معهد ماساتشوستس للتكنولوجيا. محاضرة رقم 6.858. "أمن أنظمة الكمبيوتر." نيكولاي زيلدوفيتش ، جيمس ميكنز. 2014 سنة
أمان أنظمة الكمبيوتر هي دورة حول تطوير وتنفيذ أنظمة الكمبيوتر الآمنة. تغطي المحاضرات نماذج التهديد ، والهجمات التي تهدد الأمن ، وتقنيات الأمان بناءً على العمل العلمي الحديث. تشمل الموضوعات أمان نظام التشغيل (OS) ، والميزات ، وإدارة تدفق المعلومات ، وأمان اللغة ، وبروتوكولات الشبكة ، وأمان الأجهزة ، وأمان تطبيقات الويب.
المحاضرة 1: "مقدمة: نماذج التهديد"
الجزء 1 /
الجزء 2 /
الجزء 3المحاضرة 2: "السيطرة على هجمات القراصنة"
الجزء 1 /
الجزء 2 /
الجزء 3 هل يمكنك أن تخبرني ما هو عدم وجود نهج أمني يستخدم
صفحة حراسة ؟
الجمهور: يستغرق وقتًا أطول!
الأستاذ: بالضبط! لذا ، تخيل أن هذا الكومة صغير جدًا جدًا ، لكنني اخترت صفحة كاملة للتأكد من أن هذا الشيء الصغير لم يتم مهاجمته بواسطة مؤشر. هذه عملية مكثفة للغاية ، ولا ينشر الأشخاص شيئًا كهذا في بيئة العمل. قد يكون هذا مفيدًا لاختبار "الأخطاء" ، ولكنك لن تفعل ذلك أبدًا لبرنامج حقيقي. أعتقد الآن أنك تفهم ما هو مصحح ذاكرة
السياج الكهربائي .
الجمهور: لماذا يجب أن تكون
صفحة الحماية كبيرة جدًا؟
الأستاذ: السبب هو أنهم عادة ما يعتمدون على الأجهزة ، مثل الحماية على مستوى الصفحة ، لتحديد أحجام الصفحات. بالنسبة لمعظم أجهزة الكمبيوتر ، يتم تخصيص صفحتين بحجم 4 كيلوبايت لكل مخزن مؤقت مخصص ، بإجمالي 8 كيلوبايت. بما أن كومة الذاكرة المؤقتة تتكون من كائنات ، يتم تخصيص صفحة منفصلة لكل دالة
malloc . في بعض الأوضاع ، لا يقوم مصحح الأخطاء هذا بإرجاع المساحة المحجوزة إلى البرنامج ، لذلك فإن
السياج الكهربائي شاسع جدًا من حيث الذاكرة ويجب ألا يتم تجميعه مع رمز العمل.
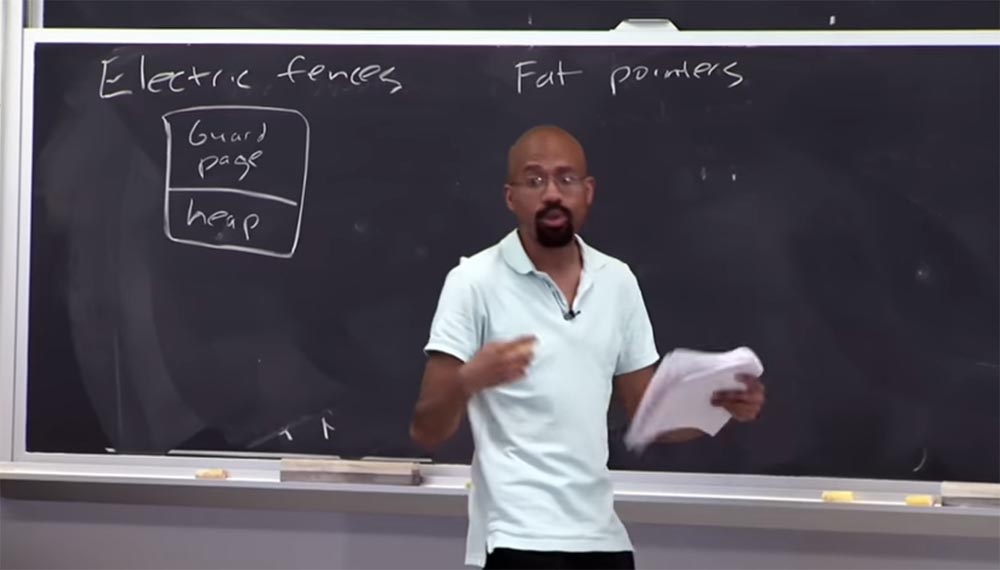
نهج أمني آخر يستحق إلقاء نظرة عليه يسمى
مؤشرات الدهون ، أو "مؤشرات سميكة". في هذه الحالة ، يعني المصطلح "سميك" أن كمية كبيرة من البيانات مرفقة بالمؤشر. في هذه الحالة ، الفكرة هي أننا نريد تغيير تمثيل المؤشر من أجل تضمين معلومات حول الحدود في تكوينه.
