مرحبا يا هبر! في الآونة الأخيرة ،
تحدثنا لفترة وجيزة عن واجهات اللغة الطبيعية. حسنا ، اليوم لم نقم بإيجاز. تحت القطع ستجد قصة كاملة عن إنشاء NL2API لواجهة برمجة تطبيقات الويب. لقد جرب زملاؤنا من قسم الأبحاث نهجًا فريدًا لجمع بيانات التدريب الخاصة بالإطار. انضم الآن!

شرح
مع تطور الإنترنت نحو بنية موجهة للخدمة ، تزداد أهمية واجهات البرامج (API) كطريقة لتوفير الوصول إلى البيانات والخدمات والأجهزة. نحن نعمل على قضية إنشاء واجهة لغة طبيعية لواجهة برمجة التطبيقات (NL2API) ، مع التركيز على خدمات الويب. تتمتع حلول NL2API بالعديد من الفوائد المحتملة ، على سبيل المثال ، مما يساعد على تبسيط دمج خدمات الويب في المساعدين الافتراضيين.
نحن نقدم أول منصة شاملة (إطار عمل) تسمح لك بإنشاء NL2API لواجهة برمجة تطبيقات ويب معينة. المهمة الرئيسية هي جمع البيانات للتدريب ، أي أزواج "أمر NL - استدعاء API" ، مما يسمح لـ NL2API بدراسة دلالات كلا الأمرين NL الذين ليس لديهم تنسيق محدد بدقة ومكالمات API رسمية. نحن نقدم نهجنا الفريد الخاص بجمع بيانات التدريب لـ NL2API باستخدام التعهيد الجماعي - جذب العديد من العاملين عن بعد لإنشاء فرق NL مختلفة. نحن نحسن عملية التعهيد الجماعي نفسه من أجل تقليل التكاليف.
على وجه الخصوص ، نقدم نموذجًا احتماليًا هرميًا جديدًا بشكل أساسي سيساعدنا على توزيع الميزانية من أجل التعهيد الجماعي ، بشكل رئيسي بين مكالمات API ذات القيمة العالية لتعلم NL2API. نطبق إطار عملنا على واجهات برمجة التطبيقات الحقيقية ونوضح أنه يسمح لك بجمع بيانات تدريب عالية الجودة بأقل تكلفة ، بالإضافة إلى إنشاء NL2API عالي الأداء من البداية. نثبت أيضًا أن نموذج التعهيد الجماعي لدينا يحسن كفاءة هذه العملية ، أي أن بيانات التدريب التي تم جمعها في إطارها توفر أداء NL2API أعلى ، والذي يتجاوز بشكل كبير خط الأساس.
مقدمة
تلعب واجهات برمجة التطبيقات (APIs) دورًا متزايد الأهمية في كل من العالمين الافتراضي والمادي ، وذلك بفضل تطوير تقنيات مثل العمارة الموجهة نحو الخدمة (SOA) والحوسبة السحابية وإنترنت الأشياء (IoT). على سبيل المثال ، توفر خدمات الويب المستضافة في السحابة (الطقس والرياضة والتمويل ، وما إلى ذلك) من خلال واجهة برمجة تطبيقات الويب البيانات والخدمات للمستخدمين النهائيين ، وتمكن أجهزة إنترنت الأشياء أجهزة الشبكة الأخرى من استخدام وظائفها.
 الشكل 1. تم تجميع أزواج "أمر NL (يسار) ومكالمة API (يمين)"
الشكل 1. تم تجميع أزواج "أمر NL (يسار) ومكالمة API (يمين)"
إطار عملنا والمقارنة مع IFTTT. GET-Messages و GET-Events هما واجهتا برمجة تطبيقات ويب للعثور على رسائل البريد الإلكتروني وأحداث التقويم ، على التوالي. يمكن استدعاء API بمعلمات مختلفة. نحن نركز على مكالمات API ذات المعلمات الكاملة ، بينما يقتصر IFTTT على واجهات برمجة التطبيقات ذات المعلمات البسيطة.عادةً ، يتم استخدام واجهات برمجة التطبيقات في مجموعة متنوعة من البرامج: تطبيقات سطح المكتب ومواقع الويب وتطبيقات الجوال. كما أنها تخدم المستخدمين من خلال واجهة مستخدم رسومية (GUI). قدمت واجهة المستخدم الرسومية مساهمة كبيرة في تعميم أجهزة الكمبيوتر ، ولكن مع تطور تكنولوجيا الكمبيوتر ، تتجلى قيودها العديدة بشكل متزايد. من ناحية ، عندما تصبح الأجهزة أصغر حجمًا وأكثر قدرة على الحركة وأكثر ذكاءً ، تتزايد باستمرار متطلبات العرض الرسومي على الشاشة ، على سبيل المثال ، فيما يتعلق بالأجهزة المحمولة أو الأجهزة المتصلة بإنترنت الأشياء.
من ناحية أخرى ، يجب على المستخدمين التكيف مع مختلف واجهات المستخدم الرسومية المتخصصة لمختلف الخدمات والأجهزة. مع زيادة عدد الخدمات والأجهزة المتاحة ، تزداد أيضًا تكلفة التدريب وتكييف المستخدم. تُظهر واجهات اللغة الطبيعية (NLIs) ، مثل المساعد الافتراضي لـ Apple Siri و Microsoft Cortana ، والتي تسمى أيضًا واجهات المحادثة أو واجهات الحوار (CUIs) ، إمكانات كبيرة كأداة ذكية واحدة لمجموعة واسعة من خدمات الخادم والأجهزة.
في هذا البحث ، نعتبر مشكلة إنشاء واجهة لغة طبيعية لواجهة برمجة التطبيقات (NL2API). ولكن ، على عكس المساعدين الافتراضيين ، هذه ليست أهدافًا غير هادفة للأغراض العامة ،
نحن نعمل على تطوير مناهج لإنشاء NLIs لواجهات برمجة تطبيقات ويب معينة ، مثل واجهات برمجة تطبيقات خدمات الويب مثل خدمة ESPN1 للرياضات المتعددة. يمكن لمثل هذه NL2API حل مشكلة قابلية التوسع في NLI ذات الأغراض العامة من خلال تمكين التنمية الموزعة. تعتمد فائدة المساعد الافتراضي بشكل كبير على اتساع قدراته ، أي على عدد الخدمات التي يدعمها.
ومع ذلك ، فإن دمج خدمات الويب في مساعد افتراضي واحد في كل مرة هو عمل شاق للغاية. إذا كان لدى مزودي خدمة الويب الفرديين طريقة غير مكلفة لإنشاء NLIs لواجهات برمجة التطبيقات الخاصة بهم ، فسيتم تخفيض تكاليف التكامل بشكل كبير. لن يضطر المساعد الافتراضي إلى معالجة واجهات مختلفة لخدمات الويب المختلفة. سيكون كافياً بالنسبة له ببساطة أن يدمج NL2APIs الفردية ، التي تحقق التوحيد بفضل اللغة الطبيعية. من ناحية أخرى ، يمكن لـ NL2API أيضًا تبسيط اكتشاف خدمات الويب وتوصيات البرمجة وأنظمة المساعدة لواجهات برمجة التطبيقات ، مما يلغي الحاجة إلى تذكر العدد الكبير من واجهات برمجة تطبيقات الويب المتاحة ونحوها.
