قلة من الناس لديهم جلاستر في روسيا ، وأي تجربة مثيرة للاهتمام. لدينا كبيرة وصناعية ، وبحكم المناقشة في
آخر مشاركة ، في الطلب. تحدثت عن بداية تجربة ترحيل النسخ الاحتياطية من تخزين Enterprise إلى Glusterfs.
هذا ليس متشددا بما فيه الكفاية. لم نتوقف وقررنا جمع شيء أكثر خطورة. لذلك ، سنتحدث هنا عن أشياء مثل تشفير المحو ، والتجزئة ، وإعادة التوازن ، والاختناق ، واختبار الضغط وما إلى ذلك.

- المزيد من نظرية الحجم / subwolum
- قطع غيار ساخنة
- شفاء / شفاء كامل / إعادة التوازن
- الاستنتاجات بعد إعادة تشغيل 3 عقد (لا تفعل ذلك أبدًا)
- كيف يؤثر التسجيل بسرعات مختلفة من VMs المختلفة وميزة تشغيل / إيقاف التشغيل على حمل الحجم الفرعي؟
- إعادة التوازن بعد رحيل القرص
- إعادة التوازن السريع
ماذا تريد
المهمة بسيطة: جمع متجر رخيص ولكنه موثوق. رخيصة الثمن وموثوق بها - حتى لا يكون مخيفًا تخزين ملفاتنا الخاصة بها للبيع. وداعا. بعد ذلك ، بعد الاختبارات الطويلة والنسخ الاحتياطي لنظام تخزين آخر - أيضًا العملاء.
التطبيق (IO التسلسلي) :
- النسخ الاحتياطية
- اختبار البنى التحتية
- اختبار التخزين لملفات الوسائط الثقيلة.
نحن هنا.
- ملف المعركة والبنية التحتية للاختبار الجاد
