
انتهت
المرحلة المؤهلة من DataScienceGame2018 ، التي جرت بتنسيق kaggle InClass ، مؤخرًا.
DataScienceGame عبارة عن مسابقة دولية للطلاب تُقام سنويًا. تمكن فريقنا من أن يكون في المركز الثالث من بين أكثر من 100 فريق وفي نفس الوقت لا تذهب إلى المرحلة النهائية.
تفاعل الفريق

في مسابقات kaggle الكبيرة ، عادة ما يتم تشكيل الفرق على طول الطريق من الأشخاص الذين يتقدمون تقريبًا على لوحة الصدارة (
مثال نموذجي للفريق ) ، وبالتالي يمثلون مدنًا مختلفة ، وغالبًا ، بلدان مختلفة. على الفور ، وفقًا لشروط المسابقة ، يجب أن يتكون كل فريق من 4 أشخاص من مؤسسة تعليمية واحدة (مثلنا MIPT). وهذا يعني أن معظم المشاركين ، كما يبدو لي ، جرت جميع المناقشات دون اتصال بالإنترنت. على سبيل المثال ، كان لدينا الفريق بأكمله يعيش في طابق واحد من بيت الشباب ، لذلك اجتمعنا للتو في المساء مع شخص ما في الغرفة.
لم يكن لدينا فصل بين المهام أو التخطيط أو بناء الفريق. في بداية المسابقة ، جلسنا في دائرة ، وناقشنا ما يمكننا القيام به في المستقبل ولم نفعل. تم كتابة الرمز من قبل شخص واحد ، والبقية في ذلك الوقت نظروا ببساطة وقدموا المشورة. لا أحب حقًا كتابة التعليمات البرمجية ، لذلك أحببت هذا التفاعل ، على الرغم من حقيقة أنه لم يكن الأفضل. ولكن بما أن مرحلة التأهل سقطت بالضبط في الجلسة في الجامعة ، فلم يتمكن جزء من الفريق من تكريس الكثير من الوقت وما زلت أضطر إلى كتابة الرمز بنفسي.
وصف المهمة
وفقًا للتاريخ الذي قدمه BNP ، كان من الضروري التنبؤ بما إذا كان المستخدم مهتمًا ببعض الأمان (Isin) الأسبوع المقبل أم لا. في الوقت نفسه ، تم تحديد "الفائدة" من خلال عمود TradeStatus ، الذي وصف حالة المعاملة وكان له القيم الفريدة التالية:
- اكتملت المعاملة (أي أن المستخدم اشترى / باع الورق)
- نظر المستخدم إلى الورقة ، لكنه لم يكمل المعاملة
- وضع المستخدم جانبا الورق لشراء / بيع في المستقبل
- لم تكتمل المعاملة لأسباب فنية.
- القابضة
لذلك ، إذا أخذت TradeStatus القيمة 1) -4) ، فيعتبر أن المستخدم كان مهتمًا بهذه الورقة ولم يكن مهتمًا بجميع الحالات الأخرى. وفي الوقت نفسه ، أشارت الفقرة 4) إلى أن الخط مع هذه المعاملة كان وهميًا ، وتم إعداده لإعداد تقارير ملائمة. وبالتحديد ، في نهاية كل شهر ، تمت مقارنة حالة حافظة كل مستخدم بالحالة التي كان عليها قبل شهر ، وإذا كان المستخدم ، على سبيل المثال ، في الحافظة بطريقة أو بأخرى ، زاد مبلغ تأمين معين بمقدار 10 آلاف ، فإن هذا السطر يشير إلى "شراء" ومع قيمة اسمية 10k. تحتوي الخطوط التي تحمل علامة "Hold" على متغير هدف 0 (لم يكن المستخدم مهتمًا).
