تم تطوير نظرية التشفير التلقائي ونماذج التوليد بشكل جدي في الآونة الأخيرة ، ولكن تم تخصيص عدد قليل من الأعمال لكيفية استخدامها في مشاكل التعرف. في الوقت نفسه ، فإن خاصية أجهزة الترميز التلقائي للحصول على نموذج بيانات معلمي مخفي وعواقب رياضية من هذا تجعل من الممكن ربطها بأساليب صنع القرار بايزي.
تقترح المقالة جهازًا رياضيًا أصليًا "مجموعة من برامج التشفير التلقائي مع مساحة كامنة مشتركة" ، والتي تسمح لك باستخراج مفاهيم مجردة من بيانات الإدخال وتوضح القدرة على "التعلم بلقطة واحدة". بالإضافة إلى ذلك ، يمكن استخدامه للتغلب على العديد من المشاكل الأساسية لخوارزميات التعلم الآلي الحديثة القائمة على الشبكات متعددة الطبقات ونهج "التعلم العميق".
الخلفية
الشبكات العصبية الاصطناعية ، المدربة باستخدام آلية الانتشار الخلفي للأخطاء ، كادت تحل محل النهج الأخرى في العديد من مشاكل الاعتراف وتقدير المعلمات. لكن لديهم عدد من العوائق ، والتي ، على ما يبدو ، لا يمكن القضاء عليها دون مراجعة جادة للنهج:
- عدم الاستقرار الشديد لإدخال البيانات غير موجودة في عينة التدريب (بما في ذلك في حالة الهجمات العدائية)
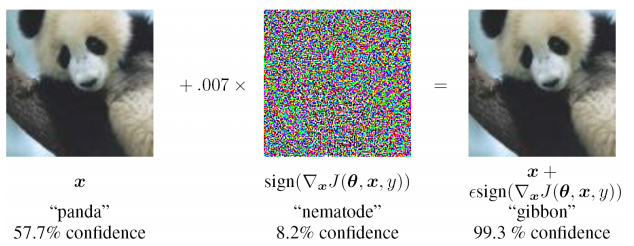
- من الصعب تقييم مصدر المشكلة وإعادة التدريب محليًا على أحد المستويات (عليك فقط استكمال عينة التدريب وإعادة التدريب) ، أي مشكلة الصندوق الأسود
- لا يتم توفير إمكانية تفسيرات مختلفة لنفس معلومات الإدخال ، يتم تجاهل الطبيعة الإحصائية للبيانات المرصودة

من خلال المشاركة في حل المشكلات التطبيقية ، والاعتماد على عدد من الأعمال الحالية ، أقترح نهجًا مختلفًا بشكل ملحوظ عن تلك الموجودة ، ويزيل عددًا من أوجه القصور فيها ويسري على حل المشكلات التطبيقية في مختلف مجالات التعلم الآلي.
التشفير التلقائي لتقدير كثافة التوزيع
في نظرية صنع القرار ، تحتل مكانة مهمة جدًا كثافة التوزيع (أو دالة التوزيع) للمتغيرات العشوائية. من الضروري الحصول على تقديرات لوظائف التوزيع لحساب المخاطر الخلفية.
اتضح أن الترميز التلقائي طبيعي جدًا لتقييم وظائف التوزيع. يمكن تفسير ذلك على النحو التالي: يتم تحديد مجموعة بيانات التدريب من خلال كثافة توزيعها. كلما زادت كثافة أمثلة التدريب حول نقطة محلية في مساحة الإدخال ، كلما كان برنامج التشفير التلقائي يعيد بناء ناقل الإدخال في هذا الموقع في الفضاء بشكل أفضل. بالإضافة إلى ذلك ، يوجد داخل جهاز الترميز التلقائي ناقل للتمثيل الكامن لبيانات الإدخال (عادةً ذات أبعاد منخفضة) ، وإذا تم عرض البيانات في مساحة كامنة في منطقة لم يتم استخدامها سابقًا في التدريب ، فلا يوجد شيء مماثل في عينة التدريب.
هناك عدد من الأعمال المغلقة والمعزولة إلى حد ما:
- Alain، G. and Bengio، Y. ما يتعلمه المبرمجون التلقائيون المنتظمون من توزيع توليد البيانات. 2013.
- Kamyshanska ، H. 2013. على تسجيل تلقائي
- دانيال جيونج ايم ، محمد اسماعيل بلغازي ، رولان ميميسيفيتش. 2016. المحافظة على الترميز التلقائي غير المقيدة
يبرر الأول أن نتيجة إعادة التشويش على التشفير التلقائي مرتبطة بوظيفة كثافة الاحتمال لبيانات الإدخال ، ولكن يتم فرض عدد من القيود على الترميز التلقائي. يحتوي الثاني على متطلبات كافية للتشفير التلقائي - يجب أن تكون أوزان التشفير وفك الشفرة "متصلة" ، أي مصفوفة الوزن لطبقة التشفير هي مصفوفة محول الشفرة المنقولة. في العمل الأخير ، تم التحقق من الشروط الضرورية والكافية لحقيقة أن المشفر التلقائي مرتبط بكثافة الاحتمال بشكل كامل.
هذه الأعمال تثبت بدقة الأساس النظري لعلاقة الترميز الآلي بكثافة توزيع بيانات التدريب. في المشكلات التطبيقية ، غالبًا ما لا يكون هذا التحليل الجاد مطلوبًا ، وبالتالي ، سيتم إعطاء نهج مختلف قليلاً أدناه والذي سيسمح لنا بتقدير دالة كثافة الاحتمال لبيانات الإدخال بسبب جهاز ترميز تلقائي مدرب مسبقًا.
