لقد كتبنا بالفعل في
المقالة الأولى من مدونة الشركة حول كيفية عمل خوارزمية الكشف عن الاقتراضات القابلة للتحويل. تم تخصيص فقرتين فقط في تلك المقالة لموضوع مقارنة النصوص ، على الرغم من أن الفكرة تستحق وصفًا أكثر تفصيلاً. ومع ذلك ، كما تعلم ، لا يمكن للمرء أن يقول على الفور عن كل شيء ، على الرغم من أن المرء يريد ذلك حقًا. في محاولة للإشادة بهذا الموضوع وبنية الشبكة المسماة "
التشفير التلقائي " ، والتي لدينا مشاعر دافئة للغاية ، كتبت
Oleg_Bakhteev هذه المراجعة.

المصدر:
Deep Learning for NLP (without Magic)كما ذكرنا في تلك المقالة ، كانت مقارنة النصوص "دلالية" - لم نقارن أجزاء النص نفسها ، ولكن المتجهات المقابلة لها. تم الحصول على هذه المتجهات نتيجة لتدريب شبكة عصبية ، والتي عرضت جزءًا نصيًا بطول تعسفي في ناقلات ذات أبعاد كبيرة ولكنها ثابتة. كيفية الحصول على مثل هذا التخطيط وكيفية تعليم الشبكة لتحقيق النتائج المرجوة هي مسألة منفصلة ، والتي سيتم مناقشتها أدناه.
ما هو برنامج التشفير التلقائي؟
رسميا ، تسمى الشبكة العصبية التشفير التلقائي (أو التشفير التلقائي) ، والذي يتدرب لاستعادة الكائنات التي تم تلقيها عند إدخال الشبكة.
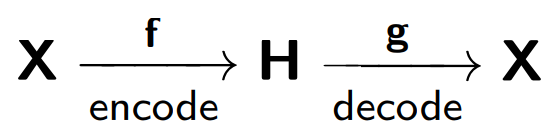
يتكون المشفر التلقائي من جزأين: المشفر
f ، الذي يشفر العينة
X في تمثيلها الداخلي
H ، وفك التشفير
g ، الذي يعيد العينة الأصلية. وبالتالي ، يحاول المبرمج الآلي دمج النسخة المستعادة من كل كائن عينة مع الكائن الأصلي.
عند تدريب برنامج التشفير التلقائي ، يتم تصغير الوظيفة التالية:
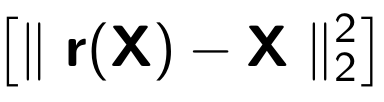
حيث يشير
r إلى النسخة المستعادة من الكائن الأصلي:

فكر في المثال المقدم في
blog.keras.io :

