عندما بدأ Dropbox للتو ، علق مستخدم على Hacker News أنه يمكن تنفيذه باستخدام العديد من البرامج النصية bash باستخدام FTP و Git. الآن لا يمكن أن يقال هذا بأي شكل من الأشكال ، هذا هو تخزين كبير للملفات السحابية مع مليارات الملفات الجديدة كل يوم ، والتي لا يتم تخزينها بطريقة أو بأخرى في قاعدة البيانات ، ولكن بطريقة يمكن بها استعادة أي قاعدة بيانات إلى أي نقطة خلال الأيام الستة الماضية.
تحت القطع ، نص تقرير
Glory Bakhmutov (
m0sth8 ) في Highload ++ 2017 ، حول كيفية تطوير قواعد البيانات في Dropbox وكيف يتم ترتيبها الآن.
حول المتحدث: المجد إلى Bakhmutov - مهندس موثوقية الموقع في فريق Dropbox ، يحب Go كثيرًا ويظهر أحيانًا في بودكاست golangshow.com.
المحتويات
هندسة Dropbox بلغة بسيطة
ظهر Dropbox في عام 2008. هذا هو في الأساس تخزين ملفات سحابة. عندما بدأ Dropbox للتو ، علق مستخدم في Hacker News أنه يمكن تنفيذه باستخدام العديد من البرامج النصية bash باستخدام FTP و Git. ولكن ، مع ذلك ، فإن Dropbox يتطور ، وهي الآن خدمة كبيرة إلى حد ما مع أكثر من 1.5 مليار مستخدم ، و 200 ألف شركة وعدد كبير (عدة مليارات!) من الملفات الجديدة كل يوم.
كيف يبدو Dropbox؟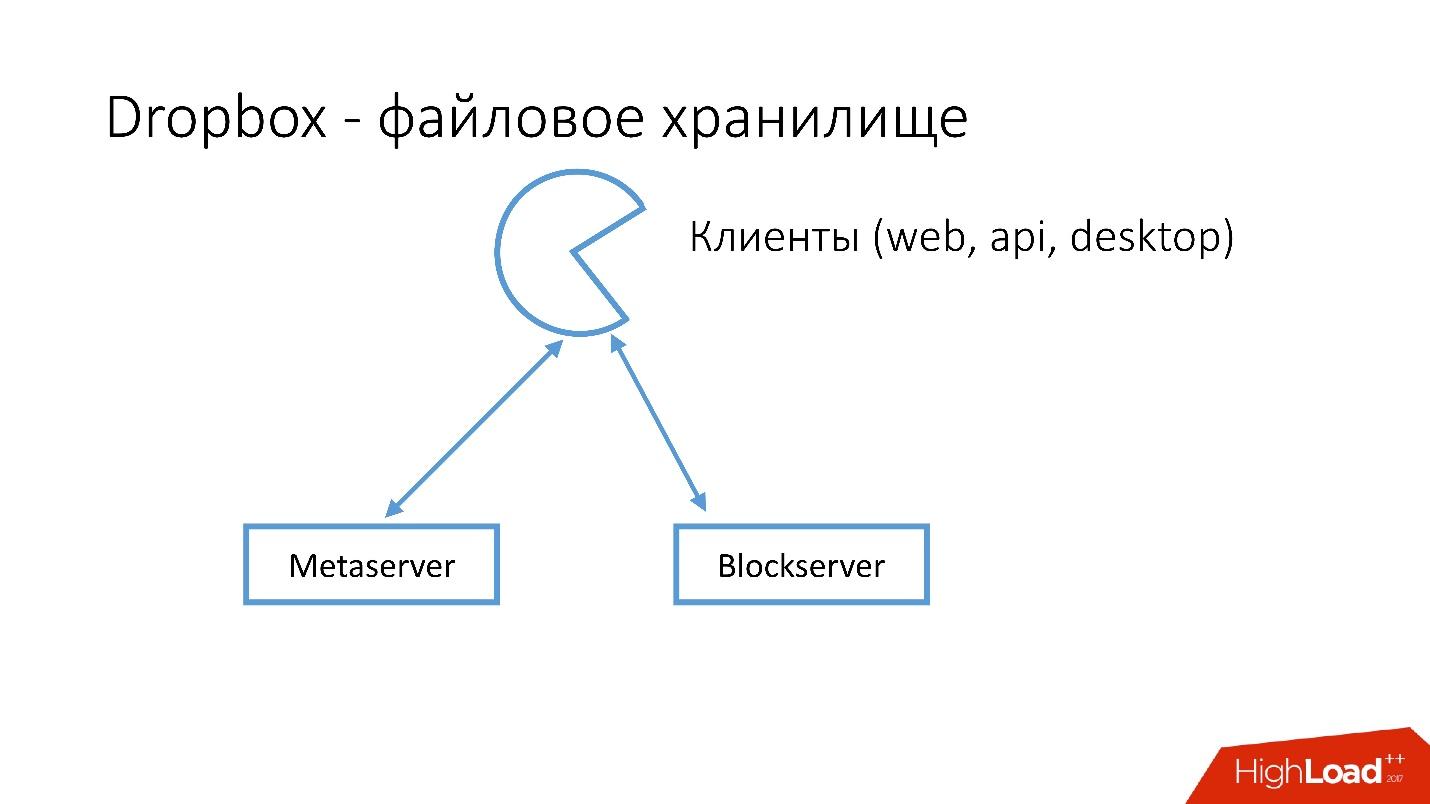
لدينا العديد من العملاء (واجهة الويب ، API للتطبيقات التي تستخدم Dropbox ، تطبيقات سطح المكتب). يستخدم جميع هؤلاء العملاء واجهة برمجة التطبيقات ويتواصلون مع خدمتين كبيرتين يمكن تقسيمهما منطقيًا إلى:
- Metaserver
- بلوك سيرفر
يخزن Metaserver معلومات تعريفية عن الملف: الحجم ، والتعليقات عليه ، والروابط إلى هذا الملف في Dropbox ، وما إلى ذلك. يقوم Blockserver بتخزين المعلومات حول الملفات فقط: المجلدات ، المسارات ، إلخ.
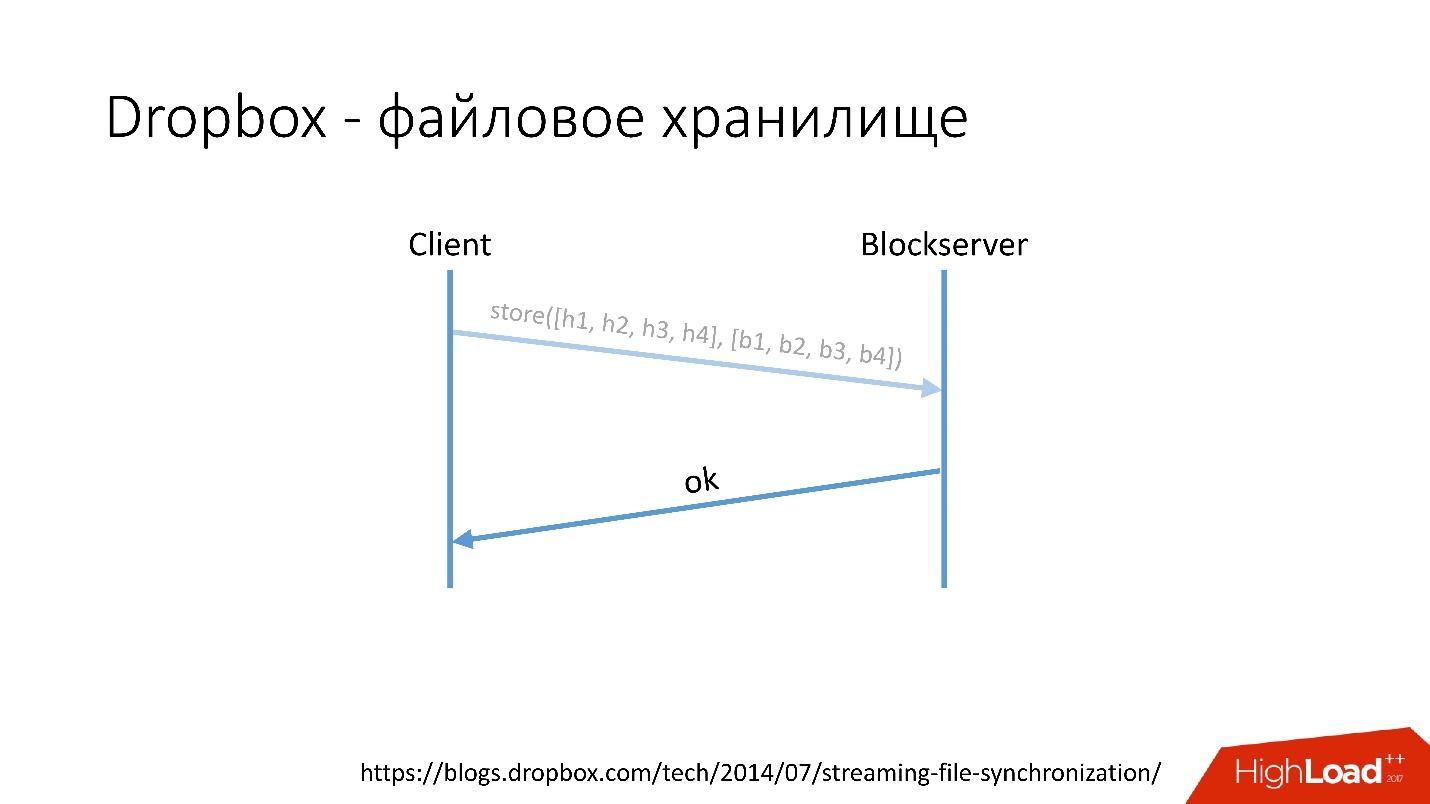
كيف يعمل؟على سبيل المثال ، لديك ملف video.avi مع نوع من الفيديو.
 رابط من الشريحة
رابط من الشريحة- يقوم العميل بتقسيم هذا الملف إلى عدة أجزاء (في هذه الحالة ، 4 ميغابايت لكل منها) ، ويحسب المجموع الاختباري ويرسل طلبًا إلى Metaserver: "لدي ملف * .avi ، وأريد تحميله ، ومقدار التجزئة مثل هذا".
- يعرض Metaserver الجواب: "ليس لدي هذه الكتل ، دعنا ننزل!" أو يمكنه أن يجيب أن لديه كل أو بعض الكتل ، وأن الباقي فقط يحتاج إلى التحميل.
 رابط من الشريحة
رابط من الشريحة- بعد ذلك ، يذهب العميل إلى Blockserver ، ويرسل كمية التجزئة وكتلة البيانات نفسها ، والتي يتم تخزينها على Blockserver.
- يؤكد Blockserver العملية.
 رابط من الشريحة
رابط من الشريحةبالطبع ، هذا مخطط مبسط للغاية ، البروتوكول أكثر تعقيدًا: هناك تزامن بين العملاء داخل نفس الشبكة ، وهناك برامج تشغيل kernel ، والقدرة على حل التصادمات ، وما إلى ذلك. هذا بروتوكول معقد إلى حد ما ، لكنه يعمل مثل هذا بشكل تخطيطي.

عندما يقوم العميل بحفظ شيء ما على Metaserver ، يتم نقل جميع المعلومات إلى MySQL. يقوم Blockserver أيضًا بتخزين معلومات حول الملفات ، وكيف يتم هيكلتها ، والكتل التي تتكون منها ، في MySQL. يقوم Blockserver أيضًا بتخزين الكتل نفسها في Block Storage ، والتي بدورها تخزن معلومات حول مكان الكتل ، على أي خادم وكيفية معالجتها ، أيضًا في MYSQL.
لتخزين ملفات exabytes ، نقوم في نفس الوقت بتخزين معلومات إضافية في قاعدة بيانات تضم عشرات البيتابايتات المنتشرة عبر 6 آلاف خادم.
تاريخ تطوير قاعدة البيانات
كيف تطورت قواعد البيانات في Dropbox؟

في عام 2008 ، بدأ كل شيء بقاعدة بيانات Metaserver واحدة وقاعدة بيانات عالمية واحدة. جميع المعلومات التي يحتاجها Dropbox لتخزينها في مكان ما ، حفظها في MySQL العالمي الوحيد. لم يدم ذلك طويلاً ، لأن عدد المستخدمين زاد ، وتضخم قواعد البيانات الفردية والأجهزة اللوحية داخل قواعد البيانات بشكل أسرع من غيرها.

