تتناقص أحجام الترانزستورات في الدوائر الدقيقة الحديثة بشكل لا ينفصم - على الرغم من حقيقة أنهم كانوا يتحدثون عن وفاة قانون مور لعدة سنوات ، والحد الفعلي للتصغير قريب بالفعل (بشكل أدق ، تم التحايل عليه بنجاح في بعض الأماكن). ومع ذلك ، فإن هذا الانخفاض ليس عبثًا ، وتنمو شهوات المستخدم بشكل أسرع من إمكانيات مطوري الشرائح. لذلك ، بالإضافة إلى تصغير الترانزستورات ، يتم استخدام تقنيات أخرى لا تقل تقدمًا في كثير من الأحيان لإنشاء منتجات إلكترونية دقيقة حديثة.

في جملتي الأخيرة ، استخدمت عمدًا عبارة "منتج إلكتروني دقيق" بدلاً من كلمة "دائرة دقيقة" ، لأن هذه المقالة ستركز على حقيقة أنه داخل وحدة المعالجة المركزية أو وحدة معالجة الرسومات قد لا يكون هناك بلورة واحدة فحسب ، بل نظام كامل من عدة شرائح ، لذلك ويسمى: نظام في حزمة أو نظام في حزمة.
مصطلح "النظام في حالة" أقل شهرة على نطاق واسع من مصطلح "النظام على رقاقة" ، الذي يحب المطورون أن يتفوقوا عليه بأي شيء. علاوة على ذلك ، الآن أي شريحة تقريبًا (باستثناء الأبسط منها) هي بطريقة ما نظام على شريحة ، وأوقات مجموعات المعالجات الدقيقة وحتى شرائح فردية من الجسور الجنوبية والشمالية هي شيء من الماضي. مزايا الأنظمة الموجودة على الشريحة واضحة تمامًا: عدد أقل من الحالات على اللوحة ، مساحة أقل (مما يعني أرخص) ، عدد أقل من الحث والقدرات الضالة (مما يعني أن المنتج سيعمل بشكل أفضل وأسرع) ، أسهل للمستخدم (إنه أكثر ملاءمة للتنفيذ ومساحة أقل للخطأ) ، أرخص في الإنتاج (بدلاً من العديد من الدوائر المصغرة المتخصصة ، يمكن إنتاج واحدة أخرى عالمية).
لكن الأنظمة الموجودة على الرقاقة لها مآزقها أيضًا.
أولاً ، عندما تحاول دفع كل شيء على بلورة واحدة في وقت واحد ، فإنك تخاطر بالحصول على شريحة بهذا الحجم (ومع العديد من الأرجل) بحيث لا تتناسب مع أي حالة. بالإضافة إلى ذلك (كما يقترح تقني محترف في التعليقات) ، فإن شريحة كبيرة جدًا تخاطر بعدم الدخول في حجم مجال الماسح الضوئي الضوئي. يمكنك تجاوز هذا القيد ، ولكنه صعب للغاية من الناحية الفنية ، وبالتالي مكلف للغاية.
ثانيًا ، كلما كان حجم الشريحة أكبر ، انخفضت النسبة المئوية للعائد ، خاصة إذا كنت تحتاج للإنتاج معًا عدة نوافذ على قناع صور. وهذا بالطبع يؤثر أيضًا على التكلفة.
ثالثًا ، إذا كان نظامك يتكون من مكونات غير متجانسة ، فإن دمجها جميعًا على شريحة واحدة يمكن أن يكون صعبًا جدًا أو مكلفًا جدًا أو سيئًا جدًا بالنسبة لجودة النظام. على سبيل المثال ، تتطلب DRAM مكثفات خاصة ، وإضافتها إلى عملية التصنيع "العادية" يمكن أن تكون مكلفة بشكل غير معقول للمصنع (والتي ستضطر بسبب ذلك إلى رفع الأسعار للعملاء). يمكن أن تحتوي معلمات التردد أو الطاقة الراديوية على السيليكون على معلمات أسوأ بكثير من مواد A3B5 (زرنيخ الغاليوم ونظائره) ، ويخلق توصيل الأجزاء الرقمية والتناظرية على نفس البلورة مشكلة ضوضاء.