تستقبل الشبكة كائن
x كمدخل (في حالتنا ، الرقم 2).
تشفر شبكتنا هذا الكائن في حالة مخفية. ثم ، وفقًا للحالة الكامنة ،
تتم استعادة إعادة بناء الكائن
r ، والذي يجب أن يكون مشابهًا لـ x. كما نرى ، أصبحت الصورة المستعادة (على اليمين) أكثر ضبابية. ويفسر ذلك حقيقة أننا نحاول الاحتفاظ في العرض المخفي فقط بأهم علامات الكائن ، بحيث يتم استعادة الكائن مع الخسائر.
يتم تدريب نموذج التشفير التلقائي على مبدأ الهاتف التالف ، حيث يقوم شخص واحد (التشفير) بنقل المعلومات
(x ) إلى الشخص الثاني (فك التشفير
) ، ويخبره بدوره إلى الثالث
(r (x)) .
أحد الأغراض الرئيسية لمثل هذه التشفير التلقائي هو تقليل أبعاد مساحة المصدر. عندما نتعامل مع المشفرات التلقائية ، فإن إجراء تدريب الشبكة العصبية نفسه يجعل المشفر التلقائي يتذكر الميزات الرئيسية للكائنات التي سيكون من الأسهل استعادة كائنات العينة الأصلية.
هنا يمكننا رسم تشابه مع
طريقة المكونات الرئيسية : هذه طريقة لتقليل البعد ، ونتيجة ذلك هي إسقاط العينة على مساحة فرعية يكون فيها تباين هذه العينة إلى أقصى حد.
في الواقع ، يعد التشفير التلقائي تعميماً لطريقة المكون الرئيسي: في الحالة التي نقتصر فيها على النظر في النماذج الخطية ، يعطي التشفير التلقائي وطريقة المكون الرئيسي نفس تمثيلات المتجه. ينشأ الاختلاف عندما نفكر في نماذج أكثر تعقيدًا ، على سبيل المثال ، الشبكات العصبية المتصلة بالكامل متعددة الطبقات ، كمشفر وفك تشفير.
يتم تقديم مثال على مقارنة طريقة المكون الرئيسي والتشفير التلقائي في المقالة
تقليل أبعاد البيانات مع الشبكات العصبية :
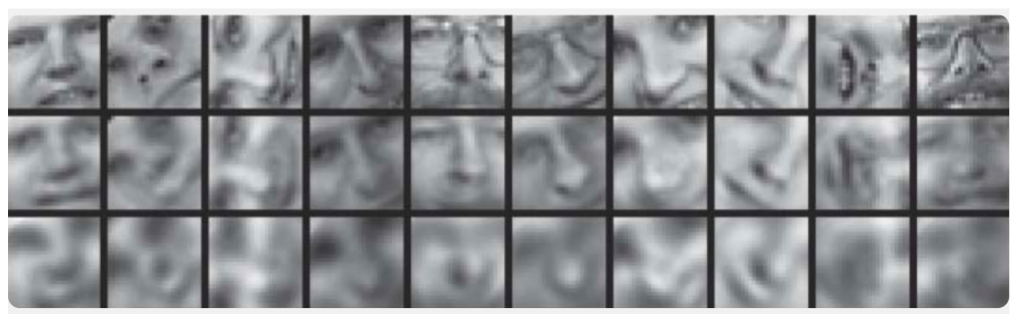
هنا ، يتم عرض نتائج تدريب المشفر التلقائي وطريقة المكون الرئيسي لأخذ عينات من صور الوجوه البشرية. يوضح السطر الأول وجوه الأشخاص من عينة التحكم ، أي من جزء مؤجل بشكل خاص من العينة لم تستخدمه الخوارزميات في عملية التعلم. على السطرين الثاني والثالث توجد الصور المستعادة من الحالات المخفية للترميز التلقائي وأسلوب المكون الرئيسي ، على التوالي ، من نفس البعد. هنا يمكنك أن ترى بوضوح مدى عمل برنامج التشفير التلقائي بشكل أفضل.
في نفس المقالة ، مثال توضيحي آخر: مقارنة نتائج التشفير التلقائي وأسلوب
LSA لمهمة استرجاع المعلومات. طريقة LSA ، مثل طريقة المكون الرئيسي ، هي طريقة التعلم الآلي الكلاسيكية وغالبًا ما تستخدم في المهام المتعلقة بمعالجة اللغة الطبيعية.

