مقدمة
إن تطبيق PHP trie الموصوف هنا يجعل القاموس سمينًا جدًا حتى الآن ، والذي يستغرق وقتًا طويلاً للتحميل في الذاكرة ، مما يزيل السرعة الجيدة لعمله. سرعة البحث حوالي 80 ألف كلمة في الثانية. القاموس مصنوع من قائمة lemmas من قاموس opencorpora.org ويتضمن 389844 كلمة. في شكل غير مضغوط ، يزن القاموس ~ 150mb ، و gzip مضغوط ~ 6mb. ومع ذلك ، تثبت نتائج الأداء الجيد أنه في PHP النقي يمكنك إنشاء شجرة بادئة trie تعمل بكامل طاقتها.
أطلب من المبرمجين مقدما مع أقوال النقاد الأدبيين ألا يكتبوا تعليقات خبيثة. يجب أن تكون هذه المقالة مثيرة للاهتمام بالنسبة للمبتدئين ، كما أنا نفسي. كسول جدا للقراءة ، يمكنك أن ترى على الفور رمز على
جيثب .
كيف بدأ كل شيء
منذ فترة طويلة وأنا أتحدث عن فكرة كتابة محلل صرفي لمشاريع PHP الخاصة بي ، والتي ستكون قادرة على إجراء تحليل صرفي لكلمات معينة بسرعة ، بالإضافة إلى تحويل الكلمات إلى الشكل الصرفي المطلوب.
PHP لديها بالفعل مكتبة مماثلة تسمى phpmorhy. إنه يعمل بسرعة كبيرة وسأستخدمه ولن أخترع أي شيء ، ولكن مترجم القاموس فيه مصنوع كتطبيق منفصل غير PHP ، مما يجعل من المستحيل بالنسبة لي استخدام هذه المكتبة. تم بناء المكتبة نفسها على أساس قاموس AOT الذي طال انتظاره ، والذي يقلل من فائدته.
مرت أسابيع وشهور ، قرأت
مقالاً بقلم خابروفشانين ، ثم
مقالة بقلم إ. سيغالوفيتش حول خوارزمية صرفية سريعة لمحرك بحث ، ثم مجموعة من المقالات المختلفة.
لقد نضجت شيئًا فشيئًا لكتابة
lunapark الخاص
بي مع لعبة ورق وعظام محلل صرفي. أعتقد: "
حسنًا ، تقدم التقدم إلى الأمام ، في PHP يمكنك بالفعل تحليل الجينوم البشري! "
أخذت قاموس opencorpora.org ، ووضعته في الخلية وحصلت على سرعة بحث تبلغ 2000 كلمة في الثانية. أعتقد أنه من الضروري تحميل القاموس في الذاكرة. وهنا اتضح أنه من أجل توفير هياكل بيانات منتظمة في PHP مثل مصفوفة أو كائن ، تحتاج إلى تخزين حوالي 3 غيغابايت من ذاكرة الوصول العشوائي لقاموس 3 ملايين. كانت جميع تطبيقات php trie التي صادفتها مناسبة فقط كبرنامج تعليمي لإثبات منطق العمل ، نظرًا لأنها بنيت بنفسها على هياكل تخزين بيانات PHP الأصلية.
جهاز تخزين القاموس ومبدأ التشغيل
أينما تمكنت من قراءة شجرة البادئة trie أو الاستماع إليها أو النظر إليها ، لم يتم شرح كيفية تخزين البيانات في الذاكرة بالضبط. هنا لدينا العقدة ، وهنا ورثتها ، وهنا علم نهاية الكلمة ، التي لا تظهر تحت غطاء المحرك. لذلك ، كان عليّ اختراع طريقة تخزين بنفسي.
كما تعلم ، تتكون شجرة بادئة trie من العقد. تخزن العقدة بادئة ، روابط إلى العقد اللاحقة (أحفاد) ، ومؤشر لحقيقة أن هذه البادئة هي الأخيرة في السلسلة. يقول الهندي بشكل واضح جدا عن تري.
