
نحن في قسم التحليلات في السينما عبر الإنترنت Okko نحب أتمتة حساب رسوم فيلم Alexander Nevsky قدر الإمكان ، وفي وقت الفراغ لتعلم أشياء جديدة وتنفيذ أشياء رائعة تترجم لسبب ما عادة إلى برامج الروبوت لـ Telegram. على سبيل المثال ، قبل بدء كأس العالم 2018 FIFA ، قمنا بتطبيق روبوت على دردشة العمل ، والتي جمعت الرهانات على توزيع الأماكن النهائية ، وبعد المباراة النهائية ، قمنا بحساب النتائج وفقًا لمقياس تم اختراعه مسبقًا وتحديد الفائزين. كرواتيا لم تضع أربعة في المراكز الأربعة الأولى.
وقت الفراغ الأخير من تجميع الكوميديا الروسية TOP-10 التي كرسناها لإنشاء روبوت يجد المشاهير الذين يشبههم المستخدم. في دردشة العمل ، قدر الجميع الفكرة كثيرًا لدرجة أننا قررنا إتاحة الروبوت للجمهور. في هذه المقالة ، نتذكر بإيجاز النظرية ، ونتحدث عن إنشاء روبوتنا وكيفية القيام بذلك بنفسك.
القليل من النظرية (غالبًا في الصور)
بالتفصيل حول كيفية ترتيب أنظمة التعرف على الوجوه ، تحدثت في إحدى مقالاتي السابقة . يمكن للقارئ المهتم اتباع الرابط ، وسأوضح أدناه النقاط الرئيسية فقط.
لذا ، لديك صورة ، ربما ، حتى يظهر وجه وتريد أن تفهم من هو. للقيام بذلك ، تحتاج إلى اتباع 4 خطوات بسيطة:
- حدد المستطيل المحيط بالوجه.
- قم بتمييز النقاط الرئيسية للوجه.
- قم بمحاذاة وجهك واقتصاصه.
- تحويل صورة وجه إلى بعض التمثيل المفسر آليًا.
- قارن هذا الرأي مع الآخرين المتاحين لديك.
اختيار الوجه
على الرغم من أن الشبكات العصبية التلافيفية قد تعلمت مؤخرًا كيفية العثور على وجوه في صورة ليست أسوأ من الأساليب الكلاسيكية ، إلا أنها لا تزال أدنى من HOG الكلاسيكي في السرعة وسهولة الاستخدام.
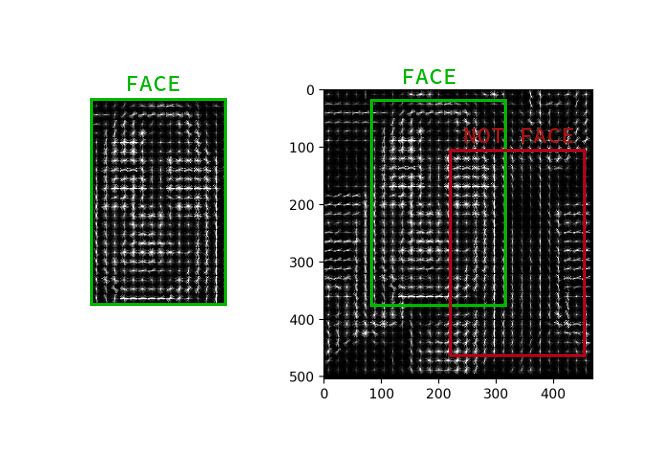
HOG - الرسوم البيانية للتدرجات الموجهة. يربط هذا الرجل كل بكسل من صورة المصدر بتدرجه - وهو متجه في اتجاه تغير سطوع وحدات البكسل أكثر. ميزة هذا النهج هي أنه لا يهتم بالقيم المطلقة لسطوع البكسل ، فقط نسبة كافية. لذلك ، سيتم عرض وجه عادي ومظلم ومضاء بشكل سيء وصاخب في نفس المدرج التكراري تقريبًا.
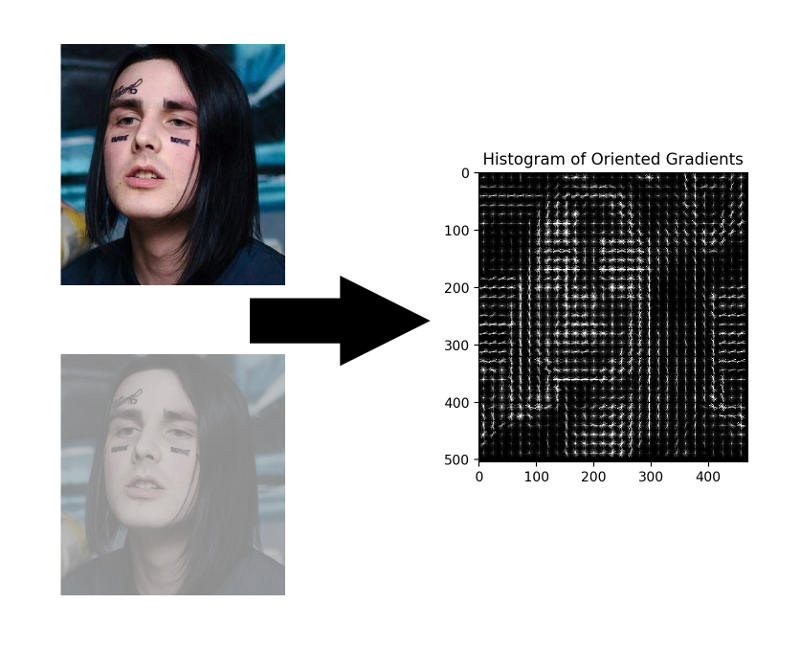
ليس من الضروري حساب التدرج لكل بكسل ، يكفي حساب متوسط التدرج لكل مربع صغير n بـ n . باستخدام حقل المتجه المستلم ، يمكنك بعد ذلك المرور عبر بعض الكاشف مع نافذة وتحديد كل نافذة مدى احتمالية وجود الوجه فيه. يمكن أن يكون الكاشف SVM أو غابة عشوائية أو أي شيء آخر.
