في المقالة سوف نتحدث عن استخدام الشبكات العصبية التلافيفية لحل مهمة عمل عملية لاستعادة رسم بياني حقيقي من صور الرفوف مع البضائع. باستخدام Tensorflow Object Detection API ، سنقوم بتدريب نموذج البحث / التوطين. سنحسن جودة البحث عن المنتجات الصغيرة في صور عالية الدقة باستخدام نافذة عائمة وخوارزمية كبح غير قصوى. في Keras ، نقوم بتنفيذ مصنف للسلع حسب العلامة التجارية. وبالتوازي ، سنقوم بمقارنة المقاربات والنتائج بالقرارات التي اتخذت منذ 4 سنوات. جميع البيانات المستخدمة في المقالة متاحة للتنزيل ، ورمز العمل الكامل موجود على
GitHub وهو مصمم كبرنامج تعليمي.

مقدمة
ما هو المخطط؟ رسم تخطيطي لعرض البضائع على معدات التداول الخرسانية في المتجر.
ما هو ريلوجرام؟ تخطيط البضائع على معدات تداول محددة موجودة في المتجر هنا والآن.
Planogram - كما يجب ، realogram - ما لدينا.

حتى الآن ، في العديد من المتاجر ، فإن إدارة بقية البضائع على الرفوف والرفوف والعدادات والرفوف هي عمل يدوي حصري. يقوم الآلاف من الموظفين بالتحقق من توفر المنتجات يدويًا ، وحساب الرصيد ، والتحقق من الموقع بالمتطلبات. إنها باهظة الثمن ، والأخطاء محتملة جدًا. عرض غير صحيح أو نقص في السلع يؤدي إلى انخفاض المبيعات.
أيضا ، يدخل العديد من الشركات المصنعة في اتفاقيات مع تجار التجزئة لعرض سلعهم. وبما أن هناك الكثير من الشركات المصنعة ، فيما بينها يبدأ النضال من أجل أفضل مكان على الرف. يريد الجميع أن يكمن منتجه في المركز أمام أعين المشتري ويحتل أكبر مساحة ممكنة. هناك حاجة للتدقيق المستمر.
ينتقل الآلاف من التجار من متجر إلى آخر للتأكد من أن منتجات شركتهم على الرف وعرضها وفقًا للعقد. في بعض الأحيان يكونون كسالى: من اللطيف تجميع تقرير دون مغادرة منزلك من الذهاب إلى نقطة بيع. هناك حاجة لتدقيق دائم لمراجعي الحسابات.
وبطبيعة الحال ، تم حل مهمة الأتمتة وتبسيط هذه العملية لفترة طويلة. كانت معالجة الصور من أصعب الأجزاء: العثور على المنتجات والتعرف عليها. وفي الآونة الأخيرة نسبيًا فقط تم تبسيط هذه المهمة لدرجة أنه بالنسبة لحالة معينة في شكل مبسط ، يمكن وصف حلها الكامل في مقالة واحدة. هذا ما سنفعله.
تحتوي المقالة على حد أدنى من التعليمات البرمجية (فقط للحالات التي يكون فيها الرمز أكثر وضوحًا من النص). الحل الكامل متاح كبرنامج تعليمي مصور في
دفاتر الملاحظات jupyter . لا تحتوي المقالة على وصف لبنية الشبكات العصبية ، ومبادئ الخلايا العصبية ، والصيغ الرياضية. في المقالة ، نستخدمها كأداة هندسية ، دون الخوض في تفاصيل جهازها.
البيانات والنهج
كما هو الحال مع أي نهج قائم على البيانات ، تتطلب حلول الشبكات العصبية بيانات. يمكنك أيضًا تجميعها يدويًا: لالتقاط عدة مئات من العدادات
وترميزها باستخدام ، على سبيل المثال ،
LabelImg . يمكنك طلب الترميز ، على سبيل المثال ، على Yandex.Tolok.
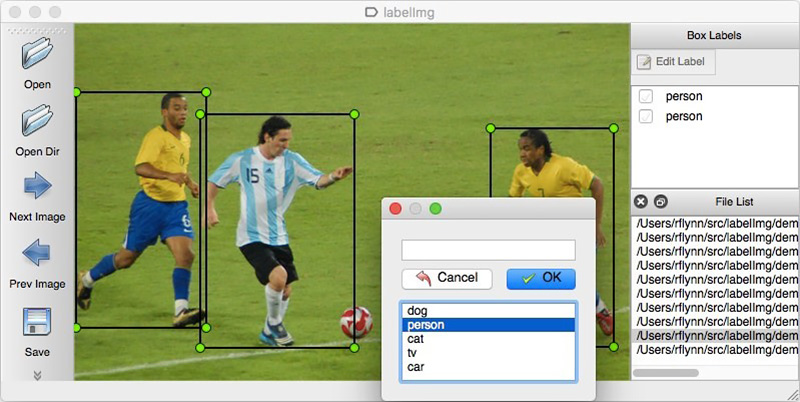
لا يمكننا الكشف عن تفاصيل مشروع حقيقي ، لذلك سنشرح التكنولوجيا على البيانات المفتوحة. كان التسوق والتقاط الصور كسولًا جدًا (ولم نكن لنفهم ذلك هناك) ، وانتهت الرغبة في عمل ترميز للصور الموجودة على الإنترنت بمفردنا بعد الكائن المصنف المائة. لحسن الحظ ، صادفت أرشيف أرشيف
مجموعة بيانات البقالة .
في عام 2014 ، قام موظفو Idea Teknoloji ، اسطنبول ، تركيا بتحميل 354 صورة من 40 متجرًا تم تصنيعها على 4 كاميرات. في كل من هذه الصور ، سلطوا الضوء بالمستطيلات على عدة آلاف من الأشياء ، تم تصنيف بعضها إلى 10 فئات.
هذه صور علب سجائر. نحن لا نشجع أو نشجع على التدخين. ببساطة لم يكن هناك شيء أكثر حيادية. ونعد بأننا في كل مكان في المقالة ، حيث يسمح الوضع ، سوف نستخدم صور القطط.

