في نهاية فصل الشتاء من هذا العام ، عقدت جمعية معالجة الإشارات في IEEE - مسابقة تحديد طراز الكاميرا. شاركت في هذه المسابقة الجماعية كمرشد. حول طريقة بديلة لبناء الفريق ، القرار والمرحلة الثانية تحت الخفض.
 tldr.py
tldr.pyfrom internet import yandex_fotki, flickr, wiki commons from Andres_Torrubia import Ivan_Romanov as pytorch_baseline import kaggle dataset = kaggle.data() for source in [yandex_fotki, flickr, wiki_commons]: dataset[train].append(source.download()) predicts = [] for model in [densenet201, resnext101, se_resnext50, dpn98, densenet161, resnext101 d4, se resnet50, dpn92]: with pytorch_baseline(): model.fit(dataset[train]) predicts.append(model.predict_tta(dataset[test])) kaggle.submit(gmean(predicts))
بيان المشكلةمن الصورة ، من الضروري تحديد الجهاز الذي تم الحصول على هذه الصورة. تتألف مجموعة البيانات من صور لعشر فئات: اثنان من أجهزة iPhone وسبعة هواتف ذكية تعمل بنظام Android وكاميرا واحدة. تضمنت عينة التدريب 275 صورة كاملة الحجم لكل فصل. في عينة الاختبار ، تم تقديم المحاصيل المركزية 512 × 512 فقط. علاوة على ذلك ، تم تطبيق واحد من ثلاث عمليات تكبير على 50 بالمائة منها: ضغط JPG ، تغيير الحجم مع الاستيفاء المكعب ، أو تصحيح غاما. كان من الممكن استخدام البيانات الخارجية.
 الجوهر (TM)
الجوهر (TM)إذا حاولت شرح المهمة بلغة بسيطة ، يتم عرض الفكرة في الصورة أدناه. كقاعدة ، يتم تدريس الشبكات العصبية الحديثة لتمييز الأشياء في الصورة. أي عليك أن تتعلم التمييز بين القطط من الكلاب والمواد الإباحية عن المايوه أو الدبابات من الطرق. في الوقت نفسه ، يجب أن تكون دائمًا غير مبالية بكيفية التقاط صورة لقطة وخزان وعلى أي جهاز.

في نفس المسابقة ، كان كل شيء على العكس تماما. بغض النظر عما يظهر في الصورة ، تحتاج إلى تحديد نوع الجهاز. بمعنى ، استخدم أشياء مثل ضوضاء المصفوفة ، وعناصر معالجة الصور ، والعيوب البصرية ، وما إلى ذلك. كان هذا هو التحدي الرئيسي - لتطوير خوارزمية تلتقط ميزات الصور منخفضة المستوى.
ميزات العمل الجماعييتم تشكيل الغالبية العظمى من فرق kaggle على النحو التالي: يتحد المشاركون الذين يتقدمون تقريبًا على لوحة الصدارة في فريق ، بينما يشهد كل واحد نسخته من الحل من البداية إلى النهاية. لقد كتبت
منشورًا عن مثال نموذجي لمثل هذا الخطاب. ومع ذلك ، هذه المرة ذهبنا في الاتجاه الآخر ، وهي: قسمنا أجزاء القرار إلى أشخاص. بالإضافة إلى ذلك ، وفقًا لقواعد المسابقة ، تلقت أفضل 3 فرق طلابية تذكرة إلى كندا للمرحلة الثانية. لذلك ، عندما اجتمع العمود الفقري ، قللنا من عدد الموظفين للامتثال للقواعد.
الحللإظهار نتيجة جيدة في هذه المهمة ، كان من الضروري تجميع اللغز التالي وفقًا للأولويات:
- البحث عن البيانات الخارجية وتنزيلها. تم السماح لهذه المسابقة باستخدام عدد غير محدود من البيانات الخارجية. وسرعان ما أصبح من الواضح أن مجموعة بيانات خارجية كبيرة كانت تسحب.