إذا فكرت في الأمر ، يمكنك أن تفهم أن مجموعة البيانات كانت تسير على النحو التالي: كان المستخدمون نشطين على موقع البنك على الإنترنت - لقد بحثوا / اشتروا أوراقًا ، وتم تسجيل جميع هذه الإجراءات في قاعدة البيانات. على سبيل المثال ، قرر مستخدم لديه معرف = 15 تأجيل ورقة ذات معرف = 7 لعمليات الشراء المستقبلية. على الفور في قاعدة البيانات ظهر السطر المقابل للهدف 1 (أصبح المستخدم مهتمًا)
| معرف المستخدم | معرف الأمان | نوع المعاملة | حالة الصفقة | حقول إضافية | الهدف |
|---|
| 15 | 7 | الشراء | ضع جانبا للمستقبل | ... | 1 |
بالإضافة إلى ذلك ، تمت إضافة سجلات شهرية مع حالة الحفظ والهدف 0 إلى ذلك. على سبيل المثال ، زاد المستخدم 15 عدد المشاركات 93 لسبب ما (ربما قام بشرائه على موقع آخر) ، بينما هو نفسه لم يستخدم هذه الورقة على موقع BNP تفاعلت (غير مهتم).
| معرف المستخدم | معرف الأمان | نوع المعاملة | حالة الصفقة | حقول إضافية | الهدف |
|---|
| 15 | 93 | الشراء | القابضة | ... | 0 |
ولكن ، من الواضح ، بالنسبة لـ BNP ، ليس هناك جدوى من توقع هذه الحيازات نفسها ، لأنه يمكن استعادتها بشكل لا لبس فيه من القاعدة. وهذا يعني أن هناك نوعًا آخر من الرموز المميزة غير المدرجة في جدول التدريب ، أي أي "مستخدم - ورق - نوع معاملة" ثلاث مرات لم تظهر في قاعدة البيانات. أي أن المستخدم لم يكن مهتمًا بإجراء معين ، مما يعني أنه لم يتفاعل معه في نظام BNP ، لذلك لم يظهر السطر المقابل في قاعدة البيانات ، مما يعني أنه يجب أن يكون له هدف 0. وهذا يشير إلى أنك بحاجة إلى إنشاء مثل هذه الخطوط للتدريب بنفسك ( انظر قسم "تجميع عينة تدريبية"). كل هذا يمكن أن يؤدي إلى بعض الارتباك ، لأن العديد من المشاركين ربما اعتقدوا - هناك مجموعة بيانات ، وهناك أصفار وأخرى - يمكنك التنبؤ بها. ولكن ليس بهذه البساطة.
لذلك ، يوجد في القطار جدول يحتوي على تاريخ المعاملات (أي تفاعل "المستخدم - الورق - نوع المعاملة" وبعض المعلومات الإضافية عنها) ومجموعة من اللوحات الأخرى التي تتميز بخصائص المستخدم والأسهم وظروف السوق العالمية. يوجد في الاختبار ثلاث مرات فقط "نوع المعاملة - ورقة - نوع المعاملة" ولكل مثل هذه الثلاثية ، تحتاج إلى توقع ما إذا كانت ستظهر الأسبوع المقبل. على سبيل المثال ، تحتاج إلى توقع ما إذا كان معرف المستخدم = 8 سيكون مهتمًا بمعرف الإجراء = 46 مع نوع المعاملة "بيع"؟
| معرف المستخدم | معرف الأمان | نوع المعاملة | الهدف |
|---|
| 8 | 46 | للبيع | ؟؟؟ |
ميزات بناء مجموعة البيانات
بما أنه ، كما قلت بالفعل ، في قاعدة بيانات BNP الحقيقية لم يكن هناك خطوط مع الأصفار "غير القابضة" ، قام المنظمون بطريقة أو بأخرى بتوليد مثل هذه الخطوط للاختبار بأنفسهم. وحيث يوجد توليد بيانات اصطناعي ، غالبًا ما تكون هناك وجوه ومعلومات ضمنية أخرى يمكن أن تحسن النتيجة بشكل كبير دون تغيير النماذج / الميزات. يصف هذا القسم بعض ميزات بناء مجموعة بيانات تمكنا من فهمها ، لكنها للأسف لم تساعدنا بأي شكل من الأشكال.

