مقدمة
منذ بعض الوقت ، أصبحت مشاركًا في مشروع لتطوير منتج برمجي مصمم لتحليل سجلات المرضى والبيانات عن حالتهم الصحية القادمة من المنظمات الطبية من أجل إنشاء سجل طبي موحد. لفترة طويلة ، لم يتمكن الفريق من تطوير نهج للجمع بين بيانات المرضى. كانت نقطة البداية هي دراسة الرموز المصدرية لحل Open EMPI (Open Enterprise Master Patient Index) الذي دفعنا إلى خوارزميات تحليل التشابه المتسلسل . منذ تلك اللحظة ، بدأت دراسة أعمق للمواد ، مما جعل من الممكن إنشاء تخطيط أولاً ، ثم حل عملي.
حتى الآن ، في أنواع مختلفة من العروض التقديمية ، يجب على المرء أن يسمع الكثير من الأسئلة حول منطق عمل هذه المنتجات ، والتي استنتج منها أن مراجعة طرق ربط النص ستكون ذات فائدة لدائرة واسعة من القراء.
المواد عبارة عن ترجمة لمقالة ويكيبيديا " رابط التسجيل " مع حقوق النشر والإضافات.
ما هو ربط النص؟
يصف مصطلح " ربط السجلات" عملية إرفاق السجلات النصية من مصدر بيانات إلى سجلات من مصدر آخر ، بشرط أن تصف نفس الكائن. في علوم الكمبيوتر ، يسمى هذا "تعيين البيانات" أو "مشكلة هوية الكائن" . يتم استخدام التعريفات البديلة في بعض الأحيان ، مثل "تحديد" و "ملزم" و "كشف مكرر" و "إلغاء البيانات المكررة" و "مطابقة السجلات" و "تعريف الكائن" والتي تصف نفس المفهوم. وقد أدت هذه الوفرة الاصطلاحية إلى فصل نهج معالجة المعلومات وهيكلتها - ربط السجلات وربط البيانات . على الرغم من أنهما يحددان تحديد الكائنات المتطابقة من خلال مجموعات مختلفة من المعلمات ، يُستخدم مصطلح "ربط السجلات النصية" بشكل شائع عند الإشارة إلى "جوهر" الشخص ، بينما يعني "ربط البيانات" إمكانية ربط أي مورد ويب بين مجموعات البيانات ، باستخدام ، على التوالي ، المفهوم الأوسع للمعرف ، وهو معرف موارد منتظم (URI).
لماذا هذا مطلوب؟
عند تطوير منتجات برمجية لبناء أنظمة آلية مستخدمة في مجالات مختلفة تتعلق بمعالجة البيانات الشخصية للشخص (الرعاية الصحية ، والتاريخ ، والإحصاءات ، والتعليم ، وما إلى ذلك) ، تنشأ المهمة في تحديد البيانات حول مواضيع المحاسبة القادمة من مصادر مختلفة.
ومع ذلك ، عند جمع الأوصاف من عدد كبير من المصادر ، تنشأ مشاكل تجعل من الصعب تحديدها بشكل لا لبس فيه. تتضمن هذه المشاكل:
- الأخطاء المطبعية.
- تبديل المجال (على سبيل المثال ، في الاسم الأول) ؛
- استخدام الاختصارات والاختصارات ؛
- استخدام تنسيق مختلف للمعرفات (التواريخ وأرقام المستندات وما إلى ذلك).
- تشويه صوتي
- الخ.
تؤثر جودة البيانات الأولية بشكل مباشر على نتائج عملية الربط. بسبب هذه المشاكل ، غالبًا ما يتم نقل مجموعات البيانات إلى المعالجة ، والتي ، على الرغم من أنها تصف نفس الكائن ، تبدو مثل هذه السجلات تبدو مختلفة. لذلك ، من جهة ، يتم تقييم جميع معرفات السجلات المرسلة من أجل تطبيقها للاستخدام في عملية تحديد الهوية ، ومن ناحية أخرى ، يتم تطبيع السجلات نفسها أو توحيدها من أجل إحضارها إلى تنسيق واحد.
