واحدة من الأخبار الأكثر شعبية ومناقشة على مدى السنوات القليلة الماضية هو الذي أضاف الذكاء الاصطناعي إلى أين وماذا اخترق المتسللون ماذا وأين. من خلال الجمع بين هذه المواضيع ، تظهر دراسات مثيرة للاهتمام للغاية ، وكانت هناك بالفعل العديد من المقالات في المحور التي كانت قادرة على خداع نماذج التعلم الآلي ، على سبيل المثال: مقال حول قيود التعلم العميق ، حول كيفية جذب الشبكات العصبية . علاوة على ذلك ، أود أن أعتبر هذا الموضوع بمزيد من التفصيل من وجهة نظر أمان الكمبيوتر:

خذ بعين الاعتبار المسائل التالية:
- مصطلحات مهمة.
- ما هو التعلم الآلي ، إذا كنت لا تعرف فجأة.
- ما علاقة أمن الحاسوب بذلك ؟!
- هل من الممكن التلاعب بنموذج التعلم الآلي للقيام بهجوم مستهدف؟
- هل يمكن أن ينخفض أداء النظام؟
- هل يمكنني الاستفادة من قيود نماذج التعلم الآلي؟
- تصنيف الهجمات.
- طرق الحماية.
- العواقب المحتملة.
1. أول شيء أود أن أبدأ به هو المصطلحات.
يمكن أن يتسبب هذا البيان المحتمل في وجود فضاء كبير من جانب كل من الأوساط العلمية والمهنية بسبب العديد من المقالات المكتوبة بالفعل باللغة الروسية ، ولكن أود أن أشير إلى أن مصطلح "الذكاء العدائي" يُترجم على أنه "ذكاء معاد". ولا يجب ترجمة كلمة "عدو" نفسها ليس بالمصطلح القانوني "عدو" ، ولكن بمصطلح أكثر ملاءمة من الأمن "ضار" (لا توجد شكاوى حول ترجمة اسم بنية الشبكة العصبية). ثم تأخذ جميع المصطلحات ذات الصلة باللغة الروسية معنى أكثر إشراقًا ، مثل "المثال العدائي" - مثال ضار للبيانات ، "إعدادات الخصومة" - بيئة ضارة. والمجال الذي سننظر فيه في "التعلم الآلي العدائي" هو التعلم الآلي الضار.
على الأقل في إطار هذه المقالة ، سيتم استخدام هذه المصطلحات باللغة الروسية. آمل أن يكون من الممكن إظهار أن هذا الموضوع يتعلق أكثر بكثير بالأمان من أجل استخدام مصطلحات من هذا المجال إلى حد ما ، بدلاً من المثال الأول من مترجم.
والآن ، بعد أن أصبحنا مستعدين للتحدث بنفس اللغة ، يمكننا أن نبدأ بشكل أساسي :)
2. ما هو التعلم الآلي ، إذا كنت لا تعرف فجأة
حسنًا ، ما زلت على دراية بالفعلمن خلال طرق التعلم الآلي ، نعني عادةً طرقًا لإنشاء خوارزميات قادرة على التعلم والتصرف دون برمجة سلوكها بشكل صريح على البيانات المحددة مسبقًا. بالبيانات ، يمكننا أن نعني أي شيء ، إذا استطعنا وصفه ببعض العلامات أو قياسه. إذا كانت هناك بعض العلامات غير المعروفة لبعض البيانات ، ولكننا نحتاجها حقًا ، فنحن نستخدم طرق التعلم الآلي لاستعادة أو توقع هذه العلامة بناءً على البيانات المعروفة بالفعل.
