هذا
الخبر (+
البحث ) حول اختراع مولد الميمي من قبل علماء من جامعة ستانفورد دفعني إلى كتابة مقال. في مقالتي ، سأحاول أن أثبت أنك لست بحاجة إلى أن تكون عالمًا في ستانفورد من أجل القيام بأشياء مثيرة للاهتمام مع الشبكات العصبية. في المقالة ، أصف كيف قمنا في عام 2017 بتدريب شبكة عصبية على جسم يحتوي على ما يقرب من 30000 نص وأجبروها على إنشاء ميمات وميمات إنترنت جديدة (علامات اتصال) بالمعنى الاجتماعي للكلمة. نحن نصف خوارزمية التعلم الآلي التي استخدمناها ، والصعوبات الفنية والإدارية التي واجهناها.
خلفية صغيرة عن كيفية وصولنا إلى فكرة الكاتب العصبي وما الذي تتكون منه بالضبط. في عام 2017 ، قمنا بعمل مشروع لموقع فكونتاكتي العام ، وهو الاسم ولقطات الشاشة التي منعها مشرفو Habrahabr للنشر ، معتبرا ذكرها على أنها علاقات عامة "ذاتية". الجمهور موجود منذ عام 2013 ويوحد المشاركات مع الفكرة العامة لتحليل النكتة من خلال خط وفصل الخطوط برمز "@":
@
@
يمكن أن يختلف عدد الخطوط ، يمكن أن تكون المؤامرة أي. في معظم الأحيان ، هذه هي الفكاهة أو الملاحظات الاجتماعية الحادة حول حقائق الواقع المتفشية. بشكل عام ، يسمى هذا التصميم "buhurt".
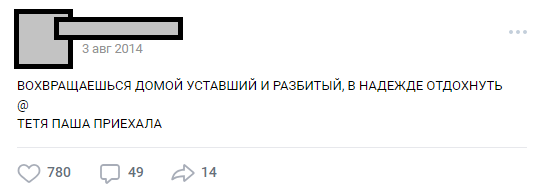 واحدة من buhurts نموذجية
واحدة من buhurts نموذجيةعلى مر السنين ، نما الجمهور إلى تقاليد داخلية (الشخصيات ، المؤامرات ، المواقع) ، وتجاوز عدد المشاركات 30،000. في وقت تحليلهم لاحتياجات المشروع ، تجاوز عدد سطور المصدر للنص نصف مليون.
الجزء 0. ظهور الأفكار والفرق
في أعقاب الشعبية الكبيرة للشبكات العصبية ، كانت فكرة تدريب ANN على نصوصنا في الهواء لمدة ستة أشهر ، ولكن تمت صياغتها في النهاية باستخدام E7su في ديسمبر 2016. وفي نفس الوقت ، تم اختراع الاسم ("Neurobugurt"). في ذلك الوقت ، كان الفريق المهتم بالمشروع يتألف من ثلاثة أشخاص فقط. كنا جميعًا طلابًا بدون خبرة عملية في الخوارزميات والشبكات العصبية. الأسوأ من ذلك ، لم يكن لدينا حتى GPU واحد مناسب للتدريب. كل ما كان لدينا هو الحماس والثقة بأن هذه القصة يمكن أن تكون مثيرة للاهتمام.
الجزء 1. صياغة الفرضية والمهام
تحولت فرضيتنا إلى افتراض أنه إذا مزجت جميع النصوص المنشورة على مدى ثلاث سنوات ونصف ودربت الشبكة العصبية على هذا المبنى ، يمكنك الحصول على:
أ) أكثر إبداعًا من الناس
ب) مضحك
حتى إذا اتضح أن الكلمات أو الأحرف في buhurt يتم الخلط بينها وترتيبها عشوائيًا - نعتقد أن هذا يمكن أن يعمل كخدمة المعجبين وسيظل يرضي القراء.
