حتى وقت قريب ، في Odnoklassniki ، تم تخزين حوالي 50 تيرابايت من البيانات في الوقت الحقيقي في SQL Server. بالنسبة لمثل هذا الحجم ، يكاد يكون من المستحيل توفير الوصول السريع والموثوق ، وحتى الآمن إلى مركز البيانات باستخدام SQL DBMS. عادة في مثل هذه الحالات ، يستخدمون أحد مستودعات NoSQL ، ولكن لا يمكن نقل كل شيء إلى NoSQL: تتطلب بعض الكيانات ضمانات لمعاملات ACID.
أدى هذا بنا إلى استخدام تخزين NewSQL ، أي نظام إدارة قواعد البيانات (DBMS) الذي يوفر التسامح مع الخطأ ، وقابلية التطوير والأداء لأنظمة NoSQL ، ولكنه يحافظ في الوقت نفسه على ضمانات ACID المألوفة للأنظمة الكلاسيكية. هناك عدد قليل من الأنظمة الصناعية العاملة في هذه الفئة الجديدة ، لذلك قمنا بتنفيذ هذا النظام بأنفسنا ووضعناه في التشغيل التجاري.
كيف يعمل وما حدث - اقرأ تحت القطع.
اليوم ، جمهور Odnoklassniki الشهري أكثر من 70 مليون زائر فريد. نحن من
بين أكبر
خمس شبكات اجتماعية في العالم ، والمواقع العشرون التي يقضي فيها المستخدمون معظم الوقت. البنية التحتية "OK" تتعامل مع الأحمال العالية جدًا: أكثر من مليون طلب HTTP في الثانية إلى الجبهات. توجد أجزاء من أسطول الخوادم بكمية تزيد عن 8000 قطعة بالقرب من بعضها البعض - في أربعة مراكز بيانات في موسكو ، مما يسمح بوقت استجابة للشبكة يقل عن 1 مللي ثانية فيما بينها.
نحن نستخدم كاساندرا منذ عام 2010 ، بدءًا من الإصدار 0.6. واليوم ، تعمل عشرات المجموعات. أسرع مجموعة معالجة أكثر من 4 ملايين عملية في الثانية ، وأكبر مخازن 260 تيرابايت.
ومع ذلك ، كل هذه مجموعات NoSQL عادية تستخدم لتخزين البيانات
المتسقة بشكل ضعيف . لكننا أردنا استبدال التخزين المتناسق الرئيسي ، Microsoft SQL Server ، والذي تم استخدامه منذ تأسيس Odnoklassniki. يتكون التخزين من أكثر من 300 جهاز SQL Server Standard Edition ، والتي تحتوي على 50 تيرابايت من البيانات - كيانات الأعمال. يتم تعديل هذه البيانات كجزء من معاملات ACID وتتطلب
اتساقًا عاليًا .
لتوزيع البيانات بين عقد SQL Server ، استخدمنا
التقسيم الرأسي والأفقي (
تقسيم ). تاريخياً ، استخدمنا مخططًا بسيطًا لتقاسم البيانات: ارتبط كل كيان برمز مميز - وظيفة معرف الكيان. تم وضع الكيانات التي لها نفس الرمز المميز على نفس خادم SQL. تم تنفيذ علاقة نوع التفاصيل الرئيسية بحيث تتزامن الرموز المميزة للسجلات الرئيسية والمولدة دائمًا وتكون على نفس الخادم. في الشبكة الاجتماعية ، يتم إنشاء جميع السجلات تقريبًا نيابة عن المستخدم - مما يعني أنه يتم تخزين جميع بيانات المستخدم في نظام فرعي وظيفي واحد على خادم واحد. بمعنى أن جداول خادم SQL واحدة شاركت دائمًا تقريبًا في معاملة تجارية ، مما جعل من الممكن ضمان تناسق البيانات باستخدام معاملات ACID المحلية ، دون الحاجة إلى معاملات ACID الموزعة
البطيئة وغير الموثوقة .
بفضل التقسيم وتسريع SQL:
- نحن لا نستخدم قيود المفتاح الخارجي ، لأن عند المشاركة ، يمكن أن يكون معرف الكيان على خادم آخر.
- لا نستخدم الإجراءات المحفزة والمشغلات بسبب الحمل الإضافي على وحدة المعالجة المركزية DBMS.
- لا نستخدم JOINs بسبب كل ما سبق والعديد من القراءات العشوائية من القرص.
- خارج المعاملة ، للحد من الجمود ، نستخدم مستوى العزل "قراءة غير الملتزم بها".
- نقوم بإجراء معاملات قصيرة فقط (في المتوسط ، أقصر من 100 مللي ثانية).
- لا نستخدم UPDATE و DELETE متعدد الصفوف بسبب العدد الكبير من حالات الجمود - نقوم بتحديث سجل واحد فقط.
- نقوم دائمًا بتنفيذ الاستعلامات عن طريق الفهارس فقط - فاستعلام بخطة لفحص جدول كامل بالنسبة لنا يعني زيادة تحميل قاعدة البيانات وفشلها.
جعلت هذه الخطوات من الممكن ضغط أقصى أداء تقريبًا خارج خوادم SQL. ومع ذلك ، أصبحت المشاكل أكثر وأكثر. دعونا نلقي نظرة عليهم.
مشاكل SQL
- نظرًا لأننا استخدمنا تقسيم الملكية ، فقد أضاف المسؤولون قطعًا جديدة يدويًا. كل هذا الوقت ، لم تخدم النسخ المتماثلة للبيانات قابلة للتطوير الطلبات.
- مع زيادة عدد السجلات في الجدول ، تنخفض سرعة الإدراج والتعديل ، عند إضافة الفهارس إلى جدول موجود ، تنخفض السرعة عدة مرات ، ويتم إنشاء الفهارس وإعادة إنشائها مع فترة التوقف.
