بايثون رائع. نقول "تثبيت نقطة" وعلى الأرجح سيتم تسليم المكتبة اللازمة. ولكن في بعض الأحيان سيكون الجواب: "فشل التجميع" ، لأن هناك وحدات ثنائية. إنهم يعانون من نوع من الألم في جميع اللغات الحديثة تقريبًا ، لأن هناك الكثير من البنى المعمارية ، يجب تجميع شيء ما لآلة معينة ، شيء ما يجب ربطه بمكتبات أخرى. بشكل عام ، سؤال مثير للاهتمام ولكنه لم يدرس إلا القليل: كيف يمكن القيام به وما هي المشاكل الموجودة؟ حاول دميتري زيلتسوف (
زابجودا ) الإجابة على هذا السؤال في موسكو بيثون كونف العام الماضي.
يوجد تحت النص النسخة النصية لتقرير ديمتري. دعنا نتناول بإيجاز وقت الحاجة إلى وحدات ثنائية ، وعندما يكون من الأفضل التخلي عنها. دعونا نناقش القواعد التي يجب اتباعها عند كتابتها. فكر في خمسة خيارات تنفيذ ممكنة:
- ملحق C / C ++ الأصلي
- أعرج
- سيثون
- الأنواع
- الصدأ
عن المتحدث : دميتري زيلتسوف يتطور منذ أكثر من 10 سنوات. يعمل في CIAN كمهندس أنظمة ، أي أنه مسؤول عن الحلول التقنية والتحكم في التوقيت. في حياتي ، تمكنت من تجربة المجمّع ، هاسكل ، سي ، وعلى مدى السنوات الخمس الماضية ، كنت أبرمج بنشاط في بايثون.
عن الشركة
كثير من الذين يعيشون في موسكو ويؤجرون مساكن ربما يعرفون عن CIAN. CYAN هو 7 ملايين مشتري ومستأجر شهريًا. كل هؤلاء المستخدمين كل شهر ، باستخدام خدمتنا ، يجدون مكانًا للعيش فيه.
حوالي 75 ٪ من سكان موسكو يعرفون عن شركتنا ، وهذا رائع جدًا. في سانت بطرسبرغ وموسكو ، نعتبر عمليا محتكرين. في الوقت الحالي ، نحاول الدخول إلى المناطق ، وبالتالي نمت التنمية 8 مرات خلال السنوات الثلاث الماضية. هذا يعني أن الفريق زاد 8 مرات ، وزادت سرعة تسليم القيم للمستخدم 8 مرات ، أي من فكرة المنتج إلى كيفية طرح يد المهندس لبناء الإنتاج. تعلمنا في فريقنا الكبير أن نتطور بسرعة كبيرة ، وسرعان ما نفهم ما يحدث في الوقت الحالي ، ولكن اليوم سنتحدث قليلاً عن شيء آخر.
سأتحدث عن الوحدات الثنائية. الآن تحتوي 50٪ تقريبًا من مكتبات Python على نوع من الوحدات الثنائية. وكما اتضح ، فإن الكثير من الناس ليسوا على دراية بهم ويعتقدون أن هذا شيء متجاوز ، شيء مظلم وغير ضروري. ويقترح أشخاص آخرون كتابة خدمة مايكرو منفصلة بشكل أفضل وعدم استخدام الوحدات الثنائية.
ستتألف المقالة من جزأين.
- تجربتي: لماذا هم في حاجة إليها ، ومتى يتم استخدامها بشكل أفضل ، ومتى لا.
- الأدوات والتقنيات التي يمكنك من خلالها تنفيذ وحدة ثنائية لـ Python.
لماذا هناك حاجة إلى وحدات ثنائية؟
نعلم جميعًا جيدًا أن Python هي لغة مترجمة. إنها تقريبًا أسرع اللغات المفسرة ، ولكن لسوء الحظ ، فإن
سرعتها لا تكفي دائمًا للحسابات الرياضية الثقيلة. على الفور يعتقد أن C سيكون أسرع.
لكن Python لديها ألم آخر - هو
GIL . وقد كتب عنه عدد كبير من المقالات وتم إعداد تقارير حول كيفية الالتفاف عليه.