جولة تاريخية
تم تقديم الفكرة الأصلية لربط الملاحظات بواسطة Halbert L. Dunn ، الذي نشر مقالة بعنوان "Link Linkage" في المجلة الأمريكية للصحة العامة في عام 1946.
في وقت لاحق ، في عام 1959 ، في مقال حول الربط التلقائي للسجلات الحيوية في مجلة العلوم ، وضع Howard B. Newcombe الأسس الاحتمالية لنظرية ربط السلسلة الحديثة ، والتي تم تطويرها وتعزيزها في عام 1969 من قبل Ivan Fellegi و Alan سانتر (آلان سونتر). لا يزال عملهم "نظرية الربط القياسي" الأساس الرياضي للعديد من خوارزميات الربط.
كان التطور الرئيسي للخوارزميات في التسعينات من القرن الماضي. ثم ، من مناطق مختلفة (الإحصائيات والأرشفة وعلم الأوبئة والتاريخ وغيرها) ، جاءت إلينا الخوارزميات المستخدمة غالبًا في منتجات البرامج ، مثل مسافة Jaro-Winkler (المسافة) ومسافة Levenshtein ، ومع ذلك ، ظهرت بعض الحلول ، على سبيل المثال ، خوارزمية Soundex الصوتية ، في وقت مبكر جدًا - في عشرينيات القرن الماضي.
خوارزميات مقارنة إدخال النص
يُميّز بين الخوارزميات الحتمية والاحتمالية لمقارنة السجلات النصية. تعتمد الخوارزميات القطعية على مصادفة كاملة لسمات السجل. تتيح الخوارزميات الاحتمالية حساب درجة مطابقة سمات السجل ، وبناءً على ذلك ، تقرر إمكانية علاقتها.
الخوارزميات القطعية
تعتمد أسهل طريقة لمقارنة السلاسل على قواعد واضحة عند إنشاء روابط بين الكائنات بناءً على عدد التطابقات لسمات مجموعات البيانات. بمعنى ، يتطابق سجلان مع بعضهما البعض من خلال خوارزمية حتمية إذا كانت كل أو بعض سماتهما متطابقة. الخوارزميات الحتمية مناسبة لمقارنة الموضوعات الموصوفة بمجموعة من البيانات التي تم تحديدها بواسطة معرف مشترك (على سبيل المثال ، رقم التأمين لحساب شخصي فردي في صندوق المعاشات التقاعدية - SNILS) أو لديها العديد من المعرّفات التمثيلية (تاريخ الميلاد ، الجنس ، إلخ) التي يمكن الوثوق بها.
يمكن تطبيق الخوارزميات الحتمية عندما يتم نقل مجموعات بيانات منظمة (موحدة) بشكل واضح إلى المعالجة.
على سبيل المثال ، يحتوي على المجموعة التالية من إدخالات النص:
| لا. | SNILS | الاسم الأول | تاريخ الميلاد | الجنس |
|---|
| أ 1 | 163-648-564 96 | Zhvanetsky Mikhail | 03/06/1934 | م |
| أ 2 | 163-648-564 96 | Zhvanetsky Mikhail | 03/06/1934 | م |
| A3 | 126-029-036 24 | Ilchenko فيكتور | 01/02/1937 | م |
| A4 | | نوفيكوفا كلارا | 12.26.1946 | و |
| لا. | SNILS | الاسم الأول | تاريخ الميلاد | الجنس |
|---|
| ب 1 | 126-029-036 24 | Ilyichenko Victor | 01/02/1937 | م |
| ب 2 | | Zhivanetsky Mikhail | 03/06/1934 | م |
| ب 3 | | Zerchaninova Klara | 12.26.1946 | 2 |
قيل سابقًا أن أبسط خوارزمية حتمية هي استخدام معرف فريد ، من المفترض أن يحدد هوية الشخص بشكل فريد. على سبيل المثال ، نفترض أن جميع السجلات التي لها نفس قيمة المعرف (SNILS) تصف نفس الموضوع ، وإلا فهي مواضيع مختلفة. سيؤدي الاتصال القطعي في هذه الحالة إلى توليد الأزواج التالية: A1 و A2 و A3 و B1. لن يرتبط B2 بـ A1 و A2 ، نظرًا لأن المعرف لا يهم ، على الرغم من أنه يتزامن في المحتوى مع السجلات المحددة.
