في مقال سابق ،
نظرة عامة على الشبكات العصبية لتصنيف الصور ، عرفنا أنفسنا بالمفاهيم الأساسية للشبكات العصبية التلافيفية ، وكذلك الأفكار الأساسية. في هذه المقالة ، سنلقي نظرة على بعض معماريات الشبكة العصبية العميقة ذات قوة المعالجة الرائعة - مثل AlexNet و ZFNet و VGG و GoogLeNet و ResNet - وتلخيص المزايا الرئيسية لكل من هذه البنى. تستند بنية المقالة على إدخال مدونة
المفاهيم الأساسية للشبكات العصبية التلافيفية ، الجزء 3 .
يمثل ImageNet Challenge حاليًا الحافز الأساسي الكامن وراء تطوير أنظمة التعرف على الآلة وتصنيف الصور. الحملة عبارة عن مسابقة للعمل مع البيانات ، حيث يتم تزويد المشاركين بمجموعة كبيرة من البيانات (أكثر من مليون صورة). تتمثل مهمة المسابقة في تطوير خوارزمية تسمح لك بتصنيف الصور المطلوبة إلى كائنات في 1000 فئة - مثل الكلاب والقطط والسيارات وغيرها - مع الحد الأدنى من الأخطاء.
وفقًا للقواعد الرسمية للمسابقة ، يجب أن توفر الخوارزميات قائمة بما لا يزيد عن خمس فئات من الكائنات بترتيب تنازلي للثقة لكل فئة من الصور. يتم تقييم جودة تعليم الصورة بناءً على الملصق الذي يتطابق بشكل أفضل مع خاصية الحقيقة الأساسية للصورة. الفكرة هي السماح للخوارزمية بتحديد عدة كائنات في الصورة وعدم تراكم نقاط الجزاء في حالة وجود أي من الأشياء المكتشفة بالفعل في الصورة ولكن لم يتم تضمينها في خاصية الحقيقة الأساسية.
في السنة الأولى من المسابقة ، تم تزويد المشاركين بسمات صورة محددة مسبقًا لتدريب النموذج. يمكن أن تكون هذه ، على سبيل المثال ، علامات لخوارزمية
SIFT تمت معالجتها باستخدام تكميم المتجهات ومناسبة للاستخدام في طريقة حقيبة الكلمات أو للعرض كهرم مكاني. ومع ذلك ، في عام 2012 كان هناك تقدم حقيقي في هذا المجال: أثبتت مجموعة من العلماء من جامعة تورنتو أن الشبكة العصبية العميقة يمكن أن تحقق نتائج أعلى بكثير مقارنة بنماذج التعلم الآلي التقليدية المبنية على أساس ناقلات من خصائص الصورة المحددة مسبقًا. في الأقسام التالية ، سيتم النظر في أول هندسة مبتكرة مقترحة في عام 2012 ، بالإضافة إلى الهياكل المعمارية التي تتبعها حتى عام 2015.