مثال MNIST
في الأعمال السابقة ، تم اقتراح الفكرة التجريبية أنه بالنسبة لمشكلة التصنيف ، من الممكن تدريب برامج التشفير التلقائي حسب عدد الفصول (تعليم كل واحد منهم فقط على العينة الفرعية المقابلة). واختر كإجابة لتلك الفئة والترميز التلقائي التي تعطي الحد الأدنى من التناقض بين صورة الإدخال والصورة المعاد بناؤها. لم يكن من الصعب التحقق من MNIST: تدريب 10 مشفرات تلقائية (لكل رقم) ، وحساب الدقة ، ثم مقارنتها بنموذج متعدد الطبقات مشابه من المصنف.
نصوص للتدريب والاختبار على git (train_ae.py ، calc_codes.py ، calc_acc.py)
العمارة وعدد الأوزان:
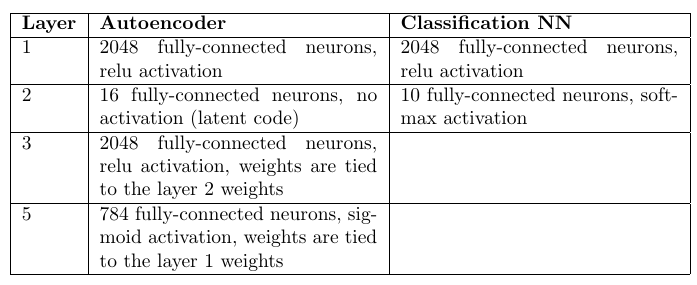
ترميز السيارات: 98.6٪
مصنف متعدد الطبقات: 98.4٪
سيلاحظ القارئ اليقظ أنه كان هناك 10 أضعاف الأوزان في أجهزة التشفير التلقائي (حسب عددها). ومع ذلك ، فإن زيادة 10 أضعاف في عدد الأوزان في الطبقة المخفية في طبقة متعددة الطبقات تؤدي إلى تفاقم الإحصائيات فقط.
بالطبع ، توفر شبكات الالتفاف دقة أعلى بكثير ، لكن المهمة كانت فقط لمقارنة المقاربات ، وكل الأشياء الأخرى متساوية.
ونتيجة لذلك ، يمكن ملاحظة أن النهج مع برامج الترميز التلقائي تنافسية تمامًا مع الشبكات المتصلة بالكامل. وعلى الرغم من أن تحسين الأوزان يستغرق وقتًا أطول ، إلا أنه يتمتع بميزة واحدة مهمة: القدرة على اكتشاف الحالات الشاذة في بيانات الإدخال. إذا لم يكن أي من برامج الترميز التلقائي قادرًا على إعادة بناء صورة الإدخال بدقة ، فيمكننا أن نذكر أن الصورة الشاذة التي لم تحدث في عينة التدريب كانت الإدخال. بالمعنى الدقيق للكلمة ، يمكنك إعادة بناء صورة ليس من عينة الإدخال ، ولكن سيتم عرض ما يجب فعله في هذه الحالة لاحقًا.
خذ بعين الاعتبار ترميز تلقائي واحد
من الممكن بطريقة مختلفة قليلاً عن الأوراق المذكورة أعلاه إجراء تحليل نوعي للعلاقة بين كثافة الاحتمال لبيانات الإدخال p (x) واستجابة الترميز التلقائي.
التشفير التلقائي - الاستخدام المتسلسل لوظيفة التشفير
ض = ز ( خ ) وفك الشفرة
س ∗ = و ( ض ) أين
س هو ناقل الإدخال ، و
ض - الأداء الكامن. في مجموعة فرعية من المدخلات (عادة ما تكون قريبة من التدريب)
س ∗ = س + ن = و ( ز ( س ) ) أين
ن - التناقض. نحن نقبل التناقض بسبب ضوضاء Gausovsky (يمكن تقدير معلماته بعد تدريب جهاز الترميز التلقائي). ونتيجة لذلك ، تم وضع عدد من الافتراضات القوية إلى حد ما:
1) التناقض - الضوضاء الغوسية
2) برنامج التشفير التلقائي "مدرب" ويعمل بالفعل
ولكن ، والأهم من ذلك ، لن يتم فرض أي قيود تقريبًا على برنامج الترميز التلقائي نفسه.
علاوة على ذلك ، يمكن الحصول على تقدير نوعي لكثافة الاحتمالية p (x) ، والتي يمكن على أساسها إجراء عدة استنتاجات مهمة جدًا في المستقبل.
النتيجة P (x) لمشفّر تلقائي واحد
كثافة التوزيع لـ
س ف ي X و
z ف ي Z المتعلقة على النحو التالي:
p ( x ) = i n t z p ( x | z ) p ( z ) d z \ ؛ \ ؛ \ ؛ ( 1 )
نحن بحاجة للحصول على الاتصال p (x) و p (z). بالنسبة لبعض برامج التشفير التلقائية ، يتم تعيين p (z) في مرحلة تدريبهم ؛ وبالنسبة للآخرين ، لا يزال الحصول على p (z) أسهل بسبب البعد الأصغر Z.
توزيع الكثافة للعدد المتبقي معروف وهو ما يعني:
p(n)=const timesexp(− frac(xf(z))T(xf(z))2 sigma2)=p(x|z)\؛\؛(2)
(x−f(z))T(x−f(z)) هي المسافة بين x وإسقاطها x *. عند نقطة معينة z * ستصل هذه المسافة إلى الحد الأدنى. عند هذه النقطة ، المشتقات الجزئية لحجة الأس في الصيغة (2) فيما يتعلق
zi (المحور Z) سيكون صفرًا:
0= frac جزئيf(z∗) جزئيziT(xf(z∗))+(xf(z∗))T frac جزئيf(z∗) جزئيzi
هنا
frac جزئيf(z∗) جزئيziT(x−f(z∗)) ثم العددية:
0= frac جزئيf(z∗) جزئيziT(x−f(z∗))\؛\؛\؛(3)
اختيار النقطة z * حيث المسافة
(x−f(z))T(x−f(z)) الحد الأدنى بسبب عملية التحسين من التشفير التلقائي. أثناء التدريب ، يتم تقليل المتبقي التربيعي (كقاعدة):
min limits theta، forallx inXtrainL2norm(x−f theta(g theta(x))) أين
theta - وزن المشفر. على سبيل المثال بعد التدريب g (x) يميل إلى z *.