إذا نظرت إلى ثلاثة أضعاف "المستخدم - الورق - نوع المعاملة" من جدول الاختبار ، فمن السهل ملاحظة أن عدد المعاملات مع نوعي "الشراء" و "البيع" هو نفسه تمامًا ، ويتم فرز الجدول بدقة حسب هذه السمة: أولاً جميع عمليات الشراء ، ثم كل مبيعات. من الواضح أن هذا ليس مصادفة ويطرح السؤال: كيف يمكن أن يحدث هذا؟ على سبيل المثال ، بهذه الطريقة: قام المنظمون بأخذ جميع السجلات الحقيقية من قاعدة بياناتهم للأسبوع الذي نحتاج إليه للتنبؤ (مثل هذه الخطوط لها هدف 1) ، بطريقة أو بأخرى إنشاء خطوط جديدة (هدفهم هو 0) ، والتي لا تتزامن مع تلك الموضحة أعلاه. لذلك تبين الجدول الذي يتم فيه ترتيب أنواع المعاملات (الشراء / البيع) بترتيب عشوائي:
| معرف المستخدم | معرف الأمان | نوع المعاملة | الهدف |
|---|
| 8 | 46 | للبيع | 1 |
| 2 | 6 | الشراء | 1 |
| 158 | 73 | الشراء | 1 |
| 3 | التاسع والعشرون | للبيع | 0 |
| 67 | 9 | الشراء | 0 |
| 17 | 465 | للبيع | 0 |
الآن من الممكن تعيين نوع الشراء على جميع الأسطر بنوع المعاملة "بيع" ، وإذا كان الهدف واحدًا ، فسيصبح صفرًا (في معظم الحالات ، كان المستخدم مهتمًا ببعض الأوراق بحالة واحدة فقط: إما الشراء أو البيع). سينتج عن هذا الجدول التالي:
| معرف المستخدم | معرف الأمان | نوع المعاملة | الهدف |
|---|
| 8 | 46 | الشراء | 0 |
| 2 | 6 | الشراء | 1 |
| 158 | 73 | الشراء | 1 |
| 3 | التاسع والعشرون | الشراء | 0 |
| 67 | 9 | الشراء | 0 |
| 17 | 465 | الشراء | 0 |
تبقى الخطوة الأخيرة: أن تفعل الشيء نفسه ، ولكن استبدال "شراء للبيع" وترتيب الأهداف الصحيحة:
| معرف المستخدم | معرف الأمان | نوع المعاملة | الهدف |
|---|
| 8 | 46 | للبيع | 1 |
| 2 | 6 | للبيع | 0 |
| 158 | 73 | للبيع | 0 |
| 3 | التاسع والعشرون | للبيع | 0 |
| 67 | 9 | للبيع | 0 |
| 17 | 465 | للبيع | 0 |
تسلسل الجدول بـ "المشتريات" والجدول بـ "المبيعات" نحصل (إذا كنا المنظمين) على جدول كما هو موضح لنا في الاختبار. من السهل أن نفهم أن النصفين الأول والثاني للجداول التي تم إنشاؤها بهذه الطريقة لها نفس الترتيب من أزواج ورق المستخدم ، والتي اتضح أنها في الواقع في جدول الاختبار.
