في مقال سابق ، نظرنا في الأنماط والطبولوجيا المستخدمة في RabbitMQ. في هذا الجزء ، سننتقل إلى كافكا ونقارنها بـ RabbitMQ للحصول على بعض الأفكار حول خلافاتهم. يجب أن يوضع في الاعتبار أنه سيتم مقارنة بنيات التطبيقات الموجهة نحو الحدث بدلاً من خطوط أنابيب معالجة البيانات ، على الرغم من أن الخط بين هذين المفهومين سيكون غير واضح إلى حد ما في هذه الحالة. بشكل عام ، هذا أكثر من طيف من فصل واضح. ستركز مقارنتنا ببساطة على الجزء من هذا الطيف المتعلق بالتطبيقات التي تعتمد على الأحداث.

الاختلاف الأول الذي يتبادر إلى الذهن هو أن آليات إعادة محاولة الرسائل والغفوة التي يستخدمها RabbitMQ للعمل مع رسائل الحروف الميتة في كافكا لا معنى لها. في RabbitMQ ، تكون الرسائل مؤقتة ويتم نقلها وتختفي. لذلك ، تعد إعادة إضافتها حالة استخدام حقيقية تمامًا. وفي كافكا ، تحتل المجلة مركز الصدارة. إن حل مشاكل التسليم عن طريق إعادة إرسال رسالة إلى قائمة الانتظار لا معنى له ويضر المجلة فقط. واحدة من المزايا هي التوزيع الواضح المضمون للرسائل عبر أقسام المجلة ، والرسائل المتكررة تخلط بين مخطط جيد التنظيم. في RabbitMQ ، يمكنك بالفعل إرسال الرسائل إلى قائمة الانتظار التي يعمل بها مستلم واحد ، وعلى منصة كافكا توجد مجلة واحدة لجميع المستلمين. إن التأخير في التسليم ومشاكل تسليم الرسائل لا تسبب الكثير من الضرر لعمل المجلة ، لكن كافكا لا تحتوي على آليات تأخير مدمجة.
ستتم مناقشة كيفية إعادة توصيل الرسائل على منصة كافكا في القسم الخاص بمخططات الرسائل.
والفرق الكبير الثاني الذي يؤثر على مخططات المراسلة المحتملة هو أن RabbitMQ يخزن الرسائل أقل بكثير من كافكا. عندما يتم تسليم رسالة بالفعل إلى المستلم في RabbitMQ ، يتم حذفها دون ترك أي أثر لوجودها. في كافكا ، يتم الاحتفاظ بكل رسالة في سجل حتى يتم مسحها. يعتمد تكرار التنظيف على مقدار البيانات المتاحة ، ومقدار مساحة القرص التي تخطط لتخصيصها لها ، ومخططات الرسائل التي تريد التأكد منها. يمكنك استخدام النافذة الزمنية التي نخزن فيها الرسائل لفترة زمنية معينة: الأيام / الأسابيع / الأشهر القليلة الماضية.
بهذه الطريقة ، يسمح Kafka للمستلم بإعادة عرض أو استعادة الرسائل السابقة. يبدو وكأنه تقنية لإرسال الرسائل ، على الرغم من أنه لا يعمل تمامًا كما هو الحال في RabbitMQ.
إذا قام RabbitMQ بنقل الرسائل ويوفر عناصر قوية لإنشاء مخططات توجيه معقدة ، فإن Kafka يحفظ الحالة الحالية والسابقة للنظام. يمكن استخدام هذه المنصة كمصدر للبيانات التاريخية الموثوقة حيث لا يمكن لـ RabbitMQ.
مثال على نظام الرسائل على منصة كافكا
أبسط مثال على استخدام كل من RabbitMQ وكافكا هو نشر المعلومات وفقًا لمخطط "الناشر-المشترك". يضيف ناشر أو أكثر رسائل إلى السجل المقسم ، ويتم تلقي هذه الرسائل من قبل المشترك لمجموعة واحدة أو أكثر من المشتركين.