- تصفية البيانات الخارجية. ينشر الأشخاص أحيانًا صورًا تمت معالجتها ، مما يقتل جميع ميزات الجهاز.
- استخدم مخطط التحقق المحلي الموثوق به. نظرًا لأن نموذجًا واحدًا أظهر الدقة في منطقة 0.98+ ، وفي الاختبار لم يكن هناك سوى 2 ألف لقطة ، وكان اختيار نقطة تفتيش النموذج مهمة منفصلة
- نماذج القطار. تم نشر خط أساسي قوي للغاية في المنتدى. ومع ذلك ، بدون قليل من السحر ، سمح فقط بالفضة.
جمع البياناتاحتل هذا الجزء
آرثر فتاخوف . لهذه المهمة ، كان من السهل جدًا الحصول على بيانات خارجية ، هذه مجرد صور من طرازات هواتف معينة. كتب آرثر نصًا ثعبانيًا يستخدم المكتبة لتحليل صفحات html بسهولة تسمى
BeautifulSoup . ولكن ، على سبيل المثال ، في صفحة ألبوم فليكر ، يتم تحميل كتل الصور ديناميكيًا ، وللتغلب على هذا ، كان علي استخدام
السيلينيوم ، الذي يحاكي عمل المتصفح. تم تنزيل ما يزيد عن 500 غيغابايت من الصور من yandex.fotki و flickr و wiki commons.
تصفية البياناتكانت هذه مساهمتي الوحيدة في الحل في شكل رمز. لقد ألقيت نظرة على كيفية ظهور الصور الخام وعملت مجموعة من القواعد: 1) الحجم النموذجي لنموذج معين 2) جودة jpg أعلى من العتبة 3) وجود العلامات الوصفية اللازمة للنماذج 4) البرنامج الصحيح الذي تمت معالجته.
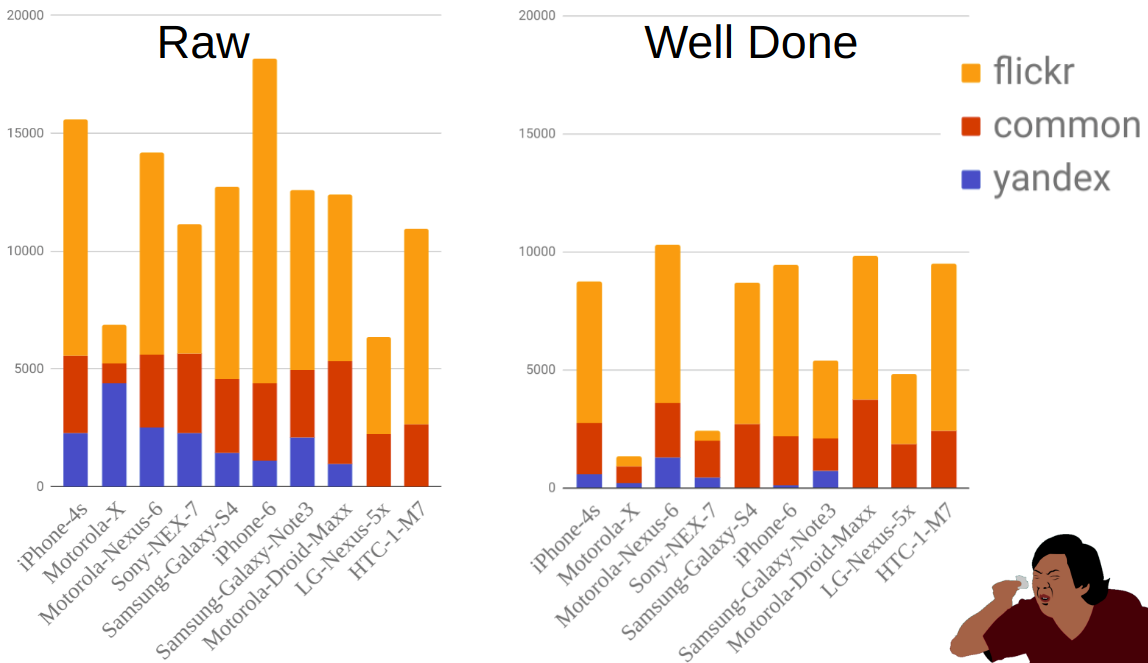
يوضح الشكل توزيع الصور حسب المصدر والجوال قبل وبعد التصفية. كما ترى ، على سبيل المثال ، Moto-X أصغر بكثير من الهواتف الأخرى. في الوقت نفسه ، كان هناك الكثير منهم قبل التصفية ، ولكن تم التخلص من معظمها نظرًا لوجود العديد من الخيارات لهذا الهاتف ولم يشر الملاك دائمًا إلى النموذج بشكل صحيح.
