تقدم هذه المقالة نظرة عامة نظرية يمكن الوصول إليها للشبكات العصبية التلافيفية (CNN) وتشرح تطبيقها على مشكلة تصنيف الصور.
نهج مشترك: لا تعلم عميق
يشير مصطلح "معالجة الصور" إلى فئة واسعة من المهام التي تكون بيانات الإدخال فيها صورًا ، ويمكن أن يكون الإخراج إما صورًا أو مجموعات من الميزات المميزة المرتبطة. هناك العديد من الخيارات: التصنيف ، والتجزئة ، والتعليق ، والكشف عن الأشياء ، وما إلى ذلك. في هذه المقالة ، ندرس تصنيف الصور ، ليس فقط لأنها أبسط مهمة ، ولكن أيضًا لأنها تكمن وراء العديد من المهام الأخرى.
يتكون النهج العام لتصنيف الصور من الخطوتين التاليتين:
- توليد ميزات مهمة للصورة.
- تصنيف صورة بناءً على سماتها.
يستخدم التسلسل الشائع للعمليات نماذج بسيطة مثل MultiLayer Perceptron (MLP) وآلة ناقلات الدعم (SVM) وطريقة أقرب الجيران والانحدار اللوجستي فوق الميزات التي تم إنشاؤها يدويًا. يتم إنشاء السمات باستخدام تحويلات متنوعة (على سبيل المثال ، كشف درجات الرمادي والكشف عن العتبة) والوصف ، على سبيل المثال ، الرسم البياني للتدرجات الموجهة (
HOG ) أو تحويلات تحويل الميزات الثابتة (
SIFT ) ، و الخ.
القيد الرئيسي للطرق المقبولة بشكل عام هو مشاركة خبير يختار مجموعة وتسلسل خطوات لتوليد الميزات.
مع مرور الوقت ، لوحظ أن معظم تقنيات توليد الميزات يمكن تعميمها باستخدام kernels (المرشحات) - المصفوفات الصغيرة (عادة 5 × 5 في الحجم) ، وهي تلاقي الصور الأصلية. يمكن اعتبار الالتفاف عملية متتابعة من مرحلتين:
- تمرير نفس النواة الثابتة في جميع أنحاء الصورة المصدر بأكملها.
- في كل خطوة ، احسب الناتج القياسي للنواة والصورة الأصلية في الموقع الحالي للنواة.
نتيجة الالتواء على الصورة والنواة تسمى خريطة المعالم.
يتم تقديم تفسير أكثر دقة رياضيًا في
الفصل ذي الصلة من الكتاب المنشور حديثًا ، Deep Learning ، من تأليف I. Goodfellow و I. Benjio و A. Courville.
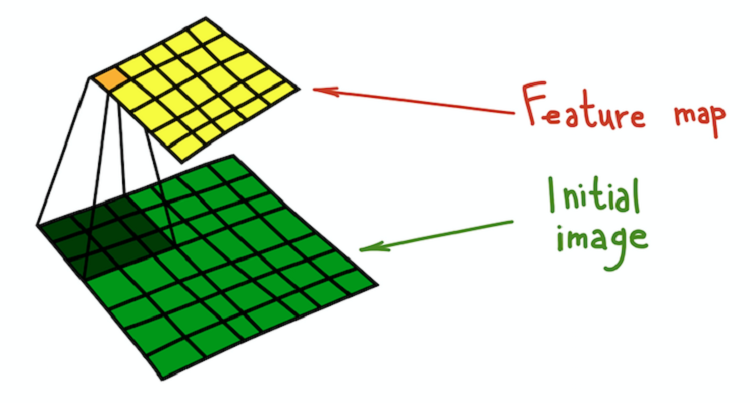 عملية الالتواء في القلب (الأخضر الداكن) مع الصورة الأصلية (الخضراء) ، ونتيجة لذلك يتم الحصول على خريطة المعالم (أصفر).
عملية الالتواء في القلب (الأخضر الداكن) مع الصورة الأصلية (الخضراء) ، ونتيجة لذلك يتم الحصول على خريطة المعالم (أصفر).من الأمثلة البسيطة للتحول الذي يمكن إجراؤه باستخدام الفلاتر عدم وضوح الصورة. خذ مرشح يتكون من جميع الوحدات. يحسب متوسط الحي الذي يحدده المرشح. في هذه الحالة ، يكون الحي مقطعًا مربعًا ، ولكن يمكن أن يكون صلبًا أو أي شيء آخر. يؤدي المتوسط إلى فقدان المعلومات حول الموقع الدقيق للأشياء ، مما يؤدي إلى عدم وضوح الصورة بأكملها. يمكن إعطاء تفسير بديهي مماثل لأي مرشح تم إنشاؤه يدويًا.