الشكل 1. يرسل العديد من الناشرين رسائل إلى السجل المقسم ، وتتلقى عدة مجموعات من المستلمين رسائل.
إذا لم تدخل في تفاصيل حول كيفية قيام الناشر بإرسال الرسائل إلى الأقسام الضرورية من المجلة ، وكيفية تنسيق مجموعات المستلمين فيما بينها ، فإن هذا المخطط لا يختلف عن طبولوجيا المعجبين (التبادل المتشعب) المستخدم في RabbitMQ.
في مقال سابق ، تمت مناقشة جميع مخططات ومخططات المراسلة RabbitMQ. ربما فكرت في مرحلة ما "لست بحاجة لكل هذه الصعوبات ، أريد فقط إرسال واستقبال الرسائل في قائمة الانتظار" ، وحقيقة أنه يمكنك إرجاع المجلة إلى المواقف السابقة تحدثت عن المزايا الواضحة لكافكا.
بالنسبة للأشخاص الذين اعتادوا على الميزات التقليدية لأنظمة الانتظار ، فإن حقيقة إمكانية إعادة عقارب الساعة إلى الخلف وإعادة لف سجل الأحداث إلى الماضي أمر مذهل. هذه الخاصية (متوفرة باستخدام السجل بدلاً من قائمة الانتظار) مفيدة جدًا للتعافي من حالات الفشل. لقد بدأت (مؤلف المقالة الإنجليزية) العمل لعملي الحالي منذ 4 سنوات بصفتي المدير الفني لمجموعة دعم نظام الخادم. كان لدينا أكثر من 50 تطبيقًا تلقت معلومات في الوقت الفعلي حول أحداث الأعمال من خلال MSMQ ، والشيء المعتاد هو أنه عندما حدث خطأ في التطبيق ، اكتشف النظام ذلك في اليوم التالي فقط. لسوء الحظ ، غالبًا ما اختفت الرسائل نتيجة لذلك ، ولكننا عادةً ما تمكنا من الحصول على البيانات الأولية من نظام تابع لجهة خارجية وإعادة توجيه الرسائل فقط إلى "المشترك" الذي واجه المشكلة. هذا يتطلب منا إنشاء بنية أساسية للمراسلة للمستلمين. وإذا كان لدينا منصة Kafka ، فلن يكون من الصعب القيام بمثل هذه المهمة من تغيير الرابط إلى موقع آخر رسالة تم تلقيها للتطبيق الذي حدث فيه الخطأ.
تكامل البيانات في التطبيقات والأنظمة الموجهة نحو الحدث
هذا المخطط هو من نواح عديدة وسيلة لتوليد الأحداث ، على الرغم من عدم ارتباطها بتطبيق واحد. هناك مستويان لتوليد الأحداث: البرمجيات والنظام. المخطط الحالي مرتبط بالأخير.
إنشاء حدث على مستوى البرنامج
يدير التطبيق حالته الخاصة من خلال تسلسل ثابت لأحداث التغيير التي يتم تخزينها في مخزن الأحداث. من أجل الحصول على الحالة الحالية للتطبيق ، يجب أن تلعب أو تجمع أحداثه بالتسلسل الصحيح. عادة في مثل هذا النموذج ، يمكن استخدام نموذج CQRS Kafka مثل هذا النظام.
التفاعل بين التطبيقات على مستوى النظام.
يمكن للتطبيقات أو الخدمات إدارة حالتها بأي طريقة يريد المطور تطويرها ، على سبيل المثال ، في قاعدة بيانات علائقية منتظمة.
ولكن غالبًا ما تحتاج التطبيقات إلى بيانات حول بعضها البعض ، وهذا يؤدي إلى بنى دون المستوى الأمثل ، على سبيل المثال ، قواعد البيانات الشائعة ، أو عدم وضوح حدود الكيان ، أو واجهات برمجة التطبيقات REST غير الملائمة.
