
عادةً ما تشير "الأنماط" في سياق C ++ إلى تراكيب لغوية محددة للغاية. هناك قوالب بسيطة تبسط العمل مع نفس النوع من التعليمات البرمجية - هذه هي قوالب الفئة والوظيفة. إذا كان القالب يحتوي على إحدى المعلمات في حد ذاته ، فيمكن القول أن هذا هو قوالب من الدرجة الثانية ويقومون بإنشاء قوالب أخرى اعتمادًا على المعلمات الخاصة بهم. ولكن ماذا لو كانت قدراتهم غير كافية وأسهل لتوليد النص المصدر على الفور؟ الكثير من التعليمات البرمجية المصدر؟
إن معجبي Python و HTML-تخطيطات مألوفة بأداة (محرك ، مكتبة) للعمل مع قوالب نصية تسمى
Jinja2 . عند الإدخال ، يتلقى هذا المحرك ملف قالب يمكن مزج النص بهياكل التحكم ، ويكون الإخراج نصًا واضحًا يتم فيه استبدال جميع هياكل التحكم بالنص وفقًا للمعايير المحددة من الخارج (أو من الداخل). تقريبًا ، هذا شيء مثل صفحات ASP (أو C ++ - المعالج الأولي) ، تختلف لغة الترميز فقط.
حتى الآن ، تم تنفيذ هذا المحرك لبيثون فقط. الآن هو لـ C ++. حول كيف ولماذا حدث ، وسيتم مناقشته في المقالة.
لماذا تناولت هذا حتى
في الحقيقة ، لماذا؟ بعد كل شيء ، هناك Python ، لذلك - تنفيذ ممتاز ، مجموعة من الميزات ، مواصفات كاملة للغة. خذ واستخدم! أنا لا أحب Python - يمكنك أن تأخذ
Jinja2CppLight أو
inja ، منافذ Jinja2 الجزئية في C ++. يمكنك في النهاية أخذ منفذ C ++ {{
Moustache }}. الشيطان ، كالعادة ، في التفاصيل. لذلك ، دعنا نقول ، كنت بحاجة إلى وظائف الفلاتر من Jinja2 وإمكانيات البنية الممتدة ، والتي تسمح لك بإنشاء قوالب قابلة للتوسيع (وكذلك وحدات الماكرو وتضمينها ، ولكن هذا لاحقًا). ولا يدعم أي من التطبيقات المذكورة ذلك. هل يمكنني الاستغناء عن كل هذا؟ أيضا سؤال جيد. احكم بنفسك. لدي
مشروع يهدف إلى إنشاء C ++ - to-C ++ code code boilerplate. يتلقى هذا المولد الذاتي ، على سبيل المثال ، ملف رأس مكتوب يدويًا بهياكل أو تعدادات ، ويقوم على أساسه بوظائف التسلسل / إلغاء التسلسل أو ، على سبيل المثال ، تحويل عناصر التعداد إلى سلاسل (والعكس صحيح). يمكنك الاستماع إلى مزيد من التفاصيل حول هذه الأداة المساعدة في تقاريري
هنا (باللغة الإنجليزية) أو
هنا (روس).
لذا ، فإن المهمة النموذجية التي تم حلها في عملية العمل على الأداة المساعدة هي إنشاء ملفات رأس ، يحتوي كل منها على رأس (مع ifdefs ويتضمن) ، وهيكل يحتوي على المحتويات الرئيسية وتذييل. علاوة على ذلك ، فإن المحتوى الرئيسي هو الإعلانات التي تم إنشاؤها مكتوبة بمساحة الاسم. في تنفيذ C ++ ، تبدو التعليمات البرمجية لإنشاء ملف رأس مثل هذا (وهذا ليس كل شيء):
الكثير من كود C ++void Enum2StringGenerator::WriteHeaderContent(CppSourceStream &hdrOs) { std::vector<reflection::EnumInfoPtr> enums; WriteNamespaceContents(hdrOs, m_namespaces.GetRootNamespace(), [this, &enums](CppSourceStream &os, reflection::NamespaceInfoPtr ns) { for (auto& enumInfo : ns->enums) { WriteEnumToStringConversion(os, enumInfo); WriteEnumFromStringConversion(os, enumInfo); enums.push_back(enumInfo); } }); hdrOs << "\n\n"; { out::BracedStreamScope flNs("\nnamespace flex_lib", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline const char* Enum2String($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline $enumFullQualifiedName$ String2Enum<$enumFullQualifiedName$>(const char* itemName)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::StringTo$enumName$(itemName);"; } } } { out::BracedStreamScope flNs("\nnamespace std", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); out::BracedStreamScope body("inline std::string to_string($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } } }
من هنا .