تم تبسيط المهمة إلى حد كبير من خلال حقيقة أن تنسيق buhurts هو في الأساس نصية. لذا ، لم نكن بحاجة إلى الغوص في رؤية الماكينة وغيرها من الأشياء المعقدة. الخبر السار الآخر هو أن النص بأكمله متشابه للغاية. هذا جعل من الممكن عدم استخدام التعلم المعزز - على الأقل في المراحل المبكرة. في الوقت نفسه ، فهمنا بوضوح أن إنشاء كاتب شبكة عصبية بمخرجات قابلة للقراءة أكثر من مرة ليس بهذه السهولة. كان خطر ولادة الوحش الذي سيرسل الرسائل بشكل عشوائي كبيرًا جدًا.
الجزء 2. إعداد مجموعة النصوص
ويعتقد أن مرحلة التحضير يمكن أن تستغرق وقتًا طويلاً جدًا ، لأنها مرتبطة بجمع وتنظيف البيانات. في حالتنا ، تبين أنها قصيرة نوعًا ما: تم كتابة
محلل صغير ضخ حوالي 30 ألف مشاركة من حائط المجتمع ووضعها في
ملف txt .
لم نقم بمسح البيانات قبل التدريب الأول. في المستقبل ، لعب هذا نكتة قاسية معنا ، بسبب الخطأ الذي تسلل في هذه المرحلة ، لم نتمكن من إحضار النتائج إلى شكل قابل للقراءة لفترة طويلة. لكن المزيد عن ذلك لاحقًا.
 ملف الشاشة مع البرغر
ملف الشاشة مع البرغرالجزء 3. الإعلان ، وصقل الفرضية ، واختيار الخوارزمية
استخدمنا موردًا يمكن الوصول إليه - عددًا كبيرًا من المشتركين العامين. كان الافتراض أنه من بين 300.000 قارئ ، هناك العديد من المتحمسين الذين يمتلكون شبكات عصبية بمستوى كافٍ لملء الفجوات في معرفة فريقنا. بدأنا من فكرة الإعلان عن المنافسة على نطاق واسع وجذب عشاق التعلم الآلي إلى مناقشة المشكلة المصاغة. بعد كتابة النصوص ، أخبرنا الناس عن فكرتنا وأملنا في الرد.
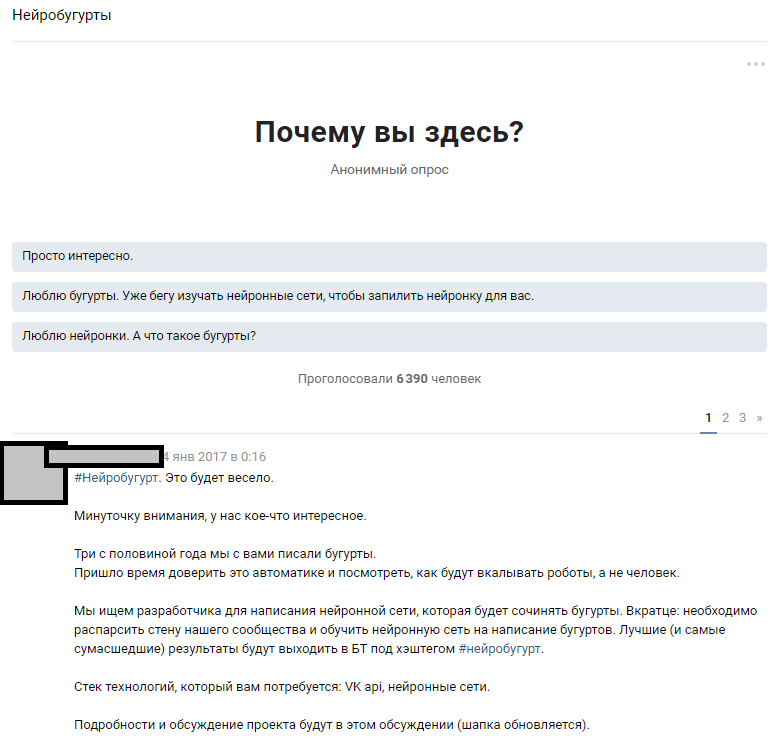 إعلان مناقشة مواضيعية
إعلان مناقشة مواضيعيةتجاوز رد فعل الناس توقعاتنا الجامحة. مناقشة حقيقة أننا سوف نقوم بتدريب شبكة عصبية تنشر المعبد بحوالي 1000 تعليق. تلاشى معظم القراء وحاولوا أن يتخيلوا كيف ستكون النتيجة. شارك حوالي 6000 شخص في المناقشة المواضيعية ، وترك أكثر من 50 هواة مهتمين تعليقات
أعطيناها مجموعة اختبار مكونة من
814 خطًا بحريًا لإجراء الاختبارات الأولية والتدريب. يمكن لكل شخص مهتم أخذ مجموعة بيانات وتعلم الخوارزمية الأكثر إثارة للاهتمام بالنسبة له ، ثم مناقشتها معنا ومع المتحمسين الآخرين. أعلنا مسبقًا أننا سنواصل العمل مع المشاركين الذين ستكون نتائجهم قابلة للقراءة.