أدى الجمع بين جميع العوامل المذكورة أعلاه إلى حقيقة أن اتجاه "وضع الكل الكل الكل على بلورة واحدة" قد تم استبداله بنهج أكثر توازناً ، فضلاً عن التطور السريع لتقنيات تعبئة البلورات في الحالة.
الأداء والعائد
المثال الأول الذي يتبادر إلى الذهن هو بالطبع معالجات AMD الدقيقة (انظر KDPV). تعتبر الأنظمة في حالة المنتجات متعددة النواة أحد الأسباب المهمة للصعود الأخير للشركة ، والتي تحدث على خلفية مشاكل Intel مع إطلاق عملية تقنية جديدة بسبب انخفاض العائد على الرقائق الضخمة.

يوضح الشكل شريحة Intel Xeon من 28 نواة. يصل حجم هذه المعالجات إلى 456 ملليمتر مربع مجنون ، في حين أن حد شريحة AMD يبلغ حوالي 200 ملم مربع لشريحة ثمانية النواة ، ويتم تجميع المنتجات ذات النوى من عدة بلورات متطابقة على لوحة دائرة مطبوعة من طبقتين تقع في حالة المعالج.

في هذا الشكل ، يمكنك رؤية تصميم اللوحة داخل علبة معالجات EPYC و Threadripper (المعروفة أيضًا باسم KDPV). توجد أربع بلورات ثمانية النواة على لوحة من طبقتين. في حالة Threadripper ، مع نصف النوى المعوقة. لماذا يتم استخدام البلورات بشكل غير عقلاني؟
أولاً ، يمكن أن يكون إنتاج نوع واحد من الكريستال أرخص من عدة أنواع مختلفة.
ثانيًا ، ينطبق الشيء نفسه على بقية الحزام - يمكن أن يكون التعطيل غير الضروري أرخص وأكثر تقنية من تطوير وإنتاج العديد من النماذج المختلفة.
ثالثًا ، على الأرجح ، ليست النسبة المئوية للإنتاجية المناسبة لشريحة بحجم 200 ملم مثالية أيضًا ، ويسمح هذا التصميم للمنتج النهائي باستخدام البلورات التي لا تعمل فيها جميع النوى. تقوم Intel بالشيء نفسه تمامًا ، ولكن مشكلات الإخراج الخاصة بها أقوى بكثير بسبب البلورات الأكبر حجمًا.

وهنا مثال أكثر إثارة للاهتمام أيضًا من AMD. AMD Fiji هي وحدة معالجة رسومات (GPU) مع ذاكرة مدمجة عالية السرعة تقع في الهيكل مباشرةً. لماذا هذا مهم؟ لأن الخطوط الأقصر بكثير من المعالج إلى الذاكرة تجعل من الممكن تحقيق سرعات عالية ، وبالتالي أداء أفضل. على عكس المثال السابق ، تختلف البلورات داخل العلبة. علاوة على ذلك ، لا يوجد خمسة منهم ، كما قد يبدو للوهلة الأولى ، ولكن أكثر من ذلك بكثير - اثنان وعشرون. هنا قسم من الهيكل:
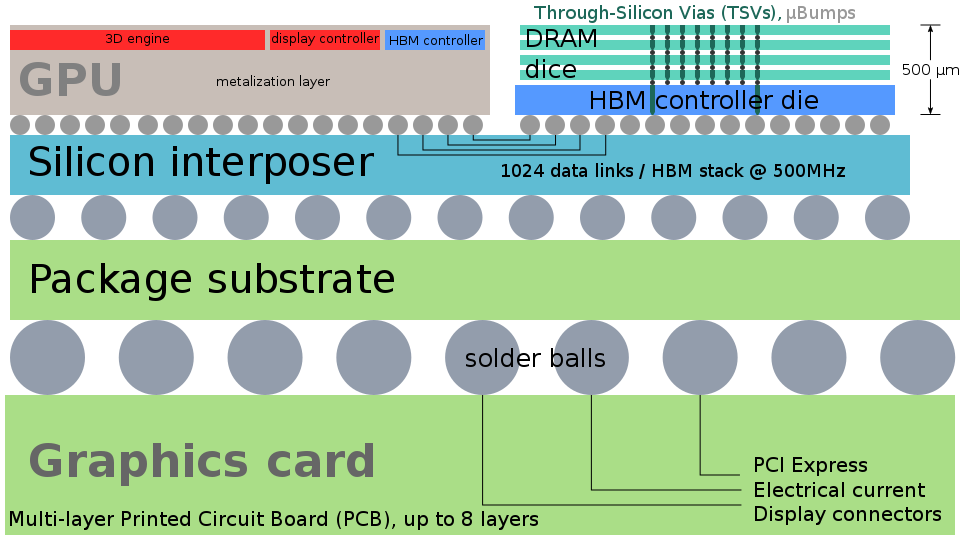
الطبقة العليا هي رقاقة GPU نفسها و "الرف" للعديد من شرائح الذاكرة (في هذه الحالة ، أربعة) متصلة باستخدام TSV (عبر السليكون عبر) - أعمدة موصلة تمر عبر البلورة إلى السماكة الكاملة.