لقد استمعت (مؤلف المقالة الإنجليزية) إلى البودكاست " Software Engineering Daily " ، الذي يصف سيناريو موجهًا إلى الأحداث لملفات تعريف الخدمة على الشبكات الاجتماعية. هناك عدد من الخدمات ذات الصلة في النظام ، مثل البحث ، ونظام الرسوم البيانية الاجتماعية ، ومحرك التوصية ، وما إلى ذلك ، وكلهم بحاجة إلى معرفة تغيير في حالة ملف تعريف المستخدم. عندما عملت (مؤلف المقال الإنجليزي) كمهندس معماري لنظام يتعلق بالنقل الجوي ، كان لدينا نظامان برمجيات كبيران مع عدد لا يحصى من الخدمات الصغيرة ذات الصلة. تطلبت خدمات الدعم بيانات الرحلة والطلب. في كل مرة يتم فيها إنشاء طلب أو تغييره ، عندما يتم تأجيل رحلة طيران أو إلغاؤها ، يجب تنشيط هذه الخدمات.
تطلبت تقنية لتوليد الأحداث. ولكن أولاً ، دعنا نلقي نظرة على بعض المشاكل الشائعة التي تنشأ في أنظمة البرمجيات الكبيرة ، ونرى كيف يمكن لتوليد الأحداث حلها.
عادة ما يتطور نظام الشركات المتكامل الكبير بشكل عضوي ؛ يتم الترحيل إلى التقنيات الجديدة والمعماريات الجديدة ، والتي قد لا تؤثر على 100٪ من النظام. يتم توزيع البيانات على أجزاء مختلفة من المؤسسة ، وتكشف التطبيقات عن قواعد البيانات للاستخدام العام بحيث يحدث التكامل في أسرع وقت ممكن ، ولا يمكن لأحد أن يتنبأ على وجه اليقين بكيفية تفاعل جميع عناصر النظام.
توزيع البيانات العشوائي
يتم توزيع البيانات في أماكن مختلفة وإدارتها في أماكن مختلفة ، لذا يصعب فهمها:
- كيف تتحرك البيانات في العمليات التجارية ؛
- كيف يمكن للتغييرات في جزء واحد من النظام أن تؤثر على أجزاء أخرى ؛
- ماذا تفعل مع تعارضات البيانات التي تنشأ بسبب حقيقة أن هناك العديد من نسخ البيانات التي تنتشر ببطء.
إذا لم تكن هناك حدود واضحة لكيانات المجال ، فستكون التغييرات مكلفة ومحفوفة بالمخاطر ، لأنها تؤثر على العديد من الأنظمة في وقت واحد.
قاعدة بيانات موزعة مركزية
يمكن أن تتسبب قاعدة البيانات المفتوحة علنًا في العديد من المشكلات:
- لم يتم تحسينها بشكل كافٍ لكل تطبيق على حدة. على الأرجح ، تحتوي قاعدة البيانات هذه على مجموعة بيانات كاملة بشكل مفرط للتطبيق ، علاوة على ذلك ، يتم تطبيعها بطريقة تجعل التطبيقات تقوم بتشغيل استعلامات معقدة للغاية لتلقيها.
- باستخدام قاعدة بيانات مشتركة ، يمكن أن تؤثر التطبيقات على عمل بعضها البعض.
- تتطلب التغييرات في الهيكل المنطقي لقاعدة البيانات تنسيقًا واسع النطاق والعمل على ترحيل البيانات ، وسيتم إيقاف تطوير الخدمات الفردية طوال هذه العملية بأكملها.
- لا أحد يريد تغيير هيكل التخزين. التغييرات التي ينتظرها الجميع مؤلمة للغاية.
