هذه هي المحاضرة الثانية مع جيه. سوبوتنيك حول قواعد البيانات -
الأولى التي نشرناها قبل أسبوعين.
تحدث رئيس مجموعة DBMS للأغراض العامة Dmitry Sarafannikov عن تطور مستودع البيانات في Yandex: كيف قررنا إنشاء واجهة متوافقة مع S3 ، ولماذا اخترنا PostgreSQL ، وما هو نوع المدخنة التي خطونا وكيفية التعامل معها.
- مرحبا بالجميع! اسمي ديما ، في Yandex أقوم بقواعد البيانات.
سأخبرك كيف قمنا بعمل S3 ، وكيف توصلنا إلى إجراء S3 بالضبط ، ونوع التخزين السابق. أولها Elliptics ، يتم نشره في مصدر مفتوح ومتاح على GitHub. ربما صادفها الكثيرون.

هذا هو في الأساس جدول تجزئة موزع مع مفتاح 512 بت ، نتيجة SHA-512. وهي تشكل حلقة رئيسية مقسمة عشوائيًا بين الأجهزة. إذا كنت ترغب في إضافة آلات هناك ، يتم إعادة توزيع المفاتيح ، تحدث إعادة التوازن. لدى هذا المستودع مشاكله الخاصة المرتبطة ، على وجه الخصوص ، بإعادة التوازن. إذا كان لديك عدد كبير بما فيه الكفاية من المفاتيح ، فأنت بحاجة إلى تفريغ السيارات باستمرار هناك ، مع زيادة الأحجام باستمرار ، وعلى عدد كبير جدًا من المفاتيح ، قد لا تتقارب إعادة التوازن ببساطة. كانت هذه مشكلة كبيرة بما فيه الكفاية.
ولكن في الوقت نفسه ، يعد هذا التخزين رائعًا لبيانات ثابتة أكثر أو أقل ، عندما تقوم بتحميل كمية كبيرة لمرة واحدة ، ثم تقوم بتحميل حمل للقراءة فقط عليه. لمثل هذه القرارات ، يناسبها تماما.
نحن نمضي قدما. كانت مشاكل إعادة التوازن خطيرة للغاية ، لذلك ظهر التخزين التالي.

ما هو جوهره؟ هذا ليس تخزين القيمة الرئيسية ، هذا تخزين القيمة. عند تحميل كائن أو ملف هناك ، فإنه يجيبك بمفتاح ، يمكنك من خلاله التقاط هذا الملف. ماذا يعطي؟ نظريًا ، مائة بالمائة من الوصول للكتابة ، إذا كان لديك مساحة خالية في التخزين. إذا كان لديك آلة كاتبة واحدة ، فأنت ببساطة تكتب للآخرين الذين لا يكذبون عليهم حيث توجد مساحة خالية ، ويمكنك الحصول على مفاتيح أخرى والتقاط بياناتك بهدوء.
هذا التخزين سهل القياس ، يمكنك رميه بالحديد ، وسوف يعمل. إنه بسيط للغاية وموثوق. عيبه الوحيد: لا يدير العميل المفتاح ، ويجب على جميع العملاء تخزين المفاتيح في مكان ما ، وتخزين تعيين مفاتيحهم. هذا غير ملائم للجميع. في الواقع ، هذه مهمة متشابهة جدًا لجميع العملاء ، وكل منهم يحلها بطريقته الخاصة في قاعدة التعريف الخاصة به ، وما إلى ذلك. هذا غير مريح. ولكن في الوقت نفسه ، لا أريد أن أفقد موثوقية وبساطة هذا التخزين ، في الواقع أنه يعمل مع سرعة الشبكة.
ثم بدأنا ننظر إلى S3. هذا هو تخزين القيمة الرئيسية ، ويدير العميل المفتاح ، وينقسم التخزين بالكامل إلى ما يسمى الدلاء. في كل دلو ، تكون المساحة الرئيسية من ناقص اللانهاية إلى اللانهاية. المفتاح هو نوع من السلسلة النصية. وقد استقرنا عليه حول هذا الخيار. لماذا S3؟
كل شيء بسيط للغاية. بحلول هذه اللحظة ، تم بالفعل كتابة العديد من العملاء الجاهزين للغات برمجة مختلفة ، والعديد من الأدوات الجاهزة لتخزين شيء ما في S3 ، على سبيل المثال ، النسخ الاحتياطية لقاعدة البيانات ، تمت كتابتها بالفعل.
تحدث أندرو عن أحد الأمثلة. هناك بالفعل واجهة برمجة تطبيقات مدروسة بشكل معقول تعمل منذ سنوات ، ولا تحتاج إلى اختراع أي شيء هناك. يحتوي API على العديد من الميزات المريحة مثل القوائم والتحميل متعدد الأجزاء وما إلى ذلك. لذلك ، قررنا البقاء عليه.
كيفية جعل S3 من التخزين لدينا؟ ما الذي يتبادر إلى الذهن؟ نظرًا لأن العملاء أنفسهم يخزنون تعيين المفاتيح ، فإننا نأخذ فقط قاعدة البيانات بجوارهم ، وسنقوم بتخزين تعيين هذه المفاتيح فيه. عند القراءة ، سنجد فقط المفاتيح والتخزين في قاعدة بياناتنا ، ونعطي العميل ما يريد. إذا قمت برسم ذلك بشكل تخطيطي ، فكيف يحدث التعبئة؟