قم بتمييز النقاط الرئيسية

النقاط الرئيسية هي النقاط التي تساعد على تحديد هوية الشخص في الفضاء. عادة ما يحتاج العلماء الضعفاء وغير الآمنون إلى 68 نقطة رئيسية ، وفي الحالات المهملة بشكل خاص ، أكثر من ذلك. الأولاد العاديون واثقون من أنفسهم ، الذين يكسبون 300 ألف في الثانية ، لديهم دائمًا ما يكفي من خمسة: الزوايا الداخلية والخارجية للعيون والأنف.
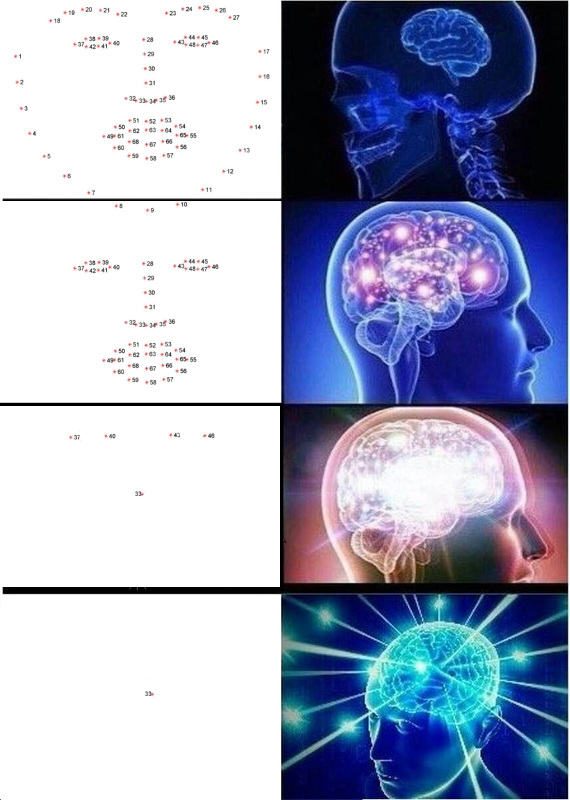
يمكن استخراج هذه النقاط ، على سبيل المثال ، عن طريق سلسلة من الانحدارات .
محاذاة الوجه
التطبيقات الملتصقة في الطفولة؟ هنا كل شيء هو نفسه تمامًا: تقوم ببناء تحول تقريبي يترجم ثلاث نقاط اعتباطية إلى مواقعها القياسية. يمكن ترك الأنف كما هو ، ولكن للعيون لحساب مراكزهم - هذه هي النقاط الثلاث جاهزة.

تحويل صور الوجه إلى ناقل

لقد مرت ثلاث سنوات منذ نشر مقال حول FaceNet ، خلال هذا الوقت ظهرت العديد من برامج التدريب المثيرة للاهتمام ووظائف الخسارة ، لكنها هي المهيمنة بين حلول OpenSource المتاحة. يبدو أن الأمر برمته هو مزيج من سهولة الفهم والتنفيذ والنتائج اللائقة. شكرا على الأقل لحقيقة أنه على مدى السنوات الثلاث الماضية تم تغيير الهيكل إلى ResNet.
يتعلم FaceNet من ثلاث أمثلة: (مرساة ، إيجابي ، سلبي). تنتمي المرساة والأمثلة الإيجابية إلى شخص واحد ، في حين يتم اختيار السلبية كوجه لشخص آخر ، والتي لسبب ما تكون الشبكة قريبة جدًا من الأولى. تم تصميم وظيفة الخسارة بطريقة لتصحيح سوء الفهم هذا ، وجمع الأمثلة اللازمة ونقل ما هو غير ضروري منها.

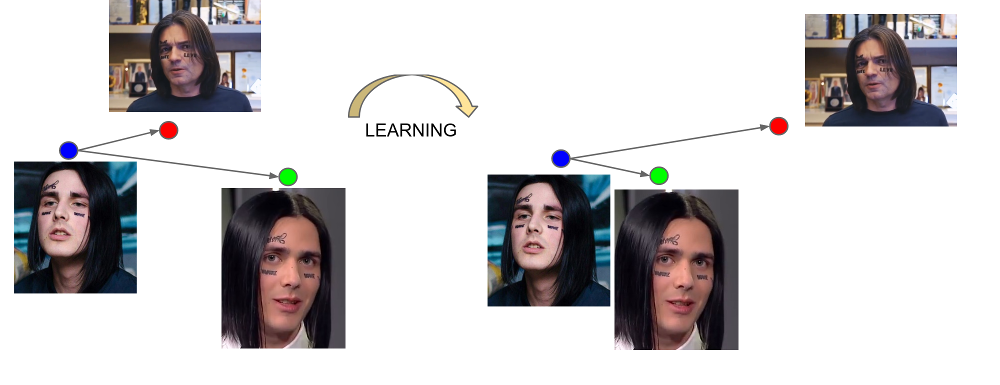
يسمى إخراج الطبقة الأخيرة من الشبكة التضمين - تمثيل تمثيلي لشخص في مساحة معينة ذات أبعاد صغيرة (عادة 128-أبعاد).