لذلك ، في عام 2011 تم تقديم عدة جداول إلى خوادم منفصلة:
- المستخدم ، مع معلومات حول المستخدمين ، على سبيل المثال ، تسجيلات الدخول ورموز oAuth المميزة ؛
- المضيف ، مع معلومات الملف من Blockserver ؛
- متفرقات ، التي لم تشارك في معالجة الطلبات من الإنتاج ، ولكن تم استخدامها لوظائف المنفعة ، مثل المهام المجمعة.
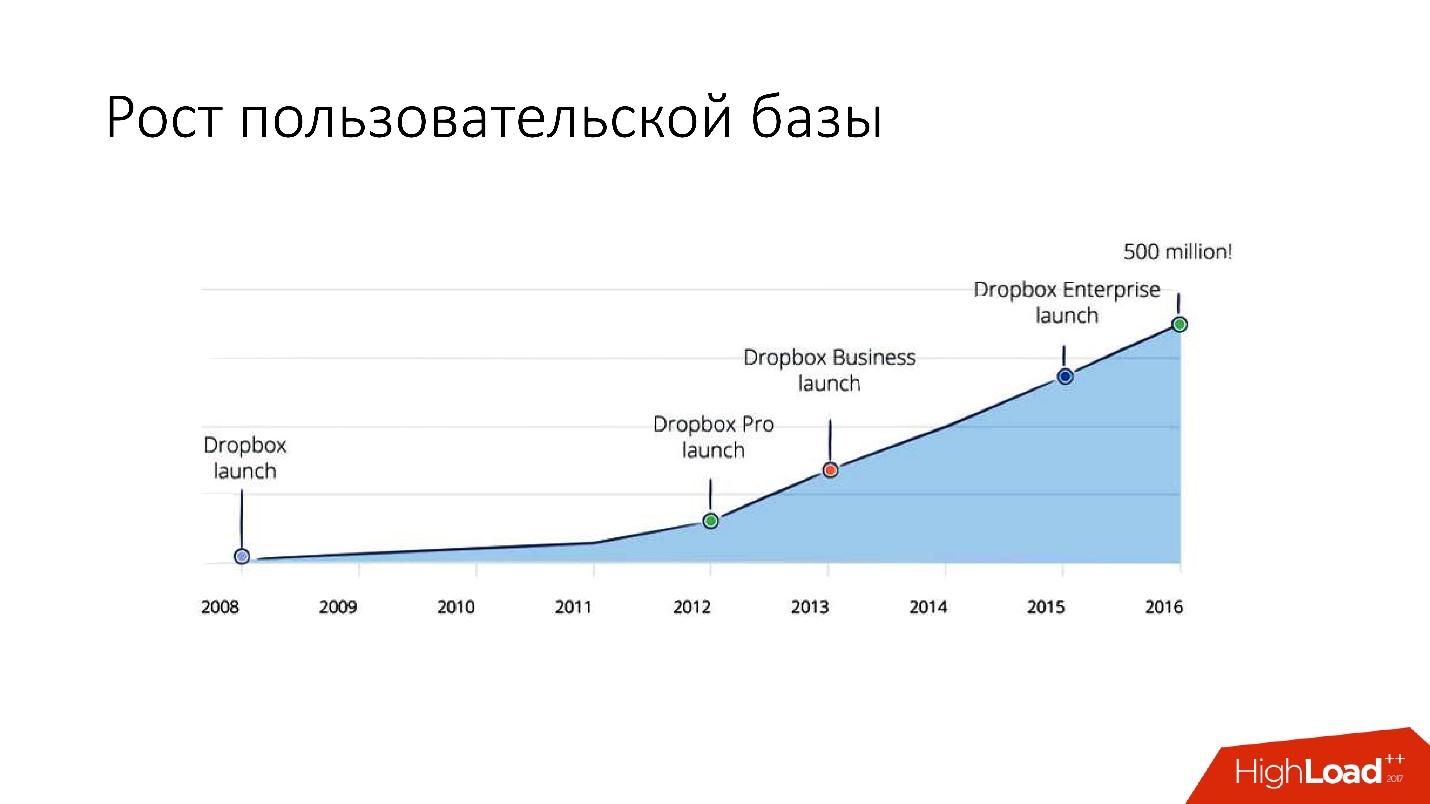
ولكن بعد عام 2012 ، بدأ Dropbox في النمو كثيرًا ، ومنذ ذلك الحين نما عددنا
بنحو 100 مليون مستخدم سنويًا .
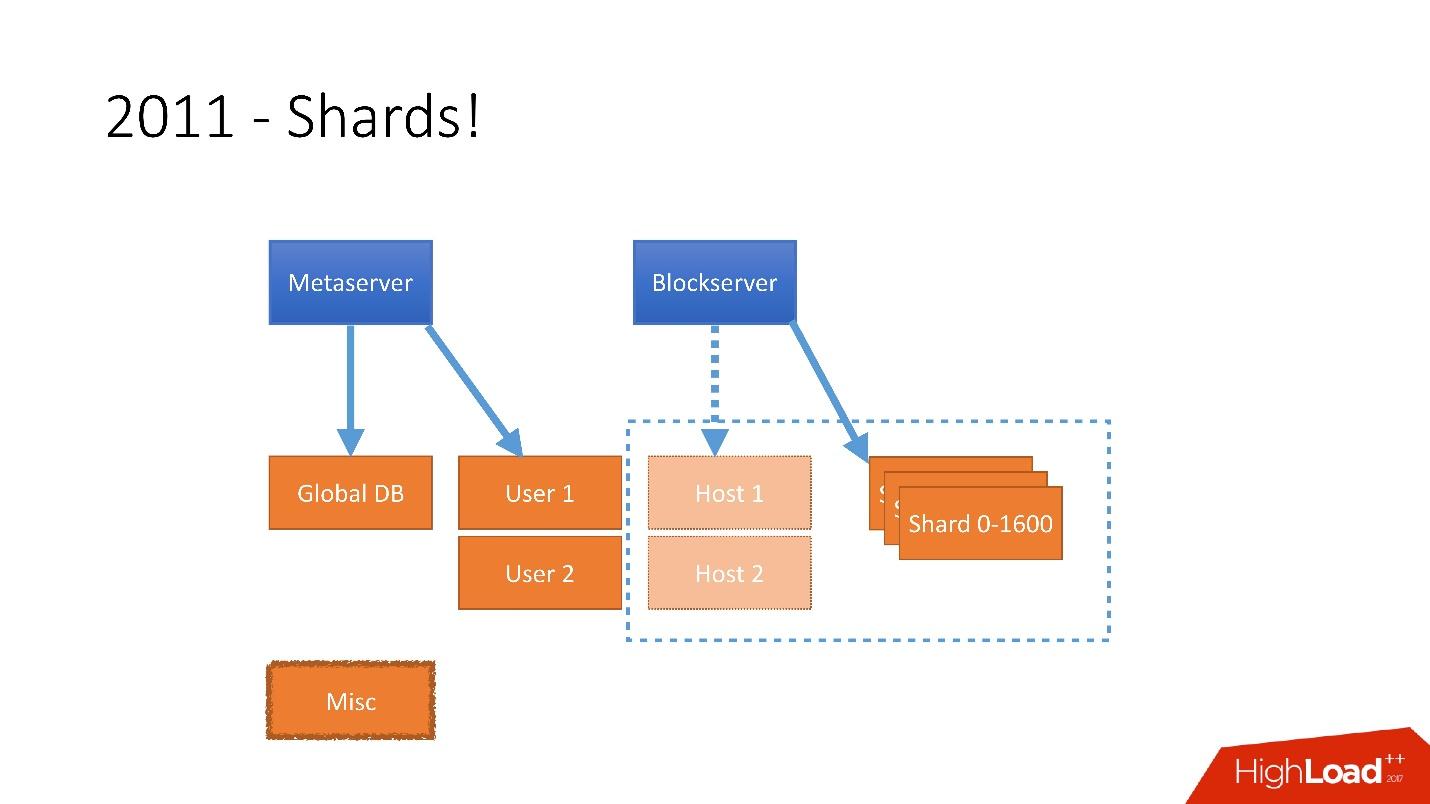
كان من الضروري مراعاة هذا النمو الهائل ، وبالتالي كان لدينا شظايا في نهاية عام 2011 - قاعدة تتكون من 1600 شظية. في البداية ، 8 خوادم فقط مع 200 جزء لكل منها. الآن أصبح عدد الخوادم الرئيسية 400 خادمًا مع 4 أجزاء.
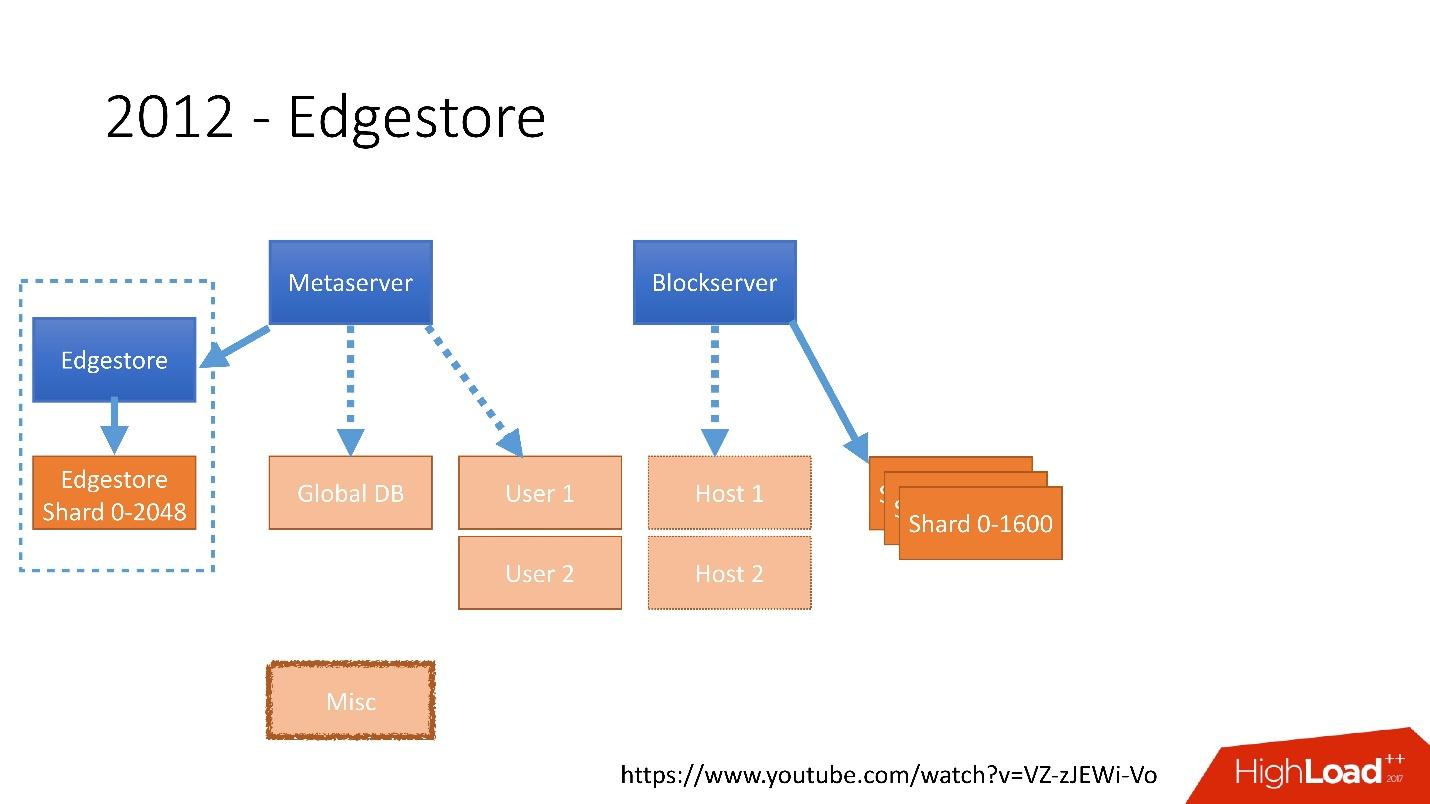 رابط من الشريحة
رابط من الشريحةفي عام 2012 ، أدركنا أن إنشاء الجداول وتحديثها في قاعدة البيانات لكل منطق عمل إضافي أمر صعب للغاية ، كئيب ومشاكل. لذلك ، في عام 2012 ، اخترعنا تخزين الرسم البياني الخاص بنا ، والذي أطلقنا عليه اسم
Edgestore ، ومنذ ذلك الحين يتم تخزين كل منطق الأعمال والمعلومات الوصفية التي ينشئها التطبيق في Edgestore.
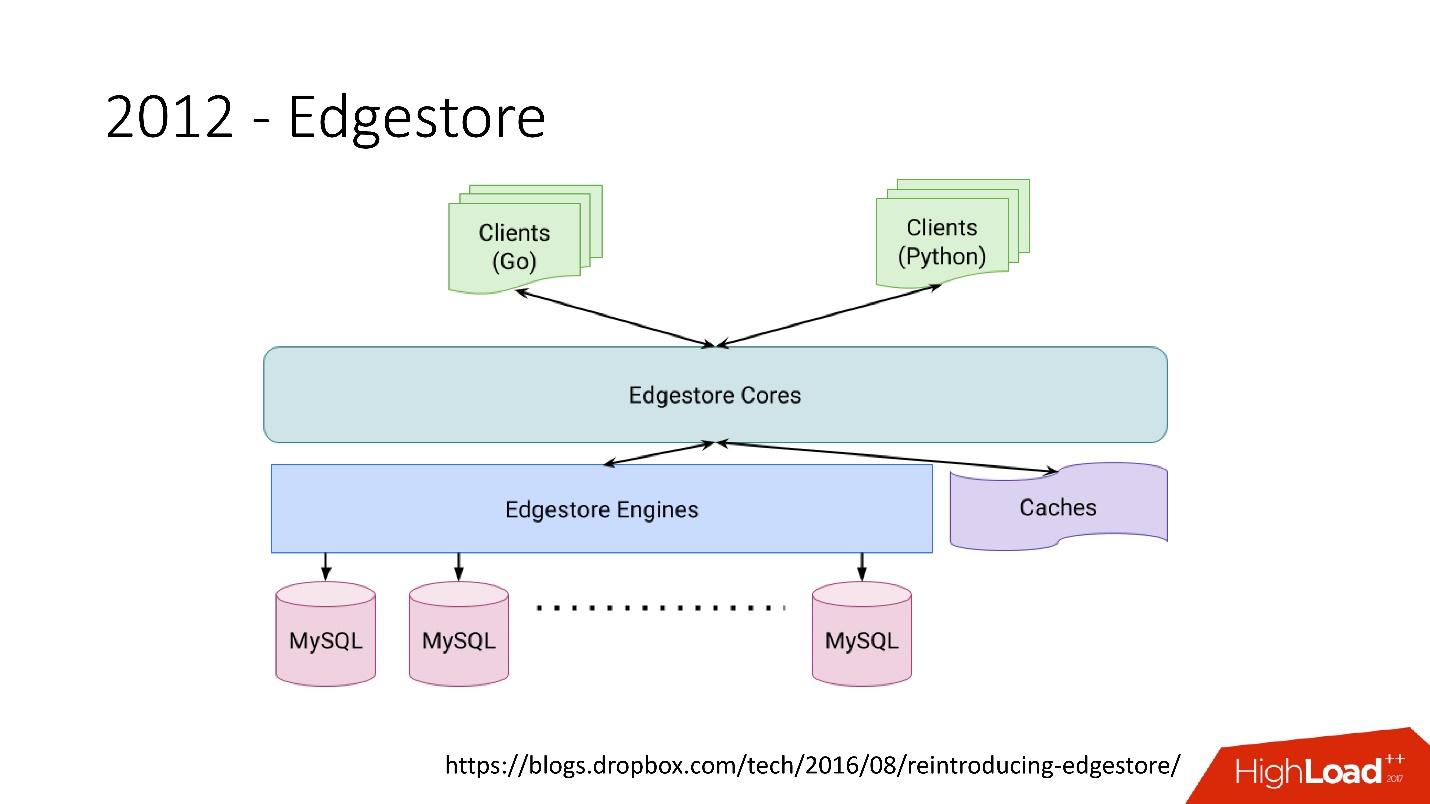
تقوم Edgestore بشكل أساسي بتلخيص MySQL من العملاء. لدى العملاء كيانات معينة مترابطة من خلال روابط من gRPC API إلى Edgestore Core ، والتي تحول هذه البيانات إلى MySQL وتقوم بتخزينها بطريقة ما (بشكل أساسي ، تقدم كل هذا من ذاكرة التخزين المؤقت).
 رابط من الشريحةفي عام 2015 ، غادرنا Amazon S3 ، وقمنا
رابط من الشريحةفي عام 2015 ، غادرنا Amazon S3 ، وقمنا بتطوير التخزين السحابي الخاص بنا والذي يسمى Magic Pocket. يحتوي على معلومات حول مكان وجود ملف كتلة ، على أي خادم ، حول تحركات هذه الكتل بين الخوادم ، المخزنة في MySQL.
 رابط من الشريحة
رابط من الشريحةولكن يتم استخدام MySQL بطريقة صعبة للغاية - في الأساس ، كجدول تجزئة كبير موزع. هذا حمل مختلف تمامًا ، بشكل أساسي عن قراءة السجلات العشوائية. 90 ٪ من الاستخدام هو I / O.
هندسة قاعدة البيانات
أولاً ، حددنا على الفور بعض المبادئ التي نبني بها بنية قاعدة بياناتنا:
- الموثوقية والمتانة . هذا هو أهم مبدأ وما يتوقعه العملاء منا - لا يجب فقدان البيانات.
- مثلى الحل مبدأ بنفس القدر من الأهمية. على سبيل المثال ، يجب إجراء النسخ الاحتياطية بسرعة واستعادتها بسرعة أيضًا.
- بساطة الحل - سواء من الناحية المعمارية أو من حيث الخدمة والمزيد من دعم التطوير.
- تكلفة الملكية . إذا كان هناك شيء ما يحسن الحل ، ولكنه مكلف للغاية ، فهذا لا يناسبنا. على سبيل المثال ، يعد العبد الذي يكون خلف السيد يومًا ما مناسبًا جدًا للنسخ الاحتياطية ، ولكنك تحتاج بعد ذلك إلى إضافة 1000 خادم إضافي إلى 6000 خادم - تكلفة ملكية هذا العبد مرتفعة جدًا.
يجب أن تكون جميع المبادئ قابلة
للتحقق منها وقابلة للقياس ، أي يجب أن يكون لها مقاييس. إذا كنا نتحدث عن تكلفة الملكية ، فيجب أن نحسب عدد الخوادم لدينا ، على سبيل المثال ، الذي يذهب إلى قواعد البيانات ، وعدد الخوادم التي تذهب إلى النسخ الاحتياطية ، وكم يكلف Dropbox في النهاية. عندما نختار حلًا جديدًا ، فإننا نحسب جميع المقاييس ونركز عليها. عند اختيار أي حل ، نسترشد تمامًا بهذه المبادئ.
طوبولوجيا القاعدة
تم بناء قاعدة البيانات على النحو التالي:
- في مركز البيانات الرئيسي ، لدينا سيد ، تحدث فيه جميع السجلات.
- يحتوي الخادم الرئيسي على خادمين تابعين يحدث فيه النسخ المتماثل شبه المتزامن. غالبًا ما تموت الخوادم (حوالي 10 في الأسبوع) ، لذلك نحتاج إلى خادمين تابعين.
- خوادم الرقيق في مجموعات منفصلة. المجموعات عبارة عن غرف منفصلة تمامًا في مركز البيانات غير متصلة ببعضها البعض. إذا احترقت غرفة واحدة ، تظل الثانية تعمل بشكل كامل.
- أيضا في مركز بيانات آخر لدينا ما يسمى سيد زائف (سيد متوسط) ، وهو في الواقع مجرد عبد ، ولديه عبد آخر.
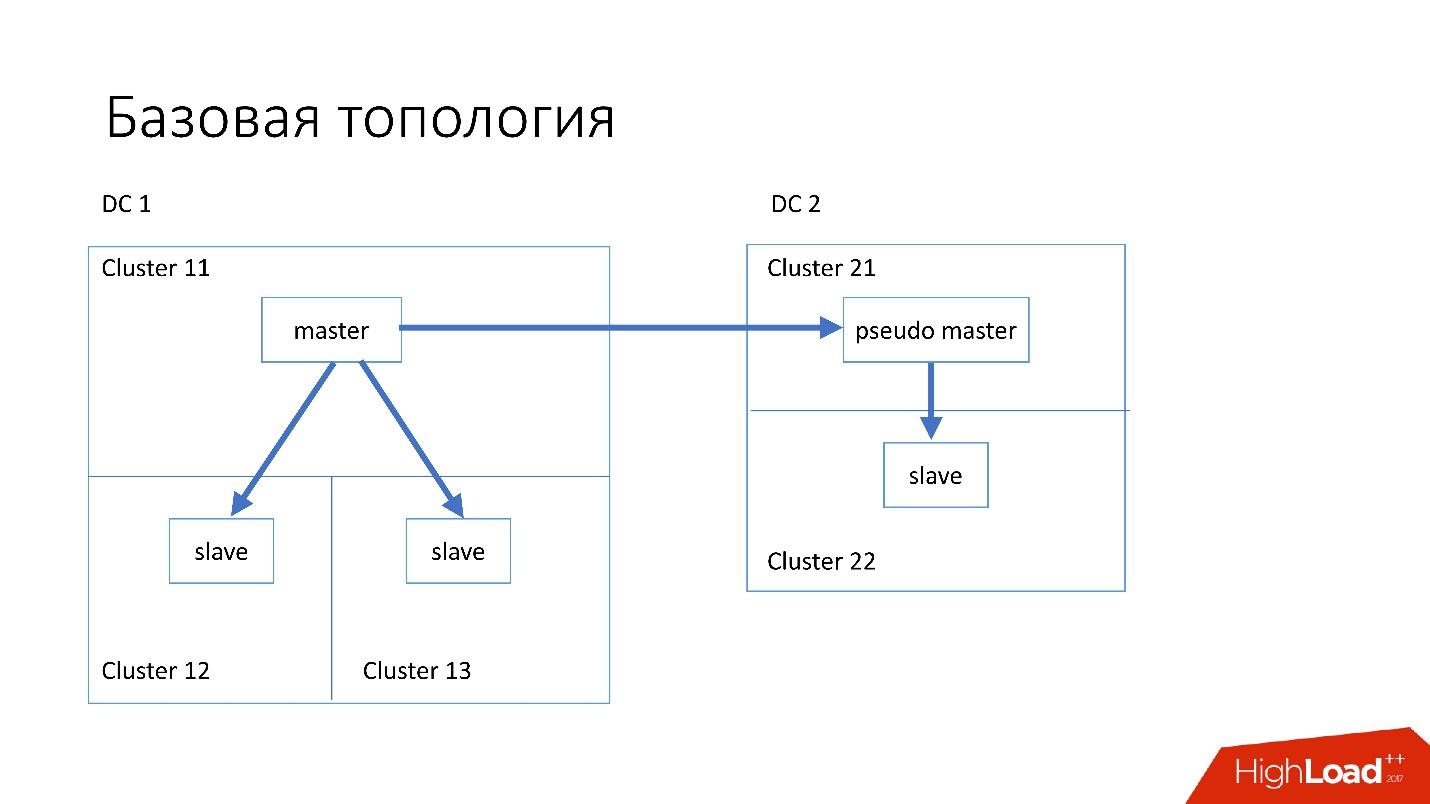
تم اختيار هذه الطوبولوجيا لأنه إذا مات مركز البيانات الأول فجأة فينا ، فعندئذٍ يكون لدينا في مركز البيانات الثاني
طبولوجيا كاملة تقريبًا . نقوم ببساطة بتغيير جميع العناوين في Discovery ، ويمكن للعملاء العمل.
الطوبولوجيا المتخصصة
لدينا أيضا طوبولوجيا متخصصة.
يتكون طوبولوجيا
Magic Pocket من خادم رئيسي واحد وخادمين تابعين. يتم ذلك لأن Magic Pocket نفسه يكرر البيانات بين المناطق. إذا فقدت كتلة واحدة ، يمكنها استعادة جميع البيانات من مناطق أخرى من خلال رمز المحو.