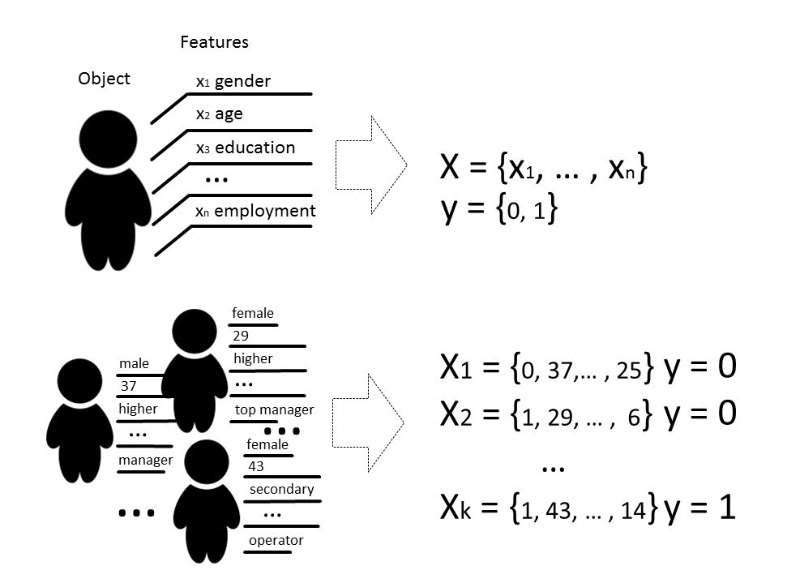
هناك عدة أنواع من المشاكل التي يمكن حلها بمساعدة التعلم الآلي ، ولكننا سنتحدث بشكل أساسي عن مشكلة التصنيف.
بشكل كلاسيكي ، الغرض من مرحلة التدريب لنموذج المصنف هو تحديد علاقة (وظيفة) تظهر التوافق بين ميزات كائن معين وأحد الفئات المعروفة. في حالة أكثر تعقيدًا ، يلزم توقع احتمالية الانتماء إلى فئة معينة.
أي أن مهمة التصنيف هي بناء مثل هذه الطائرة الزائدة التي ستقسم المساحة ، حيث ، كقاعدة ، يكون حجمها هو حجم متجه الميزة ، بحيث تقع كائنات من فئات مختلفة على جوانب متقابلة من هذه الطائرة الزائدة.
للحصول على مساحة ثنائية الأبعاد ، مثل هذه الطائرة الزائدة هي خط. فكر في مثال بسيط:

في الصورة ، يمكنك رؤية فئتين ، مربعات ومثلثات. من المستحيل العثور على الاعتماد وتقسيمها بدقة أكبر بواسطة دالة خطية. لذلك ، بمساعدة التعلم الآلي ، يمكن للمرء اختيار وظيفة غير خطية تميز بشكل أفضل بين هاتين المجموعتين.
مهمة التصنيف هي مهمة تدريس نموذجية إلى حد ما مع المعلم. لتدريب النموذج ، تعد مجموعة البيانات هذه ضرورية بحيث يمكن التمييز بين ميزات الكائن وفئته.
3. ما علاقة أمن الحاسوب بذلك ؟!
في أمان الكمبيوتر ، لطالما تم استخدام العديد من أساليب التعلم الآلي في تصفية الرسائل غير المرغوب فيها وتحليل حركة المرور والكشف عن الاحتيال أو البرامج الضارة.
وبمعنى ما ، هذه لعبة حيث تتوقع ، بعد أن قامت بخطوة ، أن يكون رد فعل العدو. لذلك ، عند لعب هذه اللعبة ، يجب عليك باستمرار تعديل النماذج ، أو التدريس على بيانات جديدة ، أو تغييرها بالكامل ، مع مراعاة أحدث إنجازات العلوم.
على سبيل المثال ، بينما تستخدم مضادات الفيروسات تحليل التوقيع والاستدلال اليدوي والقواعد التي يصعب الحفاظ عليها وتوسيعها ، لا تزال صناعة الأمن تتجادل حول الفوائد الحقيقية لمضادات الفيروسات ويعتبر الكثيرون أن مضادات الفيروسات منتج ميت. يتحايل المهاجمون على كل هذه القواعد ، على سبيل المثال ، بمساعدة التعتيم وتعدد الأشكال. نتيجة لذلك ، يتم إعطاء الأفضلية للأدوات التي تستخدم تقنيات أكثر ذكاء ، على سبيل المثال ، طرق التعلم الآلي التي تحدد الميزات تلقائيًا (حتى تلك التي لا يفسرها البشر) ، يمكنها معالجة كميات كبيرة من المعلومات بسرعة وتعميمها واتخاذ القرارات بسرعة.
أي ، من جهة ، يستخدم التعلم الآلي كأداة للحماية. من ناحية أخرى ، يتم استخدام هذه الأداة أيضًا لهجمات أكثر ذكاء.