علاوة على ذلك ، يتغير هذا الرمز قليلاً من ملف إلى آخر. بالطبع ، يمكنك استخدام تنسيق clang للتنسيق. لكن هذا لا يلغي بقية العمل اليدوي على توليد النص المصدر.
ثم لحظة واحدة جيدة ، أدركت أنه يجب تبسيط حياتي. لم أفكر في خيار شد لغة برمجة كاملة بسبب تعقيد دعم النتيجة النهائية. ولكن لإيجاد محرك قالب مناسب - لماذا لا؟ لقد وجدت أنه من المفيد البحث ، وجدته ، ثم وجدت مواصفات Jinja2 وأدركت أن هذا هو ما أحتاجه بالضبط. وفقًا لهذه المواصفات ، ستبدو قوالب إنشاء الرؤوس كما يلي:
{% extends "header_skeleton.j2tpl" %} {% block generator_headers %} #include <flex_lib/stringized_enum.h> #include <algorithm> #include <utility> {% endblock %} {% block namespaced_decls %}{{super()}}{% endblock %} {% block namespace_content %} {% for enum in ns.enums | sort(attribute="name") %} {% set enumName = enum.name %} {% set scopeSpec = enum.scopeSpecifier %} {% set scopedName = scopeSpec ~ ('::' if scopeSpec) ~ enumName %} {% set prefix = (scopedName + '::') if not enumInfo.isScoped else (scopedName ~ '::' ~ scopeSpec ~ ('::' if scopeSpec)) %} inline const char* {{enumName}}ToString({{scopedName}} e) { switch (e) { {% for itemName in enum.items | map(attribute="itemName") | sort%} case {{prefix}}{{itemName}}: return "{{itemName}}"; {% endfor %} } return "Unknown Item"; } inline {{scopedName}} StringTo{{enumName}}(const char* itemName) { static std::pair<const char*, {{scopedName}}> items[] = { {% for itemName in enum.items | map(attribute="itemName") | sort %} {"{{itemName}}", {{prefix}}{{itemName}} } {{',' if not loop.last }} {% endfor %} }; {{scopedName}} result; if (!flex_lib::detail::String2Enum(itemName, items, result)) flex_lib::bad_enum_name::Throw(itemName, "{{enumName}}"); return result; } {% endfor %}{% endblock %} {% block global_decls %} {% for ns in [rootNamespace] recursive %} {% for enum in ns.enums %} template<> inline const char* flex_lib::Enum2String({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } template<> inline {{enum.fullQualifiedName}} flex_lib::String2Enum<{{enum.fullQualifiedName}}>(const char* itemName) { return {{enum.namespaceQualifier}}::StringTo{{enum.name}}(itemName); } inline std::string to_string({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } {% endfor %} {{loop(ns.namespaces)}} {% endfor %} {% endblock %}
من هنا .

كانت هناك مشكلة واحدة فقط: لا يدعم أي محرك من المحركات المجموعة الكاملة من الميزات التي احتاجها. حسنًا ، بالطبع ، كان لدى الجميع
عيب قاتل . فكرت قليلاً وقررت أن عالمًا آخر لن يزداد سوءًا من تنفيذ آخر لمحرك القالب. علاوة على ذلك ، وفقًا للتقديرات ، لم يكن تنفيذ الوظائف الأساسية صعبًا للغاية. بعد كل شيء ، الآن في C ++ هناك regexp's!
وهكذا
جاء مشروع
Jinja2Cpp . على حساب تعقيد تنفيذ الوظيفة الأساسية (الأساسية للغاية) ، كنت على وشك التخمين. بشكل عام ، فاتني معامل Pi بالضبط: لقد استغرق مني أقل من ثلاثة أشهر لكتابة كل ما احتاجه. ولكن عندما تم الانتهاء من كل شيء ، والانتهاء وإدراجه في "مبرمج السيارات" - أدركت أنني حاولت دون جدوى. في الواقع ، تلقت أداة إنشاء التعليمات البرمجية لغة برمجة قوية مقترنة بالقوالب ، مما فتح فرص تطوير جديدة تمامًا لها.