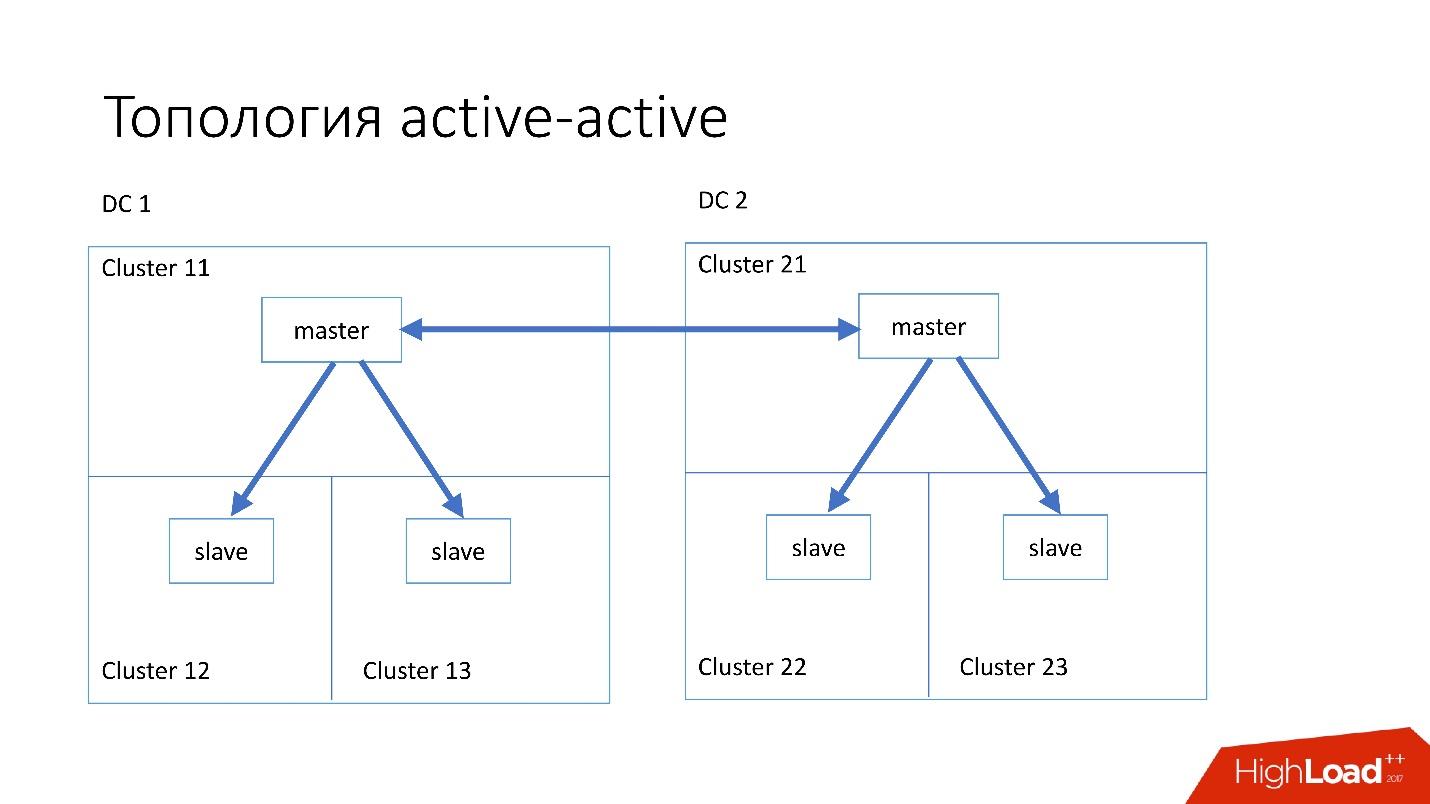
الطوبولوجيا
النشطة النشطة هي الطبولوجيا المخصصة التي يستخدمها Edgestore. ولديها سيد واحد واثنان من العبيد في كل من مركزي البيانات ، وهما عبيد لبعضهما البعض. هذا
مخطط خطير للغاية ، لكن Edgestore في مستواه يعرف تمامًا ما هي البيانات التي يعتمد عليها أي سيد على النطاق الذي يمكنه الكتابة فيه. لذلك ، لا ينكسر هذا الطبولوجيا.
المثيل
لقد قمنا بتثبيت خوادم بسيطة إلى حد ما مع تكوين قبل 4-5 سنوات:
- 2x زيون 10 نوى ؛
- 5 تيرابايت (8 SSD Raid 0 *) ؛
- ذاكرة 384 جيجا بايت.
* رائد 0 - لأنه من الأسهل والأسرع بكثير استبدال خادم كامل من محركات الأقراص.
مثيل واحد
على هذا الخادم ، لدينا مثيل MySQL واحد كبير حيث توجد العديد من الأجزاء. يخصص مثيل MySQL هذا على الفور كل الذاكرة تقريبًا. يتم تشغيل العمليات الأخرى أيضًا على الخادم: الوكيل ، وجمع الإحصاءات ، والسجلات ، وما إلى ذلك.
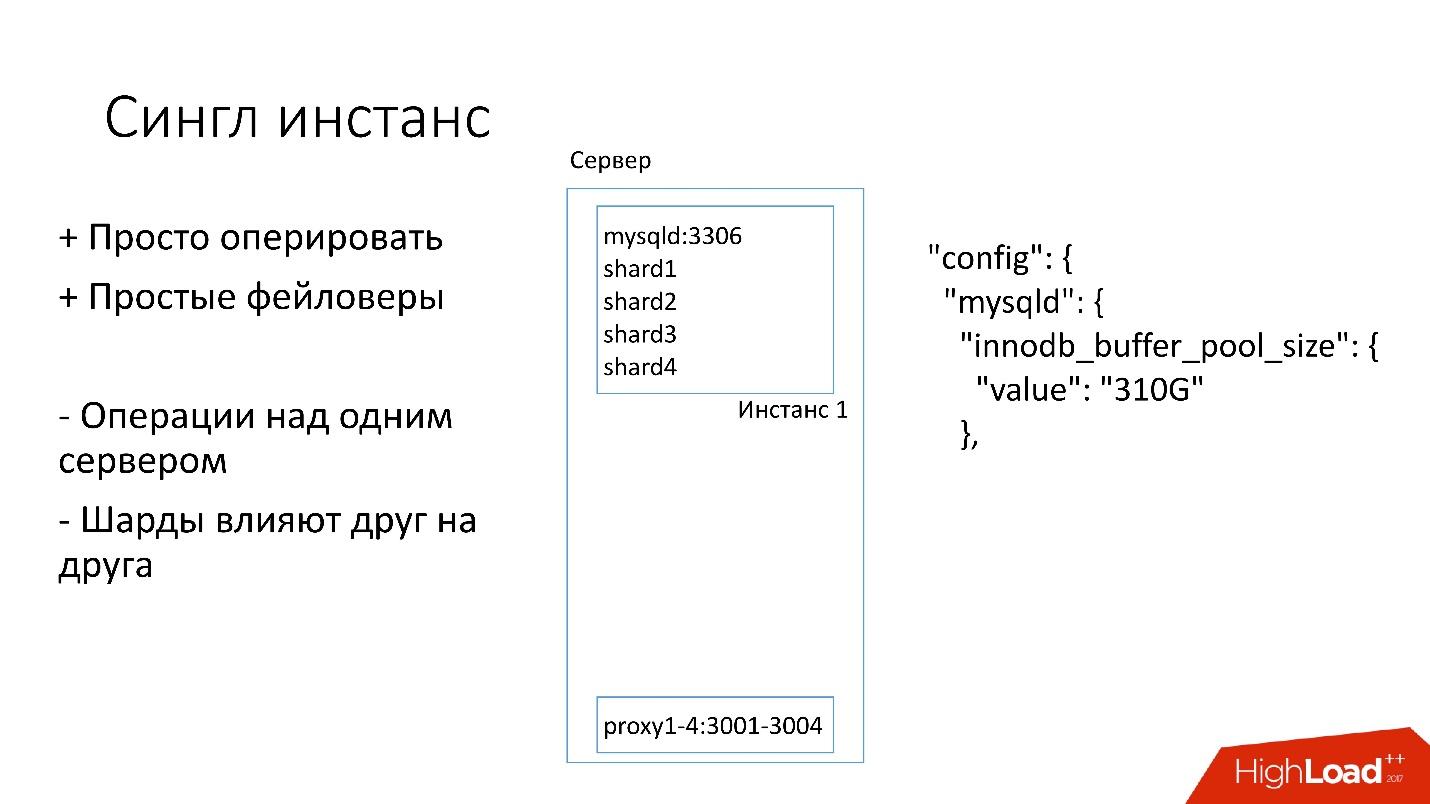
هذا الحل جيد في ذلك:
+ من
السهل إدارتها . إذا كنت بحاجة إلى استبدال مثيل MySQL ، فما عليك سوى استبدال الخادم.
+ قم
فقط faylovers .
من ناحية أخرى:
- من الصعب حدوث أي عمليات على نسخة MySQL بأكملها وعلى الفور على جميع الأجزاء. على سبيل المثال ، إذا كنت بحاجة إلى النسخ الاحتياطي ، فإننا نقوم بنسخ جميع الأجزاء احتياطيًا مرة واحدة. إذا كنت بحاجة إلى جعل faylover ، فإننا نصنع faylover من جميع الأجزاء الأربعة دفعة واحدة. وبناءً على ذلك ، فإن إمكانية الوصول تعاني أكثر من 4 أضعاف.
- مشكلات تكرار قطعة واحدة تؤثر على أجزاء أخرى. النسخ المتماثل لـ MySQL ليس متوازيًا ، وتعمل جميع الأجزاء على خيط واحد. إذا حدث شيء لقطعة واحدة ، يصبح الباقي أيضًا ضحايا.
الآن نحن ننتقل إلى طوبولوجيا مختلفة.
مثيل متعدد

في الإصدار الجديد ، يتم إطلاق العديد من مثيلات MySQL على الخادم في وقت واحد ، لكل منها جزء واحد. ما هو الأفضل؟
+ يمكننا
تنفيذ عمليات فقط على جزء واحد محدد . أي إذا كنت بحاجة إلى faylover ، فقم بتبديل جزء واحد فقط ، إذا كنت بحاجة إلى نسخة احتياطية ، فإننا نقوم بنسخ جزء واحد فقط احتياطيًا. هذا يعني أن العمليات يتم تسريعها بشكل كبير - 4 مرات لخادم ذو أربعة أجزاء.
بالكاد تؤثر شظايا على بعضها البعض .
+
تحسين النسخ المتماثل. يمكننا مزج فئات وفئات مختلفة من قواعد البيانات. تستهلك Edgestore مساحة كبيرة ، على سبيل المثال ، كل 4 تيرابايت ، ويشغل Magic Pocket مساحة 1 تيرابايت فقط ، ولكنه يستخدم 90٪. أي أنه يمكننا الجمع بين الفئات المختلفة التي تستخدم I / O وموارد الجهاز بطرق مختلفة ، وبدء 4 تيارات للنسخ المتماثل.
بالطبع ، هذا الحل له عيوبه:
- أكبر ناقص هو أنه من
الصعب إدارة كل هذا . نحتاج إلى جدولة ذكية تدرك أين يمكنه أخذ هذا المثال ، حيث سيكون هناك حمل مثالي.
-
أصعب من الفشل .
لذلك ، نحن ننتقل الآن فقط إلى هذا القرار.
الاكتشاف
يجب أن يعرف العملاء بطريقة أو بأخرى كيفية الاتصال بقاعدة البيانات المطلوبة ، لذلك لدينا Discovery ، والتي يجب أن:
- إعلام العميل بسرعة كبيرة حول تغييرات الهيكل. إذا قمنا بتغيير السيد والعبد ، يجب على العملاء التعرف عليه على الفور تقريبًا.
- لا يجب أن تعتمد الطوبولوجيا على طبولوجيا النسخ المتماثل لـ MySQL ، لأنه في بعض العمليات نقوم بتغيير طبولوجيا MySQL. على سبيل المثال ، عندما نقوم بالتقسيم ، في الخطوة التحضيرية على الهدف الرئيسي ، حيث سننقل جزءًا من الأجزاء ، تتم إعادة تكوين بعض خوادم العبيد إلى هذا الهدف الرئيسي. لا يحتاج العملاء إلى معرفة ذلك.
- من المهم أن يكون هناك ذرية للعمليات والتحقق من الدولة. من المستحيل أن يصبح خادمان مختلفان من نفس قاعدة البيانات سيدان في نفس اللحظة.
كيف تطور الاكتشاف
في البداية كان كل شيء بسيطًا: عنوان قاعدة البيانات في التعليمات البرمجية المصدر في التكوين. عندما كنا بحاجة إلى تحديث العنوان ، تم نشر كل شيء بسرعة كبيرة.