ميزة أخرى هي أنه كان هناك الكثير من الخطوط في مجموعة بيانات التدريب حيث تم تكرار مؤشر المستخدم عدة مرات على التوالي ، على الرغم من حقيقة أن مجموعة البيانات لم يتم فرزها حسب أي من العلامات:
| معرف المستخدم | معرف الأمان | نوع المعاملة | الهدف |
|---|
| 8 | 46 | للبيع | ؟؟؟ |
| 8 | 152 | للبيع | ؟؟؟ |
| 8 | 73 | الشراء | ؟؟؟ |
اعتبر زميل الفريق أن هذا أمر طبيعي ، وتم فرز مجموعة البيانات في البداية حسب معرف المستخدم ، وقام المنظمون ببساطة بإفسادها بشكل سيئ (على سبيل المثال ، إذا تم ترتيب المراوغة على التباديل العشوائية ولم يكن هناك ما يكفي من هذه التباديل). في محاولة للتأكد من ذلك ، مر بأربعة مراوغات من مكتبات مختلفة ، ولكن لم يحدث مثل هذا التكرار المتكرر في أي مكان. كان الاختبار أيضا هذه الميزة. كانت هناك فكرة أن المنظمين لم يولدوا الأصفار ، ولكنهم ببساطة أخذوا الأزواج القديمة من القطار. للتحقق ، قررت القيام بما يلي: لكل زوج "ورقة عمل" من الاختبار ، قارن رقم الخط من القطار عندما التقى هذا الزوج لأول مرة وقم بعمل مخطط من هذا. هذا ، على سبيل المثال ، ننظر إلى السطر الأول في الاختبار ، والسماح له بمعرف المستخدم = 8 و id = paper = 15. والآن ننتقل إلى جدول التدريب من الأعلى إلى الأسفل ونبحث عن أول ظهور لهذا الزوج ، فليكن ، على سبيل المثال ، الخط 51. حصلنا على مقارنة: الخط الأول في الاختبار كان في القطار 51 ، لذلك قمنا برسم النقطة بإحداثيات (1 ، 51) على الرسم البياني. نقوم بذلك للاختبار بأكمله ونحصل على الرسم البياني التالي:
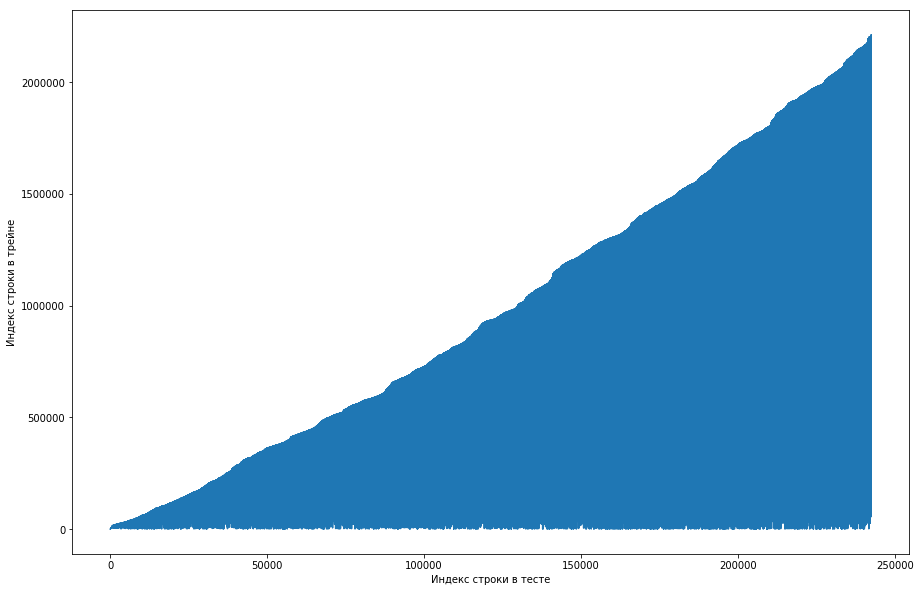
يمكن ملاحظة ذلك من حيث أنه ، إذا كان الزوجان قد التقيا من قبل في القطار ، فسيكون موقعه أعلى في طاولة الاختبار. ولكن في الوقت نفسه ، هناك بعض الارتفاعات في الرسم البياني (لا يوجد الكثير منها في الواقع ، ولكن بسبب دقة الشاشات يبدو أن هناك مثلثًا صلبًا). علاوة على ذلك ، تزامن عدد الانبعاثات تقريبًا مع العدد المتوقع للوحدات في الاختبار. بالطبع ، حاولنا وضع علامة على الانبعاثات كوحدات وإرسالها إلى ليدربورد ، ولكن للأسف ، لم تنجح. ولكن لا يزال يبدو لي أنه قد يكون هناك نوع