ملاحظة: كانت لدي فكرة لربط بايثون (أو لوا). ولكن لا يوجد أي من محركات البرمجة النصية الحالية الموجودة على الإطلاق يحل مشكلات "خارج الصندوق" في إنشاء نص من القوالب. هذا يعني أن Python لا يزال عليه أن يفسد Jinja2 نفسه ، ولكن بالنسبة لـ Lua ، ابحث عن شيء مختلف. لماذا احتجت إلى هذا الرابط الإضافي؟
تنفيذ المحلل
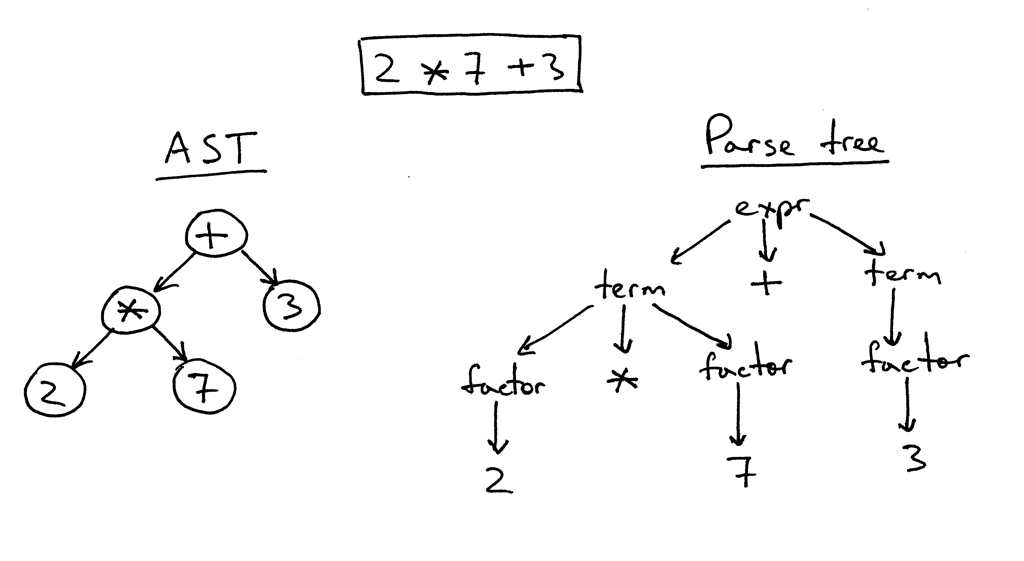
الفكرة وراء هيكل قوالب Jinja2 بسيطة للغاية. إذا كان هناك شيء في النص محاط بزوج من "{{" / "}}" ، فهذا "شيء" - تعبير يجب تقييمه وتحويله إلى تمثيل نصي وإدراجه في النتيجة النهائية. داخل الزوج "{٪" / "٪}" توجد عوامل تشغيل مثل ، إذا ، تعيين ، إلخ. حسنًا ، في "{#" / "#}" هناك تعليقات. بعد دراسة تنفيذ Jinja2CppLight ، قررت أن محاولة العثور على جميع هياكل التحكم هذه يدويًا في نص النموذج ليست فكرة جيدة جدًا. لذلك ، سلّحت نفسي باستخدام regexp البسيط إلى حد ما: ((\ \ {\ {) | (\} \}) | (\ {٪) | (٪ \}) | (\ {#) | (# \}) | (# ن)) وبمساعدة نصه إلى الأجزاء الضرورية. وأطلق عليها المرحلة الصعبة من التحليل. في المرحلة الأولى من العمل ، أظهرت الفكرة فعاليتها (نعم ، في الواقع ، لا تزال تظهر) ، ولكن بطريقة جيدة ، ستحتاج إلى إعادة هيكلتها في المستقبل ، حيث يتم الآن فرض قيود طفيفة على نص النموذج: الهروب من الأزواج "{{" و تمت معالجة "}}" في النص "جبهته" أيضًا.