نحتاج أيضًا إلى ملحقات ثنائية
لإعادة استخدام المنطق . على سبيل المثال ، وجدنا مكتبة بها كل الوظائف التي نحتاجها ، ولماذا لا نستخدمها. أي أنك لست بحاجة إلى إعادة كتابة الرمز ، فنحن فقط نأخذ الرمز النهائي ونعيد استخدامه.
يعتقد الكثير من الناس أنه باستخدام ملحقات ثنائية يمكنك
إخفاء شفرة المصدر . السؤال مثير للجدل للغاية ، بالطبع ، بمساعدة بعض الانحرافات البرية يمكن تحقيق ذلك ، ولكن لا يوجد ضمان 100 ٪. الحد الأقصى الذي يمكنك الحصول عليه هو عدم السماح للعميل بفك الترجمة ومعرفة ما يحدث في التعليمات البرمجية التي قمت بتمريرها.
متى تحتاج ملحقات ثنائية حقا؟
حول السرعة و Python ، من الواضح - عندما تعمل بعض الوظائف ببطء شديد وتحتل 80 ٪ من وقت تنفيذ جميع التعليمات البرمجية ، نبدأ في التفكير في كتابة ملحق ثنائي. ولكن من أجل اتخاذ مثل هذه القرارات ، تحتاج إلى البدء ، كما قال أحد المتحدثين المشهورين ، فكر في عقلك.
لكتابة ملحقات التمديد ، يجب على المرء أن يأخذ في الاعتبار أن هذا ، أولاً ، سيكون طويلًا. تحتاج أولاً إلى "لعق" الخوارزميات الخاصة بك ، أي انظر إذا كان هناك أي عضادات.
في 90٪ من الحالات ، بعد فحص دقيق للخوارزمية ، تختفي الحاجة إلى كتابة بعض الامتدادات.
الحالة الثانية التي تحتاج إلى ملحقات ثنائية حقًا هي
استخدام خيوط متعددة لعمليات بسيطة . الآن هذا ليس ذو صلة ، لكنه لا يزال في المؤسسة الدموية ، في بعض تكاملات النظام ، حيث لا يزال Python 2.6 مكتوبًا. لا يوجد عدم تزامن ، وحتى بالنسبة للأشياء البسيطة ، على سبيل المثال ، عند تحميل مجموعة من الصور ، ترتفع سلاسل المحادثات المتعددة. يبدو أن هذا في البداية لا يتكبد أي نفقات للشبكة ، ولكن عندما نقوم بتحميل الصورة إلى المخزن المؤقت ، فإن GIL المشؤوم يأتي ويبدأ نوع من الفرامل. كما تظهر الممارسة ، يتم حل هذه الأشياء بشكل أفضل باستخدام مكتبات لا تعرف بايثون شيئًا عنها.
إذا كنت بحاجة إلى تنفيذ بعض البروتوكولات المحددة ، فقد يكون من المناسب عمل كود C / C ++ بسيط والتخلص من الكثير من الألم. فعلت ذلك في وقتي في مشغل اتصالات واحد ، حيث لم تكن هناك مكتبة جاهزة - كان علي أن أكتبها بنفسي. لكني أكرر ، الآن هذا ليس ذو صلة ، لأن هناك عدم التزامن ، وهذا بالنسبة لمعظم المهام هذا يكفي.
حول
العمليات الصعبة بشكل واضح
، سبق أن قلت ذلك مسبقًا. عندما يكون لديك أعطال ومصفوفات كبيرة وما شابه ذلك ، فمن المنطقي أنك بحاجة إلى إجراء تمديد لـ C / C ++. أريد أن أشير إلى أن بعض الناس يعتقدون أننا لسنا بحاجة إلى ملحقات ثنائية هنا ، فمن الأفضل إنشاء خدمة صغيرة في بعض "
لغة فائقة السرعة " ونقل مصفوفات ضخمة عبر الشبكة. لا ، من الأفضل عدم القيام بذلك.
مثال جيد آخر عندما يمكن ويجب أخذها هو عندما يكون لديك
منطق ثابت للوحدة النمطية . إذا كان لديك نوع من وحدة Python في شركتك أو مكتبة موجودة بالفعل لمدة 3 سنوات ، فهناك تغييرات فيها مرة واحدة في السنة ثم سطرين ، فلماذا لا تحولها إلى مكتبة C عادية إذا كانت هناك موارد ووقت مجاني. كحد أدنى ، احصل على زيادة في الإنتاجية. وسيكون هناك أيضًا فهم بأنه إذا كانت هناك حاجة لبعض التغييرات الجوهرية في المكتبة ، فهذا ليس بهذه البساطة ، وربما يكون من المفيد التفكير مرة أخرى مع الدماغ واستخدام هذه المكتبة بطريقة مختلفة.
