
هذا استمرار للجزء الأول من المقال.
في الجزء الأول من المقال ، تحدث المؤلف عن شروط المسابقة للعبة Agario على mail.ru ، وبنية عالم اللعبة وجزئياً حول هيكل الروبوت. جزئيا ، لأنها أثرت فقط على جهاز استشعار الإدخال والأوامر عند الإخراج من الشبكة العصبية (فيما يلي في الصور والنصوص سيكون هناك اختصار NN). لذا دعونا نحاول فتح الصندوق الأسود ونفهم كيف يتم ترتيب كل شيء هناك.
وها هي الصورة الأولى:
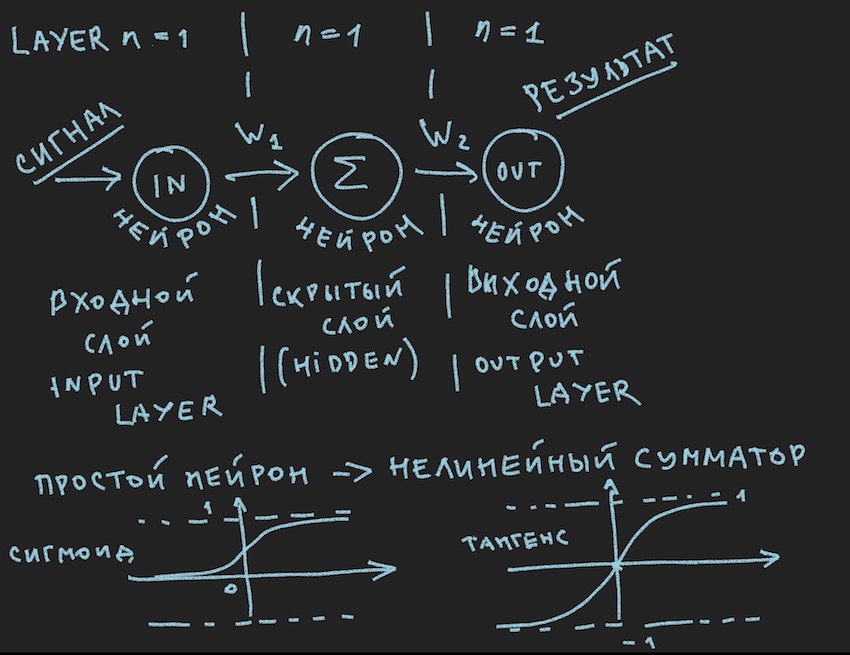
يصور بشكل تخطيطي ما يجب أن يسبب ابتسامة مللة من قارئي ، كما يقولون مرة أخرى في الصف الأول ، لقد شوهدوا عدة مرات في مصادر مختلفة . لكننا نريد حقًا تطبيق هذه الصورة عمليًا على إدارة برنامج التتبُّع ، لذلك نلقي نظرة فاحصة عليها بعد الملاحظة المهمة.
ملاحظة مهمة: هناك عدد كبير من الحلول الجاهزة (الأطر) للعمل مع الشبكات العصبية:

تحل جميع هذه الحزم المهام الرئيسية لمطور الشبكات العصبية: بناء وتدريب NN أو البحث عن أوزان "مثالية". والطريقة الرئيسية لهذا البحث هي الانتشار العكسي . تم اختراعه في السبعينيات من القرن الماضي ، كما يشير المقال في الرابط أعلاه ، خلال هذا الوقت ، حيث اكتسب الجزء السفلي من السفينة تحسينات مختلفة ، ولكن الجوهر هو نفسه: العثور على معاملات الوزن مع قاعدة من أمثلة التدريب ومن المستحسن للغاية أن الجميع تحتوي هذه الأمثلة على إجابة جاهزة في شكل إشارة خرج لشبكة عصبية. القارئ قد يعترض علي. أن شبكات التعلم الذاتي من مختلف الطبقات والمبادئ قد تم اختراعها بالفعل ، ولكن كل شيء لا يسير على ما يرام هناك ، على حد علمي. بالطبع ، هناك خطط لدراسة حديقة الحيوان هذه بمزيد من التفصيل ، ولكن أعتقد أنني سأجد أشخاصًا يشبهونك التفكير في أن دراجة مصنوعة يدويًا ، حتى الأكثر انحناءًا ، أقرب إلى قلب المبدع من استنساخ ناقل لدراجة مثالية.
إدراكًا أن خادم الألعاب على الأرجح لن يكون لديه هذه المكتبات وأن قوة الحوسبة المخصصة من قبل المنظمين لأن جوهر المعالج 1 لا يكفي بشكل واضح لإطار ثقيل ، ذهب المؤلف إلى إنشاء دراجته الخاصة. انتهى تعليق هام على هذا.