للأسف ، هذا لا يعمل إذا كان هناك الكثير من الخوادم.
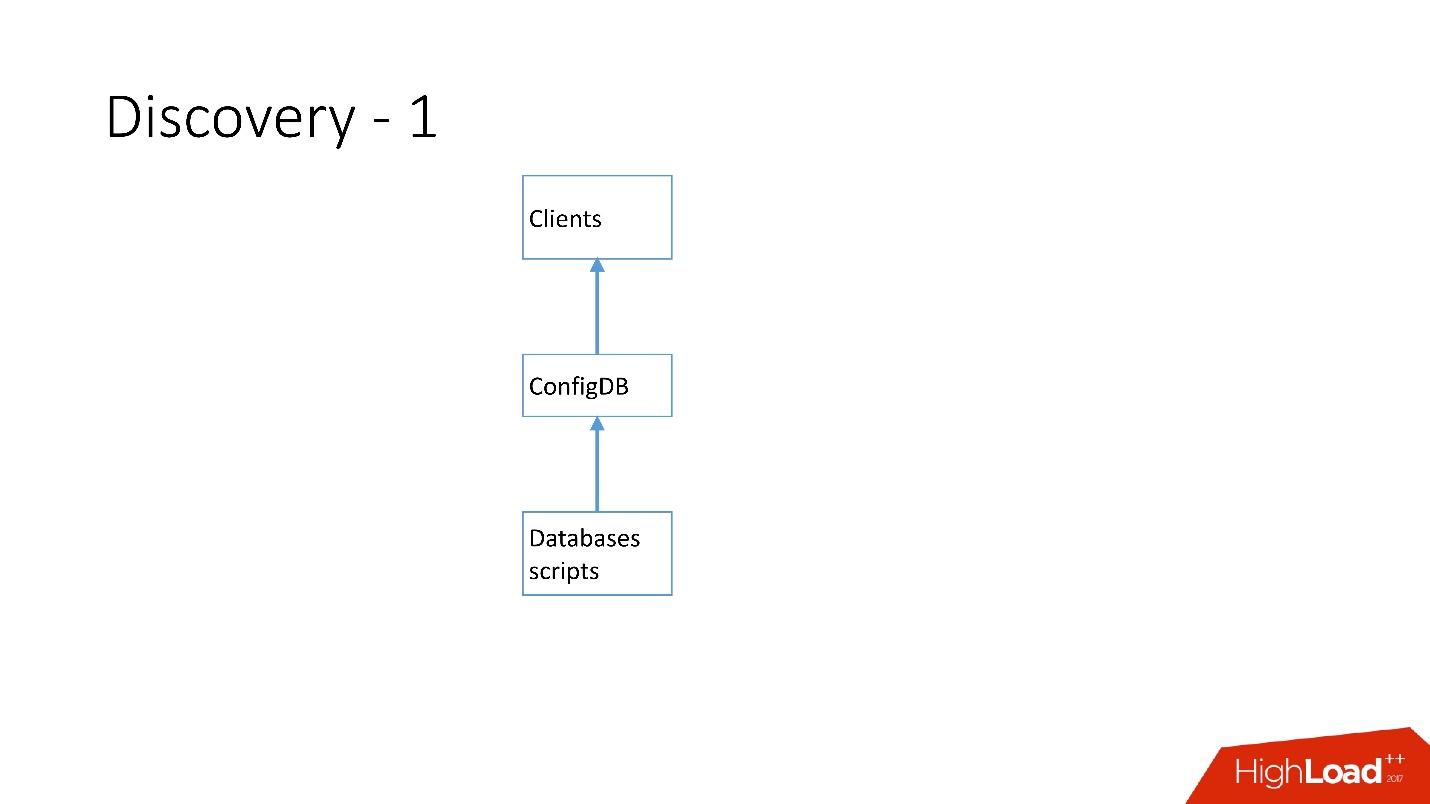
أعلاه هو أول اكتشاف لنا. كانت هناك نصوص برمجية لقاعدة البيانات غيرت لوحة الاسم في ConfigDB - كانت لوحة اسم MySQL منفصلة ، واستمع العملاء بالفعل إلى قاعدة البيانات هذه وأخذوا البيانات بشكل دوري من هناك.

الجدول بسيط للغاية ، هناك فئة قاعدة بيانات ، ومفتاح شارد ، وسيد / عبد فئة قاعدة بيانات ، وكيل وعنوان قاعدة بيانات. في الواقع ، طلب العميل فئة ، وفئة DB ، ومفتاح shard ، وتم إرجاع عنوان MySQL الذي يمكنه بالفعل إنشاء اتصال.
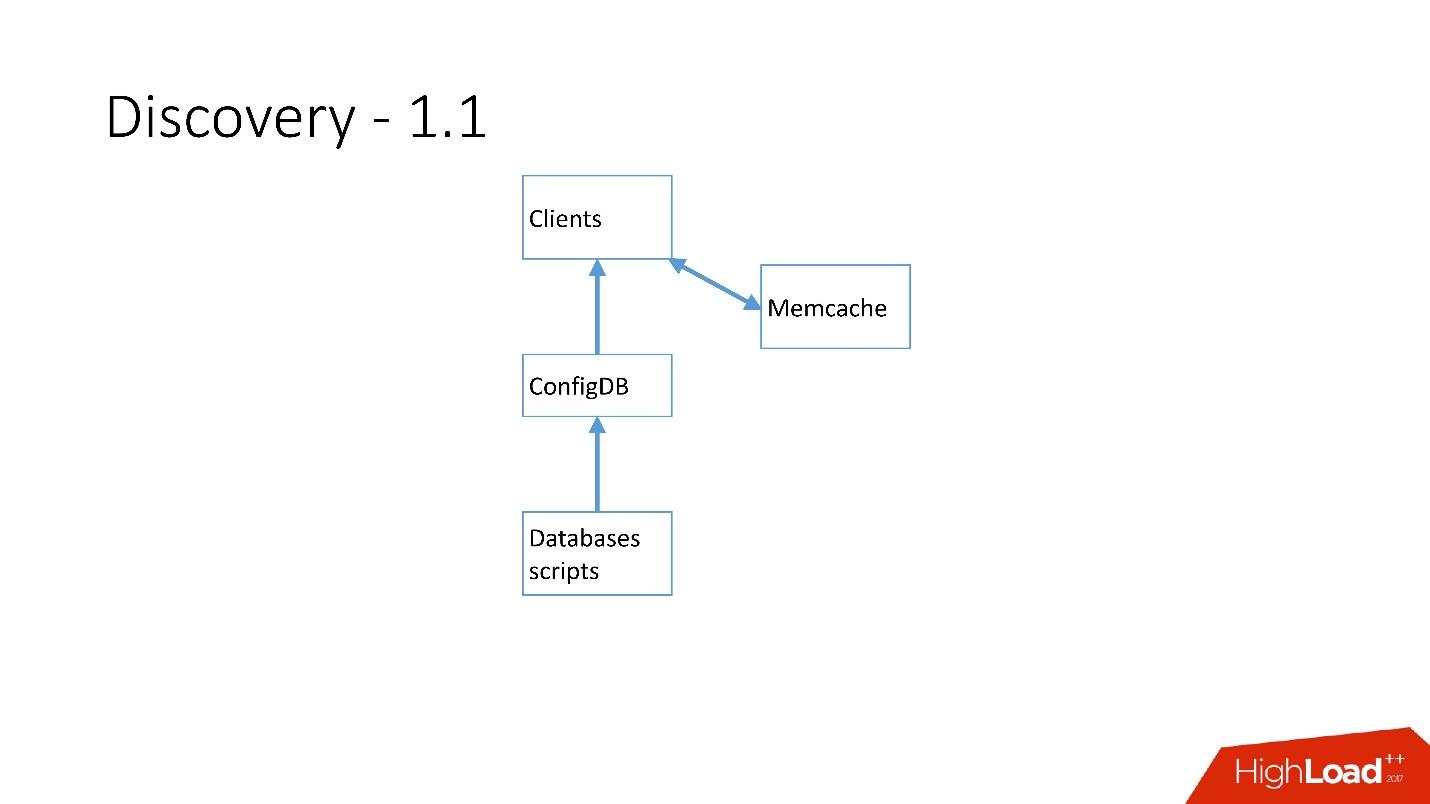
بمجرد وجود الكثير من الخوادم ، تمت إضافة Memcache وبدأ العملاء في الاتصال بها بالفعل.
ولكن بعد ذلك أعدنا صياغة ذلك. بدأت مخطوطات MySQL في التواصل من خلال gRPC ، من خلال عميل رفيع بخدمة أطلقنا عليها RegisterService. عندما حدثت بعض التغييرات ، كان لدى RegisterService قائمة انتظار ، وقد فهم كيفية تطبيق هذه التغييرات. حفظت RegisterService البيانات في AFS. AFS هو نظامنا الداخلي القائم على ZooKeeper.

الحل الثاني ، الذي لا يظهر هنا ، استخدم ZooKeeper مباشرة ، وهذا خلق مشاكل لأن كل قطعة كانت عقدة في ZooKeeper. على سبيل المثال ، يتصل 100 ألف عميل بـ ZooKeeper ، إذا ماتوا فجأة بسبب نوع من الأخطاء معًا ، فسيأتي 100 ألف طلب إلى ZooKeeper على الفور ، مما سيؤدي ببساطة إلى إسقاطه ولن يكون قادرًا على الارتفاع.
لذلك ، تم تطوير
نظام AFS ، والذي يستخدمه Dropbox بأكمله . في الواقع ، يلخص العمل مع ZooKeeper لجميع العملاء. يعمل البرنامج الخفي AFS محليًا على كل خادم ويوفر واجهة برمجة تطبيقات ملف بسيطة جدًا للنموذج: إنشاء ملف وحذف ملف وطلب ملف وتلقي إشعار بتغيير الملف ومقارنة وعمليات التبادل. أي أنه يمكنك محاولة استبدال الملف ببعض الإصدارات ، وإذا تغير هذا الإصدار أثناء التغيير ، فسيتم إلغاء العملية.
في الأساس ، مثل هذا التجريد على ZooKeeper ، حيث يوجد تراجع محلي وخوارزميات غضب. لم يعد يتعطل ZooKeeper تحت الحمل. مع AFS ، نأخذ نسخًا احتياطية في S3 و GIT ، ثم يقوم AFS المحلي نفسه بإبلاغ العملاء بتغيير البيانات.

في AFS ، يتم تخزين البيانات كملفات ، أي أنها API لنظام الملفات. على سبيل المثال ، ما ورد أعلاه هو ملف shard.slave_proxy - الأكبر ، يستغرق حوالي 28 كيلوبايت ، وعندما نغير فئة الفئة shard و slave_proxy ، فإن كل العملاء المشتركين في هذا الملف يتلقون إشعارًا. يعيدون قراءة هذا الملف الذي يحتوي على جميع المعلومات الضرورية. باستخدام مفتاح Shard ، يحصلون على فئة ويعيدون تكوين تجمع الاتصال إلى قاعدة البيانات.
العمليات
نحن نستخدم عمليات بسيطة للغاية: الترويج ، الاستنساخ ، النسخ الاحتياطي / الاسترداد.
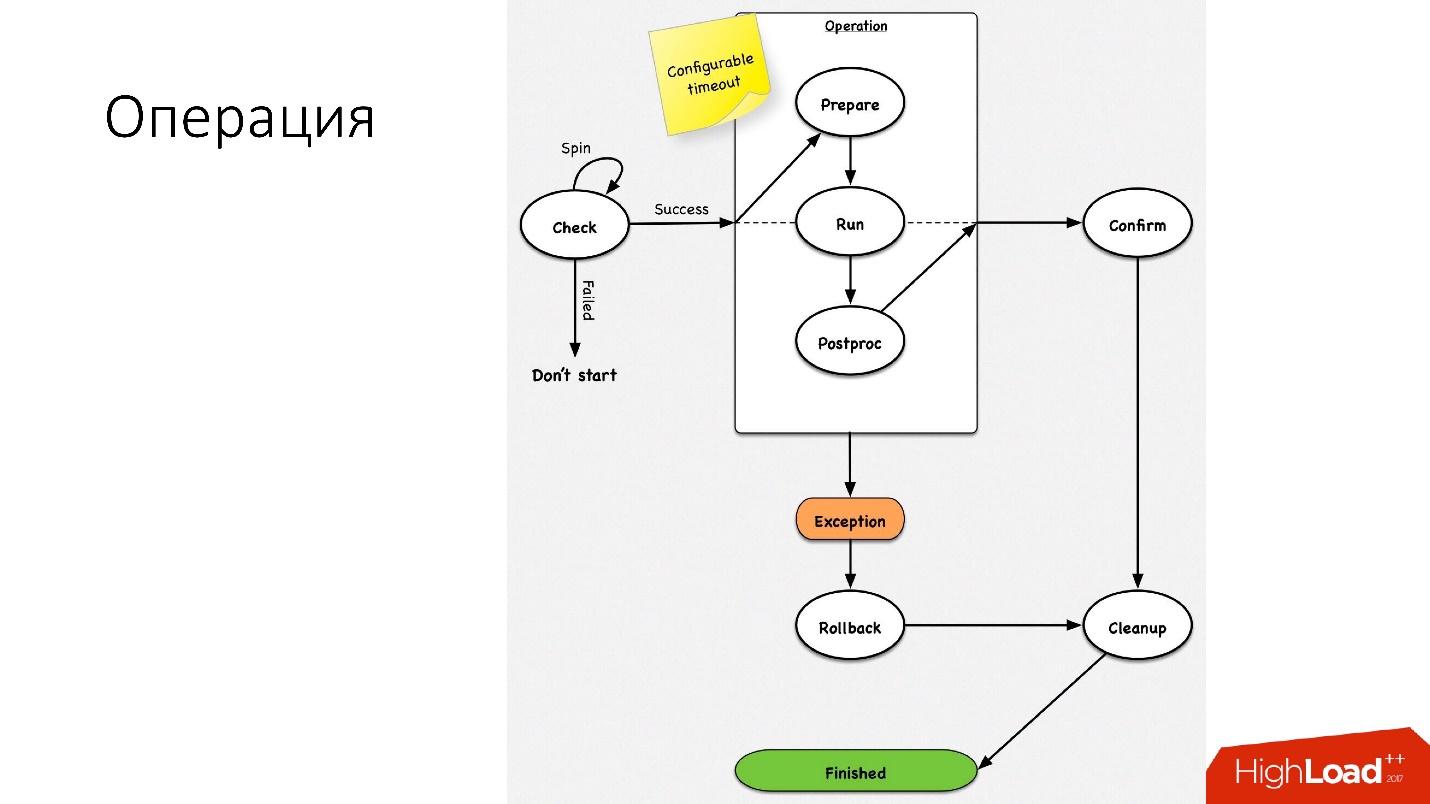 العملية هي آلة حالة بسيطة
العملية هي آلة حالة بسيطة . عندما نبدأ في العملية ، نقوم ببعض عمليات الفحص ، على سبيل المثال ، فحص الدوران ، والذي يتحقق عدة مرات حسب المهلة مما إذا كان يمكننا إجراء هذه العملية. بعد ذلك نقوم ببعض الأعمال التحضيرية التي لا تؤثر على الأنظمة الخارجية. بعد ذلك ، العملية نفسها.
جميع الخطوات في العملية لها
خطوة تراجع (تراجع). إذا كانت هناك مشكلة في العملية ، فستحاول العملية إعادة النظام إلى مكانه الأصلي. إذا كان كل شيء على ما يرام ، يحدث التنظيف ويتم الانتهاء من العملية.
لدينا آلة حالة بسيطة لأي عملية.
الترقية (تغيير الماجستير)
هذه عملية شائعة جدًا في قاعدة البيانات. كانت هناك أسئلة حول كيفية إجراء تغيير على خادم رئيسي ساخن يعمل - سيحصل على حصة. كل ما في الأمر أن هذه العمليات تتم على خوادم تابعة ، ومن ثم يتم تغييرها باستخدام الأماكن الرئيسية. لذلك ، فإن
عملية الترويج متكررة للغاية .