بدأ العمل: قام شخص ما بتجميع مولد بصمت على سلاسل ماركوف ، وجرب شخص عمليات تنفيذ مختلفة مع جيثوب ، وأصاب معظمهم بالجنون في المناقشة وأقنعنا بالرغوة في الفم أنه لن يأتي شيء منها. بدأ هذا الجزء الفني من المشروع.
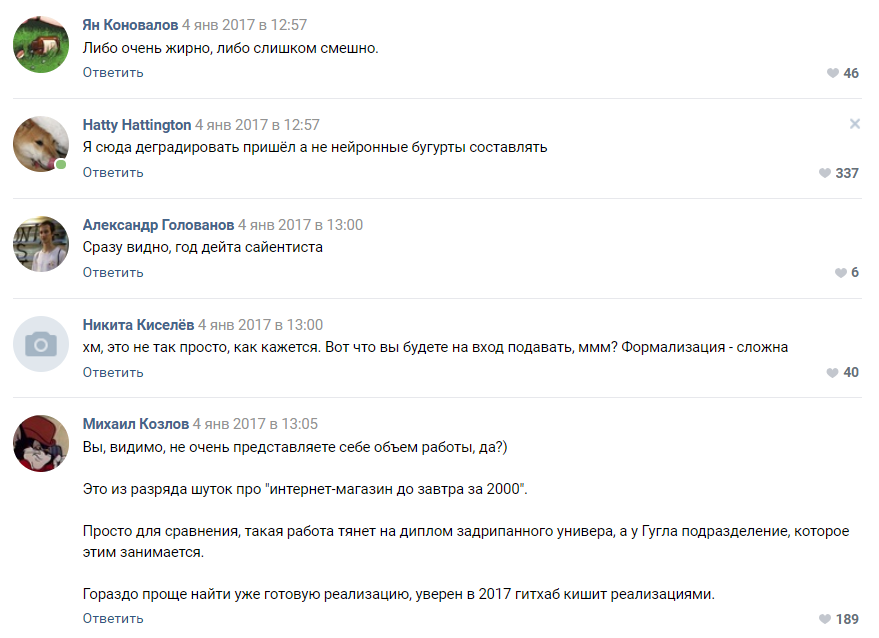
بعض الاقتراحات من قبل المتحمسين
عرض الناس العشرات من الخيارات للتنفيذ:
- سلاسل ماركوف.
- ابحث عن تنفيذ جاهز لشيء مشابه لـ GitHub وقم بتدريبه.
- مولد عبارة عشوائي مكتوب بلغة باسكال.
- احصل على نيغرو أدبي سيكتب هراء عشوائيًا ، وسنقوم بتمرير ذلك كمخرج للشبكة العصبية.