يتكون مؤشر 32 بت العادي من 32 بت ، والعناوين موجودة داخله. إذا اعتبرنا "المؤشر السميك" ، فإنه يتكون من 3 أجزاء. الجزء الأول عبارة عن قاعدة 4 بايت ، يتم إرفاق نهاية 4 بايت بها أيضًا. في الجزء الأول ، يبدأ الكائن ، في الثاني ينتهي ، وفي الثالث ، 4 بايت أيضًا ،
يتم تضمين عنوان العنوان. وضمن هذه الحدود المشتركة مؤشر.

وبالتالي ، عندما ينشئ المحول البرمجي رمز وصول لهذا "المؤشر السميك" ، فإنه يقوم بتحديث محتويات الجزء الأخير من
عنوان cur ويقوم في نفس الوقت بفحص محتويات أول جزأين للتأكد من عدم حدوث أي شيء سيئ مع المؤشر أثناء عملية التحديث.
تخيل أن لدي هذا الرمز:
int * ptr = malloc (8) ، هذا مؤشر يتم تخصيص 8 بايت له. بعد ذلك ، لدي بعض
حلقة التكرار التي توشك على تعيين قيمة معينة للمؤشر ، ثم يتبع ذلك زيادة مؤشر
ptr ++ . في كل مرة يتم تنفيذ هذا الرمز على العنوان
الحالي لمؤشر
عنوان cur ، فإنه يتحقق مما إذا كان المؤشر ضمن الحدود المحددة في الجزئين الأول والثاني.
هذا هو الحال في الكود الجديد الذي يولده المترجم. غالبًا ما تثير مجموعة عبر الإنترنت السؤال حول ما هو "رمز الأداة". هذا هو الرمز الذي يولده المترجم. أنت ، كمبرمج ، ترى فقط ما يظهر على اليمين - هذه الخطوط الأربعة. ولكن قبل هذه العملية ، يقوم المترجم بإدراج بعض كود C الجديد في
عنوان cur ، ويعين قيمة للمؤشر ويتحقق من الحدود في كل مرة.

وإذا تجاوزت القيمة الحدود المسموح بها عند استخدام الرمز الجديد ، فستتم مقاطعة الوظيفة. وهذا ما يسمى "رمز الأداة". هذا يعني أنك تأخذ شفرة المصدر باستخدام برنامج C ، ثم تضيف رمز مصدر C الجديد ، ثم تجمع البرنامج الجديد. لذا فإن الفكرة الأساسية وراء
مؤشرات Fat بسيطة جدًا.
