
في السنوات القليلة الماضية ، لم يعد موضوع الذكاء الاصطناعي والتعلم الآلي شيئًا للناس من عالم الخيال ودخل بقوة في الحياة اليومية. تعرض الشبكات الاجتماعية حضور الأحداث التي تهمنا ، والسيارات على الطرق التي تعلمت التنقل بدون سائق ، ومساعد صوت على الهاتف يخبر متى يكون من الأفضل مغادرة المنزل لتجنب الاختناقات المرورية وما إذا كنت ستأخذ معك مظلة.
في هذه المقالة ، سننظر في أدوات التعلم الآلي التي يقدمها مطورو Apple ، ونحلل ما أظهرته الشركة جديدًا في هذا المجال في WWDC18 ، ونحاول فهم كيفية وضع كل هذا موضع التنفيذ.
التعلم الآلي
لذا ، فإن التعلم الآلي هو عملية يقوم خلالها النظام ، باستخدام خوارزميات معينة لتحليل البيانات ومعالجة عدد كبير من الأمثلة ، بتحديد الأنماط واستخدامها للتنبؤ بخصائص البيانات الجديدة.
ولد التعلم الآلي من النظرية القائلة بأن أجهزة الكمبيوتر يمكن أن تتعلم من تلقاء نفسها ، ولم تتم برمجتها بعد لأداء إجراءات معينة. بعبارة أخرى ، على عكس البرامج التقليدية التي تحتوي على تعليمات محددة مسبقًا لحل مشكلات معينة ، يسمح التعلم الآلي للنظام بتعلم كيفية التعرف على الأنماط بشكل مستقل وإجراء التنبؤات.
BNNS و CNN
تستخدم Apple تقنية تعلُم الآلة على أجهزتها منذ فترة طويلة: يحدد البريد رسائل البريد الإلكتروني العشوائية ، ويساعدك Siri في العثور بسرعة على إجابات لأسئلتك ، ويتعرف تطبيق "الصور" على الوجوه في الصور.
في WWDC16 ، قدمت الشركة اثنين من واجهات برمجة التطبيقات المستندة إلى الشبكة العصبية - Subroutines الشبكة العصبية الأساسية (BNNS) والشبكات العصبية التلافيفية (CNN). يعد BNNS جزءًا من نظام Accelerate ، وهو الأساس لإجراء العمليات الحسابية السريعة على وحدة المعالجة المركزية ، و CNN هي مكتبة تظليل الأداء المعدني التي تستخدم GPU. يمكنك معرفة المزيد عن هذه التقنيات ، على سبيل المثال ، هنا .
Core ML و Turi Create
في العام الماضي ، أعلنت Apple عن إطار عمل يسهل بشكل كبير العمل مع تقنيات التعلم الآلي - Core ML. ويستند إلى فكرة أخذ نموذج بيانات مدرب مسبقًا ودمجه في تطبيقك في بضعة أسطر من التعليمات البرمجية.
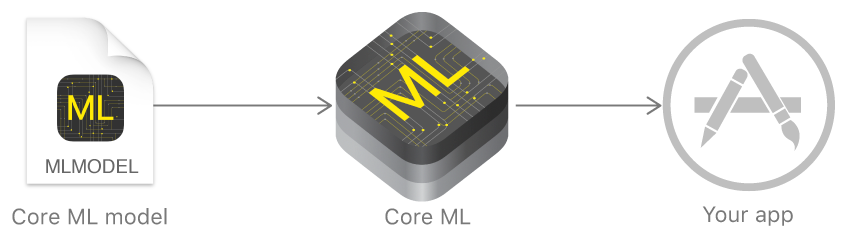
باستخدام Core ML ، يمكنك تنفيذ العديد من الوظائف:
- تعريف الأشياء في الصورة والفيديو ؛
- إدخال النص التنبئي ؛
- تتبع الوجه والتعرف عليه ؛
- تحليل الحركة
- تعريف الباركود ؛
- فهم النص والتعرف عليه ؛
- التعرف على الصور في الوقت الحقيقي ؛
- نمط الصورة ؛
- وغير ذلك الكثير.
تستخدم Core ML ، بدورها ، المعادن ذات المستوى المنخفض والتسريع و BNNS ، وبالتالي فإن نتائج الحسابات سريعة جدًا.
تدعم النواة الشبكات العصبية ، والنماذج الخطية المعممة ، والهندسة المميزة ، وخوارزميات صنع القرار القائمة على الأشجار (مجموعات الأشجار) ، وطريقة الآلات الناقلة ، ونماذج خطوط الأنابيب.
لكن شركة Apple لم تعرض في البداية تقنياتها الخاصة لإنشاء النماذج وتدريبها ، ولكنها صنعت فقط محولًا لأطر العمل الشائعة الأخرى: Caffe و Keras و scikit-learn و XGBoost و LIBSVM.
لم يكن استخدام أدوات الطرف الثالث في كثير من الأحيان أسهل مهمة ، وكانت النماذج المدربة كبيرة جدًا ، واستغرق التدريب نفسه الكثير من الوقت.
في نهاية العام ، قدمت الشركة Turi Create - إطار عمل نموذجي للتعلم كانت فكرته الرئيسية سهولة الاستخدام والدعم لعدد كبير من السيناريوهات - تصنيف الصور ، وتعريف الأشياء ، وأنظمة التوصيات ، وغيرها الكثير. لكن Turi Creat ، على الرغم من سهولة استخدامها النسبية ، دعمت Python فقط.