يوضح الشكل إسقاطًا ثنائي الأبعاد لوثائق متعددة تم الحصول عليها باستخدام طريقة التشفير التلقائي وطريقة LSA. تشير الألوان إلى موضوع المستند. يمكن ملاحظة أن الإسقاط من برنامج التشفير التلقائي يكسر المستندات حسب الموضوع جيدًا ، بينما ينتج LSA نتيجة أكثر تشويشًا.
تطبيق آخر مهم من برامج
التشفير التلقائي
هو التدريب المسبق للشبكة . يتم استخدام التدريب المسبق للشبكة عندما تكون الشبكة المحسنة عميقة بما يكفي. في هذه الحالة ، يمكن أن يكون تدريب الشبكة "من البداية" أمرًا صعبًا ، لذلك يتم أولاً تمثيل الشبكة بأكملها كسلسلة من برامج التشفير.
إن خوارزمية التدريب المسبق بسيطة للغاية: لكل طبقة نقوم بتدريب برنامج التشفير التلقائي الخاص بنا ، ثم نضع أن ناتج برنامج التشفير التالي هو في نفس الوقت إدخال طبقة الشبكة التالية. يتكون النموذج الناتج من سلسلة من برامج التشفير التي تم تدريبها على الحفاظ على شغف أهم ميزات الأشياء ، كل منها في الطبقة الخاصة بها. يتم عرض مخطط ما قبل التدريب أدناه:
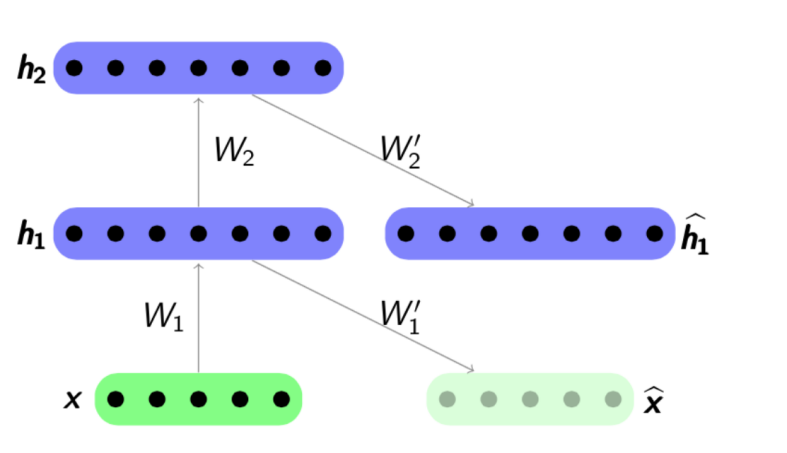
المصدر:
psyyz10.imtqy.comيُطلق على هذا الهيكل مكدس تلقائي مكدس وغالبًا ما يُستخدم كـ "رفع تردد التشغيل" لزيادة تدريب نموذج الشبكة العميق بالكامل. الدافع لمثل هذا التدريب للشبكة العصبية هو أن الشبكة العصبية العميقة هي وظيفة غير محدبة: في عملية تدريب الشبكة ، يمكن تحسين المعلمات "التعثر" في الحد الأدنى المحلي. يتيح لك التدريب الجشع المسبق لمعلمات الشبكة العثور على نقطة بداية جيدة للتدريب النهائي وبالتالي محاولة تجنب مثل هذه الحدود الدنيا المحلية.
بالطبع ، لم نفكر في جميع الهياكل الممكنة ، لأن هناك
Sparse Autoencoders ،
Denoising Autoencoders ،
Contractive Autoencoder ،
Reconstruction Contractive Autoencoder . وهي تختلف فيما بينها باستخدام وظائف الخطأ المختلفة ومصطلحات العقوبة لها. كل هذه البنى في رأينا تستحق مراجعة منفصلة. في مقالتنا ، نظهر أولاً وقبل كل شيء ، المفهوم العام للتشفير التلقائي والمهام المحددة لتحليل النص التي يتم حلها باستخدامها.
كيف يعمل في النصوص؟
ننتقل الآن إلى أمثلة محددة لاستخدام أجهزة التشفير الآلي لمهام تحليل النص. نحن مهتمون بكلا جانبي التطبيق - كلا النموذجين للحصول على تمثيلات داخلية ، واستخدام هذه التمثيلات الداخلية كسمات ، على سبيل المثال ، في مشكلة التصنيف الإضافية. غالبًا ما تتناول المقالات حول هذا الموضوع مهامًا مثل تحليل المشاعر أو إعادة صياغة الكشف ، ولكن هناك أيضًا أعمال تصف استخدام الترميز التلقائي لمقارنة النصوص بلغات مختلفة أو للترجمة الآلية.
في مهام تحليل النص ، غالبًا ما يكون الكائن هو الجملة ، أي ترتيب ترتيب الكلمات. وبالتالي ، يتلقى المشفر التلقائي بالضبط هذا التسلسل من الكلمات ، أو بالأحرى ، تمثيلات المتجهات لهذه الكلمات المأخوذة من بعض النماذج المدربة سابقًا. ما هي الكلمات المتجهية للكلمات ، تم اعتبارها في حبري بتفاصيل كافية ، على سبيل المثال
هنا . وبالتالي ، يجب على المشفر التلقائي ، مع أخذ سلسلة من الكلمات كمدخل ، تدريب بعض التمثيل الداخلي للجملة بأكملها التي تلبي الخصائص التي تهمنا ، بناءً على المهمة. في مشاكل تحليل النص ، نحتاج إلى تعيين جمل للمتجهات بحيث تكون قريبة بمعنى بعض وظيفة المسافة ، وغالبًا ما يكون مقياس جيب التمام:
المصدر:
Deep Learning for NLP (without Magic)كان
ريتشارد سوشر من أوائل المؤلفين الذين أظهروا الاستخدام الناجح
للمشفرات التلقائية في تحليل النص.
في مقاله
الديناميكي والتشفير التلقائي المتكرر للكشف عن إعادة صياغة ، يصف بنية تشفير تلقائية جديدة - تتكشف ترميز تلقائي متكرر (تتكشف RAE) (انظر الشكل أدناه).