5 قواعد ذهبية
لقد اشتقت هذه القواعد في ممارستي. فهي لا تتعلق فقط بـ Python ، ولكن أيضًا باللغات الأخرى التي يمكنك استخدام ملحقات ثنائية لها. يمكنك أن تجادل معهم ، ولكن يمكنك أيضًا التفكير وإحضارها بنفسك.
- وظائف التصدير فقط . إن بناء فصول في Python في المكتبات الثنائية يستغرق وقتًا طويلاً: تحتاج إلى وصف الكثير من الواجهات ، تحتاج إلى مراجعة الكثير من التكامل المرجعي في الوحدة النمطية نفسها. من الأسهل كتابة واجهة صغيرة للوظيفة.
- استخدم فئات المجمّع . البعض مغرمون جدًا بـ OOP ويريدون حقًا دروسًا. على أي حال ، حتى إذا لم تكن هذه الفئات ، فمن الأفضل كتابة غلاف Python فقط: إنشاء فئة ، وتحديد طريقة فئة أو طريقة عادية ، واستدعاء وظائف C / C ++ الأصلية. يساعد هذا كحد أدنى على الحفاظ على سلامة بنية البيانات. إذا كنت تستخدم نوعًا من ملحق C / C ++ من جهة خارجية لا يمكنك إصلاحه ، فيمكنك في الغلاف أن تخترقه حتى يعمل كل شيء.
- لا يمكنك تمرير الحجج من Python إلى امتداد - هذه ليست حتى قاعدة ، بل شرط. في بعض الحالات ، قد ينجح ذلك ، ولكنها عادة ما تكون فكرة سيئة. لذلك ، في التعليمات البرمجية الخاصة بك ، يجب عليك أولاً إنشاء معالج يلقي نوع Python إلى النوع C. وفقط بعد ذلك استدعاء أي دالة أصلية تعمل بالفعل مع النوع s. يتلقى المعالج نفسه استجابة من دالة قابلة للتنفيذ ويحولها إلى أنواع بيانات Python ، ويلقيها في رمز Python.
- ضع في الاعتبار جمع القمامة . يحتوي Python على GC معروف ، ولا يجب نسيانه. على سبيل المثال ، نقوم بتمرير جزء كبير من النص حسب المرجع ونحاول العثور على بعض الكلمات في المكتبة. نريد موازنة ذلك ، ونمرر الرابط إلى منطقة الذاكرة هذه وإطلاق العديد من الخيوط. في هذا الوقت ، يأخذ GC ويقرر ببساطة أنه لا شيء آخر يشير إلى هذا الكائن ويزيله من منطقة الذاكرة. في نفس الرمز ، نحصل فقط على مرجع فارغ ، وعادة ما يكون هذا خطأ تجزئة. يجب ألا ننسى هذه الميزة في جامع القمامة وننقل أبسط أنواع البيانات إلى مكتبات تشار: char ، integer ، إلخ.
من ناحية أخرى ، قد يكون للغة التي تتم كتابة الامتداد بها جامع القمامة الخاص بها. إن الجمع بين Python ومكتبة C # هو ألم بهذا المعنى.
- تحديد وسيطات الدالة المُصدرة بشكل صريح . بهذا ، أود أن أقول إن هذه الوظائف ستحتاج إلى شرح توضيحي نوعيًا. إذا قبلنا وظيفة PyObject ، وفي أي حال سنقبلها في مكتبتنا ، فسوف نحتاج إلى الإشارة بوضوح إلى أي الوسيطات تنتمي إلى الأنواع. هذا مفيد لأنه إذا مررنا بنوع بيانات خاطئ ، فسوف نحصل على خطأ في المكتبة. أي أنك تحتاجه لراحتك.
