لن تتناول هذه المقالة أساسيات السبات (كيفية تحديد كيان أو استعلام معايير الكتابة). هنا سأحاول التحدث عن نقاط أكثر إثارة للاهتمام مفيدة حقًا في العمل. المعلومات التي لم أقابلها في مكان واحد.

سأقوم بالحجز على الفور. كل ما يلي ينطبق على السبات 5.2. الأخطاء ممكنة أيضًا نظرًا لأنني أسأت فهم شيء ما. إذا وجدت - اكتب.
مشاكل في تخطيط نموذج كائن في علاقة
ولكن دعونا نبدأ بأساسيات ORM. ORM - رسم خرائط الكائنات العلائقية - وفقًا لذلك ، لدينا نماذج علائقية وكائنات وعند عرض أحدهما للآخر ، هناك مشاكل نحتاج إلى حلها بمفردنا. دعنا ننفصل بينهما.
للتوضيح ، لنأخذ المثال التالي: لدينا كيان "المستخدم" ، والذي يمكن أن يكون إما Jedi أو طائرة هجومية. يجب أن يكون للجدي القوة ، وتخصص الطائرات الهجومية. يوجد أدناه رسم تخطيطي للصف.
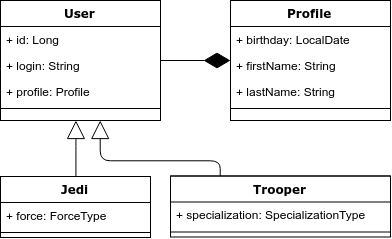
المشكلة 1. استفسارات الوراثة وتعدد الأشكال.
هناك وراثة في نموذج الكائن ، ولكن ليس في النموذج العلائقي. وفقًا لذلك ، هذه هي المشكلة الأولى - كيفية تعيين الميراث بشكل صحيح للنموذج العلائقي.
يوفر السبات 3 خيارات لعرض نموذج كائن مثل:
- جميع الورثة في نفس الجدول:
Inheritance (استراتيجية = InheritanceType.SINGLE_TABLE)

في هذه الحالة ، الحقول المشتركة وحقول الورثة تقع في جدول واحد. باستخدام هذه الاستراتيجية ، نتجنب الانضمام عند اختيار الكيانات. من السلبيات ، تجدر الإشارة إلى أنه ، أولاً ، لا يمكننا تعيين تقييد "NOT NULL" لعمود "القوة" في النموذج العلائقي ، وثانيًا ، نفقد الشكل العادي الثالث. (تظهر تبعية متعدية للسمات غير الرئيسية: القوة والقرص).
بالمناسبة ، بما في ذلك لهذا السبب ، هناك طريقتان لتحديد قيد حقل غير فارغ - NotNull مسؤول عن التحقق ؛ Column (nullable = true) - مسؤول عن القيد غير الفارغ في قاعدة البيانات.
في رأيي ، هذه هي أفضل طريقة لتعيين نموذج كائن لنموذج علائقي.
- الحقول الخاصة بالكيانات موجودة في جدول منفصل.
Inheritance (Strategy = InheritanceType.JOINED)
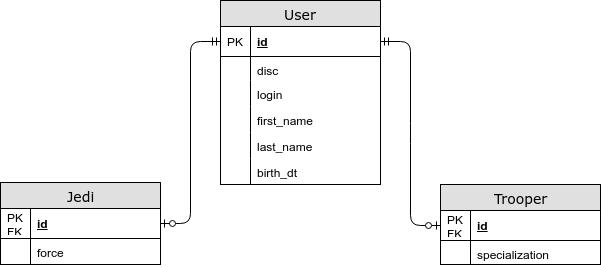
في هذه الحالة ، يتم تخزين الحقول المشتركة في جدول مشترك ، ويتم تخزين الكيانات الفرعية الخاصة في حقول منفصلة. باستخدام هذه الإستراتيجية ، نحصل على JOIN عند اختيار كيان ، ولكننا الآن نحفظ النموذج العادي الثالث ، ويمكننا أيضًا تحديد قيد NOT NULL في قاعدة البيانات. - كل كيان لديه جدول خاص به.
