 كيف يمكن أن تتعلم ترجمة الذكاء الاصطناعي لتوليد صور القطط
كيف يمكن أن تتعلم ترجمة الذكاء الاصطناعي لتوليد صور القطط .
كان بحث شبكات الخصومة التوليدية (GAN) المنشور في عام 2014 إنجازًا كبيرًا في مجال النماذج التوليدية. ووصف الباحث الرائد يان ليكون شبكات الخصومة بأنها "أفضل فكرة في التعلم الآلي على مدار العشرين عامًا الماضية". اليوم ، بفضل هذه الهندسة المعمارية ، يمكننا إنشاء ذكاء اصطناعي يولد صورًا واقعية للقطط. رائع!
 DCGAN أثناء التدريب
DCGAN أثناء التدريبكل كود العمل موجود في
مستودع جيثب . سيكون من المفيد لك إذا كان لديك أي خبرة في برمجة Python والتعلم العميق والعمل مع Tensorflow والشبكات العصبية التلافيفية.
وإذا كنت جديدًا في التعلم العميق ، فإنني أوصيك بأن تتعرف على سلسلة المقالات الممتازة من
التعلم الآلي أمر ممتع!ما هو DCGAN؟
الشبكات العكسية التوليفية العميقة (DCGAN) هي بنية تعلم عميقة تولد بيانات مشابهة للبيانات من مجموعة التدريب.