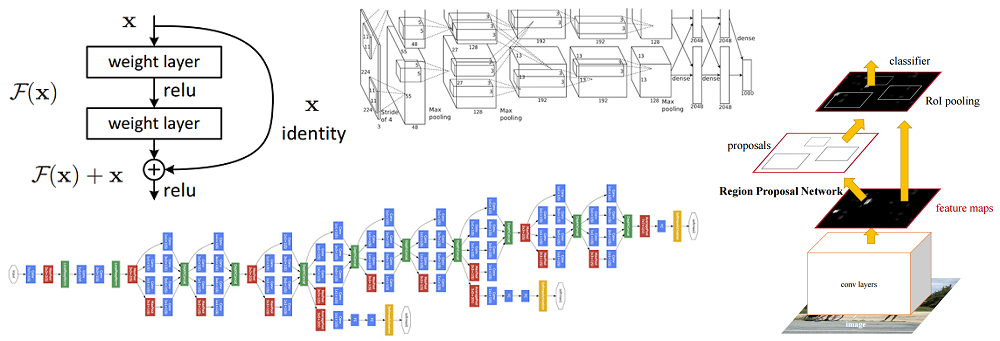
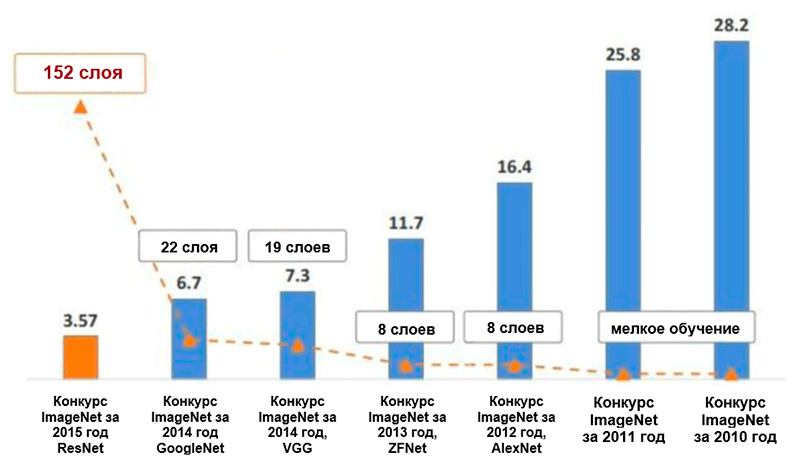 رسم تخطيطي للتغيرات في عدد الأخطاء (بالنسبة المئوية) في تصنيف صور ImageNet * للفئات الخمس الرائدة. صورة مأخوذة من عرض Kaiming He ، التعلم العميق المتبقي للتعرف على الصور
رسم تخطيطي للتغيرات في عدد الأخطاء (بالنسبة المئوية) في تصنيف صور ImageNet * للفئات الخمس الرائدة. صورة مأخوذة من عرض Kaiming He ، التعلم العميق المتبقي للتعرف على الصورAlexnet
تم اقتراح العمارة
AlexNet في عام 2012 من قبل مجموعة من العلماء (A. Krizhevsky و I. Sutskever و J.Hinton) من جامعة تورنتو. كان هذا عملًا مبتكرًا استخدم فيه المؤلفون لأول مرة (في ذلك الوقت) الشبكات العصبية التلافيفية العميقة بعمق إجمالي من ثماني طبقات (خمس طبقات تلافيفية وثلاث طبقات متصلة بالكامل).
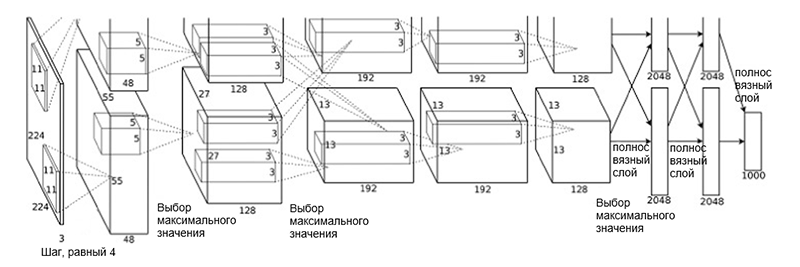 العمارة AlexNet
العمارة AlexNetتتكون بنية الشبكة من الطبقات التالية:
- [طبقة الالتفاف + تحديد القيمة القصوى + التطبيع] × 2
- [طبقة الالتفاف] × 3
- [اختيار القيمة القصوى]
- [طبقة كاملة] × 3
قد يبدو هذا المخطط غريبًا بعض الشيء ، لأن عملية التعلم تم تقسيمها بين وحدتي GPU نظرًا لتعقيدها الحسابي العالي. يتطلب هذا الفصل بين وحدات معالجة الرسومات فصلًا يدويًا للنموذج إلى كتل رأسية تتفاعل مع بعضها البعض.