مثال 1. يظهر مثالان في الشكل 1. يمكن استدعاء API بمعلمات مختلفة. في حالة واجهة برمجة تطبيقات بحث البريد الإلكتروني ، يمكن للمستخدمين تصفية البريد الإلكتروني حسب خصائص معينة أو البحث عن رسائل البريد الإلكتروني حسب الكلمات الرئيسية. تتمثل المهمة الرئيسية لـ NL2API في تعيين أوامر NL لمكالمات API المقابلة.
التحدي. يعد جمع بيانات التدريب أحد أهم المهام المرتبطة بالبحث في تطوير واجهات NLI وتطبيقها العملي. تستخدم NLI بيانات تدريب محكومة ، والتي في حالة NL2API تتكون من أزواج من "أمر NL - استدعاء API" لدراسة الدلالات وتعيين أوامر NL بشكل لا لبس فيه للتمثيلات الرسمية ذات الصلة. اللغة الطبيعية مرنة للغاية ، لذلك يمكن للمستخدمين وصف مكالمة API بطرق مختلفة نحويًا ، أي أن إعادة الصياغة تحدث.
ضع في اعتبارك المثال الثاني في الشكل 1. يمكن للمستخدمين إعادة صياغة هذا السؤال على النحو التالي: "أين سيعقد الاجتماع التالي" أو "البحث عن مكان للاجتماع التالي". لذلك ، من المهم للغاية جمع بيانات تدريب كافية بحيث يعترف النظام بمثل هذه الخيارات. تلتزم المؤسسات غير الربحية القائمة عادةً بمبدأ "أفضل ما يمكن" في جمع البيانات. على سبيل المثال ، تستخدم أقرب مقارناتنا لمنهجتنا لمقارنة أوامر NL بمكالمات API مفهوم IF-This-Then-That (IFTTT) - "إذا كان الأمر كذلك ، ثم" (الشكل 1). تأتي بيانات التدريب مباشرة من موقع IFTTT الإلكتروني.
ومع ذلك ، إذا كانت واجهة برمجة التطبيقات غير مدعومة أو غير مدعومة بالكامل ، فلا توجد طريقة لإصلاح الموقف. بالإضافة إلى ذلك ، فإن بيانات التدريب التي تم جمعها بهذه الطريقة لا تنطبق على دعم الأوامر المتقدمة مع العديد من المعلمات. على سبيل المثال ، قمنا بتحليل سجلات مكالمات Microsoft API مجهولة الهوية للبحث عن رسائل البريد الإلكتروني للشهر ووجدنا أن حوالي 90٪ منهم يستخدمون معلمتين أو ثلاث (نفس الكمية تقريبًا) ، وهذه المعلمات متنوعة تمامًا. لذلك ، نسعى جاهدين لتوفير الدعم الكامل لمعلمات واجهة برمجة التطبيقات وتنفيذ أوامر NL المتقدمة. لا تزال مشكلة نشر عملية نشطة وقابلة للتخصيص لجمع بيانات التدريب لواجهة برمجة تطبيقات معينة في الوقت الحالي بدون حل.
لقد تم حل مشكلات استخدام NLI مع تمثيلات رسمية أخرى ، مثل قواعد البيانات العلائقية وقواعد المعرفة وجداول الويب ، بشكل جيد جدًا ، في حين لم يتم إيلاء أي اهتمام تقريبًا لتطوير NLI لواجهات برمجة تطبيقات الويب. نحن نقدم أول منصة شاملة (إطار عمل) تسمح لك بإنشاء NL2API لواجهة برمجة تطبيقات ويب معينة من البداية. في تنفيذ واجهة برمجة تطبيقات الويب ، يتضمن إطار عملنا ثلاث مراحل: (1) عرض تقديمي. يحتوي تنسيق HTTP web API الأصلي على الكثير من البيانات الزائدة ، وبالتالي تشتيت الانتباه من وجهة نظر NLI.
نقترح استخدام تمثيل دلالية وسيط لواجهة برمجة تطبيقات الويب ، حتى لا يتم تحميل NLI بالمعلومات غير الضرورية. (2) مجموعة من بيانات التدريب. نحن نقدم نهجًا جديدًا للحصول على بيانات تدريب محكومة استنادًا إلى التعهيد الجماعي. (3) NL2API. نقدم أيضًا نموذجين NL2API: نموذج استخراج مستند إلى اللغة ونموذج شبكة عصبية متكررة (Seq2Seq).
إحدى النتائج الفنية الرئيسية لهذا العمل هي نهج جديد بشكل أساسي لجمع نشط لبيانات التدريب لـ NL2API استنادًا إلى الاستعانة بمصادر خارجية - نحن نستخدم المديرين التنفيذيين عن بُعد للتعليق على مكالمات API عند مقارنتها بأوامر NL. يتيح لك هذا تحقيق ثلاثة أهداف تصميم من خلال توفير: (1) قابلية التخصيص. يجب أن تكون قادرًا على تحديد المعلمات التي تستخدمها واجهة برمجة التطبيقات ومقدار بيانات التدريب التي يجب جمعها. (2) منخفضة التكلفة. إن خدمات عمال التعهيد الجماعي هي أرخص من خدمات المتخصصين المتخصصين ، وهذا هو السبب في أنه يجب توظيفهم. (3) جودة عالية. لا ينبغي تخفيض جودة بيانات التدريب.
عند تصميم هذا النهج ، تنشأ مشكلتان رئيسيتان. أولاً ، إن مكالمات واجهة برمجة التطبيقات ذات المعلمات المتقدمة ، كما هو الحال في الشكل 1 ، غير مفهومة للمستخدم العادي ، لذلك تحتاج إلى تحديد كيفية صياغة مشكلة التعليقات التوضيحية بحيث يمكن للموظفين التعهيد الجماعي بسهولة التعامل معها. نبدأ بتطوير تمثيل دلالية وسيط لواجهة برمجة تطبيقات الويب (انظر القسم 2.2) ، مما يسمح لنا بإنشاء مكالمات API بسلاسة بالمعلمات المطلوبة.
ثم نفكر في القواعد الخاصة بتحويل كل مكالمة API تلقائيًا إلى أمر NL أساسي ، والذي يمكن أن يكون مرهقًا إلى حد ما ، ولكنه سيكون واضحًا لموظف التعهيد الجماعي (انظر القسم 3.1). سيتعين على فناني الأداء فقط إعادة صياغة الفريق الأساسي لجعله يبدو أكثر طبيعية. يسمح لك هذا النهج بمنع العديد من الأخطاء في جمع بيانات التدريب ، نظرًا لأن مهمة إعادة الصياغة أبسط بكثير وأكثر قابلية للفهم بالنسبة لموظف التعهيد الجماعي.
ثانيًا ، تحتاج إلى فهم كيفية تحديد وتعليق مكالمات API فقط ذات القيمة الحقيقية لتعلم NL2API. يؤدي "الانفجار التجميعي" الذي ينشأ أثناء وضع المعلمات إلى حقيقة أن عدد المكالمات حتى لوحدة API واحدة يمكن أن يكون كبيرًا جدًا. ليس من المنطقي وضع تعليق على جميع المكالمات. نحن نقدم نموذجًا احتماليًا هرميًا جديدًا بشكل أساسي لتنفيذ عملية التعهيد الجماعي (انظر القسم 3.2). عن طريق القياس مع نمذجة اللغة لغرض الحصول على المعلومات ، نفترض أن أوامر NL يتم إنشاؤها بناءً على استدعاءات API المقابلة ، لذلك يجب استخدام نموذج اللغة لكل استدعاء API لتسجيل هذه العملية "التوليدية".