هناك بعض العيوب لهذا النهج. أكبر عيب هو الحجم الكبير للمؤشر. وهذا يعني أنه لا يمكنك فقط أخذ "المؤشر السميك" وتمريره دون تغيير ، خارج مكتبة الصدفة. لأنه قد يكون هناك توقع بأن يكون للمؤشر حجم قياسي ، وسوف يقوم البرنامج بتزويده بهذا الحجم ، والذي "لن يتناسب معه" ، لأن كل شيء سوف ينفجر. هناك أيضًا مشاكل إذا كنت تريد تضمين مؤشرات من هذا النوع في
بنية أو شيء من هذا القبيل ، لأنها يمكن تغيير حجم
البنية .
لذلك ، هناك شيء شائع جدًا في الرمز C هو أخذ شيء بحجم الهيكل ، ثم القيام بشيء يعتمد على هذا الحجم - حجز مساحة القرص لهياكل بهذا الحجم ، وما إلى ذلك.
والشيء الأكثر حساسية هو أن هذه المؤشرات ، كقاعدة عامة ، لا يمكن تحديثها بطريقة ذرية. بالنسبة لبنيات 32 بت ، من المعتاد كتابة متغير 32 بت يكون ذريًا. لكن "المؤشرات السميكة" تحتوي على 3 أحجام
صحيحة ، لذلك إذا كان لديك رمز يتوقع أن يكون للمؤشر قيمة ذرية ، فقد تواجه مشكلة. لأنه من أجل القيام ببعض هذه الفحوصات ، عليك أن تنظر إلى العنوان الحالي ثم تنظر إلى الأحجام ، ومن ثم قد تضطر إلى زيادتها ، وهكذا دواليك. وبالتالي ، يمكن أن يتسبب هذا في أخطاء دقيقة للغاية إذا كنت تستخدم رمزًا يحاول رسم أوجه التشابه بين المؤشرات العادية والسميكة. وبالتالي ، يمكنك استخدام
مؤشرات الدهون في بعض الحالات ، مثل
الأسوار الكهربية ، ولكن الآثار الجانبية لاستخدامها كبيرة لدرجة أنه في الممارسة العادية لا يتم استخدام هذه الأساليب.
والآن سنتحدث عن التحقق من الحدود فيما يتعلق ببنية بيانات الظل. الفكرة الرئيسية للهيكل هي أنك تعرف حجم كل كائن ستقوم بوضعه ، أي أنك تعرف الحجم الذي تحتاج إلى حجزه لهذا الكائن. لذا ، على سبيل المثال ، إذا كان لديك مؤشر تتصل به وظيفة
malloc ، فأنت بحاجة إلى تحديد حجم الكائن:
char xp = malloc (size) .

إذا كان لديك شيء مثل متغير ثابت مثل هذا
الحرف ص [256] ، فإن المترجم يمكنه تلقائيًا معرفة ما يجب أن تكون الحدود لموضعه.
لذلك ، لكل من هذه المؤشرات ، تحتاج إلى إدراج عمليتين بطريقة أو بأخرى. هذا هو الحساب بشكل أساسي ، مثل
q = p + 7 ، أو شيء مماثل. يتم هذا الإدراج من خلال
إلغاء الإشارة إلى ارتباط من النوع
deref * q = 'q' . قد تتساءل لماذا لا يمكنك الاعتماد على الرابط عند اللصق؟ لماذا نحتاج إلى القيام بهذه العمليات الحسابية؟ والحقيقة هي أنه عند استخدام C و c ++ ، يكون لديك مؤشر يشير إلى تمرير واحد إلى النهاية الصحيحة للكائن على اليمين ، وبعد ذلك تستخدمه كشرط توقف. لذلك ، تذهب إلى الكائن وبمجرد وصولك إلى هذا المؤشر اللاحق ، فأنت في الواقع توقف الحلقة أو تحبط العملية.
لذا ، إذا تجاهلنا الحساب ، فإننا نتسبب دائمًا في خطأ فادح ، حيث يتجاوز المؤشر الحدود ، مما قد يعطل عمل العديد من التطبيقات. لذا لا يمكننا إدراج الرابط فقط ، لأنه كيف تعرف أن هذا يحدث خارج الحدود المحددة؟ يتيح لنا الحساب أن نقول ما إذا كان الأمر كذلك أم لا ، وهنا سيكون كل شيء قانونيًا وصحيحًا. لأن هذا الإسفين باستخدام الحساب يسمح لك بتتبع مكان المؤشر بالنسبة لخط الأساس الأصلي.