دعنا نعود إلى الصورة التي تصور على الأرجح أبسط الشبكات العصبية الممكنة مع طبقة مخفية (تعرف أيضًا باسم الطبقة المخفية أو الطبقة المخفية). الآن الكاتب نفسه يحدق بثبات في الصورة بأفكار حول هذا المثال البسيط ليكشف للقارئ أعماق الشبكات العصبية الاصطناعية. عندما يتم تبسيط كل شيء إلى بدائي ، يكون من الأسهل فهم الجوهر. خلاصة القول هي أن الخلايا العصبية للطبقة المخفية ليس لديها ما تلخصه. والأرجح أن هذه ليست شبكة عصبية ، حيث أن أبسط NN في الكتب هو شبكة ذات مدخلين. لذلك نحن هنا ، كما كانوا ، مكتشفين لأبسط الشبكات.
دعونا نحاول وصف هذه الشبكة العصبية (الكود الزائف):
نقدم طوبولوجيا الشبكة في شكل صفيف ، حيث يتوافق كل عنصر مع الطبقة وعدد الخلايا العصبية الموجودة فيها:
int array Topology= { 1, 1, 1}
نحتاج أيضًا إلى مجموعة عائمة من أوزان الشبكة العصبية W ، مع الأخذ في الاعتبار شبكتنا "الشبكات العصبية إلى الأمام (FF أو FFNN)" ، حيث يتم توصيل كل خلية عصبية من الطبقة الحالية بكل عصبون من الطبقة التالية ، نحصل على أبعاد الصفيف W [عدد الطبقات ، عدد الخلايا العصبية في الطبقة ، عدد الخلايا العصبية في الطبقة]. ليس التشفير الأمثل تمامًا ، ولكن نظرًا لأن التنفس الساخن لوحدة معالجة الرسومات في مكان قريب جدًا من النص ، فهذا أمر مفهوم.
إجراء CalculateSize قصير CalculateSize عدد الخلايا العصبية العصبية وعدد اتصالاتها في الشبكة العصبية neuroncount ، أعتقد أنه سيشرح بشكل أفضل للمؤلف طبيعة هذه الاتصالات:
void CalculateSize(array int Topology, int neuroncount, int dendritecount) { for (int i : Topology) // i neuroncount += i; for (int layer = 0, layer <Topology.Length - 1, layer++) // for (int i = 0, i < Topology[layer] + 1, i++) // for (int j = 0, j < Topology[layer + 1], j++) // dendritecount++; }
قاريئي ، الشخص الذي يعرف كل هذا بالفعل ، جاء المؤلف إلى هذا الرأي في المقالة الأولى ، بالتأكيد لن يسأل: لماذا في الحلقة الثالثة من الطوبولوجيا المتداخلة [layer1 + 1] بدلاً من Topology [layer1] ، والتي تعطي المزيد من الخلايا العصبية أكثر من طبولوجيا الشبكة . لن أجيب. من المفيد أيضًا أن يسأل القارئ الواجبات المنزلية.
نحن على بعد خطوة تقريبًا من بناء شبكة عصبية عاملة. يبقى إضافة وظيفة جمع الإشارات عند إدخال العصبون وتنشيطه. هناك العديد من وظائف التنشيط ، ولكن الأقرب إلى طبيعة العصبون هي السيني والتانجينسويد (ربما من الأفضل تسميته أنه على الرغم من عدم استخدام هذا الاسم بشكل خاص في الأدب ، فإن الحد الأقصى هو الظل ، ولكن هذا هو اسم الرسم البياني ، على الرغم من ما هو الرسم البياني إذا لم يكن انعكاسًا للوظيفة؟)
لذلك لدينا هنا وظائف تنشيط الخلايا العصبية (وهي موجودة في الصورة ، في الجزء السفلي منها)
float Sigmoid(float x) { if (x < -10.0f) return 0.0f; else if (x > 10.0f) return 1.0f; return (float)(1.0f / (1.0f + expf(-x))); }
يُرجع السيني القيم من 0 إلى 1.
float Tanh(float x) { if (x < -10.0f) return -1.0f; else if (x > 10.0f) return 1.0f; return (float)(tanhf(x)); }
يعرض المماس tangentoid القيم من -1 إلى 1.
الفكرة الرئيسية لإشارة تمر عبر الشبكة العصبية هي الموجة: يتم تغذية الإشارة لإدخال الخلايا العصبية -> من خلال الاتصالات العصبية ، تنتقل الإشارة إلى الطبقة الثانية -> تلخص الخلايا العصبية من الطبقة الثانية الإشارات التي وصلت إليها تغيرت من خلال الأوزان الداخلية -> تتم إضافتها من خلال وزن تحيز إضافي -> نستخدم وظيفة التنشيط> و wu-al ننتقل إلى الطبقة التالية (اقرأ الدورة الأولى من المثال بالطبقات) ، أي تكرار السلسلة من البداية فقط الخلايا العصبية للطبقة التالية ستصبح الخلايا العصبية المدخلة. في التبسيط ، لا تحتاج حتى إلى تخزين قيم الخلايا العصبية للشبكة بأكملها ، ما عليك سوى تخزين أوزان NN وقيم الخلايا العصبية للطبقة النشطة.