مقارنة الوجه
جمال التضمينات المدربة جيدًا هو أن وجوه شخص واحد معروضة في حي صغير من المساحة ، بعيدًا عن غرس وجوه الآخرين. لذلك ، بالنسبة لهذه المساحة ، يمكنك إدخال مقياس للتشابه ، متبادل المسافة: إقليدية أو جيب التمام ، اعتمادًا على المسافة التي تم تدريب الشبكة عليها.
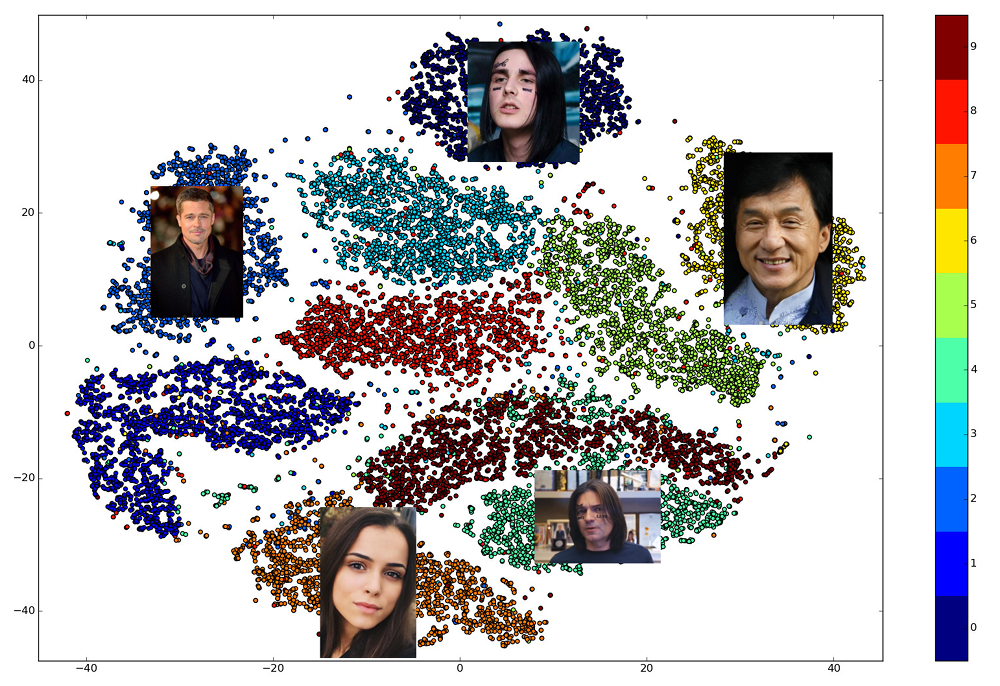
وبالتالي ، نحتاج مقدمًا إلى إنشاء عمليات تضمين لجميع الأشخاص الذين سيتم إجراء البحث من بينهم ، ثم ، لكل طلب ، ابحث عن أقرب ناقل بينهم. أو ، بطريقة أخرى ، حل مشكلة إيجاد أقرب جيران ، حيث قد تكون k مساوية لواحد ، أو ربما لا ، إذا أردنا استخدام بعض منطق الأعمال الأكثر تقدمًا. سيكون الشخص الذي يمتلك متجه النتيجة هو الأكثر تشابهًا مع الشخص المطلوب.

أي مكتبة تستخدم؟
إن اختيار المكتبات المفتوحة التي تنفذ أجزاء مختلفة من خط الأنابيب أمر رائع. dlib و OpenCV العثور على الوجوه والنقاط الرئيسية ، ويمكن العثور على إصدارات مدربة مسبقًا من الشبكات لأي إطار عمل شبكة عصبية كبير. هناك مشروع OpenFace حيث يمكنك اختيار البنية لمتطلبات السرعة والجودة. لكن مكتبة واحدة فقط تسمح لك بتنفيذ جميع نقاط التعرف على الوجوه الخمس في المكالمات لثلاث وظائف عالية المستوى: dlib . في الوقت نفسه ، هو مكتوب بلغة C ++ الحديثة ، ويستخدم BLAS ، ولديه غلاف لـ Python ، ولا يتطلب GPU ، ويعمل بسرعة كبيرة على وحدة المعالجة المركزية. وقع اختيارنا عليها.
صنع الروبوت الخاص بك
تم وصف هذا القسم بالفعل في كل دليل لإنشاء برامج الروبوت ، ولكن بمجرد أن نكتب نفس الشيء ، سيتعين علينا تكراره. نكتب BotFather ونطلب منه رمزًا لروبوتنا الجديد.
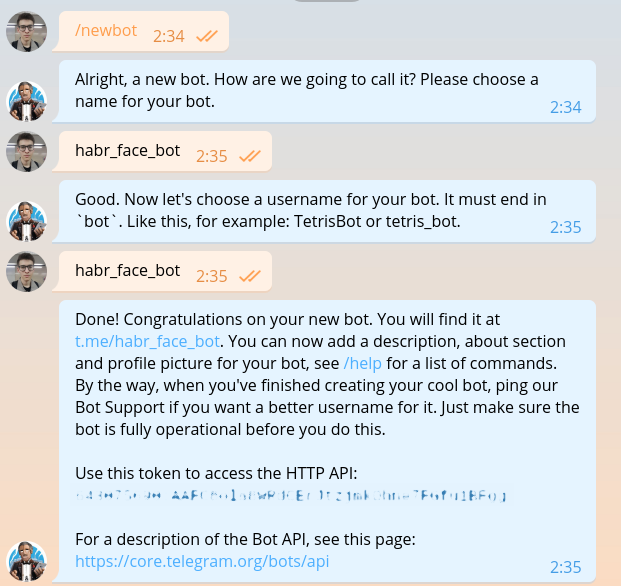
يبدو الرمز المميز شيئًا كهذا: 643075690:AAFC8ola8WRdhGbJtzjmkOhne1FGfu1BFg . من الضروري الحصول على إذن عند كل طلب إلى Telegram bot API.
