
لغة جديدة في علوم البيانات. جوليا هي لغة نادرة إلى حد ما في روسيا ، على الرغم من أنها تستخدم في الخارج لمدة 5 سنوات (لقد فاجأوني أيضًا). لا توجد مصادر باللغة الروسية ، لذلك قررت أن أقوم بدراسة قضية جوليا ، مأخوذة من كتاب رائع. أفضل طريقة لتعلم اللغة هي البدء في كتابة شيء فيها.
ولجذب الانتباه أيضًا ، استخدم التعلم الآلي.مرحبا هابروجيتلام.
منذ بعض الوقت ، بدأت أتعلم لغة جوليا الجديدة. حسنًا ، مثل الجديد. هذا شيء بين Matlab و Python ، الصيغة متشابهة للغاية ، واللغة نفسها مكتوبة في C / C ++. بشكل عام ، تاريخ الخلق وماذا ولماذا ولماذا على ويكيبيديا وفي عدد من المقالات حول حبري.
أول شيء بدأ دراستي للغة - حقًا ، Google على Coursera google
دورة عبر الإنترنت باللغة الإنجليزية. هناك ، حول البنية الأساسية + ، يتم كتابة مشروع صغير حول التنبؤ بالأمراض في إفريقيا بالتوازي. الأساسيات والممارسة على الفور. إذا كنت بحاجة إلى شهادة ، قم بشراء النسخة الكاملة. ذهبت مجانا. الفرق بين هذا الإصدار هو أنه لن يقوم أحد بفحص اختباراتك و DZ. كان أهم شيء بالنسبة لي التعرف على الشهادة. (اقرأ انحشر 50 باكز)
بعد ذلك قررت أن أقرأ كتابًا عن جوليا. أصدرت Google قائمة بالكتب ومزيد من دراسة المراجعات والمراجعات ، واخترت أحدها وطلبت على أمازون. دائمًا ما تكون إصدارات الكتاب أجمل للقراءة والرسم بالقلم الرصاص.
يسمى الكتاب
جوليا لعلوم البيانات من قبل زكريا فولغاريس ، دكتوراه. يحتوي المقتطف الذي أريد تقديمه على العديد من الأخطاء المطبعية في التعليمات البرمجية التي قمت بإصلاحها ، وبالتالي سيقدم نسخة العمل + نتائجي.
كيلو نيوتن
هذا مثال على تطبيق خوارزمية التصنيف لطريقة أقرب الجيران. ربما تكون واحدة من أقدم خوارزميات التعلم الآلي. لا تحتوي الخوارزمية على مرحلة تعليمية وهي سريعة جدًا. معناه بسيط للغاية: لتصنيف كائن جديد ، تحتاج إلى العثور على "جيران" متشابهين من مجموعة البيانات (قاعدة البيانات) ثم تحديد الفئة عن طريق التصويت.
سأحجز على الفور أن جوليا لديها حزم جاهزة ، ومن الأفضل استخدامها لتقليل الوقت وتقليل الأخطاء. لكن هذا الرمز يشير إلى حد ما إلى بناء جوليا. من الأنسب بالنسبة لي أن أتعلم لغة جديدة من خلال الأمثلة أكثر من قراءة المقتطفات الجافة للشكل العام للوظيفة.
لذا ، ما لدينا عند المدخل:
بيانات التدريب X (عينة التدريب) ،
ملصقات بيانات التدريب x (العلامات المقابلة) ،
بيانات الاختبار Y (اختيار الاختبار) ،
عدد الجيران k (عدد الجيران).
ستحتاج إلى 3 وظائف:
وظيفة حساب المسافة ووظيفة التصنيف والوظيفة الرئيسية .