مرة أخرى ، نرسل إشارة إلى المدخلات NN ، تمر الموجة عبر الطبقات وعلى طبقة الإخراج نزيل القيمة التي تم الحصول عليها.
هنا ، من طعم القارئ ، من الممكن حل المشكلة برمجيًا باستخدام العودية أو مجرد دورة ثلاثية مثل المؤلف ، لتسريع الحسابات ، لا تحتاج إلى تسييج الأشياء في شكل الخلايا العصبية واتصالاتها وغيرها من OOP. مرة أخرى ، هذا يرجع إلى الشعور بحسابات GPU القريبة ، وعلى GPUs ، بسبب طبيعتها للتوازي الجماعي ، يتوقف OOP قليلاً ، وهذا يتعلق بـ c # و C ++.
علاوة على ذلك ، القارئ مدعو للذهاب بشكل مستقل إلى طريقة بناء شبكة عصبية في التعليمات البرمجية ، مع رغبة قارئه طواعية ، وغيابها واضح تمامًا ومألوف للمؤلف ، كما هو الحال في أمثلة بناء NN من الصفر ، هناك الكثير من الأمثلة في الشبكة ، لذلك سيكون من الصعب أن تضل ، هكذا مباشرة مثل الشبكة العصبية للتوزيع المباشر في الصورة أعلاه.
ولكن أين يصرخ القارئ ، الذي لم يبتعد بعد عن المقطع السابق ، وسيكون على حق في الطفولة ، حدد المؤلف قيمة الكتاب من خلال الرسوم التوضيحية له. هنا أنت:
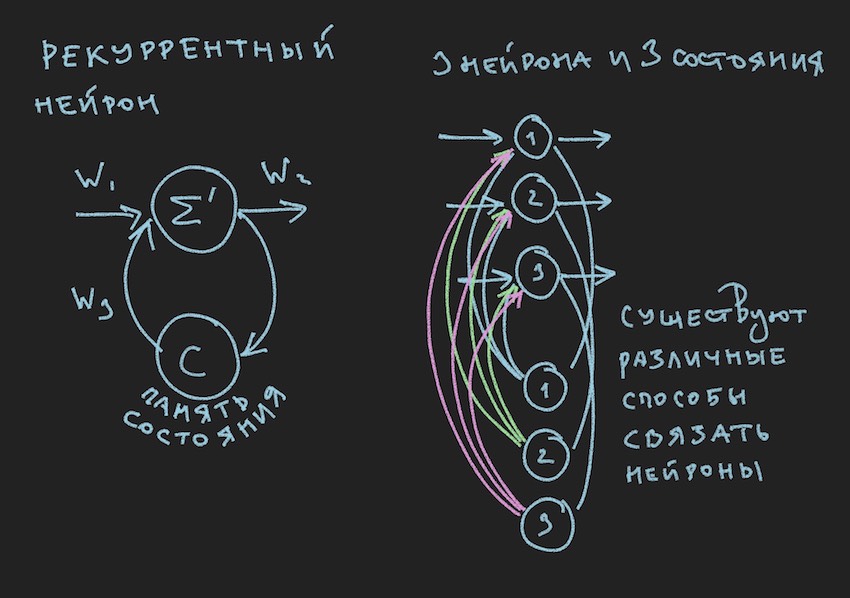
في الصورة نرى خلية عصبية متكررة و NN بنيت من هذه الخلايا العصبية تسمى RNN المتكررة. تحتوي الشبكة العصبية المحددة على ذاكرة قصيرة المدى وتم اختيارها من قبل المؤلف للبوت باعتبارها الأكثر وعدًا من حيث التكيف مع عملية اللعبة. بالطبع ، بنى المؤلف شبكة عصبية التوزيع المباشر ، ولكن في عملية البحث عن حل "فعال" تحول إلى RNN.
للخلايا العصبية المتكررة حالة إضافية C ، والتي يتم تشكيلها بعد مرور الإشارة الأولى عبر الخلايا العصبية ، Tick + 0 على الخط الزمني. بكلمات بسيطة ، هذه نسخة من إشارة خرج العصبون. في الخطوة الثانية ، اقرأ Tick + 1 (نظرًا لأن الشبكة تعمل بتردد روبوت اللعبة والخادم) ، تعود القيمة C إلى إدخال الطبقة العصبية من خلال أوزان إضافية وبالتالي تشارك في تكوين الإشارة ، ولكن بالفعل في Tick + 1 مرة.
ملاحظة: في عمل المجموعات البحثية فيما يتعلق بإدارة روبوتات لعبة NN ، هناك ميل لاستخدام إيقاعين لشبكة عصبية ، إيقاع واحد هو تكرار اللعبة Tick ، والإيقاع الثاني ، على سبيل المثال ، ضعيف مثل الأول. تعمل أجزاء مختلفة من NN على ترددات مختلفة ، مما يعطي رؤية مختلفة لوضع اللعبة داخل NN ، وبالتالي زيادة مرونتها.