 تقييم مدى تعقيد المشروع من أحد المشتركين
تقييم مدى تعقيد المشروع من أحد المشتركيناتفق معظم المعلقين على أن مشروعنا محكوم عليه بالفشل ولن نصل حتى إلى مرحلة النموذج الأولي. كما فهمنا لاحقًا ، لا يزال الناس يميلون إلى اعتبار الشبكات العصبية نوعًا من السحر الأسود الذي يحدث في "رأس زوكربيرج" والانقسامات السرية في Google.
الجزء 4. اختيار الخوارزميات ، والتدريب وتوسيع الفريق
بعد مرور بعض الوقت ، بدأت الحملة التي أطلقناها لأفكار التعهيد الجماعي للخوارزمية تؤتي ثمارها الأولى. حصلنا على حوالي 30 نموذجًا أوليًا عاملاً ، معظمها قدم هراء غير قابل للقراءة تمامًا.
في هذه المرحلة ، واجهنا أولاً انخفاض مستوى الفريق. كانت جميع النتائج متشابهة بشكل ضعيف جدًا مع buhurts وغالباً ما كانت تمثل abracadabra من الحروف والرموز. ذهب عمل عشرات من المتحمسين إلى التراب وهذا أدى إلى إحباطهم وهم.
أظهرت الخوارزمية القائمة على pyTorch نفسها أفضل من غيرها. تقرر اتخاذ هذا التنفيذ وخوارزمية LSTM كأساس. تعرّفنا على المشترك الذي اقترحها كفائز وبدأنا في العمل على تحسين الخوارزمية معه. لقد نما فريقنا الموزع إلى أربعة أشخاص. الحقيقة المضحكة هنا هي أن
الفائز في المسابقة ، كما اتضح ، كان عمره 16 عامًا فقط. كان الفوز هو أول جائزة حقيقية له في مجال علوم البيانات.
بالنسبة للتدريب الأول ، تم استئجار مجموعة من 8 بطاقات رسومية GXT1080.
 وحدة تحكم إدارة مجموعة البطاقة
وحدة تحكم إدارة مجموعة البطاقةالمستودع الأصلي وجميع أدلة مشروع Torch-rnn هنا:
github.com/jcjohnson/torch-rnn . في وقت لاحق ، وعلى أساسها ، قمنا بنشر
مستودعنا ، حيث توجد مصادرنا ، ReadMe للتثبيت ، وكذلك البكتريا العصبية النهائية نفسها.
تدربنا في المرات القليلة الأولى باستخدام تكوين مهيأ مسبقًا على مجموعة GPU مدفوعة. تبين أن إعداده ليس صعبًا - يكفي فقط تعليمات مطور Torch والمساعدة من إدارة الاستضافة ، المضمنة في الدفع.
ومع ذلك ، واجهنا بسرعة كبيرة صعوبة: كل تدريب يكلف وقت استئجار GPU - مما يعني أنه لم يكن هناك أموال في المشروع. وبسبب هذا ، في يناير وفبراير 2017 ، أجرينا تدريبًا في المرافق التي تم شراؤها ، وحاولنا إطلاق الجيل على أجهزتنا المحلية.
أي نص مناسب للتدريب النموذجي. قبل التدريب ، تحتاج إلى معالجة مسبقة له ، حيث يمتلك Torch خوارزمية preprocess.py خاصة تحول ملف my_data.txt إلى ملفين: HDF5 و JSON:
يعمل البرنامج النصي للمعالجة على النحو التالي:
python scripts/preprocess.py \ --input_txt my_data.txt \ --output_h5 my_data.h5 \ --output_json my_data.json
 بعد المعالجة المسبقة ، يظهر ملفان يتم تدريب الشبكة العصبية عليهما في المستقبل
بعد المعالجة المسبقة ، يظهر ملفان يتم تدريب الشبكة العصبية عليهما في المستقبلالأعلام المختلفة التي يمكن تغييرها في مرحلة ما قبل المعالجة موصوفة
هنا . من الممكن أيضًا تشغيل
Torch من Docker ، لكن مؤلف المقالة لم يتحقق منه.