في المرحلة الثانية ، يتم تحليل ما هو داخل "الأقواس" بالتفصيل. وهنا كان علي أن العبث. مع inja ، مع Jinja2CppLight ، فإن محلل التعبير بسيط جدًا. في الحالة الأولى - على نفس regexp'ah ، في الحالة الثانية - مكتوبة بخط اليد ، ولكنها تدعم فقط تصاميم بسيطة للغاية. دعم الفلاتر أو المختبرين أو الحساب المعقد أو الفهرسة أمر غير وارد. وكانت هذه الميزات من Jinja2 على وجه التحديد هي التي أردت أكثر من أي شيء آخر. لذلك ، لم يكن لدي أي خيار آخر سوى أن أزعج محلل كامل LL (1) (في بعض الأماكن - حساس للسياق) ينفذ القواعد اللازمة. منذ حوالي عشرة إلى خمسة عشر عامًا ، ربما كنت سأأخذ Bison أو ANTLR لهذا الأمر وأطبق محللاً بمساعدتهم. قبل حوالي سبع سنوات كنت سأحاول Boost.Spirit. الآن قمت للتو بتطبيق المحلل اللغوي الذي أحتاجه ، العمل باستخدام طريقة الهبوط العودي ، دون توليد تبعيات غير ضرورية وزيادة وقت التجميع بشكل ملحوظ ، كما يحدث إذا تم استخدام أدوات خارجية أو Boost.Spirit. عند إخراج المحلل اللغوي ، أحصل على AST (للتعبيرات أو عوامل التشغيل) ، والتي يتم حفظها كقالب ، جاهزة للعرض اللاحق.
مثال على تحليل المنطق ExpressionEvaluatorPtr<FullExpressionEvaluator> ExpressionParser::ParseFullExpression(LexScanner &lexer, bool includeIfPart) { ExpressionEvaluatorPtr<FullExpressionEvaluator> result; LexScanner::StateSaver saver(lexer); ExpressionEvaluatorPtr<FullExpressionEvaluator> evaluator = std::make_shared<FullExpressionEvaluator>(); auto value = ParseLogicalOr(lexer); if (!value) return result; evaluator->SetExpression(value); ExpressionEvaluatorPtr<ExpressionFilter> filter; if (lexer.PeekNextToken() == '|') { lexer.EatToken(); filter = ParseFilterExpression(lexer); if (!filter) return result; evaluator->SetFilter(filter); } ExpressionEvaluatorPtr<IfExpression> ifExpr; if (lexer.PeekNextToken() == Token::If) { if (includeIfPart) { lexer.EatToken(); ifExpr = ParseIfExpression(lexer); if (!ifExpr) return result; evaluator->SetTester(ifExpr); } } saver.Commit(); return evaluator; } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalOr(LexScanner& lexer) { auto left = ParseLogicalAnd(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalOr) { lexer.ReturnToken(); return left; } auto right = ParseLogicalOr(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalOr, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalAnd(LexScanner& lexer) { auto left = ParseLogicalCompare(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalAnd) { lexer.ReturnToken(); return left; } auto right = ParseLogicalAnd(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalAnd, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalCompare(LexScanner& lexer) { auto left = ParseStringConcat(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); auto tok = lexer.NextToken(); BinaryExpression::Operation operation; switch (tok.type) { case Token::Equal: operation = BinaryExpression::LogicalEq; break; case Token::NotEqual: operation = BinaryExpression::LogicalNe; break; case '<': operation = BinaryExpression::LogicalLt; break; case '>': operation = BinaryExpression::LogicalGt; break; case Token::GreaterEqual: operation = BinaryExpression::LogicalGe; break; case Token::LessEqual: operation = BinaryExpression::LogicalLe; break; case Token::In: operation = BinaryExpression::In; break; case Token::Is: { Token nextTok = lexer.NextToken(); if (nextTok != Token::Identifier) return ExpressionEvaluatorPtr<Expression>(); std::string name = AsString(nextTok.value); bool valid = true; CallParams params; if (lexer.NextToken() == '(') params = ParseCallParams(lexer, valid); else lexer.ReturnToken(); if (!valid) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<IsExpression>(left, std::move(name), std::move(params)); } default: lexer.ReturnToken(); return left; } auto right = ParseStringConcat(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(operation, left, right); }
من هنا .