لبناء RNN في رمز البوت ، نقدم صفيفًا إضافيًا في الطوبولوجيا ، حيث يتوافق كل عنصر مع الطبقة وعدد الحالات العصبية فيها:
int array TopologyNN= { numberofSensors, 16, 8, 4}
int array TopologyRNN= { 0, 16, 0, 0 }
يمكن أن نلاحظ من الطبولوجيا أعلاه أن الطبقة الثانية متكررة ، لأنها تحتوي على حالات عصبية. كما نقدم أيضًا أوزانًا إضافية على شكل تعويم لصفيف WRR ، وهو نفس البعد مثل صفيف W.
سيتغير عدد الاتصالات في شبكتنا العصبية قليلاً:
for (int layer = 0, layer < TopologyNN.Length - 1, layer++) for (int i = 0, i < TopologyNN[layer] + 1, i++) for (int j = 0, j < TopologyNN[layer + 1] , j++) dendritecount++; for (int layer = 0, layer < TopologyRNN.Length - 1, layer++) for (int i = 0, i< TopologyRNN[layer] + 1 , i++) for (int j = 0, j< TopologyRNN[layer], j++) dendritecount++;
سيرفق المؤلف الشفرة العامة لشبكة عصبية متكررة في نهاية هذه المقالة ، ولكن الشيء الرئيسي الذي يجب فهمه هو المبدأ: مرور الموجة من خلال طبقات في حالة NN المتكررة لا يغير أي شيء بشكل أساسي ، يتم إضافة مصطلح واحد فقط إلى وظيفة التنشيط العصبي. هذا هو مصطلح حالة الخلايا العصبية في القراد السابق مضروبًا في وزن الاتصال العصبي.
نفترض أن نظرية وممارسة الشبكات العصبية قد تم تحديثها ، لكن المؤلف يدرك بوضوح أنه لم يقرب القارئ من فهم كيفية تعليم هذا الهيكل البسيط للشبكات العصبية لاتخاذ أي قرارات في اللعب. ليس لدينا مكتبات بها أمثلة لتدريس NN. في مجموعات الإنترنت لمطوري برامج الروبوت ، كان هناك رأي: أعطنا ملف سجل على شكل إحداثيات الروبوتات ومعلومات اللعبة الأخرى لتشكيل مكتبة من الأمثلة. لكن المؤلف ، للأسف ، لم يتمكن من معرفة كيفية استخدام ملف السجل هذا لتدريب NN. سأكون سعيدا لمناقشة هذا في التعليقات على المقال. لذلك ، كانت الطريقة الوحيدة المتاحة للمؤلف لفهم طريقة التدريب ، أو بالأحرى إيجاد توازن عصبي "فعال" (اتصالات عصبية) ، هي الخوارزمية الجينية.
أعدت صورة عن مبادئ الخوارزمية الجينية:
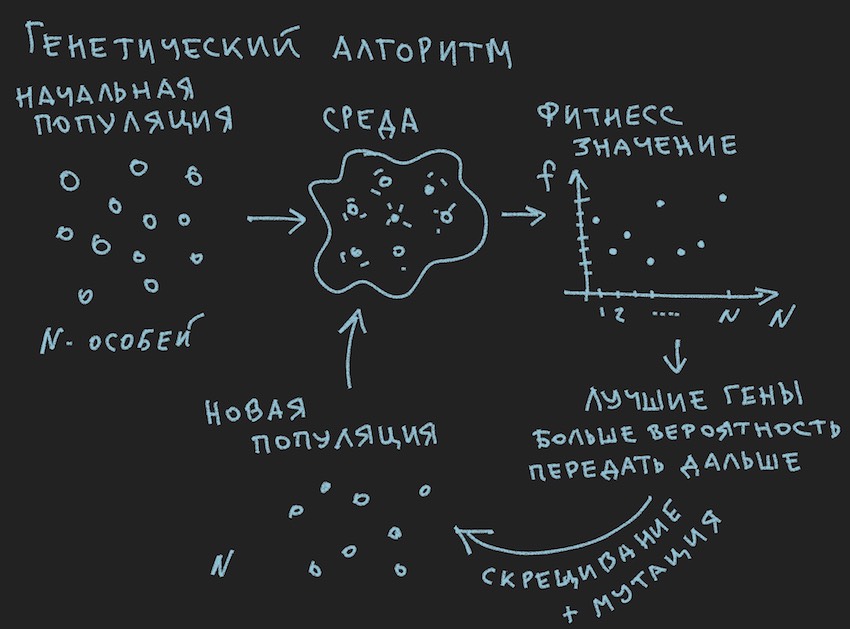
إذن الخوارزمية الجينية .
