مرحبا زملائي! نذكركم أنه منذ وقت ليس ببعيد نشرنا
كتابًا عن Spark ، والآن يخضع
كتاب عن Kafka إلى أحدث تدقيق.
نأمل أن تكون هذه الكتب ناجحة بما يكفي لمواصلة الموضوع - على سبيل المثال ، لترجمة ونشر الأدب على Spark Streaming. أردنا أن نقدم لك ترجمة حول دمج هذه التكنولوجيا مع Kafka اليوم.
1. التبريرApache Kafka + Spark Streaming هي واحدة من أفضل المجموعات لإنشاء تطبيقات في الوقت الفعلي. في هذه المقالة ، سنناقش بالتفصيل تفاصيل هذا التكامل. بالإضافة إلى ذلك ، سنلقي نظرة على مثال مع Spark Streaming-Kafka. ثم نناقش "نهج المتلقي" وخيار الدمج المباشر لكافكا وسبارك ستريم. لذا ، دعنا نبدأ في دمج كافكا و سبارك الجري.
 2. دمج كافكا و سبارك دفق
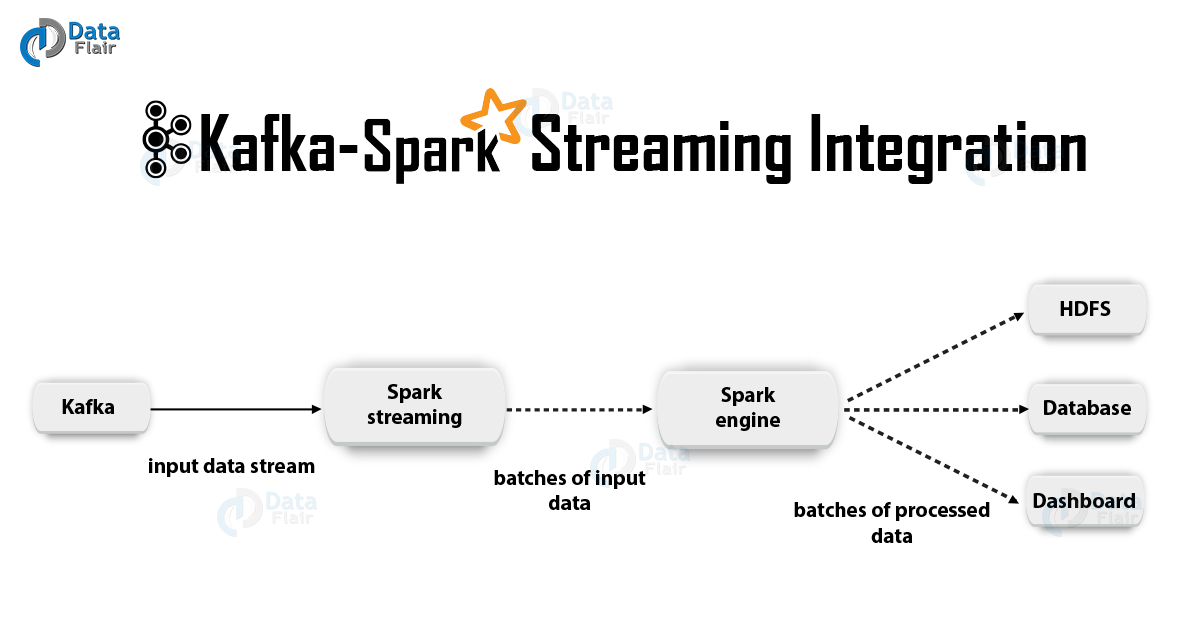
2. دمج كافكا و سبارك دفقعند دمج Apache Kafka و Spark Streaming ، هناك طريقتان محتملتان لتكوين Spark Streaming لتلقي البيانات من Kafka - أي نهجان لدمج كافكا وسبارك الجري. أولاً ، يمكنك استخدام المستلمين وواجهة برمجة تطبيقات Kafka عالية المستوى. النهج الثاني (الأحدث) هو العمل بدون مستلمين. هناك نماذج برمجة مختلفة لكلا النهجين ، تختلف ، على سبيل المثال ، من حيث الأداء والضمانات الدلالية.
دعونا ننظر في هذه الأساليب بمزيد من التفصيل.
أ. منهج المستلمينفي هذه الحالة ، يتم توفير استقبال البيانات من قبل المستلم. لذا ، باستخدام واجهة برمجة التطبيقات للاستهلاك عالية المستوى التي تقدمها كافكا ، نقوم بتنفيذ المستلم. علاوة على ذلك ، يتم تخزين البيانات المستلمة في Spark Artists. ثم يتم إطلاق الوظائف في Kafka - Spark Streaming ، حيث يتم معالجة البيانات.