التحققتم تنفيذ الجزء بالتدريب والتحقق من قبل
إيليا كيباردين . لم يفلح التحقق من صحة قطعة قطار kaggle على الإطلاق - فقد أخرجت الشبكة دقة 1.0 تقريبًا ، وكانت على المتصدرين حوالي 0.96.
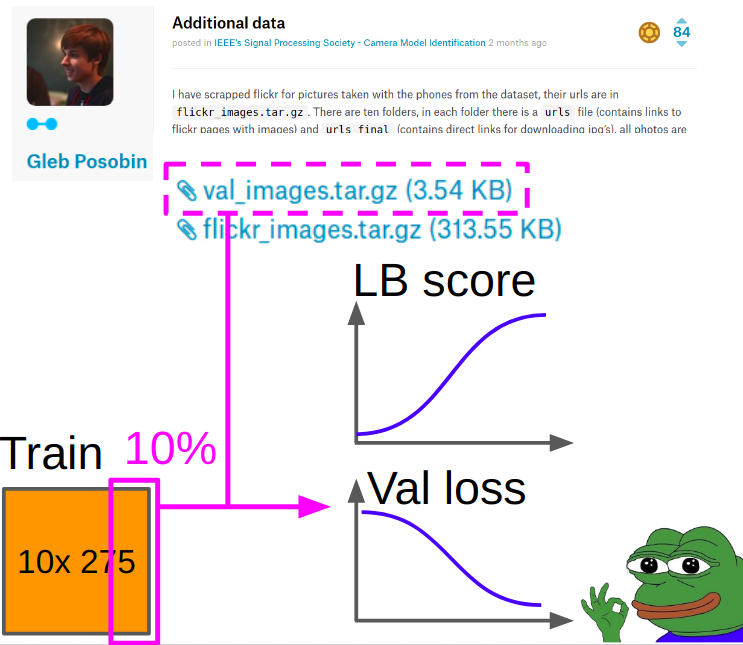
لذلك ، تم أخذ التحقق من صور
Gleb Posobin ، التي أخذها من جميع المواقع مع مراجعات الهاتف. كان هناك خطأ فيه: بدلاً من iPhone 6 كان هناك iPhone 6+. استبدلناها بجهاز iPhone 6 حقيقي وأسقطنا 10 ٪ من الصور من قطار kagla لتحقيق التوازن بين الصفوف.
عند تعلم المقياس تم اعتباره كما يلي:
- نعتبر الإنتروبيا المتقاطعة والأكوراسي في وسط المحصول من التحقق.
- نحن نعتبر الإنتروبيا المتقاطعة والأكوراسي (التلاعب + مركز المحصول) لكل من التلاعبات الثمانية.في المتوسط لها أكثر من ثمانية تلاعبات بمتوسط حسابي.
- نضيف سرعة العنصر 1 والبند 2 بأوزان 0.7 و 0.3.
تم اختيار أفضل نقاط التفتيش وفقًا للانتروبيا المتقاطعة التي تم الحصول عليها في القسم 3.