يستبدل هذا النموذج بالطبقات التلافيفية الطبقات المتصلة بالكامل لشبكة الخصومة التوليدية. لفهم كيفية عمل DCGAN ، نستخدم استعارة المواجهة بين ناقد فني خبير ومزور.
يحاول المزور ("المولد") إنشاء صورة Van Gogh مزيفة وتمريرها كصورة حقيقية.
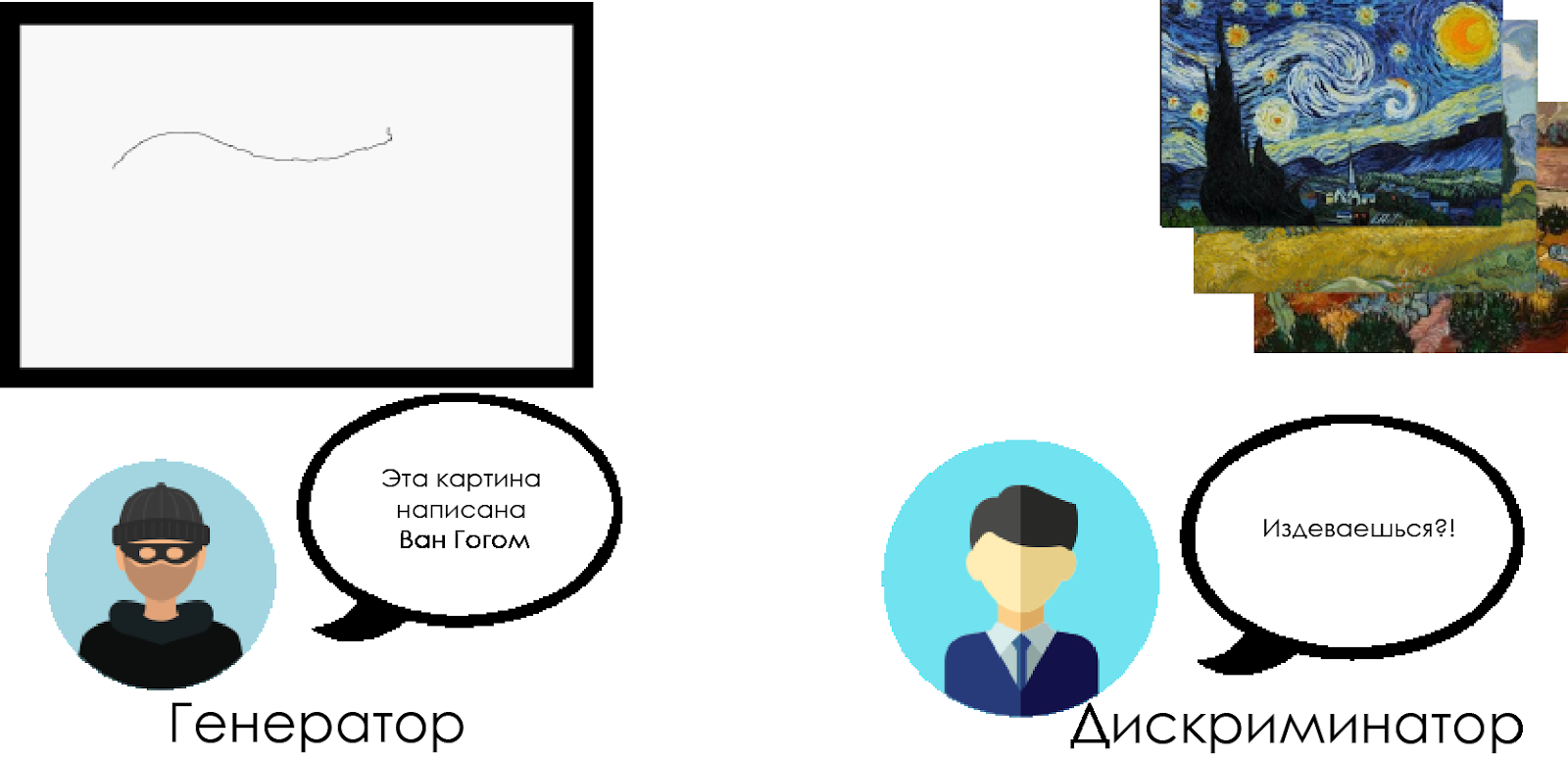
يحاول ناقد فني ("تمييز") إدانة مزور ، باستخدام معرفته باللوحات الحقيقية لفان جوخ.
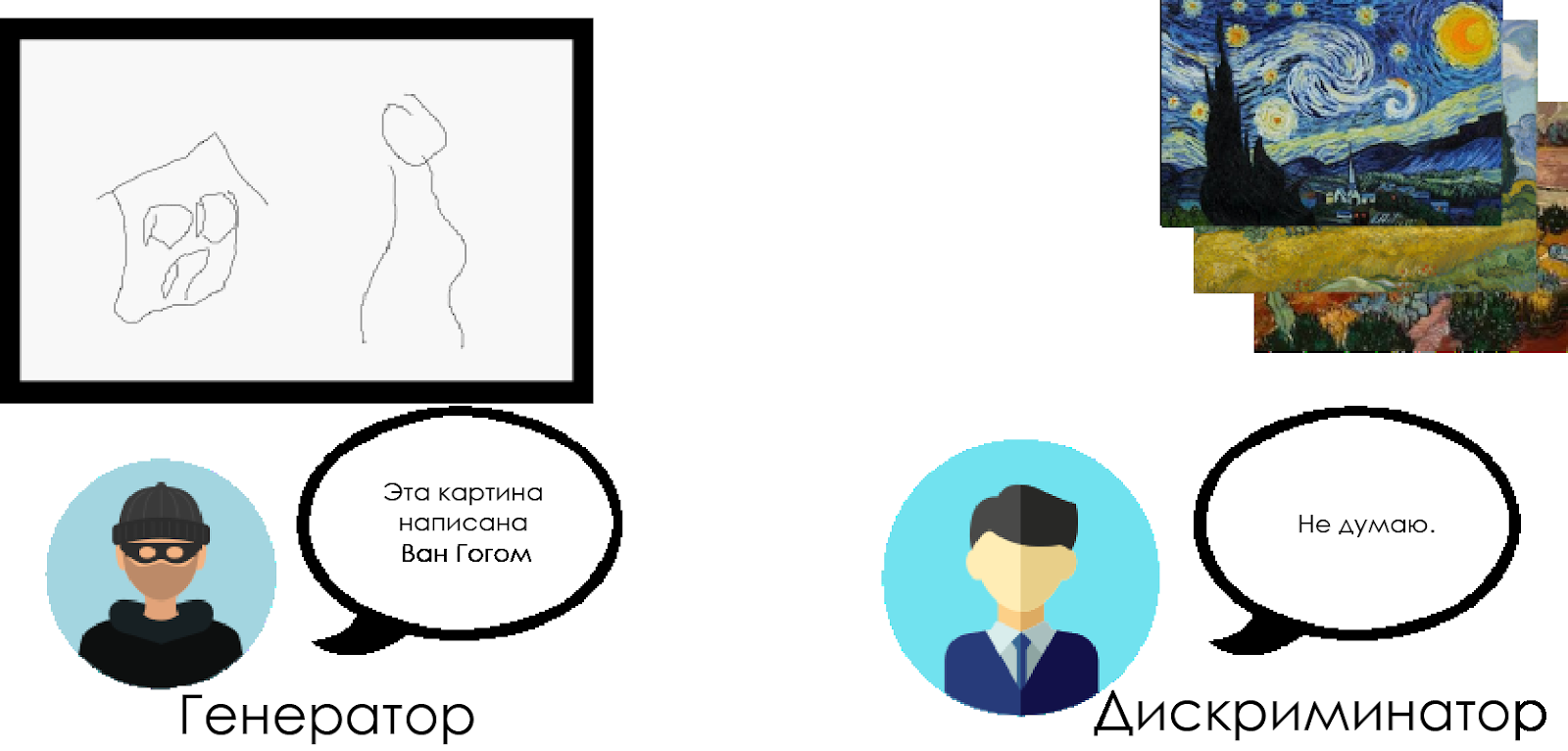
مع مرور الوقت ، يقوم الناقد الفني بتعريف المنتجات المقلدة بشكل متزايد ، ويجعلها مُزَوِّجًا أكثر مثالية.
 كما ترون ، تتكون DCGANs من شبكتين عصبيتين منفصلتين للتعلم العميق تتنافس مع بعضها البعض.
كما ترون ، تتكون DCGANs من شبكتين عصبيتين منفصلتين للتعلم العميق تتنافس مع بعضها البعض.- يحاول المولد إنشاء بيانات يمكن تصديقها. لا يعرف ما هي البيانات الحقيقية ، لكنه يتعلم من استجابات الشبكة العصبية المعادية ، ويغير نتائج عمله مع كل تكرار.