من الوجوه () ، وكقائد للفريق ، اقترحت قضاء المزيد من الوقت على كيفية فهم كيفية حدوث ذلك ، ولا يزال لدينا الوقت لتدريب النماذج وتوليد العلامات. إخلاء المسؤولية: لقد أمضينا الكثير من الوقت في هذا الأمر ، ولكن قبل أسبوع من نهاية المسابقة كتب المنظمون في المنتدى أنه تم أخذ ثلاث مرات فقط خلال الأشهر الستة الماضية في مجموعة بيانات الاختبار ، وليس جميعًا. حسنًا ، إذا أجريت العمليات الموضحة أعلاه ، ولكن خلال الأشهر الستة الماضية ، وليس فقط مجموعة البيانات ، فستحصل على منحنى رتيب مسطح:
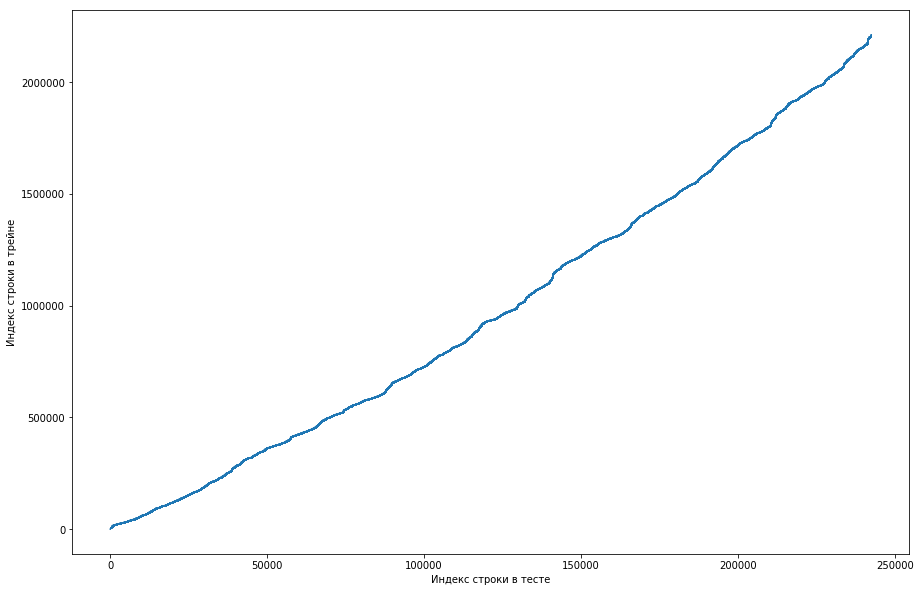
وهذا يعني أنه لا يوجد وجه هنا ولا يمكن أن يكون.
تم إعداد التدريب
نظرًا لأنك في الاختبار تحتاج إلى إجراء توقع لثلاث مرات لمدة أسبوع واحد ، فسنقسم مجموعة بيانات التدريب إلى أسابيع (في نفس الوقت ، هناك متوسط 20 ألف ثلاث مرات "المستخدم - الورق - نوع المعاملة"). الآن لأي ثلاثة ، يمكننا القول ما إذا كانت قد التقت في أسبوع معين أم لا. في الوقت نفسه ، لدينا بالفعل ثلاثيات إيجابية (هذه كلها إدخالات من هذا الأسبوع في جدول القطار) ، ويجب إنشاء العناصر السلبية بطريقة أو بأخرى. هناك العديد من الخيارات لكيفية القيام بذلك. على سبيل المثال ، يمكنك فرز جميع الثلاثيات التي لم تكن موجودة لمدة أسبوع معين في مجموعة بيانات التدريب. من الواضح أن العينة ستكون غير متوازنة للغاية ، وهذا أمر سيئ. يمكنك أولاً إنشاء مستخدمين بما يتناسب مع تكرار حدوثهم في مجموعة البيانات ، ثم إضافة عروض ترويجية لهم بطريقة أو بأخرى. ولكن مع هذا النهج ، سيكون هناك مجموعة من الخطوط التي لا يمكن حساب إحصائيات معقولة لها ، وهو أمر سيئ أيضًا. كما فعلنا: أخذنا جميع أنواع الثلاثيات التي تمت مواجهتها سابقًا في القطار ، وقمنا بنسخها ، واستبدال شراء / بيع بالآخر ، وربط هذين الجدولين. من الواضح أنه كان من الممكن حدوث التكرارات بهذه الطريقة (على سبيل المثال ، إذا اشترى المستخدم سهمًا وباعه) ، ولكن كان هناك القليل منها ، وبعد الحذف تم الحصول على جدول 500 ألف ثلاث مرات فريدة. هذا كل شيء ، الآن كل أسبوع لكل مثل هذه الثلاثية ، يمكنك القول ما إذا كانت قد التقت أم لا (وكم مرة؟).