آمل ألا يكون لدى أي شخص في هذه المرحلة أي شك عند اختيار لغة البرمجة. بالطبع ، عليك أن تكتب في هاسكل. لنبدأ بالوحدة الرئيسية.
import System.Process main :: IO () main = do (_, _, _, handle) <- createProcess (shell "python bot.py") _ <- waitForProcess handle putStrLn "Done!"
كما ترى من الكود ، سنستخدم في المستقبل DSL خاص لكتابة الروبوتات برقية. الرمز الموجود على خط المشترك الرقمي هذا مكتوب في ملفات منفصلة. قم بتثبيت لغة المجال وكل ما هو ضروري.
python -m venv .env source .env/bin/activate pip install python-telegram-bot
python-telegram-bot هو حاليًا الإطار الأكثر ملاءمة لإنشاء برامج الروبوت. إنه سهل التعلم ، مرن ، قابل للتطوير ، يدعم تعدد مؤشرات الترابط. لسوء الحظ ، في الوقت الحالي لا يوجد إطار واحد غير متزامن عادي ويجب استخدام الخيوط القديمة بدلاً من الكورونات الإلهية.

بدء روبوت باستخدام python-telegram-bot أمر سهل. أضف الكود التالي إلى bot.py
from telegram.ext import Updater from telegram.ext import MessageHandler, Filters
شغل البوت. لأغراض التصحيح ، يمكن القيام بذلك باستخدام python bot.py بدون تشغيل كود Haskell.
مثل هذا الروبوت البسيط قادر على الحفاظ على الحد الأدنى من المحادثة ، وبالتالي ، يمكن ترتيبه بسهولة للعمل كمطور أمامي.
لكن الواجهة الأمامية للمطورين كثيرة جدًا بالفعل ، لذلك سنقتلها في أقرب وقت ممكن ونمضي في تنفيذ الوظيفة الرئيسية. من أجل البساطة ، سيرد برنامج الروبوت الخاص بنا فقط على الرسائل التي تحتوي على صور ويتجاهل أي صور أخرى. قم بتغيير الرمز إلى ما يلي.
from telegram.ext import Updater from telegram.ext import MessageHandler, Filters
عندما تدخل الصورة إلى خادم Telegram ، يتم ضبطها تلقائيًا على عدة أحجام محددة مسبقًا. يمكن للبوت ، بدوره ، تنزيل صورة بأي حجم من تلك الموجودة في قائمة message.photo مصنفة بترتيب تصاعدي. الخيار الأسهل: التقاط أكبر صورة. بالطبع ، في بيئة البقالة ، تحتاج إلى التفكير في تحميل الشبكة ووقت التحميل واختيار صورة بالحجم الأدنى المناسب. أضف رمز تنزيل الصورة إلى أعلى وظيفة handle_photo .
import io
message = update.message photo = message.photo[~0] with io.BytesIO() as fd: file_id = bot.get_file(photo.file_id) file_id.download(out=fd) fd.seek(0)
تم تنزيل الصورة وهي في الذاكرة. لتفسيرها وتقديمها في شكل مصفوفة كثافة البكسل ، نستخدم المكتبات Pillow numpy .
from PIL import Image import numpy as np
يجب إضافة التعليمات البرمجية التالية إلى الكتلة.
image = Image.open(fd) image.load() image = np.asarray(image)
لقد حان الوقت dlib. خارج الوظيفة ، قم بإنشاء كاشف للوجه.
import dlib
face_detector = dlib.get_frontal_face_detector()
وداخل الوظيفة نستخدمها.
face_detects = face_detector(image, 1)
المعلمة الثانية للدالة تعني التكبير الذي يجب تطبيقه قبل محاولة اكتشاف الوجوه. كلما كان أكبر ، كلما كانت الوجوه الأصغر والأكثر تعقيدًا قادرة على اكتشافها ، ولكن كلما طالت مدة عملها. face_detects - قائمة الوجوه مرتبة ترتيبًا تنازليًا لثقة الكاشف بأن الوجه أمامه. في التطبيق الحقيقي ، ستحتاج على الأرجح إلى تطبيق بعض منطق اختيار الشخص الرئيسي ، وفي دراسة الحالة سنقتصر على اختيار الشخص الأول.
if not face_detects: bot.send_message(chat_id=update.message.chat_id, text='no faces') face = face_detects[0]
ننتقل إلى المرحلة التالية - البحث عن النقاط الرئيسية. قم بتنزيل النموذج المدرب وحمل حمله خارج الوظيفة.
shape_predictor = dlib.shape_predictor('path/to/shape_predictor_5_face_landmarks.dat')
ابحث عن النقاط الرئيسية.
landmarks = shape_predictor(image, face)
الشيء الوحيد المتبقي صغير: لتصويب الوجه ، ودفعه عبر ResNet والحصول على تضمين 128-أبعاد. لحسن الحظ ، يسمح لك dlib بالقيام بكل هذا بمكالمة واحدة. تحتاج فقط إلى تنزيل النموذج المدرب مسبقًا .
face_recognition_model = dlib.face_recognition_model_v1('path/to/dlib_face_recognition_resnet_model_v1.dat')
embedding = face_recognition_model.compute_face_descriptor(image, landmarks) embedding = np.asarray(embedding)
فقط انظر إلى أي وقت رائع نعيش فيه. يتم تغليف التعقيد الكامل للشبكات العصبية التلافيفية ، وطريقة ناقلات الدعم ، والتحويلات اللاحقة المطبقة على التعرف على الوجوه في ثلاث مكالمات مكتبة.
