شارك في تأليف المقال: مايك تشنغ
يحتوي Google Cloud Platform الآن على صور آلة افتراضية في محفظته ، تم تصميمها خصيصًا لأولئك المشاركين في Deep Learning. سنتحدث اليوم عن ما تمثله هذه الصور ، وما المزايا التي تمنحها للمطورين والباحثين ، وبالطبع ، كيفية إنشاء جهاز افتراضي بناءً عليها.
الانحدار الغنائي: في وقت كتابة هذا التقرير ، كان المنتج لا يزال في الإصدار التجريبي ، على التوالي ، ولا تنطبق عليه اتفاقيات مستوى الخدمة.
أي نوع من الوحوش هذا ، صور الأجهزة الافتراضية لـ Deep Learning from Google؟
صور الآلة الافتراضية لـ Deep Learning from Google هي صور Debian 9 التي تحتوي على كل ما يحتاجه Deep Learning مباشرة. حاليًا ، هناك إصدارات من الصور مع TensorFlow و PyTorch وصور للأغراض العامة. كل إصدار موجود في الإصدار لمثيلات وحدة المعالجة المركزية ووحدة معالجة الرسومات فقط. من أجل فهم الصورة التي تحتاجها بشكل أفضل ، رسمت ورقة غش صغيرة:
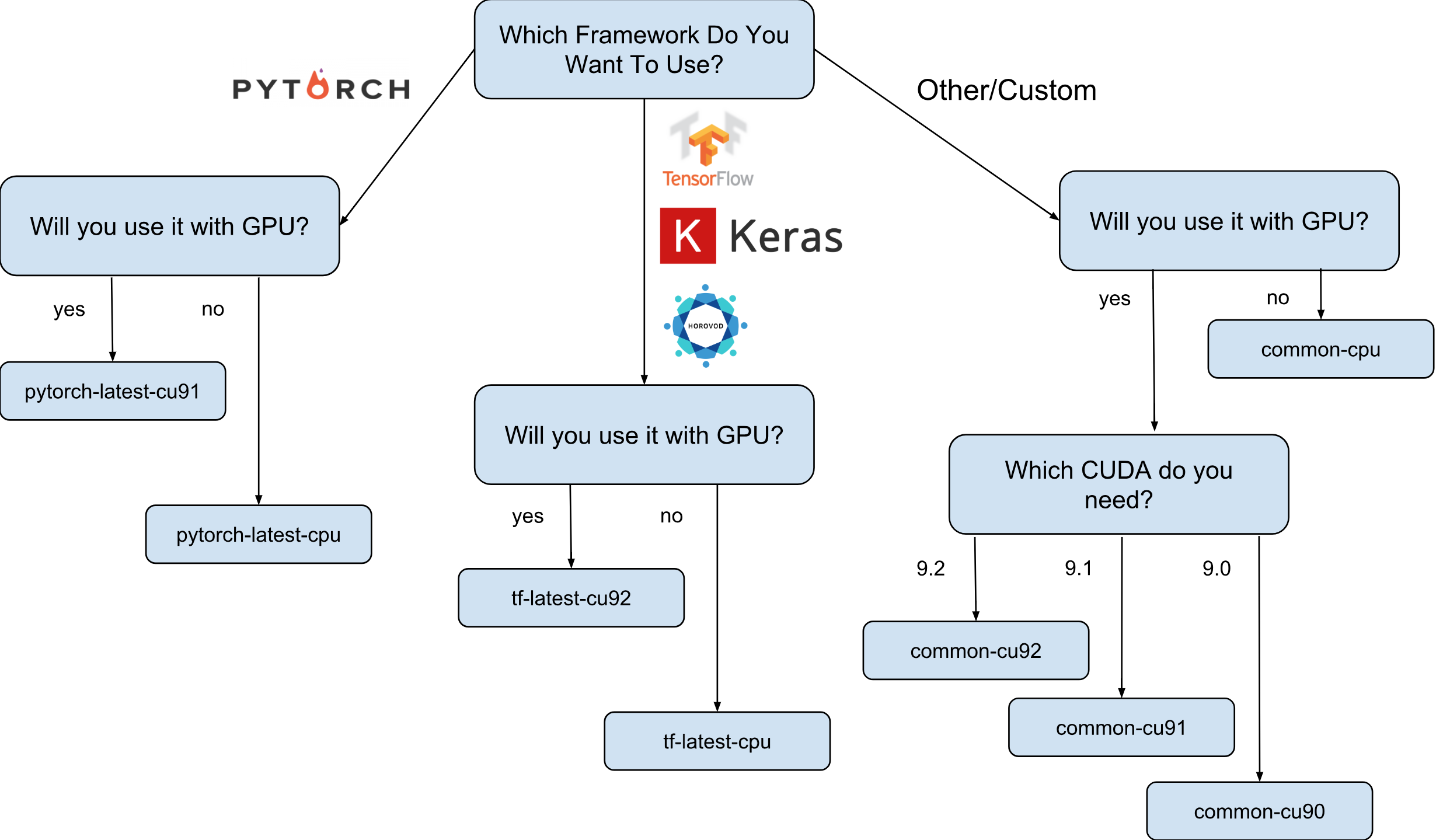
كما هو موضح في ورقة الغش ، هناك 8 عائلات صور مختلفة. كما ذكرنا من قبل ، كلهم يعتمدون على دبيان 9.