نظرًا لأننا نتعامل في الأساس مع السلاسل الزمنية - ينظر المستخدم إلى إعلان معين عدة مرات كل أسبوع ، فسننشئ جدولًا لتدريب المصنف بطريقة كلاسيكية للسلاسل الزمنية. وبالتحديد ، سنأخذ آخر أسبوع متاح من القطار ، ونرى ما إذا كان كل ثلاثة "زبون - isin - شراء أو بيع" يلتقون هذا الأسبوع. سيكون هدفا. وسنحتسب إحصاءات مختلفة كميزات ، على سبيل المثال ، على مدى الأسابيع الستة الماضية (مزيد من المعلومات عن الإحصاءات في قسم "العلامات"). الآن دعنا ننسى وجود الأسبوع الماضي ونفعل الشيء نفسه ، ولكن للأسبوع قبل الأخير وسلس الجداول. يمكن القيام بذلك عدة مرات ، وبالتالي زيادة قطار "الارتفاع" ، ولكن في نفس الوقت ، ينخفض الفاصل الزمني الذي نعتبر فيه الإحصائيات بشكل طبيعي. لقد كررنا هذه العملية 10 مرات ، لأنه إذا فعلنا المزيد ، فسيتم استهداف عطلة رأس السنة الجديدة والمشاكل ذات الصلة ، مما سيؤدي إلى تدهور الجودة النهائية للنموذج. صورة توضيحية:
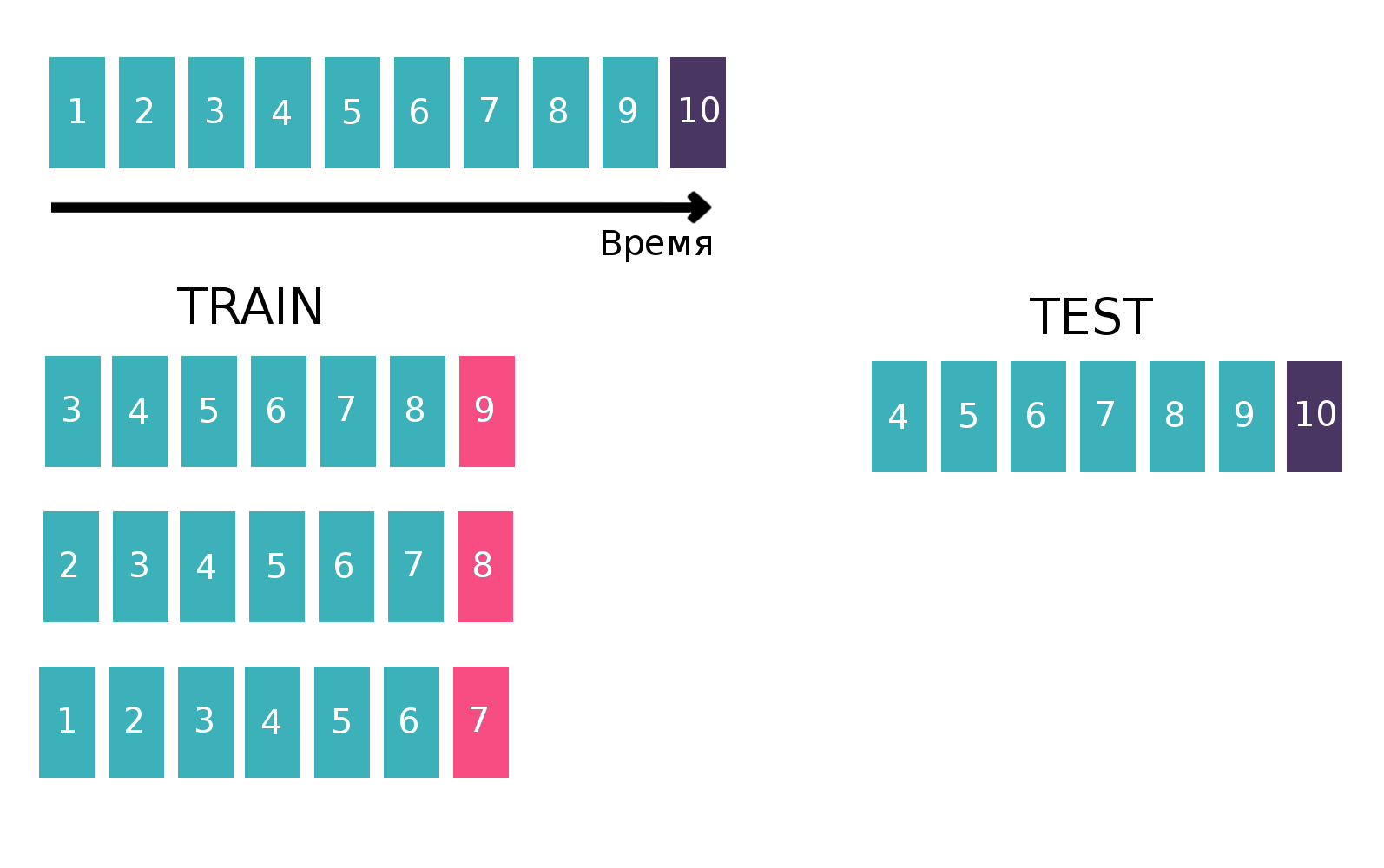
يمكن العثور على مزيد من المعلومات حول السلاسل الزمنية والتحقق من السلاسل الزمنية
هنا .