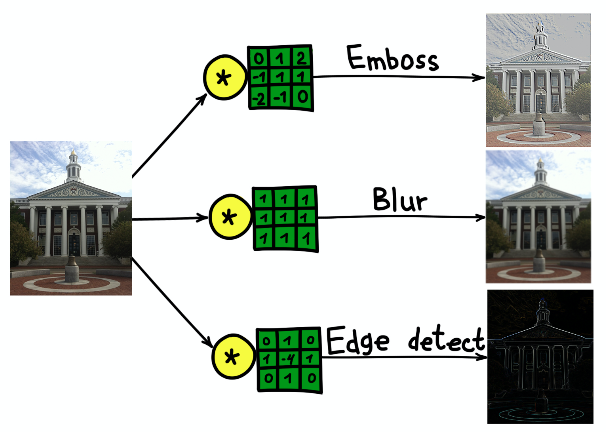 نتيجة الالتواء على صورة مبنى جامعة هارفارد بثلاث نوى مختلفة.
نتيجة الالتواء على صورة مبنى جامعة هارفارد بثلاث نوى مختلفة.الشبكات العصبية التلافيفية
يحتوي النهج التلافيفي لتصنيف الصور على عدد من العوائق الهامة:
- عملية متعددة الخطوات بدلاً من تسلسل من طرف إلى طرف.
- تعتبر الفلاتر أداة تعميمية رائعة ، ولكنها مصفوفات ثابتة. كيفية اختيار الأوزان في الفلاتر؟
لحسن الحظ ، تم اختراع الفلاتر القابلة للتعلم ، وهي المبدأ الأساسي الكامن وراء CNN. المبدأ بسيط: سنقوم بتدريب المرشحات المطبقة على وصف الصور من أجل تحقيق مهمتهم على أفضل وجه.
لا يوجد لدى CNN مخترع واحد ، ولكن إحدى الحالات الأولى لتطبيقها هي LeNet-5 * في العمل
" التعلم القائم على التدرج المطبق على التعرف على المستندات" من قبل I. LeCun وغيرها الكتاب.
تقتل CNN عصفورين بحجر واحد: ليست هناك حاجة لتعريف أولي للمرشحات ، وتصبح عملية التعلم من البداية إلى النهاية. تتكون بنية CNN النموذجية من الأجزاء التالية:
- طبقات تلافيفية
- طبقات فرعية
- طبقات كثيفة (متصلة بالكامل)
دعونا ننظر في كل جزء بمزيد من التفصيل.
طبقات تلافيفية
الطبقة التلافيفية هي العنصر الهيكلي الرئيسي لشبكة CNN. للطبقة التلافيفية مجموعة من الخصائص:
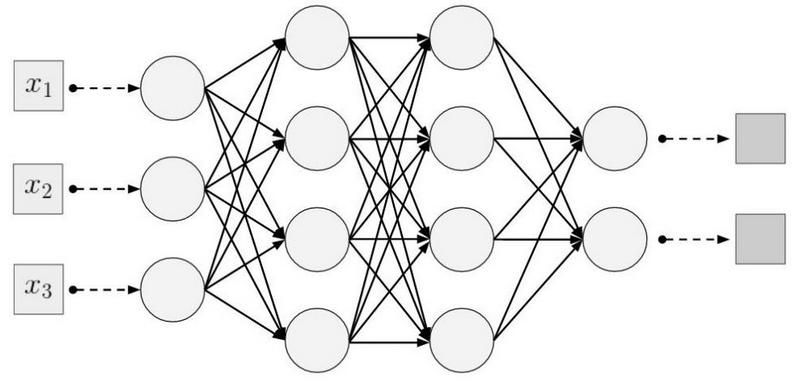
اتصال محلي (متناثر) . في الطبقات الكثيفة ، يرتبط كل عصبون بكل عصبون من الطبقة السابقة (لذلك كانت تسمى كثيفة). في الطبقة التلافيفية ، يرتبط كل خلية عصبية بجزء صغير فقط من الخلايا العصبية للطبقة السابقة.