يمكننا أيضًا التوسع
f(z) في سلسلة تايلور (حتى الحد الأول) حول ض *:
f(z)=f(z∗)+ nablaf(z∗)(z−z∗)+o((z−z∗))
لذا ، أصبحت المعادلة (2) الآن:
p(x|z) constثابت مراتexp(− frac((xf(z∗))− nablaf(z∗)(zz∗))T((xf(z∗))− nablaf(z∗)(zz∗))2 sigma2)=
=const timesexp(− frac(xf(z∗))T(xf(z∗))2 sigma2)exp(− frac( nablaf(z∗)(zz∗))T( nablaf(z∗)(zz∗))2 sigma2) times
timesexp(− frac( nablaf(z∗))T(xf(z∗))+(xf(z∗))T nablaf(z∗))(zz∗)2 sigma2)
لاحظ أن العامل الأخير هو 1 بسبب التعبير (3). يمكن إزالة العامل الأول بعلامة التكامل (لا يحتوي على z) في (1). وافترض أيضًا أن p (z) هي دالة سلسة بما فيه الكفاية ولا تتغير كثيرًا في حي z * ، أي استبدل p (z) -> p (z *).
بعد كل الافتراضات ، يحتوي التكامل (1) على التقدير:
p(x)=const timesp(z∗)exp(− frac(xf(z∗))T(xf(z∗))2 sigma2) intzexp(−(zz∗)TW(x)TW(x)(zz∗))dz،\؛\؛\؛z∗=g(x)
أين
W(x)= frac nablaf(z∗) sigma،z∗=g(x)التكامل الأخير هو تكامل Euler-Poisson الابعاد:
intzexp(− frac(zz∗)TW(x)TW(x)(zz∗)2)dz= sqrt frac1det(W(x)TW(x)/2 pi)
ونتيجة لذلك ، حصلنا على التقدير النهائي ص (س):
p(x)=const timesexp(− frac(xf(z∗∗))T(xf(z∗))2 sigma2)p(z∗) sqrt frac1det(W(x)TW(x)/2 pi)،z∗=g(x)\؛\؛\؛(4)
كل هذه الرياضيات كانت ضرورية لإظهار أن p (x) يعتمد على ثلاثة عوامل:
- المسافة بين متجه الإدخال وإعادة بنائه ، وكلما كان ترميمه أسوأ ، كلما كانت أصغر p (x)
- كثافات الاحتمال p (z *) عند z * = g (x)
- تطبيع الوظيفة p (z) عند النقطة z * ، والتي يتم حسابها للمشفِّر التلقائي من المشتقات الجزئية للدالة f
ومن ثابت التطبيع ، والذي سيكون مسؤولًا لاحقًا عن احتمال مسبق لاختيار مشفر تلقائي لوصف بيانات الإدخال.
على الرغم من كل الافتراضات ، كانت النتيجة ذات مغزى ومفيدة للغاية من وجهة نظر الحسابات.
تصنيف المعلمات أو إجراءات التصنيف
يمكنك الآن وصف إجراء التصنيف بدقة أكبر باستخدام مجموعة من برامج الترميز التلقائية:
- تدريب مشفرات السيارات المستقلة لكل فئة على الإخراج المطابق
- حساب المصفوفة W لكل جهاز ترميز آلي
- نقاط P (z) لكل مشفر تلقائي
ولكل متجه إدخال يمكنك تقييمه الآن
p(x|class) بعدد الصفوف. وستكون هذه هي وظيفة الاحتمالية اللازمة لاتخاذ القرار في إطار قاعدة بايزي لصنع القرار.
بنفس الطريقة ، يمكن أيضًا تقدير المعلمات غير المعروفة عن طريق تقسيم مساحة المعلمة إلى قيم منفصلة ، من خلال تدريب برنامج التشفير التلقائي الخاص بك لكل قيمة. وبعد ذلك ، استنادًا إلى أفضل نتيجة بايزية ، اختر القيمة التي توفر أقصى دالة احتمالية.
هنا تجدر الإشارة إلى أن مشكلة تقدير p (z) ، بشكل رسمي ، ليست أبسط من تقدير p (x). لكن في الواقع ليس الأمر كذلك. عادةً ما يكون للمسافة Z مسافة أصغر بكثير ، أو يتم تعيين التوزيع بشكل عام عند تحسين أوزان المشفر التلقائي.
فكرة الجمع بين الفضاء الكامن للمشفرات التلقائية
هناك تفسير غريب اقترحه أليكسي ريدوزوبوف ووصفه في المقالات التالية:
- بنية شبكة عصبية اصطناعية تعتمد على تحولات السياق في الأعمدة المصغرة القشرية. فاسيلي مورزاكوف ، أليكسي ريدوزوبوف
- الذاكرة الثلاثية الأبعاد: نموذج جديد لمعالجة المعلومات بواسطة الدوائر الدقيقة العصبية. أليكسي ريدوزوبوف ، سبرينغر
- لا الشبكات العصبية على الإطلاق. مورزاكوف ف.
يمكن أن يكون للمعلومات تفسير مختلف تمامًا في سياقات مختلفة. يردد نموذج "مجموعة من مشفرات السيارات" هذه الفكرة المقترحة. أي برنامج تشفير تلقائي هو نموذج كامن لبيانات الإدخال في نفس السياق (فئة واحدة أو معلمات ثابتة أخرى) ، أي المتجه الكامن هو تفسير ، وكل مشفر آلي هو سياق. عند استلام معلومات الإدخال ، يتم أخذها في الاعتبار في كل سياق (بواسطة كل مشفر تلقائي) ، ويتم تحديد السياق الذي من المرجح أن يأخذ في الاعتبار النماذج الموجودة في كل مشفر تلقائي.