يعتمد نموذجنا على الطبيعة التركيبية لمكالمات API أو التمثيلات الرسمية للبنية الدلالية ككل. على مستوى بديهي ، إذا كانت مكالمة API تتكون من مكالمات أبسط (على سبيل المثال ، "رسائل البريد الإلكتروني غير المقروءة حول مرشح للحصول على درجة علمية" = "رسائل البريد الإلكتروني غير المقروءة" + "رسائل البريد الإلكتروني لمرشح للحصول على درجة علمية" ، يمكننا إنشاؤها نموذج اللغة من مكالمات واجهة برمجة التطبيقات البسيطة حتى بدون تعليق توضيحي ، لذلك ، من خلال التعليق على عدد صغير من مكالمات واجهة برمجة التطبيقات ، يمكننا حساب نموذج اللغة لأي شخص آخر.
بالطبع ، نماذج اللغة المحسوبة بعيدة عن المثالية ، وإلا كنا قد حللنا بالفعل مشكلة إنشاء NL2API. ومع ذلك ، فإن هذا الاستقراء لنموذج اللغة لمكالمات واجهة برمجة التطبيقات (API) غير المرخصة يمنحنا عرضًا شاملاً للمساحة الكاملة لمكالمات واجهة برمجة التطبيقات ، بالإضافة إلى تفاعل اللغة الطبيعية ومكالمات واجهة برمجة التطبيقات ، مما يسمح لنا بتحسين عملية التعهيد الجماعي. في القسم 3.3 ، قمنا بوصف خوارزمية للتعليق الانتقائي على مكالمات API للمساعدة في جعل مكالمات API أكثر تميزًا ، أي لضمان أقصى اختلاف بين نماذج لغتها.
نطبق إطار عملنا على اثنين من واجهات برمجة التطبيقات المنشورة من حزمة Microsoft Graph API2. نوضح أنه يمكن جمع بيانات تدريب عالية الجودة بأقل تكلفة إذا تم استخدام النهج المقترح 3. نظهر أيضًا أن نهجنا يحسن التعهيد الجماعي. بتكاليف مماثلة ، نجمع بيانات تدريب أفضل ، تتجاوز بشكل كبير خط الأساس. نتيجة لذلك ، توفر حلولنا NL2API دقة أعلى.
بشكل عام ، تشمل مساهمتنا الرئيسية ثلاثة جوانب:
- كنا من أول من درس مشاكل NL2API واقترح إطار عمل شامل لإنشاء NL2API من الصفر.
- لقد اقترحنا نهجًا فريدًا لجمع بيانات التدريب باستخدام التعهيد الجماعي ونموذج احتمالي هرمي جديد بشكل أساسي لتحسين هذه العملية.
- لقد طبقنا إطار عملنا على واجهات برمجة تطبيقات الويب الحقيقية وأثبتنا أنه يمكن إنشاء حل NL2API فعال بما فيه الكفاية من الصفر.
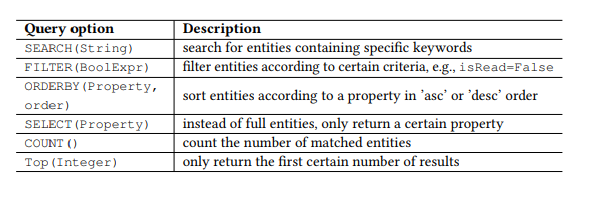 الجدول 1. معاملات الاستعلام OData.
الجدول 1. معاملات الاستعلام OData.الديباجة
RESTful API
في الآونة الأخيرة ، أصبحت واجهات برمجة تطبيقات الويب التي تتوافق مع النمط المعماري REST ، أي RESTful API ، أكثر شيوعًا بسبب بساطتها. تُستخدم واجهات برمجة التطبيقات RESTful أيضًا على الهواتف الذكية وأجهزة إنترنت الأشياء. تعمل واجهات برمجة التطبيقات المريحة مع الموارد التي يتم تناولها عبر معرفات الموارد المنتظمة (URIs) وتوفر إمكانية الوصول إلى هذه الموارد لمجموعة كبيرة من العملاء باستخدام أوامر HTTP بسيطة: GET و PUT و POST وما إلى ذلك. وسنعمل بشكل أساسي مع RESTful API ، ولكن يمكن استخدام الطرق الأساسية وواجهات برمجة التطبيقات الأخرى.
على سبيل المثال ، خذ بروتوكول Open Data Protocol (OData) الشهير لواجهة برمجة التطبيقات RESTful وواجهة برمجة التطبيقات للويب من حزمة Microsoft Graph API (الشكل 1) ، والتي يتم استخدامها ، على التوالي ، للبحث عن رسائل البريد الإلكتروني وأحداث تقويم المستخدم. الموارد الموجودة في OData هي كيانات ، يرتبط كل منها بقائمة خصائص. على سبيل المثال ، يحتوي كيان الرسائل - بريد إلكتروني - على خصائص مثل الموضوع (الموضوع) ، من (من) ، isRead (قراءة) ، و dateDateTime (تاريخ ووقت الاستلام) ، إلخ.
بالإضافة إلى ذلك ، تحدد OData مجموعة من معلمات الاستعلام ، مما يسمح لك بإجراء عمليات معالجة متقدمة على الموارد. على سبيل المثال ، تسمح لك المعلمة FILTER بالبحث عن رسائل البريد الإلكتروني من مرسل معين أو الرسائل المستلمة في تاريخ معين. يتم تقديم معلمات الطلب التي سنستخدمها في الجدول 1. نحن نسمي كل تركيبة من أمر HTTP والكيان (أو مجموعة الكيانات) كواجهة برمجة تطبيقات ، على سبيل المثال ، GET-Messages - للبحث عن رسائل البريد الإلكتروني. أي طلب ذي معلمات ، على سبيل المثال ، FILTER (isRead = False) ، يسمى معلمة ، واستدعاء API هو API يحتوي على قائمة من المعلمات.
NL2API
تتمثل المهمة الرئيسية لـ NLI في مقارنة عبارة (أمر بلغة طبيعية) مع تمثيل رسمي معين ، على سبيل المثال ، الأشكال المنطقية أو استعلامات SPARQL لقواعد المعرفة أو واجهات برمجة تطبيقات الويب في حالتنا. عندما يكون من الضروري التركيز على رسم الخرائط الدلالية دون تشتيت الانتباه بالتفاصيل غير ذات الصلة ، عادة ما يتم استخدام التمثيل الوسيط الوسطي حتى لا تعمل مباشرة مع الهدف. على سبيل المثال ، يتم استخدام القواعد الفئوية التوافقية على نطاق واسع في إنشاء NLIs لقواعد البيانات وقواعد المعرفة. إن اتباع نهج مماثل في التجريد مهم أيضًا بالنسبة لـ NL2API. يمكن للعديد من التفاصيل ، بما في ذلك اصطلاحات عناوين URL ورؤوس HTTP ورموز الاستجابة ، "تشتيت" NL2API من حل المشكلة الرئيسية - رسم الخرائط الدلالية.
لذلك ، نقوم بإنشاء عرض وسيط لواجهات برمجة التطبيقات RESTful (الشكل 2) مع اسم واجهة برمجة التطبيقات ؛ يعكس هذا العرض دلالات الإطار. يتكون إطار API من خمسة أجزاء. HTTP Verb (أمر HTTP) والموارد هي العناصر الأساسية لواجهة برمجة تطبيقات RESTful. يسمح لك نوع الإرجاع بإنشاء واجهات برمجة تطبيقات مركبة ، أي دمج مكالمات API متعددة لإجراء عملية أكثر تعقيدًا. غالبًا ما يتم استخدام المعلمات المطلوبة في مكالمات PUT أو POST في واجهة برمجة التطبيقات ، على سبيل المثال ، يعد عنوان ورأس ونص الرسالة معلمات مطلوبة لإرسال البريد الإلكتروني. غالبًا ما تكون المعلمات الاختيارية موجودة في مكالمات GET في واجهة برمجة التطبيقات ، فهي تساعد في تضييق طلب المعلومات.