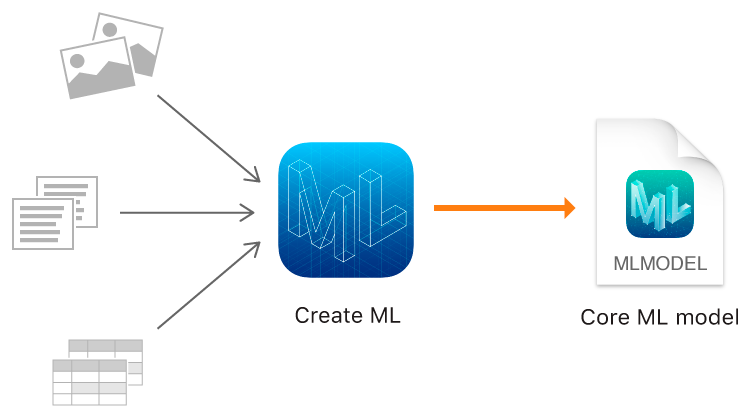
إنشاء ML
وفي هذا العام ، أظهرت شركة Apple ، بالإضافة إلى Core ML 2 ، أداؤها الخاص بها لنماذج التدريب - إطار إنشاء ML باستخدام تقنيات Apple الأصلية - Xcode و Swift.
إنه يعمل بسرعة ، وإنشاء النماذج باستخدام Create ML أمر سهل حقًا.
في WWDC ، تم الإعلان عن الأداء المذهل لـ Create ML و Core ML 2 باستخدام تطبيق Memrise كمثال. إذا استغرق تدريب نموذج واحد في وقت سابق 24 ساعة باستخدام 20 ألف صورة ، فإن Create ML يقلل هذا الوقت إلى 48 دقيقة على MacBook Pro وما يصل إلى 18 دقيقة على iMac Pro. انخفض حجم النموذج المدرب من 90 ميجا بايت إلى 3 ميجا بايت.
يسمح لك Create ML باستخدام الصور والنصوص والكائنات المنظمة كجداول ، على سبيل المثال ، كبيانات مصدر.
تصنيف الصورة
أولاً ، دعنا نرى كيف يعمل تصنيف الصور. لتدريب النموذج ، نحتاج إلى مجموعة بيانات أولية: نأخذ ثلاث مجموعات من صور الحيوانات: الكلاب والقطط والطيور ونوزعها في مجلدات بالأسماء المقابلة ، والتي ستصبح أسماء فئات النموذج. تحتوي كل مجموعة على 100 صورة بدقة تصل إلى 1920 × 1080 بكسل وحجم يصل إلى 1 ميجابايت. يجب أن تكون الصور مختلفة قدر الإمكان حتى لا يعتمد النموذج المدرب على علامات مثل اللون في الصورة أو المساحة المحيطة.
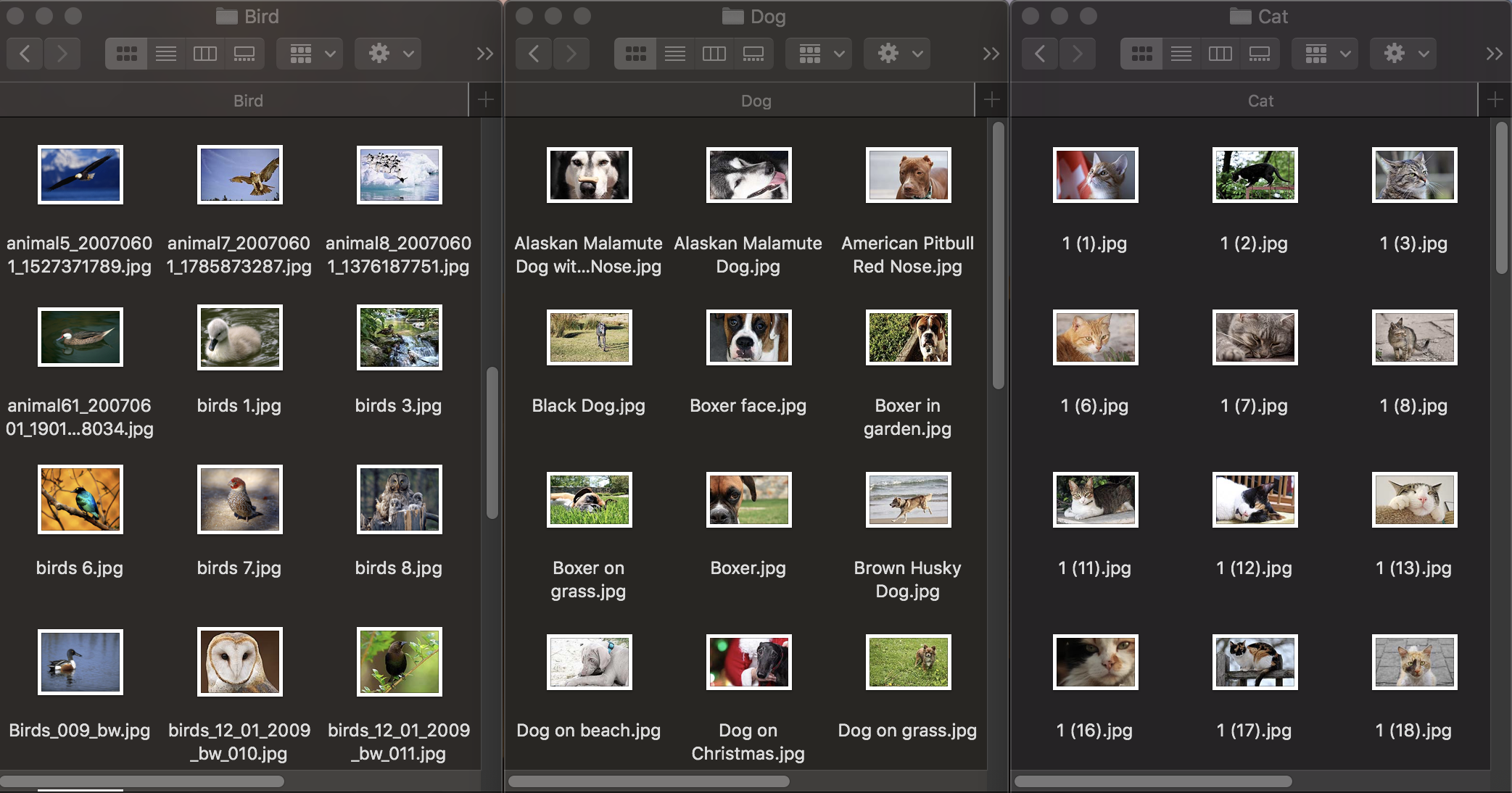
أيضًا ، للتحقق من مدى تعامل النموذج المدرب مع التعرف على الكائنات ، تحتاج إلى مجموعة بيانات اختبار - الصور غير الموجودة في مجموعة البيانات الأصلية.