الخطوة المعقولة التالية هي السماح بتقاطع التفسيرات في سياقات مختلفة. على سبيل المثال أثناء التدريب ، نعلم غالبًا أن التفسير يظل كما هو ، ولكن شكل العرض (السياق) يتغير. على سبيل المثال ، يتغير اتجاه كائن ، ولكن يبقى الكائن كما هو. يجب الحفاظ على متجه وصف الكائن ، وتغيير اتجاه السياق.
بعد ذلك ، إذا ألقينا نظرة على الصيغة (4) ، يتبين أن العامل p (z) يتم تقديره لمجموعة كاملة من برامج التشفير التلقائي ، وليس لكل منها على حدة. سيكون للتوزيع (ناقل كامن) توزيع مشترك. بالنسبة لعدد قليل من برامج الترميز التلقائية ، قد لا يكون لهذا دور مهم ، ولكن في مهمة حقيقية يمكن أن يكون هذا الرقم ضخمًا. على سبيل المثال ، إذا قمت بتحديد سياق واحد لكل اتجاه محتمل لكائن ثلاثي الأبعاد ، فقد يكون هناك مئات الآلاف منهم. الآن ، كل مثال مقدم للتدريب في أي سياق سيشكل توزيع p (z).
قابلية التبادل للتفسير والسياق
في المشكلة التطبيقية ، يطرح السؤال على الفور: ماذا يتم تعيينه عن طريق التفسير ، وماذا حسب السياق؟ يمكن بسهولة تبديل السياق والتفسير ، ولا يستبعد أحد إمكانية الأداء المتوازي المتزامن لزوج من "مجموعات من أجهزة الترميز التلقائي".
للتوضيح ، يمكنك تقديم هذا المثال:
تحتوي صورة الإدخال على وجوه الأشخاص.
- السياق - اتجاه الوجه. ثم ، لإعادة بناء الصورة المدخلة ، ليس لدينا ما يكفي من "التفسير" - رمز يحدد الشخص ، والذي سيحتوي على وصف للوجه وتصفيفة الشعر وإضاءة. أثناء التدريب ، سنحتاج إلى تقديم نفس الوجه من جوانب مختلفة ، "تجميد" الرمز الكامن ، مع تغيير الاتجاه.
- السياق - نوع الوجه والإضاءة وتصفيفة الشعر. ثم ، لإعادة بناء الصورة المدخلة ، نفتقر إلى اتجاه الوجه. أثناء التدريب ، سيكون من الضروري إظهار وجوه مختلفة في ظروف إضاءة مختلفة ، ولكن بنفس الاتجاه.
يتم اتخاذ قرار بايزي الأمثل في الحالة الأولى فيما يتعلق بتوجيه الوجه ، وفي الحالة الثانية - نوعه. من المفترض أن الخيار الأول سيعطي دقة أفضل في التوجيه ، والثاني سيقيم بدقة وجهه.
تعلم مجموعة من برامج الترميز التلقائية مع مساحة كامنة مشتركة
في التدريب ، نحتاج إلى معرفة كيف يبدو كيان واحد من حيث المعنى في سياقات مختلفة. على سبيل المثال ، إذا تحدثنا عن صورة الأرقام واتجاه السياق ، فإن هذا التدريب التبادلي يبدو تخطيطيًا كما يلي:

يتم استخدام برنامج تشفير أحد برامج التشفير التلقائي ، ثم يتم فك الشفرة الكامنة بواسطة وحدة فك ترميز جهاز تشفير تلقائي آخر. تبقى وظيفة فقدان التعلم قياسية. من المثير للاهتمام أنه إذا تم اختيار برنامج التشفير التلقائي بشكل متناظر (على سبيل المثال ، تم ربط أوزان جهاز التشفير وفك التشفير) ، فسيتم تحسين كل أوزان برامج التشفير التلقائي في كل تكرار.
كان PyTorch هو الأكثر ملاءمة لمثل هذا التدريب الصعب ، والذي يسمح لك بعمل مخططات معقدة إلى حد ما للانتشار الخلفي للأخطاء ، بما في ذلك تلك الديناميكية.
تتبدل خطوات التعلم القياسية لكل مشفر تلقائي مع تكرار التدريب المتقاطع. ونتيجة لذلك ، فإن جميع برامج التشفير التلقائية لها مساحة كامنة مشتركة أو "تفسير" في سياقات مختلفة.
من المهم جدًا أنه نتيجة لهذا التحليل سنكون قادرين على تقسيم معلومات الإدخال إلى "سياق" و "تفسير".
مثال تدريبي
ضع في اعتبارك مثالًا بسيطًا إلى حد ما يعتمد على MNIST ، والذي سيساعد على توضيح مبدأ تدريب أجهزة الترميز التلقائي مع مساحة كامنة مشتركة. ونتيجة لذلك ، سيوضح هذا المثال تشكيل المفهوم المجرد لـ "المكعب" باستخدام الآلية الموضحة في المقالة.
يتم رسم الأرقام من MNIST على حافة المكعب وتدور حول أحد محاورها:
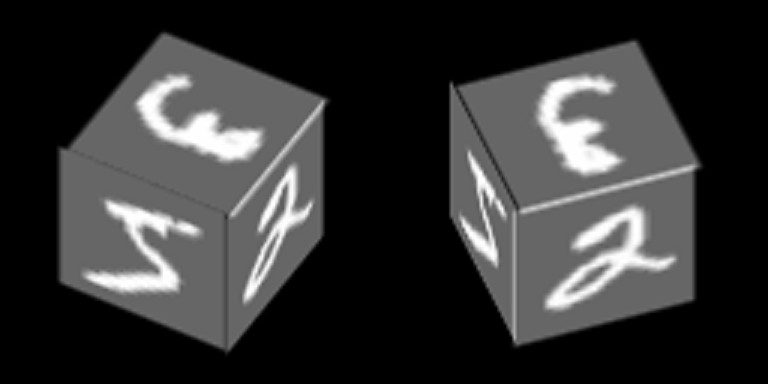
سنقوم بتدريب برامج الترميز التلقائي على استعادة الوجوه ، السياق - اتجاه الوجه.