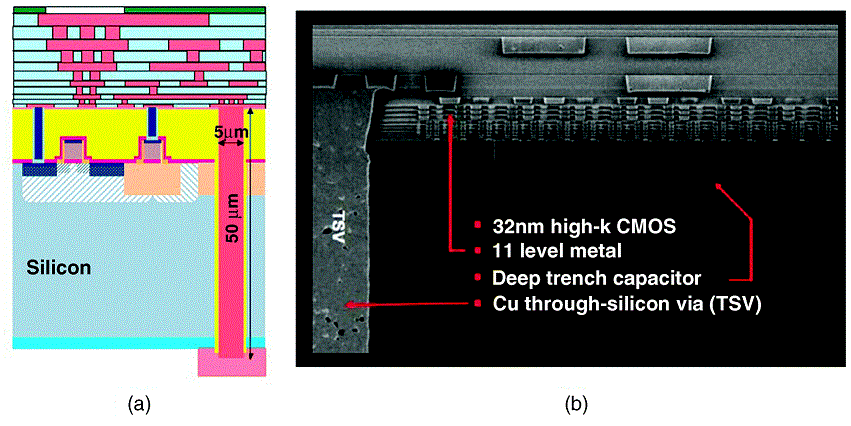
تبدو TSVs مثل هذا ، بشكل تخطيطي وعلى نطاق حقيقي.
تقنية TSV ، التي ظهرت أصلاً فقط لمصفوفات الذاكرة (بعد كل شيء ، لا يوجد الكثير من الذاكرة ، أليس كذلك؟) ، أصبحت الآن أكثر انتشارًا ، بما في ذلك بفضل الشريحة التالية الموجودة تحت GPU والذاكرة.
Silicon Interposer هو بديل للوحة الدوائر المطبوعة متعددة الطبقات المصنوعة من كريستال السيليكون وتحتوي على عدة طبقات من المعدن و TSV لتوصيل الرقائق في الأعلى والعلبة. يسمح استخدام السليكون بالحصول على أحجام أصغر بكثير من العناصر (وحدات الميكرون) من لوحة الدوائر المطبوعة ، ولكن في نفس الوقت يمكن أن تكون معايير التصميم قاسية بما يكفي بحيث تتمتع رقاقة الاتصال هذه بمردود مرتفع وسعر في المتناول. تعني الأبعاد الأصغر للعناصر تأثيرًا أقل على المعلمات الطفيلية للتوصيلات ، وتكون TSVs المذكورة بالفعل أكثر إحكامًا من الفتحات الموجودة على لوحة الدوائر المطبوعة وتسمح بنقل مئات أو حتى الآلاف من جهات الاتصال من خلال جهاز التداخل إلى العلبة. إلى جانب MEMS ، تعد رقائق الربط هذه سوقًا جديدًا مهمًا للمصانع القديمة التي تحتوي على رقائق قطرها 100-150 ملم.
رائد آخر للتكامل ثلاثي الأبعاد هو Xilinx. من الناحية التكنولوجية ، فإن FPGAs قريبة من منتجات AMD (خاصة تلك التي تحتوي على ذاكرة مدمجة) ، والدوافع متشابهة أيضًا: تعتبر FPGAs مكانًا في السوق حيث يمكن للانتقال المبكر إلى عملية تصنيع جديدة أن يعطي ميزة خطيرة على المنافسين. وفقًا لتقديرات مختلفة ، في مرحلة مبكرة من عمر التكنولوجيا ، يمكن أن يؤدي تقليل حجم البلورة بمقدار ثلاث إلى أربع مرات إلى زيادة المحصول مرتين إلى ثلاث مرات ، من بضع عشرات بالمائة إلى أكثر من النصف. علاوة على ذلك ، فإن FPGAs هي بنية منتظمة تكون ملائمة لتتبع العيوب التكنولوجية. لذلك ، فإن مصنعي FPGA هم "العملاء الأوائل" النموذجيون لعمليات التصنيع الجديدة ، و Xilinx ، نظرًا لأن منتجاتها تحتوي على عدة بلورات صغيرة بدلاً من واحدة كاملة الحجم ، يمكنها إطلاق نماذج جديدة أسرع بعدة أشهر من المنافسين.