توفر Apple طريقتين للتفاعل مع Create ML: استخدام واجهة المستخدم على MacOS Playground Xcode وبرمجياً باستخدام CreateMLUI.framework و CreateML.framework. باستخدام الطريقة الأولى ، يكفي كتابة سطرين من التعليمات البرمجية ، ونقل الصور المحددة إلى المنطقة المحددة ، والانتظار بينما يتعلم النموذج.

على جهاز Macbook Pro 2017 بأقصى تكوين ، استغرق التدريب 29 ثانية لـ 10 تكرارات ، وكان حجم النموذج المدرب 33 كيلوبايت. تبدو مثيرة للإعجاب.
دعونا نحاول معرفة كيف تمكنا من تحقيق هذه المؤشرات وما هو "تحت الغطاء".
تعد مهمة تصنيف الصور واحدة من الاستخدامات الأكثر شيوعًا للشبكات العصبية التلافيفية. أولاً ، من الجدير شرح ما هي عليه.
يمكن للشخص ، الذي يرى صورة لحيوان ، أن ينسبها بسرعة إلى فئة معينة على أساس أي ميزات مميزة. تعمل الشبكة العصبية بطريقة مماثلة من خلال البحث عن الخصائص الأساسية. بأخذ المصفوفة الأولية من البكسل كمدخلات ، فإنها تمرر المعلومات بشكل تسلسلي من خلال مجموعات من الطبقات التلافيفية وتبني تجريدات معقدة بشكل متزايد. تتعلم في كل طبقة لاحقة إبراز ميزات معينة - أولاً هذه هي الخطوط ، ثم مجموعات من الخطوط والأشكال الهندسية وأجزاء من الجسم وما إلى ذلك. في الطبقة الأخيرة نحصل على ختام فئة أو مجموعة من الفئات المحتملة.
في حالة إنشاء ML ، لا يتم تدريب الشبكة العصبية من الصفر. يستخدم الإطار شبكة عصبية تم تدريبها مسبقًا على مجموعة بيانات ضخمة ، والتي تتضمن بالفعل عددًا كبيرًا من الطبقات وذات دقة عالية.
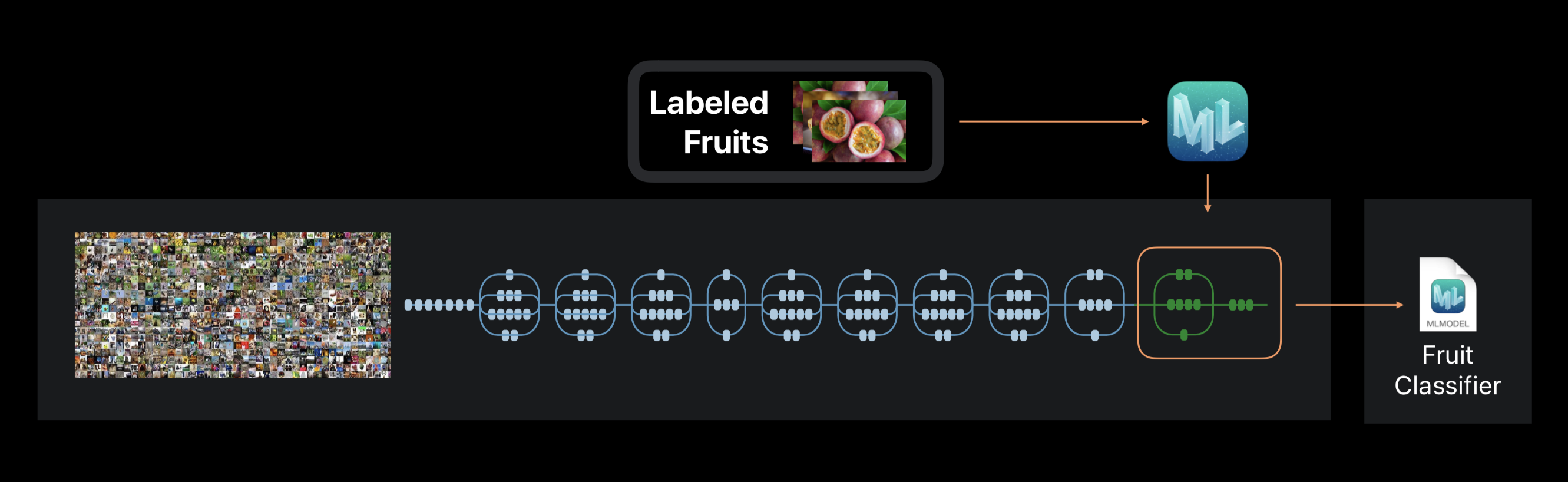
تسمى هذه التكنولوجيا التعلم بالانتقال. باستخدامه ، يمكنك تغيير بنية شبكة تم تدريبها مسبقًا بحيث تكون مناسبة لحل مشكلة جديدة. يتم بعد ذلك تدريب الشبكة التي تم تغييرها على مجموعة بيانات جديدة.
إنشاء ML أثناء مقتطفات التدريب من الصورة حوالي 1000 ميزات مميزة. يمكن أن يكون هذا شكل الأشياء ، ولون القوام ، وموقع العيون ، والأحجام ، وغيرها الكثير.