هناك كيان معين ، هنا يطلق عليه Proxy ، ما يسمى الخلفية. يقبل الملف ، ويحمله على التخزين ، ويحصل على المفتاح من هناك ويحفظه في قاعدة البيانات ، وكل شيء بسيط للغاية.
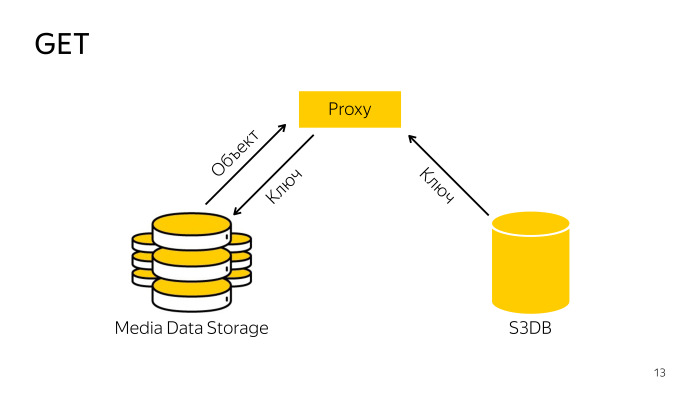
كيف هو الاستلام؟ يعثر الوكيل على المفتاح الضروري في قاعدة البيانات ، ويذهب مع مفتاح التخزين ، وينزل الكائن من هناك ، ويعطيه للعميل. كل شيء بسيط أيضًا.
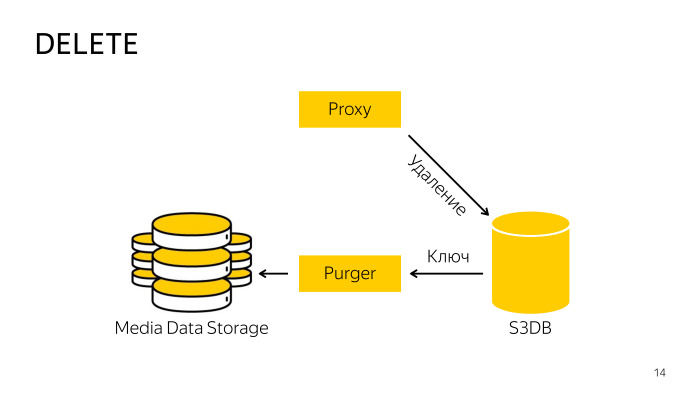
كيف هي الإزالة؟ عند الحذف مباشرة من التخزين ، لا يعمل الوكيل ، لأنه من الصعب تنسيق قاعدة البيانات والتخزين ، لذلك يذهب فقط إلى قاعدة البيانات ، ويخبره أن هذا الكائن محذوف ، وهناك يتم نقل الكائن إلى قائمة انتظار الحذف ، ومن ثم في الخلفية ، يتم تدريب محترف متخصص يأخذ الروبوت هذه المفاتيح ، ويحذفها من التخزين ومن قاعدة البيانات. كل شيء هنا بسيط للغاية.
لقد اخترنا PostgreSQL كقاعدة بيانات لقاعدة البيانات هذه.
أنت تعرف بالفعل أننا نحبه كثيرًا. من خلال نقل Yandex.Mail ، اكتسبنا خبرة كافية في PostgreSQL ، وعندما انتقلت خدمات البريد المختلفة ، طورنا العديد من أنماط ما يسمى تقسيم. سقط أحدهم بشكل جيد على S3 مع تعديلات طفيفة ، لكنه ذهب بشكل جيد هناك.
ما هي خيارات التقسيم؟ هذا مستودع كبير. على نطاق ياندكس على نطاق واسع ، يجب أن تعتقد على الفور أنه سيكون هناك العديد من الأشياء ، يجب أن تفكر على الفور في كيفية تقسيم كل شيء. يمكنك إجراء التجزئة باستخدام العنصر التجزئة نيابة عن الكائن ، وهذه هي الطريقة الأكثر موثوقية ، ولكنها لن تعمل هنا ، لأن S3 ، على سبيل المثال ، قوائم يجب أن تعرض قائمة المفاتيح بترتيب تم فرزها ، وعند التخزين المؤقت ، ستختفي جميع الفرز ، تحتاج إلى إزالة جميع الكائنات بحيث يتوافق الإخراج مع مواصفات API.
الخيار التالي ، يمكنك التقسيم بواسطة التجزئة نيابة عن أو معرف المجموعة. يمكن أن يعيش دلو واحد داخل جزء قاعدة بيانات واحد.
خيار آخر هو التشريح عبر نطاقات رئيسية. داخل الدلو ، هناك مساحة من ناقص اللانهاية إلى اللانهاية ، يمكننا تقسيمها إلى أي عدد من النطاقات ، نسمي هذا النطاق قطعة ، يمكن أن يعيش في جزء واحد فقط.