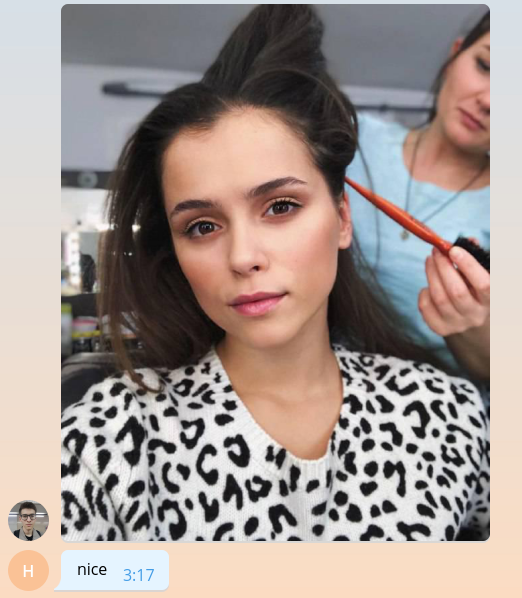
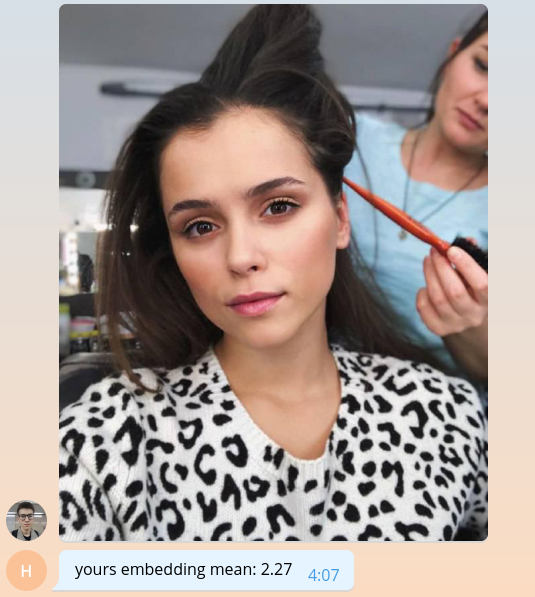
نظرًا لأننا لا نعرف كيفية القيام بأي شيء ذي معنى حتى الآن ، فلنعد للمستخدم متوسط قيمة التضمين ، مضروبًا في الألف.
bot.send_message( chat_id=update.message.chat_id, text=f'yours embedding mean: {embedding.mean() * 1e3:.2f}' )
لكي يتمكن البوت الخاص بنا من تحديد المشاهير الذين يشبههم المستخدمون ، نحتاج الآن إلى العثور على صورة واحدة على الأقل لكل شخص مشهور ، وبناء تضمين عليها وحفظها في مكان ما. سنضيف 10 مشاهير فقط إلى روبوت التدريب الخاص بنا ، ونعثر على صورهم يدويًا ونضعهم في دليل photos . هذا ما يجب أن يبدو عليه:
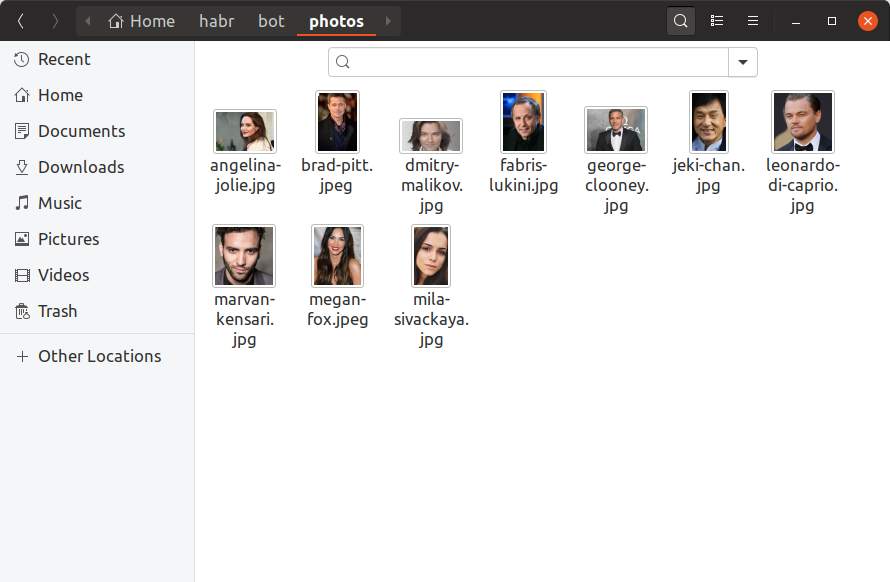
إذا كنت تريد أن يكون لديك مليون من المشاهير في قاعدة البيانات ، فسيبدو كل شيء كما هو تمامًا ، فقط هناك المزيد من الملفات ومن غير المحتمل أن تبحث عنها بيديك. الآن دعنا build_embeddings.py الأداة المساعدة build_embeddings.py باستخدام مكالمات dlib التي نعرفها بالفعل ونقوم بحفظ تضمين المشاهير مع أسمائهم بتنسيق ثنائي.
