ربما لا توجد تقنية أخرى اليوم تدور حولها الكثير من الأساطير والأكاذيب وعدم الكفاءة. الصحفيون الذين يتحدثون عن التكنولوجيا يكذبون ، السياسيون الذين يتحدثون عن التنفيذ الناجح يكذبون ، معظم بائعي التكنولوجيا يكذبون. كل شهر ، أرى عواقب كيفية محاولة الناس تطبيق التعرف على الوجوه في الأنظمة التي لا يمكنها العمل معها.

أصبح موضوع هذه المقالة مؤلمًا منذ فترة طويلة ، ولكنه كان بطريقة ما كسولًا إلى حد ما في كتابته. الكثير من النص الذي كررته بالفعل عشرين مرة لأشخاص مختلفين. ولكن ، بعد قراءة الحزمة التالية من القمامة ، قررت مع ذلك أن الوقت قد حان. سأعطي رابط لهذه المقالة.
لذا في المقال سأجيب على بعض الأسئلة البسيطة:
- هل من الممكن التعرف عليك في الشارع؟ وكيف التلقائي / موثوق؟
- أول من أمس كتبوا أن المجرمين محتجزون في مترو موسكو ، وبالأمس كتبوا أنهم لا يستطيعون في لندن. وكذلك في الصين يعترفون بالجميع ، والجميع في الشارع. وهنا يقولون إن 28 من أعضاء الكونغرس الأمريكي مجرمون. أو قبضوا على لص.
- من الذي يطلق الآن حلول التعرف على الوجه ، ما الفرق بين الحلول وميزات التكنولوجيا؟
ستعتمد معظم الإجابات على الأدلة ، مع ارتباط للبحث حيث يتم عرض المعلمات الرئيسية للخوارزميات + مع رياضيات الحساب. سيعتمد جزء صغير على تجربة تنفيذ وتشغيل أنظمة المقاييس الحيوية المختلفة.
لن أخوض في تفاصيل كيفية تنفيذ التعرف على الوجوه الآن. يوجد في حبري العديد من المقالات الجيدة حول هذا الموضوع:
أ ،
ب ،
ج (هناك الكثير منها ، بالطبع ، تنبثق هذه في الذاكرة). لكن مع ذلك ، بعض النقاط التي تؤثر على القرارات المختلفة - سأصف. لذا فإن قراءة واحدة على الأقل من المقالات أعلاه ستبسط فهم هذه المقالة. دعنا نبدأ!
مقدمة ، أساس
علم القياسات الحيوية هو علم دقيق. ليس هناك مجال لعبارات "يعمل دائمًا" و "مثالي". كل شيء يعتبر جيدًا. ولحساب تحتاج إلى معرفة كميتين فقط:
- أخطاء من النوع الأول - حالة عندما لا يكون الشخص في قاعدة البيانات الخاصة بنا ، لكننا نحدده على أنه شخص موجود في قاعدة البيانات (في biometrics FAR (معدل الوصول الزائف))
- أخطاء من النوع الثاني - حالات عندما يكون الشخص في قاعدة البيانات ، لكننا افتقدناه. (في المقاييس الحيوية FRR (معدل الرفض الكاذب))
يمكن أن تحتوي هذه الأخطاء على عدد من الميزات ومعايير التطبيق. سنتحدث عنها أدناه. في غضون ذلك ، سأخبركم بمكان الحصول عليهم.
الخصائص
الخيار الأول . ذات مرة ، نشر المصنعون أنفسهم أخطاء. ولكن هنا الشيء: لا يمكنك الوثوق بالشركة المصنعة. تحت أي ظروف وكيف قام بقياس هذه الأخطاء - لا أحد يعرف. وسواء يقاس على الإطلاق ، أو رسمها قسم التسويق.
الخيار الثاني. ظهرت قواعد مفتوحة. بدأ المصنعون في الإشارة إلى الأخطاء على الأساس. يمكن صقل الخوارزمية لقواعد البيانات المعروفة ، بحيث تُظهر جودة رائعة لها. ولكن في الواقع ، قد لا تعمل مثل هذه الخوارزمية.