خفضت بنية AlexNet عدد الأخطاء للفئات الرائدة الخمس إلى 16.4 في المائة - ما يقرب من النصف مقارنة بالتطورات المتقدمة السابقة! أيضًا في إطار هذه البنية ، تم تقديم وظيفة التنشيط مثل وحدة التصحيح الخطي (
ReLU ) ، والتي تعد حاليًا معيار الصناعة. فيما يلي ملخص موجز للسمات الرئيسية الأخرى لهندسة AlexNet وعملية التعلم الخاصة بها:
- زيادة البيانات المكثفة
- طريقة الاستبعاد
- التحسين باستخدام لحظة SGD (انظر دليل التحسين "نظرة عامة على خوارزميات تحسين نزول التدرج")
- الضبط اليدوي لسرعة التعلم (تقليل هذا المعامل بمقدار 10 مع استقرار الدقة)
- النموذج الأخير عبارة عن مجموعة من سبع شبكات عصبية تلافيفية
- تم إجراء التدريب على معالجي رسومات NVIDIA * GeForce GTX * 580 بإجمالي 3 جيجابايت من ذاكرة الفيديو لكل منهما.
Zfnet
بنية شبكة
ZFNet التي اقترحها الباحثان M. Zeiler و R. Fergus من جامعة نيويورك متطابقة تقريبًا مع بنية AlexNet. الاختلافات الكبيرة بينهما فقط هي كما يلي:
- حجم المرشح والخطوة في الطبقة التلافيفية الأولى (في AlexNet ، يكون حجم المرشح 11 × 11 ، والخطوة 4 ؛ في ZFNet - 7 × 7 و 2 ، على التوالي)
- عدد المرشحات في طبقات تلافيفية نظيفة (3 ، 4 ، 5).
 هندسة ZFNet
هندسة ZFNetبفضل بنية ZFNet ، انخفض عدد الأخطاء للفئات الرائدة الخمس إلى 11.4 في المائة. ربما يتم لعب الدور الرئيسي في هذا عن طريق الضبط الدقيق للمعلمات الفائقة (الحجم وعدد الفلاتر ، وحجم العبوة ، وسرعة التعلم ، وما إلى ذلك). ومع ذلك ، فمن المحتمل أيضًا أن أفكار بنية ZFNet أصبحت مساهمة كبيرة جدًا في تطوير الشبكات العصبية التلافيفية. اقترح زيلر وفيرجوس نظامًا لتصور النوى والأوزان وعرض مخفي للصور تسمى DeconvNet. بفضلها ، أصبح من الممكن فهم أفضل للشبكات العصبية التلافيفية وتطويرها.
VGG Net
في عام 2014 ، اقترح K. Simonyan و E. Zisserman من جامعة أكسفورد بنية تسمى
VGG . الفكرة الرئيسية والمميزة لهذا الهيكل هي
إبقاء المرشحات بسيطة قدر الإمكان . لذلك ، يتم تنفيذ جميع عمليات الالتفاف باستخدام مرشح الحجم 3 وخطوة الحجم 1 ، ويتم تنفيذ جميع عمليات أخذ العينات الفرعية باستخدام مرشح الحجم 2 وخطوة الحجم 2. ومع ذلك ، هذا ليس كل شيء. جنبا إلى جنب مع بساطة الوحدات التلافيفية ، نمت الشبكة بشكل كبير في العمق - الآن لديها 19 طبقة! الفكرة الأكثر أهمية ، المقترحة لأول مرة في هذا العمل ، هي
فرض طبقات تلافيفية بدون طبقات من الاختزال الجزئي . الفكرة الأساسية هي أن مثل هذا التراكب لا يزال يوفر مجالًا استقباليًا كبيرًا بما فيه الكفاية (على سبيل المثال ، ثلاث طبقات تلافيفية متراكبة 3 × 3 في حجم 1 لها مجال استقبال مشابه لطبقة تلافيفية واحدة 7 × 7 في الحجم) ، ومع ذلك ، فإن عدد المعلمات أقل بكثير من الشبكات ذات المرشحات الكبيرة (تعمل كمنظم). بالإضافة إلى ذلك ، يصبح من الممكن إدخال تحويلات غير خطية إضافية.
بشكل أساسي ، أظهر المؤلفون أنه حتى مع كتل البناء البسيطة جدًا ، يمكنك تحقيق نتائج عالية الجودة في مسابقة ImageNet. تم تخفيض عدد الأخطاء للفئات الخمس الرائدة إلى 7.3 في المئة.