نحن بحاجة إلى تحديث النواة - نحن نقوم بالتبديل ، نحتاج إلى تحديث إصدار MySQL - نقوم بتحديث الرقيق ، والتحول إلى إتقان ، والتحديث هناك.

لقد حققنا تعزيز سريع للغاية. على سبيل المثال ،
بالنسبة لأربعة أجزاء ، لدينا الآن ترقية لمدة تتراوح من 10 إلى 15 ثانية. يوضح الرسم البياني أعلاه أنه مع توفر الترقية فقد عانى بنسبة 0.0003٪.
لكن الترويج العادي ليس مثيرًا للاهتمام ، لأن هذه عمليات عادية يتم إجراؤها يوميًا. تجاوزات الفشل مثيرة للاهتمام.
تجاوز الفشل (استبدال سيد مكسور)
يعني تجاوز الفشل أن قاعدة البيانات قد ماتت.
- إذا مات الخادم حقًا ، فهذه مجرد حالة مثالية.
- في الواقع ، يحدث أن الخوادم على قيد الحياة جزئيا.
- في بعض الأحيان يموت الخادم ببطء شديد. تحكم الغارة ، فشل نظام القرص ، بعض الطلبات ترجع الإجابات ، ولكن بعض التدفقات ممنوعة ولا ترجع الإجابات.
- يحدث أن السيد ببساطة مثقل ولا يستجيب لفحصنا الصحي. ولكن إذا قمنا بالترقية ، فسيتم تحميل المدير الجديد أيضًا بشكل زائد ، وسيزداد الأمر سوءًا.
يتم استبدال الخوادم الرئيسية المتوفاة حوالي
2-3 مرات في اليوم ، وهذه عملية مؤتمتة بالكامل ، ولا يلزم تدخل بشري. يستغرق القسم الحاسم حوالي 30 ثانية ، ولديه مجموعة من الفحوصات الإضافية لمعرفة ما إذا كان الخادم على قيد الحياة بالفعل ، أو ربما مات بالفعل.
فيما يلي مثال تخطيطي لكيفية عمل faylover.

في القسم المحدد ، نقوم
بإعادة تشغيل الخادم الرئيسي . هذا ضروري لأن لدينا MySQL 5.6 ، وفيه النسخ المتماثل شبه ضياع. لذلك ، فإن القراءات الوهمية ممكنة ، ونحن بحاجة إلى هذا السيد ، حتى لو لم يمت ، فقتل بأسرع ما يمكن حتى ينقطع العملاء عنه. لذلك ، نقوم بإعادة ضبط القرص الصلب عبر Ipmi - هذه هي أول عملية مهمة يجب علينا القيام بها. في إصدار MySQL 5.7 ، هذا ليس بالغ الأهمية.
تزامن الكتلة. لماذا نحتاج إلى مزامنة الكتلة؟
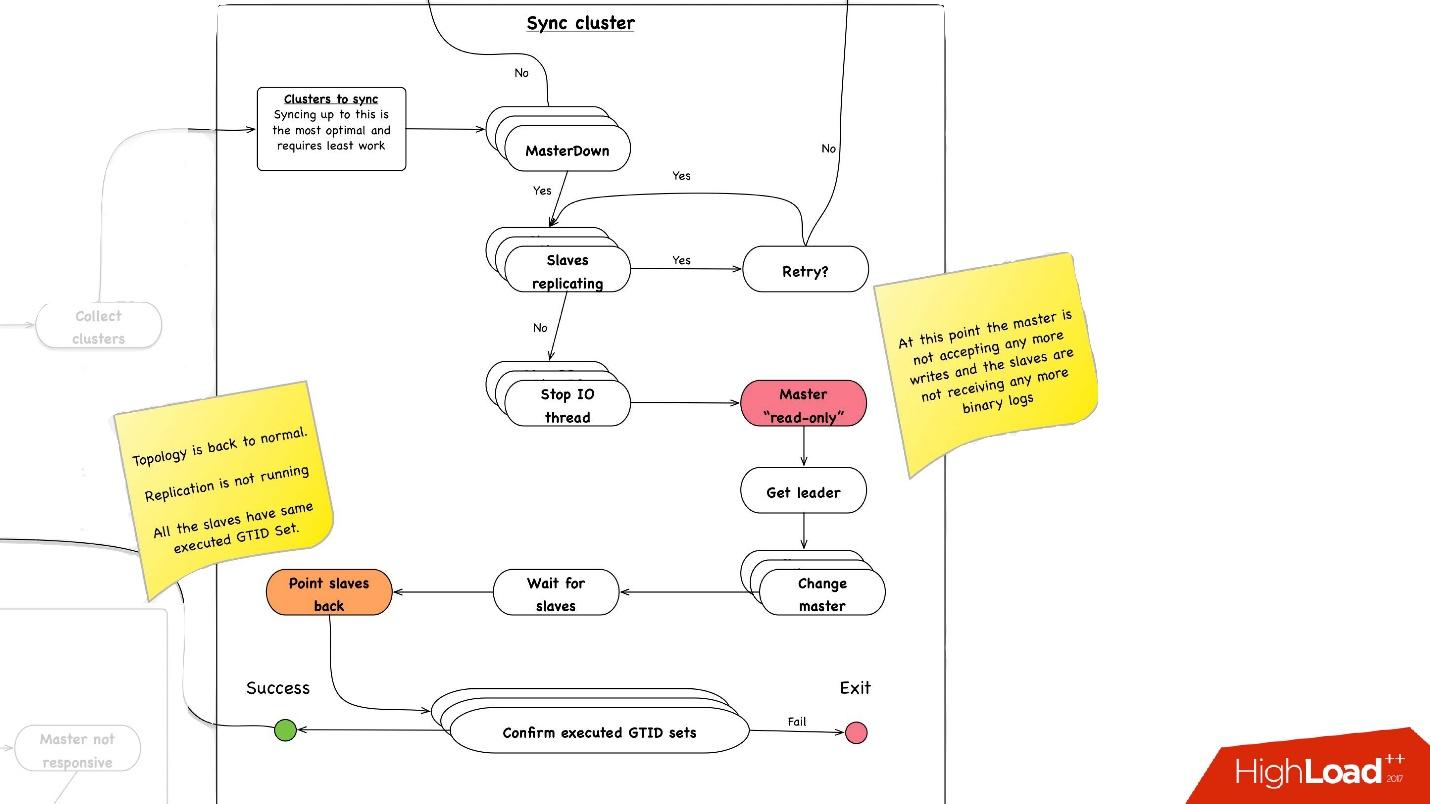
إذا تذكرنا الصورة السابقة مع طوبولوجيا لدينا ، فإن أحد الخوادم الرئيسية له ثلاثة خوادم تابعة: اثنان في مركز بيانات واحد ، واحد في الآخر. مع الترويج ، نحتاج إلى أن نكون في نفس مركز البيانات الرئيسي. ولكن في بعض الأحيان ، عندما يتم تحميل العبيد ، مع شبه متزامن يحدث أن يصبح العبد شبه المتزامن عبدا في مركز بيانات آخر ، لأنه لا يتم تحميله. لذلك ، نحتاج أولاً إلى مزامنة المجموعة بأكملها ، ثم نقوم بالفعل بالترويج على الرقيق في مركز البيانات الذي نحتاجه. يتم ذلك ببساطة شديدة:
- نوقف جميع خيط الإدخال / الإخراج على جميع خوادم الرقيق.
- بعد ذلك ، نعلم بالفعل بالتأكيد أن المعلم "للقراءة فقط" ، نظرًا لأن نصف الاتصال غير متصل ولا يمكن لأي شخص آخر كتابة أي شيء هناك.
- بعد ذلك ، نختار العبد مع أكبر مجموعة GTID تم استردادها / تنفيذها ، أي مع أكبر معاملة يتم تنزيلها أو تطبيقها بالفعل.
- نقوم بإعادة تكوين جميع خوادم الرقيق إلى هذا الرقيق المحدد ، وبدء مؤشر ترابط الإدخال / الإخراج ، وتتم مزامنتها.
- ننتظر حتى تتم مزامنتها ، وبعد ذلك تصبح المجموعة بأكملها متزامنة. , executed GTID set .
—
.
promotion , :
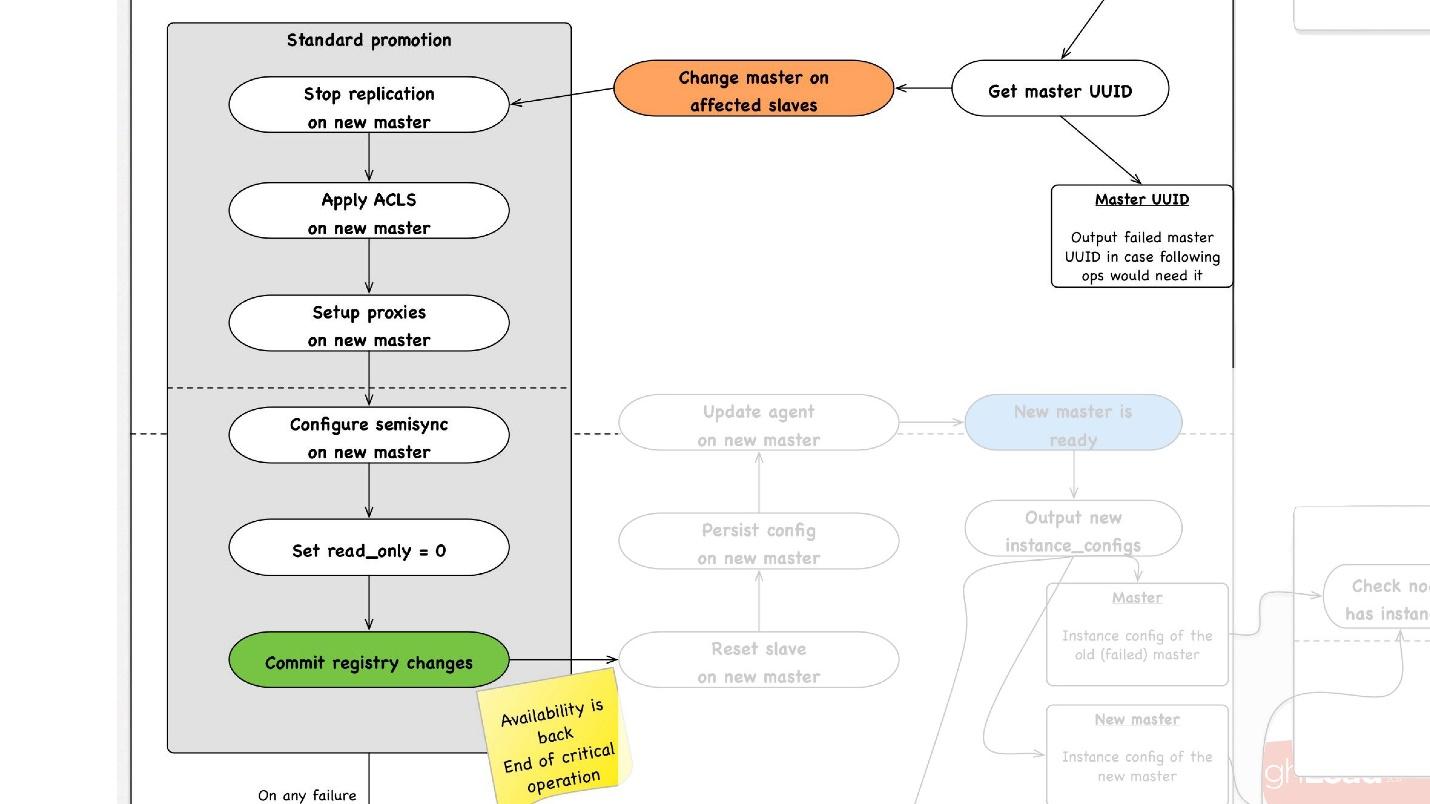
- slave -, , master, promotion.
- slave- master, , ACLs, , - proxy, , - .
- read_only = 0, , master , . master .
- - . - , , , , , proxy .
- .
, rollback , . rollback reboot. , , , — change master — master .
— . , , , , .
● slave
, slave-, . .
●
, , . .
●
, , . . 3 .
, , , :
- . 1 40 .
- .
, . 1 40 , , , .
, . . 4 .
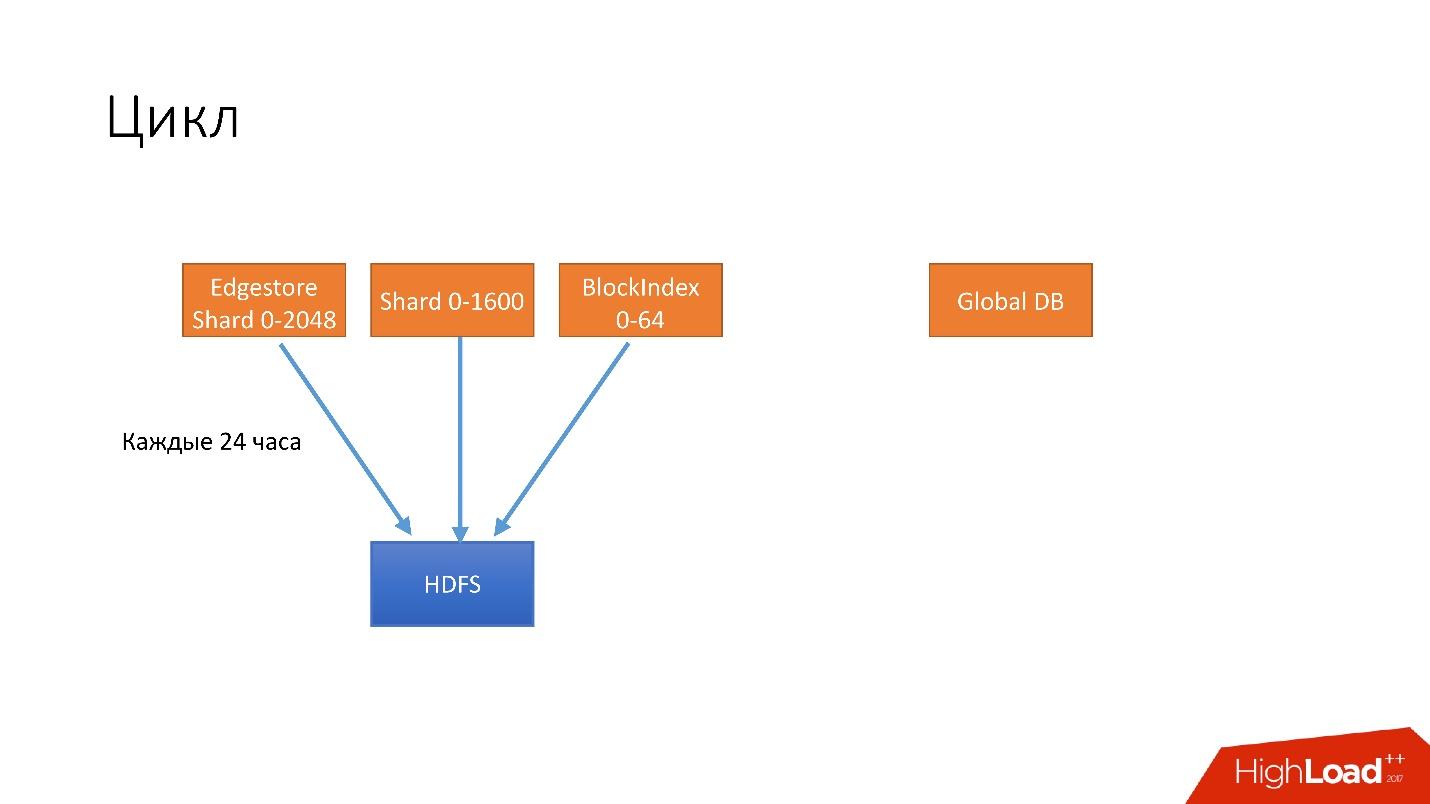
- 24 . HDFS, .
- 6 unsharded databases, Global DB. , , , .
- 3 S3.
- 3 S3 .

. , 3 , HDFS 3 , 6 S3. .
, .

, , . , , recovery - . , , - . 100 , .
, , , , , , , . .

hot-, Percona xtrabackup. —stream=xbstream, , . script-splitter, , .
MySQL 2x. 3 , , , 1 500 . , , HDFS S3.
.