الخيار الثالث هو المسابقات المفتوحة مع حل مغلق. يتحقق المنظم من القرار. kaggle أساسا. أشهرها هو
MegaFace . كانت الأماكن الأولى في هذه المسابقة ذات مرة تتمتع بشعبية كبيرة وشهرة. على سبيل المثال ، جعلت N-Tech و Vocord إلى حد كبير اسمًا لأنفسهما على MegaFace.
كل شيء سيكون على ما يرام ، ولكن بصراحة. يمكنك تخصيص الحل هنا. هذا أصعب بكثير ، أطول. ولكن يمكنك حساب الأشخاص ، ويمكنك ترميز القاعدة يدويًا ، إلخ. والأهم من ذلك - لن يكون لها علاقة بكيفية عمل النظام على البيانات الحقيقية. يمكنك أن ترى من هو القائد في MegaFace الآن ، ثم ابحث عن حلول هؤلاء الرجال في الفقرة التالية.
الخيار الرابع . حتى الآن ، الأكثر صدقا. لا أعرف كيف أغش هناك. على الرغم من أنني لا أستبعدهم.
يوافق معهد كبير ومشهور عالميًا على نشر نظام اختبار حل مستقل. يتم تلقي حزمة SDK من الشركات المصنعة ، والتي تخضع للاختبار المغلق ، والتي لا تشارك فيها الشركة المصنعة. يحتوي الاختبار على العديد من المعلمات ، والتي يتم نشرها رسميًا بعد ذلك.
الآن
يتم إجراء هذا
الاختبار من قبل NIST - المعهد الوطني الأمريكي للمعايير والتقنيات. هذا الاختبار هو الأكثر صدقًا وإثارة للاهتمام.
يجب أن أقول أن المعهد القومي للمعايير والتقنية يقوم بعمل رائع. طوروا خمس حالات ، وأصدروا تحديثات جديدة كل شهرين ، تحسنوا باستمرار وشملوا شركات تصنيع جديدة. هنا يمكنك العثور على أحدث إصدار من الدراسة.
يبدو أن هذا الخيار مثالي للتحليل. لكن لا! العيب الرئيسي لهذا النهج هو أننا لا نعرف ما هو موجود في قاعدة البيانات. انظر إلى هذا الرسم البياني هنا:

هذه هي بيانات شركتين تم اختبارهما. المحور x هو الشهر ، y هي النسبة المئوية للأخطاء. خضت اختبار "الوجوه البرية" (أسفل الوصف مباشرة).
زيادة مفاجئة في الدقة بمقدار 10 مرات في شركتين مستقلتين (بشكل عام ، أقلع الجميع هناك). من أين؟
يقول سجل نيست "كانت قاعدة البيانات معقدة للغاية ، قمنا بتبسيطها." ولا توجد أمثلة على القاعدة القديمة أو القاعدة الجديدة. في رأيي هذا خطأ جسيم. في الأساس القديم كان الفرق بين خوارزميات البائع مرئيًا. على جميع 4-8 ٪ من التمريرات الجديدة. وفي القديم كانت النسبة 29-90٪. يقول تواصلي مع التعرف على الوجوه على أنظمة CCTV أنه في وقت سابق بنسبة 30 ٪ - كانت هذه هي النتيجة الحقيقية لخوارزميات grandmaster. من الصعب التعرف من هذه الصور:

وبالطبع فإن دقة 4٪ لا تتألق عليها. ولكن بدون رؤية قاعدة نيست ، من المستحيل 100٪ الإدلاء بهذه التصريحات. ولكن NIST هو مصدر البيانات المستقل الرئيسي.
في المقالة ، أصف الحالة ذات الصلة لشهر يوليو 2018. في الوقت نفسه ، أعتمد على الدقة ، وفقًا لقاعدة البيانات القديمة للأشخاص للاختبارات المتعلقة بمهمة "الوجوه في البرية".
من الممكن أن يتغير كل شيء تمامًا خلال نصف عام. أو ربما ستستقر على مدى السنوات العشر القادمة.