سيحاول المؤلف عدم الخوض في نظرية هذه العملية ، ولكن تذكر فقط الحد الأدنى الضروري لمواصلة القراءة الكاملة للمقال.
في الخوارزمية الجينية ، السوائل العاملة الرئيسية هي الجين (DNA هو اسم الجزيء). الجينوم في حالتنا هو مجموعة متتابعة من الجينات أو مجموعة أحادية البعد من الطفو الطويل ...
في المرحلة الأولى من العمل مع شبكة عصبية حديثة البناء ، من الضروري تهيئة الشبكة. يشير التهيئة إلى تعيين قيم عشوائية من -1 إلى 1 إلى التوازنات العصبية. وقد استوفى المؤلف أن نطاق القيم من -1 إلى 1 شديد التطرف وأن الشبكات المدربة لها أوزان في نطاق أصغر ، على سبيل المثال ، من -0.5 إلى 0.5 وأنه يجب أن تأخذ نطاقًا أوليًا من القيم الممتازة من -1 إلى 1. ولكننا سنذهب بالطريقة الكلاسيكية لجمع كل الصعوبات في بوابة واحدة ونأخذ أكبر شريحة ممكنة من المتغيرات العشوائية الأولية كأساس لتهيئة الشبكة العصبية.
الآن سيحدث انحياز . سنفترض أن طول (حجم) جينوم البوت سيكون مساوياً للطول الكلي لمصفوفات الشبكة العصبية TopologyNN.Length + TopologyRNN. الطول ليس من أجل لا شيء أن المؤلف قضى وقت القارئ على إجراء حساب الاتصالات العصبية.
ملاحظة: كما لاحظ القارئ بالفعل لنفسه ، فإننا لا ننقل سوى أوزان الشبكة العصبية إلى النمط الجيني ، ولا يتم نقل بنية الاتصال ووظائف التنشيط وحالات الخلايا العصبية. بالنسبة للخوارزمية الجينية ، يكفي فقط الاتصالات العصبية ، مما يشير إلى أنها حاملات المعلومات. هناك تطورات حيث تغير الخوارزمية الجينية أيضًا بنية الاتصالات في الشبكة العصبية ومن السهل جدًا تنفيذها. هنا ، يترك المؤلف مجالًا للإبداع للقارئ ، على الرغم من أنه هو نفسه سيفكر في الأمر باهتمام: تحتاج إلى فهم استخدام جينومين مستقلين ووظيفتين للياقة البدنية (مبسطتين خوارزميات جينية مستقلة) أو يمكنك جميعًا استخدام نفس الجين والخوارزمية.
وبما أننا قمنا بتهيئة NN بمتغيرات عشوائية ، فقد قمنا بتهيئة الجينوم. العملية العكسية ممكنة أيضًا: تهيئة النمط الجيني عن طريق المتغيرات العشوائية ونسخها اللاحق في الأوزان العصبية. الخيار الثاني شائع. نظرًا لأن الخوارزمية الجينية في البرنامج غالبًا ما توجد بصرف النظر عن الجوهر نفسه ولا ترتبط به إلا ببيانات الجينوم وقيمة وظيفة اللياقة البدنية ... توقف ، توقف ، سيقول القارئ ، فإن الصورة تظهر بوضوح السكان وليس كلمة عن الجينوم الفردي.
حسنًا ، أضف بعض الصور إلى أذهان القارئ:
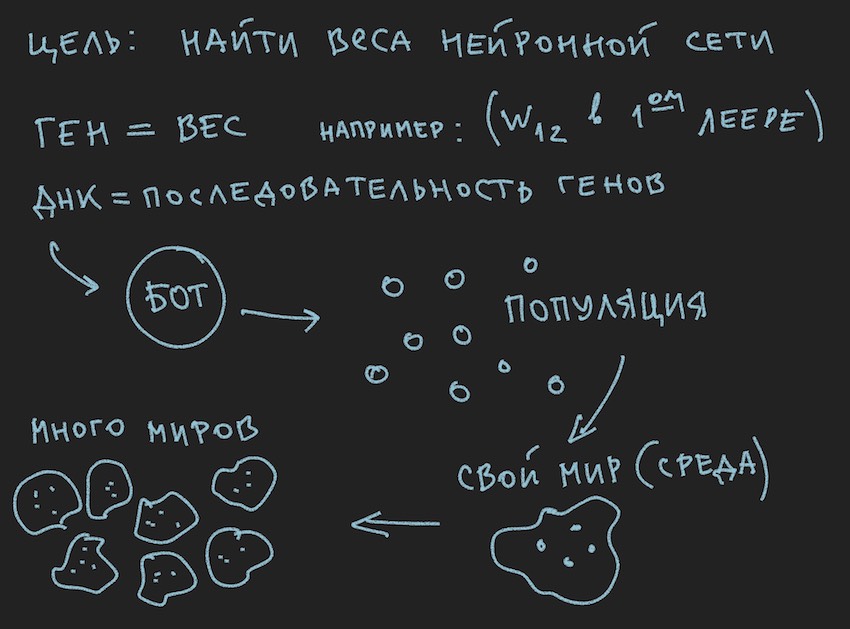
بما أن المؤلف رسم الصور قبل كتابة نص المقالة ، فإنهم يدعمون النص ، لكنهم لا يتبعون الرسالة إلى خطاب القصة الحالية.