هندسة التمديد الثنائي

في الواقع ، لا يوجد شيء معقد في بنية التمديدات الثنائية. هناك Python ، هناك وظيفة استدعاء تهبط على غلاف يستدعي الرمز أصلاً. تقوم هذه المكالمة بدورها على دالة يتم تصديرها إلى Python ويمكنها الاتصال بها مباشرة. في هذه الوظيفة تحتاج إلى إرسال أنواع البيانات إلى أنواع بيانات لغتك. وفقط بعد أن ترجمت هذه الوظيفة كل شيء إلينا ، فإننا نسمي الوظيفة الأصلية ، التي تقوم بالمنطق الرئيسي ، وترجع النتيجة في الاتجاه المعاكس وترميها إلى Python ، وترجمة أنواع البيانات مرة أخرى.
التكنولوجيا والأدوات
الطريقة الأكثر شيوعًا لكتابة ملحقات ثنائية هي امتداد C / C ++ الأصلي. فقط لأنها تقنية بيثون القياسية.
ملحق C / C ++ الأصلي
يتم تطبيق Python نفسه في C ، ويتم استخدام الطرق والهياكل من python.h لكتابة ملحقات. بالمناسبة ، هذا الشيء جيد أيضًا لأنه من السهل جدًا تنفيذه في مشروع موجود. يكفي تحديد xt_modules في setup.py والقول أنه لبناء المشروع تحتاج إلى تجميع مثل هذه المصادر مع أعلام التجميع هذه. أدناه مثال.
name = 'DateTime.mxDateTime.mxDateTime' src = 'mxDateTime/mxDateTime.c' extra_compile_args=['-g3', '-o0', '-DDEBUG=2', '-UNDEBUG', '-std=c++11', '-Wall', '-Wextra'] setup ( ... ext_modules = [(name, { 'sources': [src], 'include_dirs': ['mxDateTime'] , extra_compile_args: extra_compile_args } )] )
إيجابيات ملحق C / C ++ الأصلي
- التكنولوجيا الأصلية.
- يتم دمجها بسهولة في تجميع المشروع.
- أكبر كمية من الوثائق.
- يسمح لك بإنشاء أنواع البيانات الخاصة بك.
سلبيات ملحق C / C ++ الأصلي
- عتبة دخول عالية.
- مطلوب معرفة C.
- دفعة. بيثون.
- خطأ التقسيم.
- صعوبات في تصحيح الأخطاء.
وفقًا لهذه التقنية ، تتم كتابة كمية هائلة من الوثائق ، سواء القياسية أو المنشورات على المدونة. ميزة إضافية كبيرة هي أنه يمكننا القيام بأنواع بيانات Python الخاصة بنا وإنشاء فصولنا.
هذا النهج له عيوب كبيرة. أولاً ، إنها عتبة الإدخال - لا يعلم الجميع C بما يكفي لترميز الإنتاج. عليك أن تفهم أنه لا يكفي قراءة الكتاب والتشغيل لكتابة ملحقات أصلية. إذا كنت تريد القيام بذلك ، فعليك أولاً: تعلم C؛ ثم ابدأ في كتابة أدوات القيادة ؛ فقط بعد ذلك انتقل إلى كتابة ملحقات.
Boost.Python جيد جدًا لـ C ++ ، فهو يسمح لك بالتجريد بالكامل تقريبًا من جميع هذه الأغلفة التي نستخدمها في Python. لكن النقص ، على ما أعتقد ، هو أنك بحاجة إلى التعرق كثيرًا لأخذ جزء منه واستيراده في المشروع دون تنزيل Boost بالكامل.
عند سرد صعوبات تصحيح الأخطاء في السلبيات ، أعني أن الجميع معتادون الآن على استخدام مصحح أخطاء رسومية ، ومع الوحدات الثنائية لن يعمل مثل هذا الشيء. على الأرجح تحتاج إلى تثبيت GDB مع مكون إضافي لـ Python.
دعونا نلقي نظرة على مثال لكيفية إنشاء هذا.