ما هو بالضبط مثبت مسبقًا على الصور؟
تحتوي جميع الصور على Python 2.7 / 3.5 مع الحزم المثبتة مسبقًا التالية:
- جامع
- sklearn
- مخادع
- الباندا
- نلتك
- وسادة
- بيئات المشتري (مختبر ودفتر)
- وغير ذلك الكثير.
مكدس مكون من Nvidia (فقط في صور GPU):
- كودا 9. *
- كودن 7.1
- NCCL 2. *
- أحدث سائق نفيديا
يتم تحديث القائمة باستمرار ، لذا ابق على اطلاع على الصفحة الرسمية .
ولماذا هذه الصور مطلوبة بالفعل؟
لنفترض أنك بحاجة إلى تدريب نموذج الشبكة العصبية باستخدام Keras (مع TensorFlow). سرعة التعلم مهمة بالنسبة لك وأنت تقرر استخدام GPU. لاستخدام GPU ، ستحتاج إلى تثبيت وتكوين مكدس Nvidia (Nvidia driver + CUDA + CuDNN + NCCL). هذه العملية ليست معقدة في حد ذاتها فقط (خاصة إذا لم تكن مهندس نظام ، ولكن باحثًا) ، بل إنها أكثر تعقيدًا بحقيقة أنك بحاجة إلى التفكير في التبعيات الثنائية لإصدارك من مكتبة TensorFlow. على سبيل المثال ، يتم تجميع توزيع TensorFlow 1.9 الرسمي مع CUDA 9.0 ولن يعمل إذا كان لديك مكدس مثبت عليه CUDA 9.1 أو 9.2. يمكن أن يكون إنشاء هذا المكدس عملية "ممتعة" ، أعتقد أنه لا يمكن لأحد أن يجادل في هذا (خاصة أولئك الذين قاموا بذلك).
افترض الآن أنه بعد عدة ليال بلا نوم تم إعداد كل شيء والعمل. سؤال: هذا التكوين ، الذي كنت قادرًا على تكوينه ، هل هو الأمثل لجهازك؟ على سبيل المثال ، هل صحيح أن CUDA 9.0 المثبتة والحزمة الثنائية الرسمية TensorFlow 1.9 تظهر أسرع سرعة في مثيل مع معالج SkyLake ووحدة معالجة رسومات Volta V100 واحدة؟
يكاد يكون من المستحيل الإجابة دون اختبار مع إصدارات أخرى من CUDA. للإجابة بالتأكيد ، تحتاج إلى إعادة بناء TensorFlow يدويًا في تكوينات مختلفة وتشغيل الاختبارات الخاصة بك. يجب تنفيذ كل هذا على تلك الأجهزة باهظة الثمن ، والتي من المقرر تدريب النموذج عليها لاحقًا. حسنًا ، والأخير جدًا ، يمكن التخلص من كل هذه القياسات بمجرد إصدار الإصدار الجديد من TensorFlow أو مكدس Nvidia. يمكن القول بأمان أن معظم الباحثين لن يفعلوا ذلك ببساطة وسيستخدمون ببساطة مجموعة TensorFlow القياسية ، دون السرعة المثلى.
هذا هو المكان الذي تظهر فيه صور Deep Learning من Google على المشهد. على سبيل المثال ، تحتوي الصور التي تحتوي على TensorFlow على تجميع TensorFlow الخاص بها ، والذي تم تحسينه للأجهزة المتوفرة على Google Cloud Engine. يتم اختبارها بتكوين مختلف لمكدس Nvidia وتستند إلى التكوين الذي أظهر أعلى أداء (المفسد: هذا ليس دائمًا الأحدث). حسنًا والأهم من ذلك - تم تثبيت كل ما تحتاجه تقريبًا للبحث مسبقًا!