هنا مقطع عرضي من الدواخل من Xilinx FPGA. الرقاقة العلوية هي في الواقع جزء من FPGA مع جهات اتصال صغيرة جدًا (40-45 ميكرون) إلى المتداخل الذي يربط عدة شرائح معًا ، وفي الجزء السفلي هو قاعدة العلبة ، التي تحتوي على عشرات الطبقات من الروابط المعدنية الخاصة بها.

للمقارنة - FPGA Altera على بلورة ضخمة واحدة. خمسمائة وستون مليمتر مربع ، كارل! إذا تمت قراءة هذا المنشور فجأة من قبل تقنيي إنتاج الإلكترونيات الدقيقة ، فتأكد من عدم تعرضهم لأزمة قلبية.
ومع ذلك ، فإن Intel / Altera ، بطبيعة الحال ، لا تجلس ثابتة ، تراقب نجاح المنافسين. أحدث تطور في الأنظمة المغلقة هو جسر الربط المتداخل متعدد الشرائح (EMIB). من الملائم النظر إليها باستخدام Intel Stratix 10 FPGA.
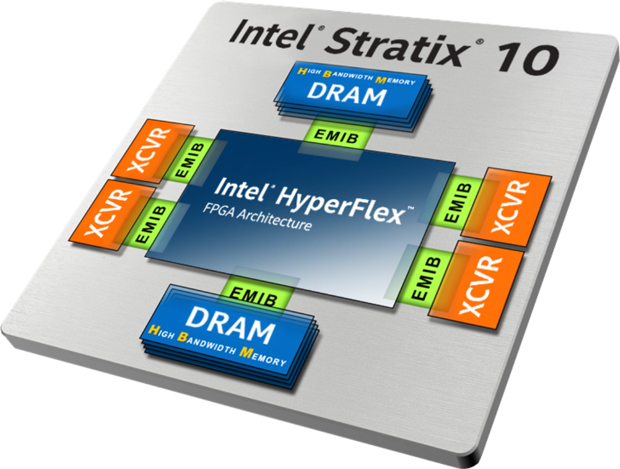
كما ترون ، EMIB يربط رقاقة FPGA (واحد!) ، والذاكرة (وهنا الهياكل متعددة الطوابق) والبلورات الطرفية. إذن ما هذا EMIB؟ أعلى قليلاً كتبت عن مداخل السيليكون أنه بسبب عملية تقنية أكثر صرامة ، فإن سعره أقل بكثير من شريحة بحجم مماثل مصنوعة باستخدام تقنية رقيقة. ومع ذلك ، فإن المتدخل ضخم. هل من الممكن تصغيره؟