دعونا نرى ما إذا كانت هذه الأداة يمكن أن تكون عرضة للخطر؟
بالنسبة لأي خوارزمية ، ليس فقط اختيار المعلمات مهمًا جدًا ، ولكن أيضًا البيانات التي يتم تدريب الخوارزمية عليها. بالطبع ، في وضع مثالي ، من الضروري أن تكون هناك بيانات كافية للتدريب ، ويجب أن تكون الفصول الدراسية متوازنة ، ووقت التدريب يمر دون أن يلاحظه أحد ، وهو أمر مستحيل عمليًا في الحياة الواقعية.
عادةً ما تُفهم جودة النموذج المدرب على أنها دقة التصنيف على البيانات التي لم "يراها" النموذج ، في الحالة العامة ، كنسبة معينة من نسخ البيانات المصنفة بشكل صحيح إلى إجمالي كمية البيانات التي أرسلناها إلى النموذج.
بشكل عام ، ترتبط جميع تقييمات الجودة بشكل مباشر بالافتراضات حول التوزيع المتوقع لبيانات الإدخال للنظام ولا تأخذ في الاعتبار الظروف البيئية الضارة ( إعدادات الخصومة ) ، والتي غالبًا ما تتجاوز التوزيع المتوقع لبيانات الإدخال. تُفهم البيئة الخبيثة على أنها بيئة يمكن فيها مواجهة النظام أو التفاعل معه. من الأمثلة النموذجية لهذه البيئات تلك التي تستخدم عوامل تصفية الرسائل غير المرغوب فيها وخوارزميات الكشف عن الاحتيال وأنظمة تحليل البرامج الضارة.
وبالتالي ، يمكن اعتبار الدقة كمقياس لمتوسط أداء النظام في متوسط استخدامه ، بينما يهتم تقييم السلامة بأسوأ تنفيذه.
أي أن نماذج التعلم الآلي عادة ما يتم اختبارها في بيئة ثابتة إلى حد ما حيث تعتمد الدقة على كمية البيانات لكل فئة بعينها ، ولكن في الواقع لا يمكن ضمان نفس التوزيع. ونحن مهتمون بجعل النموذج خاطئًا. وبناءً على ذلك ، فإن مهمتنا هي العثور على أكبر عدد ممكن من المتجهات التي تعطي النتيجة الخاطئة.
عندما يتحدثون عن أمان نظام أو خدمة ، فإنهم عادة ما يعنيون أنه من المستحيل انتهاك سياسة أمنية ضمن نموذج تهديد معين في الأجهزة أو البرامج ، في محاولة للتحقق من النظام في مرحلة التطوير وفي مرحلة الاختبار. ولكن اليوم ، يعمل عدد كبير من الخدمات على أساس خوارزميات تحليل البيانات ، لذا فإن المخاطر لا تكمن فقط في الوظائف الضعيفة ، ولكن أيضًا في البيانات نفسها ، والتي يمكن للنظام على أساسها اتخاذ القرارات.
لا أحد يقف ساكنًا ، كما يتقن المتسللون شيئًا جديدًا. والطرق التي تساعد على دراسة خوارزميات التعلم الآلي لإمكانية التسوية من قبل مهاجم يمكنه استخدام المعرفة بكيفية عمل النموذج تسمى التعلم الآلي العدائي ، أو باللغة الروسية لا يزال التعلم الآلي الخبيث .
إذا تحدثنا عن سلامة نماذج تعلُّم الآلة من منظور أمن المعلومات ، فإنني أرغب من الناحية النظرية في النظر في العديد من المشكلات.
4. هل من الممكن التلاعب بنموذج التعلم الآلي للقيام بهجوم مستهدف؟
هنا مثال جيد مع تحسين محرك البحث. يدرس الناس كيف تعمل خوارزميات محرك البحث الذكي وتتلاعب بالبيانات الموجودة على مواقعهم لتكون أعلى في ترتيب البحث. إن مسألة أمن مثل هذا النظام في هذه الحالة ليست شديدة حتى يتم اختراق بعض البيانات أو تسبب في أضرار جسيمة.