في ما يلي مثال على الرقم "صفر" في 100 سياق ، أول 34 منها تتوافق مع زوايا مختلفة لتدوير الوجه الجانبي ، والباقي 76 - زوايا دوران مختلفة للجانب العلوي.

نفترض أنه لكل واحدة من هذه الصور المائة يجب أن تكون "التفسيرات" هي نفسها ، وهي مجموعاتها العشوائية التي يتم استخدامها للتدريب المتبادل.
بعد التدريب باستخدام الطريقة الموضحة أعلاه ، كان من الممكن تحقيق أنه يمكن فك الشفرة الكامنة لأحد برامج الترميز التلقائي بواسطة أجهزة ترميز تلقائية أخرى ، للحصول على تحويل سياقي ذي مغزى حقيقي.
على سبيل المثال ، توضح هذه الصورة كيف يتم فك ترميز نتيجة التشفير التلقائي في الرقم 10 بواسطة برامج تشفير آلية أخرى لأحد الأرقام:
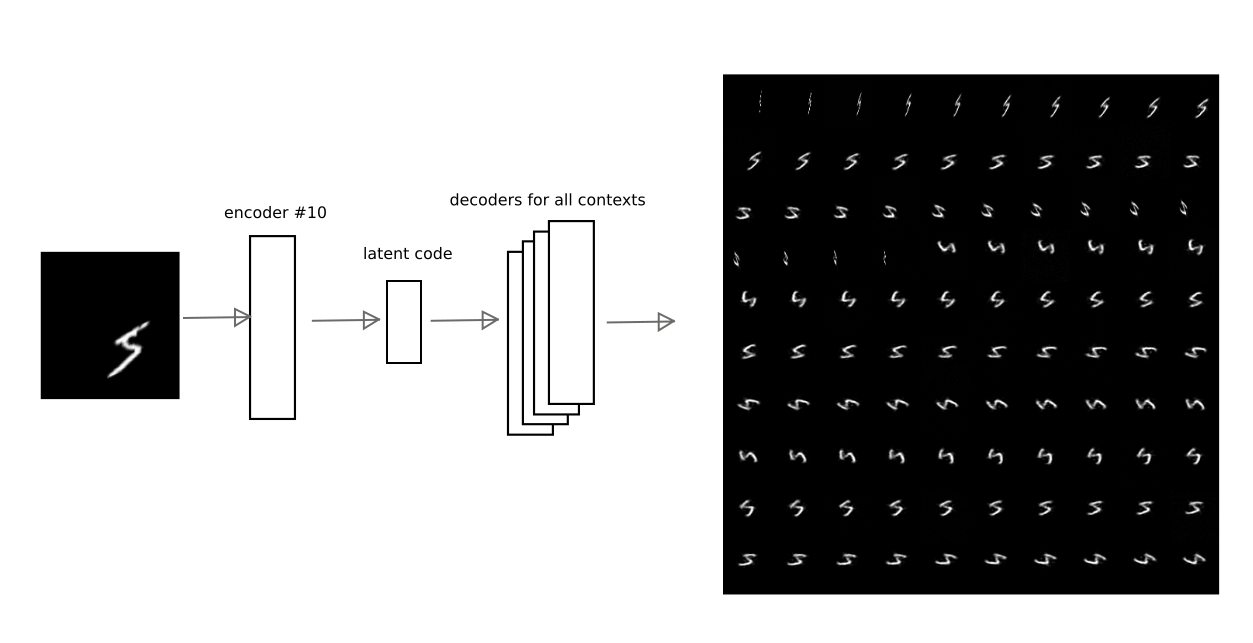
وبالتالي ، الحصول على رمز "التفسير" ، أي ناقل كامن لبرنامج التشفير التلقائي ، يمكنك استعادة الصورة الأصلية في أي من السياقات المدربة (أي وحدة فك التشفير لأي برنامج تشفير تلقائي).
إخفاء إخفاء متجه الإدخال
في الصيغة (4) ، تشتت المتبقي
سيجما ، الذي يتم اختياره بواسطة ثابت لأي من مكونات متجه الإدخال. ومع ذلك ، إذا لم يكن لبعض المكونات أي علاقة إحصائية بالنموذج الكامن ، فمن المحتمل أن يكون التباين أعلى بشكل ملحوظ لهذه المكونات. يوجد التشتت في كل مكان في المقام ، مما يعني أنه كلما كان التباين أكبر ، قل مساهمة خطأ المكون. يمكنك ربط هذا كإخفاء جزء من متجه الإدخال.
بالنسبة لهذا المثال مع الوجوه الدوارة ، يكون القناع واضحًا - إسقاط الوجه في سياق معين.

في النهج المبسط في هذا المثال ، الذي يستخدم فقط المتبقي بين صورة الإدخال وإعادة البناء ، ما عليك سوى مضاعفة المتبقي في القناع لكل من السياقات.
في الحالة العامة ، من الضروري إجراء تقييم أكثر دقة لمعلمات التوزيع ، وبالتالي دون إدخال القناع يدويًا.
فصل التفسير عن السياق
بفصل التفسير عن السياق ، يمكنك الحصول على مفاهيم مجردة. في المثال المدرب ، من المثير للاهتمام إظهار تأثيرين:
1) التعلم بلقطة واحدة ، أي التدريب مع عدد قليل للغاية من الأمثلة (في حد واحد).