@ InheritanceType.TABLE_PER_CLASS
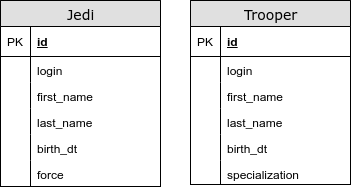
في هذه الحالة ، ليس لدينا جدول مشترك. باستخدام هذه الاستراتيجية ، نستخدم UNION للاستعلامات متعددة الأشكال. نحن نواجه مشاكل مع مولدات المفاتيح الرئيسية وقيود التكامل الأخرى. هذا النوع من رسم خرائط الميراث لا يشجع بشدة.
تحسبًا فقط ، سأذكر التعليق التوضيحي - MappedSuperclass. يتم استخدامه عندما تريد "إخفاء" الحقول المشتركة للعديد من الكيانات في نموذج الكائن. علاوة على ذلك ، لا تعتبر الفئة المشروحة نفسها ككيان منفصل.
المشكلة 2. نسبة التركيب في OOP
بالعودة إلى مثالنا ، نلاحظ أننا في نموذج الكائن أخذنا ملف تعريف المستخدم إلى كيان منفصل - ملف تعريف. لكن في النموذج العلائقي ، لم نختار جدولًا منفصلاً له.
غالبًا ما يكون موقف OneToOne ممارسة سيئة لأنه في الاختيار ، لدينا JOIN غير مبرر (حتى تحديد fetchType = LAZY في معظم الحالات سيكون لدينا JOIN - سنناقش هذه المشكلة لاحقًا).
توجد تعليقات توضيحيةEmbedable وEmbeded لعرض تركيبة في جدول مشترك. يتم وضع الأول فوق الحقل ، والثاني فوق الفصل. إنها قابلة للتبديل.
مدير الكيان
يحدد كل مثيل لـ EntityManager (EM) جلسة تفاعل مع قاعدة البيانات. داخل مثيل EM ، توجد ذاكرة تخزين مؤقت من المستوى الأول. هنا سوف ألقي الضوء على النقاط الهامة التالية:
- جاري التقاط اتصال قاعدة البيانات
هذه مجرد نقطة مثيرة للاهتمام. لا يلتقط السبات الاتصال في وقت تلقي EM ، ولكن في أول وصول إلى قاعدة البيانات أو فتح المعاملة (على الرغم من أنه يمكن حل هذه المشكلة). يتم ذلك لتقليل وقت الاتصال مشغول. أثناء استلام EM-a ، يتم التحقق من وجود معاملة JTA. - الكيانات المستمرة لديها دائما معرف
- الكيانات التي تصف سطرًا واحدًا في قاعدة البيانات مكافئة حسب المرجع
كما هو مذكور أعلاه ، يحتوي EM على ذاكرة تخزين مؤقت من المستوى الأول ، ويتم مقارنة الكائنات الموجودة فيه كمرجع. وبناءً على ذلك ، يُطرح السؤال - ما هي الحقول التي يجب استخدامها لإلغاء التساوي ورمز التجزئة؟ فكر في الخيارات التالية:
- كيف يعمل تدفق
Flush - ينفذ الإضافات المتراكمة ، والتحديثات ، والحذف المتراكم في قاعدة البيانات. بشكل افتراضي ، يتم تنفيذ التدفق في الحالات:
- قبل تنفيذ الاستعلام (باستثناء em.get) ، يعد ذلك ضروريًا للالتزام بمبدأ ACID. على سبيل المثال: قمنا بتغيير تاريخ ميلاد الطائرة الهجومية ، ثم أردنا الحصول على عدد الطائرات الهجومية البالغة.