#include <Python.h> static PyObject*addList_add(Pyobject* self, Pyobject* args){ PyObject * listObj; if (! PyARg_Parsetuple( args, "", &listObj)) return NULL; long length = PyList_Size(listObj) int i, sum =0; // return Py_BuildValue("i", sum); }
للبدء ، نقوم بتضمين ملفات رأس Python. بعد ذلك ، نصف وظيفة addList_add التي ستستخدمها Python. الشيء الأكثر أهمية هو تسمية الوظيفة بشكل صحيح ، في هذه الحالة addList هو اسم الوحدة النمطية ، _add هو اسم الوظيفة التي سيتم استخدامها في Python. نقوم بتمرير وحدة PyObject نفسها ونقوم بتمرير الحجج باستخدام PyObject أيضًا. بعد ذلك ، نقوم بإجراء فحوصات قياسية. في هذه الحالة ، نحاول تحليل حجة tuple ونقول أنه كائن - يجب تحديد الحرف "O" بشكل صريح. بعد ذلك ، نعلم أننا تجاوزنا listObj ككائن ، ونحاول معرفة طوله باستخدام طرق Python القياسية: PyList_Size. لاحظ أننا ما زلنا لا نستطيع استخدام مكالمات الاتصال لمعرفة طول هذا المتجه ، ولكن استخدم وظيفة Python. نحذف التنفيذ ، وبعد ذلك من الضروري إعادة جميع القيم إلى Python. للقيام بذلك ، اتصل Py_BuildValue ، حدد نوع البيانات التي نعرضها ، وفي هذه الحالة يكون "i" عددًا صحيحًا ، ومتغير المجموع نفسه.
في هذه الحالة ، يفهم الجميع - نجد مجموع جميع عناصر القائمة. دعنا نذهب أبعد قليلا.
for(i = 0; i< length; i++){
هذا هو نفس الشيء ؛ في الوقت الحالي ، listObj هو كائن Python. وفي هذه الحالة ، نحاول أخذ عناصر القائمة. Python.h لديها كل ما تحتاجه لذلك.
بعد أن وصلنا إلى درجة الحرارة ، نحاول إلقاءها لفترة طويلة. وفقط بعد ذلك يمكنك القيام بشيء في C.
بعد تنفيذ الوظيفة بأكملها ، من الضروري كتابة الوثائق.
التوثيق جيد دائمًا ، وتحتوي مجموعة الأدوات هذه على كل شيء من أجل الصيانة المريحة. بعد اصطلاح التسمية ، نقوم بتسمية وحدة addList_docs وحفظ الوصف هناك. الآن تحتاج إلى تسجيل الوحدة النمطية ، لهذا هناك بنية PyMethodDef خاصة. عند وصف الخصائص ، نقول أن الوظيفة يتم تصديرها إلى Python تحت اسم "add" ، والتي تستدعيها هذه الوظيفة PyCFunction. يعني METH_VARARGS أن الدالة يمكن أن تأخذ أي عدد من المتغيرات. قمنا أيضًا بتدوين الأسطر الإضافية ووصفنا فحصًا قياسيًا ، في حالة استيراد الوحدة للتو ، لكننا لم نستخدم أي طريقة حتى لا تسقط.
بعد أن أعلنا عن كل هذا ، نحاول إنشاء وحدة نمطية. ننشئ نموذجًا موحدًا ونضع كل ما قمنا به هناك.
static struct PyModuleDef moduledef = { PyModuleDef_HEAD_INIT, "addList example module", -1, adList_funcs, NULL, NULL, NULL, NULL };
PyModuleDef_HEAD_INIT هو ثابت Python قياسي يجب استخدامه دائمًا. يشير -1 إلى أنه لا يلزم تخصيص ذاكرة إضافية في مرحلة الاستيراد.
عندما أنشأنا الوحدة نفسها ، نحتاج إلى تهيئتها. تبحث Python دائمًا عن init ، لذا قم بإنشاء PyInit_addList لـ addList. الآن من الهيكل المجمع ، يمكنك استدعاء PyModule_Create وأخيرًا إنشاء الوحدة النمطية نفسها. بعد ذلك ، أضف المعلومات الوصفية وأعد الوحدة النمطية نفسها.
PyInit_addList(void){ PyObject *module = PyModule_Create(&mdef); If (module == NULL) return NULL; PyModule_AddStringConstant(module, "__author__", "Bruse Lee<brus@kf.ch>:"); PyModule_addStringConstant (Module, "__version__", "1.0.0"); return module; }
كما لاحظت بالفعل ، هناك الكثير من الأشياء التي يجب تغييرها. يجب أن تتذكر Python دائمًا عندما نكتب بلغة C / C ++.
لهذا السبب ، لتسهيل حياة مبرمج بشري عادي ، منذ حوالي 15 عامًا ، ظهرت تقنية SWIG.
أعرج
تتيح لك هذه الأداة التجريد من روابط بايثون وكتابة كود أصلي. له نفس إيجابيات وسلبيات Native C / C ++ ، ولكن هناك استثناءات.