من المعلومات المستمدة ، يتبع ذلك أن الجسم العامل الرئيسي للخوارزمية الجينية هو مجموعة من الجينومات . هذا يتناقض قليلاً مع ما قاله المؤلف سابقًا ، ولكن كيف يمكن فعله في العالم الحقيقي بدون تناقضات صغيرة. بالأمس ، تدور الشمس حول الأرض ، واليوم يتحدث المؤلف عن الشبكة العصبية داخل برنامج الروبوت. لا عجب أن يتذكر فرن العقل.
أنا أثق في أن القارئ نفسه سيحل قضية تناقضات العالم. عالم الروبوت مكتفٍ ذاتيًا تمامًا للمقال.
لكن ما استطاع المؤلف فعله ، في هذا الجزء من المقالة ، هو تشكيل مجموعة من الروبوتات.
دعونا نلقي نظرة عليه من جانب البرنامج:
يوجد Bot (يمكن أن يكون كائنًا في OOP ، بنية ، على الرغم من أنه ربما يكون أيضًا كائنًا أو مجرد مجموعة من البيانات). في الداخل ، يحتوي بوت على معلومات حول إحداثياته وسرعته وكتلته ومعلومات أخرى مفيدة في عملية اللعبة ، ولكن الشيء الرئيسي بالنسبة لنا الآن هو أنه يحتوي على رابط إلى نوعه الجيني أو نوعه الجيني نفسه ، اعتمادًا على التنفيذ. ثم يمكنك الذهاب بطرق مختلفة ، وتقييد نفسك بمصفوفات من أوزان الشبكة العصبية أو تقديم مجموعة إضافية من الأنماط الجينية ، حيث سيكون من الملائم للقارئ أن يتخيل ذلك في خيالهم. في المراحل الأولى ، خصص المؤلف في البرنامج صفائف للتوازن العصبي والأنماط الجينية. ثم رفض تكرار المعلومات وقصر نفسه على أوزان الشبكة العصبية.
باتباع منطق القصة ، تحتاج إلى معرفة أن مجموعة الروبوتات هي مجموعة من الروبوتات المذكورة أعلاه. ما حلقة اللعبة ... توقف مرة أخرى ، ما دورة اللعبة؟ قدم المطورون بأدب مكانًا لبوت واحد فقط على متن برنامج محاكاة عالم اللعبة على خادم أو بحد أقصى أربعة برامج روبوت في جهاز محاكاة محلي. وإذا كنت تتذكر طوبولوجيا الشبكة العصبية التي اختارها المؤلف:
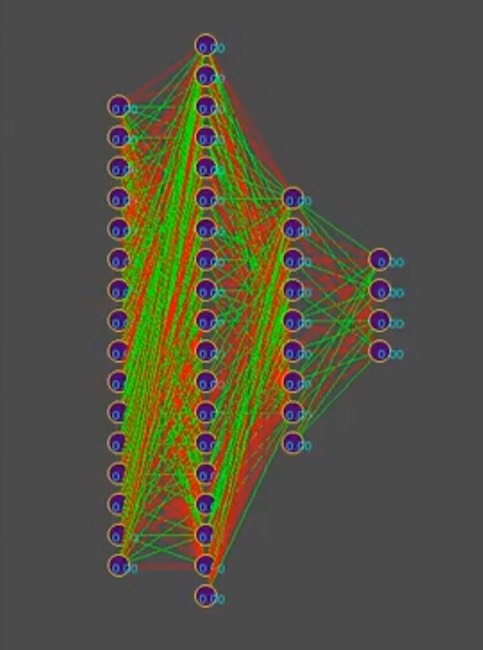
ولتبسيط القصة ، افترض أن النمط الجيني يحتوي على ما يقرب من 1000 اتصال عصبي ، بالمناسبة ، في المحاكاة ، تبدو الأنماط الجينية على هذا النحو (الأحمر هو قيمة جينية سلبية ، الأخضر قيمة موجبة ، كل سطر هو جينوم منفصل):

ملاحظة للصورة: بمرور الوقت ، يتغير النمط في اتجاه هيمنة أحد الحلول ، والخطوط الرأسية هي جينات النمط الجيني الشائعة.