كمثال على هذا النظام ، يمكننا الاستشهاد بالخدمات التي تستخدم بشكل أساسي التدريب على النموذج عبر الإنترنت ، أي التدريب الذي يتلقى فيه النموذج البيانات بترتيب تسلسلي لتحديث المعلمات الحالية. بمعرفة كيفية تدريب النظام ، يمكنك التخطيط للهجوم وتزويد النظام ببيانات معدة مسبقًا.
على سبيل المثال ، بهذه الطريقة يتم خداع أنظمة المقاييس الحيوية ، التي تقوم بتحديث معلماتها تدريجيًا مع حدوث تغييرات صغيرة في مظهر الشخص ، على سبيل المثال ، مع تغير طبيعي في العمر ، وهو وظيفة طبيعية وضرورية للغاية للخدمة في هذه الحالة. باستخدام خاصية النظام هذه ، يمكنك إعداد البيانات وإرسالها إلى نظام المقاييس الحيوية ، وتحديث النموذج حتى يقوم بتحديث المعلمات إلى شخص آخر. وبالتالي ، فإن المهاجم سيعيد تدريب النموذج وسيكون قادرًا على تحديد نفسه بدلاً من الضحية.

تنشأ هذه المشكلة بشكل طبيعي تمامًا من حقيقة أن نموذج التعلم الآلي غالبًا ما يتم اختباره في بيئة ثابتة إلى حد ما ، ويتم تقييم جودته من خلال توزيع البيانات التي تم تدريب النموذج عليها. في الوقت نفسه ، غالبًا ما يتم طرح أسئلة محددة للغاية على أخصائيي تحليل البيانات ، والتي يحتاج النموذج للإجابة عليها:
- هل الملف ضار؟
- هل تنتمي هذه المعاملة إلى الاحتيال؟
- هل حركة المرور الحالية شرعية؟
ومن المتوقع أن الخوارزمية لا يمكن أن تكون دقيقة بنسبة 100٪ ، يمكن فقط مع بعض الاحتمالية أن تنسب الكائن إلى فئة معينة ، لذلك علينا إيجاد حلول وسط في حالة أخطاء من النوع الأول والثاني ، عندما لا يمكن للخوارزمية التأكد تمامًا في اختياره وما زال مخطئا.
خذ نظامًا ينتج غالبًا أخطاء من النوع الأول والثاني. على سبيل المثال ، قام برنامج مكافحة الفيروسات بحظر ملفك لأنه اعتبره ضارًا (على الرغم من أن هذا ليس كذلك) ، أو أن برنامج مكافحة الفيروسات تخطي ملفًا ضارًا. في هذه الحالة ، يعتبر مستخدم النظام أنه غير فعال وغالبًا ما يقوم بإيقاف تشغيله ، على الرغم من أنه من المحتمل أنه تم اكتشاف مجموعة من هذه البيانات للتو.
ومجموعة البيانات التي يُظهر النموذج أسوأ نتيجة لها موجودة دائمًا. ومهمة المهاجم هي البحث عن مثل هذه البيانات من أجل إيقاف تشغيل النظام. مثل هذه المواقف غير سارة إلى حد ما ، وبالطبع يجب أن يتجنبها النموذج. ويمكنك أن تتخيل حجم عواقب التحقيقات في جميع الحوادث الكاذبة!
يُنظر إلى أخطاء النوع الأول على أنها مضيعة للوقت ، في حين يُنظر إلى أخطاء النوع الثاني على أنها فرصة ضائعة. على الرغم من حقيقة أن تكلفة هذه الأنواع من الأخطاء لكل نظام معين قد تكون مختلفة. إذا كان من الممكن أن يكون برنامج مكافحة الفيروسات أرخص ، فيمكن ارتكاب خطأ من النوع الأول ، لأنه من الأفضل تشغيله بأمان وقول أن الملف ضار ، وإذا قام العميل بإيقاف تشغيل النظام وتبين أن الملف ضار حقًا ، فإن برنامج مكافحة الفيروسات "كما تم تحذيره" وتبقى المسؤولية على عاتق المستخدم. إذا أخذنا ، على سبيل المثال ، نظامًا للتشخيصات الطبية ، فسيكون كل من الخطأين مكلفًا للغاية ، لأنه في أي حال يكون المريض معرضًا لخطر العلاج غير الصحيح والمخاطر الصحية.