, , HDFS S3, , splitter xtrabackup, . crash-recovery.
hot , crash-recovery . , . binlog, master.
binlogs?binlog'. master , 4 , 100 , HDFS.
: Binlog Backuper, . , , binlog HDFS.
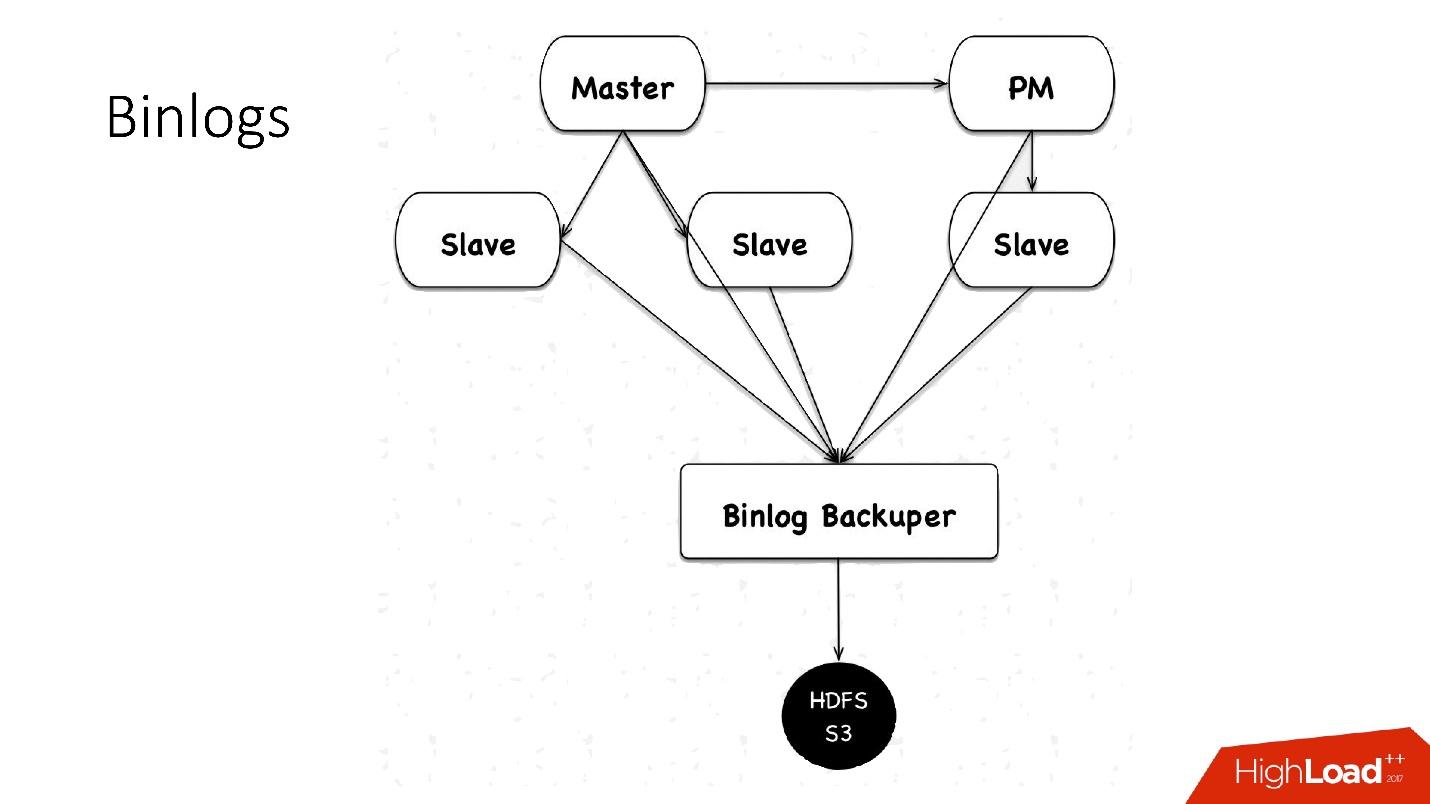
, 4 , 5 , , , . HDFS S3 .
.
:
- — 10 , 45 — .
- , scheduler multi instance slave master .
- — , . , , , , , , . pt-table-checksum , .
, :
- 1 10 , . crash-recovery, .
- .

slave -, . , . .
++
. Hardware , (HDD) 10 , + crash recovery xtrabackup, . , , . , , , , HDD , HDFS .
, — :
- ;
- .
, HDFS, , , .
الأتمتة
, 6 000 . , , — :
- Auto-replace;
- DBManager;
- Naoru, Wheelhouse
Auto-replace
, , , , — , -. , .
Availability () — , . — recovery , .

MySQL , heartbeat. Heartbeat — timestamp.
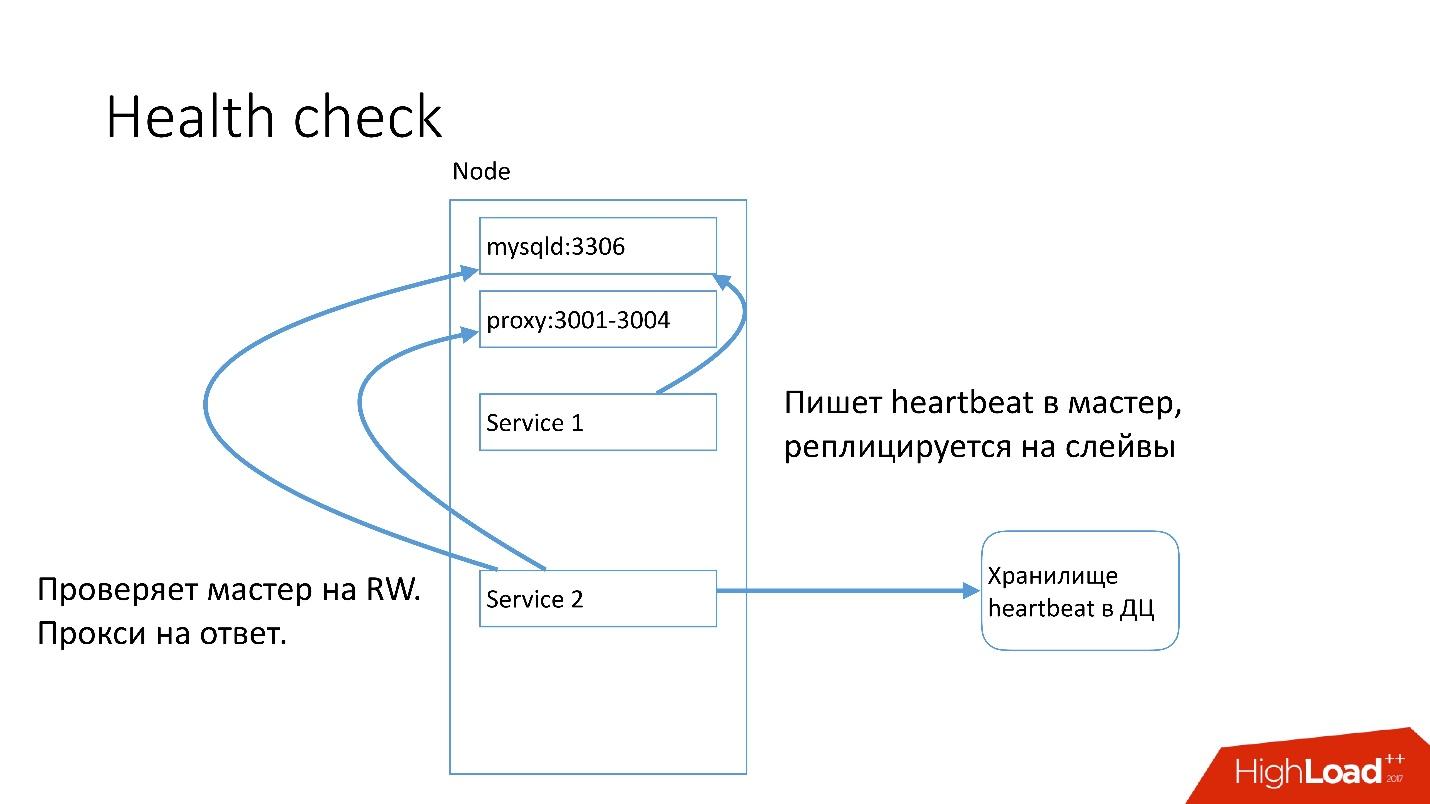
, , , master read-write. heartbeat.
auto-replace , .
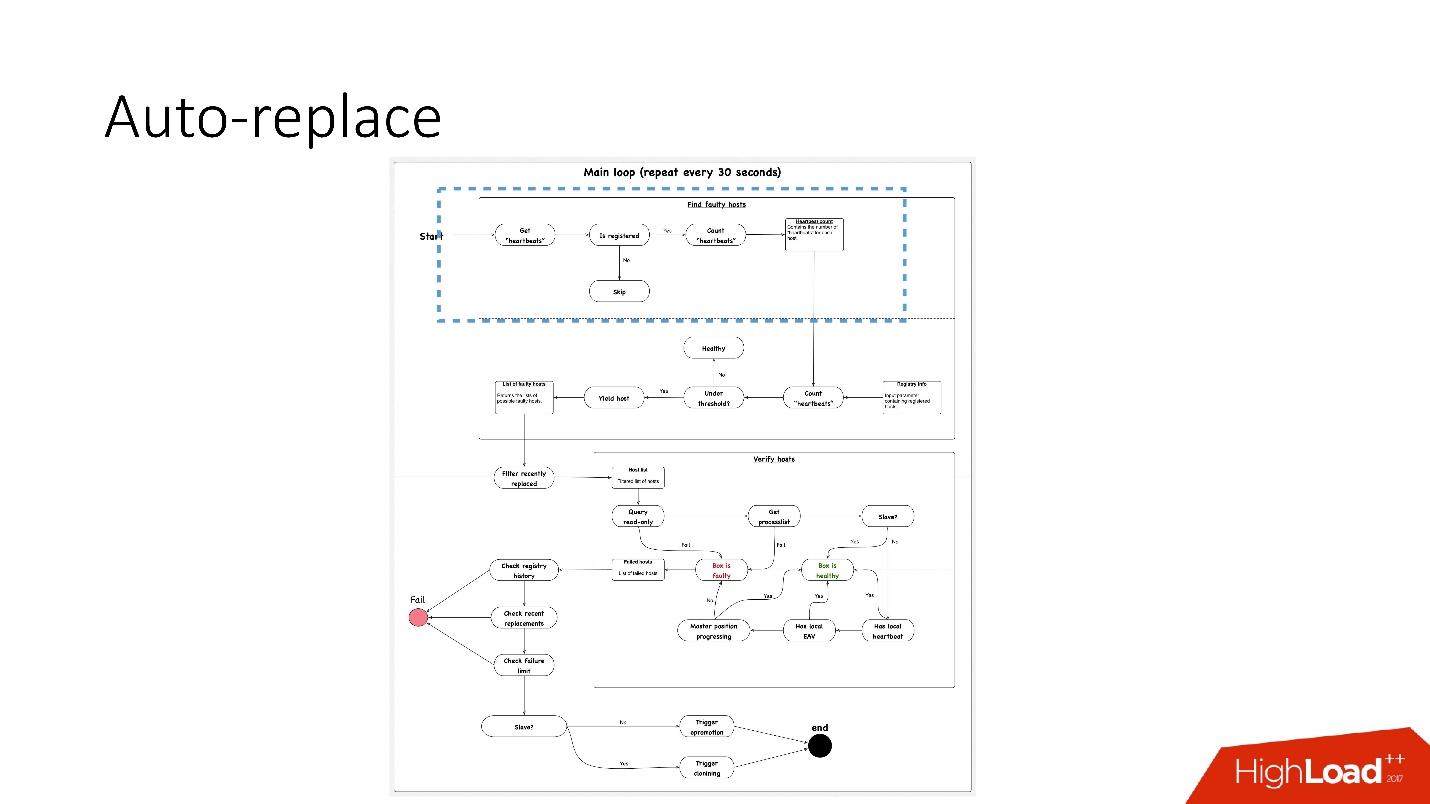 , 91 .?
, 91 .?- , heartbeat . , . heartbeat', , heartbeat' 30 .
- بعد ذلك ، تحقق مما إذا كان رقمهم يستوفي قيمة العتبة. إذا لم يكن الأمر كذلك ، فهناك خطأ ما في الخادم - نظرًا لأنه لم يرسل نبضات القلب.
- بعد ذلك ، نقوم بإجراء فحص عكسي فقط في حالة - فجأة ماتت هاتان الخدمتان ، شيء ما مع الشبكة ، أو لا يمكن لقاعدة البيانات العالمية كتابة نبضات القلب لسبب ما. في الفحص العكسي ، نقوم بالاتصال بقاعدة بيانات معطوبة والتحقق من حالتها.
- إذا فشل كل شيء آخر ، فإننا ننظر إلى ما إذا كان الموضع الرئيسي يتقدم أم لا ، وما إذا كانت هناك سجلات عليه. إذا لم يحدث شيء ، فهذا الخادم لا يعمل بالتأكيد.
- والخطوة الأخيرة هي في الواقع الاستبدال التلقائي.
الاستبدال التلقائي محافظ للغاية ، فهو لا يريد أبدًا القيام بالكثير من العمليات التلقائية.
- أولاً ، نتحقق مما إذا كانت هناك أي عمليات طوبولوجيا مؤخرًا؟ ربما تمت إضافة هذا الخادم للتو ولم يتم تشغيل أي شيء عليه حتى الآن.
- نتحقق لمعرفة ما إذا كان هناك أي بدائل في نفس المجموعة في أي وقت.
- تحقق من حد الفشل لدينا. إذا كانت لدينا العديد من المشكلات في وقت واحد - 10 ، 20 - فلن نتمكن من حلها جميعًا تلقائيًا ، لأنه يمكننا تعطيل تشغيل جميع قواعد البيانات عن غير قصد.
لذلك ،
نحل مشكلة واحدة فقط في كل مرة .
وفقًا لذلك ، بالنسبة لخادم العبيد ، نبدأ الاستنساخ ونزيله ببساطة من الطوبولوجيا ، وإذا كان سيدًا ، فإننا نطلق feylover ، ما يسمى ترويج الطوارئ.
مدير DBManager
DBManager هي خدمة لإدارة قواعد البيانات الخاصة بنا. لديها:
- برنامج جدولة المهام الذكي الذي يعرف بالضبط متى ستبدأ الوظيفة ؛
- السجلات وجميع المعلومات: من ومتى وما تم إطلاقه - هذا هو مصدر الحقيقة ؛
- نقطة التزامن.
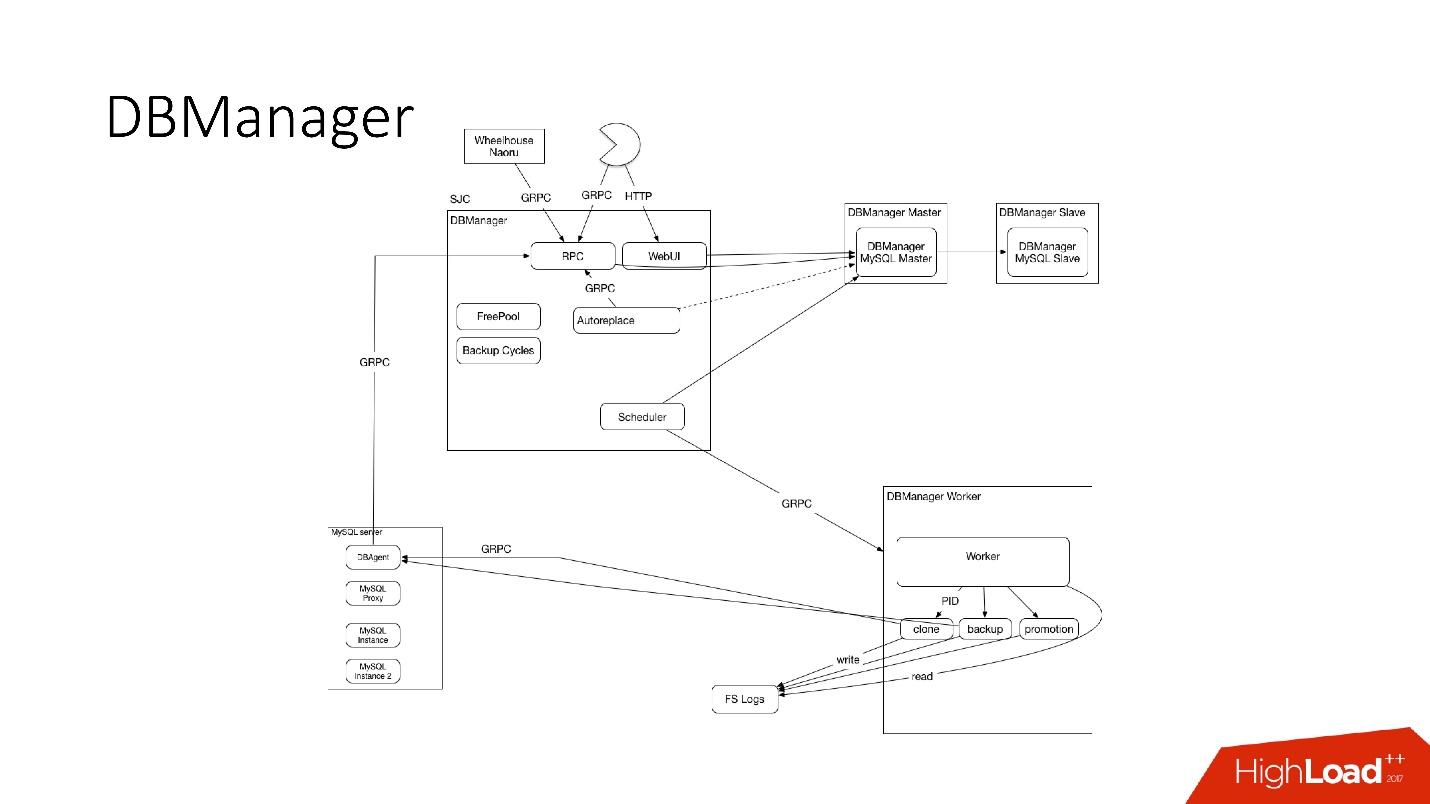
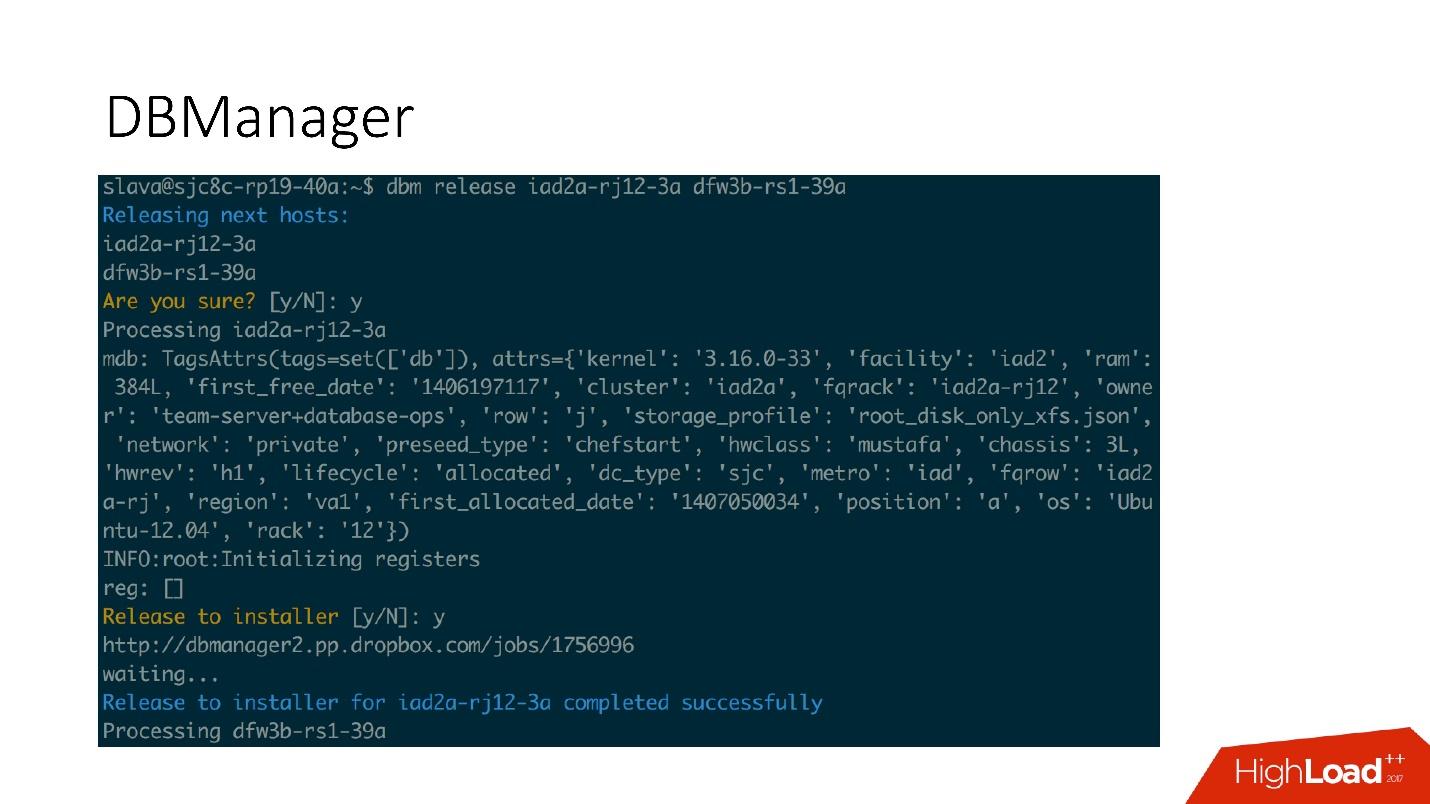
DBManager بسيط من الناحية المعمارية.
- هناك عملاء ، إما DBA يفعلون شيئًا من خلال واجهة الويب ، أو نصوص / خدمات كتب DBA يمكن الوصول إليها عبر gRPC.
- هناك أنظمة خارجية مثل Wheelhouse و Naoru ، والتي تذهب إلى DBManager عبر gRPC.
- هناك مجدول يدرك العملية ، ومتى وأين يمكنه البدء.
- هناك عامل غبي للغاية ، عندما تأتي إليه العملية ، تبدأ ، وتتحقق من PID. يجوز للعامل إعادة التشغيل ، ولا تتم مقاطعة العمليات. يقع جميع العمال في أقرب مكان ممكن من الخوادم التي تجري عليها العمليات ، بحيث ، على سبيل المثال ، عند تحديث ACLS ، لا نحتاج إلى القيام بالعديد من الرحلات الدائرية.
- على كل مضيف SQL لدينا DBAgent - هذا هو خادم RPC. عندما تحتاج إلى إجراء بعض العمليات على الخادم ، نرسل طلب RPC.
لدينا واجهة ويب لـ DBManager ، حيث يمكنك رؤية المهام قيد التشغيل حاليًا ، وسجلات هذه المهام ، ومن بدأها ومتى ، وما هي العمليات التي تم تنفيذها لخادم قاعدة بيانات محددة ، وما إلى ذلك.
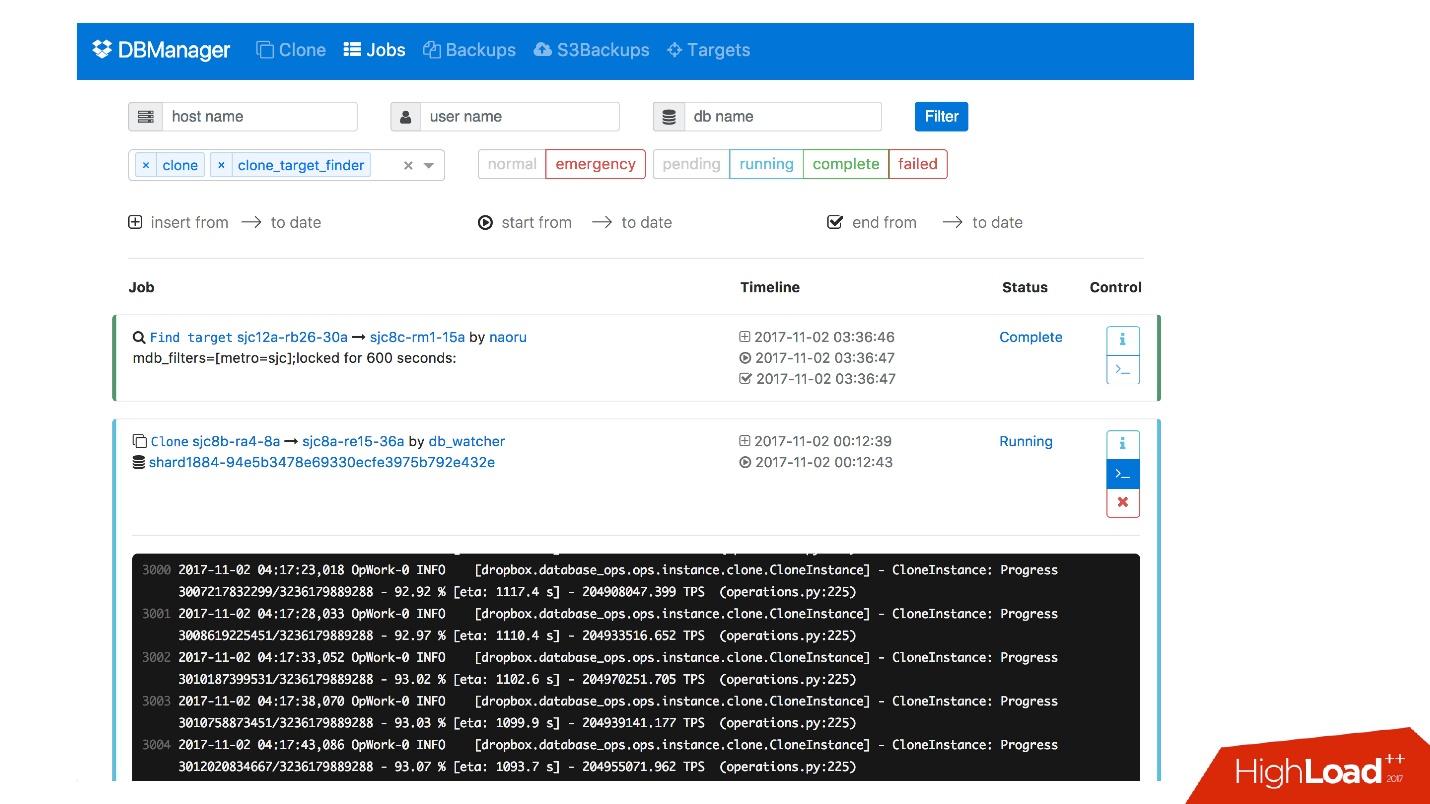
هناك واجهة CLI بسيطة إلى حد ما حيث يمكنك تشغيل المهام وعرضها أيضًا في طرق عرض مريحة.
العلاجات
لدينا أيضًا نظام للاستجابة للمشكلات. عندما يتم كسر شيء ما ، على سبيل المثال ، تعطل محرك الأقراص ، أو لا تعمل بعض الخدمات ، يعمل
Naoru. هذا هو النظام الذي يعمل في جميع أنحاء Dropbox ، ويستخدمه الجميع ، وهو مصمم خصيصًا لمثل هذه المهام الصغيرة. تحدثت عن Naoru في تقريري في عام 2016.
يعتمد
Wheelhouse على جهاز
الحالة ومصمم لعمليات طويلة. على سبيل المثال ، نحتاج إلى تحديث النواة على جميع MySQL على مجموعتنا المكونة من 6000 جهاز. يقوم Wheelhouse بذلك بوضوح - تحديثات على خادم الرقيق ، إطلاق ترويج ، يصبح الرقيق سيد ، تحديثات على الخادم الرئيسي. قد تستغرق هذه العملية شهرًا أو حتى شهرين.
المراقبة