ومع ذلك ، عند استخدام هذا النهج ، يبقى خطر فقدان البيانات في حالة الفشل (مع التكوين الافتراضي). وبالتالي ، سيكون من الضروري أيضًا إضافة سجل قبل الكتابة في Kafka - Spark Streaming من أجل القضاء على فقدان البيانات. وبالتالي ، يتم تخزين جميع البيانات الواردة من Kafka بشكل متزامن في سجل الكتابة المسبقة في نظام ملفات موزع. لهذا السبب ، حتى بعد فشل النظام ، يمكن استعادة جميع البيانات.
بعد ذلك ، سنلقي نظرة على كيفية استخدام هذا النهج مع المستلمين في تطبيق باستخدام Kafka - Spark Streaming.
ط. ملزمالآن سنقوم بتوصيل تطبيق البث الخاص بنا بالقطع الفنية التالية لتطبيقات Scala / Java ، وسوف نستخدم تعريفات المشروع لـ SBT / Maven.
groupId = org.apache.spark artifactId = spark-streaming-kafka-0-8_2.11 version = 2.2.0
ومع ذلك ، عند نشر تطبيقنا ، سيتعين علينا إضافة المكتبة المذكورة أعلاه وتبعياتها ، وستكون هذه ضرورية لتطبيقات Python.
ثانيا. برمجةبعد ذلك ، قم بإنشاء دفق إدخال
DStream عن طريق استيراد
KafkaUtils في رمز تطبيق الدفق:
import org.apache.spark.streaming.kafka._ val kafkaStream = KafkaUtils.createStream(streamingContext, [ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
بالإضافة إلى ذلك ، باستخدام خيارات createStream ، يمكنك تحديد الفئات الرئيسية وفئات القيم ، بالإضافة إلى الفئات المقابلة لفك ترميزها.
ثالثا. النشركما هو الحال مع أي تطبيق Spark ، يتم استخدام الأمر spark-Submit لبدء التشغيل. ومع ذلك ، فإن التفاصيل تختلف قليلاً في تطبيقات Scala / Java وفي تطبيقات Python.
علاوة على ذلك ، مع -
–packages يمكنك إضافة
spark-streaming-Kafka-0-8_2.11 وتبعياته مباشرة إلى إرسال
spark-submit ، وهذا مفيد لتطبيقات Python حيث من المستحيل إدارة المشاريع باستخدام SBT / Maven.
./bin/spark-submit --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.0 ...
يمكنك أيضًا تنزيل أرشيف JAR من مجموعة Maven artifact
spark-streaming-Kafka-0-8-assembly من مستودع Maven. ثم أضفه إلى
spark-submit مع -
jars .
ب. نهج مباشر (لا مستلمين)بعد استخدام المنهج للمستلمين ، تم تطوير نهج أحدث - "المباشر". يوفر ضمانات موثوقة من طرف إلى طرف. في هذه الحالة ، نسأل بشكل دوري كافكا عن تعويضات الإزاحة لكل موضوع / قسم ، ولا نرتب لتسليم البيانات من خلال المستلمين. بالإضافة إلى ذلك ، يتم تحديد حجم جزء القراءة ، وهذا ضروري للمعالجة الصحيحة لكل حزمة. أخيرًا ، يتم استخدام واجهة برمجة تطبيقات بسيطة تستهلك لقراءة النطاقات باستخدام البيانات من كافكا مع الإزاحات المعينة ، خاصة عند بدء مهام معالجة البيانات. العملية برمتها مثل قراءة الملفات من نظام الملفات.
ملاحظة: ظهرت هذه الميزة في Spark 1.3 لـ Scala و Java API ، وكذلك في Spark 1.4 ل Python API.
الآن دعونا نناقش كيفية تطبيق هذا النهج في تطبيق البث لدينا.
يتم وصف واجهة برمجة تطبيقات المستهلك بمزيد من التفصيل على الرابط التالي:
اباتشي كافكا المستهلك | أمثلة على مستهلك كافكاط. ملزم
صحيح ، هذا النهج معتمد فقط في تطبيقات Scala / Java. باستخدام الأداة التالية ، قم ببناء مشروع SBT / Maven.
groupId = org.apache.spark artifactId = spark-streaming-kafka-0-8_2.11 version = 2.2.0
ثانيا. برمجةبعد ذلك ، قم باستيراد KafkaUtils وإنشاء
DStream إدخال في رمز تطبيق الدفق:
import org.apache.spark.streaming.kafka._ val directKafkaStream = KafkaUtils.createDirectStream[ [key class], [value class], [key decoder class], [value decoder class] ]( streamingContext, [map of Kafka parameters], [set of topics to consume])
في معلمات Kafka ، ستحتاج إلى تحديد إما
metadata.broker.list أو
bootstrap.servers . لذلك ، بشكل افتراضي ، سنستهلك البيانات بدءًا من الإزاحة الأخيرة في كل قسم من كافكا. ومع ذلك ، إذا كنت تريد أن تبدأ القراءة من أصغر جزء ، فستحتاج في معلمات Kafka إلى تعيين خيار التكوين
auto.offset.reset .