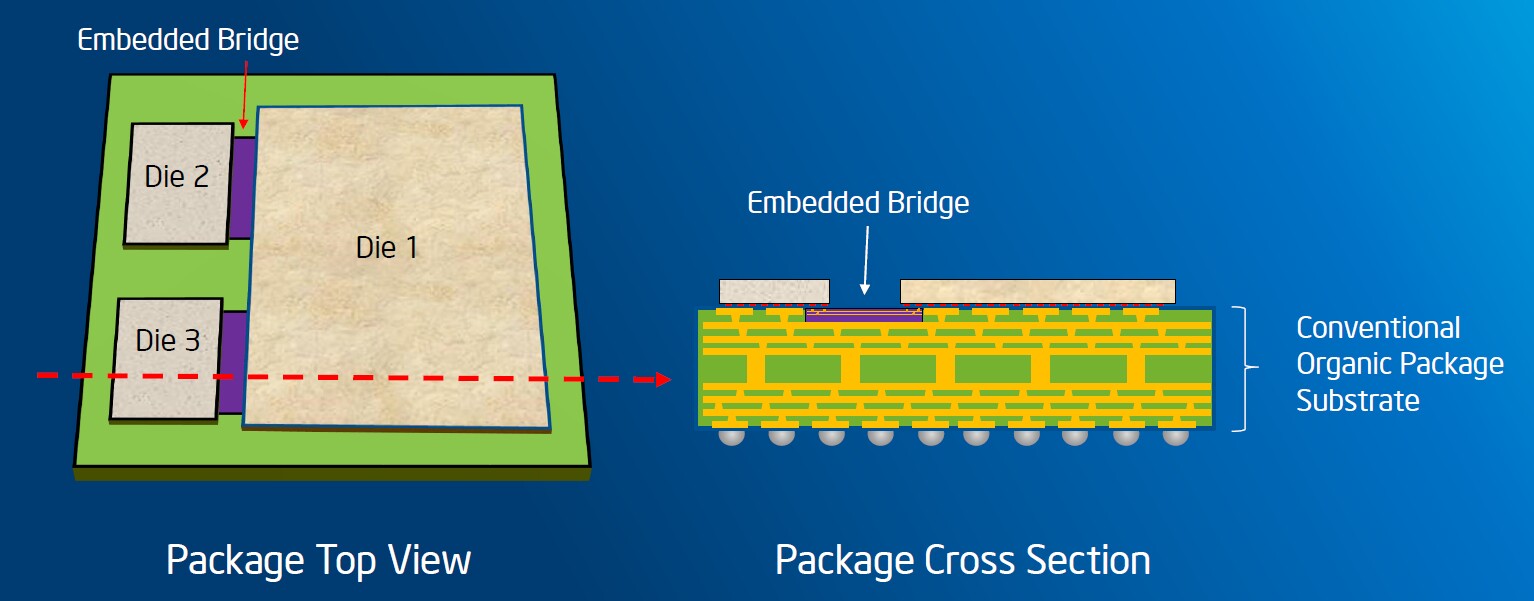
إجابة إنتل هي نعم. تتمثل فكرة EMIB في استخدام العديد من تلك الصغيرة بدلاً من مداخل كبير واحد ، وبالتالي دمجها مباشرة في الركيزة الأساسية للجسم.
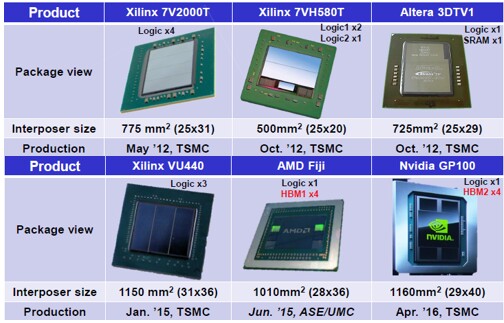
فيما يلي مجموعة صغيرة من المنتجات التي تم إنشاؤها باستخدام مداخل السيليكون. انتبه إلى أبعادها الهائلة من خلال المعايير الإلكترونية الدقيقة وحقيقة أنه ، كما ناقشنا أعلاه ، تنقسم رقائق Xilinx القتالية إلى عدة قطع صغيرة.
أكثر من مجرد أداء.
يوضح الشكل أدناه الجزء الداخلي من غلاف ADC للأجهزة التناظرية ومخطط الدائرة. يبدو أن لوحة الدوائر المطبوعة العادية تمامًا لـ ADC ، أصغر فقط ، أليس كذلك؟ هذا صحيح ، هذا هو ، فقط بسبب استخدام مكونات الإطار المفتوح ، تم تقليل الأخطاء المرتبطة بالعناصر الزائفة ، وحقيقة أن اللوحة تم تطويرها في الأجهزة التناظرية تسمح لها بتوفير الكثير من وقت العميل وفي نفس الوقت تأكد من أن المستخدم لا يخطئ عن طريق اختيار العناصر الخاطئة مكونات أو لوحة سلكية سيئة.