إذا قمنا بتحليل التفسير فقط ، متجاهلين السياق ، يصبح من الممكن التعرف على صورة جديدة في اتجاهات وجه مختلفة ، عندما تم عرض صورة جديدة في اتجاه واحد فقط.
من المهم ملاحظة أنه يجب تقديم صورة جديدة. من أجل الصواب ، وضعنا لأنفسنا أيضًا الهدف المتمثل في تذكر ليس صورة واحدة ، ولكن تعلم كيفية مشاركة صورتين جديدتين لم يتم العثور عليهما سابقًا في قاعدة تدريب MNIST. على سبيل المثال ، مثل:
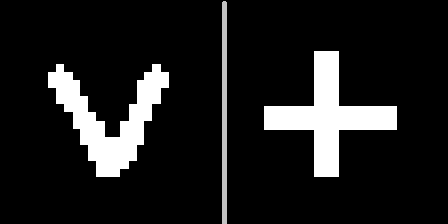 الفكرة هي كما يلي: إظهار هذه العلامات في أحد السياقات الهندسية (على سبيل المثال ، تحت الرقم 10) ، حدد الطائرة الزائدة التي تعمل على مسافة متساوية من تفسيرات هذه العلامات ، ثم تأكد من أنه مع هذه الطائرة الزائدة يمكننا التعرف على نوع العلامة التي يتم تقديمها لنا عند تدوير الوجه (سياقات أخرى).من المهم ملاحظة أنه لن يتم تدريب برامج التشفير التلقائية على الإشارات الجديدة. نظرًا لتنوع الأرقام الموجودة في MNIST ، يمكنك توقع كيف ستبدو شخصية جديدة لم تتم رؤيتها من قبل في سياقات مختلفة.لذا ستعتني علامة V بالتشفير في سياق الرقم 10 وفك التشفير في الباقي:
الفكرة هي كما يلي: إظهار هذه العلامات في أحد السياقات الهندسية (على سبيل المثال ، تحت الرقم 10) ، حدد الطائرة الزائدة التي تعمل على مسافة متساوية من تفسيرات هذه العلامات ، ثم تأكد من أنه مع هذه الطائرة الزائدة يمكننا التعرف على نوع العلامة التي يتم تقديمها لنا عند تدوير الوجه (سياقات أخرى).من المهم ملاحظة أنه لن يتم تدريب برامج التشفير التلقائية على الإشارات الجديدة. نظرًا لتنوع الأرقام الموجودة في MNIST ، يمكنك توقع كيف ستبدو شخصية جديدة لم تتم رؤيتها من قبل في سياقات مختلفة.لذا ستعتني علامة V بالتشفير في سياق الرقم 10 وفك التشفير في الباقي: يمكن ملاحظة أن التنبؤ ليس مثاليًا ، ولكن يمكن التعرف عليه بصريًا.نشير إلى هذا العرض التوضيحي على أنه "تجربة 1" ووصف النتيجة أدناه.2) ومع المكعب ، من المثير للاهتمام توضيح ما سيحدث إذا تجاهلت محتويات المتجه الكامن ، ويتم نقل درجة معقولية كل مشفر تلقائي فقط.دعونا نرى كيف يبدو الاحتمال لكل من السياقات لمكعبين مع مواد مختلفة تمامًا (الرقمان 5 و 9) لـ 100 سياق يمكن عرضها كخريطة:
يمكن ملاحظة أن التنبؤ ليس مثاليًا ، ولكن يمكن التعرف عليه بصريًا.نشير إلى هذا العرض التوضيحي على أنه "تجربة 1" ووصف النتيجة أدناه.2) ومع المكعب ، من المثير للاهتمام توضيح ما سيحدث إذا تجاهلت محتويات المتجه الكامن ، ويتم نقل درجة معقولية كل مشفر تلقائي فقط.دعونا نرى كيف يبدو الاحتمال لكل من السياقات لمكعبين مع مواد مختلفة تمامًا (الرقمان 5 و 9) لـ 100 سياق يمكن عرضها كخريطة: يمكن ملاحظة أن الخرائط متشابهة تمامًا ، على الرغم من النسيج المختلف على جانبي المكعب.
يمكن ملاحظة أن الخرائط متشابهة تمامًا ، على الرغم من النسيج المختلف على جانبي المكعب.على سبيل المثال
يسمح لنا المتجه نفسه ، الذي يحتوي على احتمالية نماذج الترميز التلقائي (السياقات) ، بصياغة مفهوم تجريدي جديد يتعلق بالشكل ثلاثي الأبعاد للمكعب. يمكن أيضًا وصف هذا المتجه في المستوى التالي من خلال برنامج ترميز تلقائي يتعلم نموذج المكعب.في التجربة الثانية ، سيكون من الضروري إنشاء مستوى ثان من معالجة المعلومات لتدريب المشفر التلقائي لنموذج المكعب المجرد. ثم استخدام الإسقاط الخلفي لاستعادة الصورة الأصلية لعمليات التنفيذ المختلفة لنموذج هذا المكعب. ببساطة ، اجعل المكعب يدور.نتيجة "التجربة رقم 1"
تنطبق مجموعة برامج الترميز التلقائية التي تدرب عليها MNIST على صورتين جديدتين مقدمتين في السياق رقم 10. تبين نقطتين في الفضاء الكامن المقابل لعلامات V و +. نحدد مسافة متساوية من كلتا النقطتين ، والتي سنستخدمها لاتخاذ قرار. إذا كانت النقطة على جانب واحد من الطائرة - علامة V ، على الجانب الآخر - علامة زائد.الآن نحصل على رموز الصور المحولة ولكل منها نحسب المسافة إلى المستوى ، مع الحفاظ على العلامة.ونتيجة لذلك ، من الممكن التمييز بين نوع العلامة التي تم تقديمها لجميع السياقات المائة.توزيع المسافة على الرسم البياني: تصور النتيجة باستخدام الرموز الفردية كمثال:
تصور النتيجة باستخدام الرموز الفردية كمثال:
على سبيل المثال
تكون الرموز الكامنة لإشارات V في سياقات مختلفة تمامًا أقرب إلى بعضها البعض في الفضاء الكامن من رموز V والإشارات الزائدة في نفس السياق. ونتيجة لذلك ، في 100 حالة من أصل 100 حالة ، من الممكن التمييز بنجاح بين العلامات في اتجاهات مختلفة لوجوه المكعب ، على الرغم من حقيقة أنه تم تقديم عينة واحدة فقط من كل علامة.كان من الممكن إظهار "التعلم بلقطة واحدة" الكلاسيكي ، وهو أمر مستحيل في الهندسة المعمارية الأصلية للشبكات العصبية الاصطناعية. يشبه المبدأ الأساسي الذي يعمل من خلاله هذا النهج إلى حد كبير "التعلم الانتقالي" الموضح ، على سبيل المثال ، في هذه المقالة .رابط إلى git (train_ae_shared.py ، test_AB.py)نتيجة "التجربة رقم 2"
يسمح فصل التفسيرات عن السياق أيضًا بالتعلم من مجموعة محدودة من الأمثلة. من الممكن إظهار واحد فقط من التفسيرات المحتملة في سياقات مختلفة (تحديد "ناقل كامن"). يمكن الحصول على نموذج مكعب مجردة من خلال إظهار رقم واحد فقط على جميع الوجوه.التجربة مبنية على النحو التالي:- يتم إعداد قاعدة تدريب: مكعبات بدرجة دوران من 0 إلى 90 درجة. على وجوه المكعبات هو الرقم 5.