وتجدر الإشارة إلى أن مجموعة البيانات الأولية التي تدربت عليها الشبكة العصبية المستخدمة ، مثل شبكتنا ، قد تحتوي على صور للقطط والكلاب والطيور ، ولكن هذه الفئات غير مخصصة على وجه التحديد. جميع الفئات تشكل التسلسل الهرمي. لذلك ، من المستحيل ببساطة تطبيق هذه الشبكة في شكلها الخالص - من الضروري إعادة تدريبها على بياناتنا.
في نهاية العملية ، نرى مدى دقة تدريب نموذجنا واختباره بعد عدة تكرارات. لتحسين النتائج ، يمكننا زيادة عدد الصور في مجموعة البيانات الأصلية أو تغيير عدد التكرارات.
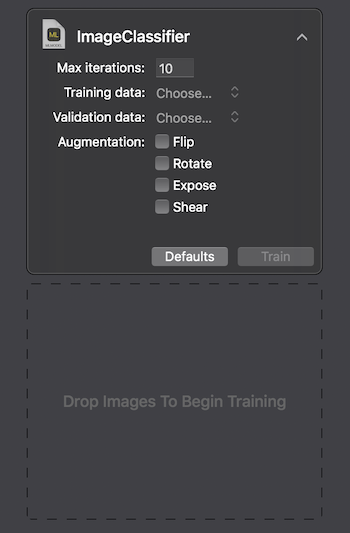
بعد ذلك ، يمكننا اختبار النموذج بأنفسنا في مجموعة بيانات اختبار. يجب أن تكون الصور فيه فريدة ، أي لا تدخل مجموعة المصادر.
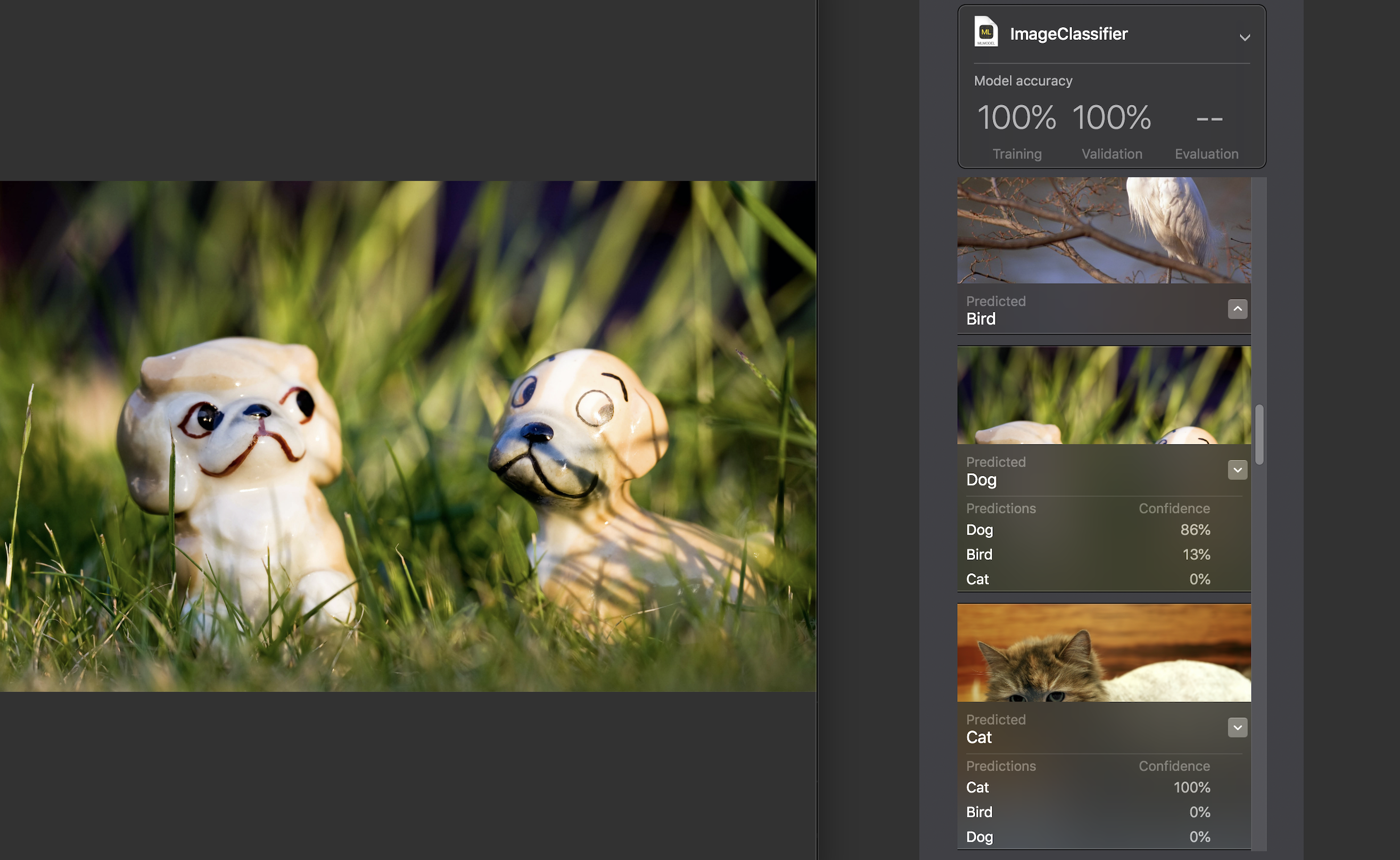
لكل صورة ، يتم عرض مؤشر الثقة - مدى دقة التعرف على الفئة بمساعدة النموذج الخاص بنا.
بالنسبة لجميع الصور تقريبًا ، مع استثناءات نادرة ، كان هذا الرقم 100٪. لقد أضفت على وجه التحديد الصورة التي تراها أعلاه إلى مجموعة بيانات الاختبار ، وكما ترون ، قم بإنشاء ML معترف بها في 86٪ من الكلب و 13٪ من الطيور.