import os import dlib import numpy as np import pickle from PIL import Image face_detector = dlib.get_frontal_face_detector() shape_predictor = dlib.shape_predictor('assets/shape_predictor_5_face_landmarks.dat') face_recognition_model = dlib.face_recognition_model_v1('assets/dlib_face_recognition_resnet_model_v1.dat') fs = os.listdir('photos') es = [] for f in fs: print(f) image = np.asarray(Image.open(os.path.join('photos', f))) face_detects = face_detector(image, 1) face = face_detects[0] landmarks = shape_predictor(image, face) embedding = face_recognition_model.compute_face_descriptor(image, landmarks, num_jitters=10) embedding = np.asarray(embedding) name, _ = os.path.splitext(f) es.append((name, embedding)) with open('assets/embeddings.pickle', 'wb') as f: pickle.dump(es, f)
أضف التحميل المضمّن إلى رمز الروبوت الخاص بنا.
import pickle
with open('assets/embeddings.pickle', 'rb') as f: star_embeddings = pickle.load(f)
ومن خلال البحث الشامل ، سنكتشف من هو المستخدم نفسه.
ds = [] for name, emb in star_embeddings: distance = np.linalg.norm(embedding - emb) ds.append((name, distance)) best_match, best_distance = min(ds, key=itemgetter(1)) bot.send_message( chat_id=update.message.chat_id, text=f'your look exactly like *{best_match}*', parse_mode='Markdown' )
يرجى ملاحظة أننا نستخدم المسافة الإقليدية كمسافة ، لأن تم تدريب الشبكة في dlib بدقة بمساعدة ذلك.

هذا كل شيء ، مبروك! لقد أنشأنا روبوتًا بسيطًا يمكنه تحديد المشاهير الذين يشبههم المستخدم. يبقى العثور على المزيد من الصور وإضافة العلامات التجارية وقابلية التوسع وقليل من التسجيل ويمكن تحرير كل شيء في الإنتاج. جميع هذه المواضيع ضخمة للغاية بحيث لا يمكن الحديث عنها بالتفصيل مع قوائم الرموز الضخمة ، لذلك سأقوم فقط بإيجاز النقاط الرئيسية في تنسيق إجابة السؤال في القسم التالي.
رمز بوت التدريب الكامل متاح على جيثب .
نتحدث عن الروبوت لدينا
كم عدد المشاهير في قاعدة البيانات الخاصة بك؟ اين وجدتهم
يبدو أن القرار الأكثر منطقية عند إنشاء الروبوت يأخذ بيانات المشاهير من قاعدة المحتوى الداخلي لدينا. وهي في شكل الرسم البياني تخزن الأفلام وجميع الكيانات المرتبطة بالأفلام ، بما في ذلك الممثلين والمخرجين. لكل شخص ، نعرف اسمها وتسجيل الدخول وكلمة المرور من iCloud والأفلام والأسماء المستعارة ذات الصلة ، والتي يمكن استخدامها لإنشاء روابط إلى الموقع. بعد تنظيف واستخراج المعلومات الضرورية فقط ، يبقى ملف json كما يلي:
[ { "name": " ", "alias": "tilda-swinton", "role": "actor", "n_movies": 14 }, { "name": " ", "alias": "michael-shannon", "role": "actor", "n_movies": 22 }, ... ]
كان هناك 22000 مثل هذه الإدخالات في الكتالوج. بالمناسبة ، ليس كتالوج ، بل كتالوج.
أين تجد الصور لكل هؤلاء الناس؟

حسنًا ، كما تعلم ، هنا وهناك . هناك ، على سبيل المثال ، مكتبة رائعة تسمح لك بتحميل نتائج البحث عن الصور من Google. 22 ألف شخص - ليس كثيرًا ، باستخدام 56 تيارات تمكنا من تنزيل الصور لهم في أقل من ساعة.
من بين الصور التي تم تنزيلها ، تحتاج إلى تجاهل الصور المكسورة والصاخبة بتنسيق خاطئ. ثم اترك فقط تلك التي توجد فيها وجوه وحيث تلبي هذه الوجوه شروطًا معينة: الحد الأدنى للمسافة بين العينين ، وإمالة الرأس. كل هذا يتركنا مع 12000 صورة.
من بين 12 ألف من المشاهير ، وجد المستخدمون 2 فقط في الوقت الحالي ، أي أن هناك ما يقرب من 8 آلاف من المشاهير الذين لا يزالون ليسوا مثل أي شخص آخر. لا تترك الأمر هكذا! افتح البرقيات واعثر عليها جميعًا.
كيفية تحديد النسبة المئوية للتشابه في المسافة الإقليدية؟
سؤال عظيم! في الواقع ، المسافة الإقليدية ، على عكس جيب التمام ، ليست محدودة أعلاه. لذلك ، يُطرح سؤال معقول ، كيف تُظهر للمستخدم شيئًا أكثر معنى من "تهانينا ، المسافة بين التضمين وتضمين أنجلينا جولي هي 0.27635462738"؟ اقترح أحد أعضاء فريقنا الحل البسيط والبارع التالي. إذا قمت ببناء توزيع المسافات بين التضمينات ، فسيكون ذلك طبيعيًا. لذلك ، بالنسبة له ، يمكنك حساب المتوسط والانحراف المعياري ، ثم لكل مستخدم ، وفقًا لهذه المعلمات ، ضع في اعتبارك عدد الأشخاص الذين هم أقل شهرة من المشاهير . وهذا يعادل دمج دالة كثافة الاحتمال من d إلى plus اللانهاية ، حيث d هي المسافة بين المستخدم وتجمعات المشاهير.