- إن وجود عدد قليل من Windows لـ SQL Server في الإنتاج يجعل إدارة البنية التحتية صعبة
لكن المشكلة الرئيسية هي
التسامح مع الخطأ
SQL Server الكلاسيكي لديه التسامح مع الخطأ. افترض أن لديك خادم قاعدة بيانات واحد فقط ، وأنه يفشل مرة واحدة كل ثلاث سنوات. في هذا الوقت ، لا يعمل الموقع لمدة 20 دقيقة ، وهذا مقبول. إذا كان لديك 64 خادمًا ، فإن الموقع لا يعمل مرة واحدة كل ثلاثة أسابيع. وإذا كان لديك 200 خادم ، فلا يعمل الموقع كل أسبوع. هذه مشكلة.
ما الذي يمكن عمله لتحسين مرونة SQL Server؟ تقدم لنا ويكيبيديا بناء مجموعة
يسهل الوصول إليها : حيث في حالة فشل أي من المكونات هناك مجموعة مكررة.
يتطلب هذا أسطولًا من المعدات باهظة الثمن: التكرار المتعدد والألياف والتخزين المشترك وإدراج احتياطي لا يعمل بشكل موثوق: حوالي 10 ٪ من الشوائب تفشل مع عقدة احتياطية بواسطة المحرك خلف العقدة الرئيسية.
لكن العيب الرئيسي لمثل هذه المجموعة التي يمكن الوصول إليها بشكل كبير هو عدم توفر أي شيء في حالة فشل مركز البيانات الذي يقف فيه. يحتوي Odnoklassniki على أربعة مراكز بيانات ، ونحن بحاجة إلى توفير العمل في حالة وقوع حادث كامل في أحدها.
للقيام بذلك ، يمكنك استخدام النسخ المتماثل
Multi-Master المضمن في SQL Server. هذا الحل أغلى بكثير بسبب تكلفة البرامج ويعاني من مشاكل معروفة مع النسخ المتماثل - تأخيرات معاملة غير متوقعة أثناء النسخ المتزامن والتأخير في استخدام النسخ المتماثل (ونتيجة لذلك ، فقدان التعديلات) أثناء عدم التزامن.
الحل اليدوي الضمني
للنزاعات يجعل هذا الخيار غير قابل للتطبيق تمامًا بالنسبة لنا.
كل هذه المشاكل تتطلب حلاً جذريًا وشرعنا في تحليل مفصل لها. هنا نحتاج إلى التعرف على ما يقوم به SQL Server بشكل أساسي - المعاملات.
معاملة بسيطة
خذ بعين الاعتبار أبسط ، من وجهة نظر مبرمج SQL المطبق ، المعاملة: إضافة صورة إلى ألبوم. يتم تخزين الألبومات والصور في لوحات مختلفة. يحتوي الألبوم على عداد صور عام. ثم تنقسم هذه المعاملة إلى الخطوات التالية:
- نحن نقفل الألبوم عن طريق المفتاح.
- إنشاء إدخال في جدول الصور.
- إذا كانت الصورة ذات وضع عام ، فإننا ننهي عداد الصور العام في الألبوم ، ونحدث السجل ونلتزم بالمعاملة.
أو على شكل كود زائف:
TX.start("Albums", id); Album album = albums.lock(id); Photo photo = photos.create(…); if (photo.status == PUBLIC ) { album.incPublicPhotosCount(); } album.update(); TX.commit();
نرى أن أكثر سيناريوهات المعاملات التجارية شيوعًا هو قراءة البيانات من قاعدة البيانات في ذاكرة خادم التطبيق ، وتغيير شيء ما ، وحفظ القيم الجديدة مرة أخرى في قاعدة البيانات. عادة في مثل هذه المعاملة نقوم بتحديث العديد من الكيانات ، والعديد من الجداول.
عند تنفيذ معاملة ، قد يحدث تعديل تنافسي لنفس البيانات من نظام آخر. على سبيل المثال ، قد يقرر Antispam أن يكون المستخدم مريبًا ، وبالتالي لا ينبغي أن تكون جميع صور المستخدم عامة ، ويجب إرسالها إلى الإشراف ، مما يعني تغيير photo.status إلى قيمة أخرى وفك العدادات المقابلة. من الواضح أنه إذا حدثت هذه العملية بدون ضمانات من ذرية التطبيق وعزل التعديلات المتنافسة ، كما هو الحال في
ACID ، فلن تكون النتيجة ما هو مطلوب - إما أن يعرض عداد الصور القيمة الخاطئة ، أو لن يتم إرسال جميع الصور للإشراف.
هناك الكثير من التعليمات البرمجية المماثلة التي تتعامل مع كيانات الأعمال المختلفة في إطار معاملة واحدة خلال وجود Odnoklassniki بالكامل. من تجربة الترحيل إلى NoSQL مع
الاتساق النهائي ، نحن نعلم أن الصعوبات الكبرى (وتكاليف الوقت) هي الحاجة إلى تطوير رمز يهدف إلى الحفاظ على اتساق البيانات. لذلك ، نظرنا في المطلب الرئيسي لمستودع جديد لتوفير معاملات ACID منطقية حقيقية لمنطق التطبيق.
وكانت المتطلبات الأخرى بنفس القدر من الأهمية:
- إذا فشل مركز البيانات ، فيجب توفر كل من القراءة والكتابة إلى وحدة التخزين الجديدة.
- الحفاظ على سرعة التطوير الحالية. أي أنه عند العمل مع مستودع جديد ، يجب أن تكون كمية الشفرة هي نفسها تقريبًا ، ولا يجب أن تكون هناك حاجة لإضافة شيء ما إلى المستودع ، وتطوير خوارزميات لحل التعارضات ، والحفاظ على الفهارس الثانوية ، وما إلى ذلك.
- يجب أن تكون سرعة التخزين الجديد عالية بما يكفي عند قراءة البيانات وعند معالجة المعاملات ، وهو ما يعني بشكل فعال عدم قابلية تطبيق حلول صارمة أكاديميًا وعالمية ولكن بطيئة ، مثل ، على سبيل المثال ، تنفيذ مرحلتين .
- التحجيم التلقائي على الطاير.
- باستخدام خوادم عادية رخيصة ، دون الحاجة لشراء قطع غريبة من الحديد.