إذا كانت المعلمات المطلوبة مفقودة ، فإننا نقوم بتسلسل إطار API ، على سبيل المثال: GET-Messages {FILTER (isRead = False) ، SEARCH ("PhD application") ، COUNT ()}. يمكن أن يكون إطار API حتمياً ويتم تحويله إلى مكالمة API حقيقية. أثناء عملية التحويل ، ستتم إضافة البيانات السياقية الضرورية ، بما في ذلك معرف المستخدم والموقع والتاريخ والوقت. في المثال الثاني (الشكل 1) ، سيتم استبدال القيمة الآن في معلمة FILTER بتاريخ ووقت تنفيذ الأمر المقابل أثناء تحويل إطار واجهة برمجة التطبيقات إلى مكالمة API حقيقية. علاوة على ذلك ، سيتم استخدام مفاهيم إطار API واستدعاء API بالتبادل.
 الشكل 2. إطار API. أعلاه: فريق اللغة الطبيعية. في المنتصف: Frame API. أسفل: مكالمة API.
الشكل 2. إطار API. أعلاه: فريق اللغة الطبيعية. في المنتصف: Frame API. أسفل: مكالمة API.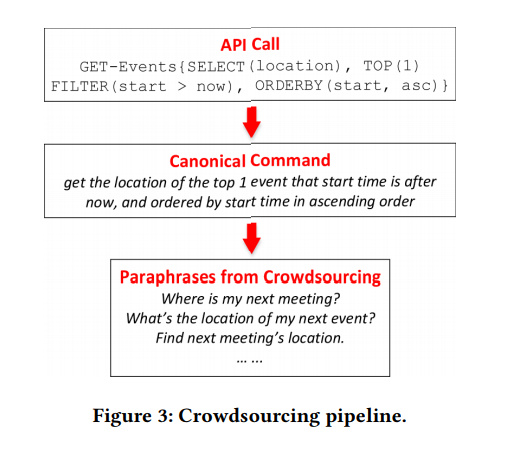 الشكل 3. الناقل التعهيد الجماعي.
الشكل 3. الناقل التعهيد الجماعي.جمع بيانات التدريب
يصف هذا القسم النهج الأساسي الجديد الذي نقدمه لجمع بيانات التدريب لحلول NL2API باستخدام التعهيد الجماعي. أولاً ، نقوم بإنشاء مكالمات API وتحويل كل منهم إلى فريق أساسي ، بالاعتماد على قواعد بسيطة (القسم 3.1) ، ثم نجذب عمال التعهيد الجماعي لإعادة صياغة الفرق الأساسية (الشكل 3). نظرًا للطبيعة التركيبية لمكالمات API ، فقد اقترحنا نموذج الاستعانة بمصادر خارجية الاحتمالية الهرمية (القسم 3.2) ، بالإضافة إلى خوارزمية لتحسين التعهيد الجماعي (القسم 3.3).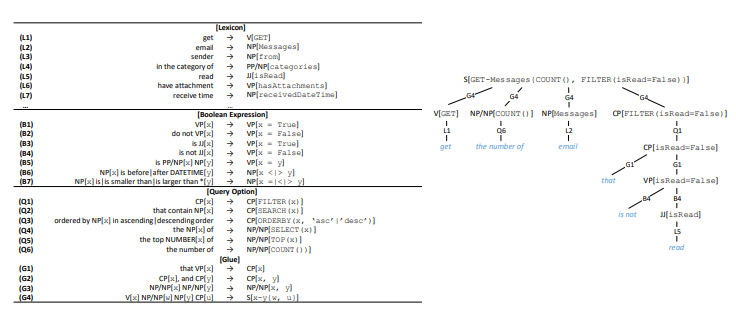 الشكل 4 الشكل 4. توليد الأوامر الكنسي. اليسار: المعجم والقواعد. اليمين: مثال على الاشتقاق.
الشكل 4 الشكل 4. توليد الأوامر الكنسي. اليسار: المعجم والقواعد. اليمين: مثال على الاشتقاق.استدعاء API والأمر الأساسي
API API. , , API, API . , Boolean, (True/False).
, Datetime, , today this_week receivedDateTime. , API (, ) API API.
, API . . , TOP, ORDERBY. , Boolean, isRead, ORDERBY . « » API API.
API. API . API API ( 4). ( HTTP, , ). , ⟨sender → NP[from]⟩ , from «sender», — (NP), .
(V), (VP), (JJ), - (CP), , (NP/NP), (PP/NP), (S) . .
, API , RESTful API OData — « » . 17 4 API, ( 5).
, API. ⟨t1, t2, ..., tn → c[z]⟩,
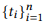
, z API, cz — . 4. API , S, G4, API . C , , - «that is not read».
, . , VP[x = False] B2, B4, x. x VP, B2 (, x is hasAttachments → «do not have attachment»); JJ, B4 (, x is isRead → «is not read»). («do not read» or «is not have attachment») .
يمكننا إنشاء عدد كبير من مكالمات API باستخدام النهج المذكور أعلاه ، ولكن التعليق عليها جميعًا باستخدام التعهيد الجماعي غير ممكن اقتصاديًا. لذلك ، نقترح نموذجًا احتماليًا هرميًا للتعهيد الجماعي يساعدك في تحديد مكالمات API التي يجب التعليق عليها. على حد علمنا ، هذا هو النموذج الاحتمالي الأول لاستخدام التعهيد الجماعي لإنشاء واجهات NLI ، مما يسمح لنا بحل المهمة الفريدة والمثيرة لنمذجة التفاعل بين تمثيلات اللغة الطبيعية والتمثيلات الهيكلية الدلالية. إن التمثيلات الرسمية للبنية الدلالية بشكل عام ومكالمات API بشكل خاص تكون تركيبية بطبيعتها. على سبيل المثال ، z12 = GET-Messages {COUNT () و FILTER (isRead = False)} يتكون من z1 = GET-Messages {FILTER (isRead = False)} و z2 = GET-Messages {COUNT ()} (هذه الأمثلة أكثر تفصيلاً مزيد من المناقشة).
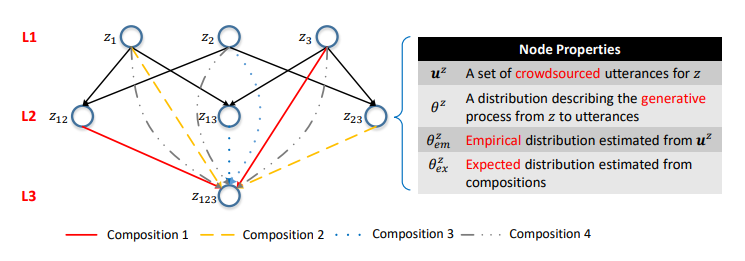 الشكل 5. الشبكة الدلالية. تتكون الطبقة ith من مكالمات API بمعلمات i. الأضلاع هي تركيبات. تميز توزيعات الاحتمال في القمم نماذج اللغة المقابلة.
الشكل 5. الشبكة الدلالية. تتكون الطبقة ith من مكالمات API بمعلمات i. الأضلاع هي تركيبات. تميز توزيعات الاحتمال في القمم نماذج اللغة المقابلة.كانت إحدى النتائج الرئيسية لدراستنا هي التأكيد على أنه يمكن استخدام هذا التكوين لنمذجة عملية التعهيد الجماعي.
أولاً ، نحدد التكوين بناءً على مجموعة من معلمات استدعاء API.
التعريف 3.1 (التكوين). خذ API ومجموعة من مكالمات API
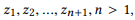
إذا حددنا r (z) كمجموعة من المعلمات لـ z ، عندها
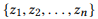
هو تكوين
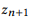
إذا وفقط إذا
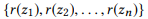
جزء
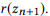
بناءً على العلاقات التركيبية لمكالمات API ، يمكنك تنظيم جميع مكالمات API في هيكل هرمي واحد. يتم تمثيل مكالمات API بنفس عدد المعلمات مثل رؤوس طبقة واحدة ، ويتم تمثيل التركيبات على أنها
الأضلاع الموجهة بين الطبقات. نحن نسمي هذا الهيكل شبكة بدائية (أو SeMesh).
قياسا على النهج القائم على نمذجة اللغة في استرجاع المعلومات ، نفترض أن العبارات المقابلة لمكالمة API z واحدة يتم إنشاؤها باستخدام عملية عشوائية تتميز بنموذج اللغة
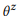
. من أجل التبسيط ، نركز على احتمالات الكلمات ، وبالتالي

