مرحبًا في هذه المقالة سأتحدث عن المصنف بايزي كأحد الخيارات لتصفية رسائل البريد الإلكتروني العشوائية. دعنا نذهب من خلال النظرية ، ثم نصلحها من خلال الممارسة ، وفي النهاية سأقدم رسمًا بيانيًا للرمز بلغتي المحبوبة R. سأحاول أن أشرح بأكبر قدر ممكن من التعبيرات والصيغ. دعنا نبدأ!

لا توجد صيغ في أي مكان ، حسناً ، نظرية مختصرة
ينتمي المصنف البايزي إلى فئة التعلم الآلي. خلاصة القول هي: النظام الذي يواجه مهمة تحديد ما إذا كان الحرف التالي هو البريد العشوائي تم تدريبه مسبقًا من قبل عدد معين من الحروف التي تعرف بالضبط أين "البريد العشوائي" وأين "ليس البريد العشوائي". لقد أصبح من الواضح بالفعل أن هذا هو التدريس مع المعلم ، حيث نلعب دور المعلم. يقدم المصنف البايزي وثيقة (في حالتنا ، رسالة) في شكل مجموعة من الكلمات التي يفترض أنها لا تعتمد على بعضها البعض (وهذه السذاجة تليه من هنا).
من الضروري حساب الدرجة لكل صف (بريد عشوائي / غير مرغوب فيه) واختيار الدرجة القصوى. للقيام بذلك ، استخدم الصيغة التالية:
- حدوث كلمة
في وثيقة الصف
(بالتنعيم) *
- عدد الكلمات المدرجة في وثيقة الفصل
م - عدد الكلمات من مجموعة التدريب
- عدد تكرارات الكلمة
في وثيقة الصف
- معلمة للتنعيم
عندما يكون حجم النص كبيرًا جدًا ، يجب عليك العمل مع أرقام صغيرة جدًا. لتجنب ذلك ، يمكنك تحويل الصيغة وفقًا لخاصية اللوغاريتم **:
استبدل واحصل على:
* خلال الحسابات ، قد تصادف كلمة لم تكن في مرحلة تدريب النظام. يمكن أن يؤدي هذا إلى أن يكون التقييم مساويًا للصفر ولا يمكن تعيين المستند لأي من الفئات (البريد العشوائي / غير المرغوب فيه). بغض النظر عن الطريقة التي تريدها ، فأنت لا تعلم نظامك جميع الكلمات الممكنة. للقيام بذلك ، من الضروري تطبيق التجانس ، أو بالأحرى إجراء تصحيحات صغيرة على جميع احتمالات إدخال الكلمات إلى المستند. تم تحديد المعلمة 0 <α≤1 (إذا كانت α = 1 ، فهذا هو تمهيد لابلاس)
** اللوغاريتم هو دالة متزايدة رتيبة. كما يتبين من الصيغة الأولى - نحن نبحث عن الحد الأقصى. سوف يصل لوغاريتم الدالة إلى الذروة عند نفس النقطة (الإحداثي) للدالة نفسها. هذا يبسط الحساب ، لأن القيمة العددية فقط تتغير.
من النظرية إلى الممارسة
دع نظامنا يتعلم من الحروف التالية ، والمعروفة مقدمًا حيث "البريد العشوائي" و "ليس البريد العشوائي" (عينة تدريبية):
البريد المزعج- “قسائم بسعر منخفض”
- "الترويج! اشترِ شوكولاتة واحصل على هاتف كهدية »
ليست رسائل غير مرغوب فيها:- "سيعقد الاجتماع غدا"
- "اشترِ كيلوغرامًا من التفاح وحانة شوكولاتة"
الواجب: حدد الفئة التي ينتمي إليها الحرف التالي:
- "يحتوي المتجر على جبل من التفاح. اشتر سبعة كيلوغرامات وحانة شوكولاتة "
الحل:نصنع طاولة. نزيل جميع "كلمات التوقف" ، نحسب الاحتمالات ، ونأخذ المعلمة للتنعيم كواحد.
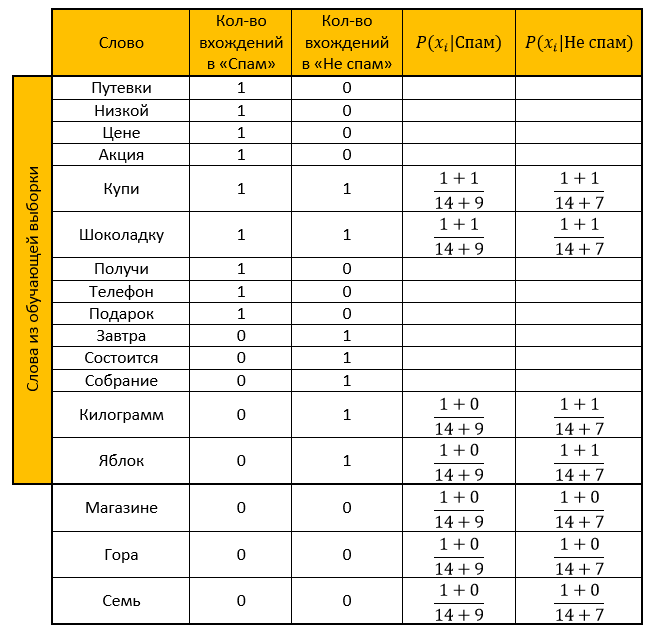
تصنيف الفئة بريد مزعج:
تصنيف لفئة "Non-spam":
الإجابة: تصنيف "ليست رسائل غير مرغوب فيها" أكثر من تصنيف "الرسائل غير المرغوب فيها". لذا فإن رسالة التحقق ليست رسالة غير مرغوب فيها!
