة الحساب ، بمقدار 4200.
إن إدخال مثل هذه الشبكة العصبية غير المعقدة للغاية يسمح لعملائنا بتوظيف عشرات الموظفين الإضافيين كل يوم من خلال hh.ru ، وخلال التنفيذ هزمنا جزءًا كبيرًا من المشاكل الكبيرة. لذلك ، نخطط لتطوير شبكاتنا العصبية بشكل أكبر. تهدف الخطط إلى محاولة الجذع العام ، lemmatization إضافية ، معالجة النصوص الكاملة للشواغر واستئناف ، وإجراء تجارب على الطوبولوجيا (الطبقات المخفية ، وربما RNN / LSTM).
أهم شيء قمنا به مع هذا النموذج:
- لا تسقط التجربة في المنتصف.
- قمنا بحساب مؤشرات زيادة الاستجابة ووجدنا أن العمل على هذا النموذج كان يستحق ذلك. من المهم جدًا فهم مدى الفائدة التي يجلبها كل تنفيذ من هذا القبيل.
ومن المثير للاهتمام أن النموذج الذي قمنا به وأضفناه في النهاية إلى المنتج يشبه إلى حد كبير طريقة المكون الأساسي (PCA) المطبق على المصفوفة [نص الاستعلام ، عنوان المستند ، ما إذا كانت هناك نقرة]. أي ، إلى مصفوفة يتطابق فيها صف مع استعلام فريد ، عمود إلى عنوان شاغر فريد ؛ القيمة في الخلية هي 1 إذا نقر المستخدم بعد هذا الطلب على وظيفة شاغرة بهذا العنوان ، و 0 إذا لم يكن هناك نقرة.
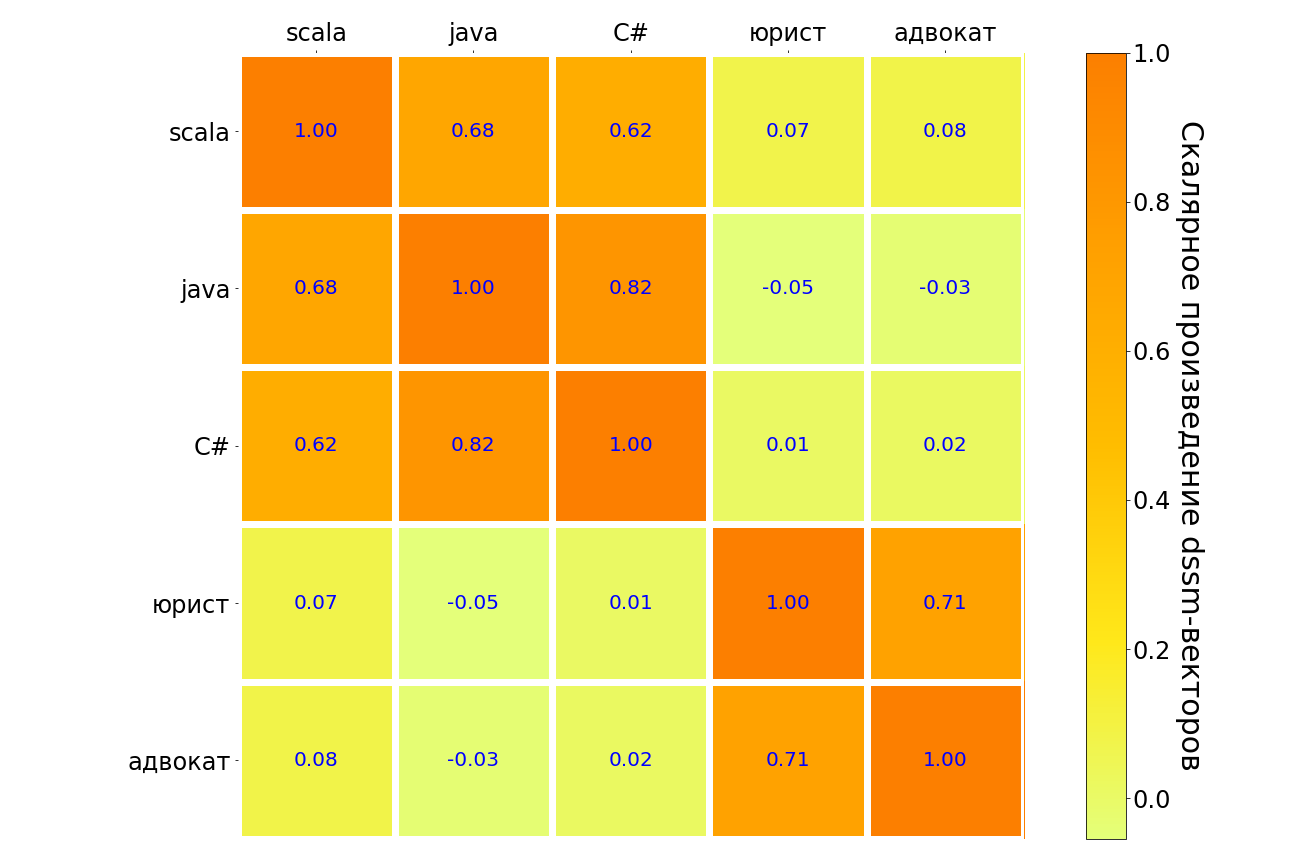
نتائج تطبيق هذا النموذج على طلبات scala و java و C # و "المحامي" و "المحامي" موجودة في الجدول أدناه. متشابه في المعنى ، يتم تمييز أزواج الاستعلامات في الظلام ، على عكس - الضوء. يمكن ملاحظة أن النموذج يفهم العلاقة بين لغات البرمجة المختلفة ، وهناك علاقة قوية بين طلب "المحامي" و "المحامي". ولكن بين "المحامي" وأي لغة برمجة ، فإن الاتصال ضعيف للغاية.
في مرحلة ما ، أريد حقًا أن أستسلم - التجارب جارية ، لكنها لا "تشتعل". عند هذه النقطة ، قد يجد عالم البيانات أنه من المفيد دعم الفريق وحساب الفوائد مرة أخرى: قد يكون من المفيد "دفن المضيفة" وعدم محاولة "ركوب الحصان الميت" ، فهذا ليس فشلًا ، ولكنه تجربة ناجحة بنتيجة سلبية. أو ، بعد تقييم الإيجابيات والسلبيات ، ستجري تجربة أخرى "ستطلق النار". لذلك حدث لنا.