تؤدي هذه الاستثناءات إلى الحاجة إلى استكمال الخوارزمية الحتمية بقواعد جديدة. على سبيل المثال ، إذا لم يكن هناك معرف فريد ، يمكنك استخدام سمات أخرى مثل الاسم وتاريخ الميلاد والجنس. في المثال المحدد ، لن تعطي هذه القاعدة الإضافية مرة أخرى مراسلات B2 و A1 / A2 ، لأن الأسماء الآن مختلفة - هناك تشويه صوتي لللقب.
يمكن حل هذه المشكلة باستخدام طرق التحليل الصوتي ، ولكن إذا قمت بتغيير اللقب (على سبيل المثال ، في حالة الزواج) ، فستحتاج إلى اللجوء إلى تطبيق قاعدة جديدة ، على سبيل المثال ، مقارنة تاريخ الميلاد أو السماح بالاختلافات في السمات الحالية للسجل (على سبيل المثال ، الجنس).
يوضح المثال بوضوح أن الخوارزمية القطعية حساسة جدًا لجودة البيانات ، ويمكن أن تؤدي الزيادة في عدد سمات السجل إلى زيادة كبيرة في عدد القواعد المطبقة ، مما يعقد بشكل كبير استخدام الخوارزميات القطعية.
علاوة على ذلك ، يمكن استخدام الخوارزميات القطعية إذا كانت هناك مجموعة بيانات تم التحقق منها (مرجع رئيسي) تتم مقارنة المعلومات الواردة معها. ومع ذلك ، في حالة التجديد المستمر للدليل الرئيسي نفسه ، قد يتطلب الأمر إصلاحًا شاملاً للعلاقات القائمة ، مما يجعل استخدام الخوارزميات القطعية مستهلكًا للوقت أو ببساطة مستحيلاً.
الخوارزميات الاحتمالية
تستخدم الخوارزميات الاحتمالية لربط سجلات السلسلة مجموعة من السمات أوسع من السمات القطعية ، ويتم حساب معامل الوزن لكل سمة يحدد القدرة على التأثير على الاتصال في التقييم النهائي لاحتمال مطابقة السجلات المقدرة. تعتبر السجلات التي تراكمت الوزن الإجمالي فوق عتبة معينة ذات صلة ، وتعتبر السجلات التي تراكمت الوزن الكلي تحت عتبة غير ذات صلة. تعتبر الأزواج التي اكتسبت قيمة الوزن الإجمالي من منتصف النطاق مرشحين للربط ويمكن اعتبارها لاحقًا (على سبيل المثال ، من قبل المشغل) ، الذي سيقرر اتحادهم (الرابط) أو يتركهم غير مقيد. وبالتالي ، على عكس الخوارزميات الحتمية ، وهي مجموعة من عدد كبير من القواعد الواضحة (المبرمجة) ، يمكن تكييف الخوارزميات الاحتمالية مع جودة البيانات عن طريق تحديد قيم العتبة ولا تتطلب إعادة البرمجة.
لذا ، تقوم الخوارزميات الاحتمالية بتعيين معاملات الوزن ( u و m ) لسمات السجل ، والتي سيتم تحديد مراسلاتها أو تضاربها مع بعضها البعض.