لذا فإن السؤال التالي هو: كيف نطبق بالفعل التحقق من الحدود؟ لأننا بحاجة إلى مطابقة العنوان المحدد للمؤشر بطريقة ما مع نوع من معلومات الحدود لهذا المؤشر. وبالتالي ، تستخدم العديد من قراراتك السابقة أشياء مثل ، على سبيل المثال ، جدول التجزئة أو شجرة ، مما يسمح لك بإجراء البحث الصحيح. لذا ، بالنظر إلى عنوان المؤشر ، أقوم ببعض البحث في بنية البيانات هذه ومعرفة الحدود التي يحتوي عليها. وبالنظر إلى هذه الحدود ، أقرر ما إذا كان يمكنني أن أترك الإجراء يحدث أم لا. تكمن المشكلة في أن هذا البحث بطيء ، لأن هياكل البيانات هذه متفرعة ، وعند فحص شجرة ، تحتاج إلى فحص مجموعة من هذه الفروع حتى تجد القيمة الصحيحة. وحتى إذا كان جدول التجزئة ، فعليك اتباع سلاسل التعليمات البرمجية وما إلى ذلك. وبالتالي ، نحتاج إلى تحديد بنية بيانات فعالة للغاية تتتبع حدودها ، بنية تجعل هذا التحقق بسيطًا وواضحًا للغاية. لذا دعنا نصل إليها الآن.
ولكن قبل أن نفعل ذلك ، دعني أخبرك باختصار شديد عن كيفية عمل نهج
تخصيص ذاكرة الأصدقاء . لأن هذا هو أحد الأشياء التي غالبًا ما يتم طرحها.
يقسم
تخصيص ذاكرة الأصدقاء الذاكرة إلى أقسام تعد مضاعفة قوة 2 ، ويحاول تخصيص طلبات الذاكرة فيها. دعونا نرى كيف يعمل. في البداية ، يعامل
تخصيص الأصدقاء الذاكرة غير المخصصة ككتلة واحدة كبيرة - هذا هو المستطيل العلوي 128 بت. بعد ذلك ، عندما تطلب كتلة أصغر للتخصيص الديناميكي ، فإنها تحاول تقسيم مساحة العنوان هذه إلى أجزاء بزيادات من 2 حتى تجد كتلة كافية لاحتياجاتك.
افترض أن طلبًا من النوع
a = malloc (28) وصل ، أي طلب تخصيص 28 بايت. لدينا 128 بايت كتلة مضيعة للغاية لتخصيصها لهذا الطلب. لذلك ، يتم تقسيم كتلتنا إلى مجموعتين من 64 بايت - من 0 إلى 64 بايت ومن 64 بايت إلى 128 بايت. وهذا الحجم كبير أيضًا لطلبنا ، لذلك يقسم
الأصدقاء مرة أخرى كتلة من 64 بايت إلى جزأين ويتلقى 2 كتل من 32 بايت.

الأقل هو المستحيل ، لأن 28 بايت لن يصلح ، و 32 هو الحجم الأدنى الأنسب. حتى الآن سيتم تخصيص هذه الكتلة 32 بايت لعنواننا أ. افترض أن لدينا استعلام آخر لـ
b = malloc (50) . يتحقق
Buddy من الكتل المحددة ، وبما أن 50 أكبر من نصف 64 ، ولكن أقل من 64 ، فإنها تضع القيمة b في الكتلة الموجودة في أقصى اليمين.
أخيرًا ، لدينا طلب آخر لـ 20 بايت:
c = malloc (20) ، يتم وضع هذه القيمة في الكتلة الوسطى.