إذا كنا نتحدث عن CriteriaQuery أو JPQL ، فسيتم تنفيذ المسح إذا كان الاستعلام يؤثر على جدول توجد كياناته في ذاكرة التخزين المؤقت للمستوى الأول. - عند تنفيذ المعاملة ؛
- في بعض الأحيان عند الإصرار على كيان جديد - في الحالة التي يمكننا فيها الحصول على معرفها فقط من خلال الإدراج.
والآن القليل من الاختبار. كم عدد عمليات التحديث التي سيتم إجراؤها في هذه الحالة؟
val spaceCraft = em.find(SpaceCraft.class, 1L); spaceCraft.setCoords(...); spaceCraft.setCompanion( findNearestSpaceCraft(spacecraft) );
تم إخفاء ميزة مثيرة للإسبات تحت عملية التدفق - فهي تحاول تقليل الوقت المستغرق لقفل الصفوف في قاعدة البيانات.
لاحظ أيضًا أن هناك استراتيجيات مختلفة لعملية التدفق. على سبيل المثال ، يمكنك منع "دمج" التغييرات في قاعدة البيانات - يطلق عليها MANUAL (وتعطل أيضًا آلية التحقق القذرة).
- فحص قذر
الفحص القذر هو آلية يتم تنفيذها أثناء عملية التدفق. الغرض منه هو العثور على الكيانات التي قامت بتغييرها وتحديثها. لتطبيق هذه الآلية ، يجب أن يقوم السبات بتخزين النسخة الأصلية من الكائن (ما سيتم مقارنة الكائن الفعلي به). لكي تكون أكثر دقة ، يقوم السبات بتخزين نسخة من حقول الكائن ، وليس الكائن نفسه.
تجدر الإشارة إلى أنه إذا كان الرسم البياني للكيانات كبيرًا ، فقد تكون عملية الفحص القذر مكلفة. لا تنس أن السبات يخزن نسختين من الكيانات (تقريبًا).
من أجل "تقليل التكلفة" لهذه العملية ، استخدم الميزات التالية:
- em.detach / em.clear - فصل الكيانات من EntityManager
- FlushMode = MANUAL- مفيد في عمليات القراءة
- غير قابل للتغيير - يتجنب أيضًا عمليات الفحص القذرة
- المعاملات
كما تعلم ، يسمح لك السبات بتحديث الكيانات فقط داخل المعاملة. توفر عمليات القراءة المزيد من الحرية - يمكننا تنفيذها دون فتح معاملة صراحة. ولكن هذا هو السؤال بالتحديد: هل يستحق الأمر فتح معاملة صريحة لعمليات القراءة؟
سأذكر بعض الحقائق:
- يتم تنفيذ أي بيان في قاعدة البيانات داخل المعاملة. حتى لو من الواضح أننا لم نفتحه. (وضع الالتزام التلقائي).
- كقاعدة ، نحن لا يقتصر على استعلام واحد لقاعدة البيانات. على سبيل المثال: للحصول على أول 10 سجلات ، ربما تريد إرجاع إجمالي عدد السجلات. وهذا تقريبًا طلبان.
- إذا كنا نتحدث عن بيانات الربيع ، فإن طرق المستودع هي معاملات بشكل افتراضي ، بينما تكون طرق القراءة للقراءة فقط.
- يؤثر التعليق التوضيحي لربيع الربيع @ (readOnly = true) أيضًا على FlushMode ، وبشكل أدق ، يضعه الربيع في حالة MANUAL ، وبالتالي لن يقوم السبات بفحص متسخ.
- ستُظهر الاختبارات الاصطناعية مع استعلام واحد أو اثنين من استعلامات قاعدة البيانات أن الالتزام التلقائي أسرع. ولكن في وضع القتال ، قد لا يكون الأمر كذلك. ( مقال ممتاز في هذا الموضوع ، + انظر التعليقات)
باختصار: من الممارسات الجيدة إجراء أي اتصال بقاعدة البيانات في المعاملة.