لقد اخترنا الخيار الثالث ، وهو التقسيم بالقطع ، لأنه من الناحية النظرية البحتة يمكن أن يكون هناك عدد لا نهائي من الأشياء في دلو واحد ، ولن يتناسب بغباء مع قطعة واحدة من الحديد. ستكون هناك مشاكل كبيرة ، لذا سنقطع ونرسم الأجزاء كما نريد. هذا كل شيء.

ماذا حدث؟ تتكون قاعدة البيانات بأكملها من ثلاثة مكونات. S3 Proxy - مجموعة من المضيفين ، وهناك أيضًا قاعدة بيانات. PL / Proxy تحت الموازن ، الطلبات من تلك الواجهة الخلفية تطير هناك. مزيد من S3Meta ، مثل هذه المجموعة من الجهير ، التي تخزن معلومات حول الدلاء والقطع. و S3DB ، شظايا حيث يتم تخزين الكائنات ، وقائمة انتظار حذف. إذا تم تصويره بشكل تخطيطي ، فسيبدو مثل هذا.
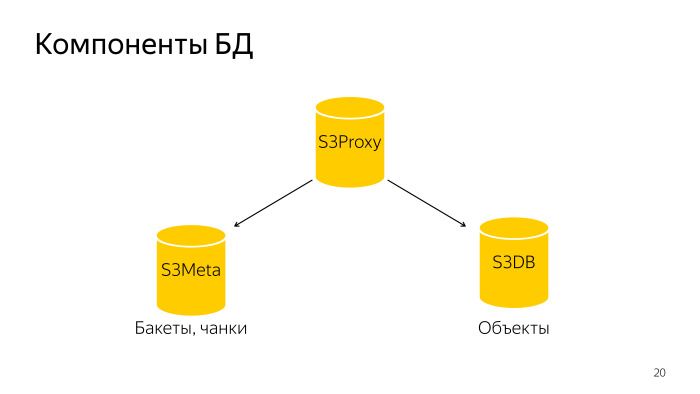
يأتي الطلب إلى S3Proxy ، وينتقل إلى S3Meta و S3DB ويصدر معلومات إلى الأعلى.

دعونا نفكر بمزيد من التفصيل. S3Proxy ، الوظائف الموجودة فيه يتم إنشاؤها باللغة الإجرائية PLProxy ، إنها مثل هذه اللغة التي تسمح لك بتنفيذ الإجراءات أو الطلبات المخزنة عن بعد. هذا هو شكل رمز دالة ObjectInfo ، في جوهره ، طلب Get.
تحتوي الكتلة LProxy على عامل تشغيل الكتلة ، في هذه الحالة db_ro. ماذا يعني هذا؟