- يتم تمرير متجه احتمالية السياقات ، المنفصلة عن التفسير (الرمز الكامن) ، إلى المستوى التالي ، حيث يتم تدريب المشفر التلقائي المسؤول عن نموذج المكعب
- : , «», , , , , .
تكونت عينة التدريب من 5421 صورة مع صورة الرقم 5 على الجانبين ، على سبيل المثال: مكعبات مع دوران من 0 إلى 90 درجةونحن نعلم مقدمًا أن المكعب لديه درجة واحدة فقط من حرية الدوران ، وبالتالي فإن التشفير التلقائي في المستوى الثاني يحتوي على مكون واحد فقط في الرمز الكامن. بعد التدريب ، يمكنك تغيير هذا المكون من 0 إلى 1 (تم تحديد وظيفة السيني لتنشيط الطبقة الكامنة) ومعرفة متجه احتمالية السياق الذي يتم إعادة إنتاجه أثناء فك التشفير:
مكعبات مع دوران من 0 إلى 90 درجةونحن نعلم مقدمًا أن المكعب لديه درجة واحدة فقط من حرية الدوران ، وبالتالي فإن التشفير التلقائي في المستوى الثاني يحتوي على مكون واحد فقط في الرمز الكامن. بعد التدريب ، يمكنك تغيير هذا المكون من 0 إلى 1 (تم تحديد وظيفة السيني لتنشيط الطبقة الكامنة) ومعرفة متجه احتمالية السياق الذي يتم إعادة إنتاجه أثناء فك التشفير: ثم يتم نقل هذا المتجه إلى المستوى 1 ، حيث 100 سياق اتجاه للوجوه ، والحد الأقصى المحلي و تخيلت "أي رمز كامن للإشارة على وجوه المكعب. "تخيل" الرقم 3 على الوجوه ، وتغيير المتجه الكامن في برنامج التشفير التلقائي المسؤول عن المفهوم المجرد للمكعب ، والحصول على الصورة التالية للمكعب:
ثم يتم نقل هذا المتجه إلى المستوى 1 ، حيث 100 سياق اتجاه للوجوه ، والحد الأقصى المحلي و تخيلت "أي رمز كامن للإشارة على وجوه المكعب. "تخيل" الرقم 3 على الوجوه ، وتغيير المتجه الكامن في برنامج التشفير التلقائي المسؤول عن المفهوم المجرد للمكعب ، والحصول على الصورة التالية للمكعب: أو رمز علامة V ، التي لم يتم العثور عليها على الإطلاق في مجموعة التدريب:
أو رمز علامة V ، التي لم يتم العثور عليها على الإطلاق في مجموعة التدريب: الجودة أسوأ ، ولكن يمكن التعرف على العلامة.وهكذا ، في المستوى الثاني من معالجة الصور ، حصلنا على جهاز تشفير تلقائي يميز مجموعة متنوعة من المفاهيم المجردة لـ "المكعب". من الناحية العملية ، في مشاكل التعرف ، فإن مبدأ الإسقاط الخلفي الموضح في التجربة مهم للغاية ، لأنه يسمح بالقضاء على الغموض في التفسير بسبب تكوين المفاهيم المجردة على مستوى أعلى.رابط إلى git (second_level.py، second_level_test.py)
الجودة أسوأ ، ولكن يمكن التعرف على العلامة.وهكذا ، في المستوى الثاني من معالجة الصور ، حصلنا على جهاز تشفير تلقائي يميز مجموعة متنوعة من المفاهيم المجردة لـ "المكعب". من الناحية العملية ، في مشاكل التعرف ، فإن مبدأ الإسقاط الخلفي الموضح في التجربة مهم للغاية ، لأنه يسمح بالقضاء على الغموض في التفسير بسبب تكوين المفاهيم المجردة على مستوى أعلى.رابط إلى git (second_level.py، second_level_test.py)أمثلة أخرى حيث يعمل فصل السياق
في مقالتي السابقة ، عند التعرف على أرقام السيارات ، تم استخدام طريقة مماثلة دون تفسير. تم فصل موضع واتجاه وحجم الأرقام في الصورة عن المحتويات ، وأدرك المستوى التالي هذه البيانات لبناء نموذج "رقم السيارة". بغض النظر عن الأرقام ، فإن تكوينها الهندسي المتبادل مهم ، بحيث يمكننا القول بثقة أن هذا رقم سيارة (بالمناسبة ، وهو أيضًا مفهوم مجردة).قياساً على ذلك ، يمكننا إعطاء عدد من الأمثلة الأخرى من رؤية الكمبيوتر: يمكن فصل الشكل ثلاثي الأبعاد للكائن أو معالمه عن نسيجه وخلفيته ؛ غالبًا ما يسمح تعداد المكونات بمعزل عن التكوين المكاني المتبادل بتشكيل مفهوم تجريدي جديد.من المثير للاهتمام أيضًا كيف يمكن أن يعمل هذا في مجالات أخرى من تعلم الآلة: إبراز لحن الأغنية هو أيضًا رفض للتفسير (أي حرف العلة واضح) واستخدام السياق فقط (الملعب) ؛ التراكيب النحوية (الزخرفة ، على سبيل المثال ، "قام شخص ما بشيء ما").مناقشة مشكلة الذكاء الاصطناعي القوي