لذا نحتاج هذا الجدول:
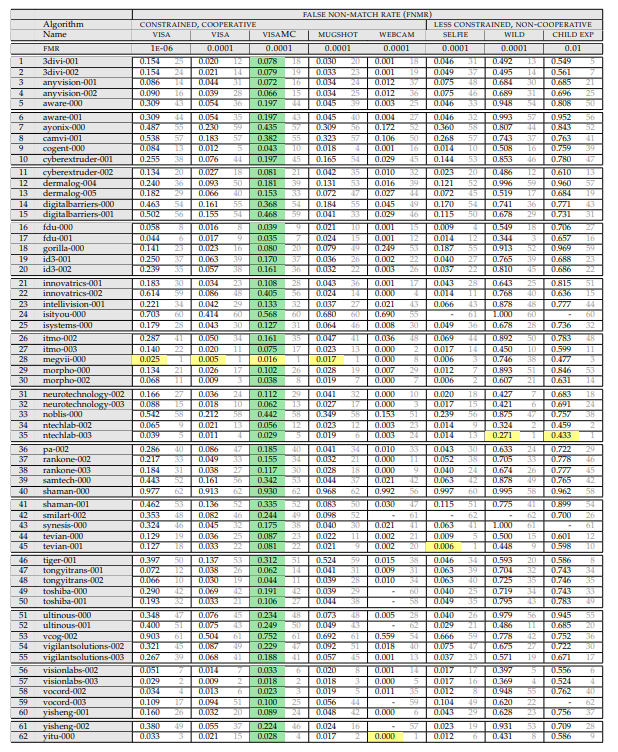
(أبريل 2018 ، لأن البرية أكثر ملاءمة هنا)
دعونا ننظر إلى ما هو مكتوب فيه وكيف يتم قياسه.
أعلاه قائمة التجارب. تتكون التجربة من:
التي يتم قياس المجموعة عليها. المجموعات هي:
- صورة جواز سفر (مثالية ، أمامية). الخلفية بيضاء ، أنظمة تصوير مثالية. يمكن العثور على هذا أحيانًا عند نقطة التفتيش ، ولكن نادرًا جدًا. عادة ما تكون هذه المهام مقارنة بين شخص في المطار مع القاعدة.

- التصوير الفوتوغرافي هو نظام جيد ، ولكن بدون جودة عالية. هناك خلفيات خلفية ، قد لا يقف الشخص بالتساوي / ينظر إلى ما وراء الكاميرا ، إلخ.

- صور ذاتية من هاتف ذكي / كاميرا كمبيوتر. عندما يتعاون المستخدم ، لكن ظروف التصوير سيئة. هناك مجموعتان فرعيتان ، لكن لديهم صور كثيرة فقط في صور السيلفي.

- "الوجوه في البرية" - التصوير من أي تصوير جانبي / مخفي تقريبًا. الحد الأقصى لزوايا دوران الوجه للكاميرا هي 90 درجة. هذا هو المكان الذي قام NIST بتبسيط القاعدة بشكل كبير.

- أطفال. تعمل جميع الخوارزميات بشكل سيئ للأطفال.
بالإضافة إلى ذلك ، على أي مستوى يتم قياس أخطاء الأخطاء من النوع الأول (يتم اعتبار هذه المعلمة فقط لصور جواز السفر):
- 10 ^ -4 - FAR (إيجابية كاذبة من النوع الأول) لـ 10 آلاف مقارنات مع القاعدة
- 10 ^ -6 - FAR (واحد إيجابي كاذب من النوع الأول) لكل مليون مقارنة بالقاعدة
نتيجة التجربة هي قيمة FRR. احتمالية أن نفتقد الشخص الموجود في قاعدة البيانات.
وهنا بالفعل يمكن للقارئ اليقظ أن يلاحظ أول نقطة مثيرة للاهتمام. "ماذا يعني FAR 10 ^ -4؟" وهذه هي اللحظة الأكثر إثارة للاهتمام!
الإعداد الرئيسي
ماذا يعني مثل هذا الخطأ في الممارسة؟ هذا يعني أنه على أساس 10000 شخص سيكون هناك مصادفة واحدة خاطئة عند فحص أي شخص عادي عليه. أي إذا كان لدينا قاعدة من 1000 مجرم ، وقارننا بها 10000 شخص في اليوم ، فسيكون لدينا في المتوسط 1000 من الإيجابيات الكاذبة. هل يحتاج أحد هذا حقا؟
في الواقع ، كل شيء ليس بهذا السوء.