يحدد المعامل u احتمالية تطابق معرّفين لسجلين مستقلين بشكل عشوائي. على سبيل المثال ، احتمال U لشهر الميلاد (عندما يكون هناك اثني عشر قيمة موزعة بشكل موحد) هو 1 \ 12 = 0.083. سيكون للمعرفات التي تحتوي على قيم غير موزعة بالتساوي احتمالات مختلفة لقيم مختلفة (أحيانًا ، بما في ذلك القيم المفقودة).
المعامل m هو احتمال أن المعرفات في الأزواج المُقارنة تتوافق مع بعضها البعض أو متشابهة تمامًا - على سبيل المثال ، في حالة الاحتمال العالي بواسطة خوارزمية Jaro-Winkler أو منخفضة بواسطة خوارزمية Levenshtein. إذا كانت سمات السجلات متناسقة تمامًا ، يجب أن يكون لهذه القيمة قيمة 1.0 ، ولكن بالنظر إلى الاحتمالية المنخفضة لذلك ، يجب تقييم المعامل بشكل مختلف. يمكن إجراء هذا التقييم على أساس التحليل الأولي لمجموعة البيانات ، على سبيل المثال ، من خلال "تعلم" الخوارزمية الاحتمالية يدويًا لتحديد عدد كبير من أزواج المطابقة وعدم التوافق أو من خلال تشغيل الخوارزمية بشكل متكرر لتحديد القيمة الأكثر ملائمة لمعامل m.
إذا تم تعريف احتمالية m على أنها 0.95 ، فستبدو معاملات الامتثال / عدم الامتثال لشهر الميلاد كما يلي:
| متري | حصة الروابط | حصة القيم وليس المراجع | التردد | الوزن |
|---|
| الامتثال | م = 0.95 | ش = 0.083 | م \ u = 11.4 | ln (م / ش) / ln (2) ≈ 3.51 |
| عدم تطابق | 1 م = 0.05 | 1-يو = 0.917 | (1 م) / (1-ش) ≈ 0.0545 | ln ((1-m) / (1-u)) / ln (2) ≈ -4.20 |
يجب إجراء حسابات مماثلة لمعرفات السجلات الأخرى من أجل تحديد معاملات الامتثال وعدم الامتثال الخاصة بها. بعد ذلك ، تتم مقارنة كل معرف لسجل واحد بالمعرف المقابل لسجل آخر لتحديد الوزن الإجمالي للزوج: يتم إضافة وزن الزوج المقابل إلى النتيجة الإجمالية بإجمالي تراكمي ، بينما يتم طرح وزن الزوج غير المناسب من النتيجة الإجمالية. تتم مقارنة المبلغ الناتج بقيم العتبة المحددة لتحديد ما إذا كان سيتم إقران الزوج الذي تم تحليله تلقائيًا أم نقله إلى عامل التشغيل للنظر فيه أم لا.
المنع
إن تحديد حدود الامتثال / عدم الامتثال هو التوازن بين الحصول على حساسية مقبولة (حصة السجلات ذات الصلة التي تم اكتشافها بواسطة الخوارزمية) والقيمة التنبؤية للنتيجة (أي الدقة ، كمقياس للسجلات المطابقة الحقيقية المرتبطة بالخوارزمية). نظرًا لأن تحديد العتبات يمكن أن يكون مهمة صعبة للغاية ، خاصة بالنسبة لمجموعات البيانات الكبيرة ، غالبًا ما يتم استخدام طريقة تعرف بالحظر لزيادة الكفاءة الحسابية. تتم المحاولات لإجراء مقارنة بين السجلات التي تم الكشف عن وجود اختلاف كبير ( التمييز ) في قيم السمات الأساسية. هذا يؤدي إلى زيادة الدقة بسبب انخفاض الحساسية.