مولدات
المولدات ضرورية لوصف كيف ستتلقى المفاتيح الأساسية لكياناتنا القيم. دعنا نراجع الخيارات بسرعة:
- GenerationType.AUTO - يعتمد اختيار المولد على اللهجة. ليس الخيار الأفضل ، حيث إن قاعدة "الصريح أفضل من القاعدة الضمنية" تنطبق هنا فقط.
- GenerationType.IDENTITY هي أسهل طريقة لتكوين مولد. يعتمد على عمود الزيادة التلقائية في الجدول. لذلك ، للحصول على معرف مع استمرار نحتاج إلى إدراج. هذا هو السبب في أنه يلغي إمكانية استمرار المؤجل وبالتالي الخلط.
- GenerationType.SEQUENCE هي الحالة الأكثر ملاءمة عندما نحصل على معرف من التسلسل.
- GenerationType.TABLE - في هذه الحالة يحاكي السبات تسلسلًا من خلال جدول إضافي. ليس الخيار الأفضل ، لأنه في مثل هذا الحل ، يجب على السبات استخدام معاملة منفصلة وقفل لكل سطر.
لنتحدث قليلاً عن التسلسل. من أجل زيادة سرعة التشغيل ، يستخدم السبات خوارزميات تحسين مختلفة. تهدف جميعها إلى تقليل عدد المحادثات مع قاعدة البيانات (عدد رحلات الذهاب والإياب). دعونا نلقي نظرة عليها بمزيد من التفصيل:
- بلا - لا يوجد تحسينات. لكل معرف نسحب تسلسل.
- pooled and pooled-lo - في هذه الحالة ، يجب أن يزيد التسلسل لدينا بفاصل زمني معين - N في قاعدة البيانات (SequenceGenerator.allocationSize). وفي التطبيق ، لدينا مجموعة معينة ، والقيم التي يمكننا من خلالها تعيين كيانات جديدة دون الوصول إلى قاعدة البيانات ..
- hilo - لإنشاء معرف ، تستخدم خوارزمية hilo رقمين: hi (مخزنة في قاعدة البيانات - القيمة التي تم الحصول عليها من استدعاء التسلسل) و lo (مخزنة فقط في التطبيق - SequenceGenerator.allocationSize). بناءً على هذه الأرقام ، يتم حساب الفاصل الزمني لإنشاء المعرّف كما يلي: [(hi - 1) * lo + 1، hi * lo + 1). لأسباب واضحة ، تعتبر هذه الخوارزمية قديمة ولا يوصى باستخدامها.
الآن دعنا نرى كيف يتم اختيار المحسن. يحتوي السبات على عدة مولدات تسلسلية. سنهتم بـ 2 منهم:
- SequenceHiLoGenerator هو مولد قديم يستخدم محسّن hilo. يتم تحديده افتراضيًا إذا كان لدينا hibernate.id.new_generator_mappings == خاصية خاطئة.
- SequenceStyleGenerator - يُستخدم افتراضيًا (إذا كانت hibernate.id.new_generator_mappings == خاصية حقيقية). يدعم هذا المولد عدة محسنات ، ولكن يتم تجميع الافتراضي.
يمكنك أيضًا تهيئة التعليق التوضيحي للمولدGenericGenerator.
طريق مسدود
دعونا نلقي نظرة على مثال لموقف رمز زائف يمكن أن يؤدي إلى طريق مسدود:
Thread #1: update entity(id = 3) update entity(id = 2) update entity(id = 1) Thread #2: update entity(id = 1) update entity(id = 2) update entity(id = 3)
لمنع مثل هذه المشاكل ، الإسبات لديه آلية تتجنب الجمود من هذا النوع - المعلمة hibernate.order_updates. في هذه الحالة ، سيتم ترتيب جميع التحديثات عن طريق المعرف وتنفيذها. سأذكر أيضًا مرة أخرى أن السبات يحاول "تأخير" التقاط الاتصال وتنفيذ عمليات الإدراج والتحديث.
مجموعة ، حقيبة ، قائمة
يمتلك السبات 3 طرق رئيسية لتقديم مجموعة اتصالات OneToMany.