- يحاول المميّز تحديد البيانات المزيفة (مقارنة بالبيانات الحقيقية) ، وتجنب الإيجابيات الزائفة بقدر الإمكان فيما يتعلق بالبيانات الحقيقية. نتيجة هذا النموذج هي ردود الفعل للمولد.
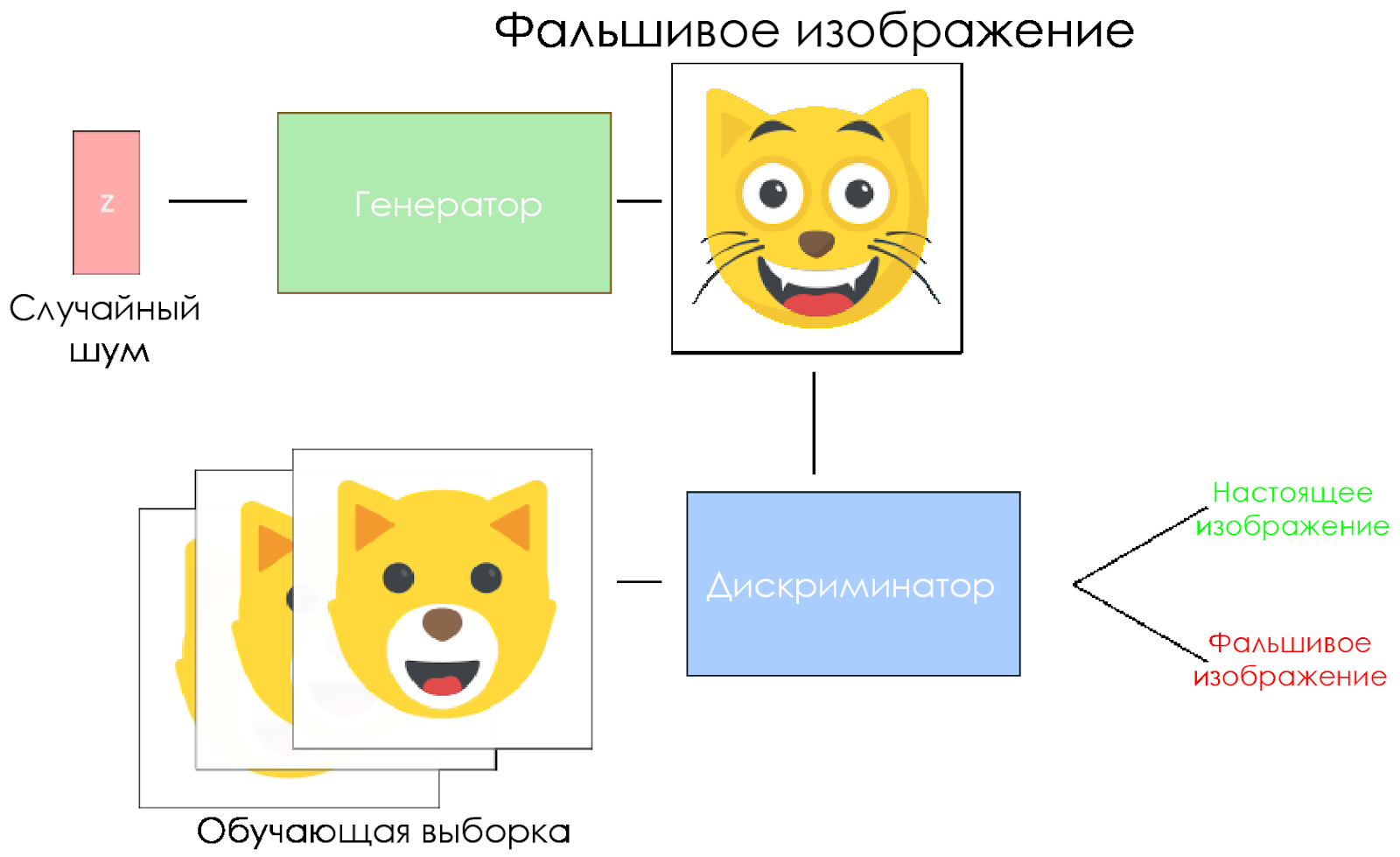 مخطط DCGAN.
مخطط DCGAN.- يأخذ المولد متجهًا عشوائيًا للضوضاء ويقوم بإنشاء صورة.
- الصورة تعطى للمميز ويقارنها بعينة التدريب.
- يقوم المميّز بإرجاع رقم - 0 (مزيف) أو 1 (صورة حقيقية).
دعونا ننشئ DCGAN!
الآن نحن على استعداد لإنشاء الذكاء الاصطناعي الخاص بنا.
في هذا الجزء ، سنركز على المكونات الرئيسية لنموذجنا. إذا كنت تريد رؤية الرمز بالكامل ، فانتقل إلى
هنا .
بيانات الإدخال
إنشاء بذرة للمدخلات:
inputs_real و
inputs_z للمولد. يرجى ملاحظة أنه سيكون لدينا معدلين للتعلم ، بشكل منفصل للمولد والمميز.
تعد وحدات تحكم المجال DCGAN حساسة جدًا للمعلمات المفرطة ، لذا من المهم جدًا ضبطها.