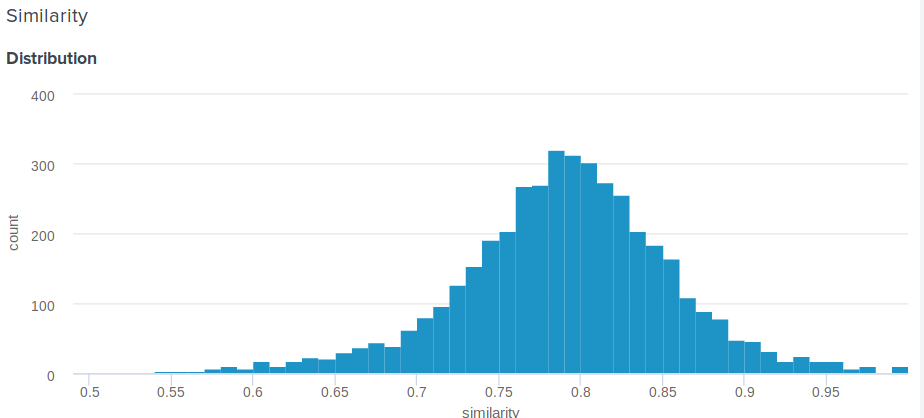
فيما يلي الوظيفة الدقيقة التي نستخدمها:
def _transform_dist_to_sim(self, dist): p = 0.5 * (1 + erf((dist - self._dist_mean) / (self._dist_std * 1.4142135623730951))) return max(min(1 - p, 1.0), self._min_similarity)
هل من الضروري التكرار على قائمة جميع النقابات من أجل العثور على تطابق؟
بالطبع لا ، هذا ليس الأمثل ويستغرق الكثير من الوقت. أسهل طريقة لتحسين الحسابات هي استخدام عمليات المصفوفة. بدلاً من طرح المتجهات من بعضها البعض ، يمكنك تكوين مصفوفة منها وطرح متجه من المصفوفة ، ثم حساب معيار L2 في الصفوف.
scores = np.linalg.norm(emb - embeddings, axis=1) best_idx = scores.argmax()
هذا يعطي بالفعل زيادة كبيرة في الإنتاجية ، ولكن اتضح أنه يمكنك أسرع. يمكن تسريع البحث بشكل كبير بفقدان القليل من دقته باستخدام مكتبة nmslib . ويستخدم أسلوب HNSW لتقريب البحث عن أقرب جيران k . لجميع المتجهات المتاحة ، يجب بناء ما يسمى الفهرس ، ثم سيتم إجراء البحث. يمكنك إنشاء وحفظ الفهرس لمسافة الإقليدية كما يلي:
import nmslib index = nmslib.init(method='hnsw', space='l2', data_type=nmslib.DataType.DENSE_VECTOR) for idx, emb in enumerate(embeddings): index.addDataPoint(idx, emb) index_time_params = { 'indexThreadQty': 4, 'skip_optimized_index': 0, 'post': 2, 'delaunay_type': 1, 'M': 100, 'efConstruction': 2000 } index.createIndex(index_time_params, print_progress=True) index.saveIndex('./assets/embeddings.bin')
يتم وصف المعلمات M و efConstruction بالتفصيل في الوثائق ويتم اختيارها تجريبيًا بناءً على الدقة المطلوبة ووقت بناء الفهرس وسرعة البحث. قبل استخدام الفهرس ، يجب عليك تنزيل:
index = nmslib.init(method='hnsw', space='l2', data_type=nmslib.DataType.DENSE_VECTOR) index.loadIndex('./assets/embeddings.bin') query_time_params = {'efSearch': 400} index.setQueryTimeParams(query_time_params)
تؤثر معلمة efSearch في دقة الاستعلامات وسرعتها وقد لا تتطابق مع efConstruction . الآن يمكنك تقديم الطلبات.
ids, dists = index.knnQuery(embedding, k=1) best_dx = ids[0] best_dist = dists[0]
في حالتنا ، nmslib أسرع 20 مرة من الإصدار الخطي nmslib ، ويتم معالجة طلب واحد في المتوسط 0.005 ثانية.
كيف أجعل بوت جاهزاً للإنتاج؟
1. التزامن
أولاً ، يجب أن تجعل وظيفة handle_photo غير متزامنة. كما قلت بالفعل ، يوفر python-telegram-bot تعدد سلاسل لهذا الغرض وينفذ الديكور المريح.
from telegram.ext.dispatcher import run_async @run_async def handle_photo(bot, update): ...
الآن سيتم تشغيل الإطار نفسه المعالج الخاص بك في مؤشر ترابط منفصل في التجمع الخاص به. يتم تعيين حجم التجمع عند إنشاء Updater . "ولكن في بيثون ليس هناك تعدد!" أكثر صبر منك قد هتف بالفعل. وهذا ليس صحيحًا تمامًا. بسبب GIL ، لا يمكن تنفيذ كود Python العادي بشكل متوازٍ ، ولكن يتم إصدار GIL لانتظار جميع عمليات IO ، ويمكن أيضًا إصداره من قبل المكتبات التي تستخدم ملحقات C.
الآن قم بتحليل وظيفة handle_photo بنا: فهي تتكون فقط من انتظار عمليات الإدخال / الإخراج (تحميل صورة ، إرسال استجابة ، قراءة صورة من القرص ، وما إلى ذلك) ووظائف الاتصال من numpy nmslib .
لم أذكر dlib لسبب ما. المكتبة التي تستدعي الكود الأصلي ليست مطلوبة لتحرير GIL و dlib هذا الحق. إنها لا تحتاج إلى هذا القفل ، لكنها لا تسمح لها بالذهاب. يقول المؤلف أنه سيقبل بكل سرور طلب السحب المناسب ، لكنني كسول جدًا.