استخدام REST API غير مريح
يضيف الحصول على البيانات من أنظمة أخرى من خلال REST API من ناحية الراحة والعزلة ، ولكن قد لا يكون دائمًا ناجحًا. يمكن لكل واجهة مثل هذه أن يكون لها أسلوبها الخاص والأعراف الخاصة بها. يمكن أن يتطلب الحصول على البيانات اللازمة الكثير من طلبات HTTP وأن يكون معقدًا للغاية.
نحن نتحرك أكثر فأكثر نحو مركزية API ، وتوفر هذه البنى العديد من المزايا ، خاصة عندما تكون الخدمات نفسها خارجة عن سيطرتنا. هناك العديد من الطرق المناسبة لإنشاء واجهة برمجة تطبيقات في الوقت الحالي ، حيث لا يتعين علينا كتابة أكبر قدر ممكن من التعليمات البرمجية. ومع ذلك ، هذه ليست الأداة الوحيدة المتاحة ، وهناك بدائل للبنية الداخلية للنظام.
كافكا كمستودع للحدث
نعطي مثالا. هناك نظام يدير التحفظات في قاعدة بيانات علائقية. يستخدم النظام جميع الضمانات للذرة والاتساق والعزلة والمتانة التي توفرها قاعدة البيانات من أجل إدارة خصائصها بشكل فعال والجميع سعداء. تقسيم المسؤولية إلى فرق وطلبات ، وتوليد الأحداث ، والخدمات الصغيرة غائبة ، بشكل عام متراصة مبنية تقليديا. ولكن هناك عدد لا يحصى من خدمات الدعم (ربما الخدمات الصغيرة) المتعلقة بالحجوزات: الإشعارات الفورية ، وتوزيع البريد الإلكتروني ، ونظام مكافحة الاحتيال ، وبرنامج الولاء ، والفواتير ، ونظام الإلغاء ، إلخ. القائمة تطول وتطول. تتطلب جميع هذه الخدمات تفاصيل الحجز ، وهناك طرق عديدة للحصول عليها. تنتج هذه الخدمات نفسها بيانات قد تكون مفيدة لتطبيقات أخرى.

الشكل 2. أنواع مختلفة من تكامل البيانات.
العمارة البديلة على أساس كافكا. في كل مرة تقوم فيها بحجز جديد أو تغيير حجز سابق ، يرسل النظام بيانات كاملة عن الحالة الحالية لهذا الحجز إلى كافكا. من خلال دمج دفتر اليومية ، يمكنك تقصير الرسائل بحيث تبقى فقط المعلومات حول أحدث حالة الحجز فيها. في هذه الحالة ، سيكون حجم المجلة تحت السيطرة.
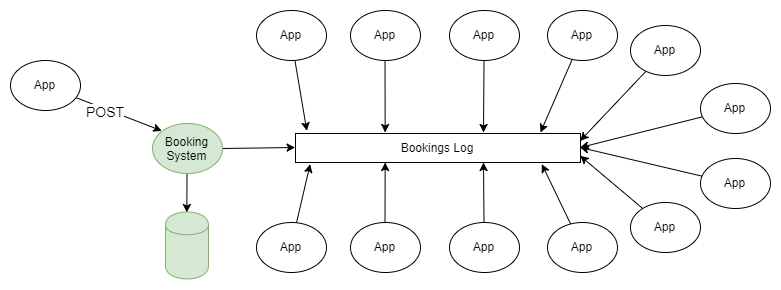
الشكل 3. تكامل البيانات القائمة على كافكا كأساس لتوليد الحدث
بالنسبة لجميع التطبيقات التي يكون هذا ضروريًا لها ، تعد هذه المعلومات مصدر الحقيقة والمصدر الوحيد للبيانات. فجأة ، ننتقل من شبكة متكاملة من التبعيات والتقنيات إلى إرسال واستقبال البيانات من / إلى مواضيع كافكا.