لذا ، لدينا 1000 جين في النمط الجيني وأربعة روبوتات كحد أقصى في برنامج محاكاة عالم اللعبة من منظمي المسابقة. كم عدد المرات التي تحتاج فيها لتشغيل محاكاة لمعركة الروبوتات بحيث تقترب القوة الوحشية ، حتى الأذكى ، من البحث عن "فعال"
النمط الجيني ، اقرأ التركيبة "الفعالة" للاتصالات العصبية ، شريطة أن يختلف كل اتصال عصبي من -1 إلى 1 في الخطوات ، وأي خطوة؟ كان التهيئة تعويم عشوائي ، وهو 15 منزلة عشرية. لم تتضح لنا الخطوة بعد. حول عدد متغيرات مجموعات الأوزان العصبية ، يفترض المؤلف أن هذا رقم لا نهائي ، عند اختيار حجم معين للخطوة ، ربما يكون عددًا محدودًا ، ولكن على أي حال ، فإن هذه الأرقام هي أكثر من 4 أماكن في المحاكي ، حتى مع الأخذ في الاعتبار الإطلاق المتسلسل من قائمة انتظار الروبوتات بالإضافة إلى التشغيل المتوازي المتزامن للمحاكاة الرسمية ، حتى 10 على جهاز كمبيوتر واحد (لمحبي البرمجة القديمة: أجهزة الكمبيوتر).
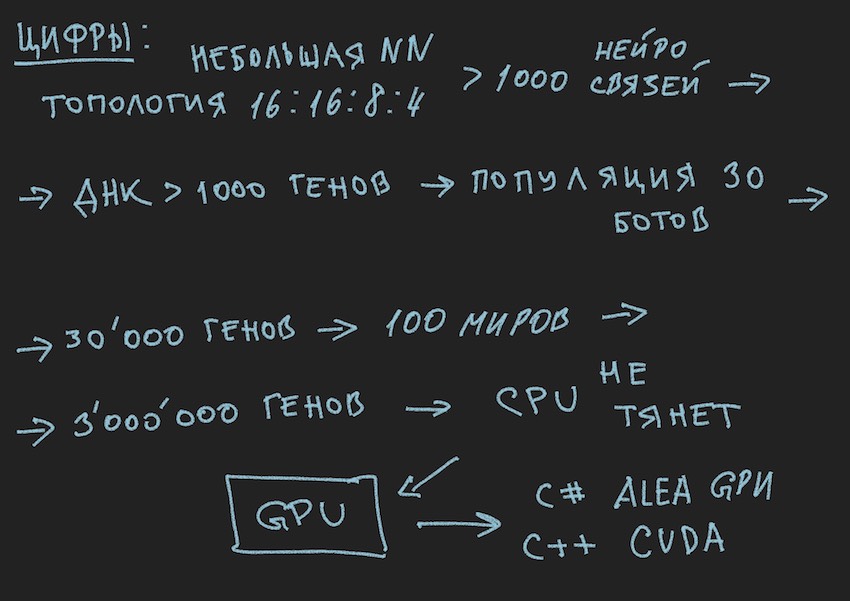
آمل أن تساعد الصور القارئ.
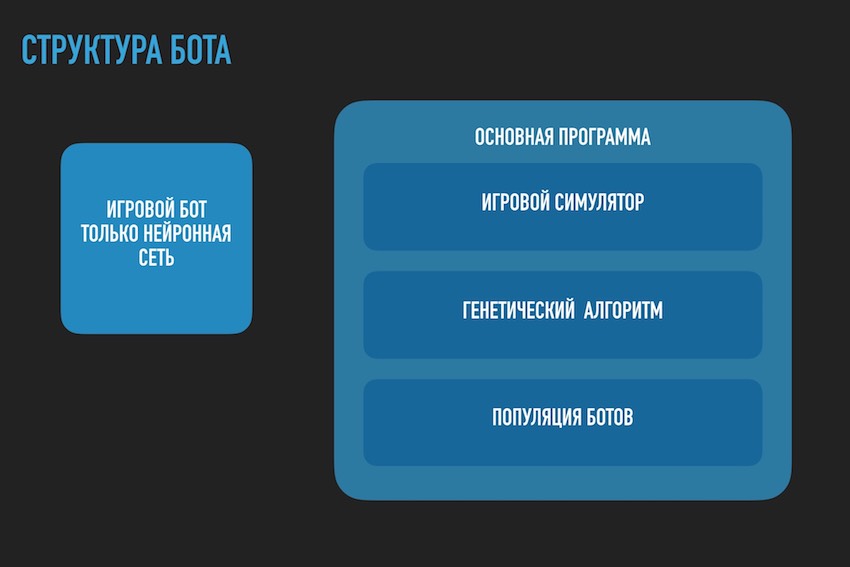
هنا تحتاج للتوقف والتحدث عن بنية حل البرنامج. نظرًا لأن الحل في شكل روبوت برامج منفصل تم تحميله على موقع المنافسة لم يعد مناسبًا. كان من الضروري فصل روبوت اللعب وفقًا لقواعد المنافسة في إطار النظام البيئي للمنظمين والبرنامج الذي يحاول العثور على تكوين الشبكة العصبية له. الرسم البياني التالي مأخوذ من العرض التقديمي للمؤتمر ، ولكنه يعكس بشكل عام الصورة الحقيقية.