جزء من فئات شجرة التعبير AST class ExpressionFilter; class IfExpression; class FullExpressionEvaluator : public ExpressionEvaluatorBase { public: void SetExpression(ExpressionEvaluatorPtr<Expression> expr) { m_expression = expr; } void SetFilter(ExpressionEvaluatorPtr<ExpressionFilter> expr) { m_filter = expr; } void SetTester(ExpressionEvaluatorPtr<IfExpression> expr) { m_tester = expr; } InternalValue Evaluate(RenderContext& values) override; void Render(OutStream &stream, RenderContext &values) override; private: ExpressionEvaluatorPtr<Expression> m_expression; ExpressionEvaluatorPtr<ExpressionFilter> m_filter; ExpressionEvaluatorPtr<IfExpression> m_tester; }; class ValueRefExpression : public Expression { public: ValueRefExpression(std::string valueName) : m_valueName(valueName) { } InternalValue Evaluate(RenderContext& values) override; private: std::string m_valueName; }; class SubscriptExpression : public Expression { public: SubscriptExpression(ExpressionEvaluatorPtr<Expression> value, ExpressionEvaluatorPtr<Expression> subscriptExpr) : m_value(value) , m_subscriptExpr(subscriptExpr) { } InternalValue Evaluate(RenderContext& values) override; private: ExpressionEvaluatorPtr<Expression> m_value; ExpressionEvaluatorPtr<Expression> m_subscriptExpr; }; class ConstantExpression : public Expression { public: ConstantExpression(InternalValue constant) : m_constant(constant) {} InternalValue Evaluate(RenderContext&) override { return m_constant; } private: InternalValue m_constant; }; class TupleCreator : public Expression { public: TupleCreator(std::vector<ExpressionEvaluatorPtr<>> exprs) : m_exprs(std::move(exprs)) { } InternalValue Evaluate(RenderContext&) override; private: std::vector<ExpressionEvaluatorPtr<>> m_exprs; };
من هنا .
فئات فئات مشغلي شجرة AST struct Statement : public RendererBase { }; template<typename T = Statement> using StatementPtr = std::shared_ptr<T>; template<typename CharT> class TemplateImpl; class ForStatement : public Statement { public: ForStatement(std::vector<std::string> vars, ExpressionEvaluatorPtr<> expr, ExpressionEvaluatorPtr<> ifExpr, bool isRecursive) : m_vars(std::move(vars)) , m_value(expr) , m_ifExpr(ifExpr) , m_isRecursive(isRecursive) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void SetElseBody(RendererPtr renderer) { m_elseBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: void RenderLoop(const InternalValue& val, OutStream& os, RenderContext& values); private: std::vector<std::string> m_vars; ExpressionEvaluatorPtr<> m_value; ExpressionEvaluatorPtr<> m_ifExpr; bool m_isRecursive; RendererPtr m_mainBody; RendererPtr m_elseBody; }; class ElseBranchStatement; class IfStatement : public Statement { public: IfStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void AddElseBranch(StatementPtr<ElseBranchStatement> branch) { m_elseBranches.push_back(branch); } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; std::vector<StatementPtr<ElseBranchStatement>> m_elseBranches; }; class ElseBranchStatement : public Statement { public: ElseBranchStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } bool ShouldRender(RenderContext& values) const; void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; };
من هنا .
ترتبط عُقد AST فقط بنص القالب ويتم تحويلها إلى قيم إجمالية في وقت العرض ، مع مراعاة سياق العرض الحالي ومعلماته. هذا سمح لنا بعمل أنماط آمنة للخيط. ولكن المزيد عن هذا من حيث العرض الفعلي.