إذا نظرت إلى بناء رسم بياني لاعتماد خطأ من النوع الأول على خطأ من النوع الثاني ، فستحصل على مثل هذه الصورة الرائعة (هنا على الفور لعشرات الشركات المختلفة ، للخيار Wild ، هذا ما سيحدث في محطة المترو إذا وضعت الكاميرا في مكان ما حتى لا يراها الناس) :
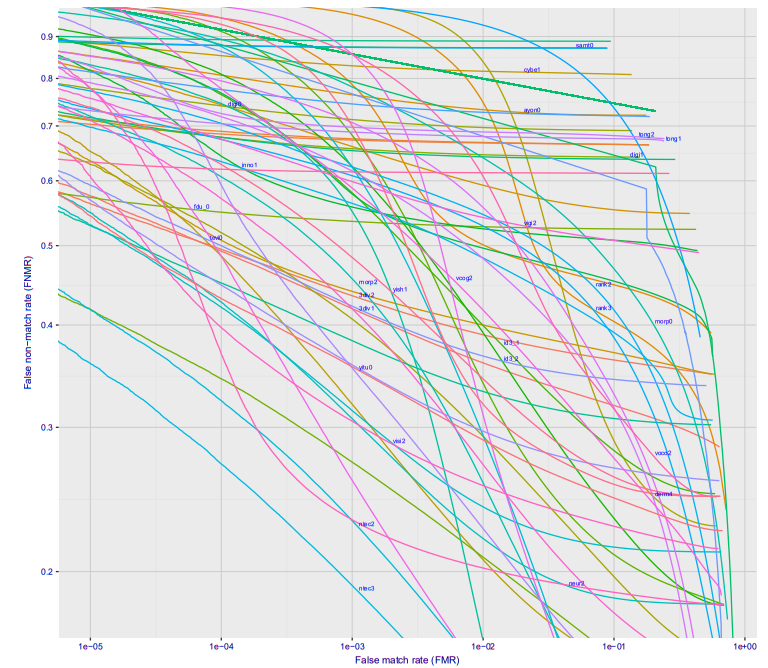
مع خطأ 10 ^ -4 ، 27 ٪ من الأشخاص غير المعترف بهم. 10 ^ -5 تقريبا 40٪. على الأرجح خسارة 10 ^ -6 ستكون حوالي 50٪
فماذا يعني هذا بالأرقام الحقيقية؟
من الأفضل أن ننطلق من نموذج "عدد الأخطاء التي يمكن ارتكابها في اليوم". لدينا عدد كبير من الأشخاص في المحطة ، إذا أعطى النظام إيجابية كاذبة كل 20-30 دقيقة ، فلن يأخذها أحد بجدية. نقوم بإصلاح العدد المسموح به من الإيجابيات الزائفة في محطة المترو 10 أشخاص يوميًا (إذا كان من الجيد أن النظام لم يتم إيقاف تشغيله على أنه مزعج ، فأنت بحاجة إلى أقل). تدفق محطة واحدة لمترو موسكو
20-120 ألف راكب يوميا. المتوسط 60 ألف.
دع القيمة الثابتة لـ FAR تكون 10 ^ -6 (لا يمكنك وضعها أدناه ، سنخسر 50 ٪ من المجرمين إذا كنا متفائلين). هذا يعني أنه يمكننا السماح بـ 10 منبهات كاذبة بحجم قاعدة 160 شخصًا.
هل هو كثير أم قليل؟ حجم القاعدة في قائمة المطلوبين الفيدرالية هو
300000 شخص تقريبًا . انتربول 35 الف. من المنطقي أن نفترض أن حوالي 30 ألفًا من سكان موسكو مطلوبون.
سيعطي هذا عددًا غير واقعي من الإنذارات الكاذبة.