- امكانية تطوير التخزين من قبل مطوري الشركة. بمعنى آخر ، تم إعطاء الأولوية للحلول الخاصة بهم أو مفتوحة المصدر ، ويفضل أن تكون في Java.
قرارات ، قرارات
بتحليل الحلول الممكنة ، توصلنا إلى خيارين ممكنين للهندسة المعمارية:
الأول هو اتخاذ أي خادم SQL وتنفيذ التسامح اللازم للأخطاء ، وآلية القياس ، ومجموعة تجاوز الفشل ، وحل التعارض ، ومعاملات ACID الموثوقة والسريعة. قمنا بتصنيف هذا الخيار على أنه غير تافه للغاية ومستهلك للوقت.
الخيار الثاني هو أخذ مستودع NoSQL جاهز مع التحجيم المطبق ، ومجموعة تجاوز الفشل ، وحل التعارض ، وتنفيذ المعاملات و SQL بأنفسنا. للوهلة الأولى ، حتى مهمة تنفيذ SQL ، ناهيك عن معاملات ACID ، تبدو مهمة لسنوات. ولكننا أدركنا بعد ذلك أن مجموعة ميزات SQL التي نستخدمها في الممارسة العملية بعيدة كل البعد عن ANSI SQL مثل
كاساندرا CQL بعيدة عن ANSI SQL. بإلقاء نظرة فاحصة على CQL ، أدركنا أنه قريب بما فيه الكفاية مما نحتاجه.
كاساندرا وسي كيو إل
لذا ، ما هو المثير للاهتمام حول كاساندرا ، ما هي القدرات التي لديها؟
أولاً ، يمكنك هنا إنشاء جداول مع دعم لأنواع البيانات المختلفة ، ويمكنك القيام بالتحديد أو التحديث على المفتاح الأساسي.
CREATE TABLE photos (id bigint KEY, owner bigint,…); SELECT * FROM photos WHERE id=?; UPDATE photos SET … WHERE id=?;
لضمان بيانات متماثلة متناسقة ، تستخدم كاساندرا
نهج النصاب القانوني . في أبسط الحالات ، هذا يعني أنه عندما يتم وضع ثلاث نسخ متماثلة من الصف نفسه على عقد مختلفة من المجموعة ، يعتبر السجل ناجحًا إذا أكدت معظم العقد (أي اثنتين من أصل ثلاثة) نجاح عملية الكتابة هذه. تعتبر بيانات السلسلة متسقة إذا تم ، عند القراءة ، استجواب معظم العقد وتأكيدها. وبالتالي ، مع وجود ثلاث نسخ متماثلة ، يتم ضمان تناسق البيانات الكاملة والفورية في حالة فشل عقدة واحدة. سمح لنا هذا النهج بتنفيذ مخطط أكثر موثوقية: إرسال الطلبات دائمًا إلى جميع النسخ المتماثلة الثلاثة ، في انتظار إجابة من أسرع اثنين. ثم يتم تجاهل الاستجابة المتأخرة للنسخة المتماثلة الثالثة. يمكن أن تواجه العقدة المتأخرة بإجابة مشاكل خطيرة - الفرامل ، جمع القمامة في JVM ، استعادة الذاكرة المباشرة في نواة لينكس ، فشل الأجهزة ، قطع الاتصال بالشبكة. ومع ذلك ، لا يؤثر هذا على عمليات العميل أو بياناته.
النهج عندما ننتقل إلى ثلاث عقد والحصول على إجابة من اثنين يسمى
المضاربة : يتم إرسال طلب للحصول على ملاحظات إضافية حتى قبل أن "تسقط".
ميزة أخرى من كاساندرا هي Batchlog - آلية تضمن التطبيق الكامل أو عدم التطبيق الكامل لحزمة التغييرات التي تجريها. هذا يسمح لنا بحل A في ACID - الذرية خارج الصندوق.
الأقرب إلى المعاملات في كاساندرا هو ما يسمى "
المعاملات خفيفة الوزن ". لكنها بعيدة كل البعد عن معاملات ACID "الحقيقية": في الواقع ، إنها فرصة لجعل
CAS على بيانات سجل واحد فقط ، باستخدام الإجماع على البروتوكول الثقيل Paxos. لذلك ، فإن سرعة هذه المعاملات منخفضة.
ما فاتنا في كاساندرا
لذا ، كان علينا تنفيذ معاملات ACID حقيقية في كاساندرا. باستخدام هذا يمكننا بسهولة تنفيذ ميزتين أخريين مناسبتين لنظام DBMS الكلاسيكي: فهارس سريعة متسقة ، تسمح لنا بأداء عينات البيانات ليس فقط على المفتاح الأساسي والمولد المعتاد لمعرفات الزيادة التلقائية الرتيبة.
C * واحد
لذلك وُلد نظام إدارة قواعد البيانات الجديد
C * One ، ويتكون من ثلاثة أنواع من عُقد الخادم:
- التخزين - خوادم كاساندرا القياسية (تقريبًا) المسؤولة عن تخزين البيانات على محركات الأقراص المحلية. مع نمو الحمل وكمية البيانات ، يمكن بسهولة تحجيم عددهم إلى عشرات أو مئات.
- منسقي المعاملات - تمكين تنفيذ المعاملات.
- العملاء هم خوادم التطبيقات التي تنفذ العمليات التجارية وتبدأ المعاملات. قد يكون هناك الآلاف من هؤلاء العملاء.