بالإضافة إلى الصور ذات العلامات من الرفوف ، كتبوا مقالة
نحو التعرف على منتجات التجزئة على رفوف البقالة مع حل لمشكلة التوطين والتصنيف. هذا يحدد نوعًا من النقطة المرجعية: يجب أن يكون حلنا باستخدام الأساليب الجديدة أبسط وأكثر دقة ، وإلا فإنه ليس مثيرًا للاهتمام. يتكون نهجهم من مجموعة من الخوارزميات:
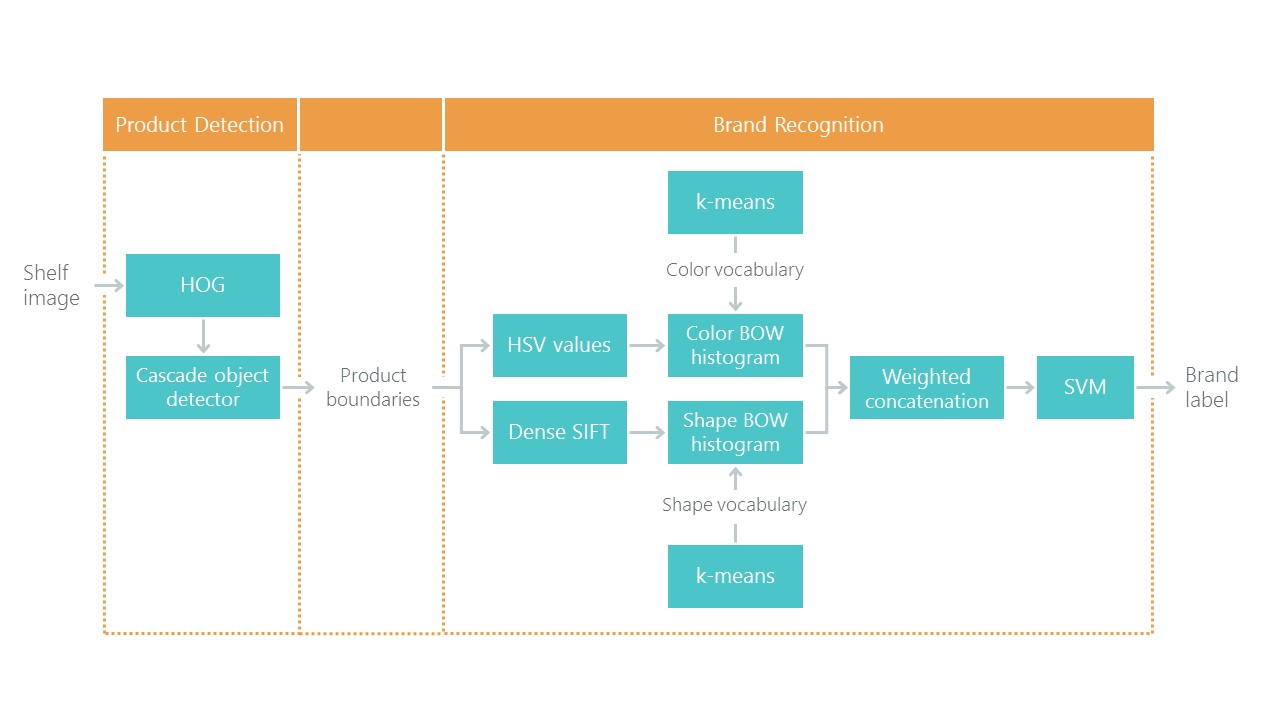
في الآونة الأخيرة ، أحدثت الشبكات العصبية التلافيفية (CNN) ثورة في مجال رؤية الكمبيوتر وغيرت تمامًا نهج حل هذه المشاكل. على مدى السنوات القليلة الماضية ، أصبحت هذه التقنيات متاحة لمجموعة واسعة من المطورين ، وقد خفضت واجهات برمجة التطبيقات عالية المستوى مثل Keras حد دخولها بشكل ملحوظ. الآن ، يمكن لأي مطور تقريبًا استخدام القوة الكاملة للشبكات العصبية التلافيفية بعد بضعة أيام فقط من المواعدة. تصف المقالة استخدام هذه التقنيات باستخدام مثال يوضح كيف يمكن بسهولة استبدال سلسلة كاملة من الخوارزميات بشبكتين عصبيتين فقط دون فقدان الدقة.
سنحل المشكلة في خطوات:
- إعداد البيانات. نقوم بضخ المحفوظات وتحويلها إلى عرض ملائم للعمل.
- تصنيف العلامة التجارية. نقوم بحل مشكلة التصنيف باستخدام شبكة عصبية.
- ابحث عن المنتجات في الصورة. ندرب الشبكة العصبية للبحث عن السلع.
- تنفيذ البحث. سنحسن جودة الكشف باستخدام نافذة عائمة وخوارزمية لقمع غير الحد الأقصى.
- الخلاصة اشرح باختصار لماذا الحياة الواقعية أكثر تعقيدًا من هذا المثال.
التكنولوجيا
التقنيات الرئيسية التي سنستخدمها: Tensorflow، Keras، Tensorflow Object Detection API، OpenCV. على الرغم من أن كل من Windows و Mac OS مناسبان للعمل مع Tensorflow ، ما زلنا نوصي باستخدام Ubuntu. حتى إذا لم تكن قد عملت مع نظام التشغيل هذا من قبل ، فإن استخدامه سيوفر لك الكثير من الوقت. تثبيت Tensorflow للعمل مع GPU هو موضوع يستحق مقالة منفصلة. لحسن الحظ ، توجد مثل هذه المقالات بالفعل. على سبيل المثال ،
تثبيت TensorFlow على Ubuntu 16.04 باستخدام Nvidia GPU . قد تكون بعض التعليمات منه قديمة.
الخطوة 1. تجهيز البيانات ( رابط جيثب )تستغرق هذه الخطوة ، كقاعدة ، وقتًا أطول بكثير من المحاكاة نفسها. لحسن الحظ ، نستخدم البيانات الجاهزة ، التي نقوم بتحويلها إلى الشكل الذي نحتاجه.
يمكنك تنزيل وفك الضغط بهذه الطريقة:
wget https://github.com/gulvarol/grocerydataset/releases/download/1.0/GroceryDataset_part1.tar.gz wget https://github.com/gulvarol/grocerydataset/releases/download/1.0/GroceryDataset_part2.tar.gz tar -xvzf GroceryDataset_part1.tar.gz tar -xvzf GroceryDataset_part2.tar.gz
نحصل على هيكل المجلد التالي:
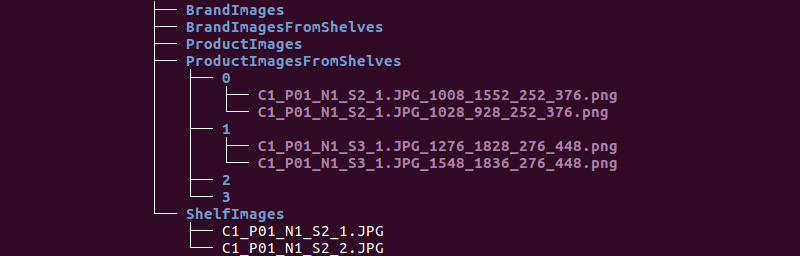
سنستخدم معلومات من دلائل ShelfImages و ProductImagesFromShelves.
يحتوي ShelfImages على صور للأرفف نفسها. في الاسم ، يتم ترميز معرف الحامل مع معرف الصورة. يمكن أن يكون هناك عدة صور لحامل واحد. على سبيل المثال ، صورة واحدة كاملة وخمس صور في أجزاء بها تقاطعات.
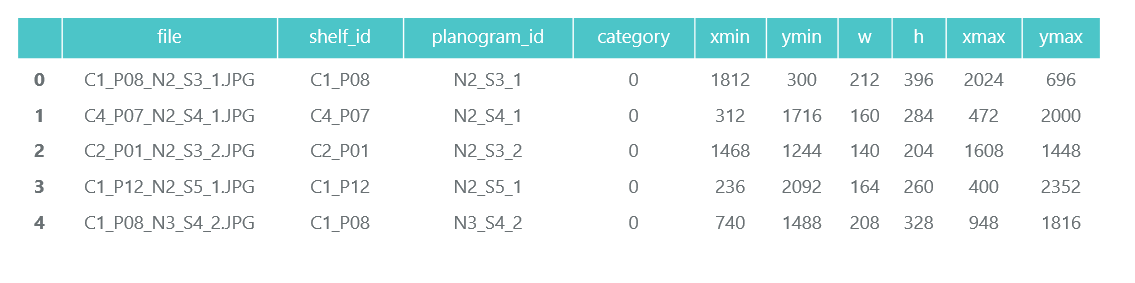
ملف C1_P01_N1_S2_2.JPG (الحامل C1_P01 ، لقطة N1_S2_2):