إيجابيات SWIG:
- تقنية مستقرة.
- كمية كبيرة من الوثائق.
- ملخصات من الارتباط بـ Python.
سلبيات SWIG:
- الإعداد الطويل.
- المعرفة ج.
- خطأ التقسيم.
- صعوبات في تصحيح الأخطاء.
- تعقيد الاندماج في تجميع المشروع.
أول ناقص هو أنه
أثناء إعداده ، ستفقد عقلك . عندما قمت بإعداده لأول مرة ، أمضيت يومًا ونصفًا حتى في إطلاقه. ثم ، بالطبع ، الأمر أسهل. أصبح إصدار SWIG 3.x أسهل.
من أجل عدم الخوض في الكود ، ضع في اعتبارك المخطط العام لـ SWIG.
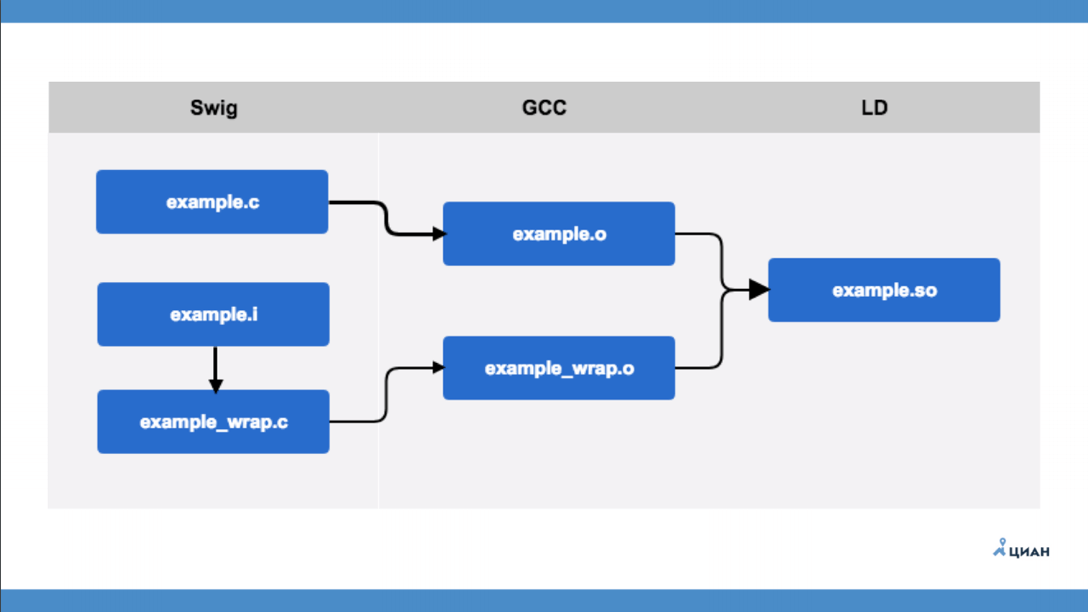
example.c هي وحدة C لا تعرف شيئًا عن Python على الإطلاق. يوجد مثال لملف الواجهة. i ، موصوف بتنسيق SWIG. بعد ذلك ، قم بتشغيل أداة SWIG ، التي تنشئ example_wrap.c من ملف الواجهة - هذا هو نفس الغلاف الذي اعتدنا القيام به بأيدينا. أي أن SWIG يخلق فقط غلاف ملف بالنسبة لنا ، ما يسمى الجسر. بعد ذلك ، باستخدام GCC ، نقوم بتجميع ملفين ونحصل على ملفين للكائن (example.o و example_wrap.o) وعندها فقط نقوم بإنشاء مكتبتنا. كل شيء بسيط وواضح.
سيثون
قدم أندريه سفيتلوف
تقريرًا ممتازًا في MoscowPython Conf ، لذلك سأقول فقط أن هذه تقنية شائعة ذات وثائق جيدة.
إيجابيات Cython:
- التكنولوجيا الشعبية.
- مستقر جدا.
- يتم دمجها بسهولة في تجميع المشروع.
- وثائق جيدة.
سلبيات Cython:
- بناء الجملة الخاصة.
- المعرفة ج.
- خطأ التقسيم.
- صعوبات في تصحيح الأخطاء.
