على الإنترنت الحديث ، يوجد أكثر من 630 مليون موقع ، لكن 6٪ فقط منها تحتوي على محتوى باللغة الروسية. إن حاجز اللغة هو المشكلة الرئيسية لنشر المعرفة بين مستخدمي الشبكة ، ونعتقد أنه يجب حلها ليس فقط من خلال تدريس اللغات الأجنبية ، ولكن أيضًا باستخدام الترجمة الآلية التلقائية في المتصفح.
اليوم سنخبر قراء هبر عن تغيرين تكنولوجيين مهمين في مترجم Yandex.Browser. أولاً ، تستخدم ترجمة الكلمات والعبارات المحددة نموذجًا هجينًا ، ونتذكر كيف يختلف هذا النهج عن استخدام الشبكات العصبية حصريًا. ثانيًا ، تأخذ الشبكة العصبية للمترجم في الاعتبار الآن بنية صفحات الويب ، والتي سنناقش ميزاتها أيضًا في الخفض.
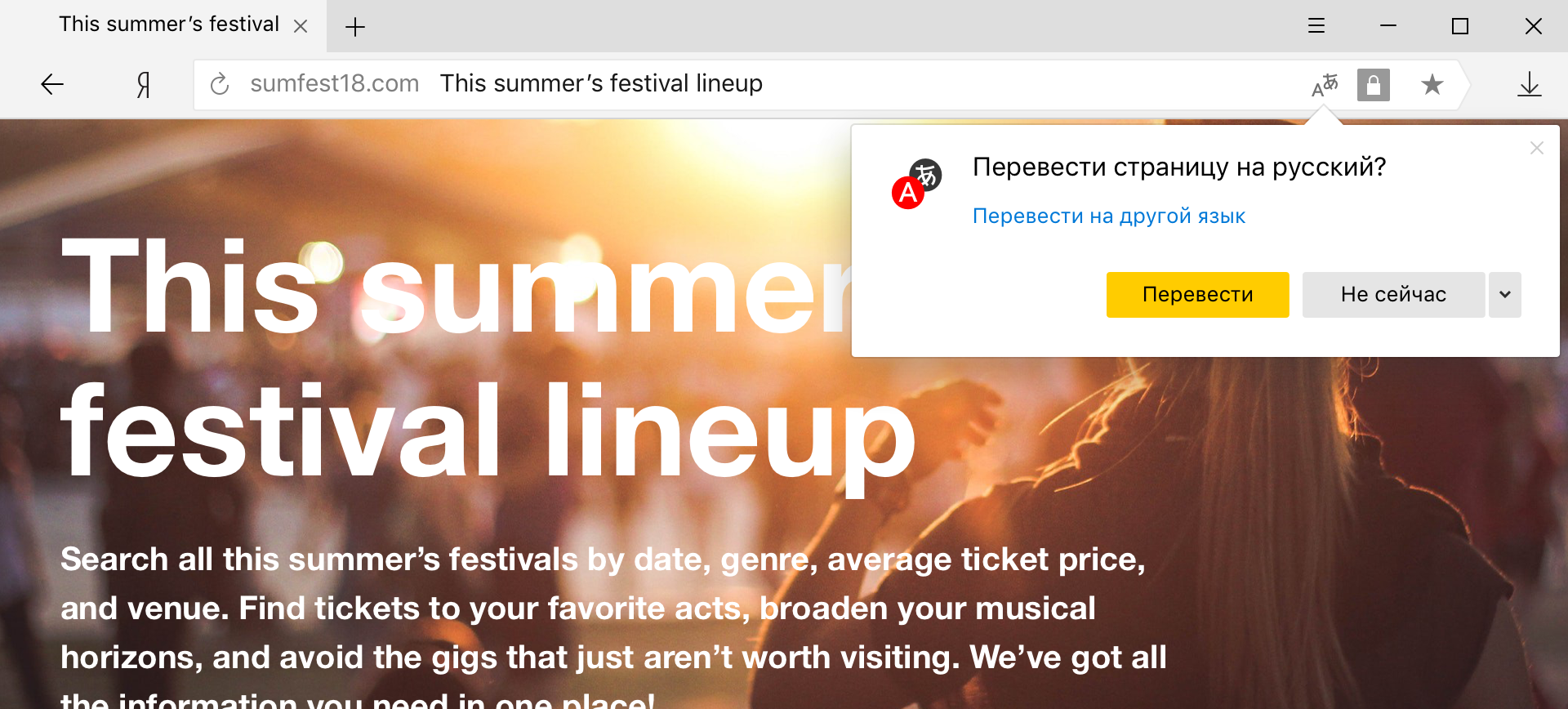
الهجينة كلمة ومترجم العبارة
استندت أنظمة الترجمة الآلية الأولى إلى
القواميس والقواعد (في الواقع ، النظامي المكتوب يدويًا) ، التي حددت جودة الترجمة. عمل اللغويون المحترفون لسنوات للتوصل إلى قواعد يدوية أكثر تفصيلاً. كان هذا العمل مستهلكًا للوقت لدرجة أنه تم إيلاء اهتمام جاد فقط لأزواج اللغات الأكثر شيوعًا ، ولكن حتى في إطارها ، تعاملت الآلات بشكل سيئ. اللغة الحية هي نظام معقد للغاية لا يلتزم بالقواعد. من الأصعب وصف قواعد المراسلات للغتين.
