تخيل أن لديك فقرة من النص. هل يمكن فهم المشاعر التي يحملها هذا النص: الفرح والحزن والغضب؟ يمكنك. نبسط مهمتنا وسنصنف المشاعر على أنها إيجابية أو سلبية ، دون تحديد. هناك العديد من الطرق لحل هذه المشكلة ، وأحدها الشبكات العصبية التلافيفية (
الشبكات العصبية التلافيفية). تم تطوير CNN في الأصل لمعالجة الصور ، لكنها تتعامل بنجاح مع المهام في مجال معالجة النصوص تلقائيًا. سأقدم لك تحليلًا ثنائيًا لنغمة النصوص باللغة الروسية باستخدام شبكة عصبية تلافيفية ، والتي تم تشكيل تمثيلات متجهية للكلمات على أساس نموذج
Word2Vec مدرب.
شددت المقالة على طبيعة نظرة عامة ، وأكدت المكون العملي. وأريد أن أحذرك على الفور من أن القرارات المتخذة في كل مرحلة قد لا تكون مثالية. قبل القراءة ، أوصي بأن تتعرف على
المقالة التمهيدية حول استخدام CNN في مهام معالجة اللغة الطبيعية ، بالإضافة إلى قراءة
المواد حول طرق تمثيل ناقلات الكلمات.
العمارة