- Set - مجموعة غير مرتبة من الكيانات دون تكرار ؛
- حقيبة - مجموعة غير منظمة من الكيانات ؛
- القائمة عبارة عن مجموعة مرتبة من الكيانات.
لا توجد فئة للحقيبة في قلب جافا تصف مثل هذا الهيكل. لذلك ، تكون كل القائمة والمجموعة عبارة عن حقيبة ما لم تحدد عمودًا يتم فرز مجموعتنا من خلاله (تعليق OrderColumn. لا يجب الخلط بينه وبين SortBy). أوصي بشدة بعدم استخدام التعليق التوضيحي OrderColumn بسبب التنفيذ السيئ للميزات (في رأيي) - وليس استعلامات SQL المثلى ، والقيم الخالية الممكنة في الورقة.
السؤال الذي يطرح نفسه ، ولكن ما هو أفضل استخدام حقيبة أو مجموعة؟ بادئ ذي بدء ، عند استخدام حقيبة ، المشاكل التالية ممكنة:
- إذا كان إصدار السبات الخاص بك أقل من 5.0.8 ، فهناك خطأ خطير إلى حد ما - HHH-5855 - عند إدخال كيان فرعي ، يمكن تكراره (في حالة cascadType = MERGE و PERSIST) ؛
- إذا كنت تستخدم حقيبة لعلاقة ManyToMany ، فإن السبات يولد استعلامات غير مناسبة للغاية عند حذف كيان من المجموعة - يقوم أولاً بإزالة جميع الصفوف من جدول الربط ، ثم يقوم بإدراج ؛
- لا يستطيع السبات جلب حقائب متعددة لنفس الكيان في نفس الوقت.
في حالة رغبتك في إضافة كيان آخر إلى اتصالOneToMany ، فمن الأفضل استخدام حقيبة ، لأن لا يتطلب تحميل جميع الكيانات ذات الصلة لهذه العملية. دعنا نرى مثال:
مراجع القوة
المرجع هو مرجع إلى كائن ، قررنا تأجيل التحميل. في حالة علاقة ManyToOne مع fetchType = LAZY ، نحصل على مثل هذا المرجع. تحدث تهيئة الكائن في وقت الوصول إلى حقول الكيان ، باستثناء المعرف (لأننا نعرف قيمة هذا الحقل).
تجدر الإشارة إلى أنه في حالة Lazy Loading ، يشير المرجع دائمًا إلى صف موجود في قاعدة البيانات. لهذا السبب ، لا تعمل معظم حالات التحميل البطيء في علاقات OneToOne - يحتاج السبات إلى JOIN للتحقق مما إذا كان الاتصال موجودًا وكان هناك بالفعل JOIN ، ثم يقوم السبات بتحميله في نموذج الكائن. إذا أشرنا إلى nullable = true في OneToOne ، فيجب أن يعمل LazyLoad.
يمكننا إنشاء مرجع خاص بنا باستخدام طريقة em.getReference. صحيح ، في هذه الحالة ليس هناك ما يضمن أن يشير المرجع إلى صف موجود في قاعدة البيانات.
دعنا نعطي مثالا لاستخدام مثل هذا الرابط:
فقط في حالة ، أذكرك أننا سنحصل على LazyInitializationException في حالة إغلاق EM أو ارتباط منفصل.
التاريخ والوقت
على الرغم من حقيقة أن java 8 لديه واجهة برمجة تطبيقات ممتازة للعمل مع التاريخ والوقت ، إلا أن JDBC API لا تزال تسمح لك بالعمل فقط مع واجهة برمجة تطبيقات التاريخ القديم. لذلك ، سنقوم بتحليل بعض النقاط المثيرة للاهتمام.