- تخزين للبيانات الهامة.
مثل آخر مرة ، فإن المتطلب الرئيسي هو سرعة الشبكة بين حالات Glaster. 10G في البداية على ما يرام.
النظرية: ما هو الحجم المشتت؟
يعتمد الحجم الموزع على تقنية تشفير المحو (EC) ، والتي توفر حماية فعالة إلى حد ما ضد فشل القرص أو الخادم. إنه مثل RAID 5 أو 6 ، لكن ليس حقًا. يقوم بتخزين الجزء المشفر من الملف لكل لبنة بطريقة تتطلب فقط مجموعة فرعية من الأجزاء المخزنة في القوالب المتبقية لاستعادة الملف. يتم تكوين عدد من الطوب التي قد تكون غير متاحة دون فقدان الوصول إلى البيانات من قبل المسؤول أثناء إنشاء وحدة التخزين.
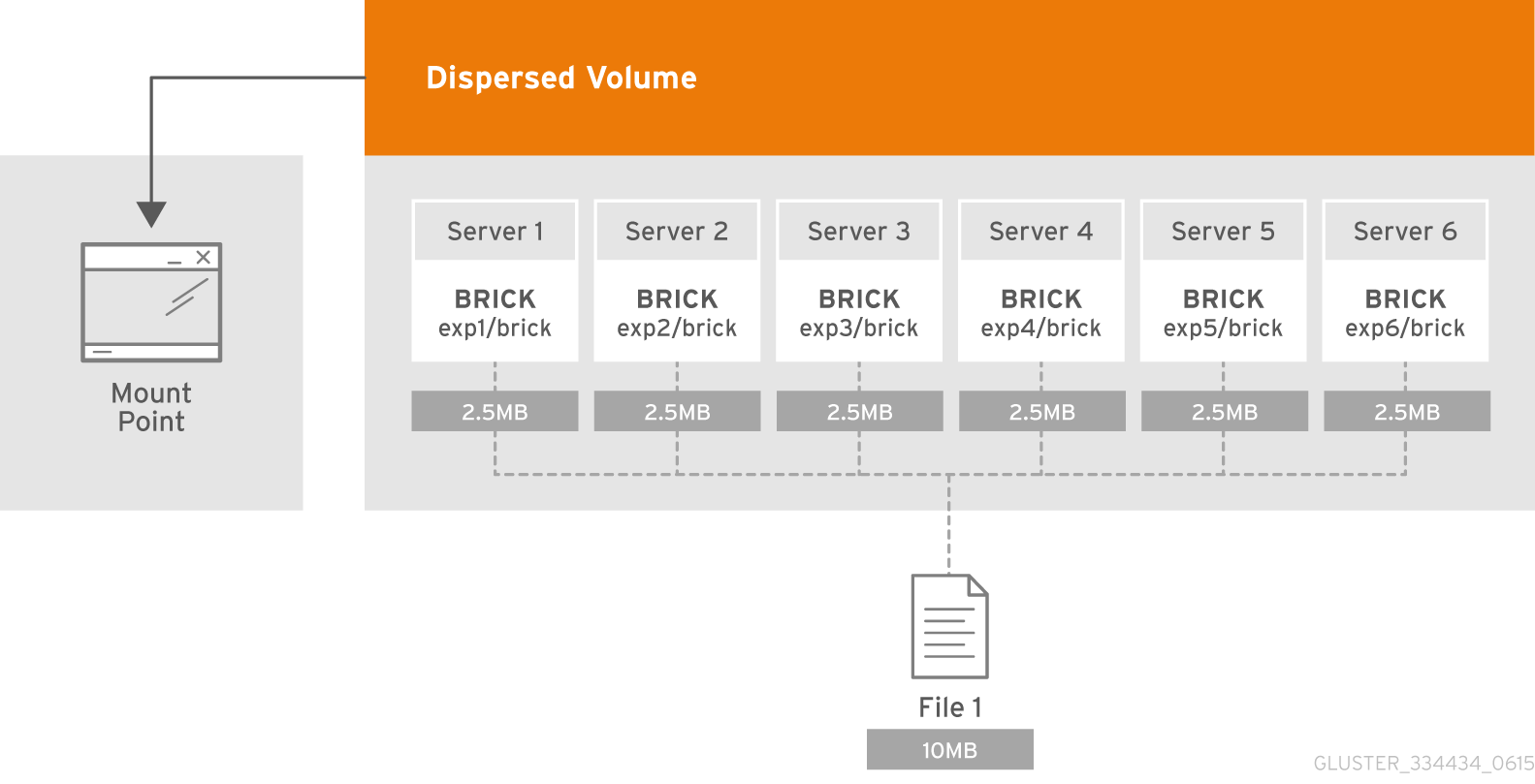
ما هو الحجم الفرعي؟
يتجلى جوهر المجلد الفرعي في مصطلحات GlusterFS مع المجلدات الموزعة. في تشفير المحو الموزع والمضطرب سيعمل فقط في إطار مضخم الصوت. وفي الحالة ، على سبيل المثال ، مع البيانات الموزعة المكررة سيتم نسخها في إطار مضخم الصوت.
يتم توزيع كل منها على خوادم مختلفة ، مما يسمح لها بفقدانها أو إخراجها بحرية للمزامنة. في الشكل ، تم تمييز الخوادم (المادية) باللون الأخضر ، بينما تنتشر الذئاب الفرعية. يتم تقديم كل منهم كقرص (وحدة تخزين) إلى خادم التطبيق:

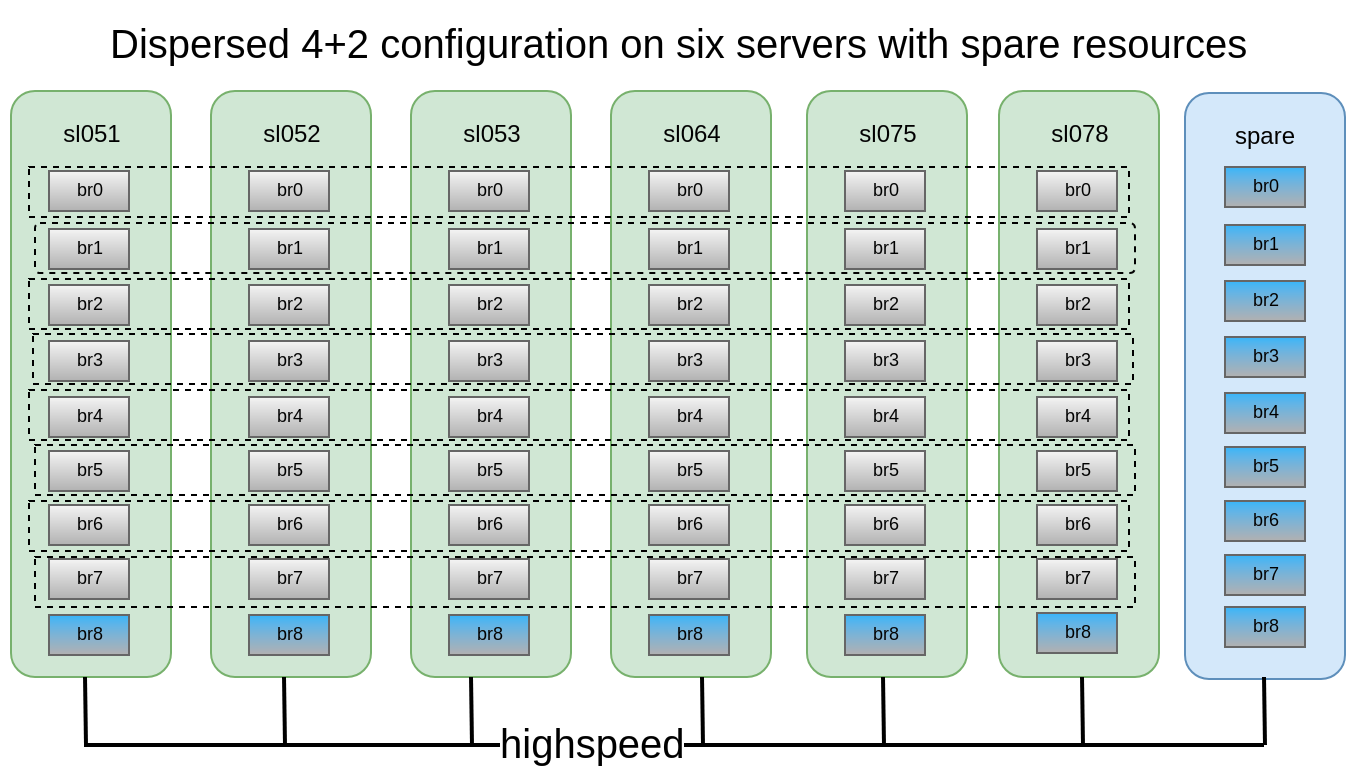
تقرر أن تكوين 4 + 2 الموزع الموزع على 6 عقد يبدو موثوقًا تمامًا ، فقد نفقد أي خادمين أو قرصين داخل كل مضخم صوت ، مع الاستمرار في الوصول إلى البيانات.
كان لدينا 6 DELL PowerEdge R510 القديمة تحت تصرفنا مع 12 فتحة قرص ومحركات 48x2TB 3.5 SATA. من حيث المبدأ ، إذا كان هناك خادم يحتوي على 12 فتحة قرص ، ولديه ما يصل إلى 12 تيرابايت من محركات الأقراص في السوق ، فيمكننا جمع مساحة تخزين تصل إلى 576 تيرابايت من المساحة القابلة للاستخدام. ولكن لا تنس أنه على الرغم من استمرار زيادة الحد الأقصى لأحجام محركات الأقراص الثابتة من عام لآخر ، إلا أن أدائها لا يزال ثابتًا ويمكن أن تستغرق عملية إعادة إنشاء قرص 10-12 تيرابايت أسبوعًا.
 إنشاء مجلد:
إنشاء مجلد:وصف مفصل لكيفية تحضير الطوب ، يمكنك أن تقرأ في مشاركتي
السابقةgluster volume create freezer disperse-data 4 redundancy 2 transport tcp \ $(for i in {0..7} ; do echo {sl051s,sl052s,sl053s,sl064s,sl075s,sl078s}:/export/brick$i/freezer ; done)
نحن نصنع ، ولكننا لسنا في عجلة من أمرنا لبدء التشغيل والتركيب ، حيث لا يزال يتعين علينا تطبيق العديد من المعلمات المهمة.