تدريب الشبكات العصبية
بعد المعالجة المسبقة ، يمكنك متابعة تدريب النموذج. في المجلد مع HDF5 و JSON ، تحتاج إلى تشغيل الأداة المساعدة th ، التي ظهرت معك إذا قمت بتثبيت Torch بشكل صحيح:
th train.lua -input_h5 my_data.h5 -input_json my_data.json
يستغرق التدريب قدرًا كبيرًا من الوقت ويولد ملفات من النموذج cv / checkpoint_1000.t7 ، وهي "أوزان" شبكتنا العصبية. تزن هذه الملفات كمية رائعة من الميغابايت وتحتوي على قوة الروابط بين أحرف معينة في مجموعة البيانات الأصلية.
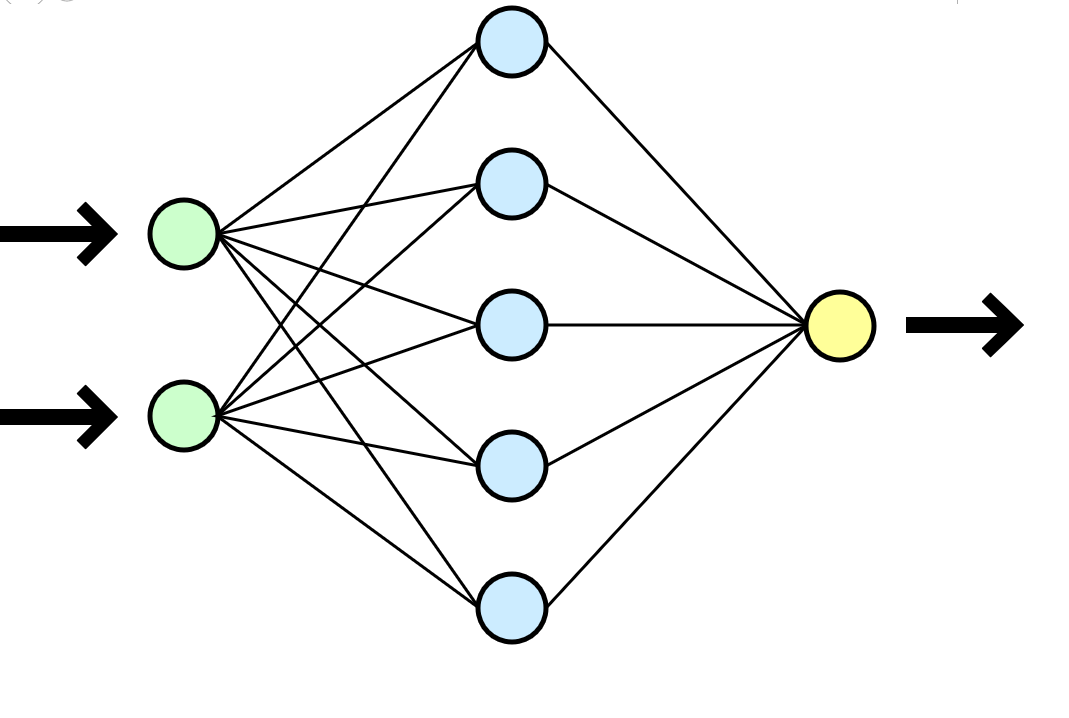 غالبًا ما تتم مقارنة الشبكة العصبية بالدماغ البشري ، ولكن يبدو لي تشابهًا أكثر وضوحًا مع وظيفة رياضية تأخذ المعلمات عند الإدخال (مجموعة البيانات الخاصة بك) وتعطي النتيجة (بيانات جديدة) عند الإخراج.