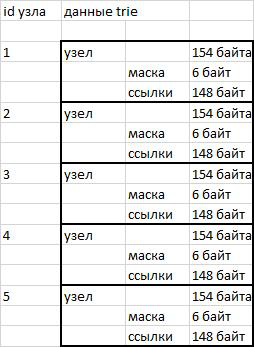
العقد في تنفيذ trie بلدي كتل البيانات بطول ثابت 154 بايت. أول 6 بايت (48 بت) تحتوي على قناع البت للورثة. أول 46 بت هي الأبجدية الروسية والأرقام وعلامة الاقتباس والواصلة والفاصلة العليا. تمت إضافة الفاصلة العليا لأنه في قاموس opencorpora.org توجد كلمة "cote d'ivoire" ، والتي تستخدم علامة الفاصلة العليا. يتم استخدام البت 47th لتخزين علامة نهاية الكلمة. تُستخدم وحدات البايت التالية البالغ عددها 148 بايت بعد قناع البت لتخزين المراجع لورثة العقدة. 3 بايت لكل حرف (46 * 3 = 148).
يتم تخزين العقد كبيانات ثنائية في سلسلة. يتم الوصول إلى القسم المطلوب باستخدام وظيفة substr () وفك الحزم التالي ().
يبسط استخدام العقد ذات الطول الثابت عملية العنونة. للتبديل إلى العقدة المطلوبة ، يكفي معرفة الرقم التسلسلي (id) وطول العقدة. نضرب الرقم التسلسلي بالطول ونكتشف الإزاحة بالنسبة لبداية السطر - كل شيء بسيط للغاية.
التين. 1 نظام التخزين
المساوئ
يعمل نظام التخزين المستخدم على تبسيط العنونة ، ولكنه يستهلك مساحة. يتطلب تخزين 380 ألف كلمة ما يزيد قليلاً عن مليون عقد. 154 بايت * 1،000،000 عقد = 146.86 ميجابايت. على سبيل المثال 400 بايت تقريبًا لكل كلمة. إذا قمت بكتابة كلمات في ملف نصي بسيط تم ترميزه في utf8 ، فإن هذه الكلمات نفسها التي يصل عددها إلى 380 ألف كلمة يمكن أن تتناسب مع 16 ميغابايت.
الخطط
لاستخدام الذاكرة بشكل أكثر عقلانية ، أريد التبديل إلى طول متغير للعقد ، ثم كحلقة وصل ، ليس علي تسجيل معرف العقدة ، ولكن موقعه بالبايت. سيتم تحديد موقع الارتباط إلى العقدة المطلوبة على النحو التالي. على مثال كلمة "abv".
الحرف "a" هو الأول في الأبجدية ، وبالتالي فإن العقدة هي أيضًا الأولى على التوالي ، الإزاحة 0. اقرأ 6 بايت ، بدءًا من 0.
$str = substr($dic, 0, 6);
فك الخط:
$mask = (ord($str[5]) << 40) + (ord($str[4]) << 32) + (ord($str[3]) << 24) + (ord($str[2]) << 16) + (ord($str[1]) << 8) + ord($str[0]);
ننظر إلى قناع البت الثاني (الحرف "b")
bit_get($mask, 2);
تم تعيين البت ، والآن نحسب عدد البتات المرفوعة في القناع إلى 2. دعنا نقول أن البت "a" من العقدة الخاصة بنا مرفوعة أيضًا ، لذا فإن جزئنا من الحرف "b" سيكون البت الثاني مرفوعًا. عد العد لقراءة الرابط
$offset = 6 + 3;
قناع 6 بايت + 3 بايت ، والذي يشغله الرابط الأول ، يتحول إلى 9 بايت. نقرأ القطعة المرغوبة.
$str = substr($dic, $offset, 3);
فك الارتباط:
$ref = (ord($str[2]) << 16) + (ord($str[1]) << 8) + ord($str[0]);
انتقل إلى العقدة التالية وكرر كل شيء مرة أخرى. في الحرف الأخير ، نتحقق من وجود 47 بت في القناع ، إذا تم تعيينه ، فهناك كلمة بحث في trie الخاص بنا.
آمل أن يكون من الممكن الحفاظ على سرعة لا تقل عن 50 ألف كلمة في الثانية.
شكر وتقدير
أود أن أشكر المشاركين في المنتدى nulled.cc و php.ru على مساعدتهم في وظائف bitwise.