علامات
كما قلت ، كان هناك العديد من الجداول التي ميزت بطريقة أو بأخرى ظروف المستخدم أو الأسهم أو السوق العالمية (العملات الرئيسية وبعض المؤشرات). ولكن جميعها لم تحسن الجودة تقريبًا ، وكانت العلامات الرئيسية هي إحصائيات محسوبة لأزواج "زبون - إيسين" وثلاث مرات "زبون - إيسين - شراء أو بيع" ، على سبيل المثال ، مثل:
- كم مرة التقى زوجان / ثلاثة في آخر 1 ، 2 ، 5 ، 20 ، 100 أسبوع؟
- إحصائيات حول الفترات الزمنية بين اجتماعات الزوج / الثلاثيات في مجموعة البيانات (المتوسط ، القياسي ، الحد الأقصى ، الحد الأدنى)
- المسافة في الوقت إلى المرة الأولى / الأخيرة التقى زوجين / ثلاثة
- نسبة كل قيمة TradeStatus للزوج / الثلاثي
- إحصائيات حول عدد مرات حدوث الزوج / الثلاثي أسبوعيًا (المتوسط ، القياسي ، الحد الأقصى ، الحد الأدنى)
بالإضافة إلى ذلك ، في اليوم الأخير من المسابقة قرأت في النموذج أنه من أجل بيع الأسهم ، يجب عليك أولاً شرائه. تسمح لك هذه المعرفة بالخروج بالعديد من العلامات المفيدة ، ولكن ، لسبب ما ، لم تكن واضحة.
في الكود ، تم التعبير عن هذا كله من خلال وظيفة طولها 200 خط ، والتي ولدت علامات مماثلة لكل من عشر قطع من القطار (للجزء حيث الهدف ، على سبيل المثال ، الأسبوع 7 ، لا ينبغي لنا استخدام المعلومات لل 8 و 9). مع الأخذ في الاعتبار الجداول الإضافية ، تم تجنيد حوالي 300 علامة. كما قلت من قبل ، قمنا بتوليد 500 ألف ثلاثية فريدة من نوعها واستغرقنا الأسابيع العشرة الأخيرة كأهداف ، وبالتالي كان جدول التدريب "العالي" 500 ألف * 10 = 5 آلاف خط.
تم وصف المزيد من الاعترافات في
قرار المركز الثاني . قام الرجال ببناء طاولة مستخدم / ورقة ، حيث توجد في كل خلية وحدة إذا كان المستخدم مهتمًا بهذه الورقة ولا شيء على الإطلاق. من خلال حساب مسافة جيب التمام بين المستخدمين في هذا الجدول ، يمكنك الحصول على تقارب المستخدمين فيما بينهم. إذا قمت بتطبيق PCA على جدول التشابه الناتج ، فستحصل على مجموعة من الميزات التي تميز المستخدم بطريقة ما.
نماذج أو قتال من أجل الألف
من الجدير بالذكر أنه لمدة ثلاثة أسابيع تقريبًا لم يتمكن أحد من التغلب على خط الأساس من BNP ، الذي كان بسرعة 0.794 (ROC AUC) على لوحة الصدارة ، وهذا على الرغم من حقيقة أن قرار "ببساطة حساب عدد المرات التي التقى فيها الزوجان في وقت سابق" أعطى 0.71 على لوحة الصدارة ، وبعض تلقى المشاركون جميع 0.74 دون استخدام التعلم الآلي.