def model_inputs(real_dim, z_dim): """ Create the model inputs :param real_dim: tuple containing width, height and channels :param z_dim: The dimension of Z :return: Tuple of (tensor of real input images, tensor of z data, learning rate G, learning rate D) """
تمييز ومولد
نستخدم
tf.variable_scope لسببين.
أولاً ، للتأكد من أن جميع الأسماء المتغيرة تبدأ بالمولد / المميّز. وسيساعدنا ذلك لاحقًا في تدريب شبكتين عصبيتين.
ثانيًا ، سنعيد استخدام هذه الشبكات ببيانات إدخال مختلفة:
- سوف ندرب المولد ، ثم نأخذ عينة من الصور الناتجة عنه.
- في المتميز ، سنشارك المتغيرات لصور الإدخال المزيفة والحقيقية.

لنقم بإنشاء تمييز. تذكر أنه كمدخل ، فإنه يأخذ صورة حقيقية أو مزيفة ويعيد 0 أو 1 استجابة.
بعض الملاحظات:
- نحتاج إلى مضاعفة حجم المرشح في كل طبقة تلافيفية.
- لا ينصح باستخدام الاختزال. بدلاً من ذلك ، يمكن تطبيق الطبقات التلافيفية المجردة فقط.
- في كل طبقة ، نستخدم تسوية الدفعة (باستثناء طبقة الإدخال) ، لأن هذا يقلل من تحول التباين. اقرأ المزيد في هذا المقال الرائع .