ما حصلنا عليه: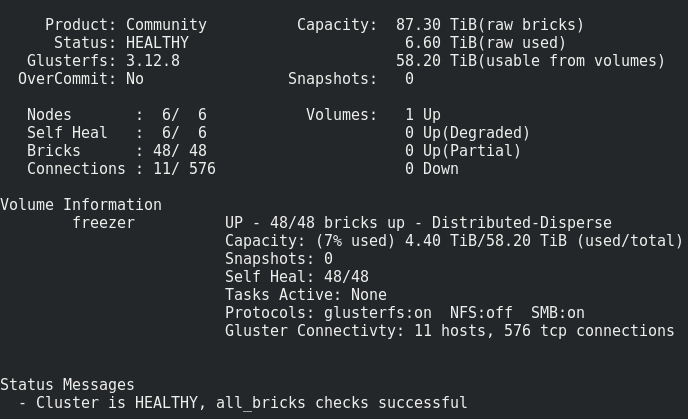
يبدو كل شيء طبيعيًا ، ولكن هناك تحذير واحد.
يتكون من تسجيل مثل هذا الحجم على الطوب:يتم وضع الملفات واحدًا تلو الآخر في الذئاب الفرعية ، ولا يتم توزيعها بشكل متساوٍ عبرها ، وبالتالي ، عاجلاً أم آجلاً سوف نركض في حجمها ، وليس حجم المجلد بأكمله. الحد الأقصى لحجم الملف الذي يمكننا وضعه في هذا المستودع هو الحجم القابل للاستخدام من مضخم الصوت مطروحًا منه المساحة المشغولة عليه بالفعل. في حالتي ، يبلغ <8 تيرابايت.
ماذا تفعل؟ كيف تكون؟يتم حل هذه المشكلة عن طريق الحجم أو حجم الشريط ، ولكن ، كما أظهرت الممارسة ، فإن الشريط يعمل بشكل سيء للغاية.
لذلك ، سنحاول تقسيم.
ما هو تقسيم ، بالتفصيل هنا .
ما هو التقسيم باختصار :
سيتم تقسيم كل ملف تضعه في مجلد إلى أجزاء (شظايا) ، مرتبة نسبيًا بالتساوي في ذئاب فرعية. يتم تحديد حجم الجزء من قبل المسؤول ، والقيمة القياسية هي 4 ميجابايت.
شغّل التجميع بعد إنشاء مجلد ، ولكن قبل أن يبدأ :
gluster volume set freezer features.shard on
قمنا بتعيين حجم القطعة (أيهما أفضل؟ ينصح الرجال من oVirt 512 ميجابايت) :
gluster volume set freezer features.shard-block-size 512MB
من الناحية التجريبية ، اتضح أن الحجم الفعلي للقطع في الطوب عند استخدام الحجم المشتت 4 + 2 يساوي حجم كتلة القطع / 4 ، في حالتنا 512M / 4 = 128M.
تتحلل كل قطعة وفقًا لمنطق تشفير المحو وفقًا للطوب في إطار العالم الفرعي بهذه القطع: 4 * 128M + 2 * 128M
ارسم حالات الفشل التي تنجو من اللمعان مع هذا التكوين:في هذا التكوين ، يمكننا البقاء على قيد الحياة من سقوط عقدتين أو 2 من أي أقراص ضمن نفس الحجم الفرعي.
للاختبارات ، قررنا أن ننزلق التخزين الناتج تحت سحابة لدينا وتشغيل المعلومات المالية من الأجهزة الافتراضية.
نقوم بتشغيل التسجيل التسلسلي من 15 VMs ونقوم بما يلي.
إعادة تشغيل العقدة الأولى:17:09
يبدو غير حرج (~ 5 ثوانٍ من عدم التوافر بواسطة معلمة ping.timeout).
17:19
أطلقت الشفاء الكامل.
عدد الإدخالات العلاجية آخذ في الازدياد فقط ، ربما بسبب المستوى العالي من الكتابة للمجموعة.
17:32
تقرر إيقاف التسجيل من VM.