هذا مهم جدا.
إذا كنت لا تراقب النظام ، فمن المرجح أنه لا يعمل.
نحن نراقب كل شيء في MySQL - يتم تخزين جميع المعلومات التي يمكننا الحصول عليها من MySQL في مكان ما ، يمكننا الوصول إليها في الوقت المناسب. نقوم بتخزين المعلومات على InnoDb ، وإحصاءات الطلبات ، والمعاملات ، وطول المعاملات ، والمئوي على أطوال المعاملات ، والنسخ المتماثل ، وعلى الشبكة - الكل - الكل - عدد ضخم من المقاييس.
تنبيه
لدينا 992 من التنبيهات تم تكوينها. في الواقع ، لا أحد ينظر إلى المقاييس ، يبدو لي أنه لا يوجد أشخاص يأتون للعمل ويبدؤون في النظر في مخطط المقاييس ، فهناك مهام أكثر إثارة للاهتمام.

لذلك ، هناك تنبيهات تعمل عند الوصول إلى قيم عتبة معينة.
لدينا 992 تنبيهًا ، بغض النظر عما يحدث ، سنكتشف ذلك .
الحوادث

لدينا PagerDuty - خدمة يتم من خلالها إرسال التنبيهات إلى الأشخاص المسؤولين الذين يبدأون في اتخاذ إجراء.

في هذه الحالة ، حدث خطأ في ترويج الطوارئ ، وبعد ذلك مباشرة تم تسجيل تنبيه بأن السيد سقط. بعد ذلك ، قام الضابط المسؤول بفحص ما منع الترقية الطارئة ، وقام بالعمليات اليدوية اللازمة.
سنقوم بالتأكيد بتحليل كل حادثة وقعت ، لكل حادثة لدينا مهمة في تعقب المهام. حتى إذا كانت هذه الحادثة مشكلة في تنبيهاتنا ، فإننا ننشئ أيضًا مهمة ، لأنه إذا كانت المشكلة في منطق التنبيه وحدودها ، فيجب تغييرها. يجب ألا تفسد التنبيهات حياة الناس. يكون التنبيه مؤلمًا دائمًا ، خاصة عند الساعة الرابعة صباحًا.
الاختبار
كما هو الحال مع المراقبة ، أنا متأكد من أن الجميع يختبرون. بالإضافة إلى اختبارات الوحدة التي نغطي بها الكود ، لدينا اختبارات تكامل نختبر فيها:
- جميع الطوبولوجيا التي لدينا ؛
- جميع العمليات على هذه الطوبولوجيا.
إذا كانت لدينا عمليات ترويج ، فإننا نختبر عمليات الترقية في اختبار التكامل. إذا كان لدينا استنساخ ، فنحن نقوم بالاستنساخ لجميع الهياكل التي لدينا.
مثال الطوبولوجيا
لدينا طوبولوجيا لجميع المناسبات: مركزا بيانات مع مثيلات متعددة ، مع شظايا ، لا شظايا ، مع مجموعات ، مركز بيانات واحد - بشكل عام أي طوبولوجيا - حتى تلك التي لا نستخدمها ، لمجرد رؤيتها.

في هذا الملف ، لدينا فقط الإعدادات والخوادم وما نحتاج إلى رفعه. على سبيل المثال ، نحتاج إلى رفع درجة الماجستير ، ونقول أننا بحاجة إلى القيام بذلك باستخدام بيانات المثيلات ومثل هذه ، وقواعد البيانات هذه على هذه المنافذ. كل شيء تقريبًا يسير مع Bazel ، الذي ينشئ طبولوجيا على أساس هذه الملفات ، ويبدأ خادم MySQL ، ثم يبدأ الاختبار.