تجدر الإشارة إلى أن 160 شخصًا يمكن أن يكونوا قاعدة كافية إذا كان النظام يعمل على الإنترنت. إذا كنت تبحث عن أولئك الذين ارتكبوا جريمة في اليوم الأخير - فهذا بالفعل حجم عمل. في نفس الوقت ، بارتداء نظارات / قبعات سوداء ، وما إلى ذلك ، يمكنك إخفاء نفسك. ولكن كم عدد يحملها في مترو الأنفاق؟
النقطة المهمة الثانية. من السهل إنشاء نظام في المترو يعطي صورة ذات جودة أعلى. على سبيل المثال ، ضع إطار الباب الدوار للكاميرا. لن تكون هناك بالفعل 50 ٪ من الخسائر بنسبة 10 ^ -6 ، ولكن فقط 2-3 ٪. وبنسبة 10 ^ -7 5-10٪. هنا الدقة من الرسم البياني على Visa ، كل شيء سيكون بالتأكيد أسوأ بكثير على الكاميرات الحقيقية ، ولكن أعتقد أنه في 10 ^ -6 يمكنك ترك هذه الخسارة بنسبة 10 ٪:

مرة أخرى ، لن يسحب النظام قاعدة 30 ألفًا ، ولكن كل ما يحدث في الوقت الفعلي سيسمح بالكشف.
الأسئلة الأولى
يبدو أن الوقت قد حان للإجابة على الجزء الأول من الأسئلة:
قال ليكستوف
انه تم تحديد 22 مطلوبا. هل هذا صحيح؟
هنا السؤال الرئيسي هو ما ارتكبه هؤلاء الأشخاص ، وكم عدد الأشخاص غير المطلوبين الذين تم فحصهم ، وكم التعرف على الوجه ساعد في احتجاز هؤلاء الأشخاص الـ 22.
على الأرجح ، إذا كان هؤلاء هم الأشخاص الذين كانت خطة "الاعتراض" تبحث عنها ، فإنهم محتجزون حقًا. وهذه نتيجة جيدة. لكن افتراضاتي المتواضعة تسمح لي بالقول أنه لتحقيق هذه النتيجة ، تم فحص ما لا يقل عن 2-3 آلاف شخص ، بل حوالي عشرة آلاف.
يتفوق على الأرقام التي تم استدعاؤها في
لندن . هناك فقط هذه الأرقام التي تم نشرها بصدق ، كما
يحتج الناس. ونحن صامتون ...
بالأمس في حبري كان هناك مقال عن
الوجوه المزيفة في التعرف على
الوجوه . لكن هذا مثال على التلاعب في الاتجاه المعاكس. لم يكن لدى أمازون أبدًا نظام جيد للتعرف على الوجوه. بالإضافة إلى السؤال عن كيفية تحديد العتبات. يمكنني على الأقل جعل 100 ٪ من الفول السوداني عن طريق التواء الإعدادات ؛)
عن الصينيين ، الذين يتعرفون على الجميع في الشارع - مزيف واضح. على الرغم من ذلك ، إذا قاموا بتتبع كفؤ ، يمكنك عندئذ إجراء بعض التحليل الأكثر ملاءمة. ولكن ، لأكون صريحًا ، لا أعتقد أنه يمكن تحقيق ذلك حتى الآن. بدلا من ذلك ، مجموعة من المقابس.
ماذا عن سلامتي؟ في الشارع ، في التجمع؟
دعنا نذهب أبعد من ذلك. دعونا نقيم لحظة أخرى. ابحث عن شخص لديه سيرة ذاتية معروفة وملف شخصي جيد في الشبكات الاجتماعية.
يتحقق NIST من التعرف على الوجه وجهاً لوجه. يتم أخذ وجهين لنفس الشخص / مختلف ومقارنة مدى قربهما من بعضهما البعض. إذا كان القرب أكبر من العتبة ، فهذا شخص واحد. إذا كان كذلك - مختلفة. ولكن هناك نهج مختلف.
إذا قرأت المقالات التي نصحت بها في البداية ، فأنت تعلم أنه عند التعرف على الوجه ، يتم إنشاء رمز تجزئة للوجه ، والذي يعرض موضعه في الفضاء N- الأبعاد. عادة ما تكون هذه المساحة الأبعاد 256/512 ، على الرغم من أن جميع الأنظمة لها طرق مختلفة.