غالبًا ما تتم مقارنة الشبكة العصبية بالدماغ البشري ، ولكن يبدو لي تشابهًا أكثر وضوحًا مع وظيفة رياضية تأخذ المعلمات عند الإدخال (مجموعة البيانات الخاصة بك) وتعطي النتيجة (بيانات جديدة) عند الإخراج.في حالتنا ، استغرق كل تدريب على مجموعة من 8 GTX 1080 في مجموعة بيانات من 500000 خط حوالي ساعة أو ساعتين ، واستغرق التدريب المماثل على نوع من وحدة المعالجة المركزية i3-2120 حوالي 80-100 ساعة. في حالة التدريب الأطول ، بدأت الشبكة العصبية في التراجع الصارم - غالبًا ما تتكرر الرموز بعضها البعض ، وتقع في دورات طويلة من حروف الجر ، والعطف والكلمات التمهيدية.
من الملائم أن تتمكن من اختيار تكرار نقاط التفتيش وخلال تدريب واحد ستحصل على الفور على العديد من النماذج: من الأقل تدريبًا (checkpoint_1000) إلى إعادة التدريب (checkpoint_1000000). فقط مساحة كافية ستكون كافية.
توليد نص جديد
بعد تلقي ملف واحد جاهز على الأقل مع الأوزان (نقطة التحقق _ *******) ، يمكنك المتابعة إلى المرحلة التالية والأكثر إثارة للاهتمام: ابدأ في إنشاء النصوص. بالنسبة لنا ، كانت لحظة حقيقية من الحقيقة ، لأنه للمرة الأولى حصلنا على بعض النتائج الملموسة - حشرة مكتوبة بواسطة آلة.
عند هذه النقطة ، توقفنا أخيرًا عن استخدام المجموعة وتم تنفيذ جميع الأجيال على آلاتنا منخفضة الطاقة. ومع ذلك ، عند محاولة البدء محليًا ، لم ننجح في اتباع الإرشادات وتثبيت Torch. كان الحاجز الأول هو استخدام الأجهزة الافتراضية. في Ubuntu 16 الافتراضي ، لا تقلع العصا - انسها. غالبًا ما وصل StackOverflow إلى الإنقاذ ، ولكن بعض الأخطاء كانت غير بديهية لدرجة أنه لم يتم العثور على الإجابة إلا بصعوبة كبيرة.
أدى تثبيت Torch على جهاز محلي إلى تعطيل المشروع لبضعة أسابيع جيدة: لقد واجهنا جميع أنواع الأخطاء في تثبيت العديد من الحزم المطلوبة ، وكافحنا أيضًا مع المحاكاة الافتراضية (virtualenv .env) وفي النهاية لم نستخدمه. تم هدم الجناح عدة مرات إلى مستوى sudo rm -rf وتم تثبيته ببساطة مرة أخرى.
باستخدام الملف الناتج بالأوزان ، تمكنا من البدء في إنشاء نصوص على جهازنا المحلي:
 أحد الاستنتاجات الأولى
أحد الاستنتاجات الأولىالجزء 5. مسح النصوص
كانت هناك صعوبة واضحة أخرى تتمثل في أن موضوع المنشورات مختلف تمامًا ، وأن خوارزميتنا لا تتضمن أي قسم وتعتبر جميع 500000 سطر كنص واحد. لقد أخذنا بعين الاعتبار خيارات مختلفة لتجميع مجموعة البيانات وكاننا مستعدين حتى لكسر نص النصوص يدويًا حسب الموضوع أو وضع علامات في عدة آلاف من buhurts (كان هناك مورد بشري ضروري لهذا) ، ولكن واجهنا باستمرار صعوبات فنية في إرسال المجموعات عند تعلم LSTM. لا يبدو أن تغيير الخوارزمية وإجراء المنافسة مرة أخرى هي الفكرة الأكثر منطقية من حيث توقيت المشروع ودافع المشاركين.