لكننا استخدمنا التعلم الآلي ، في اليوم الأخير من المسابقة (الذي تزامن مع نهاية الجلسة) ، قررنا التوقف
إذا كنت تعرف ما أعنيه وقم بعمل مزيج كبير من النماذج المختلفة المدربة على مجموعات فرعية مختلفة من العلامات بأرقام مختلفة من الأسابيع في قطار. كما سبق أن قلت ، تتكون عينة التدريب لدينا من 1.5 ألف خط ، بهدف واحد منهم حوالي 150 ألف. كان حجم الاختبار 400 ألف ، في حين أن العدد التقديري للوحدات كان 20 ألفًا (في المتوسط ، في الواقع ، هناك العديد من الثلاثيات الفريدة). أي أن نسبة الوحدات في الاختبار كانت أعلى بكثير منها في القطار. لذلك ، في جميع نماذجنا ، قمنا بتعديل معلمة scale_pos_weight ، التي تضع الوزن على الفئات. يمكن العثور على مزيد من المعلومات حول هذه المعلمة في
تحليل أفضل حل لأحد DataScienceGame العام الماضي. يتم عرض مصفوفة الارتباط لتنبؤات نماذجنا في الشكل:
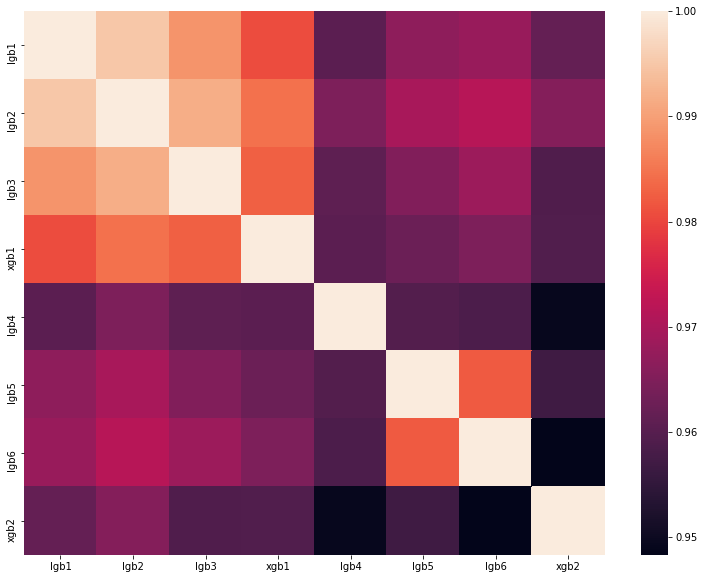
كما ترون ، كان لدينا الكثير من النماذج المختلفة تمامًا ، والتي سمحت لنا بالحصول على سرعة 0.80204 على لوحة الصدارة.
لماذا لا نذهب إلى فرنسا للمرحلة النهائية
ونتيجة لذلك ، أظهرنا نتيجة جيدة واحتلنا المركز الثالث في قائمة المتصدرين الخاصة. لكن المنظمين وضعوا القواعد التالية لاختيار المتأهلين للتصفيات النهائية:
- لا يزيد عن 20 فريقا
- لا يزيد عن 5 فرق أفضل من البلد
- ما لا يزيد عن فريق واحد من مؤسسة تعليمية
وسيكون كل شيء على ما يرام إذا لم يكن فريق آخر من معهد موسكو للفيزياء والتكنولوجيا بسرعة 0.80272 في المركز الثاني. أي أننا متأخرون 0.00068 فقط. إنه لأمر مخز ، ولكن لا يوجد شيء يجب القيام به. على الأرجح ، وضع المنظمون مثل هذه القواعد حتى لا يساعد الأشخاص من إحدى الجامعات بعضهم البعض بأي شكل من الأشكال ، ولكن في حالتنا ، لم نكن نعرف أي شيء عن الفريق المجاور ولم نتصل به بأي شكل.
الملخص
هذا العام في شهر سبتمبر في باريس ، ستتنافس 5 فرق من روسيا ، وواحد من أوكرانيا وفريقان من ألمانيا وفنلندا ، يتألفان من الطلاب الناطقين بالروسية ، على المركز الأول. ما مجموعه 8 فرق من مجتمع ru ، والتي تثبت مرة أخرى هيمنة قطاع ru من datasaens.
وسأنتقل إلى شراغا ، أتدرب وأعمل على نفسي ، حتى أتمكن من تجاوز مرحلة التصفيات في العام المقبل.