اكتمل تدريب النموذج ، وكل ما تبقى لنا هو حفظ ملف * .model وإضافته إلى مشروعك.
لاختبار النموذج ، كتبت تطبيقًا بسيطًا باستخدام إطار عمل Vision. يتيح لك العمل مع نماذج Core ML وحل المشكلات باستخدامها ، مثل تصنيف الصور أو الكشف عن الكائنات.
سيتعرف تطبيقنا على الصورة من كاميرا الجهاز ويعرض الفئة ونسبة الثقة في التصنيف.
نقوم بتهيئة نموذج Core ML للعمل مع Vision وتكوين الاستعلام:
func setupVision() { guard let visionModel = try? VNCoreMLModel(for: AnimalsClassifier().model) else { fatalError("Can't load VisionML model") } let request = VNCoreMLRequest(model: visionModel) { (request, error) in guard let results = request.results else { return } self.handleRequestResults(results) } requests = [request] }
أضف طريقة ستعالج نتائج VNCoreMLRequest. نعرض فقط أولئك الذين لديهم مؤشر ثقة أكثر من 70٪:
func handleRequestResults(_ results: [Any]) { let categoryText: String? defer { DispatchQueue.main.async { self.categoryLabel.text = categoryText } } guard let foundObject = results .compactMap({ $0 as? VNClassificationObservation }) .first(where: { $0.confidence > 0.7 }) else { categoryText = nil return } let category = categoryTitle(identifier: foundObject.identifier) let confidence = "\(round(foundObject.confidence * 100 * 100) / 100)%" categoryText = "\(category) \(confidence)" }
والأخير - سنضيف طريقة التفويض AVCaptureVideoDataOutputSampleBufferDelegate ، والتي سيتم استدعاؤها مع كل إطار جديد من الكاميرا وتنفيذ الطلب:
func captureOutput( _ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) { guard let pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else { return } var requestOptions: [VNImageOption: Any] = [:] if let cameraIntrinsicData = CMGetAttachment( sampleBuffer, key: kCMSampleBufferAttachmentKey_CameraIntrinsicMatrix, attachmentModeOut: nil) { requestOptions = [.cameraIntrinsics:cameraIntrinsicData] } let imageRequestHandler = VNImageRequestHandler( cvPixelBuffer: pixelBuffer, options: requestOptions) do { try imageRequestHandler.perform(requests) } catch { print(error) } }
دعونا نتحقق من مدى تعامل النموذج مع مهمته:

يتم تحديد الفئة بدقة عالية إلى حد ما ، وهذا أمر مثير للدهشة بشكل خاص عندما تفكر في مدى سرعة التدريب ومدى صغر مجموعة البيانات الأصلية. بشكل دوري ، على خلفية مظلمة ، يكشف النموذج عن الطيور ، ولكن أعتقد أنه يمكن حلها بسهولة عن طريق زيادة عدد الصور في مجموعة البيانات الأصلية أو عن طريق زيادة الحد الأدنى المقبول من الثقة.
إذا أردنا إعادة تدريب النموذج لتصنيف فئة أخرى ، فما عليك سوى إضافة مجموعة جديدة من الصور وتكرار العملية - سيستغرق الأمر بضع دقائق.
كتجربة ، قمت بعمل مجموعة بيانات أخرى ، قمت فيها بتغيير جميع صور القطط في صورة قطة واحدة من زوايا مختلفة ، ولكن على نفس الخلفية وفي نفس البيئة. في هذه الحالة ، يرتكب النموذج دائمًا أخطاء ويتعرف على الفئة في غرفة فارغة ، على ما يبدو يعتمد على اللون كميزة رئيسية.
ميزة أخرى مثيرة للاهتمام تم تقديمها في Vision هذا العام فقط هي القدرة على التعرف على الأشياء في الصورة في الوقت الحقيقي. يتم تمثيله بواسطة فئة VNRecognizedObjectObservation ، والتي تسمح لك بالحصول على فئة الكائن وموقعه - المربع المحيط.

لا يسمح Create ML الآن بإنشاء نماذج لتطبيق هذه الوظيفة. تقترح شركة Apple استخدام Turi Create في هذه الحالة. العملية ليست أكثر تعقيدًا بكثير مما سبق: تحتاج إلى إعداد مجلدات الفئة مع الصور وملف يتم فيه تحديد إحداثيات المستطيل حيث يوجد الكائن لكل صورة.
معالجة اللغة الطبيعية
وظيفة Create ML التالية هي تدريب النماذج على تصنيف النصوص بلغة طبيعية - على سبيل المثال ، لتحديد اللون العاطفي للجمل أو الكشف عن البريد العشوائي.