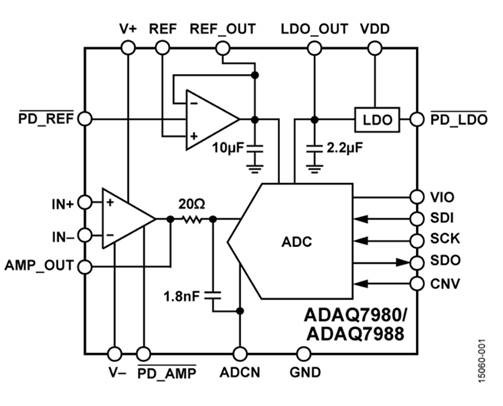
ومع ذلك ، هناك خدعة صغيرة في الشكل أعلاه: هل ترى البلورات الموضوعة على طابقين؟ البلورة العلوية عبارة عن شريحة بها مكونات نشطة لـ ADC نفسها و (على ما يبدو) مضخم تشغيل مزدوج ، والبلورة السفلية هي المكونات السلبية (المكثفات والمقاومات). يتيح لك التنفيذ على بلورة منفصلة جعلها أكبر حجمًا (وبالتالي تقليل الأخطاء) دون زيادة (وبالتالي زيادة تكلفة) البلورة الرئيسية.
يمكن القيام بكل نفس الشيء على شريحة واحدة (والتي ، في الواقع ، ليست غير شائعة ، خاصة بالنسبة لـ ADCs المضمنة في وحدات التحكم الدقيقة) ، ولكن هذه الشريحة ستكون أكبر بكثير (مما يعني ، كما اكتشفنا ، أن هناك خطرًا في تقليل النسبة المئوية للعائد) ، و التكنولوجيا بالنسبة له يجب أن تدعم جميع الخيارات الإضافية الضرورية. بالإضافة إلى ذلك ، سيؤدي الجمع بين الكتل المختلفة على نفس البلورة إلى الحاجة إلى التأكد من أنها لا تؤثر على بعضها البعض (على سبيل المثال ، تخلص بطريقة ما من الضوضاء على الركيزة البلورية).
ميزات السكن الإضافية
كما اكتشفنا بالفعل ، فإن تعبئة العناصر المختلفة (بما في ذلك مكونات SMD السلبية) في مبيت واحد تسمح لك بتقليل أبعاد المنتج النهائي بشكل كبير وحتى زيادة سرعته. ولكن ماذا لو استخدمنا العلبة نفسها كعنصر وظيفي للجهاز؟
في عام 2013 ، نفذت معالجات Intel (Haswell microarch architecture) منظمًا متكاملًا للجهد (FIVR) ، حيث تم تنفيذ الجزء النشط من المنظم على شريحة المعالج ، وتم دمج الجزء السلبي (المكثفات والمحاثات) في الحالة.
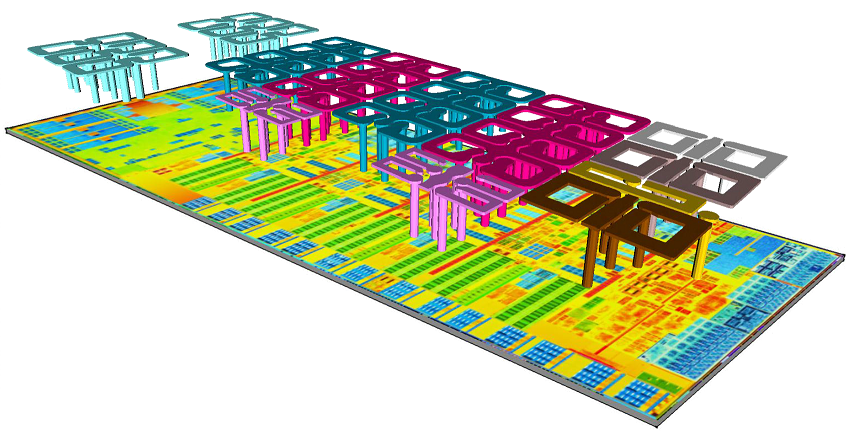
الحث المتكامل هو صداع لجميع مطوري الرقائق ، لأنه يتم الحصول على الملفات الموجودة على الرقاقة ليس فقط مع أفضل المعلمات ، ولكن أيضًا مع المعلمات الضخمة (مما يعني أنها باهظة الثمن ، خاصةً مع التقنيات الرقيقة). وهذا عن ملفات الإشارات بدون نواة ، لا يوجد أي حديث عن نقل الطاقة على الإطلاق. نجحت شركة Intel في التحايل على هذه المشكلة من خلال دمج العشرات من الملفات الصغيرة المتوازية التي تعمل بتردد 160 ميجاهرتز في غلاف المعالج الدقيق. لذلك كانوا قادرين على تبسيط متطلبات الطاقة للمعالج الدقيق بشكل كبير.