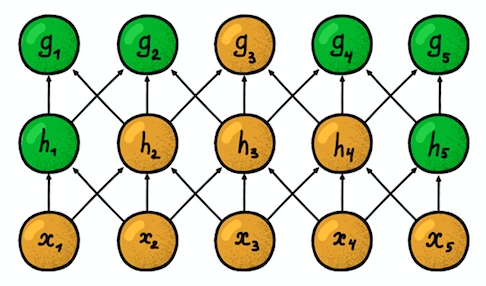
 مثال على شبكة عصبية أحادية البعد. (يسار) اتصال الخلايا العصبية في شبكة كثيفة نموذجية ، (يمين) توصيف الاتصال المحلي المتأصل في الطبقة التلافيفية. الصور المأخوذة من I. Goodfellow وآخرين بواسطة Deep Learningحجم المنطقة التي يتصل بها العصبون
مثال على شبكة عصبية أحادية البعد. (يسار) اتصال الخلايا العصبية في شبكة كثيفة نموذجية ، (يمين) توصيف الاتصال المحلي المتأصل في الطبقة التلافيفية. الصور المأخوذة من I. Goodfellow وآخرين بواسطة Deep Learningحجم المنطقة التي يتصل بها العصبون يسمى حجم المرشح (طول المرشح في حالة البيانات أحادية البعد ، على سبيل المثال ، السلسلة الزمنية ، أو العرض / الارتفاع في حالة البيانات ثنائية الأبعاد ، على سبيل المثال ، الصور). في الشكل الموجود على اليمين ، حجم المرشح هو 3. تسمى
الأوزان التي يتم من خلالها الاتصال بالفلتر (ناقل في حالة البيانات أحادية البعد ومصفوفة للبيانات ثنائية الأبعاد).
الخطوة هي المسافة التي يتحرك فيها المرشح فوق البيانات (في الشكل على اليمين ، الخطوة هي 1). إن فكرة الاتصال المحلي ليست أكثر من نواة تتحرك خطوة. يمثل كل خلية عصبية تلافيفية موضعًا محددًا للنواة ينزلق على طول الصورة الأصلية وينفذها.
 طبقتان تلافيفيتان متجاورتان أحاديتان الأبعاد
طبقتان تلافيفيتان متجاورتان أحاديتان الأبعادخاصية مهمة أخرى هي ما يسمى
بمنطقة الحساسية . إنه يعكس عدد مواضع الإشارة الأصلية التي يمكن للخلايا العصبية الحالية "رؤيتها". على سبيل المثال ، منطقة الحساسية لطبقة الشبكة الأولى ، الموضحة في الشكل ، تساوي حجم المرشح 3 ، حيث أن كل عصبون متصل بثلاثة خلايا عصبية فقط من الإشارة الأصلية. ومع ذلك ، في الطبقة الثانية ، تكون منطقة الحساسية بالفعل 5 ، لأن الخلايا العصبية للطبقة الثانية تجمع ثلاثة عصبونات من الطبقة الأولى ، لكل منها منطقة حساسية 3. مع زيادة العمق ، تنمو منطقة الحساسية بشكل خطي.
المعلمات المشتركة . تذكر أنه في معالجة الصور الكلاسيكية ، انزلق نفس النواة عبر الصورة بأكملها. نفس الفكرة تنطبق هنا. نقوم فقط بإصلاح حجم مرشح الأوزان لطبقة واحدة وسنطبق هذه الأوزان على جميع الخلايا العصبية في الطبقة. هذا يعادل انزلاق النواة نفسها في جميع أنحاء الصورة. ولكن قد يطرح السؤال: كيف يمكننا تعلم شيء ما مع هذا العدد الصغير من المعلمات؟
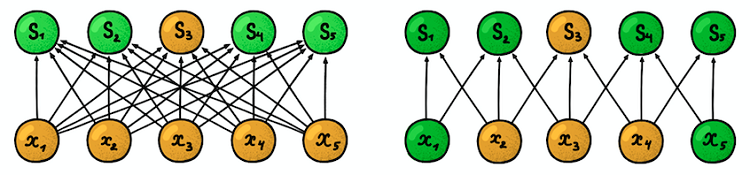
 تمثل الأسهم المظلمة نفس الأوزان. (يسار) MLP العادي ، حيث يكون كل عامل ترجيح معلمة منفصلة ، (يمين) مثال لفصل المعلمة ، حيث تشير العديد من عوامل الترجيح إلى نفس معلمة التدريبالتركيب المكاني
تمثل الأسهم المظلمة نفس الأوزان. (يسار) MLP العادي ، حيث يكون كل عامل ترجيح معلمة منفصلة ، (يمين) مثال لفصل المعلمة ، حيث تشير العديد من عوامل الترجيح إلى نفس معلمة التدريبالتركيب المكاني . الجواب على هذا السؤال بسيط: سنقوم بتدريب عدة مرشحات في طبقة واحدة! يتم وضعها بالتوازي مع بعضها البعض ، وبالتالي تشكل بعدًا جديدًا.
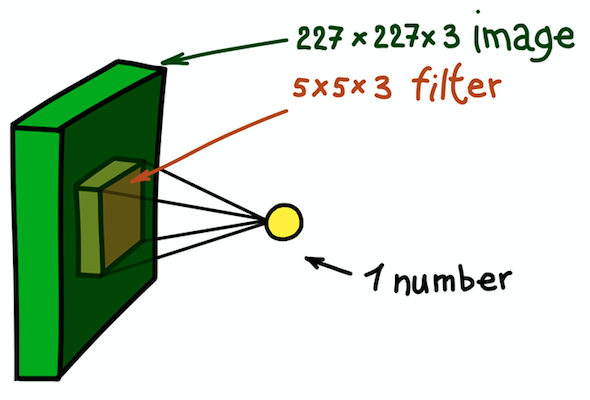
نتوقف لفترة قصيرة ونشرح الفكرة التي يقدمها مثال صورة RGB ثنائية الأبعاد بحجم 227 × 227. لاحظ أننا هنا نتعامل مع صورة إدخال ثلاثية القنوات ، مما يعني ، في جوهره ، أن لدينا ثلاث صور إدخال أو بيانات إدخال ثلاثية الأبعاد.
 البنية المكانية للصورة المدخلة
البنية المكانية للصورة المدخلةسننظر في أبعاد القنوات على أنها عمق الصورة (لاحظ أن هذا ليس هو نفسه عمق الشبكات العصبية ، وهو ما يساوي عدد طبقات الشبكة). السؤال هو كيفية تحديد النواة لهذه الحالة.
 مثال على قلب ثنائي الأبعاد ، وهو في الأساس مصفوفة ثلاثية الأبعاد مع قياس عمق إضافي. يعطي هذا المرشح الالتفاف مع الصورة ؛ أي ، ينزلق فوق الصورة في الفضاء ، ويحسب المنتجات العددية
مثال على قلب ثنائي الأبعاد ، وهو في الأساس مصفوفة ثلاثية الأبعاد مع قياس عمق إضافي. يعطي هذا المرشح الالتفاف مع الصورة ؛ أي ، ينزلق فوق الصورة في الفضاء ، ويحسب المنتجات العدديةالجواب بسيط ، على الرغم من أنه لا يزال غير واضح: سنجعل النواة ثلاثية الأبعاد أيضًا. سيظل البُعدان الأولان كما هما (العرض والارتفاع الأساسيان) ، والبعد الثالث دائمًا ما يساوي عمق بيانات الإدخال.