بدأ عدد إدخالات الشفاء في الانخفاض.
17:50
تم الشفاء.
إعادة تشغيل عقدتين:لوحظت نفس النتائج كما في العقدة الأولى.إعادة تشغيل 3 عقد:نقطة توصيل النقل الصادرة عن نقطة التحميل غير متصلة ، تلقى VMs ioerror.
بعد تشغيل العقد ، استعاد Glaster نفسه ، دون تدخل من جانبنا ، وبدأت عملية العلاج.لكن 4 من أصل 15 جهاز VM لا يمكن أن ترتفع. رأيت أخطاء في برنامج مراقبة الأجهزة الافتراضية:
2018.04.27 13:21:32.719 ( volumes.py:0029): I: Attaching volume vol-BA3A1BE1 (/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1) with attach type generic... 2018.04.27 13:21:32.721 ( qmp.py:0166): D: Querying QEMU: __com.redhat_drive_add({'file': u'/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1', 'iops_rd': 400, 'media': 'disk', 'format': 'qcow2', 'cache': 'none', 'detect-zeroes': 'unmap', 'id': 'qdev_1k7EzY85TIWm6-gTBorE3Q', 'iops_wr': 400, 'discard': 'unmap'})... 2018.04.27 13:21:32.784 ( instance.py:0298): E: Failed to attach volume vol-BA3A1BE1 to the instance: Device 'qdev_1k7EzY85TIWm6-gTBorE3Q' could not be initialized Traceback (most recent call last): File "/usr/lib64/python2.7/site-packages/ic/instance.py", line 292, in emulation_started c2.qemu.volumes.attach(controller.qemu(), device) File "/usr/lib64/python2.7/site-packages/c2/qemu/volumes.py", line 36, in attach c2.qemu.query(qemu, drive_meth, drive_args) File "/usr/lib64/python2.7/site-packages/c2/qemu/_init_.py", line 247, in query return c2.qemu.qmp.query(qemu.pending_messages, qemu.qmp_socket, command, args, suppress_logging) File "/usr/lib64/python2.7/site-packages/c2/qemu/qmp.py", line 194, in query message["error"].get("desc", "Unknown error") QmpError: Device 'qdev_1k7EzY85TIWm6-gTBorE3Q' could not be initialized qemu-img: Could not open '/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1': Could not read image for determining its format: Input/output error
من الصعب دفع 3 عقد مع إيقاف تقسيم Transport endpoint is not connected (107) /GLU/volumes/e0/e0bf9a42-8915-48f7-b509-2f6dd3f17549: ERROR: cannot read (Input/output error)
نفقد أيضًا البيانات ، ولا يمكن استعادتها.
سدد 3 عقد بلطف مع تقسيم ، هل سيكون هناك تلف في البيانات؟هناك ، ولكن أقل بكثير (صدفة؟) ، لقد فقدت 3 من 30 محرك أقراص.
الاستنتاجات:- شفاء هذه الملفات معلقة إلى ما لا نهاية ، لا يساعد إعادة التوازن. نستنتج أن الملفات التي كان يتم تسجيلها النشط عندما تم إيقاف تشغيل العقدة الثالثة فقدت إلى الأبد.
- لا تقم أبدًا بإعادة تحميل أكثر من عقدين في تكوين 4 + 2 في الإنتاج!
- كيف لا تفقد البيانات إذا كنت تريد حقًا إعادة تشغيل أكثر من 3 عقد؟ توقف عن التسجيل عند نقطة التحميل و / أو توقف الصوت.
- يجب استبدال العقد أو الطوب في أقرب وقت ممكن. لهذا ، من المستحسن للغاية أن يكون لديك ، على سبيل المثال ، 1-2 طوب ساخن في كل عقدة للاستبدال السريع. وعقدة إضافية واحدة مع الطوب في حالة تفريغ العقدة.