تستند بنية CNN قيد النظر على النهجين [1] و [2]. النهج [1] ، الذي يستخدم مجموعة من الشبكات التلافيفية والمتكررة ، في أكبر مسابقة سنوية في اللغويات الحاسوبية SemEval-2017 احتل المركز الأول [3] في خمسة ترشيحات في مهمة تحليل الدرجة اللونية
للمهمة 4 .
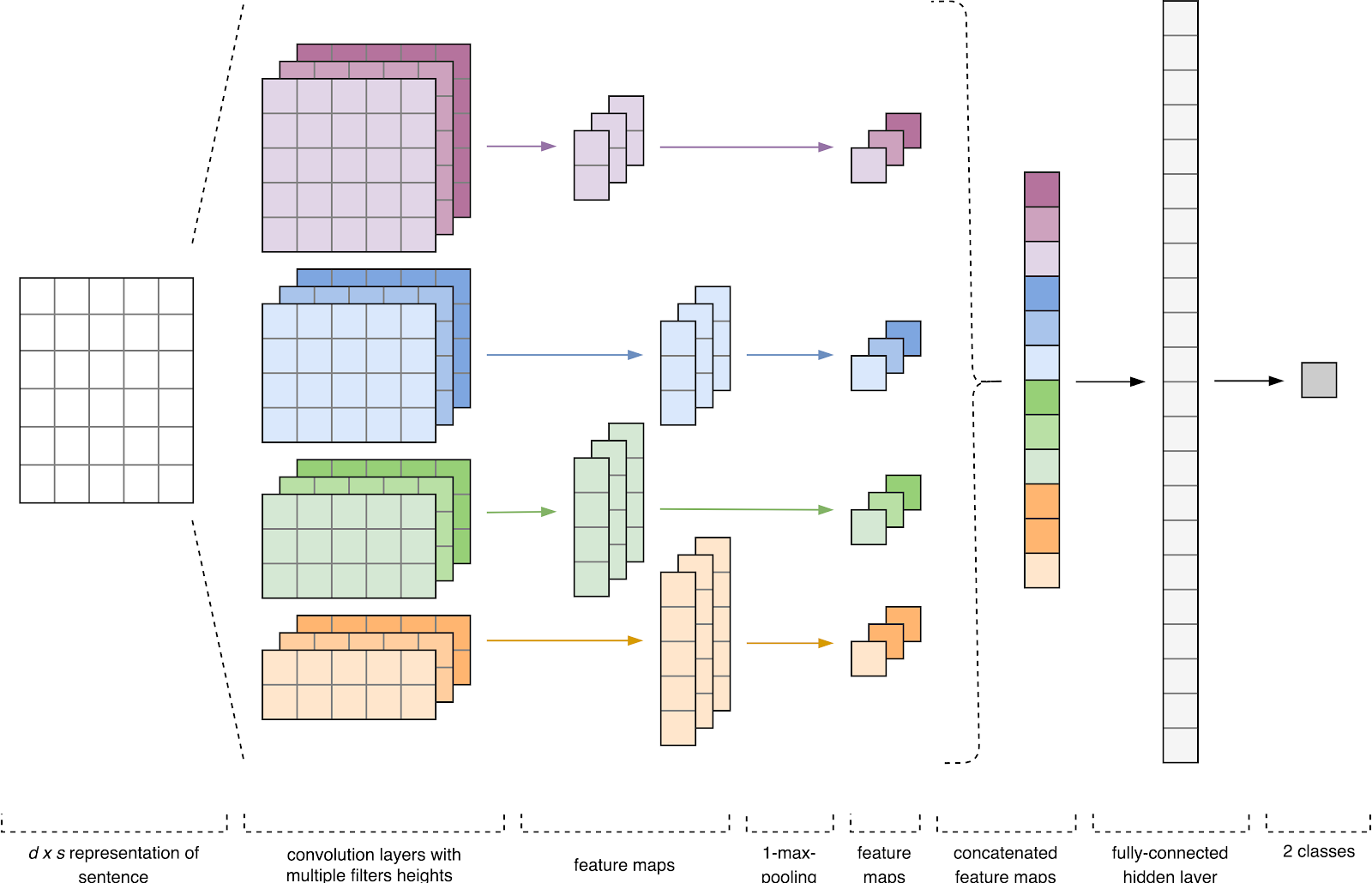 الشكل 1. العمارة CNN [2].
الشكل 1. العمارة CNN [2].إدخال CNN (الشكل 1) عبارة عن مصفوفة ذات ارتفاع ثابت
n ، حيث يكون كل صف عبارة عن تعيين متجه لرمز مميز في مساحة سمة ذات أبعاد
k . غالبًا ما تُستخدم أدوات دلالات التوزيع مثل Word2Vec و Glove و FastText وما إلى ذلك لتشكيل مساحة ميزة.
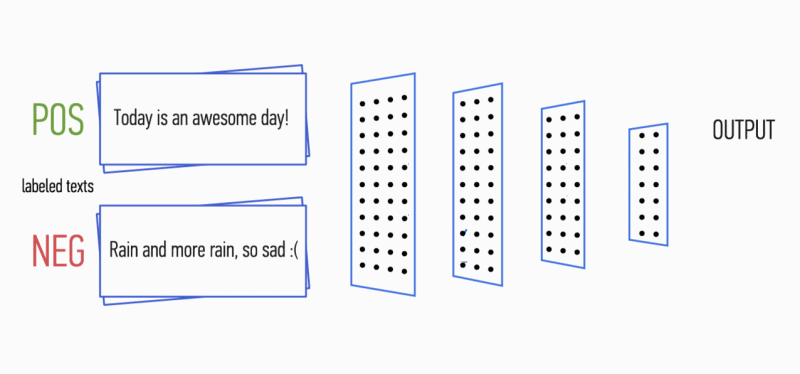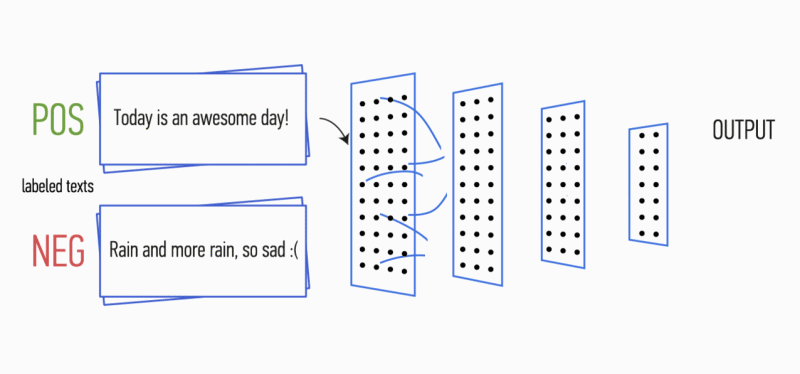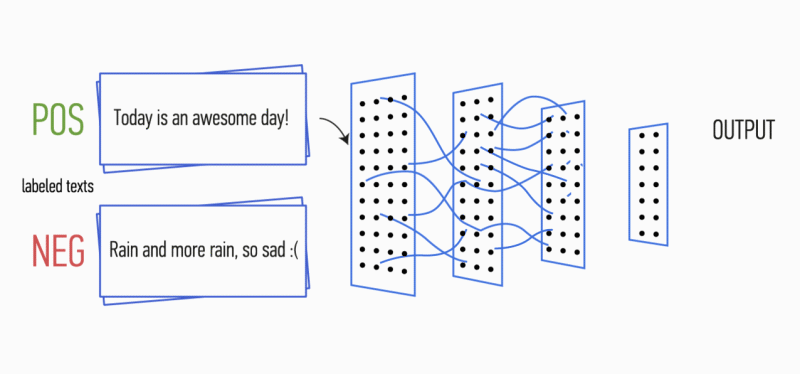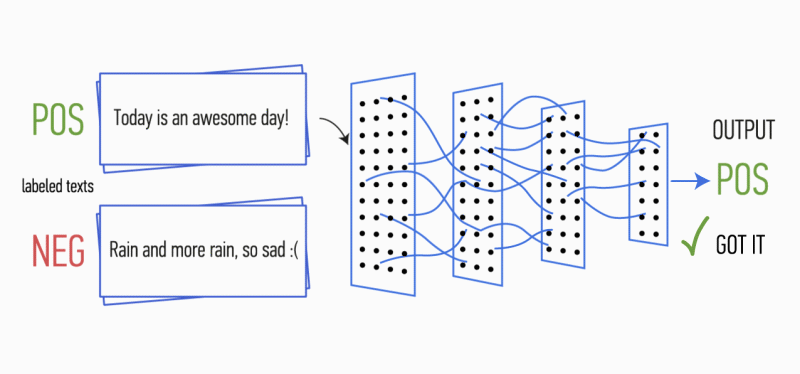
في المرحلة الأولى ، تتم معالجة مصفوفة الإدخال عن طريق طبقات الالتفاف. كقاعدة ، يكون للمرشحات عرض ثابت يساوي أبعاد مساحة السمة ، ويتم تكوين معلمة واحدة فقط لأحجام المرشح - الارتفاع