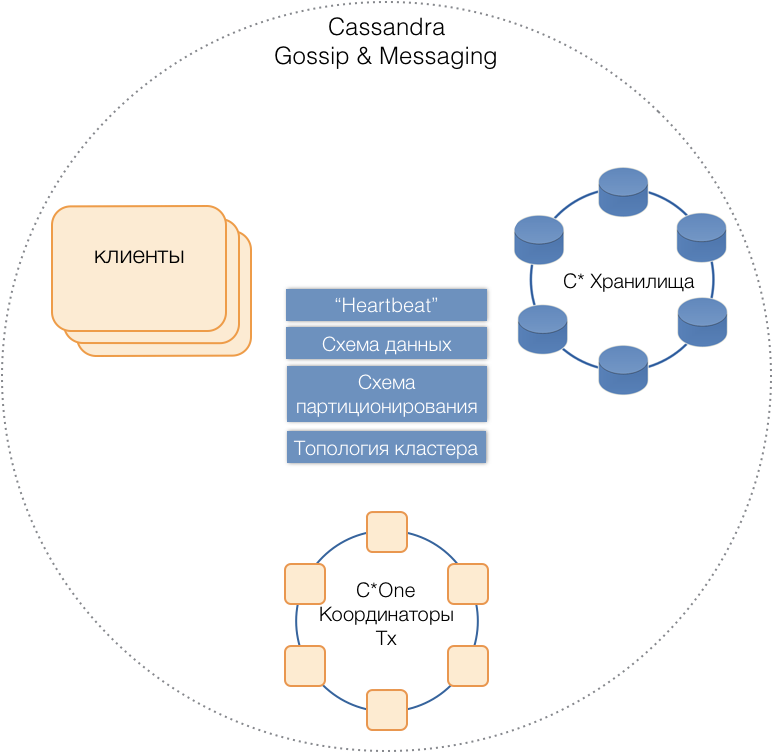
جميع أنواع الخوادم في مجموعة مشتركة ، استخدم بروتوكول رسائل كاساندرا الداخلي للتواصل مع بعضها البعض
والثرثرة لتبادل معلومات المجموعة. بمساعدة Heartbeat ، تتعرف الخوادم على الإخفاقات المتبادلة ، وتدعم مخطط بيانات واحد - الجداول ، وهيكلها وتكرارها ؛ مخطط التقسيم ، طوبولوجيا العنقود ، إلخ.
الزبائن
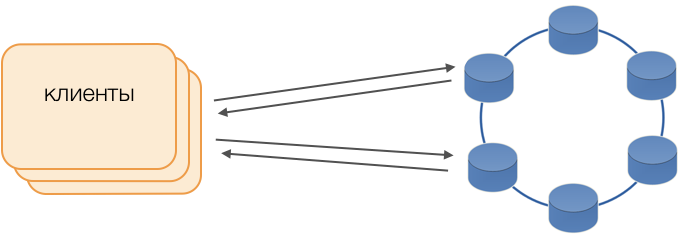
بدلاً من برامج التشغيل القياسية ، يتم استخدام وضع Fat Client. لا تقوم هذه العقدة بتخزين البيانات ، ولكنها يمكن أن تعمل كمنسق لتنفيذ الاستعلام ، أي أن العميل نفسه يؤدي وظيفة منسق طلباته: فهو يقوم باستقصاء مستودعات النسخ المتماثلة وحل التعارضات. هذا ليس فقط أكثر موثوقية وأسرع من برنامج تشغيل قياسي يتطلب الاتصال بمنسق بعيد ، ولكنه يسمح لك أيضًا بالتحكم في نقل الطلبات. خارج المعاملة المفتوحة للعميل ، يتم إرسال الطلبات إلى التخزين. إذا قام العميل بفتح المعاملة ، يتم إرسال جميع الطلبات داخل المعاملة إلى منسق المعاملات.

ج * منسق معاملات واحد
المنسق هو ما قمنا بتطبيقه لـ C * One من الصفر. وهو مسؤول عن إدارة المعاملات والأقفال وترتيب تطبيق المعاملات.
لكل معاملة تتم خدمتها ، يقوم المنسق بإنشاء طابع زمني: كل واحدة لاحقة أكبر من المعاملة السابقة. نظرًا لأن نظام حل النزاعات في كاساندرا يعتمد على الطوابع الزمنية (لسجلين متضاربين ، يعتبر السجل الحالي بأحدث طابع زمني مناسبًا) ، فسيتم حل النزاع دائمًا لصالح المعاملة اللاحقة. وهكذا ، قمنا بتطبيق
ساعات Lamport - طريقة رخيصة لحل النزاعات في نظام موزع.
أقفال
لضمان العزل ، قررنا استخدام أبسط طريقة - أقفال متشائمة على المفتاح الأساسي للسجل. بمعنى آخر ، في المعاملة ، يجب أولاً تأمين السجل ، ثم قراءته وتعديله وحفظه فقط. فقط بعد الالتزام الناجح ، يمكن فتح السجل بحيث يمكن للمعاملات المتنافسة استخدامه.
تنفيذ هذا القفل بسيط في بيئة غير مخصصة. هناك طريقتان رئيسيتان في النظام الموزع: إما تنفيذ القفل الموزع على الكتلة ، أو توزيع المعاملات بحيث يتم دائمًا خدمة المعاملات التي تنطوي على سجل واحد من قبل نفس المنسق.
نظرًا لأنه في حالتنا يتم توزيع البيانات بالفعل من قبل مجموعات المعاملات المحلية في SQL ، فقد تقرر تعيين مجموعات المعاملات المحلية للمنسقين: يقوم أحد المنسقين بإجراء جميع المعاملات برمز من 0 إلى 9 ، والثاني برمز من 10 إلى 19 ، وهكذا. نتيجة لذلك ، يصبح كل من مثيلات المنسق سيد مجموعة المعاملات.
ثم يمكن تنفيذ الأقفال على شكل HashMap عادي في ذاكرة المنسق.
فشل المنسق
نظرًا لأن أحد المنسقين يقدم حصريًا مجموعة من المعاملات ، فمن المهم جدًا تحديد حقيقة فشلها بسرعة ، بحيث تنتهي مهلة المحاولة المتكررة لتنفيذ المعاملة. لجعله سريعًا وموثوقًا به ، قمنا بتطبيق بروتوكول جلسة استماع مكتوبة بشكل كامل:
يحتوي كل مركز بيانات على عقدين منسقين على الأقل. بشكل دوري ، يرسل كل منسق رسالة نبض إلى المنسقين الآخرين ويبلغهم بوظائفهم ، وكذلك رسائل نبضات القلب التي منها المنسقون في الكتلة للمرة الأخيرة.