كافكا كمستودع للحدث:
- إذا لم تكن هناك مشكلة في مساحة القرص ، يمكن لـ Kafka تخزين سجل الأحداث بالكامل ، أي أنه يمكن نشر تطبيق جديد وتنزيل جميع المعلومات الضرورية من المجلة. يمكن ضغط سجلات الأحداث التي تعكس خصائص الكائنات بشكل كامل من خلال تجميع السجل ، مما يجعل هذا النهج أكثر تبريرًا للعديد من السيناريوهات.
- ماذا لو احتجت الأحداث للتشغيل بالترتيب الصحيح؟ طالما تم توزيع سجلات الأحداث بشكل صحيح ، يمكنك تعيين ترتيب تشغيلها وتطبيق الفلاتر وأدوات التحويل وما إلى ذلك ، بحيث ينتهي تشغيل البيانات دائمًا على المعلومات الضرورية. اعتمادًا على إمكانية توزيع البيانات ، من الممكن ضمان معالجتها المتوازية للغاية بالترتيب الصحيح.
- قد تكون هناك حاجة لتغيير نموذج البيانات. عند إنشاء وظيفة تصفية / تحويل جديدة ، قد يكون من الضروري إعادة تشغيل سجلات جميع الأحداث أو الأحداث خلال الأسبوع الماضي.
يمكن أن تأتي الرسائل إلى Kafka ليس فقط من تطبيقات مؤسستك التي ترسل رسائل حول جميع التغييرات في خصائصها (أو نتائج هذه التغييرات) ولكن أيضًا من خدمات الطرف الثالث المتكاملة مع نظامك. يحدث هذا بالطرق التالية:
- تصدير ونقل واستيراد البيانات بشكل دوري من خدمات الطرف الثالث وتحميلها إلى كافكا.
- تنزيل البيانات من خدمات طرف ثالث في كافكا.
- يتم تحميل البيانات من CSV والتنسيقات الأخرى التي يتم تحميلها من خدمات الجهات الخارجية إلى Kafka.
فلنعد إلى الأسئلة التي نظرنا فيها سابقًا. تبسط الهندسة المعمارية القائمة على كافكا توزيع البيانات. نحن نعلم أين مصدر الحقيقة ، ونعرف أين توجد مصادر بياناتها ، وجميع التطبيقات المستهدفة تعمل مع نسخ مشتقة من هذه البيانات. تنتقل البيانات من المرسل إلى المستلمين. تنتمي بيانات المصدر إلى المرسل فقط ، لكن الآخرين أحرار في العمل مع توقعاتهم. يمكنهم تصفية وتحويلها واستكمالها ببيانات من مصادر أخرى وحفظها في قواعد البيانات الخاصة بهم.
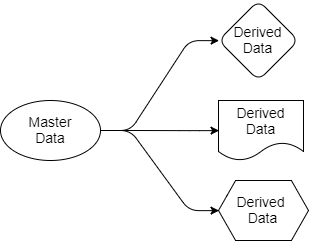
الشكل 4. بيانات المصدر والناتج
كل تطبيق يحتاج للحجز وبيانات الرحلة سوف يستلمه بنفسه لأنه "مشترك" في تلك الأجزاء من كافكا التي تحتوي على هذه البيانات. بالنسبة لهذا التطبيق ، يمكنهم استخدام SQL أو Cypher أو JSON أو أي لغة استعلام أخرى. يمكن للتطبيق بعد ذلك حفظ البيانات في نظامه كما يراه مناسبًا. يمكن تغيير مخطط توزيع البيانات دون التأثير على تشغيل التطبيقات الأخرى.
قد يطرح السؤال: لماذا لا يمكن القيام بكل هذا باستخدام RabbitMQ؟ الإجابة هي أنه يمكن استخدام RabbitMQ لمعالجة الأحداث في الوقت الفعلي ، ولكن ليس كأساس لتوليد الأحداث. RabbitMQ هو حل كامل فقط للاستجابة للأحداث التي تحدث الآن. عند إضافة تطبيق جديد يحتاج إلى الجزء الخاص به من بيانات الحجز المقدمة بتنسيق محسن لمهام هذا التطبيق ، لن يتمكن RabbitMQ من المساعدة. مع RabbitMQ ، نعود إلى قواعد البيانات المشتركة أو REST API.