 معمارية VGG. يرجى ملاحظة أن عدد الفلاتر يتناسب عكسيا مع الحجم المكاني للصورة.
معمارية VGG. يرجى ملاحظة أن عدد الفلاتر يتناسب عكسيا مع الحجم المكاني للصورة.جوجل نت
في السابق ، كان التطوير الكامل للهندسة المعمارية هو تبسيط المرشحات وزيادة عمق الشبكة. في عام 2014 ، اقترح C. Szegedy ، مع مشاركين آخرين ، نهجًا مختلفًا تمامًا وخلق أكثر الهياكل تعقيدًا في ذلك الوقت ، تسمى GoogLeNet.
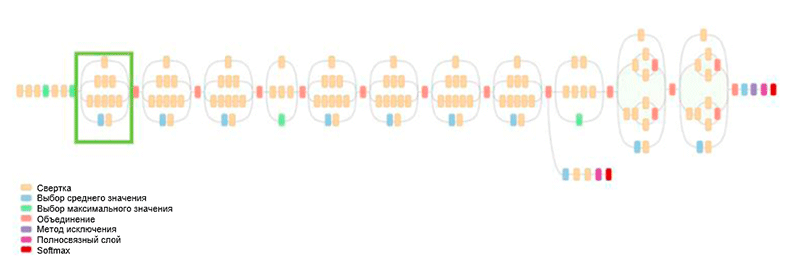 هندسة GoogLeNet. يستخدم وحدة التأسيس ، مظللة باللون الأخضر في الشكل ؛ بناء الشبكة يعتمد على هذه الوحدات
هندسة GoogLeNet. يستخدم وحدة التأسيس ، مظللة باللون الأخضر في الشكل ؛ بناء الشبكة يعتمد على هذه الوحداتأحد الإنجازات الرئيسية لهذا العمل هو ما يسمى وحدة التأسيس ، والتي تظهر في الشكل أدناه. تعالج شبكات البنى الأخرى بيانات الإدخال بالتتابع ، طبقة تلو الأخرى ، أثناء استخدام وحدة
الإدخال ،
تتم معالجة بيانات الإدخال بالتوازي . هذا يسمح لك بتسريع الإخراج ، وكذلك تقليل
العدد الإجمالي للمعلمات .
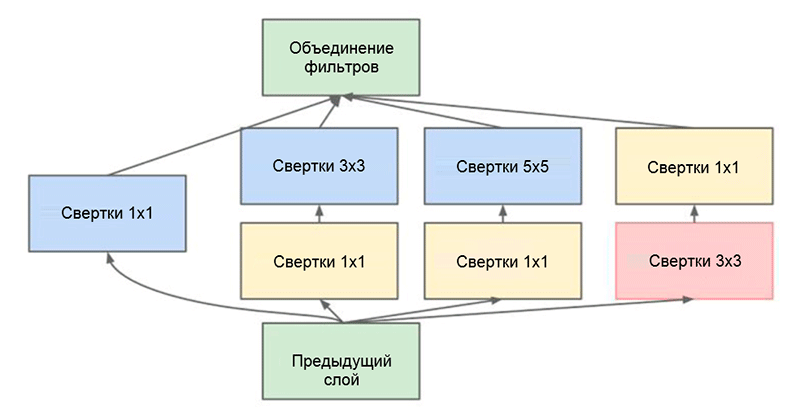 وحدة التأسيس. لاحظ أن الوحدة تستخدم عدة فروع متوازية تحسب خصائص مختلفة بناءً على نفس بيانات الإدخال ، ثم تجمع النتائج
وحدة التأسيس. لاحظ أن الوحدة تستخدم عدة فروع متوازية تحسب خصائص مختلفة بناءً على نفس بيانات الإدخال ، ثم تجمع النتائجحيلة أخرى مثيرة للاهتمام تستخدم في وحدة التأسيس هي استخدام طبقات تلافيفية من الحجم 1 × 1. قد يبدو هذا عديم الجدوى حتى نتذكر حقيقة أن المرشح يغطي أبعاد العمق بالكامل. وبالتالي ، فإن الالتفاف 1 × 1 هو طريقة بسيطة لتقليل أبعاد خريطة الملكية. تم تقديم هذا النوع من الطبقات التلافيفية لأول مرة في
الشبكة بواسطة M. Lin et al. ، ويمكن أيضًا العثور على تفسير شامل ومفهوم في مدونة ما بعد
التحويل [1 × 1] - فائدة مخالفة للحدس بواسطة A. Prakash.