على سبيل المثال ، يؤدي التأمين المستند إلى التشفير الصوتي لللقب إلى تقليل العدد الإجمالي للمقارنات المطلوبة ويزيد من احتمالية أن تكون العلاقات بين السجلات صحيحة ، لأن السمتين متناسقتين بالفعل ، ولكن من المحتمل أن تخطي السجلات المتعلقة بنفس الشخص الذي لقبه تغيرت (على سبيل المثال ، نتيجة للزواج). الحظر حسب شهر الميلاد هو مؤشر أكثر استقرارًا لا يمكن تعديله إلا إذا كان هناك خطأ في البيانات المصدر ، ولكنه يوفر فائدة أكثر تواضعا في القيمة التنبؤية الإيجابية وفقدان الحساسية ، لأنه يخلق اثني عشر مجموعة مختلفة من مجموعات البيانات الضخمة للغاية ولا يؤدي إلى زيادة في السرعة الحوسبة.
وبالتالي ، غالبًا ما تستخدم أنظمة ربط إدخال النص الأكثر كفاءة العديد من تمريرات الحظر لتجميع البيانات بطرق مختلفة من أجل إعداد مجموعات من السجلات التي يجب تقديمها لاحقًا للتحليل.
التعلم الآلي
في الآونة الأخيرة ، تم استخدام طرق التعلم الآلي المختلفة لربط السجلات النصية. في بحثه لعام 2011 ، أظهر راندال ويلسون أن خوارزمية الربط الاحتمالية الكلاسيكية للسجلات النصية تعادل خوارزمية Bayes الساذجة ويعاني من نفس المشاكل من افتراض أن ميزات التصنيف مستقلة. لزيادة دقة التحليل ، يقترح المؤلف استخدام نموذج أساسي لشبكة عصبية تسمى منظور أحادي الطبقة ، يسمح استخدامه للمرء بتجاوز النتائج التي تم الحصول عليها باستخدام الخوارزميات الاحتمالية التقليدية بشكل كبير.
ترميز صوتي
تتطابق الخوارزميات الصوتية بين كلمتين منطقتين بشكل متشابه مع نفس الرموز ، مما يسمح لك بمقارنة هذه الكلمات بناءً على التشابه الصوتي.
تم تصميم معظم الخوارزميات الصوتية لتحليل الكلمات الإنجليزية ، على الرغم من أن بعض الخوارزميات قد تم تعديلها مؤخرًا للاستخدام مع لغات أخرى ، أو تم إنشاؤها في الأصل كحلول وطنية (على سبيل المثال ، Caverphone).
Soundex
الخوارزمية الكلاسيكية لمقارنة سلسلتين بصوتهم هي Soundex (اختصار لفهرس الصوت). يقوم بتعيين نفس الرمز للسلاسل التي لها صوت مماثل باللغة الإنجليزية. تم استخدام Soundex في الأصل من قبل إدارة المحفوظات الوطنية الأمريكية في ثلاثينيات القرن العشرين لتحليل التعدادات بأثر رجعي من 1890 إلى 1920.
مؤلفو الخوارزميات هم روبرت سي راسل ومارغريت كينج أوديل ، الذين حصلوا على براءة اختراع في العشرينات من القرن الماضي. اكتسبت الخوارزمية نفسها شعبية في النصف الثاني من القرن الماضي عندما أصبحت موضوعًا للعديد من المقالات في مجلات العلوم الشعبية في الولايات المتحدة الأمريكية وتم نشرها في دراسة D.Nut "فن البرمجة".
ديتش-موكوتوف ساوندكس
نظرًا لأن Soundex مناسب للغة الإنجليزية فقط ، فقد حاول بعض الباحثين تعديله. في عام 1985 ، اقترح غاري موكوتوف وراندي ديتش شكلًا مختلفًا من خوارزمية Soundex ، المصممة لمقارنة ألقاب أوروبا الشرقية (بما في ذلك الروسية) بجودة عالية إلى حد ما.