إذا كان تكوين قاعدة بيانات نموذجي ، هناك نسخة رئيسية ونسختين. يدخل Master إلى مجموعة db_rw ، ويدخل المضيفون الثلاثة db-ro ، حيث يمكنك إرسال طلب قراءة فقط ، ويتم إرسال طلب كتابة إلى db_rw. تتضمن مجموعة db_rw جميع سادة جميع الأجزاء.
عبارة RUN ON التالية ، تأخذ إما القيمة all ، مما يعني التنفيذ على جميع الأجزاء إما مصفوفة أو نوع من القطع. في هذه الحالة ، يتلقى نتيجة دالة get_object_shard كمدخل ؛ هذا هو عدد القطع التي يقع عليها الكائن المحدد.
والهدف - أي وظيفة لاستدعاء الجزء البعيد. سيدعو هذه الوظيفة ويستبدل الحجج التي طارت في هذه الوظيفة.

تتم كتابة وظيفة get_object_shard أيضًا في PLProxy ، وهي بالفعل كتلة meta_ro ، وسوف ينتقل الطلب إلى جزء S3Meta ، والذي سيعيد هذه الوظيفة get_bucket_meta_shard.
يمكن أيضًا أن تكون S3Meta مجزأة ، لقد وضعناها أيضًا ، في حين أن هذا غير ذي صلة ، ولكن هناك فرصة. وستقوم باستدعاء دالة get_object_shard على S3Meta.

get_bucket_meta_shard هو مجرد تجزئة نص نيابة عن دلو ، قمنا بتعديل S3Meta فقط بواسطة تجزئة نيابة عن دلو.

ضع في اعتبارك S3Meta ما يحدث فيه. أهم المعلومات التي توجد طاولة مع قطع. لقد قطعت بعض المعلومات غير الضرورية قليلاً ، وأهم شيء تركه هو bucket_id ومفتاح البدء ومفتاح النهاية والجزء الذي تكمن فيه هذه القطعة.

كيف سيبدو الاستعلام على مثل هذا الجدول ، والذي سيعود إلينا بالجزء الذي يوجد فيه ، على سبيل المثال ، كائن الاختبار؟ مثل هذا. ناقص اللانهاية في شكل نص ، قدمناها كقيمة فارغة ، هناك نقاط خفية تحتاج إلى التحقق من مفتاح_البدء و end_key هو Null.

لا يبدو الطلب جيدًا جدًا ، وتبدو الخطة أسوأ. كأحد الخيارات لخطة لمثل هذا الطلب ، BitmapOr. و 6000 عظمة تستحق هذه الخطة.

كيف يمكن أن تكون مختلفة؟ هناك شيء رائع في PostgreSQL مثل مؤشر gist ، والذي يمكنه فهرسة نوع النطاق ، النطاق هو ما نحتاجه بشكل أساسي. لقد صنعنا هذا النوع ، ترجع الدالة s3.to_keyrange إلينا ، في الواقع ، النطاق. يمكننا التحقق مع عامل التشغيل المحتوي ، والعثور على القطعة التي يوجد بها مفتاحنا. ولهذا ، تم إنشاء استبعاد التقييد هنا ، مما يضمن عدم تقاطع هذه القطع. نحتاج إلى السماح ببعض القيود ، ويفضل أن يكون ذلك على مستوى قاعدة البيانات ، للتأكد من أن الأجزاء لا يمكن أن تتقاطع مع بعضها البعض ، بحيث يتم إرجاع سطر واحد فقط استجابة للطلب. وإلا فلن يكون ما أردناه. هذه هي الطريقة التي تبدو بها خطة مثل هذا الطلب ، index_scan المعتاد. يتناسب هذا الشرط تمامًا مع حالة الفهرس ، وتحتوي هذه الخطة على 700 عظمة فقط ، أقل بعشر مرات.

ما هو استبعاد القيد؟

دعنا ننشئ جدول اختبار مع عمودين ، ونضيف عائقين إليه ، أحدهما فريد يعرفه الجميع ، والآخر يستبعد القيد ، الذي له معلمات متساوية ، مثل هذه العوامل. دعنا نضعها مع عاملين متساويين ، تم بناء مثل هذه اللوحة.

ثم نحاول إدراج خطين متطابقين ، نحصل على خطأ انتهاك تفرد المفتاح في القيد الأول. إذا أسقطناه ، نكون قد انتهكنا بالفعل قيود الاستبعاد. هذه حالة شائعة لقيد فريد.

في الواقع ، القيد الفريد هو نفس قيد الاستثناء مع عامل التشغيل على قدم المساواة ، ولكن في حالة استثناء القيد ، يمكنك بناء بعض الحالات الأكثر عمومية.