نحسب الشيء نفسه بمساعدة دالة تم تحويلها بواسطة خاصية اللوغاريتم:
تصنيف الفئة بريد مزعج:
تصنيف لفئة "Non-spam":
الجواب: مماثل للإجابة السابقة. البريد الإلكتروني للتحقق - لا البريد المزعج!
تنفيذ لغة البرمجة R
لقد علق على كل إجراء تقريبًا ، لأنني أعرف عدد المرات التي لا أريد فيها فهم رمز شخص آخر ، لذا آمل ألا تتسبب قراءتي في أي صعوبات. (يا آمل)
وهنا ، في الواقع ، الرمز نفسهlibrary("tm") # stopwords library("stringr") # # : spam <- c( ' ', '! ' ) # : not_spam <- c( ' ', ' ' ) # test_letter <- " . " #---------------- -------------------- # spam <- str_replace_all(spam, "[[:punct:]]", "") # spam <- tolower(spam) # spam_words <- unlist(strsplit(spam, " ")) # , stopwords spam_words <- spam_words[! spam_words %in% stopwords("ru")] # unique_words <- table(spam_words) # data frame main_table <- data.frame(u_words=unique_words) # names(main_table) <- c("","") #--------------- ------------------ not_spam <- str_replace_all(not_spam, "[[:punct:]]", "") not_spam <- tolower(not_spam) not_spam_words <- unlist(strsplit(not_spam, " ")) not_spam_words <- not_spam_words[! not_spam_words %in% stopwords("ru")] #--------------- ------------------ test_letter <- str_replace_all(test_letter, "[[:punct:]]", "") test_letter <- tolower(test_letter) test_letter <- unlist(strsplit(test_letter, " ")) test_letter <- test_letter[! test_letter %in% stopwords("ru")] #--------------------------------------------- # main_table$_ <- 0 for(i in 1:length(not_spam_words)){ # need_word <- TRUE for(j in 1:(nrow(main_table))){ # " " , +1 if(not_spam_words[i]==main_table[j,1]) { main_table$_[j] <- main_table$_[j]+1 need_word <- FALSE } } # , data frame if(need_word==TRUE) { main_table <- rbind(main_table,data.frame(=not_spam_words[i],=0,_=1)) } } #------------- # , - main_table$_ <- NA # , - main_table$__ <- NA #------------- # Xi Qk formula_1 <- function(N_ik,M,N_k) { (1+N_ik)/(M+N_k) } #------------- # quantity <- nrow(main_table) for(i in 1:length(test_letter)) { # , need_word <- TRUE for(j in 1:nrow(main_table)) { # if(test_letter[i]==main_table$[j]) { main_table$_[j] <- formula_1(main_table$[j],quantity,sum(main_table$)) main_table$__[j] <- formula_1(main_table$_[j],quantity,sum(main_table$_)) need_word <- FALSE } } # , data frame, / if(need_word==TRUE) { main_table <- rbind(main_table,data.frame(=test_letter[i],=0,_=0,_=NA,__=NA)) main_table$_[nrow(main_table)] <- formula_1(main_table$[nrow(main_table)],quantity,sum(main_table$)) main_table$__[nrow(main_table)] <- formula_1(main_table$_[nrow(main_table)],quantity,sum(main_table$_)) } } # "" probability_spam <- 1 # " " probability_not_spam <- 1 for(i in 1:nrow(main_table)) { if(!is.na(main_table$_[i])) { # 1.1 , - probability_spam <- probability_spam * main_table$_[i] } if(!is.na(main_table$__[i])) { # 1.2 , - probability_not_spam <- probability_not_spam * main_table$__[i] } } # 2.1 , - probability_spam <- (length(spam)/(length(spam)+length(not_spam)))*probability_spam # 2.2 , - probability_not_spam <- (length(not_spam)/(length(spam)+length(not_spam)))*probability_not_spam # - ifelse(probability_spam>probability_not_spam," - !"," - !")
شكرا جزيلا على وقتك في قراءة مقالتي. آمل أن تكون قد تعلمت شيئًا جديدًا لنفسك ، أو تسلط الضوء ببساطة على اللحظات غير الواضحة لك. حظ موفق
مصادر:- مقال جيد جدا عن المصنف الساذج بايز
- المعرفة المستمدة من ويكي: هنا ، هنا ، وهنا
- محاضرات حول استخراج البيانات Chubukova I.A.