من المهم أيضًا اختبار حالات استبدال محرك الأقراص
رحيل بريك (الأقراص):
17:20ضربنا لبنة:
/dev/sdh 1.9T 598G 1.3T 33% /export/brick6
17:22 gluster volume replace-brick freezer sl051s:/export/brick_spare_1/freezer sl051s:/export/brick2/freezer commit force
يمكنك أن ترى مثل هذا السحب في وقت استبدال الطوب (سجل من مصدر واحد):

عملية الاستبدال طويلة جدًا ، مع مستوى صغير من التسجيل لكل عنقود وإعدادات افتراضية تبلغ 1 تيرابايت ، يستغرق الأمر حوالي يوم للتعافي.
معلمات قابلة للتعديل للعلاج: gluster volume set cluster.background-self-heal-count 20
الخيار: تفريق الشفاء
القيمة الافتراضية: 8
الوصف: يمكن استخدام هذا الخيار للتحكم في عدد العلاجات المتوازية
الخيار: تفريق شفاء الانتظار qlength
القيمة الافتراضية: 128
الوصف: يمكن استخدام هذا الخيار للتحكم في عدد العلاجات التي يمكن أن تنتظر
الخيار: disperse.shd-max-thread
القيمة الافتراضية: 1
الوصف: الحد الأقصى لعدد العلاجات المتوازية التي يمكن أن تقوم بها SHD لكل لبنة محلية. يمكن أن يقلل هذا من أوقات الشفاء بشكل كبير ، ولكن يمكن أيضًا أن يسحق الطوب الخاص بك إذا لم يكن لديك جهاز التخزين لدعم هذا.
الخيار: disperse.shd-wait-qlength
القيمة الافتراضية: 1024
الوصف: يمكن استخدام هذا الخيار للتحكم في عدد العلاجات التي يمكن أن تنتظر في SHD لكل حجم فرعي
الخيار: disperse.cpu-extensions
القيمة الافتراضية: auto
الوصف: فرض استخدام ملحقات وحدة المعالجة المركزية لتسريع حسابات مجال جالوا.
الخيار: تفريق شفاء نافذة حجم
القيمة الافتراضية: 1
الوصف: الحد الأقصى لعدد الكتل (128 كيلو بايت) لكل ملف يتم تطبيق عملية الشفاء الذاتي عليه في وقت واحد.ستود:
disperse.shd-max-threads: 6 disperse.self-heal-window-size: 4 cluster.self-heal-readdir-size: 2KB cluster.data-self-heal-algorithm: diff cluster.self-heal-window-size: 2 cluster.heal-timeout: 500 cluster.background-self-heal-count: 20 cluster.disperse-self-heal-daemon: enable disperse.background-heals: 18
باستخدام المعلمات الجديدة ، تم الانتهاء من 1 تيرابايت من البيانات في 8 ساعات (أسرع 3 مرات!)
اللحظة غير السارة هي أن النتيجة هي كتلة أكبر مما كانت عليهكان: Filesystem Size Used Avail Use% Mounted on /dev/sdd 1.9T 645G 1.2T 35% /export/brick2
أصبح: Filesystem Size Used Avail Use% Mounted on /dev/sdj 1.9T 1019G 843G 55% /export/hot_spare_brick_0
من الضروري أن تفهم. ربما الشيء هو تضخيم الأقراص الرقيقة. مع الاستبدال اللاحق للطوب المتزايد ، ظل الحجم كما هو.