لدينا مثل هذه المؤشرات. إذا نظرت عن كثب ، سترى أن كلاهما مؤشر جوهري ، وعمومًا هما نفس الشيء. ربما تسأل عن سبب تكرار هذا العمل على الإطلاق. سأخبرك.

الفهارس شيء ، خاصة مؤشر الجوهر ، بحيث يعيش الجدول حياته الخاصة ، تحدث التحديثات ، مقسمة ، وهكذا ، يصبح المؤشر سيئًا هناك ، يتوقف عن أن يكون الأمثل. وهناك مثل هذه الممارسة ، ولا سيما امتداد إعادة حزم الصفحات ، يتم إعادة بناء الفهارس بشكل دوري ، من حين لآخر يتم إعادة بنائها.
كيفية إعادة بناء فهرس تحت قيود فريدة؟ قم بإنشاء إنشاء فهرس حاليًا ، وقم بإنشاء نفس الفهرس بهدوء بجواره بدون قفل ، وبعد ذلك يكون جدول تعديل التعبير من القيد user_index كذا وكذا. وكل شيء ، كل شيء واضح وجيد هنا ، يعمل.
في حالة استبعاد القيد ، يمكنك إعادة بنائه فقط من خلال قفل reindex ، وبشكل أدق ، سيتم حظر فهرسك حصريًا ، وفي الواقع سيكون لديك جميع الاستعلامات المتبقية. هذا أمر غير مقبول ، يمكن بناء مؤشر gist لفترة كافية. لذلك ، نحتفظ بجانب المؤشر الثاني ، وهو أصغر في الحجم ، يشغل مساحة أقل ، ويستخدمه المنزلق ، ويمكننا إعادة بناء هذا المؤشر بشكل تنافسي دون حظر.
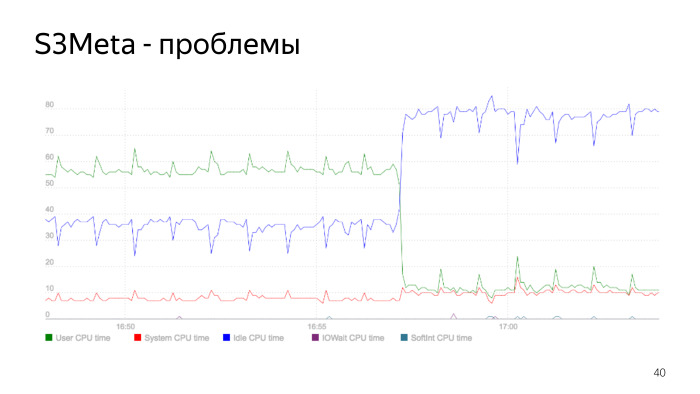
هنا رسم بياني لاستهلاك المعالج. الخط الأخضر هو استهلاك المعالج في مساحة المستخدم ، فهو يقفز من 50٪ إلى 60٪. عند هذه النقطة ، ينخفض الاستهلاك بشكل حاد ، هذه هي اللحظة التي يتم فيها إعادة بناء المؤشر. لقد أعدنا بناء المؤشر ، وحذفنا المؤشر القديم ، وانخفض استهلاك المعالج بشكل حاد. هذه مشكلة مؤشر جوهرية ، وهي كذلك ، وهذا مثال جيد على كيفية حدوث ذلك.
عندما فعلنا كل هذا ، بدأنا في الإصدار 9.5 S3DB ، وفقًا للخطة ، خططنا لتكديس 10 مليار كائن في كل قطعة. كما تعلم ، فإن أكثر من مليار وحتى المشاكل السابقة تبدأ عندما يكون للطاولة العديد من الصفوف ، يصبح كل شيء أسوأ بكثير. هناك ممارسة فراق. في ذلك الوقت كان هناك خياران ، إما قياسيًا من خلال الوراثة ، ولكن هذا لا يعمل بشكل جيد للغاية ، حيث توجد سرعة اختيار قسم خطي. وبالحكم على عدد الأشياء ، نحتاج إلى الكثير من الأقسام. بعد ذلك ، شاهد الرجال من Postgres Pro امتداد pg_pathman.

اخترنا pg_pathman ، لم يكن لدينا خيار آخر. حتى الإصدار 1.4. وكما ترى ، نستخدم 256 قسمًا. قمنا بتقسيم جدول الكائنات بالكامل إلى 256 قسمًا.
ماذا يفعل pg_pathman؟ باستخدام هذا التعبير ، يمكنك إنشاء 256 قسمًا مقسمة بواسطة التجزئة من عمود العطاء.