لدى
Buddy خاصية مثيرة للاهتمام: عندما تقوم بتحرير ذاكرة في كتلة وبجانبها كتلة من نفس الحجم ، بعد تحرير كل من الكتل ، يجمع
الأصدقاء بين كتلتين متجاورتين فارغتين في واحدة.

على سبيل المثال ، عندما نعطي الأمر
free © ، سنحرر الكتلة الوسطى ، لكن الاتحاد لن يحدث ، لذا فإن الكتلة المجاورة له ستظل مشغولة. ولكن بعد تحرير الكتلة الأولى باستخدام الأمر
free (a) ، سيتم دمج الكتل في كتلة واحدة. بعد ذلك ، إذا قمنا بتحرير قيمة b ، يتم دمج الكتل المجاورة مرة أخرى ونحصل على كتلة كاملة من 128 بايت ، كما كان في البداية. ميزة هذا النهج هو أنه يمكنك بسهولة العثور على مكان الأصدقاء عن طريق الحساب البسيط وتحديد حدود الذاكرة. هذه هي الطريقة التي يعمل بها تخصيص الذاكرة مع نهج
تخصيص ذاكرة الأصدقاء .
غالبًا ما يتم طرح جميع محاضراتي على السؤال ، أليس هذا النهج مفرطًا؟ تخيل أنه في البداية كان لدي طلب للحصول على 65 بايت ، كان علي تخصيص كامل 128 بايت لذلك. نعم ، هذا مضيعة ، في الواقع ليس لديك ذاكرة ديناميكية ولم يعد بإمكانك تخصيص الموارد في نفس الكتلة. ولكن مرة أخرى ، هذا حل وسط ، لأنه من السهل جدًا إجراء عملية حسابية ، وكيفية إجراء الاندماج وما شابه ذلك. لذلك إذا كنت تريد تخصيص ذاكرة أكثر دقة ، فأنت بحاجة إلى استخدام نهج مختلف.
إذن ماذا يفعل نظام
التحقق من Buggy Bounce ؟

تقوم بعدة حيل ، أحدها فصل كتلة الذاكرة إلى قسمين ، أحدهما يحتوي على كائن ، والثاني هو إضافة إليه. وبالتالي ، لدينا نوعان من الحدود - حدود الكائن وحدود توزيع الذاكرة. الميزة هي أنه لا توجد حاجة لتخزين العنوان الأساسي ، ويمكن البحث السريع باستخدام جدول الأسطر.
جميع أحجام التوزيع لدينا هي 2 إلى قوة
n ، حيث
n عدد صحيح. يسمى هذا المبدأ
2n قوة اثنين . لذلك ، لا نحتاج إلى الكثير من البتات لتخيل حجم حجم توزيع معين. على سبيل المثال ، إذا كان حجم الكتلة هو 16 ، فأنت بحاجة فقط إلى تحديد 4 بت - وهذا هو مفهوم اللوغاريتم ، أي أن 4 هو أس
n ، حيث تحتاج إلى رفع الرقم 2 للحصول على 16.
هذا هو نهج اقتصادي إلى حد ما لتخصيص الذاكرة ، لأنه يتم استخدام الحد الأدنى من وحدات البايت ، ولكن يجب أن يكون مضاعفًا 2 ، أي أنه يمكن أن يكون لديك 16 أو 32 ، ولكن ليس 33 بايت. بالإضافة إلى ذلك ، يسمح لك
التحقق من Buggy بتخزين المعلومات حول القيم الحدودية في صفيف خطي (1 بايت لكل سجل) ويسمح لك بتخصيص الذاكرة في فتحة واحدة بحجم 16 بايت. تخصيص الذاكرة مع دقة فتحة. ماذا يعني هذا؟

إذا كان لدينا فتحة 16 بايت حيث سنضع القيمة
p = malloc (16) ،
فستبدو القيمة في الجدول مثل
الجدول [p / slot.size] = 4 .

