
يوصي التصميم الأكاديمي لمستودع البيانات بالحفاظ على كل شيء في شكل عادي ، مع وجود روابط بين. ثم سيوفر التراجع عن التغييرات في الرياضيات العلائقية مستودعًا موثوقًا به مع دعم المعاملات. الذرية ، الاتساق ، العزلة ، المتانة - هذا كل شيء. بمعنى آخر ، تم إنشاء المستودع خصيصًا لتحديث البيانات بأمان. ولكنها ليست مثالية على الإطلاق للبحث ، خاصة مع إيماءة واسعة عبر الجداول والحقول. تحتاج إلى فهارس ، فهارس كثيرة. تنمو الأحجام ، ويتباطأ التسجيل. SQL LIKE غير مفهرسة ، وتقوم JOIN GROUP BY بإرساله إلى مخطط الاستعلام للتأمل.
الحمل المتزايد على آلة واحدة يجبرها على التوسع ، إما عموديًا في السقف أو أفقيًا ، وشراء بضع عقد أخرى. تؤدي متطلبات تجاوز الفشل إلى انتشار البيانات عبر عدة عُقد. ومتطلب الاسترداد الفوري بعد الفشل ، دون رفض الخدمة ، يجبرك على تكوين مجموعة من الآلات بحيث يمكن لأي منهم في أي وقت أداء الكتابة والقراءة. هذا يعني ، أن تكون سيدًا بالفعل ، أو أن تصبح منه تلقائيًا وعلى الفور.
تم حل مشكلة البحث السريع عن طريق تثبيت مستودع ثاني محسن للفهرسة في مكان قريب. البحث عن النص الكامل ، الأوجه ، مع الجذعية والبلاك جاك . يقبل التخزين الثاني الإدخالات من جداول الأولى كمدخلات ، يحلل ويؤسس الفهرس. وهكذا ، تم استكمال مجموعة تخزين البيانات بمجموعة أخرى للبحث عنها. مع تكوين رئيسي مماثل لمطابقة اتفاقية مستوى الخدمة الشاملة. كل شيء على ما يرام ، العمل مسرور ، ينام المسؤولون في الليل ... حتى يكون هناك أكثر من ثلاثة أجهزة في المجموعة الرئيسية.
مرن
وسعت حركة NoSQL بشكل كبير أفق المقياس للبيانات الصغيرة والكبيرة. يمكن للعقد NoSQL للمجموعة توزيع البيانات فيما بينها بحيث لا يؤدي فشل واحدة أو أكثر منها إلى رفض الخدمة للمجموعة بأكملها. كان الدفع مقابل التوفر العالي للبيانات الموزعة هو عدم القدرة على ضمان اتساقها الكامل للتسجيل في أي وقت معين. بدلاً من ذلك ، تتحدث NoSQL عن الاتساق النهائي . أي أنه يعتقد أنه في يوم ما ستنتشر جميع البيانات إلى عقد الكتلة ، وستصبح متسقة على المدى الطويل.
لذلك تم استكمال النموذج العلائقي بالآخر غير العلائقي وأنتج العديد من محركات قواعد البيانات التي تحل مشاكل مثلث CAP ببعض النجاح. أصبح المطورون في أيديهم أدوات عصرية لبناء طبقة المثابرة المثالية الخاصة بهم - لكل ذوق وميزانية وملف تحميل.
مطاط البحث هو ممثل NoSQL مجمع مع RESTful JSON API على محرك Lucene ، مفتوح المصدر في Java ، قادر على بناء فهرس بحث ، ولكن أيضًا تخزين المستند الأصلي. يساعد هذا الخداع على إعادة التفكير في دور نظام DBMS منفصل لتخزين النسخ الأصلية ، أو حتى التخلي عنه. نهاية المقدمة.
رسم الخرائط
يعد التعيين في ElasticSearch شيئًا مثل المخطط (هيكل الجدول ، من حيث SQL) الذي يخبرك تمامًا بكيفية فهرسة المستندات الواردة (السجلات ، من حيث SQL). قد تكون الخرائط ثابتة أو ديناميكية أو غائبة. التعيين الثابت لا يسمح بتغيير نفسه. ديناميكية تسمح لك بإضافة حقول جديدة. إذا لم يتم تحديد التعيين ، فسيتم إجراء البحث المرن بمفرده ، بعد استلام المستند الأول للكتابة. سيحلل هيكل الحقول ، ويضع بعض الافتراضات حول أنواع البيانات الموجودة فيها ، ويتخطى الإعدادات الافتراضية ويكتبها. يبدو هذا السلوك بدون دارة للوهلة الأولى مناسبًا جدًا. ولكن في الواقع ، هو أكثر ملاءمة للتجربة من المفاجآت في الإنتاج.