6. هل يمكن للمهاجم استخدام خصائص طريقة تعلُم الآلة لتعطيل النظام؟ أي ، دون التدخل في عملية التعلم ، تجد مثل هذه القيود النموذجية التي من الواضح أنها تعطي تنبؤات غير صحيحة.
يبدو أن أنظمة التعلم العميق محمية عمليًا من التدخل البشري في اختيار العلامات ، لذلك يمكن القول أنه لا يوجد عامل بشري عند اتخاذ أي قرارات بواسطة النموذج. إن سحر التعلم العميق بالكامل هو أنه يكفي إعطاء إدخال النموذج بيانات "أولية" تقريبًا ، والنموذج نفسه ، من خلال التحولات الخطية المتعددة ، يسلط الضوء على الميزات التي "يعتبرها" الأكثر أهمية ويتخذ قرارًا. ومع ذلك ، هل هو حقا جيد؟
هناك أعمال تصف طرق إعداد مثل هذه الأمثلة الخبيثة على نموذج التعلم العميق ، الذي يصنفه النظام بشكل غير صحيح. أحد الأمثلة القليلة ولكن الشائعة هو مقال عن الهجمات الجسدية الفعالة على نماذج التعلم العميق.
أجرى المؤلفون تجارب وطرقًا مقترحة لتجاوز النماذج استنادًا إلى تقييد التعلم العميق الذي يخدع نظام "الرؤية" ، باستخدام مثال التعرف على علامات الطريق. للحصول على نتيجة إيجابية ، يكفي أن يجد المهاجمون مثل هذه المناطق على الجسم التي تسقط المصنف بقوة ، وهي خاطئة. تم إجراء التجارب على علامة "STOP" ، والتي ، بسبب التغييرات في الباحثين ، وصفت النموذج بأنه علامة "SPEED LIMIT 45". اختبروا نهجهم على علامات أخرى وحصلوا على نتيجة إيجابية.
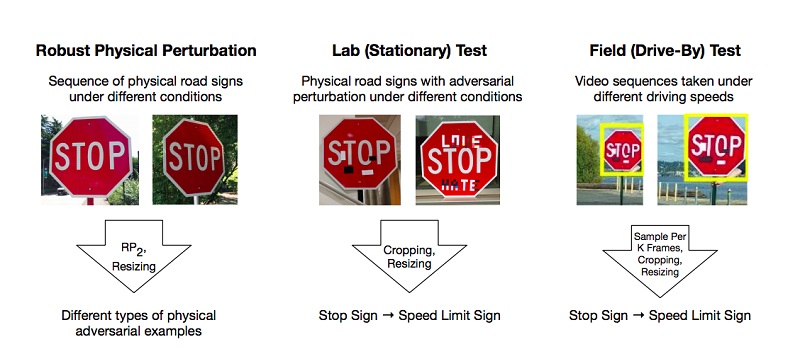
ونتيجة لذلك ، اقترح المؤلفون طريقتين يمكن للمرء من خلالهما خداع نظام التعلم الآلي: هجوم طباعة الملصقات ، والذي ينطوي على سلسلة من التغييرات الصغيرة حول محيط العلامة بالكامل ، يسمى التمويه ، وهجمات الملصقات ، عندما تم وضع بعض الملصقات على العلامة في مناطق معينة.
لكن هذه مواقف حياتية تمامًا - عندما تكون اللافتة في التراب من غبار على جانب الطريق أو عندما تتخلى المواهب الشابة عن عملهم عليها. من المحتمل أن الذكاء الاصطناعي والفن ليس لهما مكان في عالم واحد.