بعد تلقي معلومات مماثلة من الآخرين في تكوين رسائل نبضاتهم ، يقرر كل منسق لنفسه أي العقد العنقودية تعمل والتي لا تعمل ، مسترشدة بمبدأ النصاب القانوني: إذا تلقت العقدة X معلومات من غالبية العقد في المجموعة حول الاستلام العادي للرسائل من العقدة Y ، ثم ، يعمل Y. وبالعكس ، بمجرد أن تبلغ الأغلبية عن فقدان الرسائل من العقدة Y ، فإن Y قد فشلت. من الغريب أنه إذا أخبر النصاب العقدة X أنها لا تتلقى المزيد من الرسائل منها ، فإن العقدة X نفسها ستعتبر نفسها قد فشلت.
يتم إرسال رسائل نبضات القلب على تردد عالي ، حوالي 20 مرة في الثانية ، مع فترة 50 مللي ثانية. في Java ، من الصعب ضمان استجابة تطبيق تبلغ 50 مللي ثانية نظرًا للطول المماثل للإيقاف المؤقت الذي تسببه جامع البيانات المهملة. تمكنا من تحقيق مثل هذا الوقت للاستجابة باستخدام جامع القمامة G1 ، والذي يسمح لنا بتحديد الهدف طوال فترات توقف GC. ومع ذلك ، في بعض الأحيان ، نادرًا جدًا ، يتجاوز التوقف المؤقت للمجمع 50 مللي ثانية ، مما قد يؤدي إلى اكتشاف زائف للفشل. لمنع حدوث ذلك ، لا يقوم المنسق بالإبلاغ عن فشل العقدة البعيدة عندما تختفي رسالة نبضات القلب الأولى منها ، فقط في حالة اختفاء عدة رسائل متتالية. لذلك تمكنا من اكتشاف فشل عقدة المنسق في 200 مللي ثانية.
ولكن لا يكفي أن نفهم بسرعة العقدة التي توقفت عن العمل. عليك أن تفعل شيئا حيال ذلك.
الحجز
يفترض المخطط الكلاسيكي أنه في حالة رفض أحد الأساتذة إجراء انتخابات جديدة باستخدام إحدى الخوارزميات
العالمية العصرية . ومع ذلك ، فإن هذه الخوارزميات لها مشاكل معروفة مع تقارب الوقت ومدة العملية الانتخابية نفسها. تمكنا من تجنب مثل هذه التأخيرات الإضافية باستخدام دائرة المنسقين المكافئة في شبكة متصلة بالكامل:
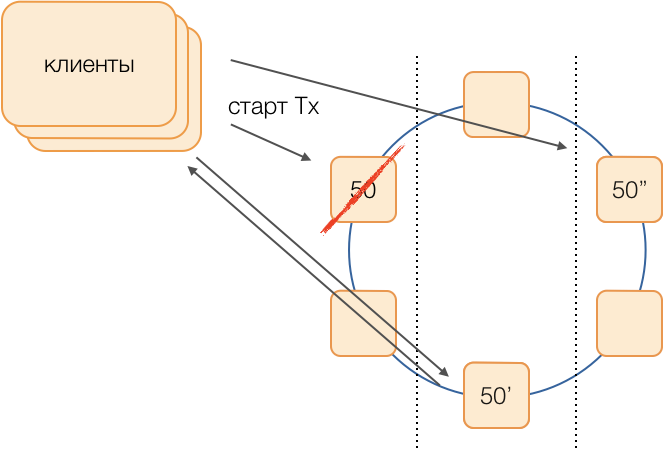
افترض أننا نرغب في تنفيذ معاملة في المجموعة 50. سنحدد مسبقًا مخطط استبدال ، أي العقد التي ستنفذ معاملات المجموعة 50 في حالة فشل المنسق الرئيسي. هدفنا هو الحفاظ على عمل النظام في حالة فشل مركز البيانات. نحدد أن الاحتياطي الأول سيكون عقدة من مركز بيانات آخر ، والاحتياطي الثاني سيكون عقدة من المركز الثالث. يتم تحديد هذا المخطط مرة واحدة ولا يتغير حتى يتغير هيكل الكتلة ، أي حتى تدخل العقد الجديدة (وهو أمر نادر الحدوث). إجراء اختيار سيد نشط جديد في حالة فشل القديم سيكون دائمًا: سيصبح الاحتياطي الأول السيد النشط ، وإذا توقف عن العمل ، سيصبح الاحتياطي الثاني.
مثل هذا المخطط أكثر موثوقية من الخوارزمية العالمية ، نظرًا لتفعيل سيد جديد ، فإنه يكفي تحديد حقيقة فشل البرنامج القديم.
ولكن كيف سيفهم العملاء أي منهم يعمل الآن؟ بالنسبة لـ 50 مللي ثانية ، لا يمكن إرسال معلومات إلى آلاف العملاء. يمكن أن يكون الموقف ممكنًا عندما يرسل العميل طلبًا لفتح معاملة ، دون معرفة بعد أن هذا المعالج لم يعد يعمل ، وسيتوقف الطلب عند انتهاء المهلة. لمنع حدوث ذلك ، يرسل العملاء بشكل تخميني طلبًا لفتح معاملة على الفور إلى رئيس المجموعة وكلا من احتياطياته ، ولكن الشخص الوحيد الذي هو سيد نشط في الوقت الحالي هو الذي سيجيب على هذا الطلب. سيقوم العميل بإجراء جميع الاتصالات اللاحقة داخل المعاملة فقط مع السيد النشط.
يتلقى سادة النسخ الاحتياطي طلبات للمعاملات غير الخاصة في قائمة انتظار المعاملات التي لم تولد بعد ، حيث يتم تخزينها لبعض الوقت. إذا مات الرئيسي النشط ، يعالج الرئيسي الجديد طلبات فتح المعاملات من قائمة الانتظار ويستجيب للعميل. إذا تمكن العميل بالفعل من فتح معاملة مع السيد القديم ، فسيتم تجاهل الاستجابة الثانية (ومن الواضح أن هذه المعاملة لن تكتمل وسيكررها العميل).