علاوة على ذلك ، من خلال العمل مع الخيارات
KafkaUtils.createDirectStream ، يمكنك البدء في القراءة من إزاحة عشوائية. ثم سنقوم بما يلي ، مما سيتيح لنا الوصول إلى شظايا كافكا المستهلكة في كل عبوة.
إذا أردنا تنظيم مراقبة كافكا بناءً على Zookeeper باستخدام أدوات خاصة ، يمكننا تحديث Zookeeper بأنفسنا بمساعدتهم.
ثالثا. النشرتشبه عملية النشر في هذه الحالة عملية النشر في المتغير مع المستلم.
3. فوائد النهج المباشرالنهج الثاني لدمج Spark Streaming مع Kafka يتفوق على الأول للأسباب التالية:
أ. التزامن المبسطفي هذه الحالة ، لا تحتاج إلى إنشاء العديد من تيارات إدخال Kafka ودمجها. ومع ذلك ، فإن Kafka - Spark Streaming سيخلق العديد من مقاطع RDD حيث سيكون هناك شرائح Kafka للاستهلاك. سيتم قراءة جميع بيانات كافكا هذه بالتوازي. لذلك ، يمكننا القول أنه سيكون لدينا مراسلات فردية بين مقاطع كافكا و RDD ، وهذا النموذج أكثر قابلية للفهم وأسهل تكوينه.
ب. الفعاليةمن أجل القضاء تمامًا على فقدان البيانات أثناء النهج الأول ، يجب تخزين المعلومات في سجل من السجلات الرائدة ، ومن ثم نسخها. في الواقع ، هذا غير فعال لأن البيانات يتم نسخها مرتين: المرة الأولى بواسطة كافكا نفسها ، والثانية بسجل الكتابة المسبق. في النهج الثاني ، يتم التخلص من هذه المشكلة ، حيث لا يوجد مستلم ، وبالتالي ، لا توجد حاجة إلى يومية كتابة رائدة. إذا كان لدينا تخزين بيانات طويل بما فيه الكفاية في Kafka ، يمكنك استرداد الرسائل مباشرة من Kafka.
ق مرة واحدة بالضبط دلالاتفي الأساس ، استخدمنا واجهة برمجة تطبيقات Kafka عالية المستوى في النهج الأول لتخزين أجزاء القراءة المستهلكة في Zookeeper. ومع ذلك ، هذه هي العادة لاستهلاك البيانات من كافكا. بينما يمكن القضاء على فقدان البيانات بشكل موثوق ، هناك احتمال ضئيل في بعض حالات الفشل ، يمكن استهلاك السجلات الفردية مرتين. النقطة الأساسية هي عدم الاتساق بين آلية نقل البيانات الموثوقة في Kafka - Spark Streaming وقراءة الأجزاء التي تحدث في Zookeeper. لذلك ، في النهج الثاني ، نستخدم واجهة برمجة تطبيقات Kafka البسيطة ، والتي لا تتطلب اللجوء إلى Zookeeper. هنا ، يتم تتبع أجزاء القراءة في Kafka - Spark Streaming ، لذلك ، يتم استخدام نقاط التحكم. في هذه الحالة ، يتم إزالة التناقض بين Spark Streaming و Zookeeper / Kafka.
لذلك ، حتى في حالة الفشل ، يتلقى Spark Streaming كل سجل مرة واحدة بدقة. نحتاج هنا إلى التأكد من أن عملية المخرجات ، التي يتم فيها تخزين البيانات في وحدة تخزين خارجية ، إما حاسمة أو معاملة ذرية يتم فيها تخزين النتائج والتعويضات. هذه هي الطريقة التي يتم بها تحقيق دلالات ذات مرة واحدة في اشتقاق نتائجنا.
على الرغم من وجود عيب واحد: لا يتم تحديث الإزاحات في Zookeeper. لذلك ، لا تسمح لك أدوات المراقبة لكافكا القائمة على Zookeeper بتتبع التقدم.
ومع ذلك ، لا يزال بإمكاننا الرجوع إلى الإزاحات ، إذا تم ترتيب المعالجة بهذه الطريقة - ننتقل إلى كل حزمة ونقوم بتحديث Zookeeper بأنفسنا.
هذا كل ما أردنا التحدث عنه حول دمج Apache Kafka و Spark Streaming. نأمل أن تكون قد استمتعت به.