لنفترض أننا نحتاج الآن إلى وضع قيمة 32 بايت بحجم
p = malloc (32) . نحتاج إلى تحديث جدول الحدود ليتناسب مع الحجم الجديد. ويتم ذلك مرتين: أولاً
كجدول [p / slot.size] = 5 ، ثم
كجدول [(p / slot.size) + 1] = 5 - المرة الأولى للفتحة الأولى المخصصة لهذه الذاكرة ، والثانية مرات - للفتحة الثانية. وهكذا نخصص 32 بايت من الذاكرة. هذا ما يبدو عليه سجل توزيع الحجم. وبالتالي ، يتم تحديث جدول الحدود مرتين لفتحتين لتخصيص الذاكرة. هل هذا واضح؟ هذا المثال مخصص للأشخاص الذين يشكون في ما إذا كان للسجلات والجداول معنى أم لا. لأنه يتم ضرب الجداول في كل مرة يحدث تخصيص الذاكرة.
دعونا نرى ما يحدث مع جدول الحدود. لنفترض أن لدينا رمز C يبدو كما يلي:
p '= p + i ، أي أن المؤشر
p' يتم الحصول عليه من
p بإضافة بعض المتغير
i . فكيف نحصل على حجم الذاكرة المخصصة ل
p ؟ للقيام بذلك ، انظر إلى الجدول باستخدام الشروط المنطقية التالية:
size = 1 << جدول [p >> log of slot_size]
على اليمين لدينا حجم البيانات المخصصة لـ
p ، والتي يجب أن تكون 1. ثم تحركها إلى اليسار وتنظر إلى الجدول ، وتأخذ حجم المؤشر هذا ، ثم تنتقل إلى اليمين ، حيث يوجد سجل جدول حجم الفتحة. إذا نجحت العمليات الحسابية ، فسنربط المؤشر بشكل صحيح بجدول الحد. بمعنى ، يجب أن يكون حجم المؤشر أكبر من 1 ، ولكنه أصغر من حجم الفتحة. على اليسار لدينا القيمة ، وعلى اليمين - حجم الفتحة ، وقيمة المؤشر تقع بينهما.
افترض أن حجم المؤشر هو 32 بايت ، ثم في الجدول ، داخل الأقواس ، سيكون لدينا الرقم 5.
لنفترض أننا نريد العثور على الكلمة الأساسية الأساسية لهذا المؤشر:
base = p & n (الحجم - 1) . ما سنفعله يعطينا كتلة معينة ، وهذه الكتلة ستسمح لنا باستعادة
القاعدة الموجودة هنا. تخيل أن حجمنا هو 16 ، في ثنائي هو 16 = ... 0010000. القطع الناقص يعني أنه لا يزال هناك العديد من الأصفار ، لكننا مهتمون بهذه الوحدة والأصفار التي خلفها. إذا أخذنا بعين الاعتبار (16 -1) ، فسيبدو الأمر كالتالي: (16 - 1) = ... 0001111. في الكود الثنائي ، سيبدو معكوس هذا كالتالي: ~ (16-1) ... 1110000.