يترجم نظام التعرف على الوجه المثالي نفس الوجه إلى نفس الرمز. ولكن لا توجد أنظمة مثالية. عادة ما يشغل الشخص نفسه نفس المساحة. حسنًا ، على سبيل المثال ، إذا كان الرمز ثنائي الأبعاد ، فقد يكون شيئًا مثل هذا:
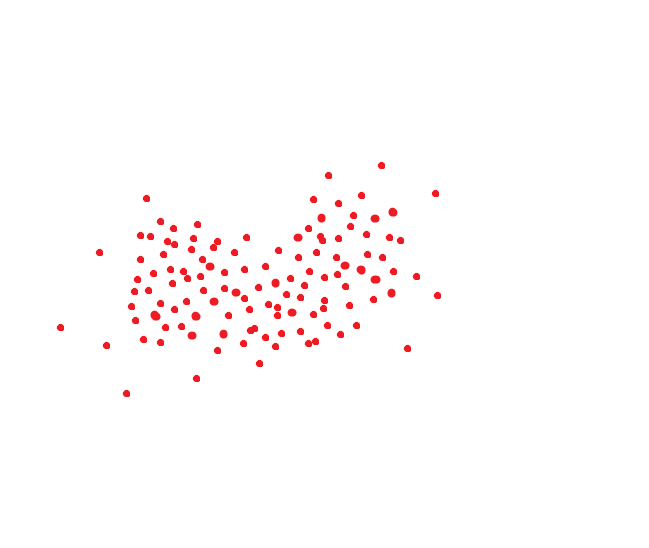
إذا استرشدنا بالطريقة التي اعتمدها المعهد القومي للمعايير والتقنية ، فستكون هذه المسافة عتبة مستهدفة حتى نتمكن من التعرف على شخص واحد ونفس الشخص باحتمالية 95٪:
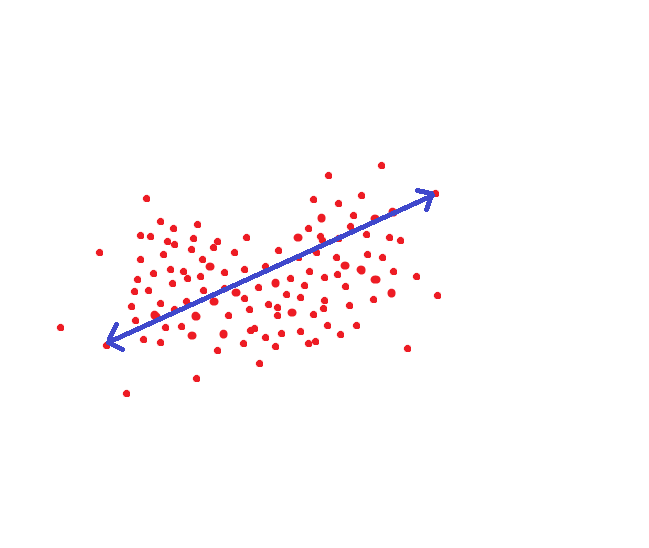
لكن يمكنك فعل خلاف ذلك. لكل شخص ، قم بتكوين منطقة الفضاء الفائق حيث يتم تخزين القيم الصالحة له:

ثم تنخفض مسافة العتبة ، مع الحفاظ على الدقة ، عدة مرات.
نحن فقط بحاجة إلى الكثير من الصور لكل شخص.
إذا كان الشخص لديه ملف تعريف على الشبكات الاجتماعية / قاعدة صوره من مختلف الأعمار ، فيمكن زيادة دقة التعرف كثيرًا. لا أعرف التقييم الدقيق لكيفية نمو FAR | FRR. ومن الخطأ بالفعل تقييم هذه الكميات. شخص في قاعدة البيانات هذه لديه صورتان ، شخص ما لديه 100. الكثير من منطق الالتفاف. يبدو لي أن الحد الأقصى للتقييم هو أمر واحد / واحد ونصف. يسمح لك بإضافة 10 ^ -7 إلى الأخطاء مع احتمال عدم التعرف على 20-30 ٪. لكنها مضاربة ومتفائلة.
بشكل عام ، بالطبع ، هناك الكثير من المشاكل في إدارة هذه المساحة (رقائق العمر ، ورقائق محرر الصور ، ورقائق الضوضاء ، ورقائق الحدة) ، ولكن كما أفهمها ، تم حل معظمها بنجاح من قبل الشركات الكبيرة التي تحتاج إلى حل.