بصفتي
الرمز الأساسي ، اخترت مكتبة
lexertk . لديها ترخيص أحتاجه ورأس فقط. صحيح ، كان علي أن أقطع جميع الأجراس وصفارات حساب توازن الأقواس وما إلى ذلك ، وترك فقط الرمز المميز نفسه ، الذي تعلم (بعد تسوية بسيطة مع ملف) العمل ليس فقط مع char ، ولكن أيضًا مع أحرف wchar_t. على رأس هذا الرمز المميز ، قمت بتغليف فئة أخرى تؤدي ثلاث وظائف رئيسية: أ) أنها تلخص رمز المحلل اللغوي من نوع الأحرف التي نعمل معها ، ب) تتعرف على الكلمات الرئيسية الخاصة بـ Jinja2 و ج) توفر واجهة ملائمة للعمل مع دفق الرمز المميز:
LexScanner class LexScanner { public: struct State { Lexer::TokensList::const_iterator m_begin; Lexer::TokensList::const_iterator m_end; Lexer::TokensList::const_iterator m_cur; }; struct StateSaver { StateSaver(LexScanner& scanner) : m_state(scanner.m_state) , m_scanner(scanner) { } ~StateSaver() { if (!m_commited) m_scanner.m_state = m_state; } void Commit() { m_commited = true; } State m_state; LexScanner& m_scanner; bool m_commited = false; }; LexScanner(const Lexer& lexer) { m_state.m_begin = lexer.GetTokens().begin(); m_state.m_end = lexer.GetTokens().end(); Reset(); } void Reset() { m_state.m_cur = m_state.m_begin; } auto GetState() const { return m_state; } void RestoreState(const State& state) { m_state = state; } const Token& NextToken() { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur ++; } void EatToken() { if (m_state.m_cur != m_state.m_end) ++ m_state.m_cur; } void ReturnToken() { if (m_state.m_cur != m_state.m_begin) -- m_state.m_cur; } const Token& PeekNextToken() const { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur; } bool EatIfEqual(char type, Token* tok = nullptr) { return EatIfEqual(static_cast<Token::Type>(type), tok); } bool EatIfEqual(Token::Type type, Token* tok = nullptr) { if (m_state.m_cur == m_state.m_end) { if(type == Token::Type::Eof && tok) *tok = EofToken(); return type == Token::Type::Eof; } if (m_state.m_cur->type == type) { if (tok) *tok = *m_state.m_cur; ++ m_state.m_cur; return true; } return false; } private: State m_state; static const Token& EofToken() { static Token eof; eof.type = Token::Eof; return eof; } };
من هنا .
وبالتالي ، على الرغم من حقيقة أن المحرك يمكن أن يعمل مع كل من char و wchar_t-Templates ، فإن رمز التحليل الرئيسي لا يعتمد على نوع الحرف. ولكن المزيد عن هذا في قسم المغامرات مع أنواع الشخصيات.
بشكل منفصل ، كان علي أن العبث بهياكل التحكم. في Jinja2 ، يتم إقران العديد منها. على سبيل المثال ، بالنسبة لـ / endfor ، if / endif ، block / endblock ، إلخ. كل عنصر من عناصر الزوج يدخل في "أقواس" خاصة به ، وبين العناصر يمكن أن يكون هناك مجموعة من كل شيء: فقط نص عادي وكتل تحكم أخرى. لذلك ، كان يجب أن يتم خوارزمية تحليل القالب على أساس المكدس ، إلى العنصر العلوي الحالي الذي يحتوي على جميع الإنشاءات والتعليمات التي تم العثور عليها حديثًا ، بالإضافة إلى أجزاء من النص البسيط بينهما ، "التشبث". باستخدام نفس المكدس ، يتم التحقق من عدم توازن نوع if-for-endif-endfor. نتيجة لكل هذا ، تبين أن الشفرة ليست "مضغوطة" مثل ، على سبيل المثال ، Jinja2CppLight (أو inja) ، حيث يكون التنفيذ بالكامل في مصدر واحد (أو رأس). لكن منطق التحليل ، وفي الواقع ، القواعد النحوية في الشفرة تكون أكثر وضوحًا ، مما يبسط دعمها وامتدادها. على الأقل هذا ما كنت أهدف إليه. لا يزال من غير الممكن تقليل عدد التبعيات أو مقدار الشفرة ، لذلك تحتاج إلى جعلها أكثر قابلية للفهم.
في
الجزء التالي ، سنتحدث عن عملية عرض القوالب ، ولكن في الوقت الحالي - الروابط:
مواصفات Jinja2:
http://jinja.pocoo.org/docs/2.10/templates/تنفيذ Jinja2Cpp:
https://github.com/flexferrum/Jinja2Cppتنفيذ Jinja2CppLight:
https://github.com/hughperkins/Jinja2CppLightالتنفيذ المصاب:
https://github.com/pantor/injaالأداة المساعدة لإنشاء التعليمات البرمجية بناءً على قوالب Jinja2:
https://github.com/flexferrum/autoprogrammer/tree/jinja2cpp_refactor