كيف تعمل الصفقة
افترض أن العميل أرسل إلى المنسق طلبًا لفتح معاملة لهذا الكيان باستخدام هذا المفتاح الأساسي. يقوم المنسق بتأمين هذا الكيان ووضعه في جدول القفل في الذاكرة. إذا لزم الأمر ، يقرأ المنسق هذا الكيان من المخزن ويخزن البيانات المستلمة في حالة المعاملات في ذاكرة المنسق.
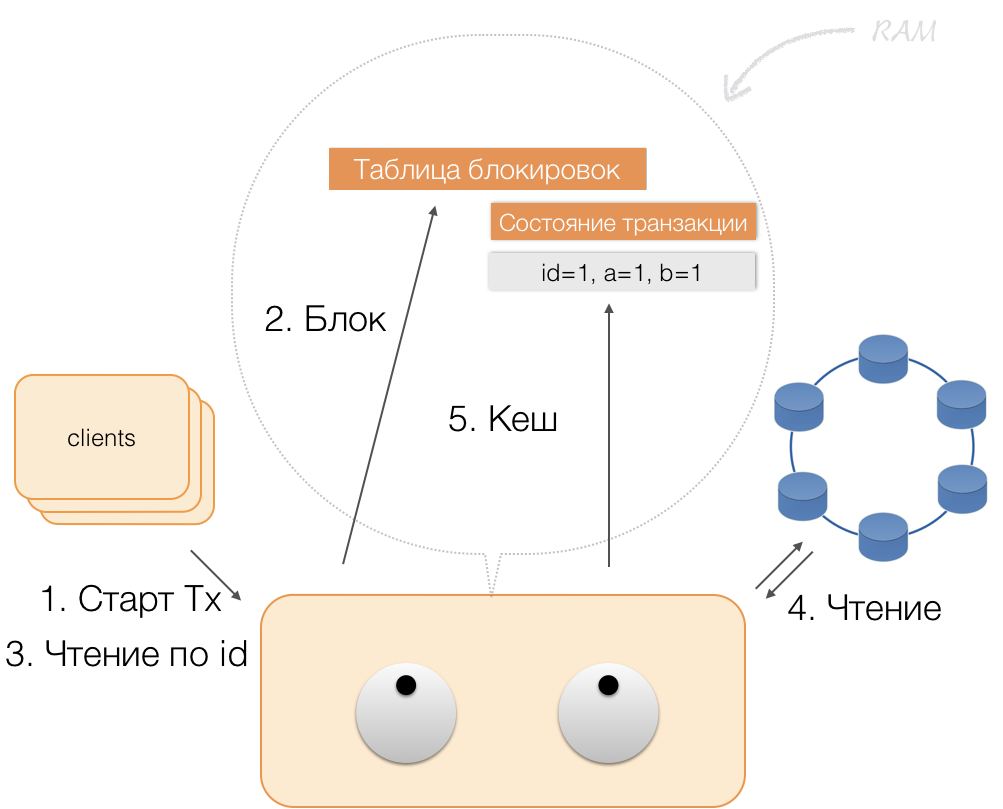
عندما يريد العميل تغيير البيانات في المعاملة ، يرسل إلى المنسق طلبًا لتحديث الكيان ، ويضع البيانات الجديدة في جدول حالة المعاملة في الذاكرة. يكتمل هذا التسجيل - لا يتم التسجيل في المستودع.
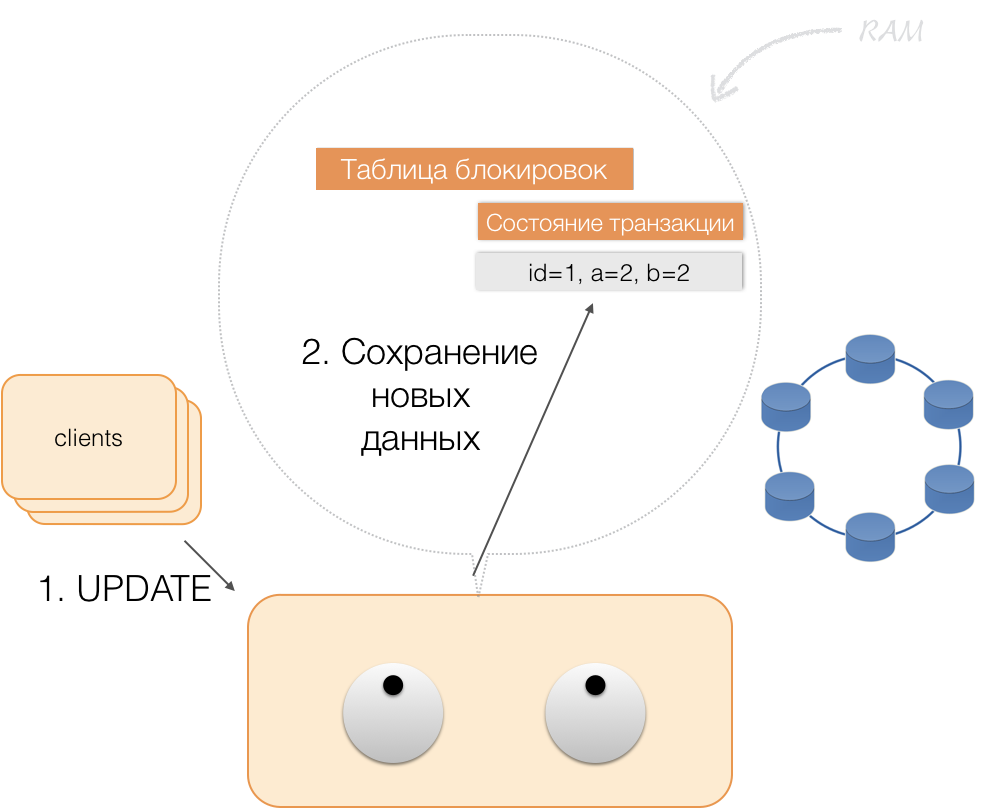
عندما يطلب العميل ، في إطار معاملة نشطة ، بياناته المتغيرة الخاصة به ، يعمل المنسق على النحو التالي:
- إذا كان المعرّف موجودًا بالفعل في المعاملة ، فسيتم أخذ البيانات من الذاكرة ؛
- إذا لم يكن هناك معرف في الذاكرة ، فسيتم قراءة البيانات المفقودة من عقد التخزين ، مع تلك الموجودة بالفعل في الذاكرة ، ويتم إرجاع النتيجة إلى العميل.