لماذا أفعل هذا. بالإضافة إلى ذلك ، يسمح استخدام ملفات التعريف عدة مرات لزيادة دقة خوارزميات التعرف. لكنها أبعد من أن تكون مطلقة. تتطلب الملفات الشخصية الكثير من العمل اليدوي. هناك العديد من الأشخاص المماثلين. ولكن إذا بدأت في وضع قيود على العمر والموقع وما إلى ذلك ، فإن هذه الطريقة تسمح لك بالحصول على حل جيد. للحصول على مثال عن كيفية العثور على شخص ما على مبدأ "البحث عن الملف الشخصي بالصورة" -> "استخدم الملف الشخصي للبحث عن شخص" أعطيت
رابطًا في البداية.
ولكن ، في رأيي ، هذه عملية قابلة للتطوير للغاية. ومرة أخرى ، الأشخاص الذين لديهم عدد كبير من الصور في الملف الشخصي ، لا قدر الله 40-50٪ في بلدنا. نعم ، وكثير منهم من الأطفال الذين يعمل كل شيء بشكل سيئ.
ولكن ، مرة أخرى - هذا تقييم.
حتى هنا. حول سلامتك. كلما قل عدد صور الملف الشخصي لديك ، كان ذلك أفضل. كلما كان التجمع أكبر ، كلما كان ذلك أفضل. لن يقوم أحد بتحليل 20 ألف صورة يدويًا. بالنسبة لأولئك الذين يهتمون بأمنهم وخصوصيتهم - أنصحك بعدم إنشاء ملفات شخصية مع صورك.
في مسيرة في مدينة يبلغ عدد سكانها 100 ألف نسمة ، سيجدونك بسهولة من خلال النظر في 1-2 مباراة. في موسكو ، يعلقون قليلاً.
منذ حوالي نصف عام ،
تحدث فاسيوتكا ، الذي نعمل معه معًا ، حول هذا الموضوع:
بالمناسبة ، عن الشبكات الاجتماعية
ثم أسمح لنفسي بأخذ رحلة صغيرة إلى الجانب. تعتمد جودة التدريب لخوارزمية التعرف على الوجه على ثلاثة عوامل:
- جودة الوجه.
- استخدام مقياس القرب من الأشخاص أثناء التدريب خسارة ثلاثية ، خسارة مركزية ، خسارة كروية ، إلخ.
- حجم القاعدة
ووفقاً للمطالبة 2 ، يبدو أنه تم الوصول إلى الحد الأقصى الآن. من حيث المبدأ ، تتطور الرياضيات على هذه الأشياء بسرعة كبيرة. وبعد الخسارة الثلاثية ، لم تقدم بقية وظائف الخسارة زيادة كبيرة ، فقط تحسن سلس وانخفاض في حجم القاعدة.
يعد استخراج الوجه أمرًا صعبًا إذا كنت بحاجة إلى العثور على وجوه من جميع الزوايا ، حيث فقدت جزءًا من النسبة المئوية. لكن إنشاء مثل هذه الخوارزمية عملية يمكن التنبؤ بها إلى حد ما وإدارتها بشكل جيد. كلما كان اللون الأزرق أكثر ، كلما تمت معالجة الزوايا الكبيرة بشكل صحيح:

وقبل ستة أشهر كان الأمر على هذا النحو:

يمكن ملاحظة أن المزيد والمزيد من الشركات تتحرك ببطء بهذه الطريقة ، وبدأت الخوارزميات في التعرف على المزيد والمزيد من الوجوه المقلوبة.
ولكن مع حجم القاعدة - كل شيء أكثر إثارة للاهتمام. القواعد المفتوحة صغيرة. قواعد جيدة بحد أقصى بضع عشرات الآلاف من الناس. تلك الكبيرة هي منظمة / سيئة بشكل غريب (
ميجا ،
MS-Celeb-1M ).
من أين حصل مبدعو الخوارزميات على قواعد البيانات هذه؟
تلميح صغير. أول منتج لـ NTech يتم طرحه حاليًا هو Find Face ، بحث عن أشخاص للاتصال بهم. أعتقد أنه لا يوجد تفسير مطلوب. بالطبع ، معارك الاتصال مع الروبوتات التي تنكمش في جميع الملفات الشخصية المفتوحة. ولكن ، بقدر ما سمعت ، لا يزال الناس يهتزون. وزملاء الدراسة. والانستقرام.