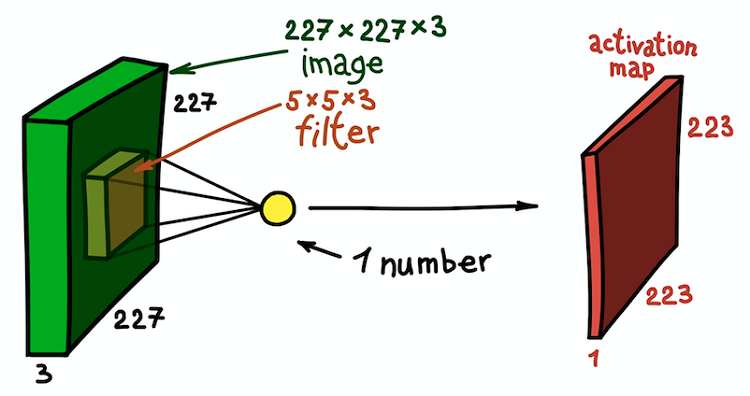
 مثال على خطوة الالتواء المكاني. نتيجة المنتج العددي للمرشح وجزء صغير من الصورة 5 × 5 × 3 (أي 5 × 5 × 5 + 1 = 76 ، أبعاد المنتج القياسي + التحول) هي رقم واحد
مثال على خطوة الالتواء المكاني. نتيجة المنتج العددي للمرشح وجزء صغير من الصورة 5 × 5 × 3 (أي 5 × 5 × 5 + 1 = 76 ، أبعاد المنتج القياسي + التحول) هي رقم واحدفي هذه الحالة ، يتم تحويل قسم 5 × 5 × 3 بالكامل من الصورة الأصلية إلى رقم واحد ، وسيتم تحويل الصورة ثلاثية الأبعاد نفسها إلى
خريطة معالم (
خريطة التنشيط ). خريطة المعالم هي مجموعة من الخلايا العصبية ، يحسب كل منها وظيفته الخاصة ، مع مراعاة مبدأين أساسيين نوقش أعلاه:
الاتصال المحلي (يرتبط كل خلية عصبية بجزء صغير فقط من بيانات الإدخال)
وفصل المعلمات (تستخدم جميع الخلايا العصبية نفس المرشح). من الناحية المثالية ، ستكون خريطة المعالم هذه هي نفسها التي تمت مواجهتها بالفعل في مثال الشبكة المقبولة بشكل عام - فهي تخزن نتائج الالتفاف لصورة الإدخال والفلتر.
 خريطة مميزة نتيجة الالتواء في القلب مع جميع المواقع المكانية
خريطة مميزة نتيجة الالتواء في القلب مع جميع المواقع المكانيةلاحظ أن عمق خريطة المعالم هو 1 ، حيث استخدمنا مرشحًا واحدًا فقط. لكن لا شيء يمنعنا من استخدام المزيد من المرشحات ؛ على سبيل المثال ، 6. سيتفاعل كل منهم مع نفس بيانات الإدخال وسيعملون بشكل مستقل عن بعضهم البعض. دعنا نذهب خطوة أخرى إلى الأمام ودمج هذه البطاقات المميزة. أبعادها المكانية هي نفسها لأن أبعاد المرشحات هي نفسها. وبالتالي ، يمكن اعتبار خرائط المعالم التي تم جمعها معًا كمصفوفة ثلاثية الأبعاد جديدة ، يتم تمثيل بُعد عمقها بخرائط المعالم من نوى مختلفة. وبهذا المعنى ، فإن قنوات RGB لصورة الإدخال ليست سوى خرائط المعالم الأصلية الثلاث.
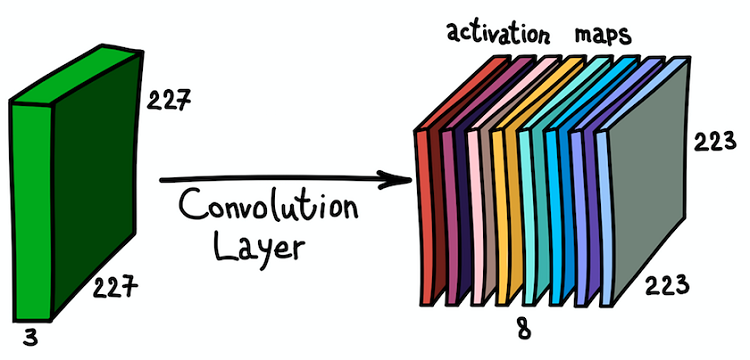 التطبيق المتوازي للعديد من المرشحات لصورة الإدخال والمجموعة الناتجة من بطاقات التنشيط
التطبيق المتوازي للعديد من المرشحات لصورة الإدخال والمجموعة الناتجة من بطاقات التنشيطهذا الفهم لخرائط المعالم ومزيجها مهم جدًا ، نظرًا لأننا أدركنا ذلك ، يمكننا توسيع بنية الشبكة وتثبيت طبقات تلافيفية واحدة فوق الأخرى ، وبالتالي زيادة منطقة الحساسية وإثراء المصنف.