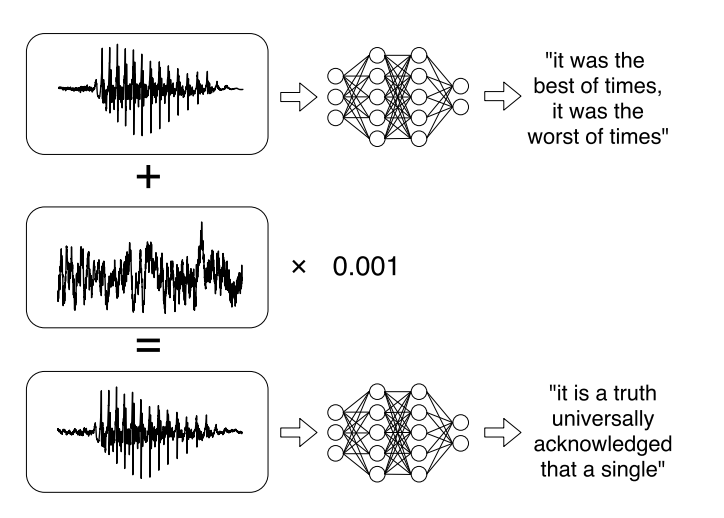
أو بحث حديث عن الهجمات المستهدفة على أنظمة التعرف الآلي على الكلام . أصبحت الرسائل الصوتية اتجاهًا عصريًا للغاية عند التواصل على الشبكات الاجتماعية ، ولكن الاستماع إليها ليس دائمًا مناسبًا. لذلك ، هناك خدمات تسمح لك ببث تسجيل صوتي إلى نص. تعلم مؤلفو العمل تحليل الصوت الأصلي ، وأخذوا في الاعتبار الإشارة الصوتية ، ثم تعلموا إنشاء إشارة صوتية أخرى ، تشبه 99٪ الصوت الأصلي ، عن طريق إضافة تغيير صغير إليها. ونتيجة لذلك ، يقوم المصنف بفك تشفير السجل كما يريد المهاجم.
7 - وفي هذا الصدد ، سيكون من الممكن تصنيف الهجمات الحالية بعدة طرق :
عن طريق التعرض (التأثير):
- تؤثر الهجمات السببية على التدريب النموذجي من خلال التدخل في مجموعة التدريب.
- تستخدم الهجمات الاستكشافية أخطاء المصنف دون التأثير على مجموعة التدريب.
انتهاك الأمان:
- تهدد هجمات النزاهة النظام من خلال أخطاء من النوع الثاني.
- تتسبب هجمات التوفر في إيقاف تشغيل النظام ، وعادةً ما تستند إلى أخطاء من النوع الأول.
الخصوصية:
- الهجوم المستهدف (الهجوم المستهدف) يهدف إلى تغيير توقع المصنف إلى فئة معينة.
- يهدف الهجوم الجماعي (الهجوم العشوائي) إلى تغيير استجابة المصنف إلى أي فئة باستثناء الفئة الصحيحة.
الغرض من الأمان هو حماية الموارد من المهاجم والامتثال للمتطلبات ، التي تؤدي انتهاكاتها إلى اختراق جزئي أو كامل لأحد الموارد.
تُستخدم نماذج مختلفة للتعلم الآلي من أجل السلامة. على سبيل المثال ، تهدف أنظمة الكشف عن الفيروسات إلى الحد من التعرض للفيروسات من خلال اكتشافها قبل إصابة النظام ، أو اكتشاف واحد موجود لإزالته. مثال آخر هو نظام كشف التسلل (IDS) ، الذي يكتشف أن النظام قد تم اختراقه من خلال الكشف عن حركة المرور الضارة أو السلوك المشبوه في النظام. مهمة قريبة أخرى هي نظام منع التطفل (IPS) ، الذي يكتشف محاولات التسلل ويمنع التسلل إلى النظام.
في سياق المشكلات الأمنية ، يتمثل هدف نماذج التعلم الآلي ، في الحالة العامة ، في فصل الأحداث الضارة ومنعها من التدخل في النظام.
بشكل عام ، يمكن تقسيم الهدف إلى قسمين:
النزاهة : منع المهاجم من الوصول إلى موارد النظام
إمكانية الوصول : تمنع المهاجم من التدخل في التشغيل العادي.
هناك اتصال واضح بين أخطاء النوع الثاني وانتهاكات التكامل: يمكن أن تكون الحالات الخبيثة التي تمر في النظام ضارة. تمامًا مثل أخطاء النوع الأول تنتهك إمكانية الوصول عادةً ، لأن النظام نفسه يرفض نسخًا موثوقًا بها من البيانات.
8. ما هي طرق الحماية من المجرمين الإلكترونيين الذين يتلاعبون بنماذج التعلم الآلي؟
في الوقت الحالي ، تعد حماية نموذج التعلم الآلي من الهجمات الضارة أكثر صعوبة من مهاجمته. فقط لأنه بغض النظر عن مقدار تدريبنا على النموذج ، سيكون هناك دائمًا مجموعة بيانات ستعمل على أسوأ وجه.