خلاصة القول هي: خذ عنصرًا واحدًا من صفيف الاختبار ، احسب المسافة منه إلى عناصر صفيف التدريب. ثم نختار مؤشرات عناصر
k التي تبين أنها قريبة قدر الإمكان. نقوم بتعيين العنصر قيد الاختبار للفئة الأكثر شيوعًا بين أقرب جيران
ك .
function CalculateDistance{T<:Number}(x::Array{T,1}, y::Array{T,1}) dist = 0 for i in 1:length(x) dist += (x[i] - y[i])^2 end dist = sqrt(dist) return dist end
الوظيفة الرئيسية للخوارزمية. مصفوفة المسافات بين كائنات عينات التدريب والاختبار ، والتسميات لمجموعة التدريب ، وعدد أقرب "الجيران" تأتي إلى المدخلات. الإخراج هو التسميات المتوقعة للكائنات الجديدة واحتمالات كل تسمية.
function Classify{T<:Any}(distances::Array{Float64,1}, labels::Array{T,1}, k::Int) class = unique(labels) nc = length(class) #number of classes indexes = Array(Int,k) #initialize vector of indexes of the nearest neighbors M = typemax(typeof(distances[1])) #the largest possible number that this vector can have class_count = zeros(Int, nc) for i in 1:k indexes[i] = indmin(distances) #returns index of the minimum element in a collection distances[indexes[i]] = M #make sure this element is not selected again end klabels = labels[indexes] for i in 1:nc for j in 1:k if klabels[j] == class[i] class_count[i] +=1 end end end m, index = findmax(class_count) conf = m/k #confidence of prediction return class[index], conf end
وبالطبع ، جميع الوظائف.
سيكون لدينا مجموعة تدريب
X عند المدخلات وعلامات مجموعة التدريب
x ومجموعة الاختبار
Y وعدد "الجيران"
ك .
عند الإخراج ، سوف نتلقى التسميات المتوقعة والاحتمالات المقابلة لمنح كل فئة.
function main{T1<:Number, T2<:Any}(X::Array{T1,2}, x::Array{T2,1}, Y::Array{T1,2}, k::Int) N = size(X,1) n = size(Y,1) D = Array(Float64,N) #initialize distance matrix z = Array(eltype(x),n) #initialize labels vector c = Array(Float64, n) #confidence of prediction for i in 1:n for j in 1:N D[j] = CalculateDistance(X[j,:], vec(Y[i,:])) end z[i], c[i] = Classify(D,x,k) end return z, c end
الاختبار
دعونا نختبر ما حصلنا عليه. من أجل الراحة ، نقوم بحفظ الخوارزمية في ملف kNN.jl.
يتم استعارة القاعدة من
دورة التعلم الآلي المفتوحة . تسمى مجموعة البيانات بالتعرف على الأنشطة البشرية من Samsung. تأتي البيانات من مقاييس التسارع والجيروسكوبات للهواتف المحمولة Samsung Galaxy S3 ؛ ومن المعروف أيضًا نوع نشاط الشخص الذي لديه هاتف في جيبه - سواء كان يمشي أو يقف أو يستلقي أو يجلس أو يصعد / ينزل الدرج. سنحل مشكلة تحديد نوع النشاط البدني على وجه التحديد كمشكلة تصنيف.
تتوافق العلامات مع ما يلي:
1 - المشي
2 - يصعد الدرج
3 - نزول الدرج
4 - المقعد
5 - كان الشخص يقف في هذا الوقت
6 - كان الشخص يكذب
include("kNN.jl") training = readdlm("samsung_train.txt"); training_label = readdlm("samsung_train_labels.txt"); testing = readdlm("samsung_test.txt"); testing_label = readdlm("samsung_test_labels.txt"); training_label = map(Int, training_label) testing_label = map(Int, testing_label) z = main(training, vec(training_label), testing, 7) n = length(testing_label) println(sum(testing_label .== z[1]) / n)
النتيجة: 0.9053274516457415يتم تقييم الجودة من خلال نسبة الأشياء المتوقعة بشكل صحيح إلى عينة الاختبار بأكملها. يبدو أنها ليست سيئة للغاية. لكن هدفي هو إظهار جوليا ، وأنه لديه مكان ليكون في علم البيانات.