2. المعالجة المتعددة
أسهل طريقة للتعامل مع dlib هي تغليف النموذج في كيان منفصل وتشغيله في عملية منفصلة. وأفضل في تجمع العملية.
def _worker_initialize(config): global model model = Model(config) model.load_state() def _worker_do(image): return model.process_image(image) pool = multiprocessing.Pool(8, initializer=_worker_initialize, initargs=(config,))
result = pool.apply(_worker_do, (image,))
3. الحديد
إذا كان برنامج الروبوت الخاص بك يحتاج إلى قراءة الصور من القرص باستمرار ، فتأكد من أن القرص هو SSD. أو حتى تركيبها في ذاكرة الوصول العشوائي. بينغ لخوادم البرقية وجودة القناة مهمة أيضًا.
4. السيطرة على الفيضانات
لا تسمح البرقيات لبرامج الروبوت بإرسال أكثر من 30 رسالة في الثانية. إذا كان برنامج الروبوت الخاص بك شائعًا ويستخدمه الكثير من الأشخاص في نفس الوقت ، فمن السهل جدًا حظره لبضع ثوانٍ ، والذي سيتحول إلى خيبة أمل من توقعات العديد من المستخدمين. لحل هذه المشكلة ، يقدم لنا python-telegram-bot قائمة انتظار لا يمكنها إرسال أكثر من حد الرسالة المحدد في الثانية ، مع الحفاظ على فترات متساوية بين الإرسال.
from telegram.ext.messagequeue import MessageQueue
لاستخدامه ، تحتاج إلى تحديد الروبوت الخاص بك واستبداله عند إنشاء Updater .
from telegram.utils.promise import Promise class MQBot(Bot): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self._message_queue = MessageQueue( all_burst_limit=30, all_time_limit_ms=1000 ) def __del__(self): try: self._message_queue.stop() finally: super().__del__() def send_message(self, *args, **kwargs): is_group = kwargs.get('chat_id', 0) >= 0 return self._message_queue(Promise(super().send_message, args, kwargs), is_group)
bot = MQBot(token=TOKEN) updater = Updater(bot=bot)
5. خطاف الويب
في بيئة المنتج ، يجب دائمًا استخدام Web Hooks بدلاً من Long Polling كطريقة لتلقي التحديثات من خوادم Telegram. يمكن قراءة ما يدور حوله وكيفية استخدامه هنا .
6. التوافه
json . , ultrajson .
IO-: , , . , .
6.
, . , , , . , .
, , BI-tool Splunk .
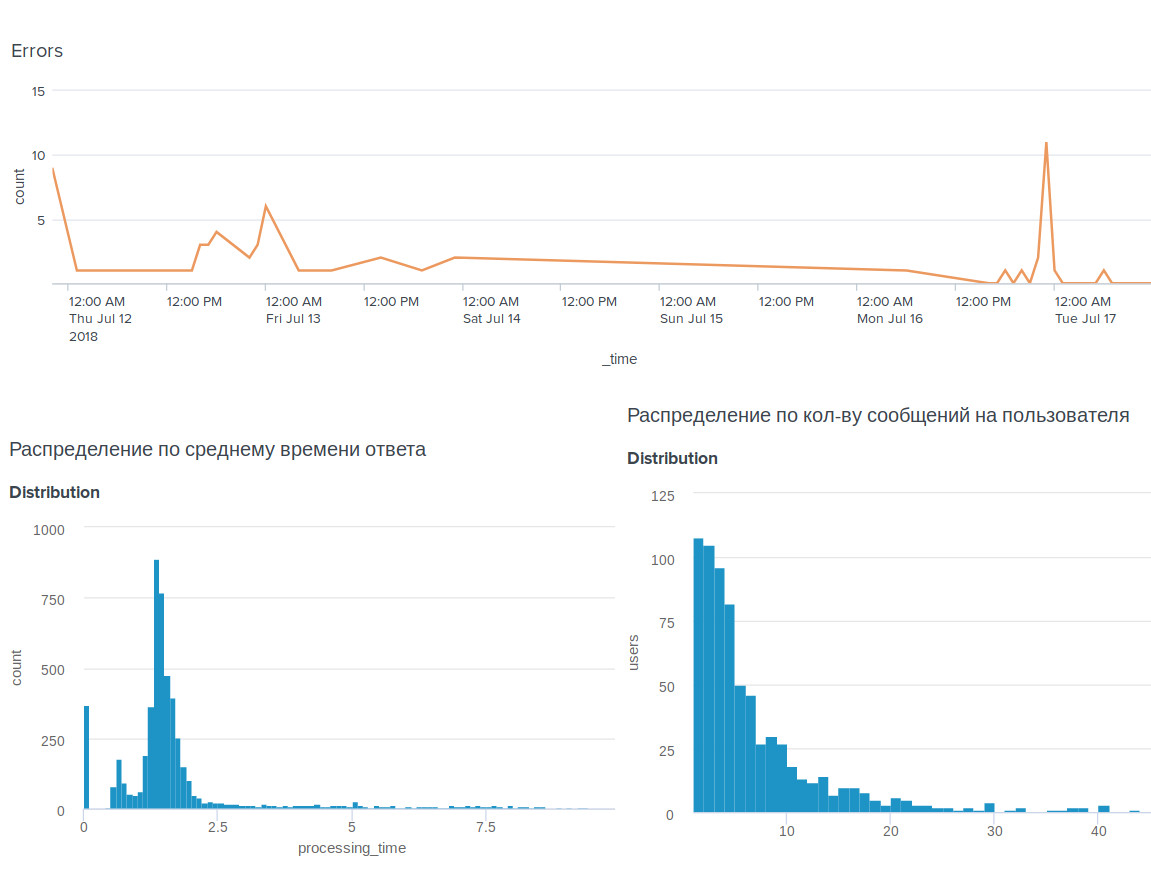
, . , .
, . , : @OkkoFaceBot .