تدريب نموذجيفي مكان ما في منتصف المسابقة ، نشر
Andres Torrubia الرمز بالكامل
لقراره . لقد كان جيدًا جدًا من حيث دقة النماذج النهائية التي حلقت مجموعة من الفرق معه في الصدارة. ومع ذلك ، فقد كتب في keras ومستوى الرمز المطلوب.
تغير الوضع مرة أخرى عندما نشر
إيفان رومانوف نسخة pytorch من هذا الرمز. كان أسرع ، وإلى جانب ذلك ، كان يوازي بسهولة العديد من بطاقات الفيديو. ومع ذلك ، لم يكن مستوى الشفرة جيدًا جدًا ، ولكن هذا ليس مهمًا جدًا.
الحزن هو أن هؤلاء الرجال انتهوا في المركزين 30 و 45 على التوالي ، ولكن في قلوبنا ظلوا دائمًا في القمة.
أخذ إيليا في فريقنا كود ميشا وأجرى التغييرات التالية.
المعالجة المسبقة:- من الصورة الأصلية يتم إجراء محصول عشوائي 960x960.
- مع احتمال 0.5 ، يتم تطبيق معالجة عشوائية واحدة. (بناءً على ما إذا كان مستخدمًا ، is_manip = 1 أو 0 تم تعيينه)
- يتم إجراء محصول عشوائي 480x480
- كان هناك خياران للتدريب: إما أن يتم دوران 90 درجة بشكل عشوائي في اتجاه معين (محاكاة التصوير الأفقي / الرأسي للهاتف المحمول) ، أو تحويل عشوائي لمجموعة D4.
 تدريب
تدريبتم التدريب من قبل الشبكة بأكملها ، دون تجميد الطبقات التلافيفية المصنفة (كان لدينا الكثير من البيانات + بشكل حدسي ، الأوزان التي يمكن أن تضاف إليها الأشياء عالية المستوى في شكل قطط / كلاب لأننا نحتاج إلى ميزات منخفضة المستوى).
 تسليط:
تسليط:آدم مع lr = 1e-4. عندما يتوقف تحسن التحقق من الصحة خلال 2-3 حقب ، فإننا نخفض lr بمقدار النصف. حتى التقارب. استبدل آدم بـ SGD وتعلم ثلاث دورات بـ lr دوري من 1e-3 إلى 1e-6.
الفرقة النهائية:طلبت من إيليا تنفيذ نهجي من المسابقة السابقة. بالنسبة للمجموعة البنائية ، قمنا بتدريب 9 نماذج ، من بين كل واحد قمنا بتحديد أفضل 3 نقاط تفتيش ، تم توقع كل نقطة تفتيش مع TTA وفي المتوسط تم توقع جميع التوقعات بالمتوسط الهندسي.
 خاتمة المرحلة الأولى
خاتمة المرحلة الأولىونتيجة لذلك ، احتلنا المركز الثاني في لوحة الصدارة والمركز الأول بين فرق الطلاب. وهذا يعني أننا وصلنا إلى المرحلة الثانية من هذه المسابقة كجزء من مؤتمر
IEEE الدولي لعام 2018 حول الصوتيات ومعالجة الكلام والإشارة في كندا. من اللافت للنظر أن الفريق الذي حصل على المركز الثالث كان أيضًا طالبًا رسميًا. إذا قمنا بحساب السرعة ، اتضح أننا قمنا بالالتفاف عليها بصورة واحدة متوقعة بشكل صحيح.
كأس IEEE النهائي لمعالجة الإشارات 2018بعد أن تلقينا كل التأكيدات ، قررت أنا وفاليري وأندري عدم الذهاب إلى كندا للمرحلة الثانية. قرر إيليا وأرثر ف. الذهاب وبدأوا في ترتيب كل شيء ولم يتم منحهم تأشيرة. لتجنب فضيحة دولية حول اضطهاد أقوى العلماء من روسيا ، سُمح للعربد بالمشاركة عن بُعد.