التصور
بعد ذلك ، أردت أن أحاول تصور نتائج التصنيف. للقيام بذلك ، تحتاج إلى بناء صورة ثنائية الأبعاد ، تحتوي على 561 علامة ولا تعرف أيها أكثر أهمية. لذلك ، لتقليل الأبعاد وتصميم البيانات اللاحق على الفضاء الفرعي المتعامد للميزات ، تقرر استخدام
تحليل المكونات الرئيسية (PCA). في جوليا ، كما هو الحال في بايثون ، هناك حزم جاهزة ، لذلك نبسط حياتنا قليلاً.
using MultivariateStats #for PCA A = testing[1:10,:] #PCA for A M_A = fit(PCA, A'; maxoutdim = 2) Jtr_A = transform(M_A, A'); #PCA for training M = fit(PCA, training'; maxoutdim = 2) Jtr = transform(M, training'); using Gadfly #shows training points and uncertain point pl1 = plot(training, layer(x = Jtr[1,:], y = Jtr[2,:],color = training_label, Geom.point), layer(x = Jtr_A[1,:], y = Jtr_A[2,:], Geom.point)) #predicted values for uncertain points from testing data z1 = main(training, vec(training_label), A, 7) pl2 = plot(training, layer(x = Jtr[1,:], y = Jtr[2,:],color = training_label, Geom.point), layer(x = Jtr_A[1,:], y = Jtr_A[2,:],color = z[1], Geom.point)) vstack(pl1, pl2)
في الشكل الأول ، تم وضع علامة على مجموعة التدريب والعديد من الأشياء من مجموعة الاختبار ، والتي ستحتاج إلى تعيينها إلى فصلهم. وبناء عليه ، يوضح الشكل الثاني أن هذه الأشياء تم تمييزها.

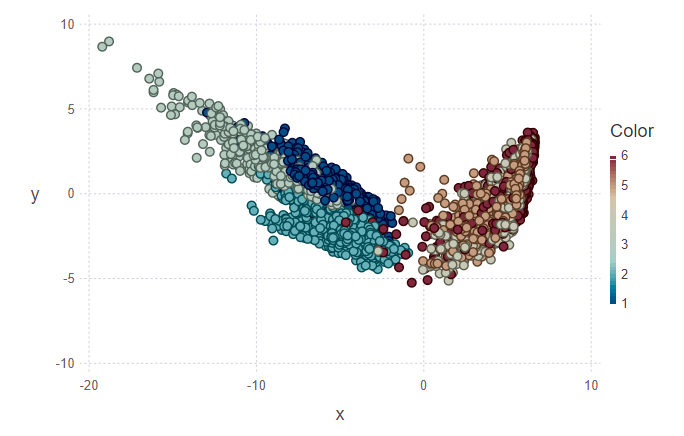
println(z[1][1:10], z[2][1:10]) > [5, 5, 5, 5, 5, 5, 5, 5, 5, 4][1.0, 0.888889, 0.888889, 0.888889, 1.0, 1.0, 1.0, 1.0, 0.777778, 0.555556]
بالنظر إلى الصور ، أريد أن أسأل السؤال "لماذا هذه التجمعات قبيحة؟". سأشرح. لم يتم تحديد المجموعات الفردية بوضوح شديد نظرًا لطبيعة البيانات واستخدام PCA. بالنسبة لـ PCA ، فإن مجرد المشي وتسلق السلالم يشبه فئة واحدة - فئة الحركة. تبعا لذلك ، الطبقة الثانية هي الطبقة الباقية (الجلوس ، الوقوف ، الكذب ، والتي لا يمكن تمييزها فيما بينها). وبالتالي ، يمكن إرجاع الفصل الواضح إلى فئتين بدلاً من ستة.
الخلاصة
بالنسبة لي ، هذا مجرد انغمار أولي في جوليا واستخدام هذه اللغة في التعلم الآلي. بالمناسبة ، أنا أيضًا على الأرجح هاوي أكثر من محترف. ولكن بينما أنا مهتم ، سأستمر في دراسة هذه المسألة بشكل أعمق. العديد من المصادر الأجنبية تراهن على جوليا. حسنا ، انتظر وشاهد.
ملاحظة: إذا كانت مثيرة للاهتمام ، يمكنني أن أخبرك في المنشورات التالية عن ميزات بناء الجملة ، حول IDE ، التي واجهت مشاكل في التثبيت.