h . اتضح أن
h هو ارتفاع الخطوط المجاورة التي يعتبرها المرشح معًا. وفقًا لذلك ، يختلف بُعد مصفوفة ميزة الإخراج لكل مرشح حسب ارتفاع هذا المرشح
h وارتفاع المصفوفة الأصلية
n .
بعد ذلك ، تتم معالجة خريطة المعالم التي تم الحصول عليها عند إخراج كل مرشح بطبقة فرعية مع وظيفة ضغط محددة (1-max pooling في الصورة) ، أي يقلل من أبعاد خريطة المعالم التي تم إنشاؤها. وبالتالي ، يتم استخراج المعلومات الأكثر أهمية لكل التفاف ، بغض النظر عن موقعها في النص. وبعبارة أخرى ، بالنسبة لعرض المتجهات المستخدم ، فإن الجمع بين طبقات الالتفاف وطبقات المعاينة الفرعية يجعل من الممكن استخراج أهم
الأعداد من النص.
بعد ذلك ، يتم دمج خرائط المعالم المحسوبة عند إخراج كل طبقة من عينات المعاينة الفرعية في ناقل سمة مشترك واحد. يتم تغذيته لإدخال طبقة مخفية متصلة بالكامل ، ثم يتم تغذيته إلى طبقة الإخراج للشبكة العصبية ، حيث يتم حساب تسميات الطبقة النهائية.