كيف يمكنني إنشاء مثيل بناءً على إحدى الصور؟
هناك خياران لإنشاء مثيل جديد بناءً على هذه الصور:
- استخدام واجهة مستخدم الويب Google Cloud Marketplace
- باستخدام gcloud
نظرًا لأنني معجب كبير بالمرافق الطرفية و CLI ، سأتحدث في هذا المقال عن هذا الخيار. علاوة على ذلك ، إذا كنت تحب واجهة المستخدم ، فهناك وثائق جيدة تصف كيفية إنشاء مثيل باستخدام واجهة مستخدم الويب .
قبل المتابعة ، قم بتثبيت أداة gcloud (إذا لم تكن قد قمت بالفعل بتثبيت). بشكل اختياري ، يمكنك استخدام Google Cloud Shell ، ومع ذلك ، لاحظ أن وظيفة WebPreview في Google Cloud Shell غير مدعومة حاليًا وبالتالي لا يمكنك استخدام Jupyter Lab أو Notebook هناك.
الخطوة التالية هي تحديد عائلة الصور. سأسمح لنفسي مرة أخرى بإحضار ورقة الغش مع اختيار مجموعة من الصور.
على سبيل المثال ، نفترض أن اختيارك وقع على tf-latest-cu92 ، وسوف نستخدمه لاحقًا في النص.
انتظر ، ولكن ماذا لو كنت بحاجة إلى إصدار محدد من TensorFlow ، بدلاً من "الأحدث"؟
لنفترض أن لدينا مشروعًا يتطلب TensorFlow 1.8 ، ولكن في نفس الوقت تم إصدار 1.9 بالفعل وأن الصور في عائلة tf-latest لديها بالفعل 1.9. في هذه الحالة ، لدينا مجموعة من الصور ، والتي تحتوي دائمًا على نسخة محددة من الإطار (في حالتنا ، tf-1-8-cpu و tf-1-8-cu92). سيتم تحديث مجموعات الصور هذه ، لكن إصدار TensorFlow لن يتغير فيها.
نظرًا لأن هذا مجرد إصدار بيتا ، فإننا ندعم الآن TensorFlow 1.8 / 1.9 و PyTorch 0.4 فقط. نحن نخطط لدعم الإصدارات المستقبلية ، ولكن لا يمكننا في المرحلة الحالية الإجابة بوضوح على السؤال عن مدة دعم الإصدارات القديمة.
ماذا لو كنت أرغب في إنشاء مجموعة أو استخدام نفس الصورة؟
في الواقع ، قد يكون هناك العديد من الحالات عندما يكون من الضروري إعادة استخدام نفس الصورة مرارًا وتكرارًا (بدلاً من مجموعة من الصور). بالمعنى الدقيق للكلمة ، فإن استخدام الصور مباشرةً هو دائمًا الخيار المفضل. حسنًا ، على سبيل المثال ، إذا قمت بتشغيل مجموعة تحتوي على عدة مثيلات ، فمن غير المستحسن في هذه الحالة تحديد مجموعات الصور مباشرة في البرامج النصية الخاصة بك ، نظرًا لأنه إذا تم تحديث العائلة في الوقت الذي يتم فيه تشغيل البرنامج النصي ، فمن المحتمل أن يتم إنشاء مثيلات مجموعة مختلفة من صور مختلفة (وقد يكون لها إصدارات مختلفة من المكتبات!). في مثل هذه الحالات ، يفضل الحصول أولاً على اسم محدد لصورة العائلة ، ثم استخدام اسم معين فقط.
إذا كنت مهتمًا بهذا الموضوع ، يمكنك إلقاء نظرة على مقالتي "كيفية استخدام مجموعات الصور بشكل صحيح".
يمكنك عرض اسم آخر صورة في العائلة باستخدام أمر بسيط:
gcloud compute images describe-from-family tf-latest-cu92 \ --project deeplearning-platform-release
لنفترض أن اسم صورة معينة هو tf-latest-cu92-1529452792 ، يمكنك استخدامها بالفعل في أي مكان:
حان الوقت لإنشاء مثيلنا الأول!
لإنشاء مثيل من مجموعة صور ، ما عليك سوى تشغيل أمر واحد بسيط:
export IMAGE_FAMILY="tf-latest-cu92"
إذا كنت تستخدم اسم الصورة وليس مجموعة الصور ، فأنت بحاجة إلى استبدال "- image-family = $ IMAGE_FAMILY" بـ "- image = $ IMAGE-NAME".
إذا كنت تستخدم مثيلًا مع GPU ، فأنت بحاجة إلى الانتباه إلى الظروف التالية:
تحتاج إلى تحديد المنطقة الصحيحة . إذا قمت بإنشاء مثيل باستخدام GPU معين ، فأنت بحاجة إلى التأكد من أن هذا النوع من GPU متاح في المنطقة التي تقوم فيها بإنشاء المثيل. هنا يمكنك العثور على مراسلات المناطق لأنواع GPU. كما ترون ، فإن us-west1-b هي المنطقة الوحيدة التي توجد فيها جميع الأنواع الثلاثة الممكنة لوحدات معالجة الرسومات (K80 / P100 / V100).
تأكد من أن لديك حصص كافية لإنشاء مثيل مع وحدة معالجة الرسومات . حتى إذا اخترت المنطقة الصحيحة ، فهذا لا يعني أن لديك حصة لإنشاء مثيل باستخدام وحدة معالجة الرسوميات في هذه المنطقة. افتراضيًا ، يتم تعيين حصة GPU على صفر في جميع المناطق ، لذلك ستفشل جميع محاولات إنشاء مثيل باستخدام GPU. يمكن العثور على شرح جيد لكيفية زيادة الحصة هنا .
تأكد من وجود عدد كافٍ من وحدات معالجة الرسومات في المنطقة لتلبية طلبك . حتى إذا اخترت المنطقة الصحيحة ولديك حصة مخصصة لوحدات معالجة الرسومات في هذه المنطقة ، فهذا لا يعني أن هناك وحدة معالجة رسومات تهمك في هذه المنطقة. لسوء الحظ ، لا أعرف كيف يمكنك التحقق من توفر GPU ، باستثناء محاولة لإنشاء مثيل ومعرفة ما يحدث =)
اختر العدد الصحيح لوحدات معالجة الرسومات (بناءً على نوع وحدة معالجة الرسومات) . الحقيقة هي أن علامة "المسرِّع" في فريقنا مسؤولة عن نوع وعدد وحدات معالجة الرسومات التي ستكون متاحة للمثال: على سبيل المثال "- مسرّع = 'type = nvidia-tesla-v100 ، count = 8'" ستنشئ مثيلًا مع ثمانية وحدات معالجة رسومية متوفرة من Nvidia Tesla V100 (Volta). يحتوي كل نوع من GPU على قائمة صالحة لقيم العد. فيما يلي قائمة بكل نوع من GPU:
- nvidia-tesla-k80 ، يمكن أن يكون لها إحصائيات: 1 ، 2 ، 4 ، 8
- nvidia-tesla-p100 ، يمكن أن يكون لها إحصائيات: 1 ، 2 ، 4
- nvidia-tesla-v100 ، يمكن أن يكون لها إحصائيات: 1 ، 8
امنح Google Cloud الإذن لتثبيت برنامج تشغيل Nvidia نيابةً عنك في وقت تشغيل المثيل . السائق من نفيديا أمر حتمي. لأسباب خارج نطاق هذه المقالة ، لا تحتوي الصور على برنامج تشغيل Nvidia مثبت مسبقًا. ومع ذلك ، يمكنك منح Google Cloud الحق في تثبيته نيابة عنك في المرة الأولى التي تقوم فيها بتشغيل المثيل. يتم ذلك عن طريق إضافة علامة “- metadata = 'install-nvidia-driver = True'”. إذا لم تحدد هذا العلم ، فعند الاتصال لأول مرة عبر SSH ، ستتم مطالبتك بتثبيت برنامج التشغيل.
لسوء الحظ ، تستغرق عملية تثبيت برنامج التشغيل بعض الوقت في التمهيد الأول ، نظرًا لأنها تحتاج إلى تنزيل برنامج التشغيل هذا وتثبيته (وهذا يتطلب أيضًا إعادة تشغيل المثيل). في المجموع ، يجب ألا يستغرق ذلك أكثر من 5 دقائق. سنتحدث بعد ذلك بقليل عن كيفية تقليل وقت التمهيد الأول.
الاتصال بمثيل عبر SSH
هذا أبسط من اللفت ويمكن تنفيذه بأمر واحد:
gcloud compute ssh $INSTANCE_NAME
سيقوم gcloud بإنشاء زوج مفاتيح وتحميلها تلقائيًا إلى المثيل الذي تم إنشاؤه حديثًا ، بالإضافة إلى إنشاء المستخدم الخاص بك عليه. إذا كنت ترغب في جعل هذه العملية أكثر بساطة ، يمكنك استخدام وظيفة تبسط ذلك أيضًا:
function gssh() { gcloud compute ssh $@ } gssh $INSTANCE_NAME
بالمناسبة ، يمكنك العثور على جميع وظائف باش gcloud هنا . حسنًا ، قبل أن نصل إلى السؤال عن مدى سرعة هذه الصور ، أو ما الذي يمكن فعله بها ، دعني أوضح المشكلة مع سرعة بدء التشغيل.
كيف يمكنني تقليل وقت البداية الأولى؟
من الناحية الفنية ، فإن وقت الإطلاق الأول ليس شيئًا. ولكن يمكنك:
- إنشاء أرخص مثيل n1-standard-1 مع K80 واحد ؛
- انتظر حتى اكتمال التنزيل الأول ؛
- التحقق من تثبيت برنامج تشغيل Nvidia (يمكن القيام بذلك عن طريق تشغيل "nvidia-smi") ؛
- أوقف المثيل
- إنشاء صورتك الخاصة من نسخة متوقفة
- الربح - جميع النسخ التي تم إنشاؤها من صورتك المشتقة سيكون لها وقت تشغيل أسطوري مدته 15 ثانية.
لذا ، من هذه القائمة ، نعرف بالفعل كيفية إنشاء مثيل جديد والاتصال به ، ونعرف أيضًا كيفية التحقق من برامج التشغيل للتأكد من قابليتها للتشغيل. يبقى فقط للحديث عن كيفية إيقاف المثيل وإنشاء صورة منه.
لإيقاف المثيل ، قم بتشغيل الأمر التالي:
function ginstance_stop() { gcloud compute instances stop - quiet $@ } ginstance_stop $INSTANCE_NAME
وإليك أمر إنشاء الصورة:
export IMAGE_NAME="my-awesome-image" export IMAGE_FAMILY="family1" gcloud compute images create $IMAGE_NAME \ --source-disk $INSTANCE_NAME \ --source-disk-zone $ZONE \ --family $IMAGE_FAMILY
تهانينا ، لديك الآن صورتك الخاصة مع برامج تشغيل Nvidia المثبتة.
ماذا عن مختبر جوبيتر؟
بمجرد تشغيل المثيل الخاص بك ، فإن الخطوة المنطقية التالية ستكون بدء Jupyter Lab لبدء العمل مباشرة :) مع الصور الجديدة ، يكون الأمر بسيطًا جدًا. يعمل Jupyter Lab بالفعل منذ إطلاق المثيل. كل ما عليك فعله هو الاتصال بالمثيل وإعادة توجيه المنفذ الذي يستمع إليه Jupyter Lab. وهذا هو المنفذ 8080. ويتم ذلك بالأمر التالي:
gssh $INSTANCE_NAME -- -L 8080:localhost:8080
كل شيء جاهز ، الآن يمكنك ببساطة فتح المتصفح المفضل لديك والانتقال إلى http: // localhost: 8080
ما مدى سرعة TensorFlow من الصور؟
سؤال مهم للغاية ، لأن سرعة تدريب النموذج هي المال الحقيقي. ومع ذلك ، فإن الإجابة الكاملة على هذا السؤال ستكون الأطول المكتوبة بالفعل في هذه المقالة. لذلك عليك الانتظار حتى المقالة التالية :)
في غضون ذلك ، سأدللك ببعض الأرقام التي تم الحصول عليها في تجربتي الشخصية الصغيرة. لذا ، كانت سرعة التدريب على ImageNet 6100 صورة في الثانية (شبكة ResNet-50). لم تسمح لي ميزانيتي الشخصية بإنهاء تدريب النموذج بالكامل ، ولكن بهذه السرعة ، أفترض أنه من الممكن تحقيق دقة 75 ٪ في 5 ساعات مع القليل.
من أين تحصل على المساعدة؟
إذا كنت بحاجة إلى أي معلومات حول الصور الجديدة ، فيمكنك:
- اطرح سؤالاً حول stackoverflow ، باستخدام العلامة google-dl-platform ؛
- الكتابة إلى مجموعة Google العامة ؛
- يمكنك الكتابة لي على البريد أو تويتر .
ملاحظاتك مهمة جدًا ، إذا كان لديك ما تقوله عن الصور ، فلا تتردد في الاتصال بي بأي طريقة تناسبك أو اترك تعليقًا تحت هذه المقالة.