لإنشاء نموذج ، يجب علينا جمع جدول بمجموعة البيانات الأصلية - الجمل أو النصوص الكاملة المعينة لفئة معينة ، وتدريب النموذج باستخدامه باستخدام كائن MLTextClassifier:
let data = try MLDataTable(contentsOf: URL(fileURLWithPath: "/Users/CreateMLTest/texts.json")) let (trainingData, testingData) = data.randomSplit(by: 0.8, seed: 5) let textClassifier = try MLTextClassifier(trainingData: trainingData, textColumn: "text", labelColumn: "label") try textClassifier.write(to: URL(fileURLWithPath: "/Users/CreateMLTest/TextClassifier.mlmodel"))
في هذه الحالة ، يكون النموذج المدرب من نوع مصنف مصنف:
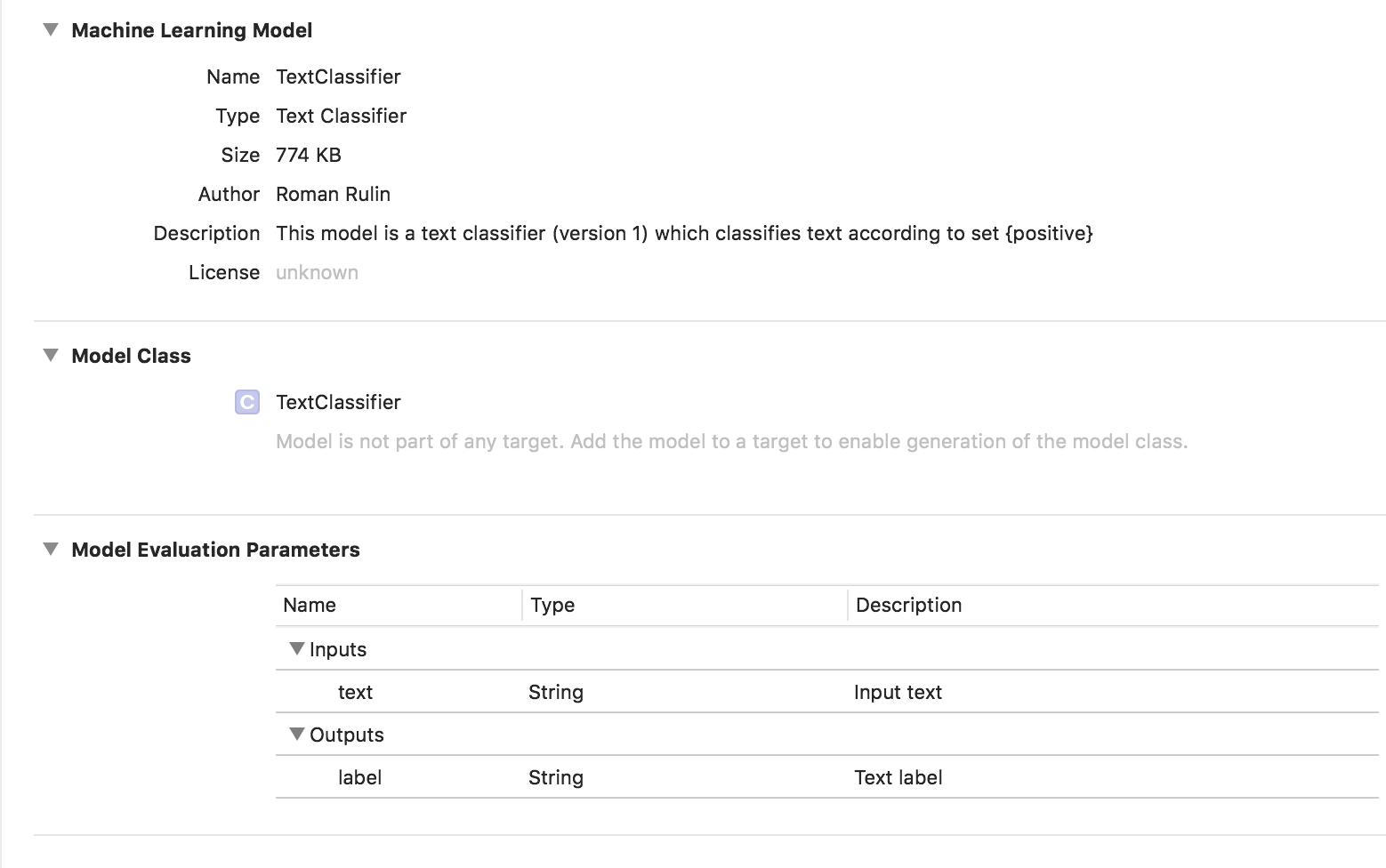
البيانات الجدولية
دعونا نلقي نظرة فاحصة على ميزة أخرى من إنشاء ML - تدريب نموذج باستخدام البيانات المنظمة (الجداول).
سنكتب تطبيق اختبار يتنبأ بسعر الشقة بناءً على موقعها على الخريطة وغيرها من المعلمات المحددة.
لذلك ، لدينا جدول يحتوي على بيانات مجردة عن الشقق في موسكو في شكل ملف csv: منطقة كل شقة ، طابق ، عدد الغرف والإحداثيات (خط العرض وخط الطول) معروفة. بالإضافة إلى ذلك ، تكلفة كل شقة معروفة. وكلما اقترب المركز أو المنطقة الأكبر ، ارتفع السعر.
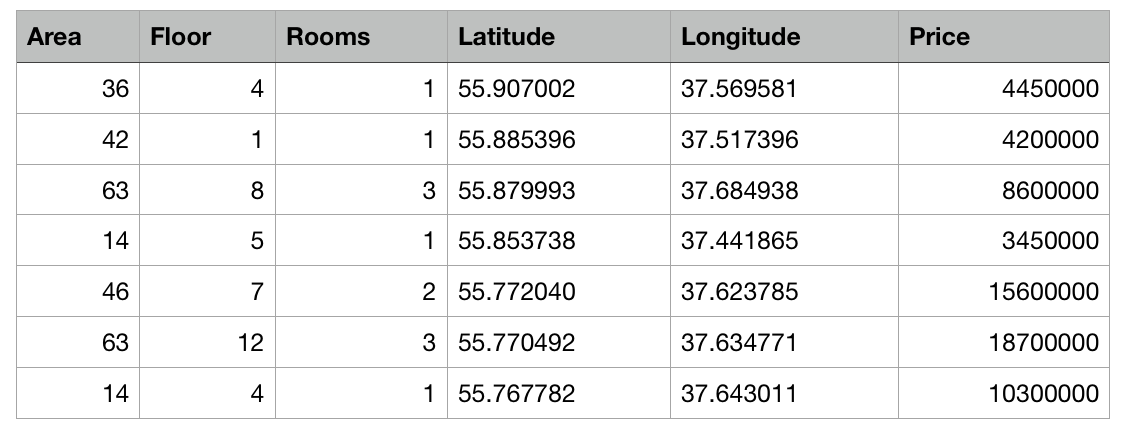
ستكون مهمة Create ML هي بناء نموذج قادر على توقع سعر الشقة بناءً على هذه الخصائص. تسمى هذه المهمة في التعلم الآلي مهمة الانحدار وهي مثال كلاسيكي للتعلم مع المعلم.