ومع ذلك ، حدث خطأ في هذا التطور ، ولم يعد هناك معالجات Intel FIVR في الجيل التالي من معالجات Haswell. منذ ذلك الحين ، كانت هناك شائعات بأنهم سيعودون إلى FIVR ، ولكن حتى الآن ظلت شائعات.
ومع ذلك ، حتى بدون Intel ، فإن اتجاه تكامل المكونات السلبية في الحالة يتطور بنشاط ، على سبيل المثال ، في حالات من نوع LTCC (سيراميك منخفض الحرارة). هناك بالطبع قيود ومزالق (مرتبطة ، على سبيل المثال ، بدقة التصنيفات) ، لكن هذه التكنولوجيا مطلوبة وتتطور بنشاط. تبدو حالة LTCC ذات الطبقات كما يلي:
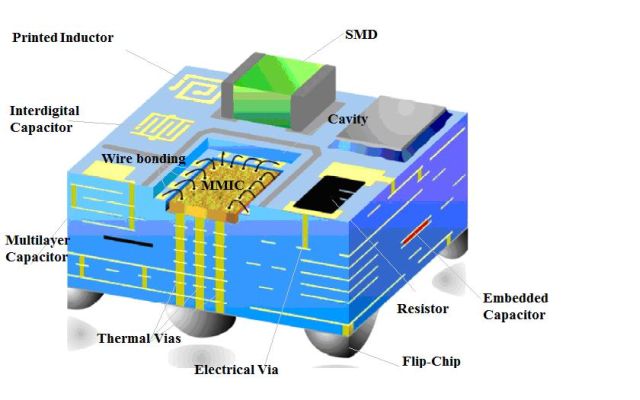
يوضح الشكل جميع أنواع العناصر السلبية المصنوعة في السيراميك متعدد الطبقات ، وحتى بالوعة الحرارة المعدنية (هذا هو الحال بالنسبة لدائرة ميكروويف قوية). في الواقع ، هو مزيج من الحالة مع لوحة الدوائر المطبوعة الخزفية. تحظى هذه القطع بشعبية كبيرة في وحدات التردد اللاسلكي ، كما أنها رخيصة نسبيًا في الإنتاج على نطاق صغير.
ماذا ايضا؟
هناك الكثير من التطبيقات المحتملة للأنظمة في الحالة ، ومن المستحيل تقريبًا سردها جميعًا ؛ علاوة على ذلك ، يظهر شيء جديد باستمرار ، بما في ذلك بسبب حقيقة أن هذه التقنيات بأسعار معقولة أكثر بكثير من الترانزستورات 10-7-5-3 نانومتر.
من الأمثلة الجيدة على التطبيقات والخصائص الجديدة التي يفتحها دمج رقائق غير متجانسة في حزمة واحدة مجموعة متنوعة من الأنظمة الضوئية حيث يسمح لك SiP بتجميع جهاز استقبال أو باعث (عادة لا يصنع على السيليكون) ، ودوائر الطاقة والتحكم الخاصة بها. في الرسم التوضيحي أدناه - رابط بصري نموذجي بسرعة 400 جيجابت / ثانية (ووعد قبل terabit) ، تم تجميعه في معهد الأبحاث البلجيكي IMEC.

بالإضافة إلى ذلك ، فإن مثل هذه التطبيقات الواعدة للأنظمة في الحالة تأخذ في الاعتبار أشياء مثل interpozers مع الشعيرات الدموية المدمجة للتبريد السائل (ليس فقط معالجات الألعاب ، ولكن أيضًا مفاتيح التشغيل والليزر) ، ووحدات MEMS المدمجة في الحالة ، وأكثر من ذلك بكثير لا تقع ضمن الإطار الضيق لقانون مور. بالإضافة إلى ذلك ، يعتبر إنترنت الأشياء في كل مكان سوقًا مهمًا للأنظمة في الحالة ، حيث تكون الأحجام الصغيرة ، وغياب الخسائر (في المقام الأول الطاقة ، وليس الوقت) على العناصر الزائفة ، والقدرة على دمج المكونات السلبية ، على سبيل المثال ، أجزاء من المسار الراديوي ، في الدائرة المصغرة مهمة.