كيف يعمل pg_pathman؟
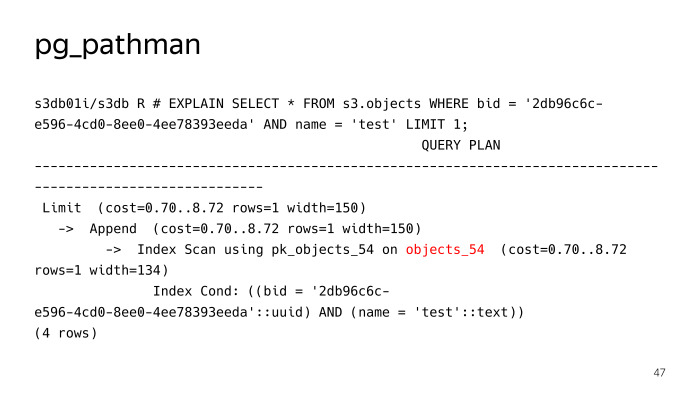
يسجل خطاطيفه في طائرة شراعية ، وكذلك في الطلبات التي يحل محلها ، في جوهرها ، الخطة. نرى أنه لم يبحث عن 256 قسمًا لاستعلام بحث عادي عن كائن باسم اختبار الاسم ، ولكن قرر على الفور أنه كان من الضروري الصعود إلى جدول الكائنات_54 ، ولكن كل شيء لم يكن بسلاسة هنا ، pg_pathman لديه مشاكله الخاصة. أولاً ، كان هناك عدد غير قليل من الأخطاء في البداية ، أثناء مشاركته ، ولكن بفضل الرجال من Postgres Pro ، قاموا بإصلاحهم بسرعة وإصلاحهم.
المشكلة الأولى هي صعوبة تحديثه. المشكلة الثانية هي البيانات المعدة.
دعونا نفكر بمزيد من التفصيل. على وجه الخصوص ، التحديث. مما يتكون pg_pathman؟

يتكون بشكل أساسي من رمز C ، والذي يتم تجميعه في مكتبة. وتتكون من جزء SQL ، وجميع أنواع الوظائف لإنشاء الأقسام ، وما إلى ذلك. بالإضافة إلى ذلك ، واجهات إلى الوظائف الموجودة في المكتبة. لا يمكن تحديث هذين الجزأين في نفس الوقت.
من هنا تنشأ صعوبات ، شيء مثل هذه الخوارزمية لتحديث إصدار pg_pathman ، نبدأ أولاً حزمة جديدة مع إصدار جديد ، ولكن PostgreSQL يحتوي على إصدارات قديمة محملة في الذاكرة ، ويستخدمها. هذا على الفور في أي حال ، يجب إعادة تشغيل القاعدة.
بعد ذلك ، نسمي الدالة set_enable_parent ، حيث تقوم بتشغيل الوظيفة في الجدول الأصلي ، والتي يتم إيقاف تشغيلها افتراضيًا. بعد ذلك ، أوقف تشغيل pathman ، وأعد تشغيل قاعدة البيانات ، قل ALTER EXTENSION UPDATE ، في هذا الوقت يقع كل شيء في الجدول الرئيسي.
بعد ذلك ، قم بتشغيل pathman ، وقم بتشغيل الوظيفة ، الموجودة في الامتداد ، والتي تنقل الكائنات من الجدول الأصلي الذي هاجمها في هذه الفترة القصيرة من الزمن ، ثم تنقلها مرة أخرى إلى الجداول حيث يجب أن تقع. ثم قم بإيقاف استخدام الجدول الأصل ، ابحث فيه.

المشكلة التالية هي البيانات المعدة.