بيانات التدريب
للتدريب ، اخترت
مجموعة النصوص القصيرة التي كتبها يوليا روبتسوفا ، التي تم تشكيلها على أساس رسائل باللغة الروسية من تويتر [4]. يحتوي على 114991 تغريدة موجبة ، 111 923 تغريدة سلبية ، بالإضافة إلى قاعدة تغريدة غير مخصصة بحجم يصل إلى 17 639 674 رسالة.
import pandas as pd import numpy as np
قبل التدريب ، اجتازت النصوص المعالجة الأولية:
- يلقي إلى أحرف صغيرة ؛
- استبدال "e" بـ "e" ؛
- استبدال الروابط إلى رمز "URL" ؛
- استبدال ذكر المستخدم برمز المستخدم ؛
- إزالة علامات الترقيم.
import re def preprocess_text(text): text = text.lower().replace("", "") text = re.sub('((www\.[^\s]+)|(https?://[^\s]+))', 'URL', text) text = re.sub('@[^\s]+', 'USER', text) text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() data = [preprocess_text(t) for t in raw_data]
بعد ذلك ، قمت بتقسيم مجموعة البيانات إلى عينة تدريب واختبار بنسبة 4: 1.
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=1)
عرض متجه للكلمات
البيانات المدخلة للشبكة العصبية التلافيفية عبارة عن مصفوفة ذات ارتفاع ثابت
n ، حيث يكون كل صف عبارة عن تعيين متجه لكلمة في مساحة سمة للبعد
k . لتكوين طبقة التضمين لشبكة عصبية ، استخدمت أداة دلالات التوزيع الموزعة Word2Vec [5] المصممة لتعيين المعنى الدلالي للكلمات في مساحة النواقل. يجد Word2Vec العلاقات بين الكلمات من خلال افتراض أن الكلمات ذات الصلة دلالة تم العثور عليها في سياقات مماثلة. يمكنك قراءة المزيد عن Word2Vec في
المقالة الأصلية ، وكذلك
هنا وهنا . نظرًا لأن التغريدات تتميز بعلامات ترقيم المؤلف والرموز التعبيرية ، فإن تحديد حدود الجمل يصبح مهمة مستهلكة للوقت. في هذا العمل ، افترضت أن كل تغريدة تحتوي على جملة واحدة فقط.
يتم تخزين قاعدة التغريدات غير المخصصة بتنسيق SQL وتحتوي على أكثر من 17.5 مليون سجل. من أجل الراحة ، قمت بتحويله إلى SQLite باستخدام
هذا البرنامج النصي.
import sqlite3
ثم ، باستخدام مكتبة Gensim ، قمت بتدريب نموذج Word2Vec بالمعلمات التالية:
- الحجم = 200 - بُعد مسافة السمة ؛
- window = 5 - عدد الكلمات من السياق التي تحللها الخوارزمية ؛
- min_count = 3 - يجب أن تحدث الكلمة ثلاث مرات على الأقل حتى يأخذها النموذج في الاعتبار.
import logging import multiprocessing import gensim from gensim.models import Word2Vec logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
 الشكل 2 الشكل 2. تصور مجموعات من كلمات مماثلة باستخدام t-SNE.
الشكل 2 الشكل 2. تصور مجموعات من كلمات مماثلة باستخدام t-SNE.لفهم أكثر تفصيلاً لعملية Word2Vec في الشكل. يوضح
الشكل 2 التصور للعديد من مجموعات الكلمات المتشابهة من النموذج المدرب ، والتي تم تعيينها في مساحة ثنائية الأبعاد باستخدام
خوارزمية التصور t-SNE .