في النهاية ، قللت هذه البنية عدد الأخطاء للفئات الرئيسية الخمس بنسبة النصف في المئة أخرى - إلى 6.7 في المئة.
إعادة الشبكة
في عام 2015 ، توصلت مجموعة من الباحثين (Cuming Hee وآخرين) من Microsoft Research Asia إلى فكرة اعتبرها معظم المجتمع حاليًا واحدة من أهم المراحل في تطوير التعلم العميق.
واحدة من المشاكل الرئيسية للشبكات العصبية العميقة هي مشكلة التدهور المتلاشي. باختصار ، هذه مشكلة فنية تنشأ عند استخدام طريقة الانتشار الخلفي الخطأ لخوارزمية حساب التدرج. عند العمل مع الانتشار الخلفي للأخطاء ، يتم استخدام قاعدة سلسلة. علاوة على ذلك ، إذا كان التدرج له قيمة صغيرة في نهاية الشبكة ، فيمكنه أن يأخذ قيمة صغيرة بشكل لا نهائي في الوقت الذي يصل فيه إلى بداية الشبكة. يمكن أن يؤدي هذا إلى مشاكل ذات طبيعة مختلفة تمامًا ، بما في ذلك استحالة تعلم الشبكة من حيث المبدأ (لمزيد من المعلومات ، راجع إدخال المدونة بواسطة R. Kapur
مشكلة التدرج الخبو ).
لحل هذه المشكلة ، اقترح Caiming Hee ومجموعته الفكرة التالية - للسماح للشبكة بدراسة الخرائط المتبقية (عنصر يجب إضافته إلى المدخلات) بدلاً من العرض نفسه. من الناحية الفنية ، يتم ذلك باستخدام اتصال الالتفاف الموضح في الشكل.
 رسم تخطيطي للكتلة المتبقية: يتم نقل بيانات الإدخال عبر اتصال قصير لتجاوز طبقات التحويل وإضافتها إلى النتيجة. يرجى ملاحظة أن الاتصال "المتطابق" لا يضيف معلمات إضافية إلى الشبكة ، وبالتالي فإن هيكله ليس معقدًا
رسم تخطيطي للكتلة المتبقية: يتم نقل بيانات الإدخال عبر اتصال قصير لتجاوز طبقات التحويل وإضافتها إلى النتيجة. يرجى ملاحظة أن الاتصال "المتطابق" لا يضيف معلمات إضافية إلى الشبكة ، وبالتالي فإن هيكله ليس معقدًاهذه الفكرة بسيطة للغاية ، ولكنها في نفس الوقت فعالة للغاية. إنه يحل مشكلة التدرج المختفي ، مما يسمح له بالتحرك دون أي تغييرات من الطبقات العليا إلى الطبقات السفلية من خلال اتصالات "متطابقة". بفضل هذه الفكرة ، يمكنك تدريب شبكات عميقة للغاية وعميقة للغاية.
احتوت الشبكة التي فازت بتحدي ImageNet في عام 2015 على 152 طبقة (تمكن المؤلفون من تدريب الشبكة التي تحتوي على 1001 طبقة ، لكنها أنتجت نفس النتيجة تقريبًا ، لذلك توقفوا عن العمل معها). بالإضافة إلى ذلك ، جعلت هذه الفكرة من الممكن تقليل عدد الأخطاء للفئات الرائدة الخمس حرفيا إلى النصف - إلى قيمة 3.6 في المئة. وفقًا لدراسة حول
ما تعلمته من خلال التنافس مع شبكة عصبية تلافيفية في مسابقة ImageNet بواسطة A. Karpathy ، يبلغ الأداء البشري لهذه المهمة حوالي 5 بالمائة. وهذا يعني أن بنية ResNet قادرة على تجاوز النتائج البشرية ، على الأقل في مهمة تصنيف الصور هذه.