إذا قمنا بحظر نفس الطلب العادي ، فابحث عن طريق العطاء والمفتاح ، وحاول تنفيذه. أداء خمس مرات - كل شيء على ما يرام. نقوم بتنفيذ السادس - نرى مثل هذه الخطة. وفي هذا الصدد نرى جميع أقسام 256. إذا نظرت عن كثب إلى هذه الظروف ، فإننا نرى الدولار 1 ، الدولار 2 ، وهذا ما يسمى بالخطة العامة ، الخطة العامة. تم بناء الاستعلامات الخمسة الأولى بشكل فردي ، وتم استخدام الخطط الفردية لهذه المعلمات ، ويمكن أن يحدد pg_pathman على الفور ، لأن المعلمة معروفة مسبقًا ، يمكنها تحديد الجدول على الفور. في هذه الحالة ، لا يمكنه القيام بذلك. وفقًا لذلك ، يجب أن تحتوي الخطة على جميع الأقسام البالغ عددها 256 قسمًا ، وعندما يذهب المنفذ للقيام بذلك ، يذهب ويأخذ قفلًا مشتركًا لجميع الأقسام البالغ عددها 256 قسمًا ، ولا يكون أداء هذا الحل على الفور. إنها ببساطة تفقد كل مزاياها ، ويتم تنفيذ أي طلب بجنون لفترة طويلة.

كيف خرجنا من هذا الوضع؟ اضطررت إلى لف كل شيء داخل الإجراءات المخزنة في التنفيذ ، في SQL الديناميكية ، حتى لا يتم استخدام العبارات المعدة ويتم بناء الخطة في كل مرة. هكذا تعمل.
الجانب السلبي هو أنه يجب عليك حشر جميع التعليمات البرمجية في الهياكل التي تلمس هذه الجداول. هذا أصعب للقراءة هنا.

كيف يتم توزيع الأشياء؟ في كل جزء S3DB ، يتم تخزين عدادات القطعة ، وهناك أيضًا معلومات حول أي قطع موجودة في هذا الجزء ، ويتم تخزين العدادات لهم. لكل عملية متحولة على كائن - إضافة أو حذف أو تغيير أو إعادة كتابة - هذه العدادات لتغيير القطعة. من أجل عدم تحديث نفس الخط عندما يكون الصب النشط في هذه القطعة ، نستخدم تقنية قياسية إلى حد ما عندما ندرج عداد دلتا في جدول منفصل ، ومرة في الدقيقة يمر روبوت خاص ويجمع كل هذا ، يقوم بتحديث العدادات في القطعة .

علاوة على ذلك ، يتم تسليم هذه العدادات إلى S3Meta مع بعض التأخير ، هناك بالفعل صورة كاملة عن عدد العدادات التي توجد فيها قطعة ، ثم يمكنك إلقاء نظرة على التوزيع بالقطع ، وعدد العناصر الموجودة في أي جزء ، وبناءً على ذلك ، يتم اتخاذ قرار حيث يقع الجزء الجديد. عندما تقوم بإنشاء دلو ، بشكل افتراضي ، يتم إنشاء قطعة واحدة من ناقص اللانهاية إلى اللانهاية ، اعتمادًا على التوزيع الحالي للكائنات التي يعرفها S3Meta ، فإنه يقع في نوع من القطع.
عندما تصب البيانات في هذا الدلو ، يتم سكب كل هذه البيانات في هذه القطعة ، عندما يتم الوصول إلى حجم معين ، يأتي روبوت خاص ويشارك هذه القطعة.

نجعل هذه القطع صغيرة. نقوم بذلك بحيث يمكن في هذه الحالة سحب هذه القطعة الصغيرة إلى جزء آخر. كيف يحدث تقسيم القطعة؟ هنا روبوت عادي ، يذهب ويقسم هذا الجزء في S3DB مع الالتزام على مرحلتين وتحديث المعلومات في S3Meta.
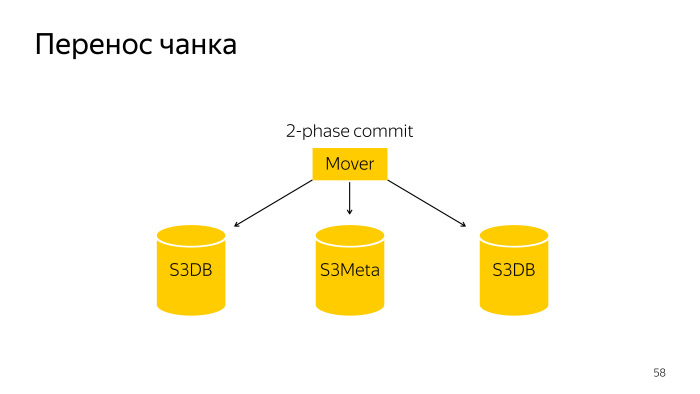
نقل القطعة عبارة عن عملية أكثر تعقيدًا بعض الشيء ؛ وهي عبارة عن التزام على مرحلتين على ثلاث قواعد ، S3Meta وقطعتان ، S3DB ، تسحب من واحدة إلى أخرى.