عرض متجه للنصوص
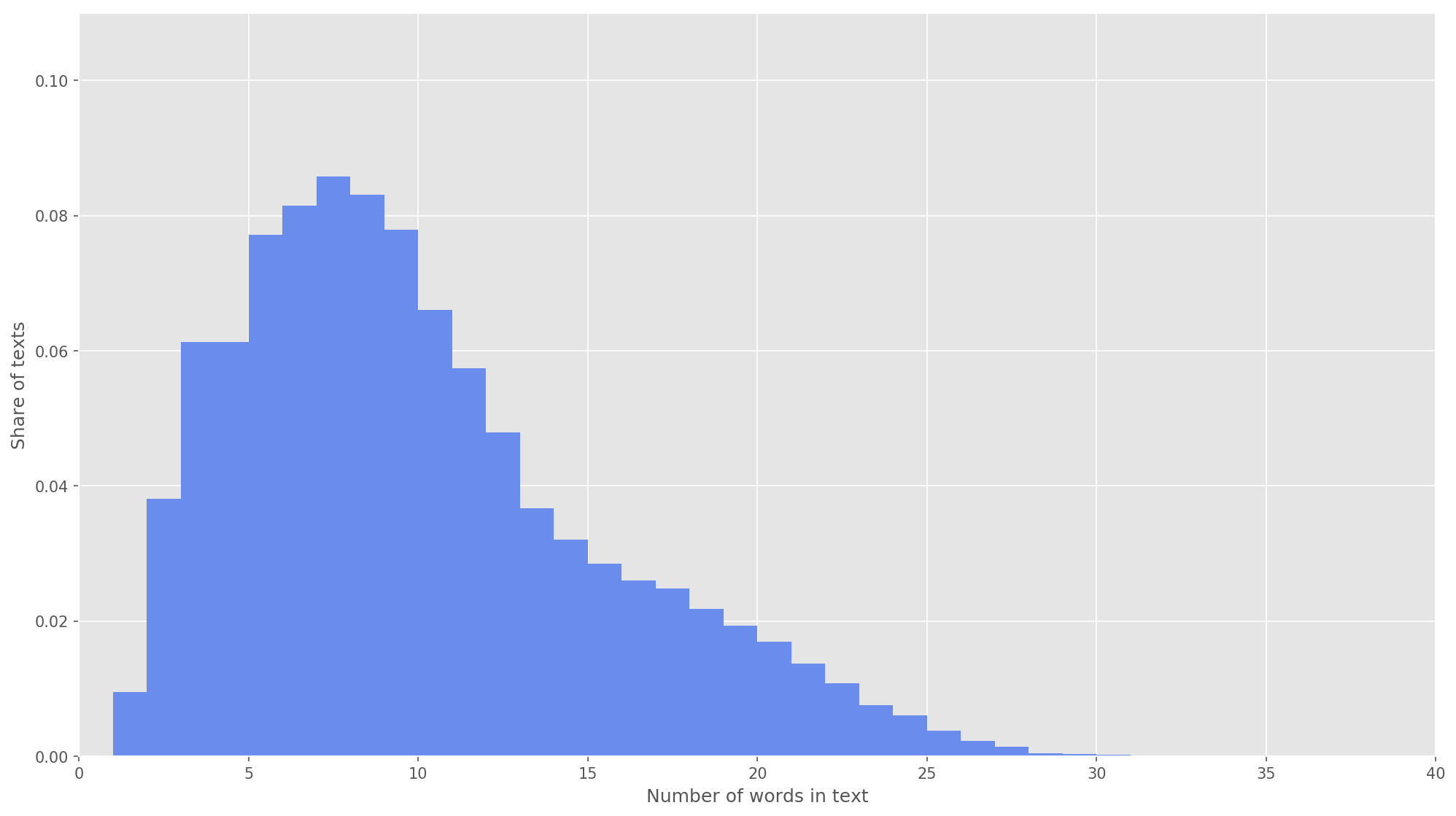 الشكل 3. توزيع طول النصوص.