السلبيات ، كما هو الحال دائمًا. العنصر الرئيسي هو بناء الجملة الخاص به ، والذي يشبه C / C ++ ، ويشبه إلى حد كبير Python.
ولكن أريد أن أشير إلى أنه يمكن تسريع كود Python باستخدام Cython من خلال كتابة كود أصلي.

كما ترون ، هناك الكثير من الديكورات ، وهذا ليس جيدًا جدًا. إذا كنت تريد استخدام Cython - ارجع إلى تقرير Andrei Svetlov.
CTypes
CTypes هي مكتبة Python القياسية التي تعمل مع واجهة الوظيفة الأجنبية. FFI هي مكتبة منخفضة المستوى. هذه تقنية أصلية ، وغالبًا ما يتم استخدامها بشكل شائع في التعليمات البرمجية ، مع مساعدتها ، يسهل تنفيذها عبر الأنظمة الأساسية.
لكن FFI يحمل الكثير من النفقات العامة لأن جميع الجسور وجميع المعالجات في وقت التشغيل يتم إنشاؤها ديناميكيًا. أي أننا قمنا بتحميل المكتبة الديناميكية ، ولا تعرف بايثون في هذه اللحظة ماهية المكتبة. فقط عندما يتم استدعاء مكتبة في الذاكرة ، يتم إنشاء هذه الجسور ديناميكيًا.
إيجابيات CTypes:
- التكنولوجيا الأصلية.
- سهل الاستخدام في التعليمات البرمجية.
- من السهل تنفيذ عبر منصة.
- يمكنك استخدام أي لغة تقريبًا.
السلبيات:
- يحمل النفقات العامة.
- صعوبات في تصحيح الأخطاء.
from ctypes import *
أخذوا adder.so ودعوه في وقت التشغيل. يمكننا حتى تمرير أنواع بايثون الأصلية.
بعد كل هذا ، السؤال هو: "الأمر معقد إلى حد ما ، في كل مكان C ، ماذا تفعل؟".
الصدأ
في وقت من الأوقات ، لم أعط اللغة الاهتمام المناسب ، ولكن الآن أنتقل إليها عمليًا.
إيجابيات الصدأ:
- لغة آمنة.
- ضمانات ثابتة قوية للسلوك الصحيح.
- يدمج بسهولة في يبني المشروع ( PyO3 ).
سلبيات الصدأ:
- عتبة دخول عالية.
- الإعداد الطويل.
- صعوبات في تصحيح الأخطاء.
- هناك القليل من الوثائق.
- في بعض الحالات ، النفقات العامة.
الصدأ لغة آمنة مع إثبات تلقائي للعمل. بناء الجملة نفسه والمعالج المسبق للغة نفسها لا يسمحان بارتكاب خطأ صريح. في الوقت نفسه ، يتم التركيز على التباين ، أي أنه يجب معالجة أي نتيجة لتنفيذ فرع التعليمات البرمجية.
بفضل فريق PyO3 ، هناك ملفات Python جيدة لـ Rust وأدوات للاندماج في المشروع.
على الجانب السلبي ، سأعتبر أنه بالنسبة للمبرمج غير المستعد يستغرق تكوينه وقتًا طويلاً جدًا. وثائق قليلة ، ولكن بدلاً من السلبيات ، ليس لدينا خطأ تجزئة. في Rust ، بطريقة جيدة ، في 99 ٪ من الحالات ، لا يمكن للمبرمج أن يحصل على خطأ تجزئة إلا إذا أشار صراحة إلى عدم الالتفاف وسجله للتو.
مثال صغير على الكود ، نفس الوحدة التي فحصناها من قبل.
#![feature(proc_macro)] #[macro_use] extern crate pyo3; Use pyo3::prelude::*;
يحتوي الرمز على بناء جملة محدد ، ولكن تعتاد عليه بسرعة كبيرة. في الواقع ، كل شيء هو نفسه هنا. باستخدام وحدات الماكرو ، نصنع modinit ، والذي يؤدي لنا جميع الأعمال الإضافية لتوليد جميع أنواع المجلدات لـ Python. تذكر قلت ، عليك القيام بغلاف معالج ، هنا هو نفسه. يحول run_py الأنواع ، ثم نسمي الشفرة الأصلية.