كان المخطط الزمني كما يلي:
03.03 - نظرا لبيانات القطار
04.09 - بيانات الاختبار الصادرة
12.04 - سمح لنا بالمشاركة عن بعد
13.04 - بدأنا ننظر إلى ما هو موجود بالبيانات
04/16 - نهائي
ملامح المرحلة الثانيةفي المرحلة الثانية لم يكن هناك ليدربورد: كان من الضروري إرسال طلب واحد فقط في النهاية. أي أنه لا يمكن التحقق من شكل التنبؤات. أيضا ، لم تكن نماذج الكاميرا معروفة. وهذا يعني ملفين في وقت واحد: لن يعمل باستخدام البيانات الخارجية ويمكن أن يكون التحقق المحلي غير تمثيلي للغاية.
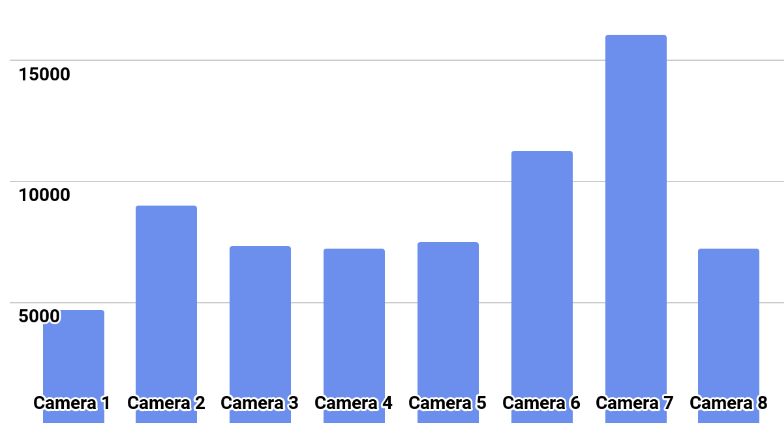
يظهر توزيع الفصل في الصورة.
الحلحاولنا تدريب العارضين بخطة من المرحلة الأولى من موازين أفضل العارضات. تم تدريب جميع الموديلات بمرح على دقة 0.97+ على طياتها ، ولكن في الاختبار أعطوا تقاطعًا بين التنبؤات في منطقة 0.87.
ما فسّرته على أنه ملابس قاسية. لذلك اقترح خطة جديدة:
- نأخذ أفضل نماذجنا في المرحلة الأولى كمستخرجين للميزات.
- نأخذ PCA من الميزات المستخرجة بحيث يتعلم كل شيء بين عشية وضحاها.
- تعلم LightGBM.

المنطق هنا هو على النحو التالي. تم تدريب الشبكات العصبية بالفعل على استخراج ميزات منخفضة المستوى من أجهزة الاستشعار ، والبصريات ، وخوارزمية العرض ، وفي الوقت نفسه لا يتمسكون بالسياق. بالإضافة إلى ذلك ، فإن الميزات المستخرجة قبل المصنف النهائي (في الواقع ، الانحدار اللوجستي) هي نتيجة تحول غير خطي بقوة. لذلك ، يمكن للمرء ببساطة تعليم شيء بسيط ، وليس عرضة لإعادة التدريب ، مثل الانحدار اللوجستي. ومع ذلك ، نظرًا لأن البيانات الجديدة يمكن أن تكون مختلفة تمامًا عن بيانات المرحلة الأولى ، فلا يزال من الأفضل تدريب شيء غير خطي ، على سبيل المثال ، تعزيز التدرج على أشجار القرار. لقد استخدمت هذا النهج في العديد من المسابقات ، حيث نشرت الرمز.
نظرًا لوجود إرسال واحد ، ليس لدي طريقة موثوقة لاختبار نهجي. ومع ذلك ، أثبتت DenseNet أنها أفضل مستخرج للميزات. أظهرت شبكات Resnext و SE-Resnext أداء أقل في التحقق المحلي. لذلك ، بدا القرار النهائي على هذا النحو.