يتذكر نكتة ملحية:
منظمة كبيرة.
الوقت 18.00 ، يعمل جميع الموظفين كوحدة واحدة. فجأة ، قام أحد الموظفين بإيقاف تشغيل الكمبيوتر وارتدى ملابسه وغادر.
الجميع يتبعه بمفاجأة.
اليوم التالي. في الساعة 18.00 يقوم نفس الموظف بإيقاف تشغيل الكمبيوتر ويغادر. الكل يواصل العمل ويهمس في الاستياء.
في اليوم التالي. في الساعة 18.00 يقوم نفس الموظف بإيقاف تشغيل الكمبيوتر ...
زميل يقترب منه:
-حيث أنك لا تخجل ، نحن نعمل ، في نهاية الربع ، الكثير من التقارير ، نريد أيضًا العودة إلى المنزل في الوقت المحدد وأنت مثل هذا الشخص ...
- يا رفاق ، أنا عمومًا في إجازة!
... أن يستمر.
نعم ، لقد نسيت تقريبًا إرفاق كود إجراء حساب RNN ، فهو صالح ومكتوب بشكل مستقل ، لذلك ربما هناك أخطاء فيه. للتضخيم ، سأحضره كما هو ، إنه في c ++ كما هو مطبق على CUDA (مكتبة للحساب على GPU).
ملاحظة: المصفوفات متعددة الأبعاد لا تتوافق بشكل جيد مع وحدات معالجة الرسومات ، بالطبع هناك مواد وحسابات مصفوفة ، لكنها توصي باستخدام المصفوفات أحادية البعد.
مثال صفيف [i، j] البعد M بواسطة j يتحول إلى صفيف النموذج [i * M + j].
رمز مصدر إجراء الحساب RNN __global__ void cudaRNN(Bot *bot, argumentsRNN *RNN, ConstantStruct *Const, int *Topology, int *TopologyRNN, int numElements, int gameTick) { int tid = blockIdx.x * blockDim.x + threadIdx.x; int threadN = gridDim.x * blockDim.x; int TopologySize = Const->TopologySize; for (int pos = tid; pos < numElements; pos += threadN) { const int ii = pos; const int iiA = pos*Const->ArrayDim; int ArrayDim = Const->ArrayDim; const int iiAT = ii*TopologySize*ArrayDim; if (bot[pos].TTF != 0 && bot[pos].Mass>0) { RNN->outputs[iiA + Topology[0]] = 1.f; //bias int neuroncount7 = Topology[0]; neuroncount7++; for (int layer1 = 0; layer1 < TopologySize - 1; layer1++) { for (int j4 = 0; j4 < Topology[layer1 + 1]; j4++) { for (int i5 = 0; i5 < Topology[layer1] + 1; i5++) { RNN->sums[iiA + j4] = RNN->sums[iiA + j4] + RNN->outputs[iiA + i5] * RNN->NNweights[((ii*TopologySize + layer1)*ArrayDim + i5)*ArrayDim + j4]; } } if (TopologyRNN[layer1] > 0) { for (int j14 = 0; j14 < Topology[layer1]; j14++) { for (int i15 = 0; i15 < Topology[layer1]; i15++) { RNN->sumsContext[iiA + j14] = RNN->sumsContext[iiA + j14] + RNN->neuronContext[iiAT + ArrayDim * layer1 + i15] * RNN->MNweights[((ii*TopologySize + layer1)*ArrayDim + i15)*ArrayDim + j14]; } RNN->sumsContext[iiA + j14] = RNN->sumsContext[iiA + j14] + 1.0f* RNN->MNweights[((ii*TopologySize + layer1)*ArrayDim + Topology[layer1])*ArrayDim + j14]; //bias=1 } for (int t = 0; t < Topology[layer1 + 1]; t++) { RNN->outputs[iiA + t] = Tanh(RNN->sums[iiA + t] + RNN->sumsContext[iiA + t]); RNN->neuronContext[iiAT + ArrayDim * layer1 + t] = RNN->outputs[iiA + t]; } //SoftMax /* double sum = 0.0; for (int k = 0; k <ArrayDim; ++k) sum += exp(RNN->outputs[iiA + k]); for (int k = 0; k < ArrayDim; ++k) RNN->outputs[iiA + k] = exp(RNN->outputs[iiA + k]) / sum; */ } else { for (int i1 = 0; i1 < Topology[layer1 + 1]; i1++) { RNN->outputs[iiA + i1] = Sigmoid(RNN->sums[iiA + i1]); //sigma } } if (layer1 + 1 != TopologySize - 1) { RNN->outputs[iiA + Topology[layer1 + 1]] = 1.f; } for (int i2 = 0; i2 < ArrayDim; i2++) { RNN->sums[iiA + i2] = 0.f; RNN->sumsContext[iiA + i2] = 0.f; } } } } }