الطريقة الوحيدة التي يمكن بها للآلة التكيف باستمرار مع الظروف المتغيرة هي التعلم بشكل مستقل على عدد كبير من النصوص المتوازية (متطابقة في المعنى ، ولكنها مكتوبة بلغات مختلفة). هذا هو النهج الإحصائي للترجمة الآلية. يقارن الكمبيوتر النصوص المتوازية ويكشف عن الأنماط بشكل مستقل.
يتمتع
المترجم الإحصائي بمزايا وعيوب. من ناحية ، يتذكر الكلمات والعبارات النادرة والمعقدة. إذا تم العثور عليها في نصوص متوازية ، فسوف يتذكرها المترجم وسيستمر في الترجمة بشكل صحيح. من ناحية أخرى ، يمكن أن تكون نتيجة الترجمة مشابهة للألغاز المجمعة: تبدو الصورة العامة مفهومة ، ولكن إذا نظرت عن كثب ، يمكنك أن ترى أنها تتكون من قطع منفصلة. والسبب هو أن المترجم يقدم كلمات فردية في شكل معرفات ، والتي لا تعكس بأي شكل العلاقة بينهما. لا يتوافق هذا مع الكيفية التي ينظر بها الناس إلى اللغة عندما يتم تحديد الكلمات من خلال كيفية استخدامها ، وكيف ترتبط بالكلمات الأخرى ، وكيف تختلف عنها.
تساعد
الشبكات العصبية في حل هذه المشكلة. يتطابق تمثيل المتجهات للكلمات (تضمين الكلمات) المستخدمة في الترجمة الآلية العصبية ، كقاعدة ، مع كل كلمة بمتجه عدة مئات من الأرقام. يتم تشكيل المتجهات ، على النقيض من المعرّفات البسيطة من النهج الإحصائي ، أثناء تدريب الشبكة العصبية وتأخذ في الاعتبار العلاقة بين الكلمات. على سبيل المثال ، يمكن للنموذج أن يدرك أنه نظرًا لأن "الشاي" و "القهوة" غالبًا ما يظهران في سياقات متشابهة ، فيجب أن تكون هاتان الكلمتان ممكنتين في سياق الكلمة الجديدة "انسكاب" ، والتي ، على سبيل المثال ، تم العثور على واحد منهما فقط في بيانات التدريب.
ومع ذلك ، من الواضح أن عملية تدريس تمثيلات المتجهات تتطلب إحصائيًا أكثر من حفظ الأمثلة ميكانيكيًا. بالإضافة إلى ذلك ، ليس من الواضح ما يجب فعله بتلك الكلمات الإدخال النادرة التي لم يتم تلبيتها في كثير من الأحيان بما يكفي للشبكة لبناء تمثيل متجه مقبول لهم. في هذه الحالة ، من المنطقي الجمع بين كلتا الطريقتين.
منذ العام الماضي ، تستخدم Yandex.Translator
نموذجًا هجينًا . عندما يتلقى المترجم النص من المستخدم ، فإنه يعطيه لكلا النظامين - كل من الشبكة العصبية والمترجم الإحصائي. ثم تقوم خوارزمية تعتمد على أسلوب التدريب
CatBoost بتقييم الترجمة الأفضل. عند تسجيل النقاط ، تؤخذ العشرات من العوامل في الاعتبار - من طول الجملة (يتم ترجمة العبارات القصيرة بشكل أفضل بواسطة النموذج الإحصائي) إلى بناء الجملة. يتم عرض الترجمة المعترف بها على أنها الأفضل للمستخدم.
إنه النموذج الهجين المستخدم الآن في Yandex.Browser ، عندما يختار المستخدم كلمات وعبارات معينة في الصفحة للترجمة.
هذا الوضع مناسب بشكل خاص لأولئك الذين يتحدثون لغة أجنبية بشكل عام ويودون ترجمة الكلمات غير المعروفة فقط. ولكن إذا كنت ، على سبيل المثال ، بدلاً من اللغة الإنجليزية المعتادة ، صادفت الصينية ، فسيكون من الصعب الاستغناء عن مترجم الصفحة. يبدو أن الاختلاف يكمن فقط في حجم النص المترجم ، ولكنه ليس بهذه البساطة.
مترجم الشبكة العصبية على شبكة الإنترنت
منذ وقت
تجربة جورجتاون وحتى اليوم تقريبًا ، تم تدريب جميع أنظمة الترجمة الآلية على ترجمة كل جملة من النص المصدر بشكل فردي. في حين أن صفحة الويب ليست مجرد مجموعة من الجمل ، ولكنها نص منظم توجد فيه عناصر مختلفة بشكل أساسي. فكر في العناصر الأساسية لمعظم الصفحات.
العنوان . عادة ما يكون النص ساطعًا وكبيرًا نراه على الفور عند الانتقال إلى الصفحة. غالبًا ما يحتوي العنوان على جوهر الأخبار ، لذا من المهم ترجمته بشكل صحيح. ولكن من الصعب القيام بذلك ، لأن النص في العنوان صغير وبدون فهم السياق ، يمكنك ارتكاب خطأ. في حالة اللغة الإنجليزية ، لا يزال الأمر أكثر تعقيدًا ، لأن عناوين اللغة الإنجليزية غالبًا ما تحتوي على عبارات ذات قواعد غير تقليدية ، أو صيغ لا حصر لها ، أو حتى أفعال تفتقدها. على سبيل المثال ، تم
الإعلان عن برقول Game of Thrones .
التنقل الكلمات والعبارات التي تساعدنا على تصفح الموقع. على سبيل المثال ،
الصفحة الرئيسية والظهر وحسابي لا تستحق الترجمة على أنها "المنزل" و "الخلف" و "حسابي" إذا كانت موجودة في قائمة الموقع وليس في نص المنشور.
النص الرئيسي . كل شيء أبسط معه ؛ فهو يختلف قليلاً عن النصوص والجمل العادية التي يمكن أن نجدها في الكتب. ولكن حتى هنا من المهم التأكد من اتساق الترجمات ، أي ضمان ترجمة نفس المصطلحات والمفاهيم داخل نفس صفحة الويب بنفس الطريقة.
للترجمة عالية الجودة لصفحات الويب ، لا يكفي استخدام شبكة عصبية أو نموذج مختلط - يجب عليك أيضًا مراعاة بنية الصفحات. ولهذا نحن بحاجة للتعامل مع العديد من الصعوبات التكنولوجية.
تصنيف مقاطع النص . للقيام بذلك ، نستخدم مرة أخرى CatBoost والعوامل المستندة إلى كل من النص نفسه وعلى ترميز HTML للمستندات (العلامة ، حجم النص ، عدد الروابط لكل وحدة نصية ، ...). العوامل غير متجانسة تمامًا ، وبالتالي فإن CatBoost (بناءً على تعزيز التدرج) هو الذي يظهر أفضل النتائج (دقة التصنيف أعلى من 95٪). لكن تصنيف القطاعات وحده لا يكفي.
عدم التوازن في البيانات . تقليديا ، تتعلم خوارزميات Yandex.Translator على النصوص من الإنترنت. يبدو أن هذا هو الحل المثالي لتدريب مترجم لصفحات الويب (بعبارة أخرى ، تتعلم الشبكة من نصوص من نفس طبيعة تلك النصوص التي سنستخدمها فيها). ولكن بمجرد أن تعلمنا فصل الأجزاء المختلفة عن بعضها البعض ، وجدنا ميزة مثيرة للاهتمام. في المتوسط ، يشغل المحتوى حوالي 85٪ من جميع النصوص على مواقع الويب ، بينما تمثل العناوين والملاحة 7.5٪ فقط لكل منها. تذكر أيضًا أن العناوين وعناصر التنقل في النمط والنحو نفسها تختلف بشكل ملحوظ عن بقية النص. يؤدي هذان العاملان معًا إلى مشكلة انحراف البيانات. من الأفضل للشبكة العصبية أن تتجاهل ببساطة ميزات هذه الأجزاء الضعيفة التمثيل في مجموعة التدريب. تتعلم الشبكة الترجمة الجيدة للنص الرئيسي فقط ، بسبب جودة الترجمة للرؤوس والملاحة. لتحييد هذا التأثير غير السار ، قمنا بعمل شيئين: لكل زوج من الجمل المتوازية ، نسبنا أحد الأنواع الثلاثة من المقاطع (المحتوى أو العنوان أو التنقل) كمعلومات وصفية ورفعنا بشكل مصطنع تركيز الاثنين الأخيرين في مبنى التدريب إلى 33٪ بسبب حقيقة أن بدأت تظهر أمثلة مماثلة للشبكة العصبية التعلم في كثير من الأحيان.
تعلم متعدد المهام . نظرًا لأننا قادرون الآن على فصل النصوص على صفحات الويب إلى ثلاث فئات من الأقسام ، فقد يبدو من الطبيعي أن تدرب ثلاثة نماذج منفصلة ، كل منها سيتعامل مع ترجمة نوع النصوص الخاص به - العناوين أو التنقل أو المحتوى. يعمل هذا بشكل جيد حقًا ، لكن المخطط يعمل بشكل أفضل عندما نقوم بتدريب شبكة عصبية واحدة لترجمة جميع أنواع النصوص في وقت واحد. يكمن مفتاح الفهم في فكرة
التعلم متعدد المهام (MTL): إذا كان هناك اتصال داخلي بين العديد من مهام التعلم الآلي ، فإن النموذج الذي يتعلم حل هذه المشاكل في نفس الوقت يمكن أن يتعلم حل كل مشكلة بشكل أفضل من نموذج متخصص ضيق النطاق!
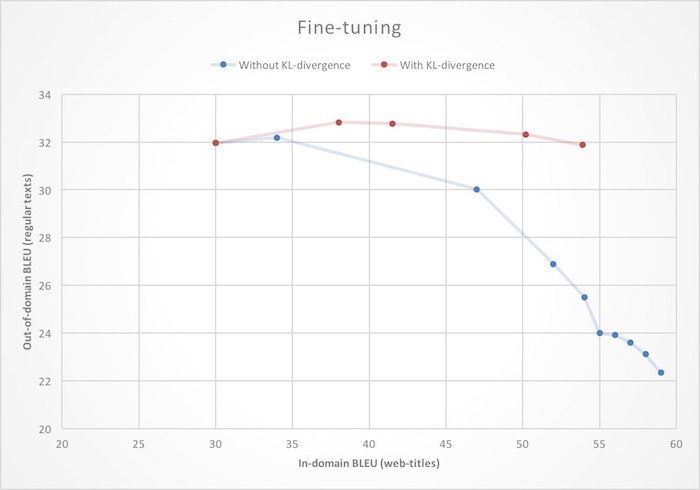
صقل . لقد كان لدينا بالفعل ترجمة آلية جيدة جدًا ، لذلك سيكون من غير المعقول تدريب مترجم جديد لـ Yandex.Browser من البداية. من المنطقي أكثر أن تتخذ نظامًا أساسيًا لترجمة النصوص العادية وإعادة تدريبها للعمل مع صفحات الويب. في سياق الشبكات العصبية ، غالبًا ما يشار إلى هذا باسم الضبط الدقيق. ولكن إذا اقتربت من هذه المهمة وجهاً لوجه ، أي فقط لتهيئة أوزان الشبكة العصبية بالقيم من النموذج النهائي وبدء التعلم على البيانات الجديدة ، قد تواجه تأثير تحول النطاق: كما تعلم ، ستزداد جودة ترجمة صفحات الويب (داخل النطاق) ، ولكن جودة ترجمة الصفحات العادية (خارج النطاق) ) ستسقط النصوص. للتخلص من هذه الميزة غير السارة ، أثناء إعادة التدريب ، نفرض قيودًا إضافية على الشبكة العصبية ، ونمنعها من تغيير الأوزان كثيرًا مقارنة بالحالة الأولية.
رياضيا ، يتم التعبير عن ذلك عن طريق إضافة المصطلح إلى دالة الخسارة ، وهي
مسافة Kullback - Leibler (اختلاف KL) بين التوزيعات الاحتمالية للكلمة التالية التي تم إنشاؤها بواسطة الشبكات الأصلية وإعادة التدريب. كما ترى في الرسم التوضيحي ، يؤدي هذا إلى حقيقة أن الزيادة في جودة ترجمة صفحات الويب لم تعد تؤدي إلى تدهور ترجمة النص العادي.
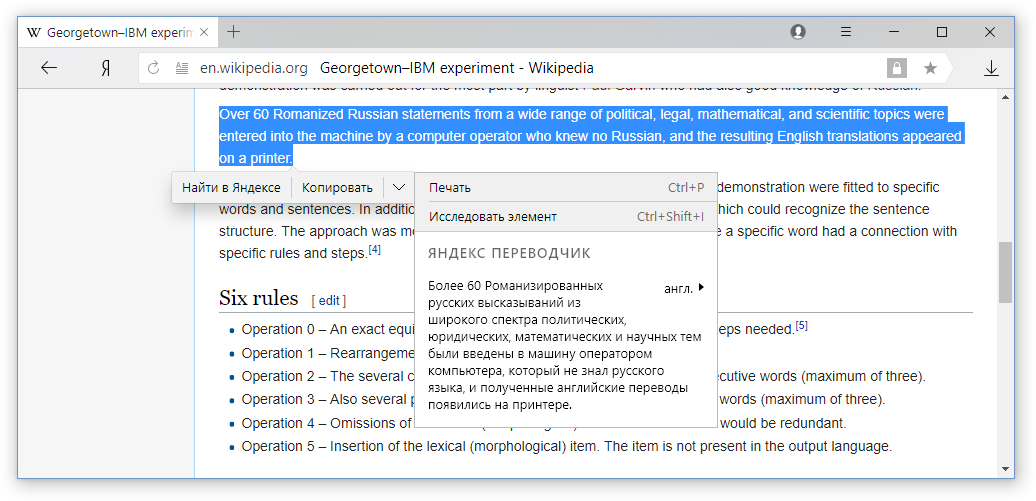
 تلميع عبارات التردد من الملاحة
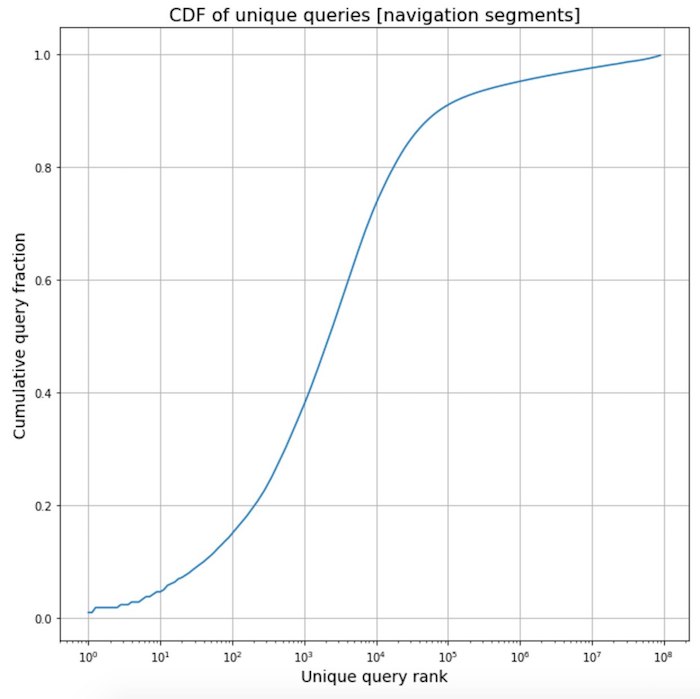
تلميع عبارات التردد من الملاحة . في سياق العمل على مترجم جديد ، قمنا بجمع إحصائيات حول نصوص أجزاء مختلفة من صفحات الويب ورأينا واحدة مثيرة للاهتمام. يتم توحيد النصوص المتعلقة بعناصر التنقل إلى حد كبير ، لذلك غالبًا ما تكون نفس العبارات النموذجية. يعد هذا تأثيرًا قويًا لدرجة أن أكثر من نصف جميع عبارات التنقل الموجودة على الإنترنت لا تمثل سوى ألفي من العبارات الأكثر شيوعًا.
بالطبع ، استفدنا من هذا وأعطينا عدة آلاف من العبارات الأكثر شيوعًا وترجماتها لمترجمينا للتحقق منها للتأكد من جودتها تمامًا.
المحاذاة الخارجية. كان هناك مطلب مهم آخر لمترجم صفحة الويب في المتصفح - يجب ألا يشوه الترميز. عندما توجد علامات HTML خارج الجمل أو عند حدودها ، لا تنشأ مشاكل. ولكن إذا كانت هناك ، على سبيل المثال ،
كلمتان مسطرتان داخل الجملة ، فإننا في الترجمة نريد أن نرى "كلمتين
مسطرتين ". على سبيل المثال نتيجة للتحويل ، يجب استيفاء شرطين:
- يجب أن يتوافق الجزء المسطر في الترجمة مع الجزء المسطر في النص المصدر.
- لا ينبغي انتهاك اتساق الترجمة على حدود الجزء الذي تحته خط.
من أجل ضمان هذا السلوك ، نقوم أولاً بترجمة النص كالمعتاد ، ثم باستخدام النماذج الإحصائية لمحاذاة
الكلمات بكلمة ، نحدد
التوافق بين أجزاء النص الأصلي والمترجم. وهذا يساعد على فهم ما يجب التأكيد عليه (تمييز بخط مائل ، والتنسيق كارتباط تشعبي ، ...).
مراقب تقاطع . تتطلب نماذج ترجمة الشبكة العصبية القوية التي قمنا بتدريبها موارد حوسبة أكبر بكثير على خوادمنا (كل من وحدة المعالجة المركزية ووحدة معالجة الرسومات) أكثر من النماذج الإحصائية للأجيال السابقة. في الوقت نفسه ، لا يقرأ المستخدمون دائمًا الصفحات حتى النهاية ، لذلك يبدو أن إرسال كل نص صفحات الويب إلى السحابة غير ضروري. لحفظ موارد الخادم وحركة مرور المستخدم ، علمنا المترجم استخدام
واجهة برمجة تطبيقات Intersection Observer لإرسال النص المعروض على الشاشة فقط للترجمة. ونتيجة لذلك ، تمكنا من تقليل استهلاك حركة المرور للترجمة بأكثر من 3 مرات.
بضع كلمات حول نتائج إدخال مترجم شبكة عصبية مع مراعاة بنية صفحات الويب في Yandex.Browser. لتقييم جودة الترجمات ، نستخدم مقياس BLEU * ، الذي يقارن الترجمات التي أجراها جهاز ومترجم محترف ، ويقيم جودة الترجمة الآلية على مقياس من 0 إلى 100٪. كلما كانت الترجمة الآلية أقرب إلى الترجمة البشرية ، زادت النسبة المئوية. عادةً ما يلاحظ المستخدمون تغييرًا في الجودة عندما ينمو مقياس BLEU بنسبة 3٪ على الأقل. أظهر مترجم Yandex.Browser الجديد زيادة بنسبة 18٪ تقريبًا.

الترجمة الآلية هي واحدة من أكثر المهام تعقيدًا ، وأكثرها بحثًا في مجال تقنيات الذكاء الاصطناعي. ويرجع ذلك إلى جاذبيتها الرياضية البحتة وأهميتها في العالم الحديث ، حيث يتم في كل ثانية إنشاء كمية لا تصدق من المحتوى على الإنترنت بلغات مختلفة. الترجمة الآلية ، التي تسببت حتى وقت قريب جدًا في الضحك بشكل رئيسي (تذكر
صانعي الفأرة ) ، في الوقت الحاضر تساعد المستخدمين على التغلب على حواجز اللغة.
الجودة المثالية لا تزال بعيدة ، لذلك سنستمر في التحرك في طليعة التكنولوجيا في هذا الاتجاه بحيث يمكن لمستخدمي Yandex.Browser تجاوز ، على سبيل المثال ، Runet والعثور على محتوى مفيد لأنفسهم في أي مكان على الإنترنت.