الشكل 3. توزيع طول النصوص.في الخطوة التالية ، تم تعيين كل نص لمجموعة من معرفات الرمز المميز. اخترت أبعاد متجه النص
s = 26 ، حيث أنه عند هذه القيمة يتم تغطية 99.71٪ من جميع النصوص في الجسم المشكل بالكامل (الشكل 3). إذا تجاوز عدد الكلمات في تغريدة أثناء التحليل ارتفاع المصفوفة ، تم تجاهل الكلمات المتبقية ولم يتم أخذها في الاعتبار في التصنيف. البعد النهائي لمصفوفة العرض كان
× × = 26 × 200 .
from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences
الشبكة العصبية التلافيفية
لبناء شبكة عصبية ، استخدمت مكتبة Keras ، التي تعمل كوظيفة إضافية عالية المستوى لـ TensorFlow و CNTK و Theano. لدى Keras وثائق ممتازة ، بالإضافة إلى مدونة تغطي العديد من مهام التعلم الآلي ، مثل
تهيئة طبقة التضمين . في حالتنا ، تم بدء طبقة التضمين من خلال الأوزان التي تم الحصول عليها عن طريق تعلم Word2Vec. لتقليل التغييرات في طبقة التضمين ، قمت بتجميدها في المرحلة الأولى من التدريب.
from keras.layers import Input from keras.layers.embeddings import Embedding tweet_input = Input(shape=(SENTENCE_LENGTH,), dtype='int32') tweet_encoder = Embedding(NUM, DIM, input_length=SENTENCE_LENGTH, weights=[embedding_matrix], trainable=False)(tweet_input)
في العمارة المتقدمة ، تم استخدام مرشحات بارتفاع
h = (2 ، 3 ، 4 ، 5) ، وهي مصممة للمعالجة المتوازية لل bigrams ، trigrams ، 4-grams و 5-grams ، على التوالي. تمت إضافة 10 طبقات تلافيفية لكل شبكة عصبية لكل ارتفاع مرشح ، ووظيفة التنشيط هي ReLU. يمكن العثور على توصيات للعثور على الارتفاع الأمثل وعدد الفلاتر في [2].
بعد المعالجة بواسطة طبقات الالتواء ، تم تغذية خرائط السمات إلى طبقات فرعية ، حيث تم تطبيق عملية التجميع 1-max عليها ، وبالتالي استخراج أهم n-grams من النص. في المرحلة التالية ، اندمجت في ناقل سمة مشترك (طبقة ضم) ، والذي تم تغذيته في طبقة مخفية متصلة بالكامل مع 30 خلية عصبية. في المرحلة الأخيرة ، تم تغذية خريطة المعالم النهائية إلى طبقة الإخراج للشبكة العصبية مع وظيفة التنشيط السيني.
نظرًا لأن الشبكات العصبية تميل إلى إعادة التدريب ، بعد طبقة التضمين وقبل الطبقة المخفية المتصلة بالكامل ، أضفت تسوية التسرب مع احتمال طرد الذروة p = 0.2.
from keras import optimizers from keras.layers import Dense, concatenate, Activation, Dropout from keras.models import Model from keras.layers.convolutional import Conv1D from keras.layers.pooling import GlobalMaxPooling1D branches = []
لقد قمت بتكوين النموذج النهائي باستخدام وظيفة تحسين Adam (تقدير اللحظة التكيفية) و interropy الثنائي كدالة للأخطاء. تم تقييم جودة المصنف من حيث دقة المتوسط الكلي واكتماله و f- مقاييس.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[precision, recall, f1]) model.summary()
في المرحلة الأولى من التدريب ، تم تجميد طبقة التضمين ، وتم تدريب جميع الطبقات الأخرى لمدة 10 عصور:
- حجم مجموعة الأمثلة المستخدمة للتدريب هو 32.