يحتوي S3 على ميزة مثل القوائم ، وهذا هو أصعب شيء ، وكانت هناك مشكلات أيضًا. في الواقع ، القوائم ، كما تقول S3 - أرني الأشياء التي لدي. المعلمة المميزة باللون الأحمر هي الآن خالية. هذه المعلمة ، محدد ، فاصل ، يمكنك تحديد القوائم التي تريد الفاصل.
ماذا يعني هذا؟ إذا لم يتم تعيين المحدد ، فإننا نرى ببساطة أن لدينا قائمة بالملفات. إذا قمنا بتعيين المحدد ، في الجوهر ، يجب أن تظهر لنا S3 المجلدات. يجب أن أفهم أن هناك مثل هذه المجلدات ، وفي الواقع ، فإنه يعرض جميع المجلدات والملفات الموجودة في المجلد الحالي. يكون المجلد الحالي مسبوقًا ، وهذه المعلمة فارغة. نرى أن هناك 10 مجلدات.
لا يتم تخزين جميع المفاتيح في نوع ما من هيكل شجرة هرمي ، كما هو الحال في نظام الملفات. يتم تخزين كل كائن كسلسلة ، ولديهم بادئة مشتركة بسيطة. يجب أن يفهم S3 نفسه أن هذا الحمار.

SQL, . , PL/pgSQL. , repeatable read. , . , - - , .
Recursive CTE, , - , execute PL/pgSQL. , . , , , list objects. , .
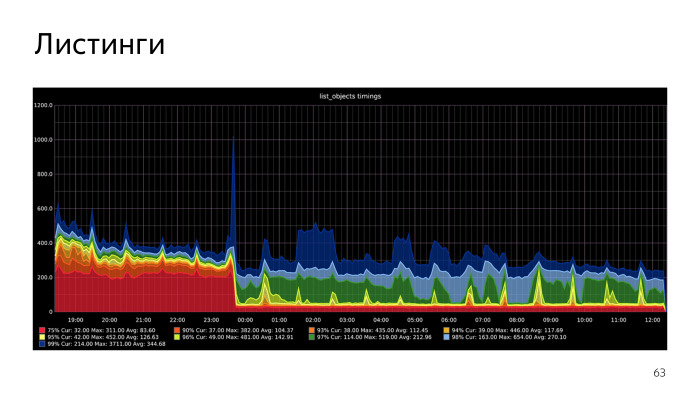
, .
. , .
Docker,
Behave Behave
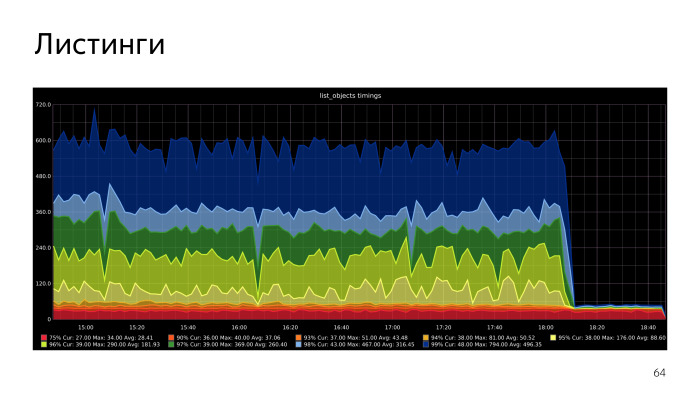
. , , , .
. , , CPU S3Meta. Gist index CPU, , . CPU S3Meta . , . PLProxy , S3Meta S3DB. , . S3Meta . , .
في النسخ المتماثل المنطقي ، هناك عدد من المشاكل التي سنحلها ، وسنحاول دفعها إلى أعلى. الخيار الثاني - يمكنك رفض الرسم البياني ، حاول وضع نطاق النص هذا في btree. هذا ليس نوعًا أحادي البعد ، ويعمل btree فقط مع الأنواع أحادية البعد. لكن شرط عدم تداخل القطع معنا سيسمح لنا بوضع قضيتنا في btree. بالأمس فقط قمنا بعمل نموذج أولي يعمل. يتم تنفيذه على وظائف PL / pgSQL. لقد حصلنا على تسارع ملحوظ ، وسوف نحسن في هذا الاتجاه.