- سنستخدم Leaky ReLU كدالة تنشيط ، وهذا سيساعد على تجنب تأثير التدهور "المختفي".
def discriminator(x, is_reuse=False, alpha = 0.2): ''' Build the discriminator network. Arguments --------- x : Input tensor for the discriminator n_units: Number of units in hidden layer reuse : Reuse the variables with tf.variable_scope alpha : leak parameter for leaky ReLU Returns ------- out, logits: ''' with tf.variable_scope("discriminator", reuse = is_reuse):
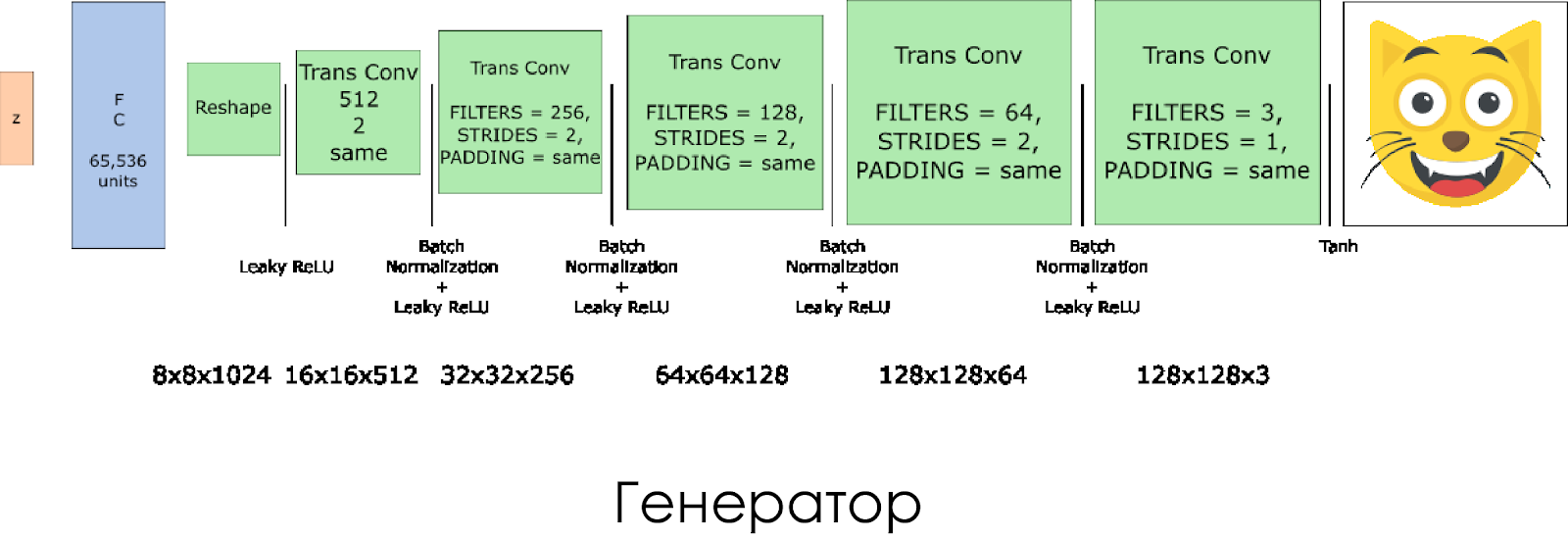
لقد أنشأنا مولد. تذكر أنه يأخذ ناقل الضوضاء (z) كمدخل ، وبفضل طبقات الالتفاف المنقولة ، يخلق صورة مزيفة.
في كل طبقة ، نخفض حجم المرشح إلى النصف ، ونضاعف أيضًا حجم الصورة.