أولاً ، تحتاج إلى فهم الاختلافات بين LocalDateTime و Instant و ZonedDateTime بوضوح. (لن أمتد ، لكني سأقدم مقالات ممتازة حول هذا الموضوع:
الأول والثاني )
إذا لفترة وجيزةيمثل LocalDateTime و LocalDate مجموعة منتظمة من الأرقام. لا ترتبط بوقت محدد. على سبيل المثال لا يمكن تخزين وقت هبوط الطائرة في LocalDateTime. وتاريخ الميلاد من خلال LocalDate طبيعي تمامًا. يمثل البحث الفوري نقطة زمنية ، نسبيًا يمكننا من خلالها الحصول على التوقيت المحلي في أي وقت على الكوكب.
نقطة أكثر إثارة للاهتمام ومهمة هي كيفية تخزين التواريخ في قاعدة البيانات. إذا كان لدينا TIMESTAMP مع نوع TIMEZONE مثبتًا ، فلن تكون هناك مشاكل ، ولكن إذا كان TIMESTAMP (بدون TIMEZONE) قائمًا ، فهناك احتمال أن تتم كتابة / قراءة التاريخ بشكل غير صحيح. (باستثناء LocalDate و LocalDateTime)
دعنا نرى لماذا:
عند حفظ التاريخ ، يتم استخدام طريقة بالتوقيع التالي:
setTimestamp(int i, Timestamp t, java.util.Calendar cal)
كما ترى ، يتم استخدام واجهة برمجة التطبيقات القديمة هنا. وسيطة التقويم الاختيارية مطلوبة لتحويل الطابع الزمني إلى تمثيل سلسلة. أي أنها تخزن المنطقة الزمنية في حد ذاتها. إذا لم يتم إرسال التقويم ، فسيتم استخدام التقويم بشكل افتراضي مع المنطقة الزمنية JVM.
هناك 3 طرق لحل هذه المشكلة:
- اضبط المنطقة الزمنية JVM المطلوبة
- استخدام معلمة السبات - hibernate.jdbc.time_zone (تمت إضافتها في 5.2) - سيتم إصلاح ZonedDateTime و OffsetDateTime فقط
- استخدم النوع TIMESTAMP مع TIMEZONE
سؤال مثير للاهتمام ، لماذا لا تقع LocalDate و LocalDateTime تحت هذه المشكلة؟
الجوابللإجابة على هذا السؤال ، تحتاج إلى فهم هيكل فئة java.util.Date (java.sql.Date و java.sql.Timestamp ، ورثتها وخلافاتهم في هذه الحالة لا تزعجنا). يخزن التاريخ التاريخ بالمللي ثانية منذ 1970 ، ويتحدث تقريبًا بالتوقيت العالمي المنسق (UTC) ، لكن طريقة toString تحول التاريخ وفقًا لنظام المنطقة الزمنية.
وفقًا لذلك ، عندما نحصل على تاريخ بدون منطقة زمنية من قاعدة البيانات ، يتم تعيينه إلى كائن الطابع الزمني بحيث تعرض طريقة toString القيمة المطلوبة. في نفس الوقت ، قد يختلف عدد المللي ثانية منذ عام 1970 (حسب المنطقة الزمنية). هذا هو السبب في عرض التوقيت المحلي فقط بشكل صحيح دائمًا.
أعطي أيضًا مثالًا على الرمز المسؤول عن تحويل Timesamp إلى LocalDateTime و Instant:
الخلط
بشكل افتراضي ، يتم إرسال الاستعلامات إلى قاعدة البيانات واحدة تلو الأخرى. عند تمكين التجميع ، سيتمكن السبات من إرسال عدة عبارات في استعلام واحد إلى قاعدة البيانات. (أي أن التجميع يقلل عدد الرحلات ذهابًا وإيابًا إلى قاعدة البيانات)
للقيام بذلك ، يجب عليك:
- تمكين التجميع وتعيين الحد الأقصى لعدد العبارات:
hibernate.jdbc.batch_size (يوصى بـ 5 إلى 30) - تمكين فرز الإدراج والتحديث:
السبات
الإسبات. order_updates
- إذا كنا نستخدم الإصدارات ، فنحن بحاجة أيضًا إلى تمكينها
hibernate.jdbc.batch_versioned_data - كن حذرًا هنا ، فأنت بحاجة إلى برنامج تشغيل jdbc حتى تتمكن من تحديد عدد الأسطر التي تأثرت أثناء التحديث.