أين
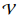
يدل على قاموس.
لأسباب ستصبح واضحة بعد ذلك بقليل ، بدلاً من نموذج unigram للغة القياسية ، نقترح استخدام مجموعة من توزيعات برنولي (حقيبة برنولي ، BoB). يقابل كل توزيع برنولي متغير عشوائي W ، يحدد ما إذا كانت الكلمة w تظهر في الجملة التي تم إنشاؤها على أساس z ، وتوزيع BoB هو مجموعة من توزيعات برنولي لجميع الكلمات

. سوف نستخدم
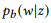
كتدوين قصير لـ
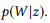
.
لنفترض أننا شكلنا مجموعة (متعددة) من العبارات

بالنسبة لـ z ،
يسمح لك الحد الأقصى لتقدير الاحتمال (MLE) لتوزيع BoB بتحديد العبارات التي تحتوي على w:
 مثال 2.
مثال 2. بخصوص استدعاء API أعلاه z1 ، افترض أننا حصلنا على عبارتين u1 = "العثور على رسائل بريد إلكتروني غير مقروءة" و u2 = "رسائل بريد إلكتروني غير مقروءة" ، ثم u = {u1، u2}. pb ("emails" | z) = 1.0 ، نظرًا لأن "رسائل البريد الإلكتروني" موجودة في العبارتين. وبالمثل ، pb ("unread" | z) = 0.5 و pb ("meeting" | z) = 0.0.
في الشبكة الدلالية ، هناك ثلاث عمليات أساسية على مستوى القمة:
الشروح والتخطيط والاستيفاء.
التعليق التوضيحي (للتعليق) يعني جمع البيانات
لإعادة صياغة الأمر القانوني للرأس z باستخدام التعهيد الجماعي وتقييم التوزيع التجريبي
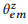
طريقة الاحتمالية القصوى.
يحاول COMPOSE (إنشاء) استنباط نموذج لغوي بناءً على التراكيب لحساب التوزيع المتوقع
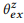
. كما نظهر تجريبيا ،
هو تكوين ل z. إذا انطلقنا من افتراض أن العبارات المقابلة تتميز بنفس الاتصال التركيبي ، فعندئذٍ
يجب وضعه على

:

حيث f هي دالة تركيبية. بالنسبة لتوزيع BoB ، ستبدو وظيفة التكوين كما يلي:
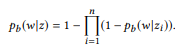
بمعنى آخر ، إذا كانت ui عبارة zi ، فإن u عبارة
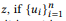
من الناحية التركيبية ، فإن الكلمة w لا تنتمي إليك. إذا وفقط إذا كان لا ينتمي إلى أي واجهة مستخدم. عندما تحتوي z على العديد من التراكيب ، يتم حساب xe x بشكل منفصل ثم يتم حساب متوسطها. لا يؤدي نموذج unigram للغة القياسية إلى وظيفة تركيبية طبيعية. في عملية تطبيع احتمالات الكلمات ، يتم تضمين طول الجمل ، والذي بدوره يأخذ في الاعتبار تعقيد مكالمات واجهة برمجة التطبيقات ، مما ينتهك التحلل في المعادلة (2). هذا هو السبب في أننا نقدم توزيع BoB.
مثال 3. لنفترض أننا قمنا بإعداد تعليق توضيحي لمكالمات API المذكورة سابقًا z1 و z2 ، ولكل منهما بيانان:
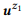
= {"البحث عن رسائل بريد إلكتروني غير مقروءة" و "رسائل بريد إلكتروني غير مقروءة"} و
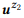
= {"كم عدد رسائل البريد الإلكتروني لدي" ، "ابحث عن عدد رسائل البريد الإلكتروني"}. قمنا بتقييم نماذج اللغة
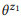
و
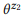
. تحاول عملية التكوين التقييم
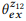
بدون سؤال
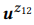
. على سبيل المثال ، بالنسبة لكلمة "emails" ، pb ("emails" | z1) = 1.0 و pb ("emails" | z2) = 1.0 ، لذلك يتبع من المعادلة (3) أن pb ("emails" | z12) = 1.0 ، أي أننا نعتقد أنه سيتم تضمين هذه الكلمة في أي بيان z12. وبالمثل ، pb ("find" | z1) = 0.5 و pb ("find" | z2) = 0.5 ، لذا pb ("find" | z12) = 0.75. تتمتع الكلمة بفرصة جيدة لتوليدها من أي z1 أو z2 ، لذا يجب أن تكون احتمالية z12 أعلى.
بالطبع ، لا يتم دمج العبارات دائمًا بشكل تأليف. على سبيل المثال ، يمكن نقل العديد من العناصر في التمثيل الرسمي للبنية الدلالية في كلمة واحدة أو عبارة واحدة في لغة طبيعية ، وتسمى هذه الظاهرة التركيب الفرعي. يظهر مثال واحد في الشكل 3 ، حيث يتم تمثيل المعلمات الثلاث - TOP (1) و FILTER (start> now) و ORDERBY (start، asc) - بالكلمة المفردة "next". ومع ذلك ، من المستحيل الحصول على مثل هذه المعلومات دون التعليق على مكالمة API ، لذا فإن المشكلة نفسها تشبه مشكلة الدجاج والبيض. في حالة عدم وجود مثل هذه المعلومات ، فمن المعقول الالتزام بالافتراض الافتراضي أن العبارات تتميز بنفس العلاقة التركيبية مثل مكالمات API.
هذا افتراض معقول. تجدر الإشارة إلى أن هذا الافتراض يستخدم فقط لنمذجة عملية التعهيد الجماعي بهدف جمع البيانات. في مرحلة الاختبار ، قد لا تتوافق بيانات المستخدمين الحقيقيين مع هذا الافتراض. ستكون واجهة اللغة الطبيعية قادرة على التعامل مع مثل هذه المواقف غير التركيبية إذا كانت مغطاة ببيانات التدريب المجمعة.
يدمج
INTERPOLATE (interpolation) جميع المعلومات المتاحة حول z ، أي الكلمات المشروحة z والمعلومات التي يتم الحصول عليها من المؤلفات ، ويحصل على تقدير أكثر دقة
عن طريق الاستيفاء
و
.
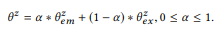
تتحكم معلمة التوازن α في المفاضلات بين التعليقات التوضيحية
القمم الحالية التي تكون دقيقة ولكنها كافية ، وقد لا تكون المعلومات التي يتم الحصول عليها من التراكيب المستندة إلى افتراض التكوين دقيقة ، ولكنها توفر تغطية أوسع. بمعنى ما ،
يخدم نفس الغرض كمضاد للتعرج في نمذجة اللغة ، مما يسمح بتقدير أفضل لتوزيع الاحتمالية مع بيانات غير كافية (التعليقات التوضيحية). أكثر من
كلما زاد الوزن
. بالنسبة لرأس الجذر الذي لا يحتوي على تركيبة ،
=
. لأعلى غير المشروح
=
.
بعد ذلك ، نصف خوارزمية تحديث الشبكة الدلالية ، أي الحسابات
لجميع z (الخوارزمية 1) ، حتى لو تم وضع جزء صغير فقط من القمم في التعليق التوضيحي. نفترض أن القيمة
تم تحديثه بالفعل لجميع المواقع ذات التعليقات التوضيحية. نزولاً من أعلى إلى أسفل ، نحسب بالتتابع
و
لكل قمة ض. أولاً ، تحتاج إلى تحديث الطبقات العليا حتى تتمكن من حساب التوزيع المتوقع للقمم في المستوى الأدنى. قمنا بتدوين جميع رؤوس الجذر ، حتى نتمكن من الحساب
لجميع القمم.
الخوارزمية 1. تحديث توزيعات عقدة الشبكة الدلالية
3.3 تحسين التعهيد الجماعي
تشكل الشبكة الدلالية نظرة شاملة للمساحة الكاملة لمكالمات API ، بالإضافة إلى تفاعل البيانات والمكالمات. استنادًا إلى هذا العرض ، يمكننا التعليق بشكل انتقائي فقط على مجموعة فرعية من مكالمات API عالية القيمة. في هذا القسم ، نصف إستراتيجية التوزيع التفاضلي الخاصة بنا لتحسين التعهيد الجماعي.
ضع في اعتبارك شبكة دلالية تحتوي على العديد من القمم Z. مهمتنا هي تحديد مجموعة فرعية من القمم في العملية التكرارية
ليتم التعليق عليها من قبل عمال التعهيد الجماعي. القمم المشروحة سابقًا ستسمى دولة الولاية ،
ثم نحتاج إلى إيجاد سياسة سياسة