نراجع جميع الملفات ونجمع المعلومات في إطار بيانات الباندا photos_df:
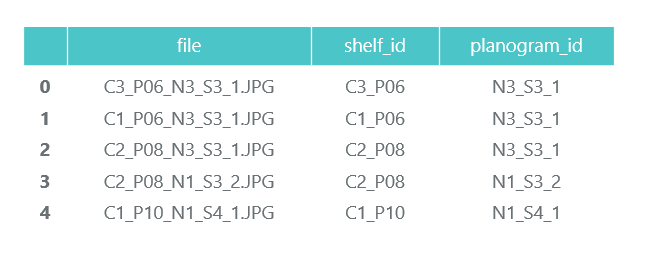
ProductImagesFromShelves يحتوي على صور مقطوعة للسلع من الرفوف في 11 دليلاً فرعيًا: 0 - غير مصنفة ، 1 - مارلبورو ، 2 - كينت ، إلخ. لكي لا نعلن عنها ، سنستخدم فقط أرقام الفئات دون تحديد أسماء. تحتوي الملفات الموجودة في الأسماء على معلومات حول الحامل وموضع وحجم العبوة عليه.
ملف C1_P01_N1_S3_1.JPG_1276_1828_276_448.png من الدليل 1 (الفئة 1 ، الحامل C1_P01 ، الصورة N1_S3_1 ، إحداثيات الزاوية اليسرى العليا (1276 ، 1828) ، العرض 276 ، الارتفاع 448):
لا نحتاج إلى صور العبوات الفردية نفسها (سنقطعها من صور الرفوف) ، ونجمع معلومات حول فئتها وموقعها في إطار بيانات الباندا products_df:
في نفس الخطوة ، نقوم بتقسيم جميع معلوماتنا إلى قسمين: تدريب للتدريب والتحقق من صحته لرصد التدريب. بالطبع ، هذا لا يستحق القيام به في المشاريع الحقيقية. وكذلك لا تثق بمن يفعل ذلك. يجب عليك على الأقل تخصيص اختبار آخر للاختبار النهائي. ولكن حتى مع هذا النهج غير الصادق ، من المهم لنا ألا نخدع أنفسنا كثيرًا.
كما أشرنا من قبل ، يمكن أن يكون هناك عدة صور لحامل واحد. وفقًا لذلك ، يمكن أن تقع نفس الحزمة في عدة صور. لذلك ، ننصحك بعدم التقسيم ليس بالصور ، وحتى أكثر من ذلك بالعلبة ، ولكن بالرفوف. هذا ضروري حتى لا يحدث أن ينتهي الشيء نفسه ، المأخوذ من زوايا مختلفة ، في كل من القطار والتحقق.
نجعل تقسيم 70/30 (30 ٪ من الرفوف يتم التحقق منها ، والباقي للتدريب):
سوف نتأكد من أنه عند الانقسام ، سيكون هناك ما يكفي من ممثلي كل فصل للتدريب والتحقق من الصحة:

يظهر اللون الأزرق عدد المنتجات في فئة التحقق ، والبرتقالي للتدريب. الوضع ليس جيدًا جدًا مع الفئة 3 للمصادقة ، ولكن من حيث المبدأ هناك عدد قليل من ممثليها.
في مرحلة إعداد البيانات ، من المهم عدم ارتكاب خطأ ، حيث أن كل عمل إضافي يعتمد على نتائجه. ما زلنا نرتكب خطأً واحدًا وقضينا ساعات سعيدة في محاولة فهم سبب جودة النماذج دون المتوسط. لقد شعرت بالفعل بأنني خاسر لتقنيات "المدرسة القديمة" ، حتى لاحظت عن طريق الخطأ أن بعض الصور الأصلية تم تدويرها 90 درجة ، وبعضها مقلوب رأساً على عقب.
في نفس الوقت ، يتم الترميز كما لو كانت الصور موجهة بشكل صحيح. بعد إصلاح سريع ، أصبحت الأمور أكثر متعة.
سنحفظ بياناتنا في ملفات pkl لاستخدامها في الخطوات التالية. المجموع لدينا:
- دليل صور الرفوف وأجزائها مع الحزم ،
- إطار بيانات مع وصف لكل رف مع ملاحظة ما إذا كان مخصصًا للتدريب ،
- إطار بيانات يحتوي على معلومات حول جميع المنتجات على الرفوف ، مما يشير إلى موقعها وحجمها وفئتها ووضع علامة على ما إذا كانت مخصصة للتدريب.
للتحقق ، نعرض رفًا واحدًا وفقًا لبياناتنا:
 الخطوة 2. التصنيف حسب العلامة التجارية ( الرابط في جيثب )
الخطوة 2. التصنيف حسب العلامة التجارية ( الرابط في جيثب )تصنيف الصور هو المهمة الرئيسية في مجال رؤية الكمبيوتر. المشكلة هي "الفجوة الدلالية": التصوير الفوتوغرافي هو مصفوفة كبيرة من الأرقام [0 ، 255]. على سبيل المثال ، 800x600x3 (3 قنوات RGB).

لماذا هذه المهمة صعبة:

كما قلنا من قبل ، حدد مؤلفو البيانات التي نستخدمها 10 علامات تجارية. هذه مهمة مبسطة للغاية ، نظرًا لوجود عدد أكبر بكثير من العلامات التجارية للسجائر على الرفوف. لكن كل ما لم يندرج ضمن هذه الفئات العشر تم إرساله إلى 0 - غير مصنف:

"
تقدم مقالتهم خوارزمية تصنيف بدقة 92٪:

ماذا سنفعل:
- سنقوم بإعداد البيانات للتدريب ،
- نقوم بتدريب شبكة عصبية تلافيفية باستخدام بنية ResNet v1 ،
- تحقق من الصور للتحقق من صحتها.
يبدو الأمر "ضخمًا" ، لكننا استخدمنا للتو مثال Keras "
Trains a ResNet على مجموعة بيانات CIFAR10 "
مستمدًا منه وظيفة ResNet v1.
لبدء عملية التدريب ، تحتاج إلى إعداد صفيفين: x - صور للحزم ذات البعد (عدد الحزم ، الارتفاع ، العرض ، 3) و y - فئاتها ذات البعد (عدد العبوات ، 10). يحتوي الصفيف y على ما يسمى بالنواقل الساخنة. إذا كانت فئة حزمة التدريب لها رقم 2 (من 0 إلى 9) ، فإن هذا يتوافق مع المتجه [0 ، 0 ، 1 ، 0 ، 0 ، 0 ، 0 ، 0 ، 0 ، 0].
السؤال المهم هو ما يجب فعله مع العرض والارتفاع ، لأن جميع الصور تم التقاطها بدرجات دقة مختلفة من مسافات مختلفة. نحن بحاجة إلى اختيار بعض الحجم الثابت ، الذي يمكننا من خلاله جلب جميع صورنا للحزم. هذا الحجم الثابت هو معلمة تعريفية تحدد كيفية تدريب وعمل شبكتنا العصبية.
من ناحية ، أريد أن أجعل هذا الحجم كبيرًا قدر الإمكان حتى لا تمر تفاصيل واحدة من الصورة دون أن يلاحظها أحد. من ناحية أخرى ، مع كمية ضئيلة من بيانات التدريب ، يمكن أن يؤدي ذلك إلى إعادة تدريب سريعة: سيعمل النموذج بشكل مثالي على بيانات التدريب ، ولكن سيء على بيانات التحقق. لقد اخترنا الحجم 120x80 ، وربما نحصل على نتيجة أفضل على حجم مختلف. وظيفة التكبير:
تحجيم وعرض حزمة واحدة للتحقق. يصعب قراءة اسم العلامة التجارية من قبل شخص ، دعنا نرى كيف ستتعامل الشبكة العصبية مع مهمة التصنيف:

بعد التحضير وفقًا للعلامة التي تم الحصول عليها في الخطوة السابقة ، نقوم بتقسيم صفائف x و y إلى x_train / x_validation و y_train / y_validation ، نحصل على:
x_train shape: (1969, 120, 80, 3) y_train shape: (1969, 10) 1969 train samples 775 validation samples
يتم تحضير البيانات ، نقوم بنسخ وظيفة مُنشئ الشبكة العصبية لبنية ResNet v1 من مثال Keras:
def resnet_v1(input_shape, depth, num_classes=10): …
نقوم ببناء نموذج:
model = resnet_v1(input_shape=x_train.shape[1:], depth=depth, num_classes=num_classes) model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=lr_schedule(0)), metrics=['accuracy'])
لدينا مجموعة بيانات محدودة إلى حد ما. لذلك ، من أجل منع النموذج من رؤية الصورة نفسها في كل مرة أثناء التدريب ، نستخدم التعزيز: قم بتحويل الصورة عشوائيًا وتدويرها قليلاً. يوفر Keras هذه المجموعة من الخيارات لهذا:
نبدأ عملية التدريب.
بعد التدريب والتقييم نحصل على الدقة في حدود 92٪. قد تحصل على دقة مختلفة: هناك القليل من البيانات ، لذلك تعتمد الدقة إلى حد كبير على نجاح القسم. في هذا القسم ، لم نحصل على دقة أعلى بكثير من تلك المشار إليها في المقالة ، لكننا لم نفعل شيئًا من الناحية العملية وكتبنا كودًا صغيرًا. علاوة على ذلك ، يمكننا بسهولة إضافة فئة جديدة ، ويجب أن تزيد الدقة (نظريًا) بشكل كبير إذا قمنا بإعداد المزيد من البيانات.
للفائدة ، قارن مصفوفات الارتباك:
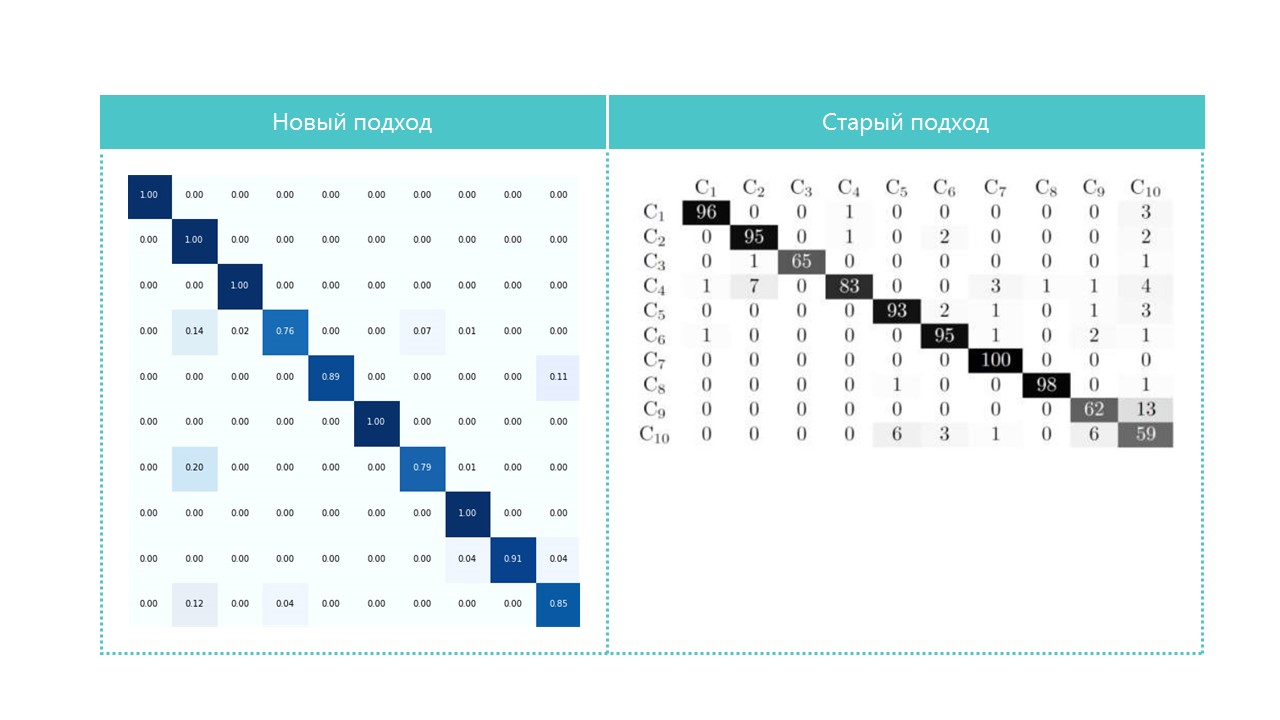
تقريبا كل الفئات تحدد شبكتنا العصبية بشكل أفضل ، باستثناء الفئتين 4 و 7. من المفيد أيضًا النظر إلى ألمع الممثلين لكل خلية مصفوفة ارتباك:
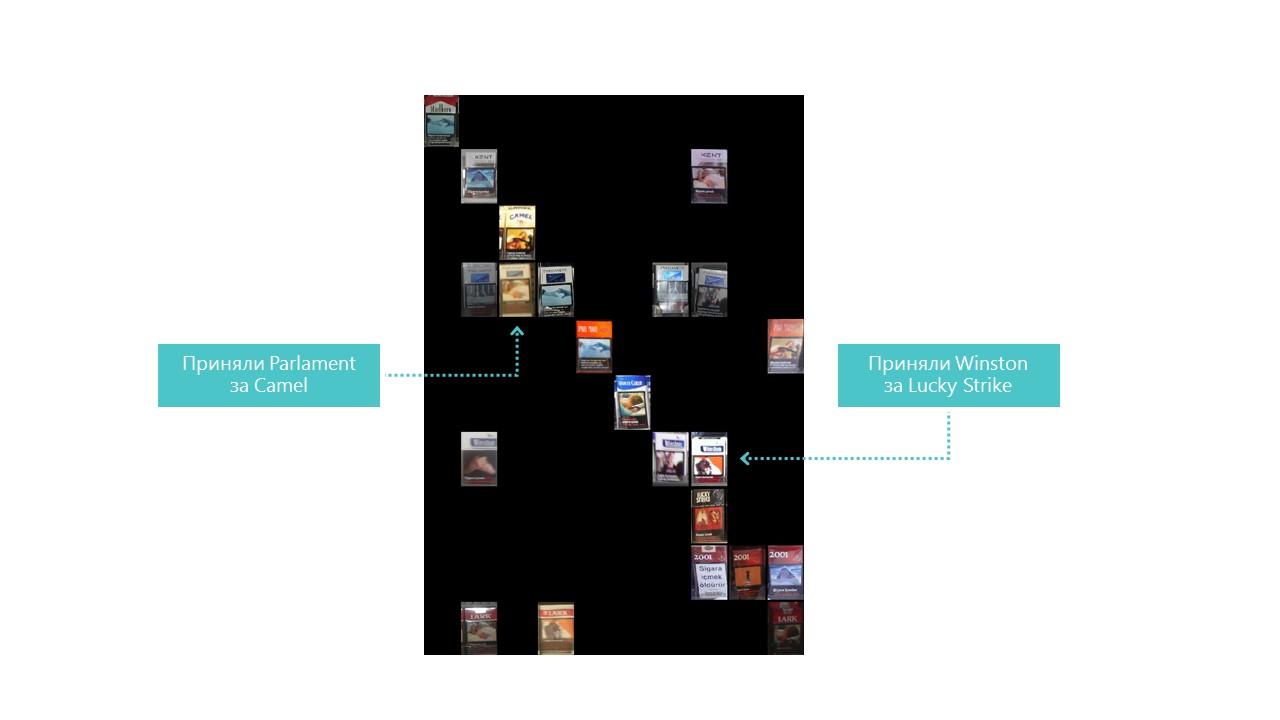
يمكنك أيضًا أن تفهم سبب خطأ البرلمان في الإبل ، ولكن لماذا كان وينستون مخطئًا في Lucky Strike أمرًا غير مفهوم تمامًا ، ولكن ليس لديهم شيء مشترك. هذه هي المشكلة الرئيسية للشبكات العصبية - العتامة الكاملة لما يحدث في الداخل. يمكنك بالطبع تصور بعض الطبقات ، ولكن بالنسبة لنا يبدو هذا التصور كما يلي:

فرصة واضحة لتحسين جودة الاعتراف في ظروفنا هي إضافة المزيد من الصور.
لذلك ، المصنف جاهز. انتقل إلى الكاشف.
الخطوة 3. البحث عن المنتجات في الصورة ( رابط على جيثب )المهام الهامة التالية في مجال رؤية الكمبيوتر هي التجزئة الدلالي ، والتعريب ، والبحث عن الكائنات ، وتجزئة المثيل.
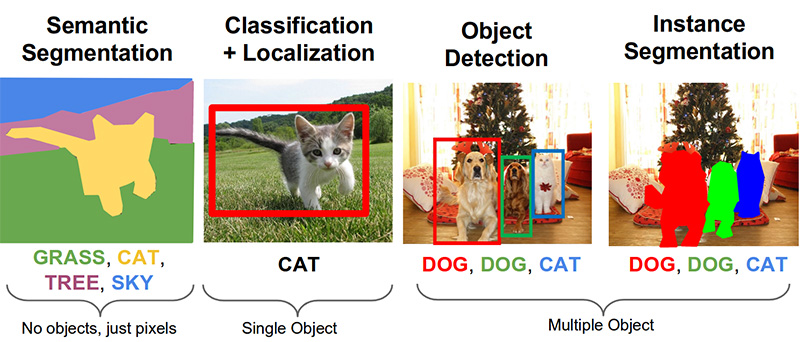
مهمتنا تحتاج إلى كشف الكائن. تقدم مقالة 2014 نهجًا يعتمد على طريقة Viola-Jones و HOG بدقة بصرية:

بفضل استخدام قيود إحصائية إضافية ، فإن دقتها جيدة جدًا:

الآن تم حل مهمة التعرف على الأشياء بنجاح بمساعدة الشبكات العصبية. سنستخدم نظام Tensorflow Object Detection API وتدريب شبكة عصبية باستخدام بنية Mobilenet V1 SSD. تدريب مثل هذا النموذج من الصفر يتطلب الكثير من البيانات ويمكن أن يستغرق أيامًا ، لذلك نستخدم نموذجًا مدربًا على بيانات COCO وفقًا لمبدأ تعلم النقل.
هذا هو المفهوم الرئيسي لهذا النهج. لماذا لا يحتاج الطفل إلى إظهار الملايين من الأشياء حتى يتعلم العثور على الكرة وتمييزها عن المكعب؟ لأن الطفل لديه 500 مليون سنة من تطور القشرة البصرية. جعل التطور الرؤية أكبر نظام حسي. ما يقرب من 50 ٪ (ولكن هذا ليس دقيقًا) من الخلايا العصبية في الدماغ البشري هي المسؤولة عن معالجة الصور. يمكن للوالدين فقط إظهار الكرة والمكعب ، ثم تصحيح الطفل عدة مرات حتى يجد ويميز أحدهما عن الآخر تمامًا.
من وجهة نظر فلسفية (مع اختلافات فنية أكثر من عامة) ، يعمل نقل التعلم في الشبكات العصبية بطريقة مماثلة. تتكون الشبكات العصبية التلافيفية من مستويات ، كل منها يحدد الأشكال المعقدة بشكل متزايد: فهو يحدد النقاط الرئيسية ، ويجمعها في خطوط ، والتي بدورها تتحد في أشكال. وفقط في المستوى الأخير من مجمل العلامات الموجودة يحدد الكائن.
الأشياء المشتركة في العالم الحقيقي تشترك في الكثير. عند نقل التعلم ، نستخدم المستويات المدربة بالفعل لتعريف السمات الأساسية ولا ندرب إلا الطبقات المسؤولة عن تحديد الأشياء. للقيام بذلك ، يكفي بضع مئات من الصور وساعتين من تشغيل وحدة معالجة الرسوميات العادية. تم تدريب الشبكة في الأصل على مجموعة بيانات COCO (كائنات Microsoft الشائعة في السياق) ، وهي 91 فئة و 2500000 صورة! الكثير ، وإن لم يكن 500 مليون سنة من التطور.
بالنظر إلى الأمام قليلاً ، فإن هذه الرسوم المتحركة gif (بطيئة قليلاً ، لا تنتقل على الفور) من tensorboard تصور عملية التعلم. كما ترى ، يبدأ النموذج في إنتاج نتيجة عالية الجودة تمامًا على الفور تقريبًا ، ثم يأتي الطحن:

يمكن لـ "المدرب" لنظام Tensorflow Object Detection API بشكل مستقل إجراء عمليات تكبير ، وقطع أجزاء عشوائية من الصور للتدريب ، واختيار أمثلة "سلبية" (أقسام الصور التي لا تحتوي على أي كائنات). من الناحية النظرية ، ليست هناك حاجة إلى معالجة مسبقة للصور. ومع ذلك ، على جهاز كمبيوتر منزلي مزود بمحرك أقراص ثابتة وكمية صغيرة من ذاكرة الوصول العشوائي ، رفض العمل مع صور عالية الدقة: في البداية كان يعلق لفترة طويلة ، ويسرق مع قرص ، ثم يطير.
ونتيجة لذلك ، قمنا بضغط الصور بحجم 1000 × 1000 بكسل مع الحفاظ على نسبة العرض إلى الارتفاع. ولكن منذ ضغط صورة كبيرة ، يتم فقدان الكثير من العلامات ، حيث تم قطع العديد من المربعات ذات الحجم العشوائي من كل صورة من الحامل وضغطها إلى 1000x1000. ونتيجة لذلك ، فإن حزم عالية الدقة (ولكن ليست كافية) وفي صغيرة (ولكن كثيرة) سقطت في بيانات التدريب. نكرر: هذه الخطوة مفروضة ، وعلى الأرجح ، غير ضرورية على الإطلاق ، وربما ضارة.
يتم حفظ الصور المحضرة والمضغوطة في أدلة منفصلة (تقييم وتدريب) ، ويتم تشكيل وصفها (مع الحزم الموجودة عليها) في شكل إطارين من بيانات الباندا (train_df و Eval_df):
يتطلب نظام Tensorflow Object Detection API إدخالاً كملفات tfrecord. يمكنك تشكيلها باستخدام الأداة المساعدة ، لكننا سنجعلها رمزًا:
def class_text_to_int(row_label): if row_label == 'pack': return 1 else: None def split(df, group): data = namedtuple('data', ['filename', 'object']) gb = df.groupby(group) return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)] def create_tf_example(group, path): with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid: encoded_jpg = fid.read() encoded_jpg_io = io.BytesIO(encoded_jpg) image = Image.open(encoded_jpg_io) width, height = image.size filename = group.filename.encode('utf8') image_format = b'jpg' xmins = [] xmaxs = [] ymins = [] ymaxs = [] classes_text = [] classes = [] for index, row in group.object.iterrows(): xmins.append(row['xmin'] / width) xmaxs.append(row['xmax'] / width) ymins.append(row['ymin'] / height) ymaxs.append(row['ymax'] / height) classes_text.append(row['class'].encode('utf8')) classes.append(class_text_to_int(row['class'])) tf_example = tf.train.Example(features=tf.train.Features(feature={ 'image/height': dataset_util.int64_feature(height), 'image/width': dataset_util.int64_feature(width), 'image/filename': dataset_util.bytes_feature(filename), 'image/source_id': dataset_util.bytes_feature(filename), 'image/encoded': dataset_util.bytes_feature(encoded_jpg), 'image/format': dataset_util.bytes_feature(image_format), 'image/object/bbox/xmin': dataset_util.float_list_feature(xmins), 'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs), 'image/object/bbox/ymin': dataset_util.float_list_feature(ymins), 'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs), 'image/object/class/text': dataset_util.bytes_list_feature(classes_text), 'image/object/class/label': dataset_util.int64_list_feature(classes), })) return tf_example def convert_to_tf_records(images_path, examples, dst_file): writer = tf.python_io.TFRecordWriter(dst_file) grouped = split(examples, 'filename') for group in grouped: tf_example = create_tf_example(group, images_path) writer.write(tf_example.SerializeToString()) writer.close() convert_to_tf_records(f'{cropped_path}train/', train_df, f'{detector_data_path}train.record') convert_to_tf_records(f'{cropped_path}eval/', eval_df, f'{detector_data_path}eval.record')
يبقى لنا إعداد دليل خاص وبدء العمليات:
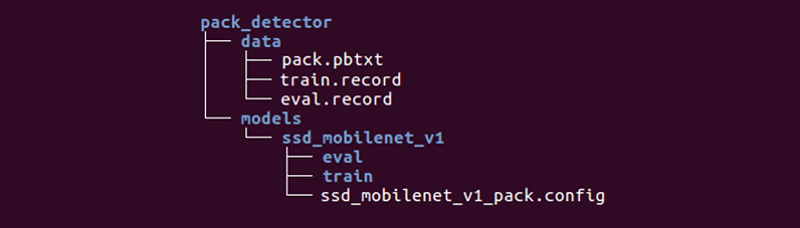
قد يكون الهيكل مختلفًا ، لكننا نجد أنه مناسب جدًا.
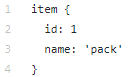