لذا ، تتم فهرسة البيانات ، وهذه عملية أحادية الاتجاه. بمجرد إنشائه ، لا يمكن تغيير التعيين ديناميكيًا مثل ALTER TABLE في SQL. لأن جدول SQL يخزن المستند الأصلي الذي يمكنك ربط فهرس البحث به. ولكن في ElasticSearch العكس. هو نفسه هو فهرس البحث الذي يمكنك ربط المستند الأصلي به. هذا هو السبب في أن مخطط الفهرس ثابت. نظريا ، يمكن للمرء إما إنشاء حقل في رسم الخرائط أو حذفه. من الناحية العملية ، يسمح لك البحث المرن فقط بإضافة الحقول. محاولة حذف حقل لا تؤدي إلى أي شيء.
الاسم المستعار
الاسم المستعار - هذا اسم إضافي لفهرس ElasticSearch. يمكن أن يكون هناك العديد من الأسماء المستعارة لفهرس واحد. أو اسم مستعار واحد للمؤشرات المتعددة. ثم يتم دمج المؤشرات منطقياً كما لو كانت من الخارج وتبدو مثل واحدة. الاسم المستعار مناسب جدًا للخدمات التي تتواصل مع الفهرس طوال حياته. على سبيل المثال ، يمكن أن تخفي منتجات الاسم المستعار كلاً من products_v2 و products_v25 ، دون الحاجة إلى تغيير الأسماء في الخدمة. الاسم المستعار لا غنى عنه لترحيل البيانات ، عندما يتم نقلها بالفعل من المخطط القديم إلى المخطط الجديد ، وتحتاج إلى تبديل التطبيق للعمل مع الفهرس الجديد. تحويل اسم مستعار من فهرس إلى فهرس عملية ذرية. أي أنه يتم في خطوة واحدة دون خسارة.
Reindex API
يميل تخطيط البيانات ورسم الخرائط إلى التغيير من وقت لآخر. تمت إضافة حقول جديدة ، يتم حذف الحقول غير الضرورية. إذا لعب ElasticSearch دور المستودع الوحيد ، فأنت بحاجة إلى نوع من الأدوات لتغيير الخرائط على الطاير. للقيام بذلك ، هناك أمر خاص لنقل البيانات من فهرس إلى آخر ، ما يسمى _reindex API . يعمل مع التعيين الجاهز أو الفارغ لفهرس المستلم ، على جانب الخادم ، والفهرسة بسرعة في دفعات من 1000 مستند في المرة الواحدة.
يمكن أن تقوم إعادة الفهرسة بتحويل نوع حقل بسيط. على سبيل المثال طويلة في النص والعودة طويلة ، أو منطقية في النص والعودة منطقية . لكن -9.99 في القيم المنطقية لم يعد يعرف كيف ، ليس PHP لك . من ناحية أخرى ، نوع التحويل غير آمن. يمكن أن تغفر خدمة مكتوبة بلغة ذات كتابة ديناميكية لمثل هذه الخطيئة. ولكن إذا لم تتمكن reindex من تحويل النوع ، فلن تتم كتابة المستند ببساطة. بشكل عام ، يجب أن يتم ترحيل البيانات على 3 مراحل: إضافة حقل جديد ، وإطلاق خدمة بها ، وتنظيف الحقل القديم.