يدعم إنشاء ML العديد من النماذج - الانحدار الخطي ، انحدار شجرة القرار ، مصنف الشجرة ، الانحدار اللوجستي ، مصنف الغابة العشوائية ، انحدار الأشجار المعززة ، إلخ.
سنستخدم كائن MLRegressor ، الذي سيحدد الخيار الأفضل بناءً على بيانات الإدخال.
أولاً ، قم بتهيئة كائن MLDataTable بمحتويات ملف csv الخاص بنا:
let trainingFile = URL(fileURLWithPath: "/Users/CreateMLTest/Apartments.csv") let apartmentsData = try MLDataTable(contentsOf: trainingFile)
نقسم مجموعة البيانات الأولية إلى بيانات لتدريب واختبار النموذج بنسبة 80/20:
let (trainingData, testData) = apartmentsData.randomSplit(by: 0.8, seed: 0)
نقوم بإنشاء نموذج MLRegressor ، للإشارة إلى بيانات التدريب واسم العمود الذي نريد التنبؤ بقيمه. سيتم تحديد نوع الانحدار الخاص بالمهمة (الخطي أو شجرة القرار أو الشجرة المعززة أو الغابة العشوائية) تلقائيًا بناءً على دراسة بيانات الإدخال. يمكننا أيضًا تحديد أعمدة المعالم - أعمدة المعلمات الخاصة للتحليل ، ولكن في هذا المثال ، هذا ليس ضروريًا ، سنستخدم جميع المعلمات. في النهاية ، احفظ النموذج المدرب وأضف إلى المشروع:
let model = try MLRegressor(trainingData: apartmentsData, targetColumn: "Price") let modelPath = URL(fileURLWithPath: "/Users/CreateMLTest/ApartmentsPricer.mlmodel") try model.write(to: modelPath, metadata: nil)
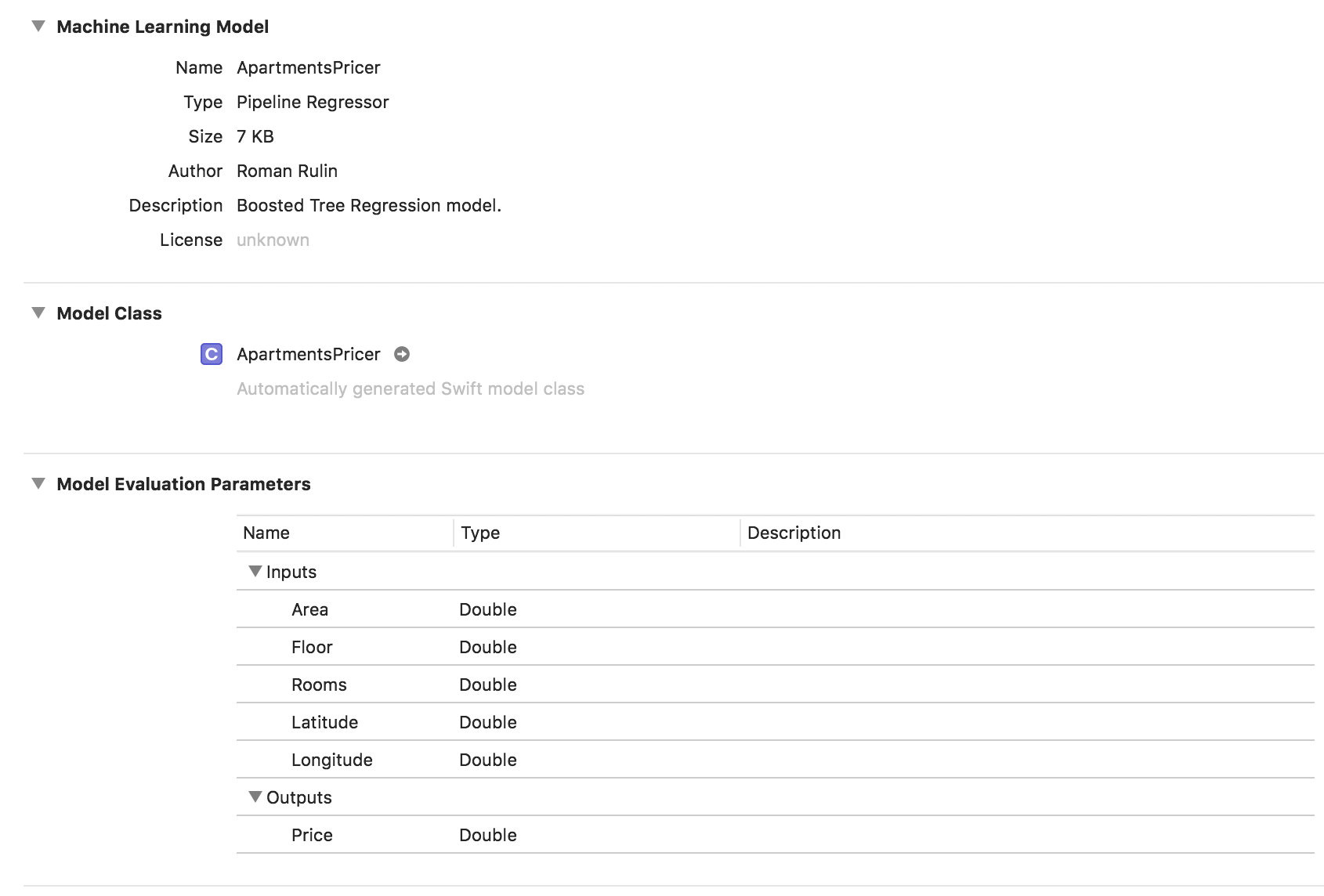
في هذا المثال ، نرى أن نوع النموذج هو بالفعل Pipeline Regressor ، وأن حقل الوصف يحتوي على نوع الانحدار المحدد تلقائيًا - نموذج انحدار الشجرة المعزز. تتوافق معلمات المدخلات والمخرجات مع أعمدة الجدول ، ولكن نوع بياناتها مزدوج.