ثانيًا ، الترتيب الذي تتم فيه معالجة الأحداث مهم. إذا كنت تعمل مع RabbitMQ ، عند إضافة مستلم ثانٍ إلى قائمة الانتظار ، يتم فقد ضمان الامتثال للنظام. وبالتالي ، يتم ملاحظة الترتيب الصحيح لإرسال الرسائل لمستلم واحد فقط ، ولكن هذا بالطبع لا يكفي.
على النقيض من ذلك ، يمكن لـ Kafka توفير جميع البيانات التي يحتاجها هذا التطبيق لإنشاء نسخته الخاصة من البيانات والحفاظ على البيانات محدثة ، بينما يتبع Kafka الترتيب الذي يتم إرسال الرسائل به.
نعود الآن إلى البنيات التي تتمحور حول API. هل ستكون هذه الواجهات دائمًا الخيار الأفضل؟ عندما ترغب في فتح الوصول إلى البيانات للقراءة فقط ، أفضل بنية انبعاث الحدث. سيمنع الفشل المتتالي وتقصير العمر المرتبط بزيادة عدد التبعيات على الخدمات الأخرى. سيكون هناك المزيد من الفرص لتنظيم البيانات بطريقة خلاقة وفعالة داخل الأنظمة. ولكن في بعض الأحيان تحتاج إلى تغيير البيانات بشكل متزامن في كل من نظامك ونظام آخر ، وفي مثل هذه الحالة ، ستكون الأنظمة التي تتمحور حول API مفيدة. يفضلها الكثيرون على الطرق الأخرى غير المتزامنة. أعتقد أن هذه مسألة ذوق.
التطبيقات الحساسة لحركة المرور العالية ومعالجة الأحداث.
منذ وقت ليس ببعيد ، نشأت مشكلة مع أحد مستلمي RabbitMQ ، الذي تلقى ملفات في قائمة الانتظار من خدمة طرف ثالث. كان الحجم الإجمالي للملف كبيرًا ، وتم تكوين التطبيق خصيصًا لاستلام مثل هذا الحجم من البيانات. كانت المشكلة أن البيانات جاءت بشكل غير متناسق ، وهذا خلق الكثير من المشاكل.
بالإضافة إلى ذلك ، في بعض الأحيان كانت هناك مشكلة في حقيقة أنه في بعض الأحيان كان هناك ملفان مخصصان للوجهة نفسها ، ويختلف وقت وصولهما بعدة ثوان. كلاهما خضع للمعالجة وكان يجب تحميلهما على خادم واحد. وبعد تسجيل الرسالة الثانية على الخادم ، فإن الرسالة الأولى التي تليها تكتب فوق الثانية. وهكذا ، انتهى كل شيء بحفظ البيانات غير الصالحة. قامت RabbitMQ بدورها وأرسلت الرسائل بالترتيب الصحيح ، ولكن على الرغم من كل شيء ، انتهى كل شيء بترتيب خاطئ في التطبيق نفسه.
تم حل هذه المشكلة عن طريق قراءة الطابع الزمني من السجلات الموجودة وعدم الاستجابة إذا كانت الرسالة قديمة. بالإضافة إلى ذلك ، تم تطبيق التجزئة المتسقة أثناء تبادل البيانات ، وتم تقسيم قائمة الانتظار ، كما هو الحال مع نفس التقسيم على منصة كافكا.