يعمل المولد بشكل أفضل عند استخدام
tanh كوظيفة تنشيط الإخراج.
def generator(z, output_channel_dim, is_train=True): ''' Build the generator network. Arguments --------- z : Input tensor for the generator output_channel_dim : Shape of the generator output n_units : Number of units in hidden layer reuse : Reuse the variables with tf.variable_scope alpha : leak parameter for leaky ReLU Returns ------- out: ''' with tf.variable_scope("generator", reuse= not is_train):
خسائر في المولد و المولد
نظرًا لأننا ندرب كلاً من المولد والمميز ، فإننا بحاجة إلى حساب الخسائر لكل من الشبكات العصبية. يجب أن يمنح المميّز 1 عندما "تعتبر" الصورة حقيقية ، و 0 إذا كانت الصورة مزيفة. وفقًا لهذا وتحتاج إلى تكوين الخسارة. تُحسب خسارة التمييز على أنها مجموع الخسائر للصورة الحقيقية والمزيفة:
d_loss = d_loss_real + d_loss_fakeحيث
d_loss_real هي الخسارة عندما يعتبر
d_loss_real الصورة كاذبة ، لكنها في الواقع حقيقية. تحسب على النحو التالي:
- نستخدم
d_logits_real ، جميع التصنيفات تساوي 1 (لأن جميع البيانات حقيقية). labels = tf.ones_like(tensor) * (1 - smooth) . دعنا نستخدم تجانس الملصق: خفض قيم الملصق من 1.0 إلى 0.9 لمساعدة المتميز على التعميم بشكل أفضل.
d_loss_fake خسارة عندما يعتبر
d_loss_fake الصورة حقيقية ، لكنها في الواقع مزيفة.
- نستخدم
d_logits_fake ، جميع التصنيفات هي 0.
لفقد المولد ، يتم استخدام
d_logits_fake من التمييز. هذه المرة ، جميع التسميات هي 1 ، لأن المولد يريد خداع المميّز.
def model_loss(input_real, input_z, output_channel_dim, alpha): """ Get the loss for the discriminator and generator :param input_real: Images from the real dataset :param input_z: Z input :param out_channel_dim: The number of channels in the output image :return: A tuple of (discriminator loss, generator loss) """
محسنات
بعد حساب الخسائر ، يجب تحديث المولد والمميز بشكل فردي. للقيام بذلك ، استخدم
tf.trainable_variables() لإنشاء قائمة بجميع المتغيرات المحددة في الرسم البياني الخاص بنا.
def model_optimizers(d_loss, g_loss, lr_D, lr_G, beta1): """ Get optimization operations :param d_loss: Discriminator loss Tensor :param g_loss: Generator loss Tensor :param learning_rate: Learning Rate Placeholder :param beta1: The exponential decay rate for the 1st moment in the optimizer :return: A tuple of (discriminator training operation, generator training operation) """
تدريب
الآن نقوم بتنفيذ وظيفة التدريب. الفكرة بسيطة جدًا:
- نحفظ نموذجنا كل خمس فترات (حقبة).
- نقوم بحفظ الصورة في المجلد مع الصور كل 10 دفعات مدربة.
- كل 15 فترة نقوم بعرض
g_loss و d_loss والصورة المولدة. وذلك لأن Jupyter قد يتعطل عند عرض عدد كبير جدًا من الصور. - أو يمكننا إنشاء صور حقيقية مباشرة عن طريق تحميل نموذج محفوظ (سيوفر هذا 20 ساعة من التدريب).
def train(epoch_count, batch_size, z_dim, learning_rate_D, learning_rate_G, beta1, get_batches, data_shape, data_image_mode, alpha): """ Train the GAN :param epoch_count: Number of epochs :param batch_size: Batch Size :param z_dim: Z dimension :param learning_rate: Learning Rate :param beta1: The exponential decay rate for the 1st moment in the optimizer :param get_batches: Function to get batches :param data_shape: Shape of the data :param data_image_mode: The image mode to use for images ("RGB" or "L") """
كيف تركض
يمكن تشغيل كل هذا مباشرة على جهاز الكمبيوتر الخاص بك إذا كنت على استعداد للانتظار لمدة 10 سنوات. لذا من الأفضل استخدام خدمات GPU المستندة إلى السحابة مثل AWS أو FloydHub. أنا شخصياً قمت بتدريب هذا DCGAN لمدة 20 ساعة على Microsoft Azure وآلتهم
الافتراضية للتعلم العميق . ليس لدي علاقة عمل مع Azure ، فأنا أحب خدمة العملاء.
إذا واجهتك أي صعوبات في التشغيل في جهاز افتراضي ، فراجع هذه
المقالة الرائعة.
إذا قمت بتحسين النموذج ، فلا تتردد في تقديم طلب سحب.