يبدو الاختبار بسيطًا جدًا: نوضح أي طوبولوجيا يتم استخدامها. في هذا الاختبار ، نقوم باختبار الإعداد التلقائي.
- نحن ننشئ خدمة الإرجاع التلقائي ، ونبدأها.
- نقتل الرئيسي في طوبولوجيا لدينا ، ننتظر بعض الوقت ونرى أن العبد الهدف أصبح سيدًا. إذا لم يكن كذلك ، فشل الاختبار.
المراحل
تعتبر بيئات المسرح هي نفس قواعد البيانات الموجودة في الإنتاج ، ولكن لا توجد حركة مرور مستخدمين عليها ، ولكن هناك بعض حركة المرور الاصطناعية التي تشبه الإنتاج من خلال تشغيل Percona و sysbench والأنظمة المشابهة.
في تشغيل Percona ، نسجل حركة المرور ، ثم نفقدها في بيئة المسرح بكثافة مختلفة ، يمكننا أن نفقد 2-3 مرات أسرع. أي أنها مصطنعة ، ولكنها قريبة جدًا من الحمل الحقيقي.
هذا ضروري لأنه في اختبارات التكامل لا يمكننا اختبار إنتاجنا. لا يمكننا اختبار التنبيه أو حقيقة عمل المقاييس. في مرحلة الاختبار ، نختبر التنبيهات والمقاييس والعمليات ونقتل الخوادم بشكل دوري ونرى أنه يتم جمعها بشكل طبيعي.
بالإضافة إلى ذلك ، نقوم باختبار جميع الأتمتة معًا ، لأنه في اختبارات التكامل ، على الأرجح ، يتم اختبار جزء واحد من النظام ، وفي المرحلة ، تعمل جميع الأنظمة الآلية في وقت واحد. في بعض الأحيان تعتقد أن النظام سوف يتصرف بهذه الطريقة وليس بطريقة أخرى ، ولكن قد يتصرف بطريقة مختلفة تمامًا.
DRT (اختبار التعافي من الكوارث)
نجري أيضًا اختبارات في الإنتاج - على أسس حقيقية. وهذا ما يسمى اختبار التعافي من الكوارث. لماذا نحتاج هذا؟
● نريد اختبار ضماناتنا.
يتم ذلك من قبل العديد من الشركات الكبيرة. على سبيل المثال ، لدى Google خدمة واحدة تعمل بثبات - 100٪ من الوقت - لدرجة أن جميع الخدمات التي استخدمتها قررت أن هذه الخدمة مستقرة 100٪ ولا تتعطل أبدًا. لذلك ، كان على Google إسقاط هذه الخدمة عمدًا ، حتى يأخذ المستخدمون هذه الإمكانية في الاعتبار.
لذلك نحن - لدينا ضمان بأن MySQL يعمل - وأحيانًا لا يعمل! ولدينا ضمان بأنه قد لا يعمل لفترة معينة من الوقت ، يجب على العملاء أخذ ذلك في الاعتبار. من وقت لآخر ، نقتل سيد الإنتاج ، أو إذا أردنا أن نجعل عاشقًا ، نقتل جميع العبيد لنرى كيف يتصرف النسخ المتماثل شبه.
● العملاء على استعداد لهذه الأخطاء (استبدال وموت الماجستير)
لماذا هذا جيد؟ كانت لدينا حالة عندما انخفض التوافر إلى 20٪ أثناء الترويج لـ 4 أجزاء من أصل 1600. يبدو أن هناك خطأ ما ، بالنسبة لأربعة أجزاء من 1600 يجب أن يكون هناك بعض الأرقام الأخرى. كانت حالات الفشل لهذا النظام نادرة ، مرة واحدة تقريبًا في الشهر ، وقرر الجميع: "حسنًا ، إنه فشل ، يحدث".
في مرحلة ما ، عندما انتقلنا إلى نظام جديد ، قرر شخص واحد تحسين هاتين الخدمتين لتسجيل نبضات القلب ودمجهما في نظام واحد. قامت هذه الخدمة بشيء آخر ، وفي النهاية ماتت وتوقف نبضات القلب عن التسجيل. حدث أن لهذا العميل كان لدينا 8 faylovers في اليوم. كل شيء يكمن - توفر 20 ٪.
اتضح أنه في هذا العميل يبقى على قيد الحياة 6 ساعات. وفقًا لذلك ، بمجرد وفاة المعلم ، تم الاحتفاظ بجميع الاتصالات لمدة 6 ساعات أخرى. تعذر على المسبح الاستمرار في العمل - يتم الاحتفاظ باتصالاته ، وهو محدود ولا يعمل. تم إصلاحه.
نعيد العاشق مرة أخرى - لم يعد 20٪ ، ولكن لا يزال كثيرًا. لا يزال هناك خطأ. اتضح أن خلل في تنفيذ المجمع. عند الطلب ، تحولت المجموعة إلى العديد من الأجزاء ، ثم ربطت كل هذا. إذا كانت بعض الشظايا شديدة الحرارة ، فقد حدثت بعض حالات السباق في كود Go ، وكان المسبح بأكمله مسدودًا. كل هذه القطع لم تعد قادرة على العمل.
اختبار التعافي من الكوارث مفيد للغاية ، لأنه يجب أن يكون العملاء مستعدين لهذه الأخطاء ، يجب عليهم التحقق من رمزهم.
● بالإضافة إلى ذلك ، يعد اختبار التعافي من الكوارث أمرًا جيدًا لأنه يتم خلال ساعات العمل وكل شيء في مكانه ، وضغط أقل ، يعرف الناس ما سيحدث الآن. هذا لا يحدث في الليل ، وهذا رائع.
الخلاصة
1. كل شيء يحتاج لأتمتة ، لا تضع يديك عليه.
في كل مرة عندما يصعد شخص إلى النظام بأيدينا ، يموت كل شيء ويكسر في نظامنا - في كل مرة! - حتى في العمليات البسيطة. على سبيل المثال ، مات عبد واحد ، كان على الشخص إضافة ثان ، لكنه قرر إزالة العبد الميت بيديه من الطوبولوجيا. ومع ذلك ، بدلاً من المتوفى ، نسخ إلى الأمر مباشرة - تم ترك السيد بدون عبد على الإطلاق. لا ينبغي أن تتم هذه العمليات يدويا.
2. يجب أن تكون الاختبارات مستمرة وأوتوماتيكية (وفي الإنتاج).
نظامك يتغير ، بنيتك التحتية تتغير. إذا قمت بالتحقق مرة واحدة ، وبدا أنها تعمل ، فهذا لا يعني أنها ستعمل غدًا. لذلك ، تحتاج إلى إجراء اختبار مؤتمت بشكل مستمر كل يوم ، بما في ذلك في الإنتاج.
3. تأكد من امتلاك العملاء (المكتبات).
قد لا يعرف المستخدمون كيفية عمل قواعد البيانات. قد لا يفهمون سبب الحاجة إلى المهلات ، والبقاء على قيد الحياة. لذلك ، من الأفضل امتلاك هؤلاء العملاء - ستكون أكثر هدوءًا.
4. من الضروري تحديد مبادئك لبناء النظام وضماناتك ، والامتثال لها دائمًا.
وبالتالي ، يمكنك دعم 6 آلاف خادم قاعدة بيانات.
في الأسئلة بعد التقرير ، وخاصة الإجابات عليها ، هناك أيضًا الكثير من المعلومات المفيدة.سؤال وجواب
- ماذا سيحدث إذا كان هناك خلل في الحمل على الأجزاء - بعض المعلومات الوصفية حول بعض الملفات تبين أنها أكثر شيوعًا؟ هل من الممكن نشر هذه الشظية ، أم أن الحمل على الشظايا لا يختلف في أي مكان بأحجام كبيرة؟
لا تختلف بأوامر من الحجم. يتم توزيعه بشكل طبيعي تقريبًا. لدينا اختناق ، أي أننا لا نستطيع زيادة التحميل على الشق في الواقع ، نحن نختنق على مستوى العميل. بشكل عام ، يحدث أن يقوم بعض النجوم بتحميل صورة ، وتنفجر القشرة عمليًا. ثم نحظر هذا الرابط
- قلت أن لديك 992 تنبيه. هل يمكنك توضيح ما هو - هل هو خارج الصندوق أم تم إنشاؤه؟ إذا تم إنشاؤه ، هل هو العمل اليدوي أو شيء من هذا القبيل مثل التعلم الآلي؟
كل هذا تم إنشاؤه يدويًا. لدينا نظام داخلي خاص بنا يسمى Vortex ، حيث يتم تخزين المقاييس ، ويتم دعم التنبيهات فيه. هناك ملف yaml يشير إلى وجود شرط ، على سبيل المثال ، يجب تنفيذ النسخ الاحتياطية كل يوم ، وإذا تم استيفاء هذا الشرط ، فلن يعمل التنبيه. إذا لم يتم تنفيذ ذلك ، يأتي تنبيه.
هذا هو تطورنا الداخلي ، لأن القليل من الناس يمكنهم تخزين العدد الذي نحتاجه من المقاييس.
- ما مدى قوة الأعصاب للقيام بالـ DRT؟ لقد أسقطت ، CODERED ، لا ترتفع ، مع كل دقيقة من الذعر أكثر.
بشكل عام ، العمل في قواعد البيانات أمر مؤلم حقًا. إذا تعطلت قاعدة البيانات ، لا تعمل الخدمة ، لا يعمل Dropbox بأكمله. هذا ألم حقيقي. DRT مفيدة في أنها ساعة عمل. هذا هو ، أنا مستعد ، أجلس على مكتبي ، تناولت القهوة ، أنا جديد ، أنا مستعد لفعل أي شيء.
الأسوأ عندما يحدث في الساعة 4 صباحًا ، وليس DRT. على سبيل المثال ، آخر فشل كبير حدثناه مؤخرًا. عند إدخال نظام جديد ، نسينا تحديد درجة OOM لـ MySQL. كانت هناك خدمة أخرى تقرأ binlog. في مرحلة ما ، يكون مشغلنا يدويًا - مرة أخرى يدويًا! - يقوم بتشغيل الأمر لحذف بعض المعلومات في جدول المجموع الاختباري Percona. مجرد حذف بسيط ، عملية بسيطة ، ولكن هذه العملية ولدت binlog ضخمة. قرأت الخدمة هذه binlog في الذاكرة ، جاء OOM Killer ويعتقد من يقتل؟ ونسينا أن نضع نقاط OOM ، وتقتل MySQL!
لدينا 40 سيدًا يموتون في الساعة 4 صباحًا. عندما يموت 40 سيدًا ، يكون الأمر مخيفًا وخطيرًا حقًا. DRT ليست مخيفة وليست خطرة. نضع لمدة ساعة تقريبا.
بالمناسبة ، DRT هي طريقة جيدة للتدرب على مثل هذه اللحظات حتى نعرف بالضبط تسلسل الإجراءات اللازمة إذا كسر شيء ما بشكل جماعي.
- أرغب في معرفة المزيد حول التبديل بين المعلم والماجستير. أولاً ، لماذا لا يتم استخدام الكتلة ، على سبيل المثال؟ مجموعة قاعدة بيانات ، أي ليست عبدًا رئيسيًا مع التبديل ، ولكن تطبيقًا رئيسيًا رئيسيًا ، بحيث إذا سقط أحدهم ، فهو ليس مخيفًا.
هل تقصد شيئًا مثل النسخ الجماعي ، مجموعة جاليرا ، إلخ؟ يبدو لي أن تطبيق المجموعة ليس جاهزًا بعد للحياة. للأسف ، لم نحاول جاليرا بعد. هذا أمر رائع عندما يكون faylover داخل بروتوكولك ، ولكن للأسف ، لديهم العديد من المشاكل الأخرى ، وليس من السهل التبديل إلى هذا الحل.
- يبدو أنه في MySQL 8 يوجد شيء مثل مجموعة InnoDb. لم تحاول؟
لا يزال لدينا 5.6 بقيمة. لا أعرف متى سننتقل إلى 8. ربما سنحاول.
- في هذه الحالة ، إذا كان لديك سيد كبير ، عند التبديل من واحد إلى آخر ، يتبين أن قائمة الانتظار تتراكم على خوادم الرقيق مع حمولة عالية. إذا تم إخماد سيد ، فهل من الضروري أن تصل قائمة الانتظار ، بحيث يتحول الرقيق إلى الوضع الرئيسي - أم يتم بطريقة مختلفة؟
يتم تنظيم الحمل على الرئيسي بواسطة نصف متزامن. يحدد شبه التزامن التسجيل الرئيسي بأداء خادم تابع. بالطبع ، ربما تكون الصفقة قد أتت ، فعمل نصف متزامن ، لكن العبيد فقدوا هذه الصفقة لفترة طويلة جدًا. يجب عليك بعد ذلك الانتظار حتى يفقد التابع هذه المعاملة حتى النهاية.
- ولكن بعد ذلك ستأتي البيانات الجديدة لإتقانها ، وسيكون من الضروري ...
عندما نبدأ عملية الترويج ، نقوم بتعطيل I / O. بعد ذلك ، لا يستطيع السيد كتابة أي شيء لأنه يتم نسخ شبه متماثل. قد تأتي القراءة الوهمية للأسف ، لكن هذه مشكلة أخرى بالفعل.
- هذه كلها آلات حالة جميلة - ما هي النصوص المكتوبة ومدى صعوبة إضافة خطوة جديدة؟ ما الذي يجب القيام به للشخص الذي يكتب هذا النظام؟
جميع النصوص مكتوبة بلغة Python ، وجميع الخدمات مكتوبة بلغة Go. هذه هي سياستنا. من السهل تغيير المنطق - فقط في كود Python الذي يولد مخطط الحالة.
- ويمكنك قراءة المزيد عن الاختبار. كيف تتم كتابة الاختبارات ، وكيف تنشر العقد في جهاز افتراضي - هل هذه الحاويات؟
نعم سنقوم باختبار بمساعدة بازل. هناك بعض ملفات التكوين (json) و Bazel يلتقط نصًا برمجيًا يخلق طوبولوجيا الاختبار باستخدام ملف التكوين هذا. يتم وصف الطوبولوجيا المختلفة هناك.
يعمل كل شيء بالنسبة لنا في حاويات دوكر: إما أنه يعمل في CI أو على Devbox. لدينا نظام Devbox. نحن جميعًا نطور على خادم بعيد ، ويمكن أن يعمل هذا على سبيل المثال. هناك يتم تشغيله أيضًا داخل Bazel ، داخل حاوية عامل ميناء أو في Bazel Sandbox. Bazel معقد للغاية ولكنه ممتع.
- عند إجراء 4 مثيلات على خادم واحد ، هل فقدت كفاءة الذاكرة؟
أصبح كل مثيل أصغر. وفقًا لذلك ، كلما قل حجم الذاكرة التي تعمل بها MySQL ، أصبح من الأسهل لها أن تعيش. أي نظام أسهل للعمل مع كمية صغيرة من الذاكرة. في هذا المكان ، لم نفقد أي شيء. لدينا أبسط مجموعات C التي تحد من هذه الحالات من الذاكرة.
- إذا كان لديك 6000 خادم يخزن قواعد البيانات ، فهل يمكنك تحديد عدد المليارات من البيتابايت المخزنة في ملفاتك؟
هذه العشرات من الإيكابايتس ، قمنا بصب البيانات من أمازون لمدة عام.
- اتضح أنه في البداية كان لديك 8 خوادم ، 200 قطعة ، عليها 400 خادم مع 4 أجزاء لكل منها. لديك 1600 قطعة - هل هذا نوع من القيمة المشفرة؟ لا يمكنك فعل ذلك مرة أخرى؟ هل ستؤلمك إذا احتجت ، على سبيل المثال ، 3200 قطعة؟
نعم ، كان في الأصل 1600. وقد تم ذلك قبل أقل من 10 سنوات ، وما زلنا نعيش. ولكن لا يزال لدينا 4 أجزاء - لا يزال بإمكاننا زيادة المساحة 4 مرات.
- كيف تموت الخوادم ، ما هي الأسباب الرئيسية؟ ما الذي يحدث في كثير من الأحيان ، أقل في كثير من الأحيان ، ومثير للاهتمام بشكل خاص ، هل تحدث الكاربات التلقائية العفوية؟
الشيء الأكثر أهمية هو أن الأقراص تطير. لدينا RAID 0 - تحطم القرص ، مات السيد. هذه هي المشكلة الرئيسية ، ولكن من الأسهل علينا استبدال هذا الخادم. جوجل أسهل لاستبدال مركز البيانات ، لا يزال لدينا خادم. لم يكن لدينا مطلقًا تقريبًا اختبار الفساد. لنكون صادقين ، لا أتذكر متى كانت آخر مرة. نقوم فقط بتحديث المعالج. فترة حياتنا لسيد واحد محدودة بـ 60 يومًا. لا يمكن أن يعيش لفترة أطول ، بعد ذلك نستبدلها بخادم جديد ، لأنه لسبب ما يتراكم شيء ما باستمرار في MySQL ، وبعد 60 يومًا نرى أن المشاكل تبدأ في الحدوث. ربما ليس في MySQL ، ربما في لينكس.
لا نعلم ماهية هذه المشكلة ولا نريد التعامل معها. 60 , . .
— , 6 . , JPEG , JPEG, , ? , , - ? — , ?
, . — Dropbox .
— ? ? , , - , , ? , 10 . , 7 , 6 , . ?
Dropbox - , . . , , , - .
, . , , , . - , 6 , , , , .
, facebook youtube- — Highload++ 2018 . , 1 .