تتكشف RAE
من المفترض أن بنية الجملة يتم تعريفها بواسطة
المحلل اللغوي . يعتبر أبسط هيكل - هيكل شجرة ثنائية. تتكون هذه الشجرة من أوراق - كلمات جزء ، عقد داخلية (عقد فرعية) - عبارات ، ورأس طرفية. بأخذ تسلسل الكلمات (×
1 ، ×
2 ، ×
3 ) كمدخل (ثلاث تمثيلات متجهة للكلمات في هذا المثال) ، يقوم التشفير التلقائي بترميز تسلسلي ، في هذه الحالة ، من اليمين إلى اليسار ، تمثيلات متجهة لكلمات الجملة إلى تمثيلات متجهية للصفقات ، ثم إلى ناقل تقديم العرض بأكمله. على وجه التحديد في هذا المثال ، نقوم أولاً بربط المتجهات x
2 و x
3 ، ثم
نضربها في المصفوفة
W e بعد أن يكون البعد
مخفيًا × 2 مرئيًا ، حيث يكون
المخفي حيث يكون حجم التمثيل الداخلي المخفي ،
المرئي هو بُعد متجه الكلمة. وبالتالي ، نقوم بتقليل البعد ، ثم نضيف اللاخطية باستخدام دالة tanh. في الخطوة الأولى ، نحصل على تمثيل متجه مخفي لعبارة كلمتين
x 2 و
x 3 :
h 1 =
tanh (W e [x 2 ، x 3 ] + b e ) . في الثانية ، نقوم
بدمجها والكلمة المتبقية
h 2 =
tanh (W e [h 1 ، x 1 ] + b e ) والحصول على تمثيل متجه للجملة بأكملها -
h 2 . كما ذكر أعلاه ، في تعريف برنامج التشفير التلقائي ، نحتاج إلى تقليل الخطأ بين الكائنات وإصداراتها المستعادة. في حالتنا ، هذه الكلمات. لذلك ، بعد استلام التمثيل النهائي لناقلات الجملة بأكملها
h 2 ، سنقوم بفك تشفير نسخها المستعادة (x
1 '، x
2 ' ، x
3 '). يعمل مفكك التشفير هنا على نفس مبدأ التشفير ، فقط مصفوفة المعلمات ومتجه التحول تختلف هنا:
W d و
b d .
باستخدام بنية شجرة ثنائية ، يمكنك ترميز جمل بأي طول في متجه البعد الثابت - نحن نجمع دائمًا زوجًا من المتجهات من نفس البعد ، باستخدام نفس مصفوفة المعلمات
W e . في حالة شجرة غير ثنائية ، تحتاج فقط إلى تهيئة المصفوفات مسبقًا إذا أردنا الجمع بين أكثر من كلمتين - 3 ، 4 ، ... n ، وفي هذه الحالة ، سيكون للمصفوفة البعد
المخفي × غير مرئي .
من الجدير بالذكر أنه في هذه المقالة ، يتم استخدام تمثيلات المتجهات المدربة للعبارات ليس فقط لحل مشكلة التصنيف - يتم إعادة صياغة جملتين أم لا. يتم أيضًا تقديم بيانات تجربة على البحث عن أقرب الجيران - بناءً على متجه العرض المستلم فقط ، يتم البحث عن أقرب ناقلات في العينة قريبة منها بمعنى:

ومع ذلك ، لا أحد يزعجنا لاستخدام بنى الشبكة الأخرى للترميز وفك التشفير لدمج الكلمات بالتسلسل في جمل.
في ما يلي مثال من مقالة NIPS 2017 -
تعلم تمثيل فقرات Deconvol الدستورية :

نرى أن ترميز العينة
X في التمثيل المخفي
h يحدث باستخدام
شبكة عصبية تلافيفية ، ويعمل مفكك التشفير على نفس المبدأ.
أو هنا مثال باستخدام
GRU-GRU في مقالة
تخطي الفكر .
ميزة مثيرة للاهتمام هنا هي أن النموذج يعمل مع ثلاث جمل من الجمل: (
s i-1 ، s i ، s i + 1 ). يتم تشفير الجملة
s i باستخدام صيغ GRU القياسية ، ويحاول مفكك التشفير ، باستخدام معلومات التمثيل الداخلي
s i ، فك تشفير
s i-1 و
s i + 1 ، وكذلك باستخدام GRU.