تحقق الآن من النتيجة.
تهيئة كائن النموذج:
let model = ApartmentsPricer()
نسمي طريقة التنبؤ ، بتمرير المعلمات المحددة لها:
let area = Double(areaSlider.value) let floor = Double(floorSlider.value) let rooms = Double(roomsSlider.value) let latitude = annotation.coordinate.latitude let longitude = annotation.coordinate.longitude let prediction = try? model.prediction( area: area, floor: floor, rooms: rooms, latitude: latitude, longitude: longitude)
نعرض القيمة المتوقعة للتكلفة:
let price = prediction?.price priceLabel.text = formattedPrice(price)
عند تغيير نقطة على الخريطة أو قيم المعلمات ، نحصل على سعر الشقة قريبًا جدًا من بيانات الاختبار لدينا:
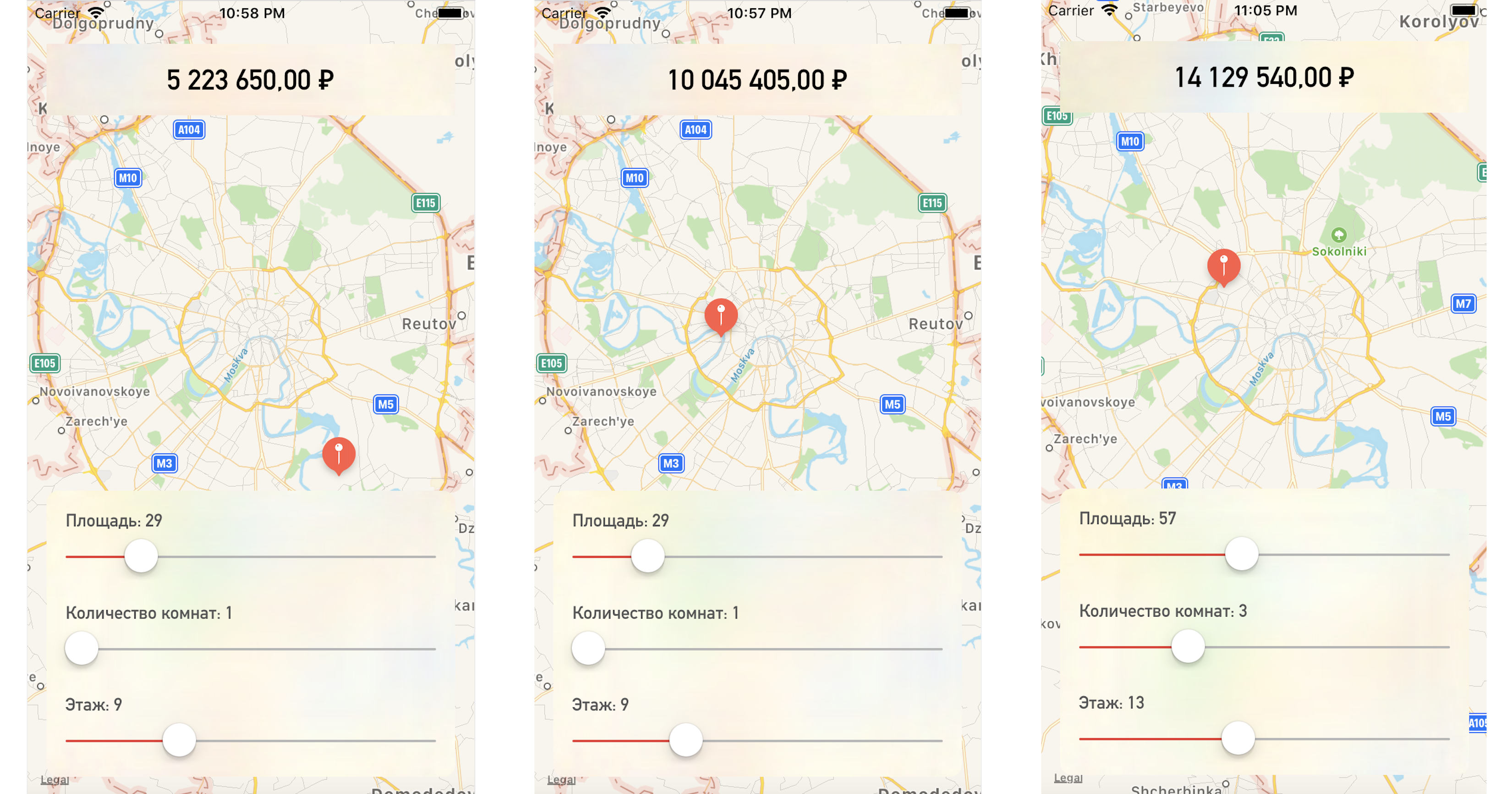
الخلاصة
يُعد إطار عمل Create ML الآن أحد أسهل الطرق للعمل مع تقنيات التعلم الآلي. لا يسمح بعد بإنشاء نماذج لحل بعض المشاكل: التعرف على الأشياء في الصورة ، تصميم الصورة ، تحديد الصور المماثلة ، التعرف على الإجراءات المادية القائمة على البيانات من مقياس التسارع أو الجيروسكوب ، والتي تعالجها شركة Turi ، على سبيل المثال.
ولكن تجدر الإشارة إلى أن Apple قد أحرزت تقدمًا خطيرًا جدًا في هذا المجال خلال العام الماضي ، وبالتأكيد ، سنرى قريبًا تطور التقنيات الموصوفة.