- حجم عينة التحقق: 25٪.
from keras.callbacks import ModelCheckpoint checkpoint = ModelCheckpoint("models/cnn/cnn-frozen-embeddings-{epoch:02d}-{val_f1:.2f}.hdf5", monitor='val_f1', save_best_only=True, mode='max', period=1) history = model.fit(x_train_seq, y_train, batch_size=32, epochs=10, validation_split=0.25, callbacks = [checkpoint])
سجلاتTrain on 134307 samples, validate on 44769 samples
Epoch 1/10
134307/134307 [==============================] - 221s 2ms/step - loss: 0.5703 - precision: 0.7006 - recall: 0.6854 - f1: 0.6839 - val_loss: 0.5014 - val_precision: 0.7538 - val_recall: 0.7493 - val_f1: 0.7452
Epoch 2/10
134307/134307 [==============================] - 218s 2ms/step - loss: 0.5157 - precision: 0.7422 - recall: 0.7258 - f1: 0.7263 - val_loss: 0.4911 - val_precision: 0.7413 - val_recall: 0.7924 - val_f1: 0.7602
Epoch 3/10
134307/134307 [==============================] - 213s 2ms/step - loss: 0.5023 - precision: 0.7502 - recall: 0.7337 - f1: 0.7346 - val_loss: 0.4825 - val_precision: 0.7750 - val_recall: 0.7411 - val_f1: 0.7512
Epoch 4/10
134307/134307 [==============================] - 215s 2ms/step - loss: 0.4956 - precision: 0.7545 - recall: 0.7412 - f1: 0.7407 - val_loss: 0.4747 - val_precision: 0.7696 - val_recall: 0.7590 - val_f1: 0.7584
Epoch 5/10
134307/134307 [==============================] - 229s 2ms/step - loss: 0.4891 - precision: 0.7587 - recall: 0.7492 - f1: 0.7473 - val_loss: 0.4781 - val_precision: 0.8014 - val_recall: 0.7004 - val_f1: 0.7409
Epoch 6/10
134307/134307 [==============================] - 217s 2ms/step - loss: 0.4830 - precision: 0.7620 - recall: 0.7566 - f1: 0.7525 - val_loss: 0.4749 - val_precision: 0.7877 - val_recall: 0.7411 - val_f1: 0.7576
Epoch 7/10
134307/134307 [==============================] - 219s 2ms/step - loss: 0.4802 - precision: 0.7632 - recall: 0.7568 - f1: 0.7532 - val_loss: 0.4730 - val_precision: 0.7969 - val_recall: 0.7241 - val_f1: 0.7522
Epoch 8/10
134307/134307 [==============================] - 215s 2ms/step - loss: 0.4769 - precision: 0.7644 - recall: 0.7605 - f1: 0.7558 - val_loss: 0.4680 - val_precision: 0.7829 - val_recall: 0.7542 - val_f1: 0.7619
Epoch 9/10
134307/134307 [==============================] - 227s 2ms/step - loss: 0.4741 - precision: 0.7657 - recall: 0.7663 - f1: 0.7598 - val_loss: 0.4672 - val_precision: 0.7695 - val_recall: 0.7784 - val_f1: 0.7682
Epoch 10/10
134307/134307 [==============================] - 221s 2ms/step - loss: 0.4727 - precision: 0.7670 - recall: 0.7647 - f1: 0.7590 - val_loss: 0.4673 - val_precision: 0.7833 - val_recall: 0.7561 - val_f1: 0.7636
ثم اختار النموذج بأعلى مقاييس F في مجموعة بيانات التحقق ، أي نموذج تم الحصول عليه في الحقبة الثامنة من التعليم (F
1 = 0.7791). قام النموذج بإذابة طبقة التضمين ، وبعد ذلك أطلق خمسة عصور تدريبية أخرى.