سأذكرك أيضًا بفاعلية عملية em.clear () - فهي تحجب الكيانات عن em ، وبالتالي تحرر الذاكرة وتقلل من وقت عملية الفحص القذرة.
إذا استخدمنا postgres ، فيمكننا أيضًا أن نقول السبات لاستخدام
إدراج متعدد الخام .
مشكلة N + 1
هذا موضوع شائع في كل مكان ، لذا راجعه بسرعة.
مشكلة N + 1 هي حالة تحدث فيها طلبات N + 1 على الأقل بدلاً من طلب واحد لتحديد كتب N.
أسهل طريقة لحل مشكلة N + 1 هي جلب الجداول ذات الصلة. في هذه الحالة ، قد نواجه العديد من المشاكل الأخرى:
- ترقيم الصفحات. في حالة علاقات OneToMany ، لن يتمكن السبات من تحديد الإزاحة والحد. لذلك ، سيحدث ترقيم الصفحات في الذاكرة.
- مشكلة المنتج الديكارتي هي حالة عندما تقوم قاعدة البيانات بإرجاع صفوف N * M * K لاختيار كتب N مع فصول M ومؤلفي K.
هناك طرق أخرى لحل مشكلة N + 1.
- FetchMode - يسمح لك بتغيير خوارزمية التحميل للكيانات الفرعية. في حالتنا ، نحن مهتمون بما يلي:
- FetchType.SUBSELECT - تحميل السجلات التابعة في طلب منفصل. الجانب السلبي هو أن كل تعقيد الطلب الرئيسي يتكرر في الاختيار الفرعي.
- BATCH (FetchType.SELECT + BatchSize التعليقات التوضيحية) - يتم أيضًا تحميل السجلات كطلب منفصل ، ولكن جنبًا إلى جنب مع الاستعلام الفرعي ، فإنه يجعل حالة مثل WHERE parent_id IN (؟،؟،؟، ...، N)
تجدر الإشارة إلى أنه عند استخدام الجلب في Criteria API ، يتم تجاهل FetchType - يتم دائمًا استخدام JOIN - JPA EntityGraph و Hibernate FetchProfile - تسمح لك بجعل قواعد تحميل الكيان في تجريد منفصل - في رأيي كلا التنفيذين غير ملائمين.
الاختبار
من الناحية المثالية ، يجب أن توفر بيئة التطوير أكبر قدر ممكن من المعلومات المفيدة حول تشغيل السبات والتفاعل مع قاعدة البيانات. وهي:
- تسجيل الدخول
- org.hibernate.SQL: تصحيح الأخطاء
- org.hibernate.type.descriptor.sql: أثر
- الإحصائيات
من بين المرافق المفيدة ، يمكن تمييز ما يلي:
- DBUnit - يسمح لك بوصف حالة قاعدة البيانات بتنسيق XML. في بعض الأحيان يكون الأمر مناسبًا. ولكن من الأفضل التفكير مرة أخرى ما إذا كنت بحاجة إليها.
- وكيل مصدر البيانات
- يعد p6spy أحد أقدم الحلول. يقدم تسجيل استعلام متقدم ووقت تشغيل وما إلى ذلك.
- com.vladmihalcea: db-util: 0.0.1 أداة مفيدة لإيجاد مشاكل N + 1. كما يسمح لك بتسجيل الاستعلامات. تشتمل التركيبة على تعليق توضيحي مثير للاهتمام لإعادة المحاولة ، والذي يعيد محاولة المعاملة في حالة OptimisticLockException.
- Sniffy - يتيح لك التأكيد على عدد الطلبات من خلال التعليق التوضيحي. في بعض النواحي ، أكثر أناقة من قرار فلاد.
ولكن مرة أخرى أكرر أن هذا هو فقط للتطوير ، لا ينبغي أن يتم تضمين هذا في الإنتاج.
الأدب