يبدو أنه مع Facebook - كل شيء أكثر تعقيدًا هناك. لكنني متأكد تقريبًا من اختراع شيء ما أيضًا.
لذا نعم ، إذا كان ملفك الشخصي مفتوحًا - يمكنك أن تكون فخورًا ، فقد تم استخدامه لتعلم الخوارزميات ؛)
حول الحلول وحول الشركات
هنا يمكنك أن تكون فخوراً. من بين الشركات الخمس الرائدة في العالم ، هناك شركتان روسيتان. هذه هي N-Tech و VisionLabs. قبل نصف عام ، كان NTech و Vocord القادة ، وعمل الأول بشكل أفضل على الوجوه المستديرة ، والأخير على الجبهة.
الآن بقية القادة - 1-2 شركات صينية وأخرى أمريكية ، Vocord مرت بشيء في التصنيف.
لا تزال روسية في ترتيب itmo، 3divi، intellivision. Synesis هي شركة بيلاروسية ، على الرغم من أن بعضها كان في موسكو مرة واحدة ، قبل نحو 3 سنوات كان لديهم مدونة على حبري. أعرف أيضًا العديد من الحلول التي تنتمي إليها الشركات الأجنبية ، ولكن مكاتب التطوير موجودة أيضًا في روسيا. لا تزال هناك العديد من الشركات الروسية التي ليست في المنافسة ، ولكن يبدو أن لديها حلول جيدة. على سبيل المثال ، الأهداف الإنمائية للألفية لها. من الواضح أن Odnoklassniki و Vkontakte لديهم أيضًا ميزاتهم الجيدة ، لكنهم للاستخدام الداخلي.
باختصار ، نعم ، نحن والصينيون ننحرف في الغالب على وجوهنا.
كانت شركة NTech بشكل عام أول شركة في العالم تُظهر معايير جيدة لمستوى جديد. في مكان ما في
نهاية عام 2015 . اشتعلت VisionLabs مع NTech فقط. في عام 2015 ، كانوا رواد السوق. لكن حلهم كان من الجيل الأخير ، وبدأوا في محاولة اللحاق بـ NTech فقط في نهاية عام 2016.
لنكون صادقين ، لا أحب هاتين الشركتين. تسويق عدواني للغاية. رأيت أشخاصًا لديهم حل غير مناسب بشكل واضح لم يحل مشاكلهم.
في هذا الجانب ، أحببت فوكورد أكثر من ذلك بكثير. بطريقة ما ، نصح الرجال الذين قال لهم Vokord بصدق شديد ، "مشروعك لن يعمل مع مثل هذه الكاميرات ونقاط التثبيت." بكل سرور حاولت NTech و VisionLabs البيع. ولكن اختفى شيء ما Vokord مؤخرا.
الاستنتاجات
في الاستنتاجات ، أود أن أقول ما يلي.
التعرف على الوجه هو أداة جيدة وقوية للغاية. يسمح لك حقًا بالعثور على المجرمين اليوم. لكن تنفيذه يتطلب تحليلاً دقيقًا جدًا لجميع المعلمات. هناك تطبيقات حيث حلول OpenSource كافية. هناك تطبيقات (الاعتراف في الملاعب في الحشد) حيث تحتاج فقط إلى تثبيت VisionLabs | Ntech ، وكذلك الاحتفاظ بفريق الخدمة والتحليل وصنع القرار. ولن يساعدك OpenSource هنا.اليوم ، لا يمكن للمرء أن يصدق كل الحكايات التي يمكنك الإمساك بها جميع المجرمين ، أو مشاهدة الجميع في المدينة. لكن من المهم أن تتذكر أن مثل هذه الأشياء يمكن أن تساعد في القبض على المجرمين. على سبيل المثال ، التوقف في مترو الأنفاق ليس الجميع ، ولكن فقط أولئك الذين يعتبرهم النظام مشابهًا. كاميرات تحديد المواقع بحيث يتم التعرف على الوجوه بشكل أفضل وإنشاء البنية التحتية المناسبة لذلك. على سبيل المثال ، أنا ضد هذا. ثمن خطأ إذا تم التعرف عليك كشخص آخر قد يكون مرتفعًا جدًا.