لتقييم كل قمة غير ملحوظة بناءً على الحالة الحالية.
قبل الخوض في مناقشة أساليب حساب السياسات الفعالة ، لنفترض أن لدينا بالفعل واحدًا وقدم وصفًا عالي المستوى لخوارزمية التعهيد الجماعي (خوارزمية 2) لوصف الأساليب المصاحبة. وبشكل أكثر تحديدًا ، نقوم أولاً بتوضيح جميع رؤوس الجذر لتقييم توزيع جميع القمم في Z (السطر 3). في كل تكرار ، نقوم بتحديث توزيع القمة (السطر 5) ، احسب
سياسة تستند إلى الحالة الحالية للشبكة الدلالية (السطر 6) ، حدد قمة غير مصحوبة بحد أقصى للتقييم (السطر 7) ، وقم بتعليق الرأس والنتيجة في الحالة الجديدة (السطر 8). من الناحية العملية ، يمكنك إضافة تعليق توضيحي لعدة رؤوس كجزء من التكرار لزيادة الكفاءة.
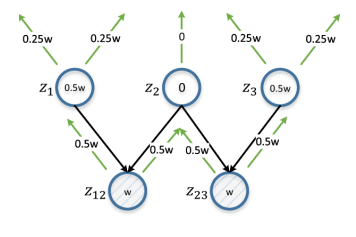 الشكل 6. التوزيع التفاضلي. يمثل z12 و z23 زوج الذروات قيد الدراسة. w هو تقدير محسوب على أساس d (z12، z23) ، وينتشر بشكل متكرر من الأسفل إلى الأعلى ، ويتضاعف في كل تكرار. سيكون تقدير القمة هو الفرق المطلق بين تقديراتها من z12 و z23 (وبالتالي التفاضلية). تحصل z2 على درجة 0 لأنها الكيان الأصلي الشائع لـ z12 و z23 ؛ سيكون التعليق التوضيحي في هذه الحالة قليل الفائدة من حيث ضمان التمييز بين z12 و z23.
الشكل 6. التوزيع التفاضلي. يمثل z12 و z23 زوج الذروات قيد الدراسة. w هو تقدير محسوب على أساس d (z12، z23) ، وينتشر بشكل متكرر من الأسفل إلى الأعلى ، ويتضاعف في كل تكرار. سيكون تقدير القمة هو الفرق المطلق بين تقديراتها من z12 و z23 (وبالتالي التفاضلية). تحصل z2 على درجة 0 لأنها الكيان الأصلي الشائع لـ z12 و z23 ؛ سيكون التعليق التوضيحي في هذه الحالة قليل الفائدة من حيث ضمان التمييز بين z12 و z23.بشكل عام ، يمكن أن تُعزى المهام التي نحلها إلى مشكلة التعلم النشط ، وضعنا لأنفسنا هدف تحديد مجموعة فرعية من الأمثلة للتعليق التوضيحي من أجل الحصول على مجموعة تدريب يمكنها تحسين نتائج التعلم. ومع ذلك ، لا تسمح العديد من الاختلافات الرئيسية بالتطبيق المباشر لطرق التدريس الكلاسيكية النشطة ، مثل "عدم اليقين في أخذ العينات". عادة ، في عملية التعلم النشط ، يحاول الطالب ، الذي سيكون في حالتنا واجهة NLI ، دراسة رسم الخرائط f: X → Y ، حيث X هي عينة مساحة الإدخال ، تتكون من مجموعة صغيرة من العينات المميزة وعدد كبير من العينات غير المميزة ، وعادة ما تكون Y مجموعة من العلامات الطبقة.
يقوم الطالب بتقييم القيمة الإعلامية للأمثلة غير المصنفة واختيار الأكثر إفادة للحصول على علامة ص من عمال التعهيد الجماعي. ولكن في إطار المشكلة التي نحلها ، يتم طرح مشكلة التعليقات التوضيحية بشكل مختلف. نحن بحاجة إلى تحديد مثيل من Y ، مساحة اتصال كبيرة لواجهة برمجة التطبيقات ، ونطلب من العاملين في التعهيد الجماعي تسمية ذلك بتحديد الأنماط في X ، مساحة الجملة. بالإضافة إلى ذلك ، نحن لسنا مرتبطين بمتدرب معين. وبالتالي ، نقترح حل جديد للمشكلة المطروحة. نستمد الإلهام من مصادر عديدة حول التعلم النشط.
أولاً ، نحدد الهدف ، والذي سيتم على أساسه تقييم محتوى المعلومات للعقد. من الواضح أننا نريد تمييز مكالمات API مختلفة. في الشبكة الدلالية ، هذا يعني أن التوزيع
القمم المختلفة لها اختلافات واضحة. بادئ ذي بدء ، نقدم كل توزيع
مثل متجه n- الأبعاد

حيث ن = |
| - حجم القاموس. بمقياس معين لمسافة المتجه d (في تجاربنا نستخدم المسافة بين المتجهات pL1) نعني

، أي أن المسافة بين الذروتين تساوي المسافة بين توزيعاتهم.
الهدف الواضح هو زيادة المسافة الإجمالية بين جميع أزواج القمم. ومع ذلك ، قد يكون تحسين جميع المسافات الزوجية معقدًا جدًا للحسابات ، وحتى هذا ليس ضروريًا. زوج من القمم البعيدة له بالفعل اختلافات كافية ، لذلك لا معنى لزيادة أخرى في المسافة. بدلاً من ذلك ، يمكننا التركيز على أزواج القمم التي تسبب أكبر قدر من الارتباك ، أي أن المسافة بينهما هي الأصغر.
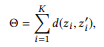
أين
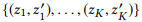
يشير إلى أزواج K الأولى من القمم إذا قمنا بترتيب جميع أزواج العقد حسب المسافة بترتيب تصاعدي.
الخوارزمية 2. علق بشكل متكرر شبكة دلالية مع سياسة الخوارزمية 3. حساب السياسة على أساس الانتشار التفاضلي
الخوارزمية 3. حساب السياسة على أساس الانتشار التفاضلي الخوارزمية 4. نشر النقاط بشكل متكرر من عقدة مصدر إلى كافة العقد الأصل الخاصة بها
الخوارزمية 4. نشر النقاط بشكل متكرر من عقدة مصدر إلى كافة العقد الأصل الخاصة بها
من المحتمل أن تؤدي القمم ذات المحتوى المعلوماتي الأعلى بعد التعليق التوضيحي إلى زيادة قيمة Θ. من أجل القياس الكمي في هذه الحالة ، نقترح استخدام استراتيجية توزيع تفاضلي. إذا كانت المسافة بين زوج من القمم صغيرة ، فإننا نفحص جميع القمم الأصلية: إذا كانت القمة الرئيسية شائعة لزوج من القمم ، فيجب أن تحصل على تصنيف منخفض ، لأن التعليق التوضيحي سيؤدي إلى تغييرات مماثلة لكل من القمم.
خلاف ذلك ، يجب أن يكون رأس القمة عالي التصنيف ، وكلما اقترب الزوج من القمم ، زاد التصنيف. على سبيل المثال ، إذا كانت المسافة بين رؤوس "رسائل البريد الإلكتروني غير المقروءة حول تطبيق PhD" و "عدد رسائل البريد الإلكتروني المتعلقة بتطبيق PhD" صغيرة ، فإن التعليق التوضيحي لرأسها الرئيسي "رسائل البريد الإلكتروني حول تطبيق PhD" لا معنى له من وجهة نظر تمييز هذه القمم. من المستحسن أكثر إضافة تعليق على العقد الأصلية التي لن تكون شائعة بالنسبة لهم: "رسائل البريد الإلكتروني غير المقروءة" و "عدد رسائل البريد الإلكتروني".
يظهر مثال لمثل هذا الموقف في الشكل 6 ، والخوارزمية الخاصة به هي الخوارزمية 3. كتقدير ، نأخذ المتبادل لمسافة العقدة التي يحدها ثابت (الخط 6) ، لذلك يكون لأقرب أزواج القمم التأثير الأكبر. عند العمل مع زوج من القمم ، نقوم في نفس الوقت بتعيين تقييم لكل قمة لجميع القمم الرئيسية (السطر 9 و 10 والخوارزمية 4). تقدير قمة غير ملحوظة هو الفرق المطلق في تقديرات الزوج المقابل من القمم مع الجمع على جميع أزواج القمم (السطر 12).
واجهة اللغة الطبيعية
لتقييم الإطار المقترح ، من الضروري تدريب نماذج NL2API باستخدام البيانات التي تم جمعها. في الوقت الحالي ، لا يتوفر نموذج NL2API النهائي ، ولكننا نقوم بتكييف نموذجين NLI تم اختبارهما من مناطق أخرى لتطبيقهما على API.
نموذج استخراج نموذج اللغة
استنادًا إلى التطورات الأخيرة في مجال NLI لقواعد المعرفة ، يمكننا التفكير في إنشاء NL2API في سياق مشكلة استخراج المعلومات من أجل تكييف نموذج الاستخراج استنادًا إلى نموذج اللغة (LM) لظروفنا.
لقول u ، تحتاج إلى العثور على مكالمة API z في الشبكة الدلالية بأفضل تطابق لـ u. أولاً نقوم بتحويل توزيع BoB