يحتوي دليل البيانات على الملفات التي أنشأناها باستخدام tfrecords (train.record و Eval.record) ، بالإضافة إلى pack.pbtxt مع أنواع الكائنات التي سنقوم بتدريب الشبكة العصبية لها. لدينا نوع واحد فقط من الكائنات لتعريفه ، لذا فإن الملف قصير جدًا:
يحتوي دليل النماذج (يمكن أن يكون هناك العديد من النماذج لحل مشكلة واحدة) في الدليل الفرعي ssd_mobilenet_v1 على إعدادات التدريب في ملف .config ، بالإضافة إلى دليلين فارغين: التدريب والتقييم. في القطار ، سيحفظ "المدرب" نقاط التحكم بالنموذج ، وسيقوم "المقيم" باستلامها وتشغيلها على البيانات للتقييم ووضعها في دليل التقييم. سيتابع Tensorboard هذين الدليلين ويعرض معلومات العملية.
وصف مفصل لبنية ملفات التكوين ، إلخ. يمكن العثور عليها
هنا وهنا . يمكن العثور على تعليمات تثبيت Tensorflow Object Detection API
هنا .
نذهب إلى دليل النماذج / البحث / كشف الكائنات ونفرغ النموذج المدرب مسبقًا:
wget http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_coco_2017_11_17.tar.gz tar -xvzf ssd_mobilenet_v1_coco_2017_11_17.tar.gz
نقوم بنسخ دليل pack_detector الذي أعدناه هناك.
أولاً ، ابدأ عملية التدريب:
python3 train.py --logtostderr \ --train_dir=pack_detector/models/ssd_mobilenet_v1/train/ \ --pipeline_config_path=pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config
نبدأ عملية التقييم. ليس لدينا بطاقة فيديو ثانية ، لذلك نطلقها على المعالج (باستخدام التعليمات CUDA_VISIBLE_DEVICES = ""). وبسبب هذا ، سيكون متأخراً للغاية فيما يتعلق بعملية التدريب ، ولكن هذا ليس سيئًا للغاية:
CUDA_VISIBLE_DEVICES="" python3 eval.py \ --logtostderr \ --checkpoint_dir=pack_detector/models/ssd_mobilenet_v1/train \ --pipeline_config_path=pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config \ --eval_dir=pack_detector/models/ssd_mobilenet_v1/eval
نبدأ عملية tensorboard:
tensorboard --logdir=pack_detector/models/ssd_mobilenet_v1
بعد ذلك ، يمكننا رؤية الرسوم البيانية الجميلة ، وكذلك العمل الفعلي للنموذج على البيانات المقدرة (gif في البداية):
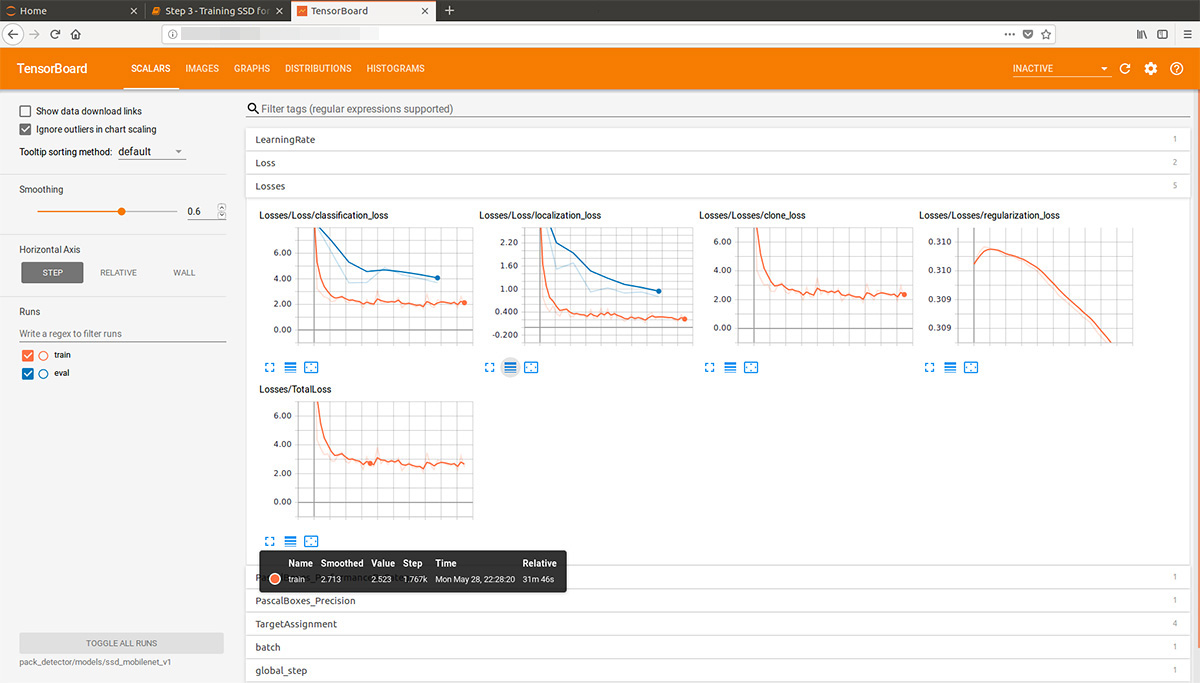
يمكن إيقاف عملية التدريب واستئنافها في أي وقت. عندما نعتقد أن النموذج جيد بما فيه الكفاية ، فإننا نحفظ نقطة التفتيش في شكل رسم بياني استدلال:
python3 export_inference_graph.py \ --input_type image_tensor \ --pipeline_config_path pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config \ --trained_checkpoint_prefix pack_detector/models/ssd_mobilenet_v1/train/model.ckpt-13756 \ --output_directory pack_detector/models/ssd_mobilenet_v1/pack_detector_2018_06_03
لذا ، في هذه الخطوة ، حصلنا على رسم بياني للاستدلال ، والذي يمكننا استخدامه للبحث عن كائنات الحزم. نحن نمر لاستخدامه.
الخطوة 4. تنفيذ البحث ( رابط جيثب )يوجد رمز الرسم البياني للاستدلال وتهيئة التهيئة على الرابط أعلاه. ميزات البحث الرئيسية:
تعثر الوظيفة على مربعات مقيدة للحزم ليس في الصورة بأكملها ، ولكن من جانبها. تقوم الوظيفة أيضًا بتصفية المستطيلات التي تم العثور عليها بدرجة كشف منخفضة محددة في معلمة القطع.
وتبين أنها معضلة. من ناحية ، مع قطع عالي نفقد الكثير من الأشياء ، من ناحية أخرى ، مع قطع منخفض ، نبدأ في العثور على العديد من الأشياء التي ليست حزم. في الوقت نفسه ، ما زلنا لا نجد كل شيء وليس من الناحية المثالية:

ومع ذلك ، لاحظ أنه إذا قمنا بتشغيل الوظيفة لقطعة صغيرة من الصورة ، فإن التعرف يكون شبه مثالي مع القطع = 0.9:

ويرجع ذلك إلى حقيقة أن طراز MobileNet V1 SSD يقبل الصور 300x300 كمدخلات. بطبيعة الحال ، مع هذا الضغط يتم فقدان الكثير من العلامات.
لكن هذه العلامات تستمر إذا قطعنا مربعًا صغيرًا يحتوي على عدة عبوات. يقترح هذا فكرة استخدام نافذة عائمة: نمر عبر مستطيل صغير في صورة ونتذكر كل ما وجدناه.

: , . . : (detection score), , , overlapTresh ( ):
:

:

, , .
الخلاصة
«»: , . , , .. .
, , :
- 150 , , ,
- 3-7 ,
- 100 ,
- ,
- (),
- (, ),
- , «»,
- , , (SSD ),
- , ,
- .
, , .