كما ترون ، من أجل تصدير بعض الوظائف ، هناك سكر نحوي. نقول فقط أننا بحاجة إلى وظيفة الإضافة ولا نصف أي واجهات. نحن نقبل القائمة ، وهي py_list بالضبط ، وليس Object ، لأن Rust نفسها ستقوم بإعداد المجلدات اللازمة في وقت التجميع. إذا قمنا بتمرير نوع بيانات خاطئ ، كما هو الحال في ملحقات الامتداد ، فسيحدث TypeError. بعد الحصول على القائمة ، نبدأ في معالجتها.
دعونا نرى بمزيد من التفصيل ما بدأ يفعله.
#[pyfn(m, "add", py_list="*")] fn add(_py: Python, py_list: &PyList) -> PyResult<i32> { match py_list.len() { 0 =>Err(EmptyListError::new("List is empty")), _ => { let mut sum : i32 = 0; for item in py_list.iter() { let temp:i32 = match item.extract() { Ok(v) => v, Err(_) => { let err_msg: String = format!("List item {} is not int", item); return Err(ItemListError::new(err_msg)) } }; sum += temp; } Ok(sum) } } }
نفس الرمز الذي كان في C / C ++ / Ctypes ، ولكن فقط في Rust. هناك حاولت أن ألقي PyObject إلى نوع من طويلة. ماذا سيحدث إذا وصلنا إلى القائمة ، باستثناء الأرقام ، هل سنحصل على سلسلة؟ نعم ، سنحصل على خطأ SystemEerror. في هذه الحالة ، من خلال
let mut sum
: i32 = 0؛ نحن نحاول أيضًا الحصول على قيمة من القائمة وإلقاءها في i32. أي أننا لن نتمكن من كتابة هذا الكود بدون item.extract () ، دون وعي وإلقاء للنوع المطلوب. عندما كتبنا i32 ، في حالة خطأ Rust ، في مرحلة التجميع ، سيقول: "تعامل مع الحالة عندما لا تكون i32". في هذه الحالة ، إذا كان لدينا i32 ، فسنعيد قيمة ، إذا كان هذا خطأ ، فإننا نرمي استثناءً.
ماذا تختار
بعد هذه الجولة القصيرة ، سنفكر في ما سنختار في النهاية؟
الجواب هو حقا لذوقك ولونك.
لن أقوم بالترويج لأي تقنية محددة.

فقط لخص ما قيل:
- في حالة SWIG و C / C ++ ، تحتاج إلى معرفة C / C ++ جيدًا ، وأن تفهم أن تطوير هذه الوحدة سوف يتطلب بعض التكاليف الإضافية. ولكن سيتم استخدام الحد الأدنى من الأدوات ، وسنعمل في تقنية Python الأصلية ، والتي يدعمها المطورون.
- في حالة Cython ، لدينا حد إدخال صغير ، ولدينا سرعة تطوير عالية ، وهذا أيضًا هو مولد رمز عادي.
- على حساب CTypes ، أريد أن أحذرك من النفقات العامة الكبيرة نسبيًا. تحميل المكتبة الديناميكي ، عندما لا نعرف نوع المكتبة ، يمكن أن يؤدي إلى الكثير من المتاعب.
- أنصح Rust أن يأخذ شخصًا لا يعرف C / C ++ جيدًا. الصدأ في الإنتاج يحمل أقل المشاكل حقًا.
دعوة لتقديم أوراق
نقبل الطلبات الخاصة بموسكو Python Conf ++ حتى 7 سبتمبر - اكتب في هذا النموذج البسيط الذي تعرفه عن Python والذي تحتاج حقًا لمشاركته مع المجتمع.
بالنسبة لأولئك المهتمين بالاستماع ، يمكنني التحدث عن التقارير الرائعة.
- يحب دونالد وايت الحديث عن تسريع الرياضيات في بايثون ، ويقوم بإعداد قصة جديدة لنا: كيفية جعل الرياضيات أسرع 10 مرات باستخدام المكتبات والحيل والخيانة الشائعة ، والشفرة واضحة ومدعومة.
- جمع Artyom Malyshev كل سنواته العديدة من الخبرة في تطوير Django ويقدم دليل تقرير عن الإطار! كل ما يحدث بين تلقي طلب HTTP وإرسال صفحة ويب منتهية: فضح السحر وخريطة الآليات الداخلية للإطار والعديد من النصائح المفيدة لمشاريعك.