واليوم لا توجد طرق فعالة بما يكفي لجعل النموذج يعمل بدقة 100٪. ولكن هناك بعض النصائح التي يمكن أن تجعل النموذج أكثر مقاومة للأمثلة الخبيثة.
فيما يلي أهمها: إذا كان من الممكن عدم استخدام نماذج التعلم الآلي في بيئة ضارة ، فمن الأفضل عدم استخدامها. ليس من المنطقي رفض التعلم الآلي إذا كنت تواجه مهمة تصنيف الصور أو إنشاء الميمات. من غير الممكن إلحاق أي ضرر كبير قد يؤدي إلى أي نتائج اجتماعية أو اقتصادية مهمة في حالة حدوث هجوم متعمد. , , , , , .
, , , . .
, , . , , , , , , , . , , , , , , .
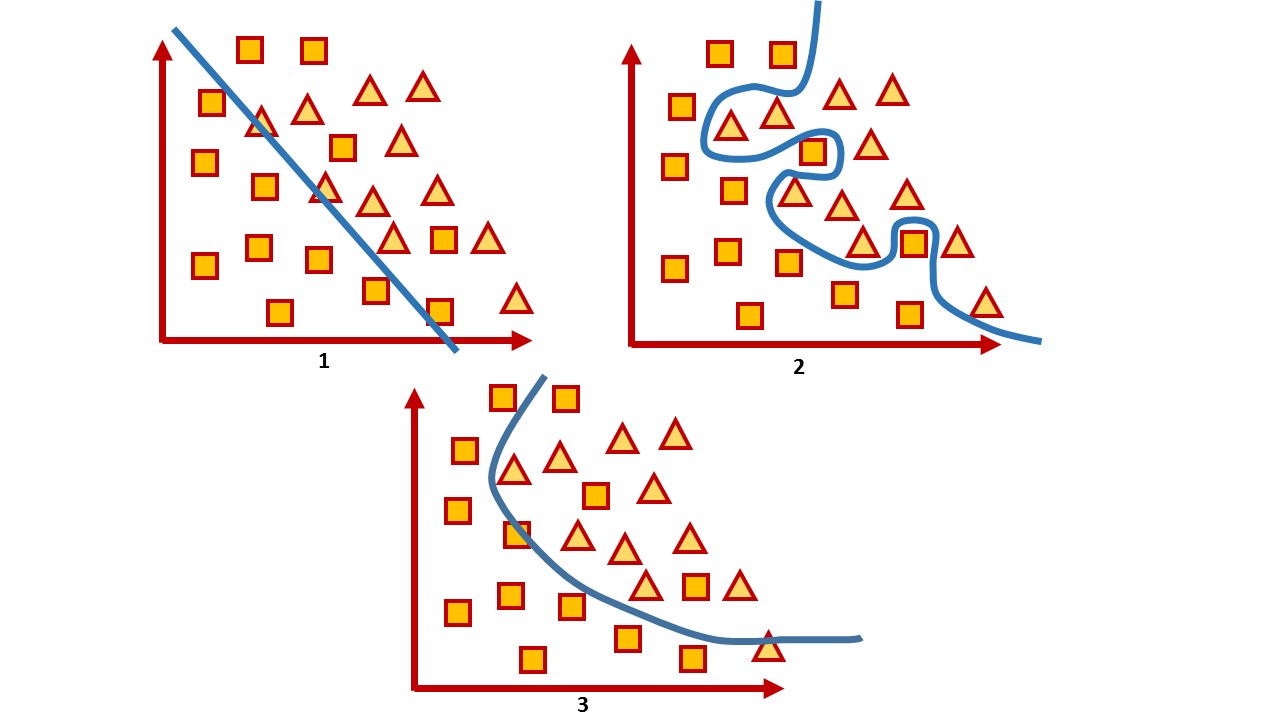
1 — , 2 — , 3 —
, , : . . , .
. , . , . 100%- - , .
- , — . , — , . , .
, , .
9. ?
. : , , , , .
, . . , . , , , «».
, - , . , , . - Twitter, Microsoft, .
? , , — , , . , , , — , , .
, , , « — , »?