كل استدعاء لـ API z إلى نموذج unigram للغة:
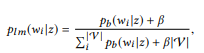
حيث نستخدم التجانس الإضافي ، و 0 ≤ β ≤ 1 هي معلمة التنعيم. قيمة أعلى
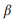
، زاد وزن الكلمات التي لم يتم تحليلها بعد. يمكن تصنيف مكالمات API حسب الاحتمالية اللوغاريتمية:
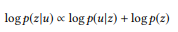
(تخضع لتوزيع احتمالي مسبق)
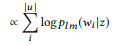
يتم استخدام مكالمة API الأعلى تقييمًا كنتيجة محاكاة.
Seq2Seq إعادة صياغة الوحدة النمطية
أصبحت الشبكات العصبية أكثر انتشارًا كنماذج لـ NLI ، في حين أن نموذج Seq2Seq أفضل من الآخرين لهذا الغرض ، لأنه يسمح لك بمعالجة تسلسل المدخلات والمخرجات ذات الأطوال المتغيرة بشكل طبيعي. نقوم بتكييف هذا النموذج مع NL2API.
لتسلسل الإدخال ه

، يقدّر النموذج التوزيع الاحتمالي الشرطي p (y | x) لجميع تتابعات الإخراج الممكنة
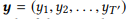
. يمكن أن تختلف أطوال T و T and وتأخذ أي قيمة. في NL2API ، x هو بيان الإخراج. يمكن أن تكون y مكالمة API متسلسلة أو أمرها الأساسي. سنستخدم الأوامر الأساسية كتسلسلات إخراج الهدف ، والتي تحول في الواقع مشكلتنا إلى مشكلة إعادة صياغة.
المشفر الذي يتم تنفيذه كشبكة عصبية متكررة (RNN) مع وحدات التكرار الخاضعة للرقابة (GRU) يمثل أولاً x كمتجه ذي حجم ثابت ،

حيث RN N هو تمثيل موجز لتطبيق GRU على تسلسل الإدخال بأكمله ، علامة بعلامة ، متبوعًا بإخراج آخر حالة مخفية.
يأخذ مفكك التشفير ، وهو أيضًا RNN مع GRU ، h0 كحالة أولية ويعالج تسلسل الإخراج y ، علامة بعلامة ، لتوليد تسلسل من الحالات ،

تأخذ طبقة الإخراج كل حالة لفك الشفرة كقيمة إدخال وتولد توزيع القاموس
كقيمة الإخراج. نحن نستخدم فقط تحويل التابعين متبوعًا بالوظيفة اللوجيستية متعددة المتغيرات softmax:
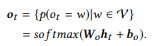
الاحتمال الشرطي النهائي ، الذي يسمح لنا بتقييم مدى جودة الأمر الأساسي y يعيد صياغة بيان الإدخال x ، هو

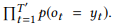
. يتم تصنيف مكالمات API بعد ذلك حسب الاحتمال الشرطي لأمرها الأساسي. نوصي بأن تتعرف على المصدر ، حيث يتم وصف عملية التعلم النموذجية بمزيد من التفصيل.
التجارب
من الناحية التجريبية ، ندرس مواضيع البحث التالية: [PI1]: هل يمكننا استخدام الإطار المقترح لجمع بيانات تدريب عالية الجودة بسعر معقول؟ [PI2]: هل توفر الشبكة الدلالية تقييمًا أكثر دقة لنماذج اللغة من تقييم الاحتمالية القصوى؟ [PI3]: هل تعمل استراتيجية التوزيع التفاضلي على تحسين كفاءة التعهيد الجماعي؟
التعهيد الجماعي
-API Microsoft — GET-Events GET-Messages — . API, API ( 3.1) . API 2. , Amazon Mechanical Turk. , API .
. API 10 , 10 . 201 , . 44 , 82 , 8,2 , , , . , 400 , 17,4 %.
(, ORDERBY a COUNT parameter) (, , ). . NLI. , , [1] . .
, , , , API (. 3). API . , . 61 API 157 GET-Messages, 77 API 190 GET-Events. , , API (, ) , , .
 2. API.
2. API. 3. : ().
3. : ()., , . , α = 0,3, LM β = 0,001. K, , 100 000. , , Seq2Seq — 500. ( ).
NLI, . .
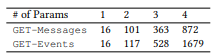
. , , . LM: , . , . ROOT — . TOP2 = ROOT + 2; TOP3 = TOP2 + 3. .
4. LM (MLE) ,
, . , , , MLE .
MLE,

,

- , . API . 16 API (ROOT) LM SeMesh Seq2Seq API (TOP2) , 500 API (TOP3).
, , , , ( 3.2) . , GET-Events , GET-Messages. , GET-Events
, , , .
 4. . LM, Seq2Seq, . , .
4. . LM, Seq2Seq, . , .LM + , ,
θem with
.
و
, , ROOT,
و
. , , . MLE. , , [2] .
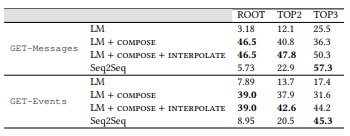
0,45 0,6: , NLI . , API. API (. 7) , RNN , . .
. : |u | α. - LM ( 7). , |u | < 10, 10 . GET-Events, GET-Messages .
, , , . , , . , α, ([0.1, 0.7]). α , , .
(DP) . API . 50 API, , NL2API .
, . LM, . . , ( 5.1), API .
7. .
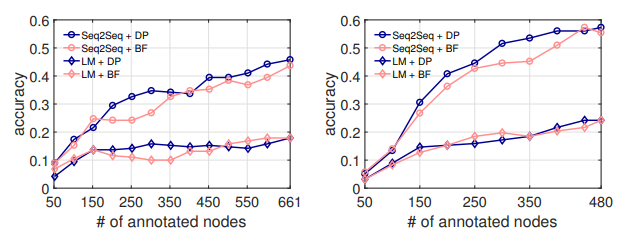
8. . : GET-Events. : GET-Messages
breadth first (BF), . . . API , API .
8. NL2API API DP . 300 API, Seq2Seq, DP 7 % API. , . , DP API, NL2API. , , [3] .
- . - (NLI) . NLI . , , . .
NLI , -, API . NL2API : API , - , . . API REST .
NLI. NLI « ». , Google Suggest API, API IFTTT. NLI, . , .
NLI, . NLI , . , , .
API . , -API. .
-API. , -API. , -API API, -API . NL2API , , API.
- -API (NL2API) NL2API . NL2API . : (1) . , , ? (2) .
? (3) NL2API. , API. (4) API. API? (5) : NL2API ?