from keras import optimizers
سجلاتTrain on 134307 samples, validate on 44769 samples
Epoch 1/5
134307/134307 [==============================] - 2042s 15ms/step - loss: 0.4495 - precision: 0.7806 - recall: 0.7797 - f1: 0.7743 - val_loss: 0.4560 - val_precision: 0.7858 - val_recall: 0.7671 - val_f1: 0.7705
Epoch 2/5
134307/134307 [==============================] - 2253s 17ms/step - loss: 0.4432 - precision: 0.7857 - recall: 0.7842 - f1: 0.7794 - val_loss: 0.4543 - val_precision: 0.7923 - val_recall: 0.7572 - val_f1: 0.7683
Epoch 3/5
134307/134307 [==============================] - 2018s 15ms/step - loss: 0.4372 - precision: 0.7899 - recall: 0.7879 - f1: 0.7832 - val_loss: 0.4519 - val_precision: 0.7805 - val_recall: 0.7838 - val_f1: 0.7767
Epoch 4/5
134307/134307 [==============================] - 1901s 14ms/step - loss: 0.4324 - precision: 0.7943 - recall: 0.7904 - f1: 0.7869 - val_loss: 0.4504 - val_precision: 0.7825 - val_recall: 0.7808 - val_f1: 0.7762
Epoch 5/5
134307/134307 [==============================] - 1924s 14ms/step - loss: 0.4256 - precision: 0.7986 - recall: 0.7947 - f1: 0.7913 - val_loss: 0.4497 - val_precision: 0.7989 - val_recall: 0.7549 - val_f1: 0.7703
تم تحقيق أعلى مؤشر
F 1 = 76.80٪ في عينة التحقق في الحقبة الثالثة من التدريب. كانت جودة النموذج المدرب على بيانات الاختبار
F 1 = 78.1٪ .
الجدول 1. جودة تحليل المشاعر على بيانات الاختبار.
النتيجة
كحل أساسي ، قمت
بتدريب مصنّف Bayes ساذج باستخدام نموذج توزيع متعدد الحدود ، ويتم عرض نتائج المقارنة في الجدول. 2.
الجدول 2. مقارنة جودة تحليل الدرجة اللونية.
كما ترون ، تجاوزت جودة تصنيف CNN MNB بنسبة عدة في المئة. يمكن زيادة قيم المقاييس بشكل أكبر إذا كنت تعمل على تحسين المعلمات الفائقة وبنية الشبكة. على سبيل المثال ، يمكنك تغيير عدد عصور التدريب ، والتحقق من فعالية استخدام تمثيلات متجهية مختلفة للكلمات ومجموعاتها ، وتحديد عدد الفلاتر وارتفاعها ، وتنفيذ معالجة نصية أكثر فاعلية (التصحيح المطبعي ، والتطبيع ، والختم) ، وضبط عدد الطبقات المخفية المتصلة بالكامل والخلايا العصبية فيها .
كود المصدر
متاح على Github ، يمكن تنزيل نماذج CNN و Word2Vec المدربة
هنا .
مصادر
- Cliche M. BB_twtr في SemEval-2017 المهمة 4: تحليل معنويات Twitter مع CNNs و LSTMs // وقائع ورشة العمل الدولية الحادية عشرة حول التقييم الدلالي (SemEval-2017). - 2017 - S. 573-580.
- Zhang Y.، Wallace B. تحليل حساسية (ودليل الممارسين) للشبكات العصبية التلافيفية لتصنيف الجمل // arXiv preprint arXiv: 1510.03820. - 2015.
- Rosenthal S. ، Farra N. ، Nakov P. SemEval-2017 المهمة 4: تحليل المشاعر في Twitter // وقائع ورشة العمل الدولية الحادية عشرة حول التقييم الدلالي (SemEval-2017). - 2017 - S. 502-518.
- Yu. V. Rubtsova. بناء مجموعة من النصوص لإعداد المصنف النغمي // منتجات البرمجيات والأنظمة ، 2015 ، رقم 1 (109) ، -C.72-78.
- Mikolov T. et al. التمثيلات الموزعة للكلمات والعبارات وتكوينها // التقدم في نظم معالجة المعلومات العصبية. - 2013. - س 3111-3119.