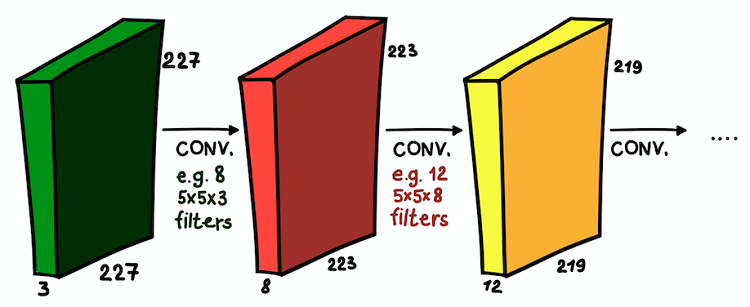 طبقات تلافيفية مثبتة فوق بعضها البعض. في كل طبقة ، قد يختلف حجم المرشحات وعددها
طبقات تلافيفية مثبتة فوق بعضها البعض. في كل طبقة ، قد يختلف حجم المرشحات وعددهاالآن نحن نفهم ما هي الشبكة التلافيفية. الهدف الرئيسي لهذه الطبقات هو نفسه كما هو الحال مع النهج المقبول بشكل عام - لاكتشاف العلامات المهمة للصورة. وإذا كانت هذه العلامات في الطبقة الأولى يمكن أن تكون بسيطة للغاية (وجود خطوط رأسية / أفقية) ، فإن عمق الشبكة يزيد من درجة تجريدها (وجود كلب / قطة / شخص).
طبقات فرعية
الطبقات التلافيفية هي اللبنة الأساسية لشبكة CNN. ولكن هناك جزءًا مهمًا آخر وغالبًا ما يستخدم - هذه طبقات عينة فرعية. في معالجة الصور التقليدية ، لا يوجد تناظري مباشر ، ولكن يمكن اعتبار العينة الفرعية كنوع آخر من النواة. ما هذا؟
 أمثلة على العينات الفرعية. (يسار) كيف تغير العينة الفرعية الأحجام المكانية (وليس القناة!) لمصفوفات البيانات ، (يمين) مخطط أساسي لكيفية عمل العينة الفرعية
أمثلة على العينات الفرعية. (يسار) كيف تغير العينة الفرعية الأحجام المكانية (وليس القناة!) لمصفوفات البيانات ، (يمين) مخطط أساسي لكيفية عمل العينة الفرعيةترشح العينة الفرعية جزءًا من جوار كل بكسل من بيانات الإدخال باستخدام وظيفة تجميع محددة ، على سبيل المثال ، الحد الأقصى ، المتوسط ، إلخ. العينة الفرعية هي في الأساس نفس الالتفاف ، ولكن وظيفة دمج البكسل لا تقتصر على المنتج القياسي. فرق مهم آخر هو أن الاختزال الفرعي يعمل فقط في البعد المكاني. السمة المميزة لطبقة العينة الجزئية هي أن
الملعب عادة ما يكون مساوياً لحجم المرشح (القيمة النموذجية هي 2).
للعينة الفرعية ثلاثة أهداف رئيسية:
- انخفاض البعد المكاني ، أو أخذ العينات الفرعية. يتم ذلك لتقليل عدد المعلمات.
- نمو منطقة الحساسية. بسبب الخلايا العصبية الفرعية في الطبقات اللاحقة ، يتم تجميع المزيد من خطوات إشارة الإدخال
- الثبات الانتقالي إلى عدم التجانس الصغير في موضع الأنماط في إشارة الإدخال. من خلال حساب إحصائيات التجميع للأحياء الصغيرة لإشارة الإدخال ، يمكن أن تتجاهل العينة الفرعية الإزاحة المكانية الصغيرة فيها.
طبقات سميكة
تخدم الطبقات التلافيفية وطبقات العينات الفرعية نفس الغرض - توليد سمات الصورة. الخطوة الأخيرة هي تصنيف صورة الإدخال بناءً على الميزات المكتشفة. في CNN ، تقوم الطبقات الكثيفة أعلى الشبكة بذلك. هذا الجزء من الشبكة يسمى
التصنيف . يمكن أن يحتوي على عدة طبقات فوق بعضها البعض مع اتصال كامل ، ولكن عادة ما ينتهي
بطبقة من فئة
softmax يتم تنشيطها بواسطة وظيفة تنشيط لوجستي متعددة المتغيرات ، حيث يساوي عدد الكتل عدد الفئات. عند إخراج هذه الطبقة هو التوزيع الاحتمالي حسب الفئة لكائن الإدخال. الآن يمكن تصنيف الصورة باختيار الفئة الأكثر ترجيحًا.