وبالتالي ، يمكن للعميل قراءة التغييرات الخاصة به ، بينما لا يرى العملاء الآخرون هذه التغييرات ، لأنها مخزنة فقط في ذاكرة المنسق ، فهي ليست في عقد كاساندرا بعد.
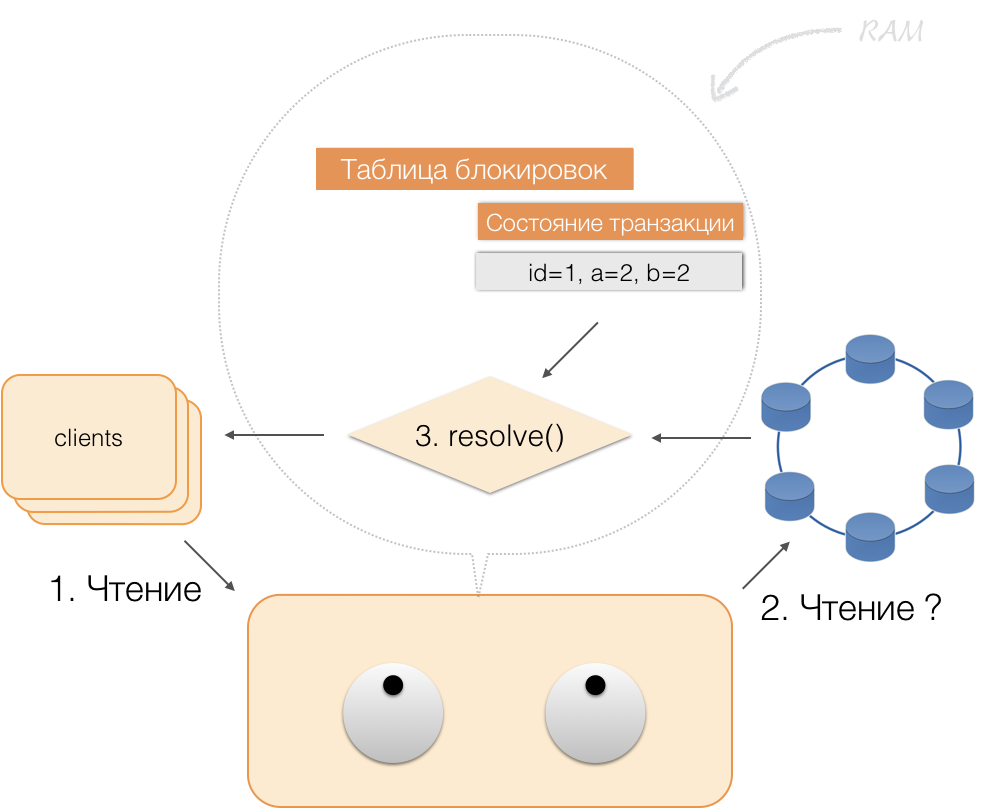
عندما يرسل العميل تعهدًا ، يتم حفظ الحالة في ذاكرة الخدمة بواسطة المنسق في الدفعة المسجلة ، ويتم بالفعل في شكل دفعة مسجلة إرسالها إلى مستودعات Cassandra. تقوم المستودعات بكل ما هو ضروري لتطبيق هذه الحزمة تلقائيًا (بشكل كامل) ، وإعادة الرد إلى المنسق ، الذي يطلق الأقفال ويؤكد نجاح المعاملة للعميل.

وللرجوع إلى المنسق ، يكفي تحرير الذاكرة التي تشغلها حالة المعاملة.
نتيجة للتحسينات المذكورة أعلاه ، قمنا بتطبيق مبادئ ACID:
- الذرية . يعد هذا ضمانًا بعدم التزام أي معاملة جزئيًا بالنظام ، أو استكمال جميع عملياته الفرعية ، أو عدم تنفيذ عملية واحدة. نحن نلتزم بهذا المبدأ بسبب الدفعة المسجلة في كاساندرا.
- التماسك . كل معاملة ناجحة ، بحكم تعريفها ، تلتقط نتائج مقبولة فقط. إذا تبين ، بعد فتح معاملة وتنفيذ جزء من العمليات ، أن النتيجة غير صالحة ، يتم تنفيذ التراجع.
- العزلة . عند تنفيذ المعاملة ، يجب ألا تؤثر المعاملات الموازية على نتيجتها. يتم عزل المعاملات المتنافسة باستخدام أقفال متشائمة على المنسق. بالنسبة للقراءات خارج المعاملة ، يتم احترام مبدأ العزل على مستوى قراءة الالتزام.
- الاستدامة . بغض النظر عن المشاكل في المستويات الأدنى - إلغاء تنشيط النظام ، وفشل الأجهزة ، - يجب أن تظل التغييرات التي تم إجراؤها بواسطة معاملة مكتملة بنجاح محفوظة بعد استئناف العملية.
قراءة الفهرس
خذ طاولة بسيطة:
CREATE TABLE photos ( id bigint primary key, owner bigint, modified timestamp, …)
لديها رقم تعريف (مفتاح أساسي) ومالك وتاريخ التغيير. تحتاج إلى تقديم طلب بسيط للغاية - حدد معلومات المالك بتاريخ التغيير "في اليوم الأخير".
SELECT * WHERE owner=? AND modified>?
لكي يعمل هذا الاستعلام بسرعة ، في SQL DBMS الكلاسيكي ، تحتاج إلى إنشاء فهرس حسب الأعمدة (مالك ، معدّل). يمكننا القيام بذلك بكل بساطة ، حيث لدينا الآن ضمانات ACID!
المؤشرات في C * One
يوجد جدول مصدر به صور ، حيث يكون معرف السجل هو المفتاح الأساسي.