تمت إضافة حقل مثل هذا. يتم أخذ مخطط الفهرس المصدر ، يتم إدخال خاصية جديدة ، يتم إنشاء فهرس فارغ. ثم يبدأ إعادة الفهرسة:
{ "source": { "index": "test" }, "dest": { "index": "test_clone" } }
يتم حذف الحقل بطريقة مماثلة. يتم أخذ مخطط الفهرس المصدر ، تتم إزالة الحقل ، يتم إنشاء فهرس فارغ. ثم يبدأ إعادة الفهرسة بقائمة من الحقول المراد نسخها:
{ "source": { "index": "test", "_source": ["field1", "field3"] }, "dest": { "index": "test_clone" } }
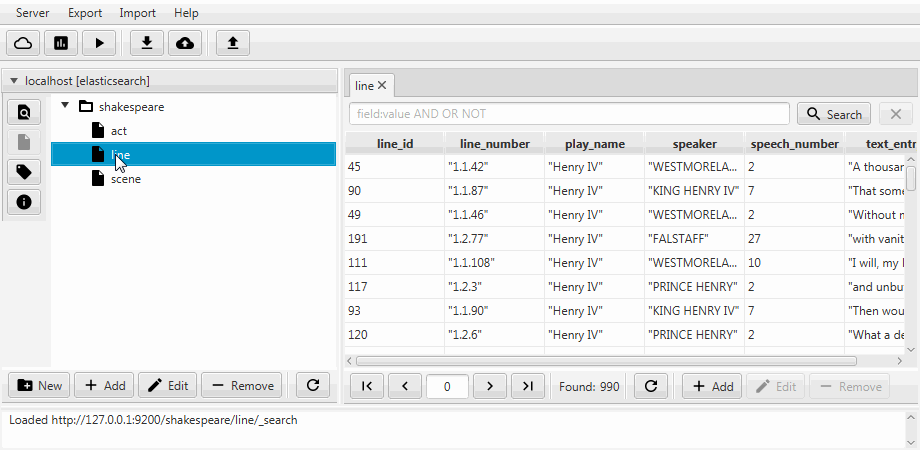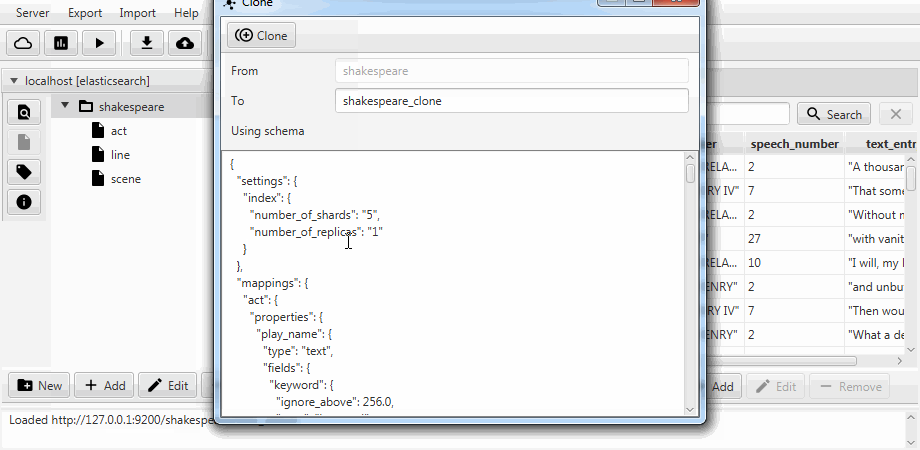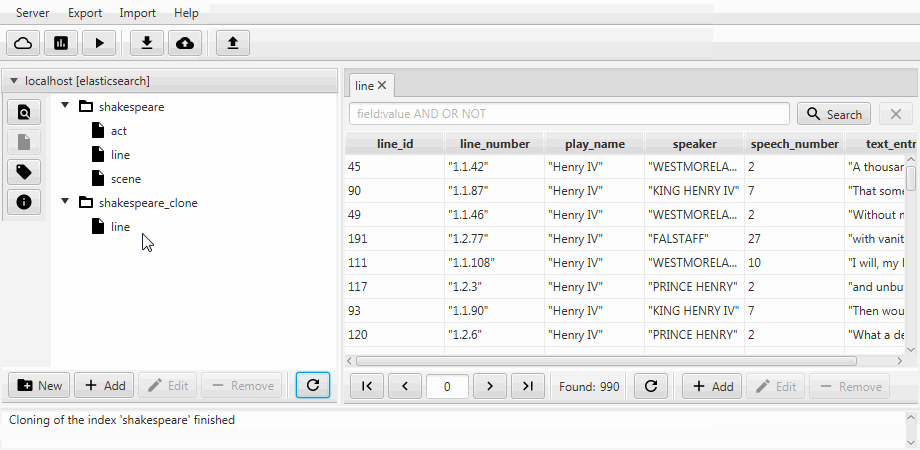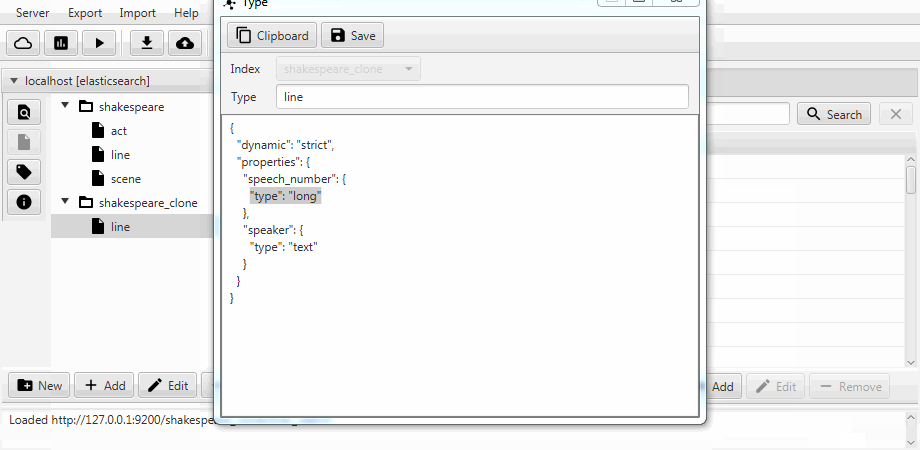
من أجل الراحة ، يتم دمج كلتا الحالتين في وظيفة استنساخ في Kaizen ، عميل سطح المكتب لـ ElasticSearch. الاستنساخ يمكن أن يتكيف مع تعيين فهرس الوجهة. يوضح المثال أدناه كيفية عمل استنساخ جزئي من فهرس بثلاث مجموعات (أنواع ، من حيث البحث المرن) ، سطر ، مشهد . لا يزال هناك سوى سطر به حقلين ، ويتم تمكين التعيين الثابت ، ويصبح حقل رقم الكلام من النص طويلاً .
الهجرة
واجهة برمجة تطبيقات reindex لديها ميزة واحدة غير سارة - فهي لا تعرف كيفية مراقبة التغييرات في فهرس المصدر. إذا تغير شيء هناك بعد بدء إعادة الفهرسة ، فلن تنعكس التغييرات في فهرس المستلمين. لحل هذه المشكلة ، تم تطوير البرنامج المساعد