يشبه مبدأ التشغيل في هذه الحالة النموذج القياسي
للترجمة الآلية للشبكة العصبية ، والذي يعمل وفقًا لمخطط وحدة فك ترميز التشفير. ومع ذلك ، هنا ليس لدينا لغتان ، نقدم عبارة في لغة واحدة لإدخال وحدة التشفير الخاصة بنا ونحاول استعادتها. في عملية التعلم ، هناك تقليل لبعض الوظائف الداخلية للجودة (هذا ليس خطأ إعادة البناء دائمًا) ، ثم ، إذا لزم الأمر ، يتم استخدام ناقلات متدربة مسبقًا كميزات في مشكلة أخرى.
تقدم ورقة أخرى ، هي
الترميز التلقائي المتكرر ثنائي اللغة للترجمة الآلية الإحصائية ، بنية تلقي نظرة جديدة على الترجمة الآلية. أولاً ، بالنسبة للغتين ، يتم تدريب أجهزة الترميز العودية بشكل منفصل (وفقًا للمبدأ الموصوف أعلاه - حيث تم تقديم Unfolding RAE). ثم ، فيما بينهم ، يتم تدريب برنامج تشفير تلقائي ثالث - تعيين بين لغتين. تتمتع مثل هذه البنية بميزة واضحة - عند عرض النصوص بلغات مختلفة في مكان واحد مخفي مشترك ، يمكننا مقارنتها دون استخدام الترجمة الآلية كخطوة وسيطة.
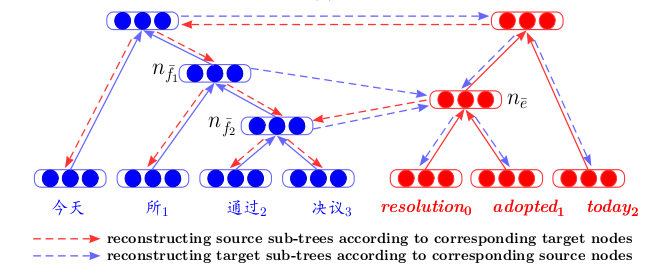
غالبًا ما يتم العثور على
تدريب برامج التشفير التلقائي على أجزاء النص في مقالات حول
تصنيف التدريب . هنا ، مرة أخرى ، حقيقة أننا نقوم بتدريب الوظيفة النهائية لجودة التصنيف أمر مهم ، نقوم أولاً بتدريب برنامج التشفير التلقائي بشكل أولي لتهيئة متجهات الطلبات والاستجابات المقدمة إلى إدخال الشبكة.

وبالطبع ، لا يسعنا إلا أن نذكر أجهزة
الترميز التلقائي المتغيرة أو
VAEs كنماذج مولدة. من الأفضل بالطبع مشاهدة مجرد مشاركة
المحاضرة هذه من Yandex . يكفي بالنسبة لنا أن نقول ما يلي: إذا أردنا
إنشاء كائنات من المساحة المخفية للمشفّر التلقائي التقليدي ، فستكون جودة هذا الجيل منخفضة ، لأننا لا نعرف أي شيء عن توزيع المتغير المخفي. ولكن يمكنك تدريب برنامج التشفير التلقائي على الفور على الإنشاء ، مع تقديم افتراض التوزيع.
وبعد ذلك ، باستخدام VAE ، يمكنك إنشاء نصوص من هذه المساحة المخفية ، على سبيل المثال ، كما يفعل مؤلفو المقالة إنشاء
جمل من الفضاء المستمر أو
A Auto Hyodial Volational Auto Vodational Auto Textoder .
تعمل الخصائص التوليدية لـ VAE أيضًا بشكل جيد في المهام التي تقارن النصوص بلغات مختلفة -
يعد نهج الترميز التلقائي المتنوع لتحفيز تضمين الكلمات عبر اللغات مثالًا ممتازًا على ذلك.
في الختام ، نريد عمل توقعات صغيرة.
تعلم التمثيل - يعد التدريب على التمثيلات الداخلية باستخدام VAE بالضبط ، خاصةً بالاقتران مع
شبكات الخصومة التوليدية ، أحد أكثر الأساليب تطورًا في السنوات الأخيرة - يمكن الحكم على ذلك من خلال أكثر الموضوعات شيوعًا على الأقل في أحدث
مؤتمرات التعلم الآلي
ICLR 2018 و
ICML 2018 . هذا أمر منطقي تمامًا - لأن استخدامه ساعد على تحسين الجودة في عدد من المهام ، وليس فقط فيما يتعلق بالنصوص. ولكن هذا هو موضوع مراجعة مختلفة تمامًا ...