بالنسبة للمؤشر C * ، يقوم المرء بإنشاء جدول جديد ، وهو نسخة من الأصل. يتطابق المفتاح مع تعبير الفهرس ، ويتضمن أيضًا المفتاح الأساسي للسجل من الجدول المصدر:
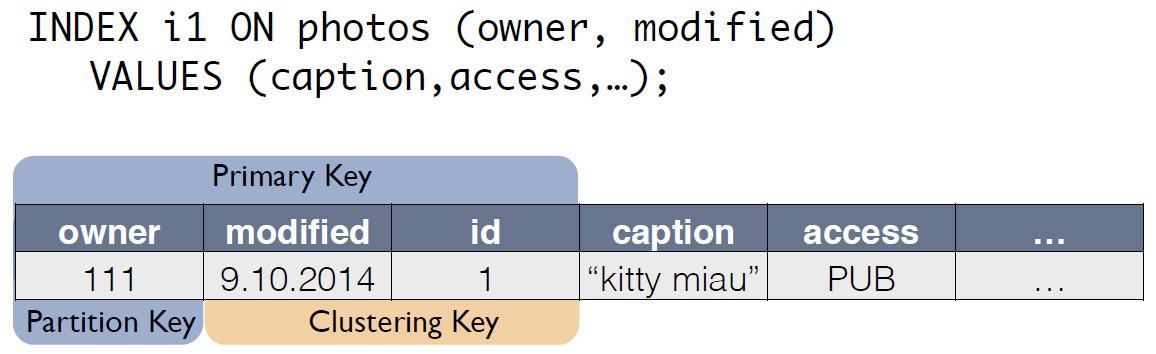
يمكن الآن إعادة كتابة طلب "المالك لليوم الأخير" على النحو المحدد من جدول آخر:
SELECT * FROM i1_test WHERE owner=? AND modified>?
يتم الحفاظ على اتساق البيانات من جدول الصور الأصلية والفهرس i1 تلقائيًا بواسطة المنسق. استنادًا إلى مخطط البيانات وحده ، عند تلقي التغيير ، يقوم المنسق بإنشاء التغيير وتذكره ليس فقط في الجدول الرئيسي ، ولكن أيضًا في تغييرات النسخ. لا يتم تنفيذ أي إجراءات إضافية مع جدول الفهرس ، ولا تتم قراءة السجلات ، ولا يتم استخدام الأقفال. أي أن إضافة الفهارس لا تستهلك الموارد تقريبًا ولا تؤثر عمليًا على سرعة تطبيق التعديلات.
باستخدام ACID ، تمكنا من تنفيذ الفهارس "مثل SQL". لديهم اتساق ، يمكن تحجيمها ، العمل بسرعة ، يمكن أن تكون مركبة ومدمجة في لغة استعلام CQL.
لدعم الفهارس ، لا تحتاج إلى إجراء تغييرات على رمز التطبيق. كل شيء بسيط ، كما هو الحال في SQL. والأهم من ذلك أن الفهارس لا تؤثر على سرعة تنفيذ التعديلات على جدول المعاملات الأصلي.ماذا حدث
قمنا بتطوير C * One قبل ثلاث سنوات ووضعناها في التشغيل التجاري.ماذا حصلنا في النهاية؟ دعنا نقيم هذا باستخدام مثال نظام فرعي لمعالجة الصور وتخزينها ، وهو أحد أهم أنواع البيانات في الشبكة الاجتماعية. لا يتعلق الأمر بأجسام الصور نفسها ، ولكن حول جميع أنواع المعلومات الوصفية. الآن في Odnoklassniki هناك حوالي 20 مليار من هذه السجلات ، يعالج النظام 80 ألف طلب قراءة في الثانية ، يصل إلى 8 آلاف معاملة ACID في الثانية المرتبطة بتعديل البيانات.عندما استخدمنا SQL مع عامل النسخ المتماثل = 1 (ولكن في RAID 10) ، تم تخزين المعلومات الوصفية للصور على مجموعة يسهل الوصول إليها من 32 جهازًا مع Microsoft SQL Server (بالإضافة إلى 11 نسخة احتياطية). كما خصصت 10 خوادم لتخزين النسخ الاحتياطية. ما مجموعه 50 سيارة باهظة الثمن. في الوقت نفسه ، عمل النظام في الحمل المقنن ، دون احتياطي.بعد الترحيل إلى النظام الجديد ، حصلنا على عامل النسخ = 3 - نسخة في كل مركز بيانات. يتكون النظام من 63 عقد تخزين كاساندرا و 6 آلات تنسيق ، بإجمالي 69 خادم. لكن هذه الأجهزة أرخص بكثير ، وتبلغ تكلفتها الإجمالية حوالي 30 ٪ من تكلفة النظام في SQL. في هذه الحالة ، يتم الاحتفاظ بالحمل بنسبة 30٪.مع تقديم C * One ، انخفضت التأخيرات أيضًا: في SQL ، استغرقت عملية الكتابة حوالي 4.5 مللي ثانية. في C * One - حوالي 1.6 مللي ثانية. مدة المعاملة في المتوسط أقل من 40 مللي ثانية ، ويتم التنفيذ في 2 مللي ثانية ، ومدة القراءة والكتابة في المتوسط 2 مللي ثانية. النسبة المئوية 99 - 3-3.1 مللي ثانية فقط ، وانخفض عدد المهلات 100 مرة - كل ذلك بسبب الاستخدام الواسع للمضاربة.حتى الآن ، تم إيقاف تشغيل معظم عقد SQL Server ؛ يتم تطوير المنتجات الجديدة فقط باستخدام C * One. لقد قمنا بتكييف C * One للعمل في سحابة واحدة ، مما سمح لنا بتسريع نشر مجموعات جديدة ، وتبسيط التكوين وتشغيل التشغيل التلقائي. بدون شفرة المصدر ، سيكون الأمر أكثر صعوبة وصنع عكاز.نعمل الآن على نقل مرافق التخزين الأخرى إلى السحابة - لكن هذه قصة مختلفة تمامًا.