 مرحبًا اسمي ماركو ، أعمل لدى Badoo في قسم المنصة. لدينا الكثير من الأشياء المكتوبة في Go ، وغالبًا ما تكون هذه ضرورية لأداء النظام. لهذا السبب أقدم لكم اليوم ترجمة لمقال أعجبني حقًا ، وأنا متأكد من أنه سيكون مفيدًا جدًا لك. يوضح المؤلف خطوة بخطوة كيف تعامل مع مشاكل الأداء وكيف تم حلها. بما في ذلك سوف تتعرف على الأدوات الغنية المتاحة في Go لمثل هذا العمل. هل لديك قراءة لطيفة!
مرحبًا اسمي ماركو ، أعمل لدى Badoo في قسم المنصة. لدينا الكثير من الأشياء المكتوبة في Go ، وغالبًا ما تكون هذه ضرورية لأداء النظام. لهذا السبب أقدم لكم اليوم ترجمة لمقال أعجبني حقًا ، وأنا متأكد من أنه سيكون مفيدًا جدًا لك. يوضح المؤلف خطوة بخطوة كيف تعامل مع مشاكل الأداء وكيف تم حلها. بما في ذلك سوف تتعرف على الأدوات الغنية المتاحة في Go لمثل هذا العمل. هل لديك قراءة لطيفة!قبل بضعة أسابيع ، قرأت مقال "
Good Code Against Bad Code in Go "
، حيث يوضح المؤلف خطوة بخطوة إعادة هيكلة تطبيق حقيقي يحل مشاكل العمل الحقيقية. وهي تركز على تحويل "الشفرة السيئة" إلى "كود جيد": أكثر اصطلاحيًا ، وأكثر قابلية للفهم ، والاستفادة الكاملة من تفاصيل Go. لكن المؤلف ذكر أيضًا أهمية أداء التطبيق المعني. وقف الفضول في داخلي: دعنا نحاول تسريعه!
يقرأ البرنامج ، بشكل تقريبي ، ملف الإدخال ، ويوزعه سطراً بسطر ويملأ الأشياء في الذاكرة.
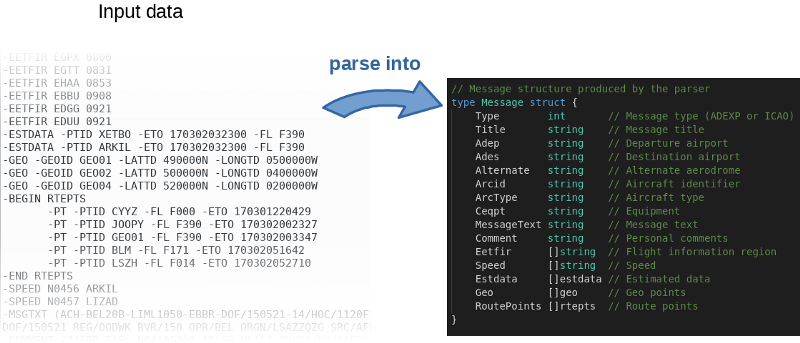
لم ينشر المؤلف
شفرة المصدر على GitHub فحسب ، بل كتب أيضًا معيارًا. هذه فكرة عظيمة في الواقع ، دعا المؤلف الجميع للتلاعب بالشفرة ومحاولة تسريعها. لإعادة إنتاج نتائج المؤلف ، استخدم الأمر التالي:
$ go test -bench=.
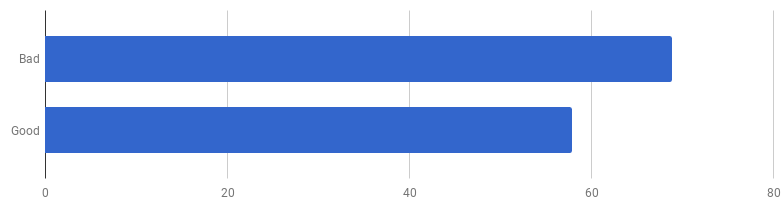 pers لكل مكالمة (أقل - أفضل)
pers لكل مكالمة (أقل - أفضل)اتضح أن "الرمز الجيد" على جهاز الكمبيوتر الخاص بي أسرع بنسبة 16٪. هل يمكننا تسريعها؟
في تجربتي ، هناك ارتباط بين جودة الكود والأداء. إذا نجحت في إعادة هيكلة الشفرة ، وجعلتها أكثر نظافة وأقل اتصالًا ، فمن المرجح أنك جعلتها أسرع لأنها أصبحت أقل تشوشًا (ولا توجد تعليمات أخرى غير ضرورية تم تنفيذها مسبقًا عبثًا). ربما لاحظت أثناء إعادة الهيكلة بعض فرص التحسين ، أو لديك الآن الفرصة فقط لتحقيقها. ولكن من ناحية أخرى ، إذا كنت ترغب في جعل الشفرة أكثر إنتاجية ، فربما يجب عليك الابتعاد عن البساطة وإضافة العديد من الاختراقات. أنت حقًا تحفظ ملي ثانية ، لكن جودة الشفرة ستعاني: سيصبح من الصعب قراءتها والتحدث عنها ، وستصبح أكثر هشاشة ومرونة.
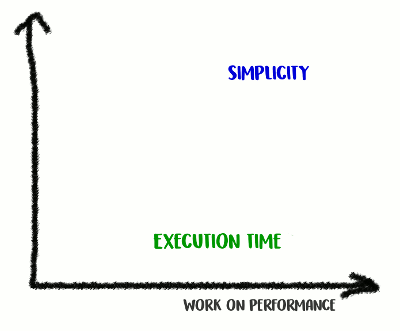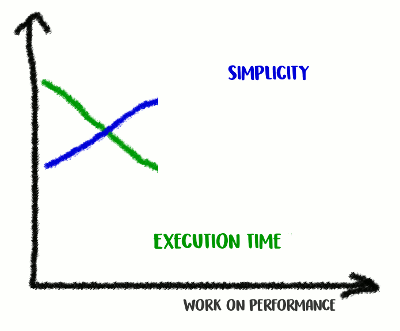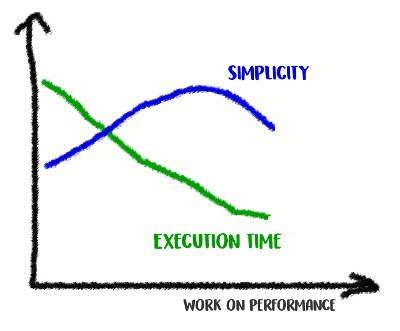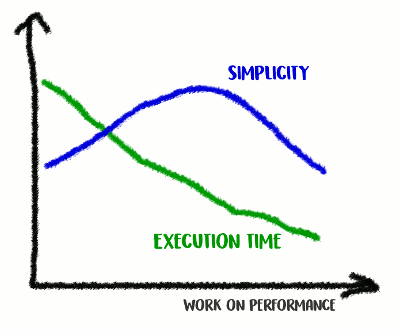 نتسلق جبل البساطة ، ثم ننزل منه
نتسلق جبل البساطة ، ثم ننزل منههذه مقايضة: إلى أي مدى أنت على استعداد للذهاب؟
لإعطاء الأولوية بشكل صحيح للعمل على التسارع ، فإن الإستراتيجية المثلى هي العثور على الاختناقات والتركيز عليها. للقيام بذلك ، استخدم أدوات التنميط.
pprof وتتبع هم أصدقائك:
$ go test -bench=. -cpuprofile cpu.prof $ go tool pprof -svg cpu.prof > cpu.svg
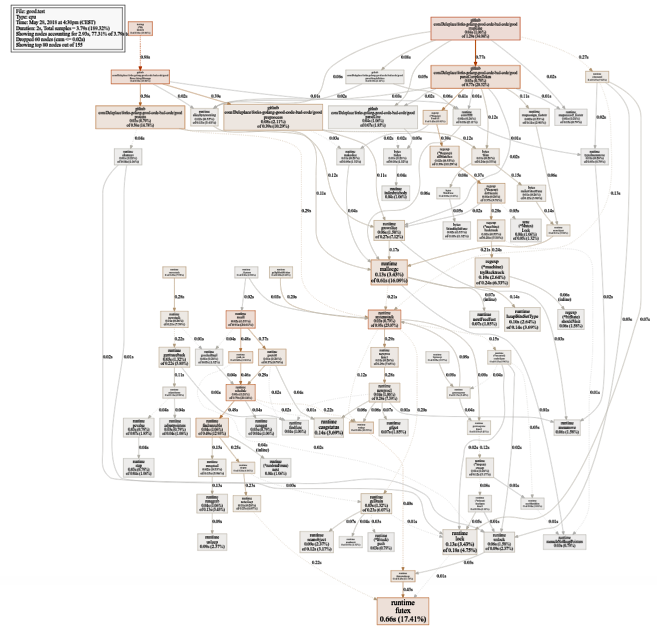 رسم بياني كبير إلى حد ما لاستخدام وحدة المعالجة المركزية (انقر لـ SVG)
رسم بياني كبير إلى حد ما لاستخدام وحدة المعالجة المركزية (انقر لـ SVG) $ go test -bench=. -trace trace.out $ go tool trace trace.out
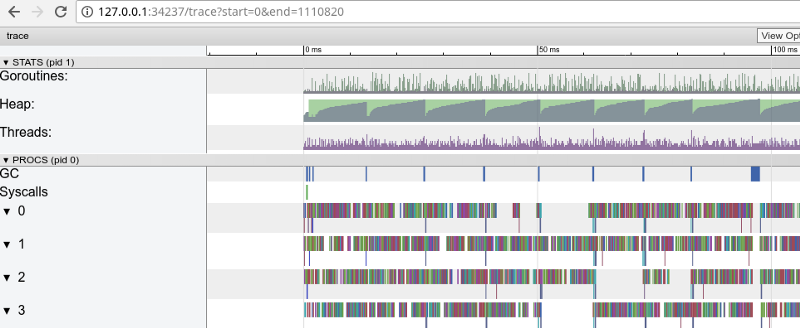 تتبع Rainbow: الكثير من المهام الصغيرة (انقر لفتح ، يعمل فقط في Google Chrome)
تتبع Rainbow: الكثير من المهام الصغيرة (انقر لفتح ، يعمل فقط في Google Chrome)يؤكد التتبع أن جميع نوى المعالج مشغولة (الخطوط أقل من 0 ، 1 ، وما إلى ذلك) ، وللوهلة الأولى ، هذا أمر جيد. لكنها تظهر أيضًا آلاف "الحسابات" الصغيرة اللون والعديد من المناطق الفارغة حيث كانت النوى خاملة. دعونا تكبير:
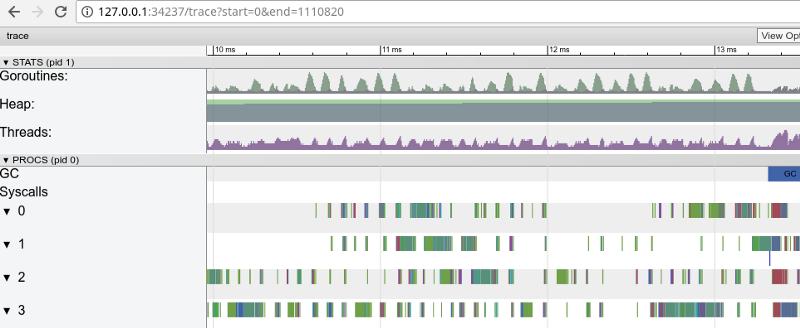 "نافذة" في 3 مللي ثانية (انقر للفتح ، تعمل فقط في Google Chrome)
"نافذة" في 3 مللي ثانية (انقر للفتح ، تعمل فقط في Google Chrome)كل نواة خاملة لبعض الوقت ، كما أنها "تقفز" بين المهام الصغيرة طوال الوقت. يبدو أن دقة هذه المهام ليست مثالية للغاية ، مما يؤدي إلى عدد كبير من
مفاتيح تبديل السياق والمنافسة بسبب المزامنة.
دعونا نرى ما يقوله لنا
كاشف الطيران . هل هناك أي مشاكل في الوصول المتزامن إلى البيانات (إذا كان هناك أي مشاكل ، فإننا نواجه مشكلات أكبر بكثير من الأداء)؟
$ go test -race PASS
عظيم! كل شيء صحيح. لم يتم العثور على رحلات طيران. وظائف الاختبار ووظائف المعيار هي وظائف مختلفة (
انظر الوثائق ) ، ولكن هنا يسمونها نفس وظيفة
ParseAdexpMessage ، لذا فإن ما قمنا بفحصه لرحلات البيانات عن طريق الاختبارات لا بأس به.
يتكون النموذج التنافسي في النسخة "الجيدة" من معالجة كل سطر من ملف الإدخال في غوروتين منفصل (لاستخدام جميع النوى). عملت حدس المؤلف هنا بشكل جيد ، لأن الغوروتين له سمعة لميزات سهلة ورخيصة. ولكن كم نربح من خلال التنفيذ المتوازي؟ لنقارن بالرمز نفسه ولكن لا نستخدم goroutines (ما عليك سوى إزالة الكلمة go التي تأتي قبل استدعاء الوظيفة):

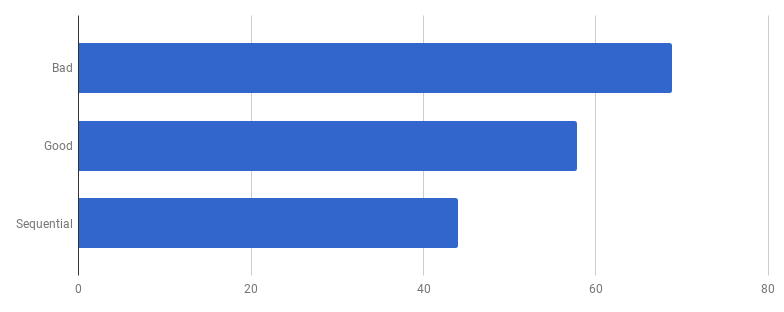
عفوًا ، يبدو أن الرمز أصبح أسرع بدون استخدام التزامن. هذا يعني أن النفقات العامة (غير الصفرية) لإطلاق الغوروتينات تتجاوز الوقت الذي فزنا به باستخدام عدة نوى في نفس الوقت. يجب أن تكون الخطوة التالية الطبيعية هي إزالة النفقات العامة (غير الصفرية) لاستخدام القنوات لإرسال النتائج. دعنا نستبدلها بشريحة عادية:
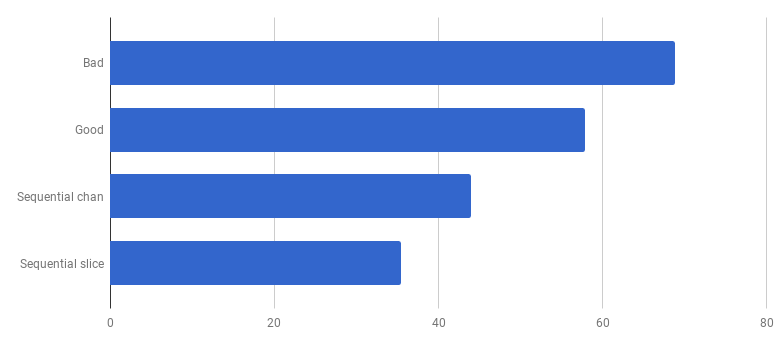 pers لكل مكالمة (الأقل هو الأفضل)
pers لكل مكالمة (الأقل هو الأفضل)حصلنا على تسارع بنسبة 40٪ تقريبًا مقارنة بالإصدار "الجيد" ، مما أدى إلى تبسيط الرمز وإزالة المنافسة (
فرق ).
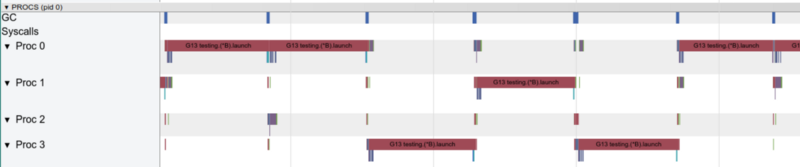 مع غوروتين واحد ، يعمل نواة واحدة فقط في كل مرة
مع غوروتين واحد ، يعمل نواة واحدة فقط في كل مرةدعنا الآن نلقي نظرة على الوظائف الساخنة في الرسم البياني pprof:
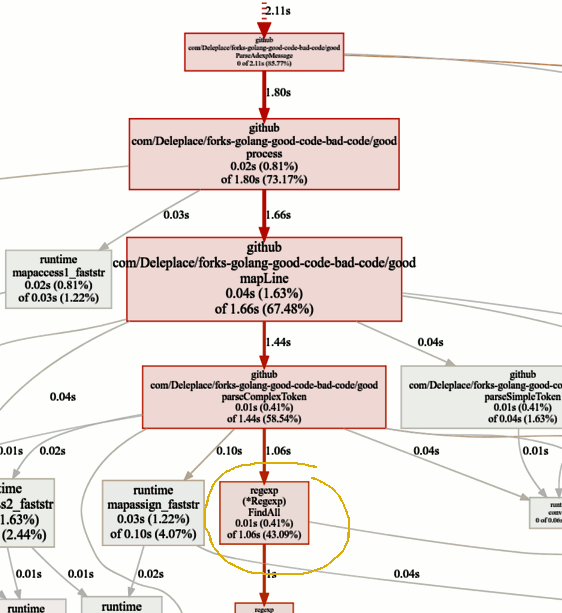 تبحث عن الاختناقات
تبحث عن الاختناقاتينفق معيار الإصدار الحالي (التشغيل المتسلسل ، الشرائح) 86٪ من وقت تحليل الرسائل ، وهذا أمر طبيعي. لكننا سنلاحظ بسرعة أن 43٪ من الوقت يتم إنفاقه على استخدام التعبيرات العادية والوظيفة
(* Regexp) .FindAll .
على الرغم من حقيقة أن التعبيرات العادية هي طريقة مريحة ومرنة للحصول على البيانات من نص عادي ، إلا أن لها عيوبًا ، بما في ذلك استخدام عدد كبير من الموارد والمعالج والذاكرة. إنها أداة قوية ، ولكن غالبًا ما يكون استخدامها غير ضروري.
في برنامجنا ، قالب
patternSubfield = "-.[^-]*"
الغرض الأساسي منه هو إبراز الأوامر التي تبدأ بشرطة (-) ، ويمكن أن يكون هناك عدة أوامر في السطر. هذا ، بعد سحب القليل من الرمز ، يمكن القيام به باستخدام
وحدات البايت . دعنا نعدل الشفرة (
الالتزام ،
الالتزام ) لتغيير التعبيرات العادية إلى تقسيم:
 pers لكل مكالمة (الأقل
pers لكل مكالمة (الأقل هو
الأفضل)واو! كود أكثر إنتاجية بنسبة 40٪! يبدو الرسم البياني لاستهلاك وحدة المعالجة المركزية الآن كما يلي:
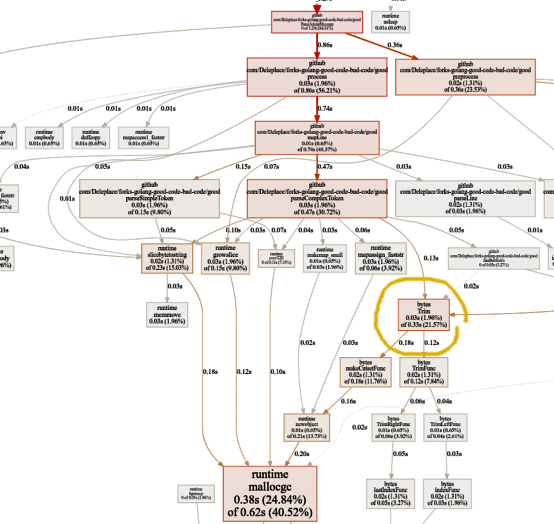
لا مزيد من الوقت الضائع على التعبيرات العادية. يذهب جزء كبير منه (40٪) إلى تخصيص الذاكرة لخمس وظائف مختلفة. من المثير للاهتمام ، يتم الآن قضاء 21 ٪ من الوقت على وظيفة
البايت.تريم :
 هذه الميزة تثير اهتمامي. ماذا يمكننا ان نفعل هنا؟
هذه الميزة تثير اهتمامي. ماذا يمكننا ان نفعل هنا؟
bytes.Trim يتوقع سلسلة مع أحرف "قطع" كوسيطة ، ولكن هذه السلسلة نمر سلسلة مع حرف واحد فقط - مسافة. هذا مجرد مثال لكيفية الحصول على التسارع بسبب التعقيد: دعنا ننشئ وظيفة القطع بدلاً من الوظيفة القياسية. ستعمل وظيفة
القطع المخصصة لدينا مع بايت واحد بدلاً من سطر كامل:

 pers لكل مكالمة (الأقل هو الأفضل)
pers لكل مكالمة (الأقل هو الأفضل)مرحى ، خصم 20٪ آخر! الإصدار الحالي أسرع أربع مرات من النسخة الأصلية "السيئة" وفي نفس الوقت يستخدم نواة واحدة فقط. ليس سيئا!
في وقت سابق ، تخلينا عن القدرة التنافسية على مستوى معالجة الخط ، لكني أجادل بأن التسارع يمكن تحقيقه باستخدام القدرة التنافسية على مستوى أعلى. على سبيل المثال ، معالجة 6000 ملف (6000 رسالة) تكون أسرع على جهاز الكمبيوتر الخاص بي إذا تمت معالجة كل ملف في مجموعته:
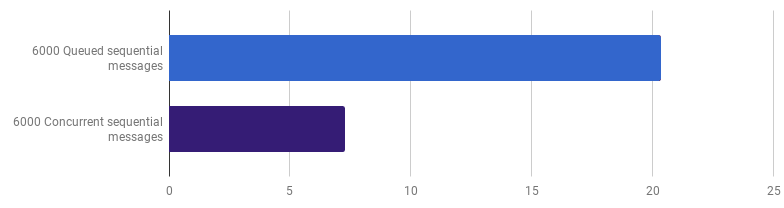 pers لكل مكالمة (الأقل هو الأفضل ؛ الأرجواني هو حل تنافسي)
pers لكل مكالمة (الأقل هو الأفضل ؛ الأرجواني هو حل تنافسي)الربح 66٪ (أي التسارع ثلاث مرات). هذا أمر جيد ، ولكن ليس للغاية ، مع الأخذ في الاعتبار أن جميع النوى 12 التي استخدمتها. قد يعني هذا أن الشفرة المُحسَّنة الجديدة التي تعالج الملف بأكمله لا تزال "مهمة صغيرة" ، حيث لا تعتبر التكاليف الإضافية لإنشاء goroutines وتكلفة المزامنة غير ذات أهمية. ومن المثير للاهتمام أن زيادة عدد الرسائل من 6000 إلى 120.000 ليس له أي تأثير على النسخة ذات الترابط الفردي ويقلل الأداء على إصدار "goroutine لكل رسالة". هذا لأنه ، على الرغم من حقيقة أن إنشاء مثل هذه الكمية الكبيرة من الغوروتينات أمر ممكن ومفيد في بعض الأحيان ، فإنه يجلب حملته الخاصة في
منطقة وقت التشغيل .
يمكننا أيضًا تقليل وقت التنفيذ (ليس 12 مرة ، ولكن لا يزال) من خلال إنشاء عدد قليل من العمال. على سبيل المثال ، 12 جوروتينًا طويل الأمد ، كل منها سيعالج جزءًا من الرسائل:
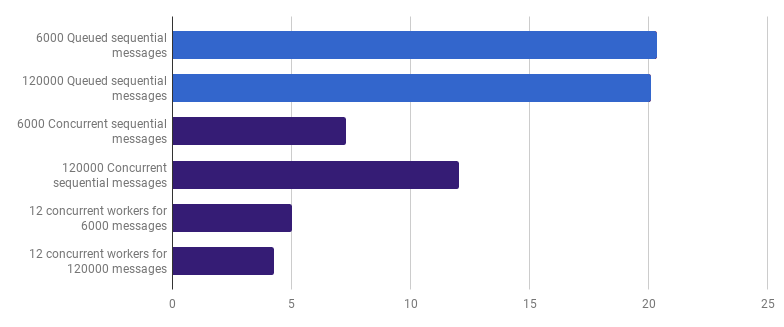 pers لكل مكالمة (الأقل هو الأفضل ؛ الأرجواني هو حل تنافسي)
pers لكل مكالمة (الأقل هو الأفضل ؛ الأرجواني هو حل تنافسي)يقلل هذا الخيار من وقت التنفيذ بنسبة 79٪ مقارنة بالإصدار المفرد. لاحظ أن هذه الإستراتيجية تكون منطقية فقط إذا كان لديك العديد من الملفات لمعالجتها.
الاستخدام الأمثل لجميع نوى المعالج هو استخدام العديد من goroutines ، كل منها يعالج كمية كبيرة من البيانات دون أي تفاعل أو تزامن قبل اكتمال العمل.
عادة ما يأخذون العديد من العمليات (goroutine) مثل نوى المعالج ، ولكن هذا ليس دائمًا الخيار الأفضل: كل هذا يتوقف على المهمة المحددة. على سبيل المثال ، إذا كنت تقرأ شيئًا من نظام الملفات أو تجري الكثير من مكالمات الشبكة ، فلكي تحصل على المزيد من الأداء ، يجب عليك استخدام عدد أكبر من goroutines من النوى.
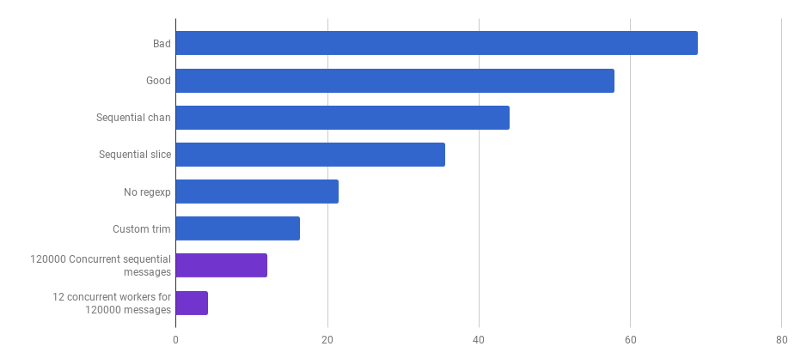 pers لكل مكالمة (الأقل هو الأفضل ؛ الأرجواني هو حل تنافسي)
pers لكل مكالمة (الأقل هو الأفضل ؛ الأرجواني هو حل تنافسي)لقد وصلنا إلى النقطة التي يصعب فيها زيادة أداء التحليل مع بعض التغييرات المحلية. يسيطر الوقت على وقت التشغيل لتخصيص الذاكرة وجمع القمامة. يبدو هذا منطقيًا نظرًا لأن وظائف إدارة الذاكرة بطيئة إلى حد ما. مزيد من التحسين للعمليات المرتبطة بالمخصصات لا يزال بمثابة واجب منزلي للقراء.
يمكن أن يؤدي استخدام خوارزميات أخرى أيضًا إلى تحقيق مكاسب كبيرة في الأداء.
هنا استلهمت من محاضرة بواسطة Lexical Scanning in Go من Rob Pike ،
لإنشاء lexer مخصص (
مصدر ) ومحلل مخصص (
مصدر ). هذا الرمز غير جاهز بعد (لا أقوم بمعالجة مجموعة من حالات الزاوية) ، وهو أقل وضوحًا من الخوارزمية الأصلية ، وأحيانًا يكون من الصعب كتابة معالجة الخطأ الصحيحة. ولكنها صغيرة وأسرع بنسبة 30 ٪ من النسخة الأكثر تحسينًا.
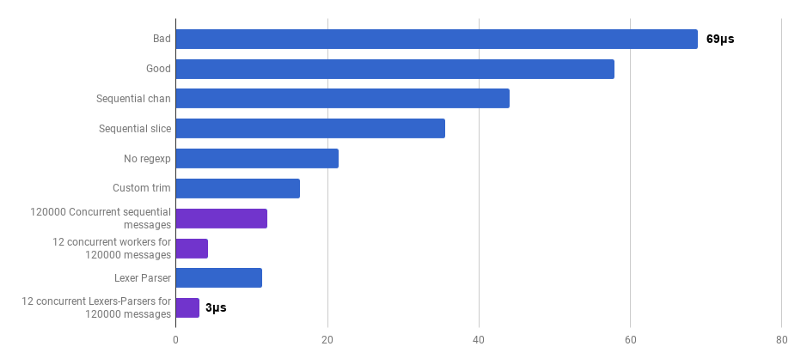 pers لكل مكالمة (الأقل هو الأفضل ؛ الأرجواني هو حل تنافسي)
pers لكل مكالمة (الأقل هو الأفضل ؛ الأرجواني هو حل تنافسي)نعم ونتيجة لذلك ، حصلنا على تسارع 23 مرة مقارنةً بكود المصدر.
هذا كل شيء لهذا اليوم. آمل أن تكون قد استمتعت بهذه المغامرة. فيما يلي بعض الملاحظات والاستنتاجات:
- يمكن تحسين الإنتاجية على مستويات مختلفة من التجريد ، باستخدام تقنيات مختلفة ، وغالبًا ما يتم زيادة المكاسب.
- يجب أن يبدأ الضبط مع تجريدات عالية المستوى: هياكل البيانات والخوارزميات وفصل الوحدات الصحيح. تناول الملخصات ذات المستوى المنخفض لاحقًا: I / O ، التجميع ، القدرة التنافسية ، استخدام المكتبة القياسية ، العمل مع الذاكرة ، تخصيص الذاكرة.
- يعد تحليل Big O مهمًا جدًا ، ولكنه ليس الأداة الأكثر ملاءمة لتسريع البرنامج.
- إن كتابة المعايير عمل شاق. استخدم التنميط والمعايير للعثور على الاختناقات واكتساب فهم أوسع لما يحدث في البرنامج. ضع في اعتبارك أن النتائج المعيارية ليست هي نفسها التي سيواجهها المستخدمون في العمل الواقعي.
- لحسن الحظ ، فإن مجموعة من الأدوات ( Bench ، pprof ، trace ، Race Detector ، Cover ) تجعل البحث عن أداء الكود ميسورًا ومثيرًا للاهتمام.
- كتابة اختبارات جيدة وذات صلة ليست مهمة تافهة. لكنهم مهمين جدًا ألا يذهبوا إلى البراري. يمكنك إعادة البناء ، مع التأكد من أن الرمز لا يزال صحيحًا.
- توقف واسأل نفسك عن مدى سرعة "السرعة الكافية". لا تضيع وقتك في تحسين بعض النصوص البرمجية لمرة واحدة. لا تنس أن التحسين ليس مجانيًا: وقت المهندس وتعقيده وأخطاءه ودينه الفني.
- فكر مرتين قبل تعقيد الكود.
- عادة ما تكون الخوارزميات ذات التعقيد Ω (n²) وما فوقها باهظة الثمن.
- عادة ما تكون الخوارزميات ذات التعقيد O (n) أو O (n log n) وأدناه جيدة.
- لا يمكن تجاهل العوامل المخفية المختلفة. على سبيل المثال ، تم إجراء جميع التحسينات في المقالة عن طريق تقليل هذه العوامل ، وليس عن طريق تغيير فئة التعقيد للخوارزمية.
- غالبًا ما يكون الإدخال / الإخراج اختناقًا: استعلامات الشبكة ، استعلامات قاعدة البيانات ، نظام الملفات.
- غالبًا ما تكون التعبيرات العادية باهظة الثمن وغير ضرورية.
- تخصيصات الذاكرة أكثر تكلفة من العمليات الحسابية.
- كائن مخصص على المكدس أرخص من كائن مخصص في كومة الذاكرة المؤقتة.
- الشرائح مفيدة كبديل لتحركات الذاكرة باهظة الثمن.
- تعتبر السلاسل فعالة عندما تكون للقراءة فقط (بما في ذلك التكرار). في جميع الحالات الأخرى ، [] البايت أكثر فعالية.
- من المهم جدًا أن تكون البيانات التي تقوم بمعالجتها قريبة (ذاكرة التخزين المؤقت للمعالج).
- القدرة التنافسية والتوازي مفيدة للغاية ، ولكن من الصعب إعدادها.
- عندما تحفر عميقًا ومنخفضًا ، تذكر "الأرضية الزجاجية" التي لا تريد اقتحامها. إذا كانت يديك تتلهف لمحاولة تعليمات المجمّع ، تعليمات SIMD ، فقد تحتاج إلى استخدام Go فقط للنماذج الأولية ، ثم التبديل إلى لغة ذات مستوى أقل للحصول على تحكم كامل في الأجهزة وكل نانو ثانية!