يبدو أننا وصلنا إلى طريق مسدود - لم نتمكن من تجميع بوهورتس ، وأسفر التدريب على مجموعة بيانات ضخمة واحدة عن نتائج مريبة. لم أكن أرغب في الرجوع خطوة إلى الوراء وتغيير الخوارزمية والتنفيذ المرتفعين تقريبًا - يمكن أن يقع المشروع ببساطة في غيبوبة. لم يكن الفريق يائسًا بما يكفي من المعرفة لحل الموقف بشكل طبيعي ، لكن SME-KAL-OCHK-A القديم الجيد جاء إلى الإنقاذ. اتضح أن الحل النهائي للعكاز هو عبقري بسيط: في مجموعة البيانات الأصلية ، قم بفصل buhurts الموجودة عن بعضها البعض بخطوط فارغة وتدريب LSTM مرة أخرى.
رتبنا الإيقاعات في 10 مساحات رأسية بعد كل buhurt ، وكررنا التدريب ، وخلال التوليد وضعنا حدًا لحجم الإخراج البالغ 500 حرف (متوسط طول buhurt "مؤامرة" واحدة في مجموعة البيانات الأصلية).
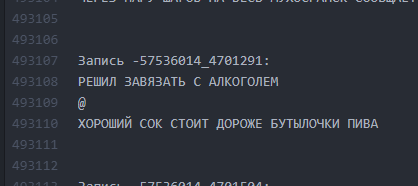 كما كان. الفترات الفاصلة بين النصوص ضئيلة.
كما كان. الفترات الفاصلة بين النصوص ضئيلة.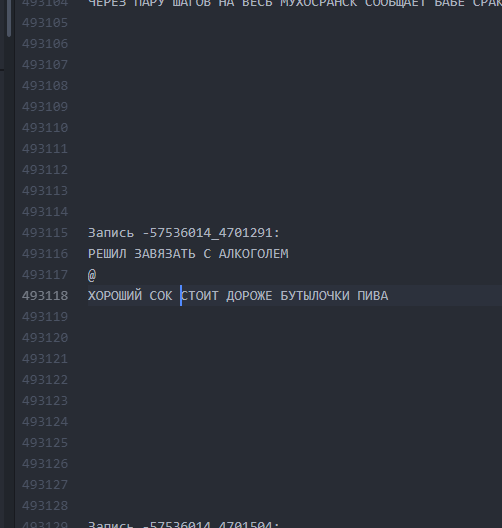 كيف أصبحت. تتيح الفواصل الزمنية لعشرة أسطر لـ LSTM "فهم" أن زباديًا واحدًا قد انتهى وبدأ آخر.
كيف أصبحت. تتيح الفواصل الزمنية لعشرة أسطر لـ LSTM "فهم" أن زباديًا واحدًا قد انتهى وبدأ آخر.وهكذا ، كان من الممكن تحقيق أن حوالي 60 ٪ من جميع buhurts المولدة بدأت في الحصول على مؤامرة قابلة للقراءة (وإن كانت في كثير من الأحيان وهمية) على طول كامل buhurt من البداية إلى النهاية. كان طول قطعة واحدة ، في المتوسط ، من 9 إلى 13 خطًا.
الجزء 6. إعادة التدريب
بعد تقدير اقتصاد المشروع ، قررنا عدم إنفاق المال على استئجار مجموعة بعد الآن ، ولكن الاستثمار في شراء بطاقاتنا الخاصة. سيزداد وقت التعلم ، ولكن بعد شراء بطاقة مرة واحدة ، يمكننا إنشاء مجموعات جديدة باستمرار. في الوقت نفسه ، لم يعد إجراء التدريب غالبًا ضروريًا.
 محاربة الإعدادات على الجهاز المحلي
محاربة الإعدادات على الجهاز المحليالجزء 7. موازنة النتائج
في مطلع مارس إلى أبريل 2017 ، أعدنا تدريب الشبكة العصبية ، مع تحديد معلمات درجة الحرارة وعدد فترات التدريب. ونتيجة لذلك ، زادت جودة المخرجات بشكل طفيف.