ElasticSearch FollowUp Plugin ، والذي يضيف أوامر تسجيل. يمكن للمكوِّن الإضافي مراقبة الفهرس والعودة بتنسيق JSON للإجراءات التي يتم تنفيذها على المستندات بترتيب زمني. الفهرس والنوع ومعرف المستند والعملية عليه - يتم تذكر INDEX أو DELETE. تم نشر البرنامج المساعد FollowUp على GitHub وتم تجميعه لجميع إصدارات ElasticSearch تقريبًا.
لذلك ، لترحيل البيانات بدون فقدان ، ستحتاج إلى تثبيت المتابعة على العقدة حيث سيبدأ إعادة الفهرسة. من المفترض أن الفهرس يحتوي بالفعل على اسم مستعار ، وتعمل جميع التطبيقات من خلاله. قبل إعادة الفهرسة مباشرة ، يتم تشغيل المكون الإضافي. عند اكتمال إعادة الفهرسة ، يتم إيقاف تشغيل المكون الإضافي ويتم قلب الاسم المستعار إلى الفهرس الجديد. ثم ، يتم استنساخ الإجراءات المسجلة على فهرس المستلمين ، واللحاق بحالته. على الرغم من السرعة العالية لإعادة الفهرسة ، يمكن أن يحدث نوعان من التصادمات أثناء التشغيل:
- لم يعد هناك مستند بمثل هذا _id في الفهرس الجديد. تمكنوا من حذف المستند بعد تبديل الاسم المستعار إلى الفهرس الجديد.
- يوجد في الفهرس الجديد مستند به _id ، ولكن برقم إصدار أعلى منه في الفهرس المصدر. تمكنوا من تحديث المستند بعد تبديل الاسم المستعار إلى الفهرس الجديد.
في هذه الحالات ، لا يجب استنساخ الإجراء في فهرس الوجهة. يتم نسخ التغييرات الأخرى.
الترميز سعيدة!