كجزء من القسم ، يقوم كافكا بتخزين الرسائل بالترتيب الذي تم إرسالها إليه. ترتيب الرسائل موجود فقط داخل القسم. في المثال أعلاه ، باستخدام Kafka ، كان علينا تطبيق دالة التجزئة على معرف الوجهة لتحديد القسم المطلوب. كان علينا إنشاء مجموعة من الأقسام ، يجب أن يكون هناك أكثر من العميل المطلوب. كان يجب أن يتم ترتيب معالجة الرسائل نظرًا لأن كل قسم مخصص لمستلم واحد فقط. بسيطة وفعالة.
لدى كافكا ، مقارنة بـ RabbitMQ ، بعض المزايا المرتبطة بتقسيم الرسائل باستخدام التجزئة. لا يوجد شيء على منصة RabbitMQ يمنع تعارضات المستلمين في نفس قائمة الانتظار التي يتم إنشاؤها كجزء من تبادل البيانات باستخدام التجزئة المتسقة. لا يساعد RabbitMQ في تنسيق المستلمين بحيث يستخدم مستلم واحد فقط من قائمة الانتظار بأكملها الرسالة. تقدم كافكا كل هذا من خلال استخدام مجموعات المستلمين وعقدة المنسق. يسمح لك ذلك بالتأكد من أن مستلمًا واحدًا فقط في القسم مضمون لاستخدام الرسالة ، وأن ترتيب معالجة البيانات مضمون.
مكان البيانات
باستخدام وظيفة التجزئة لتوزيع البيانات عبر الأقسام ، توفر Kafka مكان البيانات. على سبيل المثال ، يجب أن تنتقل الرسائل من المستخدم ذي المعرف 1001 دائمًا إلى المستلم 3. نظرًا لأن أحداث المستخدم 1001 تنتقل دائمًا إلى المستلم 3 ، يمكن للمستلم 3 تنفيذ بعض العمليات بشكل فعال والتي ستكون أكثر صعوبة إذا كان يلزم الوصول المنتظم إلى قاعدة بيانات خارجية أو أنظمة أخرى لتلقي البيانات. يمكننا قراءة البيانات ، وإجراء التجميعات ، إلخ. مباشرة مع المعلومات الموجودة في ذاكرة المستلم. هذا هو المكان الذي تبدأ فيه التطبيقات الموجهة للحدث وتدفق البيانات في الاندماج.
كيف توفر كافكا مكان البيانات؟ بادئ ذي بدء ، من المهم أن نلاحظ أن كافكا لا تسمح بزيادة وتقليل عدد الأقسام. بادئ ذي بدء ، لا يمكنك تقليل عدد الأقسام على الإطلاق: إذا كان هناك 10 أقسام ، فلا يمكنك تقليل العدد إلى 9. ولكن ، من ناحية أخرى ، هذا غير مطلوب. يمكن لكل مستلم استخدام إما قسم واحد أو عدة أقسام ، وبالتالي ، فمن الضروري تقليل عددهم. يؤدي إنشاء أقسام إضافية على كافكا إلى تأخير في وقت إعادة التوازن ، لذلك نحاول زيادة عدد الأقسام مع مراعاة ذروة الأحمال.
ولكن إذا كنا ما زلنا بحاجة إلى زيادة عدد الأقسام والمستلمين من أجل التوسع ، فسنحتاج إلى تكاليف غير مباشرة لمرة واحدة فقط إذا كانت إعادة التوازن ضرورية. وتجدر الإشارة إلى أنه عند قياس البيانات القديمة لا تزال في نفس الأقسام حيث كانت. ولكن سيتم توجيه الرسائل الواردة الجديدة بالفعل بشكل مختلف ، وستبدأ الأقسام الجديدة في تلقي الرسائل الجديدة. يمكن الآن إرسال الرسائل من المستخدم 1001 إلى المستلم 4 (لأن البيانات المتعلقة بالمستخدم 1001 الآن في قسمين).
علاوة على ذلك سنقوم بمقارنة ومقارنة دلالات تسليم رسائل التسليم في كلا النظامين. إن موضوع إعادة التوازن والتقسيم يستحق مقالة منفصلة ، سنناقشها في الجزء التالي.