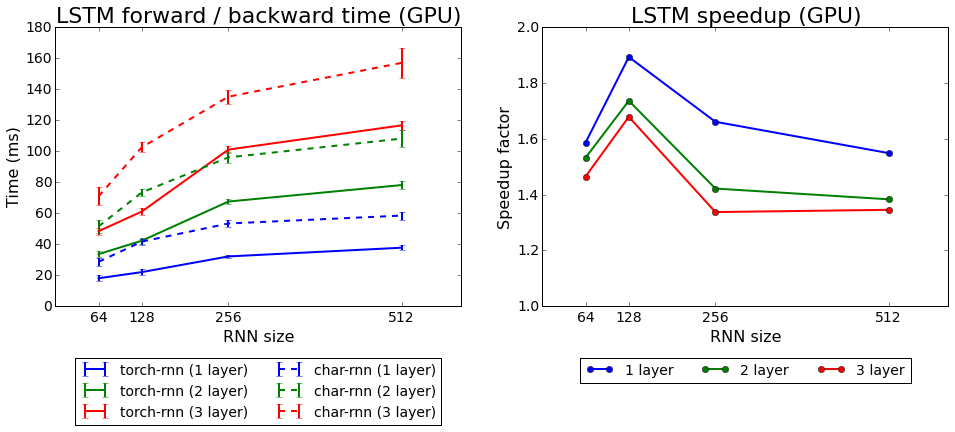 سرعة تعلم Torch-rnn مقارنةً بـ char-rnn
سرعة تعلم Torch-rnn مقارنةً بـ char-rnnاختبرنا كلا الخوارزميات التي تأتي مع Torch: rnn و LSTM. والثاني هو الأفضل.
الجزء 8. ماذا حققنا؟
تم نشر أول زبادي عصبي في 17 يناير 2017 - مباشرة بعد التدريب على المجموعة - وفي اليوم الأول تم جمع أكثر من 1000 تعليق.
 واحدة من البكتريا العصبية الأولى
واحدة من البكتريا العصبية الأولىوصلت Neurobugurts للجمهور بشكل جيد للغاية بحيث أصبحوا قسمًا منفصلاً ، والذي ظهر طوال العام تحت هاشتاغ # العصبية والمشتركين المسلحين. إجمالاً ، في عام 2017 وأوائل عام 2018 ، أنشأنا أكثر من
18000 عصاب عصبي ، بمتوسط 500 حرف لكل منهما. بالإضافة إلى ذلك ، ظهرت حركة كاملة من المحاكاة الساخرة العامة ، والتي صور المشاركون فيها عصبي الأعصاب ، أعادوا ترتيب العبارات بشكل عشوائي في الأماكن.

الجزء 9. بدلا من الاستنتاج
مع هذا المقال أردت أن أوضح أنه حتى لو لم تكن لديك خبرة في الشبكات العصبية ، فإن هذا الحزن ليس مشكلة. لست بحاجة إلى العمل في ستانفورد للقيام بأشياء بسيطة ولكنها مثيرة للاهتمام مع الشبكات العصبية. كان جميع المشاركين في مشروعنا طلابًا عاديين بمهامهم الحالية ، وشهاداتهم ، وأعمالهم ، ولكن السبب المشترك سمح لنا بوضع المشروع في النهاية. بفضل الفكرة المدروسة والتخطيط والطاقة للمشاركين ، تمكنا من الحصول على أول نتائج عقلانية في أقل من شهر بعد الصيغة النهائية للفكرة (سقط معظم العمل الفني والتنظيمي في عطلة الشتاء 2017).
 أكثر من 18000 بوورتس مولدة آليًا
أكثر من 18000 بوورتس مولدة آليًاآمل أن تساعد هذه المقالة شخصًا ما في التخطيط لمشروعه الطموح الخاص به مع الشبكات العصبية. أطلب عدم الحكم بدقة ، لأن هذه هي مقالتي الأولى عن حبري. إذا كنت ، مثلي ، متحمس ML ، فلنكن
أصدقاء .