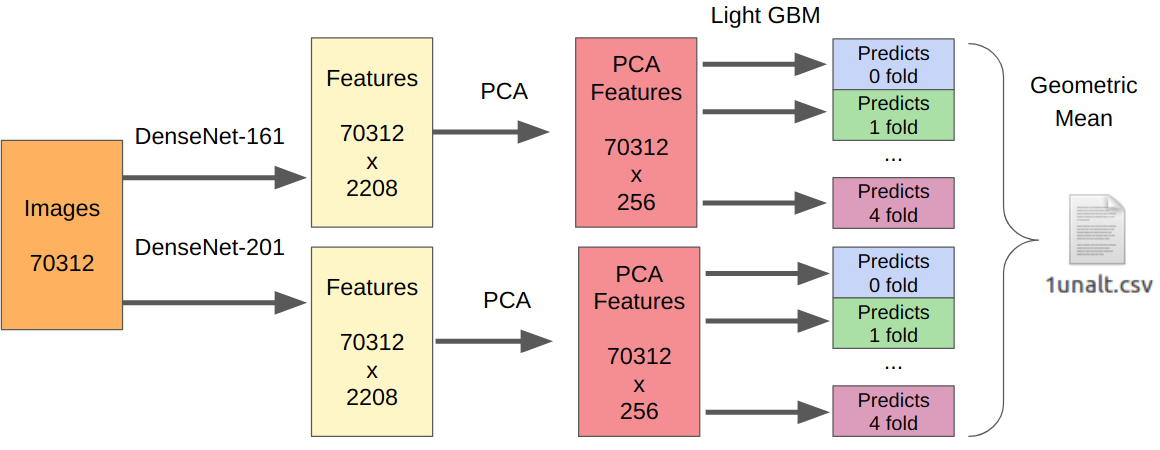
بالنسبة للجزء المتعلق بالتلاعب ، يجب ضرب عدد جميع عينات التدريب في 7 ، حيث قمت باستخراج الميزات من كل معالجة بشكل منفصل.
خاتمةنتيجة لذلك ، في المرحلة النهائية احتلنا المركز الثاني ، ولكن هناك العديد من التحفظات. بادئ ذي بدء ، تم منح المكان ليس وفقًا لدقة الخوارزمية ، ولكن وفقًا لتقديرات عرض هيئة المحلفين. الفريق ، الذي حصل على المركز الأول ، لم يكن مجرد عرض مسبق ، بل أيضًا عرضًا توضيحيًا حيًا مع عمل الخوارزمية. حسنًا ، ما زلنا لا نعرف السرعة النهائية لكل فريق ، ولا تفصح المؤسسات عن ذلك في المراسلات حتى بعد الأسئلة المباشرة.
من الأشياء المضحكة: في المرحلة الأولى ، أشارت جميع فرق مجتمعنا في اسم الفريق [ods.ai] واحتلت الصدارة بقوة. بعد ذلك ، قررت أساطير kegle مثل
الانقلاب و
Giba الانضمام إلينا لمعرفة ما كنا نفعله هنا.

لقد استمتعت حقا بالمشاركة كمرشد. بناءً على تجربة المشاركة في المسابقات السابقة ، تمكنت من تقديم عدد من النصائح القيمة حول تحسين خط الأساس ، فضلاً عن بناء التحقق المحلي. في المستقبل ، سيكون هذا التنسيق أكثر من الحال: Kaggle Master / Grandmaster كمهندس للحل + 2-3 Kaggle Expert لكتابة التعليمات البرمجية واختبار الفرضيات. في رأيي ، هذا هو فوز صافٍ ، حيث أن المشاركين ذوي الخبرة كسالى جدًا بالفعل في كتابة التعليمات البرمجية وربما ليس الكثير من الوقت ، ويحصل المبتدئون على نتيجة أفضل ، ولا ترتكب أخطاء تافهة بسبب عدم الخبرة واكتساب الخبرة بشكل أسرع.
→
رمز حلنا→
أداء التسجيل مع تجريب ML