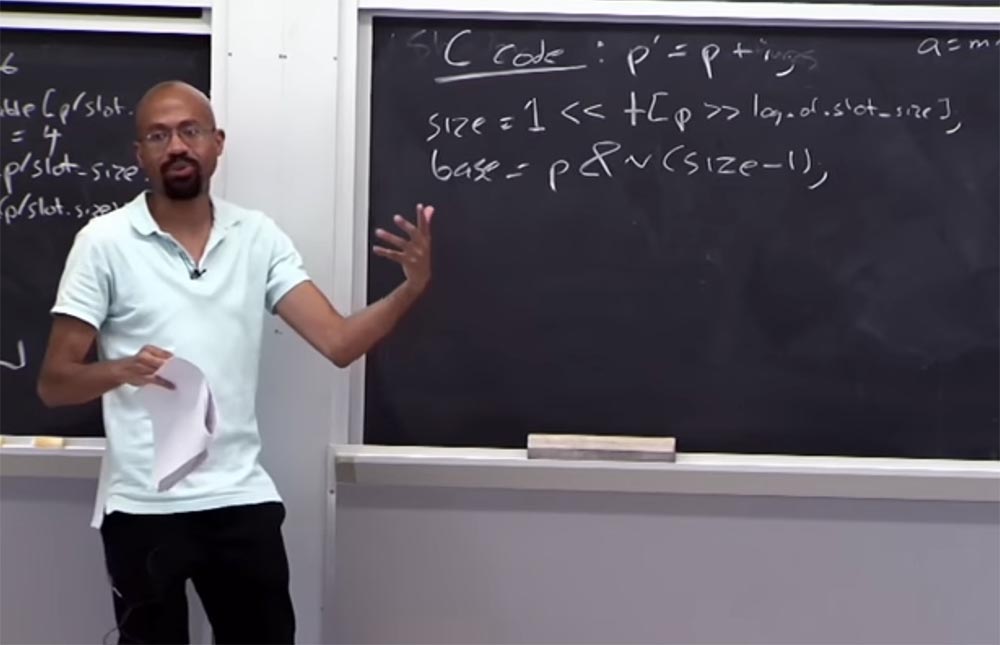

وبالتالي ، يتيح لنا هذا الشيء مسح البت بشكل أساسي ، والذي سيتم تقديمه بشكل أساسي من المؤشر الحالي وإعطائنا
قاعدته . وبفضل هذا ، سيكون من السهل جدًا علينا التحقق مما إذا كان هذا المؤشر داخل الحدود أم لا. لذا يمكننا ببساطة التحقق من أن
(p ')> = base وما إذا كانت القيمة (
p' - base) أصغر من الحجم المحدد.

هذا شيء بسيط إلى حد ما لمعرفة ما إذا كان المؤشر ضمن حدود الذاكرة. لن أخوض في التفاصيل ؛ يكفي أن نقول أن جميع العمليات الحسابية الثنائية يتم حلها بنفس الطريقة. تسمح لك هذه الحيل بتجنب الحسابات الأكثر تعقيدًا.
هناك خاصية خامسة أخرى
للتحقق من ارتداد Buggy - فهي تستخدم نظام ذاكرة افتراضية لمنع تجاوز الحدود المحددة للمؤشر. الفكرة الرئيسية هي أنه إذا كان لدينا مثل هذا الحساب للمؤشر الذي نحدد به المخرج ، فيمكننا تعيين بت عالي الترتيب للمؤشر.

من خلال القيام بذلك ، نضمن أن إلغاء الإشارة إلى المؤشر لن يسبب مشاكل في الأجهزة. لا يؤدي تعيين
بت مرتفع مرتفع من تلقاء نفسه إلى حدوث مشكلات ؛ فقد يؤدي إلغاء الإشارة إلى المؤشر إلى حدوث مشكلة.
النسخة الكاملة من الدورة متاحة
هنا .
شكرا لك على البقاء معنا. هل تحب مقالاتنا؟ هل تريد رؤية مواد أكثر إثارة للاهتمام؟ ادعمنا عن طريق تقديم طلب أو التوصية به لأصدقائك ،
خصم 30 ٪ لمستخدمي Habr على نظير فريد من خوادم مستوى الدخول التي اخترعناها لك: الحقيقة الكاملة حول VPS (KVM) E5-2650 v4 (6 نوى) 10GB DDR4 240GB SSD 1Gbps من 20 $ أو كيفية تقسيم الخادم؟ (تتوفر الخيارات مع RAID1 و RAID10 ، حتى 24 مركزًا وحتى 40 جيجابايت DDR4).
ديل R730xd أرخص مرتين؟ فقط لدينا
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV من 249 دولارًا في هولندا والولايات المتحدة! اقرأ عن
كيفية بناء مبنى البنية التحتية الطبقة باستخدام خوادم Dell R730xd E5-2650 v4 بتكلفة 9000 يورو مقابل سنت واحد؟