إعادة التوازن:بعد توسيع وحدة التخزين أو تقليصها (بدون ترحيل البيانات) (باستخدام الأمرين الإضافيين وطوب إزالة الطوب على التوالي) ، تحتاج إلى إعادة توازن البيانات بين الخوادم. في وحدة التخزين غير المنسوخة ، يجب أن تكون جميع الطوب جاهزة لإجراء عملية استبدال الطوب (خيار البدء). في وحدة تخزين منسوخة ، يجب أن يكون أحد الطوب على الأقل في النسخة المتماثلة أعلى.تشكيل إعادة التوازن:الخيار: الكتلة. خنق شفهي
القيمة الافتراضية: عادية
الوصف: لتعيين الحد الأقصى لعدد عمليات ترحيل الملفات المتوازية المسموح بها على العقدة أثناء عملية إعادة التوازن. القيمة الافتراضية طبيعية وتسمح بحد أقصى [($ (وحدات المعالجة) - 4) / 2) ، 2] من الملفات إلى b
هجرت في وقت واحد. الكسل سيسمح بترحيل ملف واحد فقط في المرة وسيسمح العدواني بحد أقصى [($ (وحدات المعالجة) - 4) / 2) ، 4]الخيار: الكتلة
القيمة الافتراضية: إيقاف
الوصف: في حالة التمكين ، ستقوم هذه الميزة بترحيل أقفال posix المرتبطة بالملف أثناء إعادة التوازنالخيار: الكتلة
القيمة الافتراضية: on
الوصف: عند التمكين ، سيتم تخصيص الملفات للطوب باحتمال يتناسب مع حجمها. خلاف ذلك ، سيكون لجميع الطوب نفس الاحتمال (السلوك القديم).