في الوقت الحالي ، من الصعب صياغة كيف يختلف الذكاء الاصطناعي القوي عن الضعيف. من المحتمل أن تتضمن هذه القائمة كل ما ينقص المناهج والخوارزميات الحالية حتى تعمل أجهزة الكمبيوتر بكفاءة مثل الشخص ، على سبيل المثال:
- اتخاذ القرارات باستخدام الاستراتيجيات وحلها في مواجهة عدم اليقين. إن عدم اليقين المرتفع يتطلب اختيار أفضل النماذج المصاغة أثناء التدريب
- انعكاس نماذج العالم المادي والاجتماعي المحيط ، بما في ذلك الوعي الذاتي ووعي الآخرين
- آليات التفكير المجرد ، مما يسمح بصياغة المفاهيم التي يمكن استخدامها على مجموعة واسعة من البيانات المدخلة في وقت لاحق
- القدرة على "فك رموز" أفكارك الخاصة
أيضا ، من الواضح أنه لا توجد آليات ذاكرة متطورة بما فيه الكفاية متكاملة مع عملية التعلم وآليات الترقية / العقاب.
توضح المقالة مقاربة مشكلة التعرف على المعلمات وتقديرها ، والتي تستند إلى اختيار أفضل نموذج يصف بيانات الإدخال. من المفترض أن هذه هي آلية اختيار أفضل تفسير وسياق. نظرًا لفصل التفسير والسياق عند إخراج الوحدة (مجموعة من برامج التشفير التلقائي) ، يمكن للمرء صياغة مفاهيم مجردة أو تعميم الخبرة بمعزل عن السياق ، وبالتالي تقليل عينة التدريب. يمكن لمجموعة من السياقات أن تعكس قراءات مستشعرات الماكينة (التوجه ، الموقف ، السرعة ، إلخ.) ، التي يصبح التعلم الطبيعي بدون معلم ممكنًا.
بالإضافة إلى ذلك ، على الرغم من استخدام التعلم العميق في تدريب أجهزة الترميز التلقائي ، إلا أنه يمكن تحليل العمليات التي تحدث في أجهزة الترميز التلقائي بسهولة في كل مستوى من مستويات معالجة المعلومات ، لأن من الممكن تحديد أي نموذج (أو في أي سياق) تم العثور على أفضل تفسير. ومعنى التغذية المرتدة بين المستويات التي يجب إدخالها في النظم المعقدة هو زيادة أو تقليل احتمالية اختيار سياق معين.
النتيجة
تم اقتراح جهاز رياضي ، يمكن للمرء على أساسه اختيار نموذج أو آخر يصف بيانات الإدخال ، مسترشداً بقاعدة قرار بايزي. يتم الحصول على النماذج باستخدام أجهزة ترميز تلقائية ذات مساحة كامنة مشتركة. يتم اقتراح فكرة بموجبها يكون الرمز الكامن للتشفير التلقائي هو تفسير ، والنموذج الكامن ، أي برنامج الترميز التلقائي نفسه سياق.
لقد ثبت أن مجموعة برامج التشفير التلقائي ليست أقل دقة من الشبكات العصبية الاصطناعية المتصلة بالكامل باستخدام مثال MNIST.
يظهر تأثير فصل التفسير عن السياق: تقليل مجموعة البيانات الضرورية (في حد "التعلم بلقطة واحدة") للتعرف على الصور المقدمة حديثًا بسبب التدريب المسبق على البيانات الأخرى.
يظهر تأثير فصل السياق عن التفسير: إمكانية تشكيل مفاهيم مجردة للمستوى التالي باستخدام التجريد الهندسي "المكعب" كمثال.
المراجع
1)
Alain، G. and Bengio، Y. ما يتعلمه المبرمجون التلقائيون المنتظمون من توزيع توليد البيانات. 2013.2)
Kamyshanska ، H. 2013. على تسجيل تلقائي3)
دانيال جيونج ايم ، محمد اسماعيل بلغازي ، رولان ميميسيفيتش. 2016. المحافظة على الترميز التلقائي غير المقيدة4)
بنية شبكة عصبية اصطناعية تعتمد على تحولات السياق في الأعمدة المصغرة القشرية. فاسيلي مورزاكوف ، أليكسي ريدوزوبوف5) الذاكرة الثلاثية الأبعاد: نموذج جديد لمعالجة المعلومات بواسطة الدوائر الدقيقة العصبية. أليكسي ريدوزوبوف ، سبرينغر
6)
لا الشبكات العصبية على الإطلاق. مورزاكوف ف.7)
en.wikipedia.org/wiki/Gaussian_integral8)
أمثلة على الخصومة: الهجمات والدفاع عن التعلم العميق9)
التعلم التقليد طلقة واحدةملاحظة: هذه المقالة هي طبعة إلكترونية باللغة الروسية ، تم نشرها لمناقشة النتائج ، والبحث عن الأخطاء. نرحب بأي نقد بناء!