في التسعينات ، اقترح لورنس فيليبس (لورنس فيليبس) نسخة بديلة من خوارزمية Soundex ، والتي كانت تسمى Metaphone. استخدمت الخوارزمية الجديدة مجموعة أكبر من القواعد للنطق باللغة الإنجليزية والتي كانت أكثر دقة. في وقت لاحق ، تم تعديل الخوارزمية لاستخدامها في لغات أخرى بناءً على النسخ باستخدام أحرف الأبجدية اللاتينية.
في عام 2002 ، نشر العدد الثامن من مجلة Programmer مقالًا بقلم بيتر كانكووسكي يتحدث عن تكيفه للنسخة الإنجليزية من خوارزمية Metaphone. تقوم هذه النسخة من الخوارزمية بتحويل الكلمات المصدر وفقًا لقواعد ومعايير اللغة الروسية ، مع مراعاة الصوت الصوتي للأحرف الصوتية غير المضغوطة و "الدمج" المحتمل للحروف الساكنة في النطق.
بدلا من الاستنتاج
نتيجة للعديد من التكرارات ، قام فريق المشروع لمشروع تطوير منتج البرمجيات ، الذي ورد ذكره في المقدمة ، بتطوير حل معماري ، يظهر مخططه في الشكل.
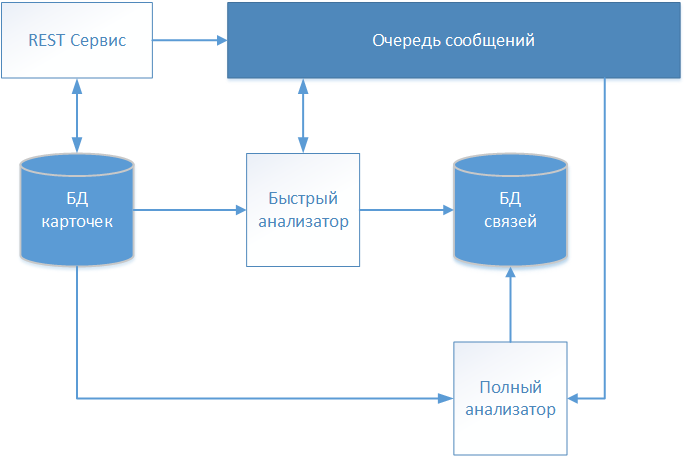
يتم قبول الأوصاف النصية للمرضى من خلال خدمة REST ويتم تخزينها في المستودع (قاعدة بيانات البطاقة) دون أي تغييرات. نظرًا لأن نظامنا يعمل مع البيانات الطبية ، فقد تم اختيار معيار FHIR (موارد التشغيل البيني للرعاية الصحية السريعة) لتبادل المعلومات. يتم نقل المعلومات حول بطاقة المريض المستلمة إلى قائمة انتظار الرسائل لمزيد من التحليل واتخاذ القرار بشأن إنشاء الاتصال.
البطاقة الأولى المراد معالجتها هي "محلل سريع" يعمل على خوارزمية حتمية. إذا نجحت جميع قواعد الخوارزمية الحتمية ، فإنها تنشئ سجلاً يحتوي على رابط للبطاقة المعالجة في وحدة تخزين منفصلة (قاعدة بيانات الروابط). يحتوي السجل بالإضافة إلى معرف البطاقة التي تم تحليلها ، وتاريخ إنشاء الاتصال ومعرف شرطي يحدد المريض المحدد عالميًا. تتم الإشارة إلى المزيد من البطاقات إلى المعرف العالمي المحدد ، وبالتالي تشكيل صفيف يصف فردًا معينًا.
إذا لم تجد الخوارزمية الحتمية تطابقًا ، فسيتم إرسال معلومات البطاقة من خلال قائمة انتظار الرسائل إلى "المحلل الكامل".
( ). . :

1. -
, . 2.
2.
- , ().
3.
, , ( ) , .
4.
, . . , , . , , , .