مقارنة الكتابة ، ثم قراءة نفس معلمات fio (نتائج أكثر تفصيلاً لاختبارات الأداء - في PM): fio --fallocate=keep --ioengine=libaio --direct=1 --buffered=0 --iodepth=1 --bs=64k --name=test --rw=write/read --filename=/dev/vdb --runtime=6000


 إذا كان الأمر مثيرًا للاهتمام ، فقم بمقارنة سرعة rsync بحركة المرور إلى عقد Glaster:
إذا كان الأمر مثيرًا للاهتمام ، فقم بمقارنة سرعة rsync بحركة المرور إلى عقد Glaster: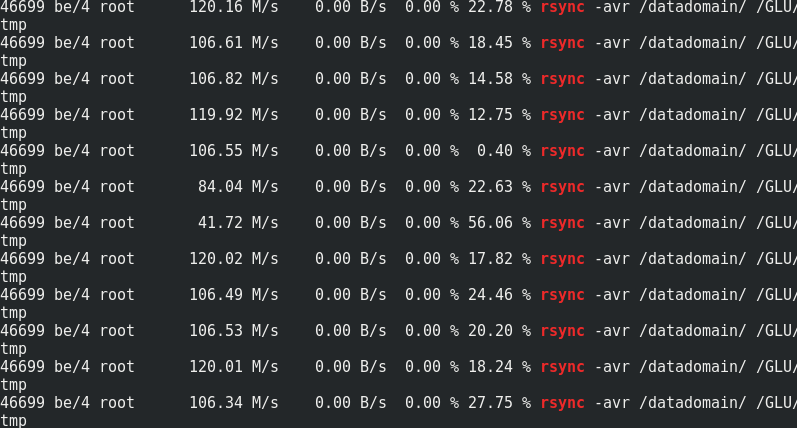
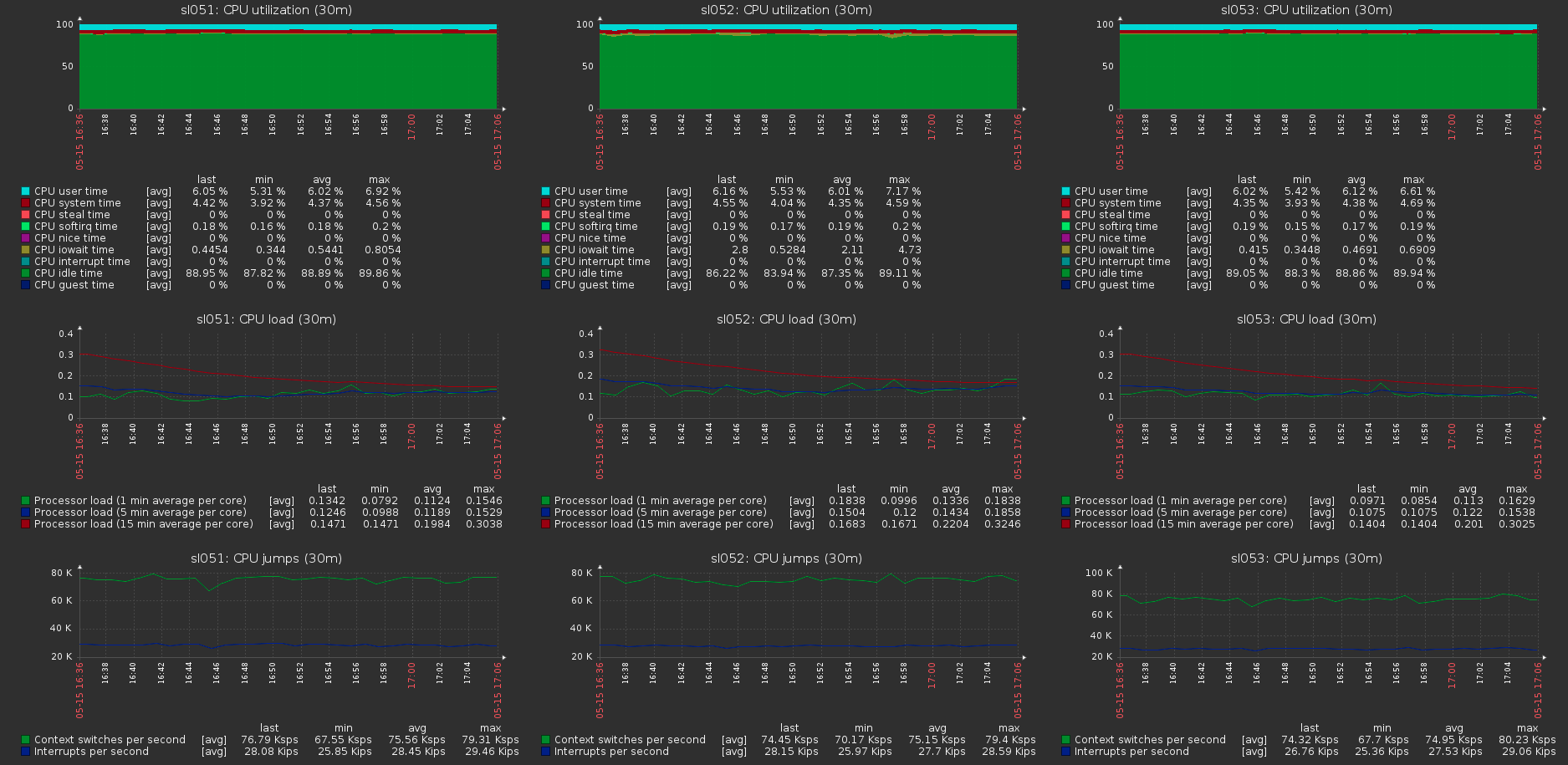
 يمكن ملاحظة أن حوالي 170 ميجابايت / ثانية / حركة مرور إلى 110 ميجابايت / ثانية / حمولة. اتضح أن هذه النسبة هي 33٪ من حركة المرور الإضافية ، بالإضافة إلى 1/3 من تكرار تشفير المحو.لا يتغير استهلاك الذاكرة من جانب الخادم مع التحميل أو بدونه:
يمكن ملاحظة أن حوالي 170 ميجابايت / ثانية / حركة مرور إلى 110 ميجابايت / ثانية / حمولة. اتضح أن هذه النسبة هي 33٪ من حركة المرور الإضافية ، بالإضافة إلى 1/3 من تكرار تشفير المحو.لا يتغير استهلاك الذاكرة من جانب الخادم مع التحميل أو بدونه: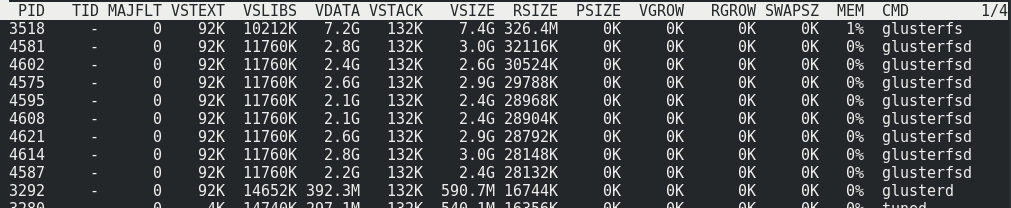 الحمل على الكتلة يستضيف مع الحمل الأقصى على وحدة التخزين:
الحمل على الكتلة يستضيف مع الحمل الأقصى على وحدة التخزين: