مرحبًا اسمي دينيس كيريانوف ، أعمل في Sberbank وأتعامل مع مشاكل معالجة اللغة الطبيعية (NLP). بمجرد أن نحتاج إلى اختيار محلل نحوي للعمل مع اللغة الروسية. للقيام بذلك ، بحثنا في براري علم التشكل والتشفير ، واختبرنا خيارات مختلفة وقيمنا تطبيقها. نشارك تجربتنا في هذا المنشور.

التحضير للاختيار
لنبدأ بالأساسيات: كيف يعمل؟ نأخذ النص ، ونجري الترميز ونحصل على مجموعة من الرموز الزائفة. تتناسب مراحل التحليل الإضافي مع الهرم:
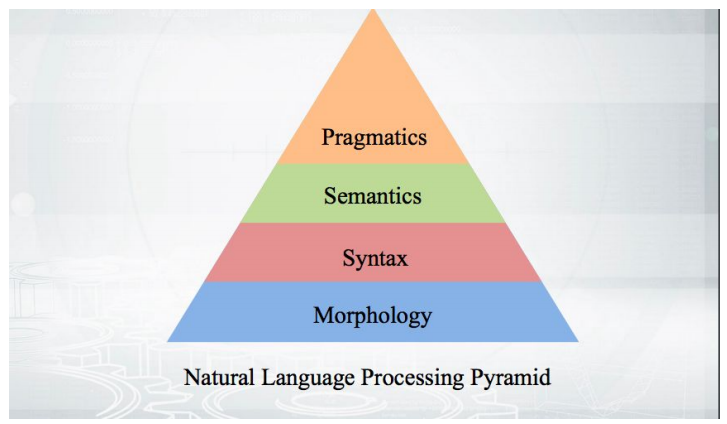
يبدأ كل شيء بالتشكيل - مع تحليل شكل الكلمة وفئاتها النحوية (الجنس ، الحالة ، إلخ). يعتمد علم التشكل على بناء الجملة - العلاقات خارج حدود كلمة واحدة ، بين الكلمات. المحللون النحويون الذين سيتم مناقشتهم وتحليل النص وإعطاء هيكل تبعيات الكلمات من بعضها البعض.
قواعد التبعيات وقواعد المكونات الفورية
هناك نهجان رئيسيان للتحليل ، والتي توجد في النظرية اللغوية على قدم المساواة.

في السطر الأول ، يتم تحليل الجملة كجزء من قواعد التبعية. يتم تدريس هذا النهج في المدرسة. كل كلمة في الجملة مرتبطة بطريقة أو بأخرى. "الصابون" - المسند الذي يعتمد عليه موضوع "الأم" (هنا تختلف قواعد التبعية عن المدرسة ، حيث يعتمد المسند على الموضوع). الموضوع له تعريف تابع لـ "خاصتي". المسند له "إطار" مكمل مباشر تابع. والإضافة المباشرة إلى "الإطار" - تعريف "القذرة".
في السطر الثاني ، يكون التحليل وفقًا لقواعد المكونات نفسها.
وفقا لها ، يتم تقسيم الجملة إلى مجموعات من الكلمات (العبارات). ترتبط الكلمات داخل مجموعة واحدة ارتباطًا وثيقًا. ترتبط الكلمتان "my" و "mother" ارتباطًا وثيقًا و "frame" و "dirty" أيضًا. ولا يزال هناك "صابون" منفصل.
النهج الثاني للتحليل التلقائي للغة الروسية قابل للتطبيق بشكل سيئ ، لأنه في كثير من الأحيان لا ترتبط الكلمات ذات الصلة الوثيقة (أعضاء من نفس المجموعة) في صف واحد. سيتعين علينا دمجها بأقواس غريبة - بكلمة واحدة أو كلمتين. لذلك ، في التحليل التلقائي للغة الروسية ، من المعتاد العمل بناءً على قواعد التبعيات. هذا أمر مريح أيضًا لأن الجميع على دراية بمثل هذا "الإطار" في المدرسة.
شجرة التبعية
يمكننا ترجمة مجموعة من التبعيات إلى هيكل شجرة. القمة هي كلمة "صابون" ، وتعتمد عليها بعض الكلمات بشكل مباشر ، وبعضها يعتمد على مدمنيها. فيما يلي
تعريف لشجرة التبعية من كتاب Martin و Zhurafsky:
شجرة التبعية هي رسم بياني موجه يفي بالقيود التالية:- توجد عقدة جذر واحدة محددة لا تحتوي على أقواس واردة.
- باستثناء العقدة الجذرية ، يكون لكل قمة قوس وارد واحد بالضبط.
- هناك مسار فريد من العقدة الجذرية إلى كل قمة في V.
هناك عقدة عالية المستوى - مسند. من خلالها يمكنك الوصول إلى أي كلمة. تعتمد كل كلمة على كلمة أخرى ، ولكن على كلمة واحدة فقط. تبدو شجرة التبعية على النحو التالي:

في هذه الشجرة ، يتم توقيع الحواف مع نوع خاص من العلاقات النحوية. في قواعد التبعيات ، لا يتم فقط تحليل حقيقة العلاقة بين الكلمات ، ولكن أيضًا طبيعة هذا الارتباط. على سبيل المثال ، "مأخوذ" هو شكل فعل واحد تقريبًا ، "الجرد" هو موضوع "مأخوذ". وبناءً على ذلك ، لدينا حافة "is" في اتجاه واحد والآخر. هذه ليست نفس الروابط ؛ فهي ذات طبيعة مختلفة ، لذلك يجب تمييزها.
فيما يلي ، نعتبر الحالات البسيطة التي يكون فيها أعضاء الجملة حاضرين ، وليس ضمنيًا. هناك هياكل وعلامات للتعامل مع التصاريح. يظهر شيء في الشجرة ليس له تعبير سطحي - كلمة. لكن هذا موضوع دراسة أخرى ، لكننا ما زلنا بحاجة إلى التركيز على دراستنا.
مشروع التبعيات العالمية
لتسهيل اختيارنا للمحلل ، وجهنا انتباهنا إلى مشروع
التبعيات العالمية ومسابقة CoNLL Shared Task ، التي تم عقدها مؤخرًا في إطارها.
التبعيات العالمية هي مشروع لتوحيد ترميز الجثث النحوية (القبائل) في إطار قواعد التبعية. في روسيا ، عدد أنواع الروابط النحوية محدود - الموضوع ، المسند ، إلخ. في اللغة الإنجليزية نفس الشيء ، ولكن المجموعة مختلفة بالفعل. على سبيل المثال ، تظهر مقالة هناك تحتاج أيضًا إلى تصنيفها بطريقة أو بأخرى. إذا أردنا كتابة محلل سحري يمكنه التعامل مع جميع اللغات ، فسنواجه بسرعة مشاكل في مقارنة القواعد النحوية المختلفة. تمكن المبدعون البطوليون من التبعيات العالمية من الاتفاق فيما بينهم وتحديد جميع المباني التي كانت تحت تصرفهم بتنسيق واحد. ليس من المهم للغاية كيف اتفقوا ، فالشيء الرئيسي هو أنه عند الإخراج حصلنا على شكل موحد معين لتقديم هذه القصة بأكملها -
أكثر من 100 فرقة ل 60 لغة .
إن مهمة CoNLL المشتركة هي منافسة بين مطوري خوارزميات التحليل ، والتي يتم عقدها كجزء من مشروع التبعيات العالمية. يأخذ المنظمون عددًا معينًا من القبائل ويقسم كل منهم إلى ثلاثة أجزاء - التدريب والتحقق والاختبار. يتم تقديم الجزء الأول للمشاركين في المسابقة لتدريب نماذجهم عليها. يستخدم الجزء الثاني أيضًا من قبل المشاركين لتقييم تشغيل الخوارزمية بعد التدريب. يمكن للمشاركين تكرار التدريب والتقييم بشكل متكرر. ثم يقدمون أفضل خوارزمية للمنظمين ، الذين يقومون بتشغيلها على جزء الاختبار ، مغلقة أمام المشاركين. نتائج النماذج على أجزاء الاختبار من القبائل هي نتائج المسابقة.
مقاييس الجودة
لدينا روابط بين الكلمات وأنواعها. يمكننا تقييم ما إذا تم العثور على أعلى الكلمة بشكل صحيح - مقياس UAS (نقاط المرفقات غير المصنفة). أو لتقييم ما إذا تم العثور على كل من الرأس ونوع التبعية بشكل صحيح - مقياس LAS (نقاط المرفق المسمى).

يبدو أن تقييم الدقة يطرح نفسه هنا - فنحن ننظر في عدد المرات التي حصلنا عليها من العدد الإجمالي للحالات. إذا كان لدينا 5 كلمات ولأربع كلمات حددنا الجزء العلوي بشكل صحيح ، نحصل على 80٪.
لكن تقييم المحلل في شكله النقي هو في الواقع إشكالية. غالبًا ما يأخذ المطورون الذين يحلون مشاكل التحليل التلقائي النص الخام كمدخل ، والذي ، وفقًا لهرم التحليل ، يمر عبر مراحل الترميز والتحليل الصرفي. يمكن أن تؤثر أخطاء هذه الخطوات السابقة على جودة المحلل اللغوي. على وجه الخصوص ، ينطبق هذا على إجراء الترميز - تخصيص الكلمات. إذا حددنا كلمات الوحدة الخاطئة ، فلن نتمكن بعد ذلك من تقييم الاتصالات النحوية بينهما بشكل صحيح - بعد كل شيء ، في السلك الأصلي المسمى كانت الوحدات مختلفة.
لذلك ، فإن صيغة التقييم في هذه الحالة هي المقياس f ، حيث الدقة هي حصة النتائج الدقيقة بالنسبة إلى العدد الإجمالي للتنبؤات ، والاكتمال هو حصة النتائج الدقيقة بالنسبة إلى عدد الروابط في البيانات المرمزة.
عندما نقدم تقديرات في المستقبل ، يجب أن نتذكر أن المقاييس المستخدمة لا تؤثر فقط على البنية ، ولكن أيضًا على جودة الرمز المميز.
اللغة الروسية في التبعيات العالمية
لكي يتمكن المحلل اللغوي من تمييز الجمل التي لم يراها بشكل نحوي ، فإنه يحتاج إلى إطعام الجسم المحدد للتدريب. بالنسبة للغة الروسية ، هناك العديد من هذه الحالات:

يشير العمود الثاني إلى عدد الرموز المميزة - الكلمات. كلما زاد عدد الرموز ، كلما كان فيلق التدريب وأفضل الخوارزمية النهائية (إذا كانت هذه بيانات جيدة). من الواضح أن جميع التجارب تجرى على SynTagRus (تم تطويره بواسطة IPPI RAS) ، حيث يوجد أكثر من مليون توكينز. سيتم تدريب جميع الخوارزميات على ذلك ، والذي سيتم مناقشته لاحقًا.
المحللون للغة الروسية في المهام المشتركة لـ CoNLL
وفقًا لنتائج
مسابقة العام الماضي ، حققت النماذج التي تم تدريبها على نفس SynTagRus مؤشرات LAS التالية:

نتائج المحللون للغة الروسية مثيرة للإعجاب - فهي أفضل من نتائج المحللين للغات الإنجليزية والفرنسية وغيرها من اللغات النادرة. كنا محظوظين للغاية لسببين في آن واحد. أولاً ، تقوم الخوارزميات بعمل جيد مع اللغة الروسية. ثانيًا ، لدينا SynTagRus - وهو مسكن كبير وملحوظ.
بالمناسبة ، لقد مرت مسابقة 2018 بالفعل ، لكننا أجرينا بحثنا في ربيع هذا العام ، لذلك نعتمد على نتائج مسار العام الماضي. بالنظر إلى المستقبل ، نلاحظ أن
الإصدار الجديد من UDPipe (المستقبل) تبين أنه أعلى هذا العام.
Syntaxnet ، محلل Google ، غير موجود في القائمة. ما خطبه؟ الجواب بسيط: بدأ بناء الجملة فقط بمرحلة التحليل الصرفي. لقد أخذ رمزًا مثاليًا جاهزًا ، وبنى بالفعل معالجة فوقه. لذلك ، من غير العدل تقييمه على قدم المساواة مع الباقي - قام الباقي بالانقسام إلى رموز مميزة مع خوارزمياتهم الخاصة ، وهذا يمكن أن يؤدي إلى تفاقم النتائج في المرحلة التالية من البنية. عينة Syntaxnet لعام 2017 لها نتيجة أفضل من القائمة بأكملها أعلاه ، لكن المقارنات المباشرة ليست عادلة.
حصلت الطاولة على نسختين من UDPipe ، في 12 و 15 مكانًا. يقوم نفس الأشخاص الذين شاركوا بنشاط في مشروع التبعيات العالمية بتطوير هذا المحلل اللغوي.
تظهر تحديثات UDPipe بشكل دوري (بشكل أقل في كثير من الأحيان ، بالمناسبة ، يتم تحديث تخطيط الحالات). لذا ، بعد المنافسة في العام الماضي ، تم تحديث UDPipe (كانت هذه التزامًا بالإصدار 2.0 لم يتم إصداره بعد ؛ في المستقبل ، من أجل البساطة ، سنشير تقريبًا إلى التزام UDPipe 2.0 الذي اتخذناه ، على الرغم من أن هذا ليس صحيحًا) ؛ بالطبع ، لا توجد مثل هذه التحديثات في جدول المسابقة. نتيجة "التزامنا" هي تقريبًا في المركز السابع.
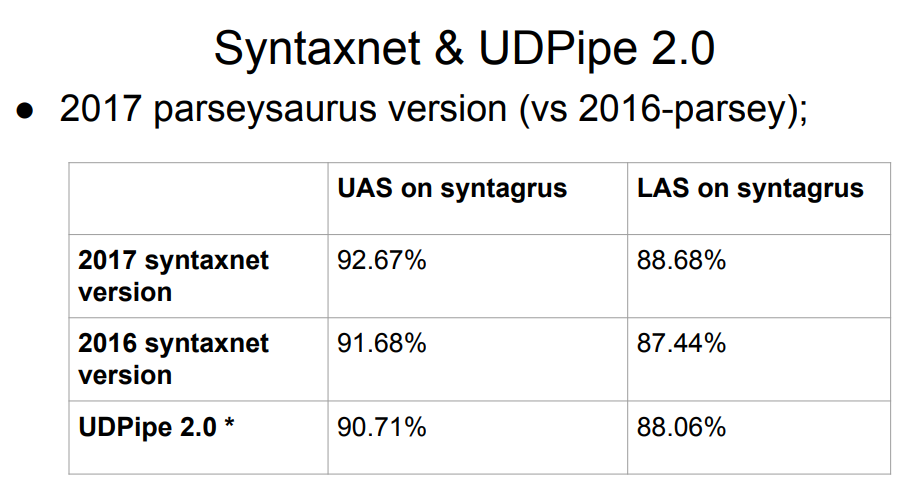
لذا ، نحتاج إلى اختيار محلل للغة الروسية. كبيانات أولية ، لدينا اللوحة أعلاه مع Syntaxnet الرائد و UDPipe 2.0 في مكان ما في المركز السابع.
اختر الموديل
نجعل الأمر بسيطًا: نبدأ مع المحلل اللغوي بأعلى المعدلات. إذا كان هناك شيء خاطئ معه ، فانتقل إلى الأسفل. قد لا يكون هناك شيء صحيح وفقًا للمعايير التالية - ربما ليست مثالية ، لكنهم توصلوا إلينا:
- سرعة العمل . يجب أن يعمل المحلل لدينا بسرعة كافية. بناء الجملة ، بالطبع ، بعيد عن الوحدة الوحيدة "تحت غطاء المحرك" لنظام الوقت الحقيقي ، لذلك لا يجب أن تنفق أكثر من اثني عشر مللي ثانية عليه.
- جودة العمل . على الأقل ، يعتمد المحلل نفسه على بيانات اللغة الروسية. الشرط واضح. بالنسبة للغة الروسية ، لدينا محللات مورفولوجية جيدة جدًا يمكن دمجها في هرمنا. إذا تمكنا من التأكد من أن المحلل اللغوي نفسه يعمل باردًا بدون مورفولوجيا ، فإن هذا سوف يناسبنا - سوف ننزلق الشكل لاحقًا.
- توافر كود تدريب ويفضل نموذج في المجال العام . إذا كان لدينا رمز تدريب ، فسنكون قادرين على تكرار نتائج مؤلف النموذج. للقيام بذلك ، يجب أن تكون مفتوحة. بالإضافة إلى ذلك ، نحتاج إلى مراقبة شروط توزيع الحالات والنماذج بعناية - هل سيتعين علينا شراء ترخيص لاستخدامها ، إذا استخدمناها كجزء من خوارزمياتنا؟
- إطلاق دون جهد إضافي . هذا البند هو موضوعي للغاية ، ولكنه مهم. ماذا يعني هذا؟ هذا يعني أنه إذا جلسنا لمدة ثلاثة أيام وبدأنا شيئًا ما ، ولكنه لم يبدأ ، فلن نتمكن من تحديد هذا المحلل اللغوي ، حتى لو كان ذا جودة مثالية.
كل شيء كان أعلى من UDPipe 2.0 على الرسم البياني للمحلل لم يناسبنا. لدينا مشروع Python ، ولم يتم كتابة بعض موزعي القائمة في Python. لتنفيذها في مشروع Python ، سيكون من الضروري تطبيق الجهود الفائقة. في حالات أخرى ، واجهنا رمز مصدر مغلق ، وتطورات أكاديمية وصناعية - بشكل عام ، لن تصل إلى القاع.
تستحق Star Syntaxnet قصة منفصلة عن جودة العمل. هنا لم يناسبنا لسرعة العمل. وقت رده على بعض العبارات البسيطة الشائعة في الدردشات هو من 100 مللي ثانية. إذا أنفقنا الكثير على بناء الجملة ، فلن يكون لدينا الوقت الكافي لأي شيء آخر. في نفس الوقت ، تحليل UDPipe 2.0 لـ 3 مللي ثانية تقريبًا. نتيجة لذلك ، وقع الاختيار على UDPipe 2.0.
UDPipe 2.0
UDPipe هو خط أنابيب يتعلم الترميز ، lemmatization ، وضع العلامات المورفولوجية ، وتحليل قواعد التبعية. يمكننا أن نعلمه كل هذا أو أي شيء على حدة. على سبيل المثال ، قم بعمل محلل صرفي آخر للغة الروسية معها. أو تدريب واستخدام UDPipe كرمز مميز.
تم توثيق UDPipe 2.0 بالتفصيل. هناك
وصف للهندسة المعمارية ،
ومستودع برمز تدريب ،
ودليل . الأكثر إثارة للاهتمام هو
النماذج الجاهزة ، بما في ذلك اللغة الروسية. تنزيل وتشغيل. أيضا على هذا المورد تم إصدار معلمات التدريب المختارة لكل مجموعة لغة. لكل نموذج ، هناك حاجة إلى حوالي 60 معلمة تدريب ، وبمساعدتهم يمكنك بشكل مستقل تحقيق نفس مؤشرات الجودة كما في الجدول. قد لا تكون مثالية ، ولكن على الأقل يمكننا التأكد من أن خط الأنابيب سيعمل بشكل صحيح تمامًا. بالإضافة إلى ذلك ، فإن وجود مثل هذا المرجع يسمح لنا بتجربة النموذج بهدوء بمفردنا.
كيف يعمل UDPipe 2.0
أولاً ، ينقسم النص إلى جمل ، والجمل إلى كلمات. يقوم UDPipe بكل هذا مرة واحدة بمساعدة وحدة مشتركة - شبكة عصبية (طبقة أحادية الجانب ثنائية الطبقة GRU) ، والتي تتنبأ لكل شخصية ما إذا كانت الأخيرة في جملة أم في كلمة.
ثم يبدأ الوسم بالعمل - وهو الشيء الذي يتنبأ بالخصائص المورفولوجية للرمز: في هذه الحالة تكون الكلمة ، بأي رقم. استنادًا إلى الأحرف الأربعة الأخيرة من كل كلمة ، يُنشئ برنامج العلامات فرضيات تتعلق بجزء من الكلمات والكلمات المورفولوجية لتلك الكلمة ، ثم بمساعدة أحد الإدخالات يحدد أفضل خيار.
يحتوي UDPipe أيضًا على lemmatizer الذي يحدد النموذج الأولي للكلمات. يتعلم عن نفس المبدأ الذي يمكن من خلاله للمتحدث غير الأصلي أن يحاول تحديد ليما كلمة غير مألوفة. نقطع البادئة ونهاية الكلمة ، ونضيف بعض "t" ، الموجودة في الشكل الأولي للفعل ، إلخ. لذلك يتم إنشاء المرشحين ، والتي يختار منها أفضل الإدراك.
مخطط وضع العلامات المورفولوجي (تحديد العدد والحالة وكل شيء آخر) وتنبؤات الليمونات متشابهة جدًا. يمكن التنبؤ بها معًا ، ولكن بشكل أفضل بشكل منفصل - مورفولوجية اللغة الروسية غنية جدًا. يمكنك أيضًا توصيل قائمة الليمونات الخاصة بك.
دعنا ننتقل إلى الجزء الأكثر إثارة للاهتمام - المحلل اللغوي. هناك العديد من معماريات الاعتماد اللغوي. UDPipe هي بنية قائمة على الانتقال: تعمل بسرعة ، تمر عبر جميع الرموز المميزة مرة واحدة في وقت خطي.
يبدأ التحليل النحوي في مثل هذه البنية بمكدس (حيث يوجد في البداية الجذر فقط) وتكوين فارغ. هناك ثلاث طرق افتراضية لتغييره:
- LeftArc - قابل للتطبيق إذا كان العنصر الثاني من المكدس ليس الجذر. يحافظ على العلاقة بين الرمز المميز في أعلى المكدس والرمز الثاني ، ويخرج أيضًا الثاني من المكدس.
- RightArc هو نفسه ، ولكن التبعية مبنية في الاتجاه الآخر ، ويتم تجاهل الطرف.
- Shift - ينقل الكلمة التالية من المخزن المؤقت إلى المكدس.
فيما يلي مثال على المحلل (
المصدر ). لدينا عبارة "احجز لي رحلة الصباح" ونعيد الاتصال بها:

ها هي النتيجة:

يحتوي المحلل اللغوي الكلاسيكي القائم على الانتقال على العمليات الثلاث المذكورة أعلاه: سهم أحادي الاتجاه وسهم اتجاه واحد وزحزحة. هناك أيضًا عملية Swap ، في معماريات المحلل اللغوي الأساسية القائمة على الانتقال ، لا يتم استخدامها ، ولكن يتم تضمينها في UDPipe. تقوم Swap بإرجاع العنصر الثاني من المكدس إلى المخزن المؤقت لأخذ العنصر التالي من المخزن المؤقت (إذا كانت متباعدة). هذا يساعد على تخطي بضع كلمات واستعادة الاتصال الصحيح.
هناك مقال جيد من
رابط الشخص الذي توصل لعملية المبادلة. نفرز نقطة واحدة: على الرغم من حقيقة أننا مررنا مرارًا وتكرارًا من خلال المخزن المؤقت المميز للرمز (أي أن وقتنا لم يعد خطيًا) ، يمكن تحسين هذه العمليات بحيث يتم إرجاع الوقت قريبًا جدًا من الخطية. أي أن أمامنا ليست مجرد عملية ذات معنى من وجهة نظر اللغة ، ولكن أيضًا أداة لا تبطئ عمل المحلل كثيرًا.
باستخدام المثال أعلاه ، أظهرنا العمليات ، ونتيجة لذلك نحصل على بعض التكوين - المخزن المؤقت للرمز والروابط بينهما. نعطي هذا التكوين في الخطوة الحالية إلى المحلل اللغوي القائم على الانتقال ، ومعه ، يجب أن يتوقع التكوين في الخطوة التالية. بمقارنة ناقلات الإدخال والتكوينات في كل خطوة ، يتم تدريب النموذج.
لذلك ، اخترنا المحلل اللغوي الذي يناسب جميع معاييرنا ، وحتى فهمنا كيف يعمل. نشرع في التجارب.
مشاكل UDPipe
دعونا نسأل جملة صغيرة: "نقل مائة روبل لأمي". والنتيجة تجعلك تمسك رأسك.
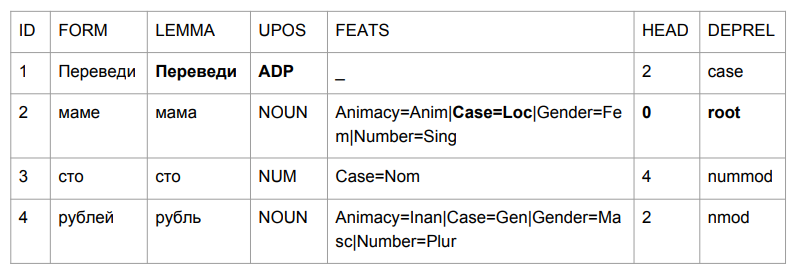
تحولت "الترجمة" إلى عذر ، لكن هذا منطقي تمامًا. نحدد قواعد شكل الكلمة من خلال الأحرف الأربعة الأخيرة. "الرصاص" يشبه "في الوسط" ، لذا فإن الاختيار منطقي نسبيًا. إنه أكثر إثارة للاهتمام مع "أمي": كانت "أمي" في حالة الجر المسبق وأصبحت قمة هذه الجملة.
إذا حاولنا تفسير كل شيء بناءً على نتائج التحليل ، فسوف نحصل على شيء مثل "في خضم أم (من أم؟ من هذه الأم؟) مئات الروبل". ليس بالضبط ما كان عليه في البداية. نحن بحاجة للتعامل مع هذا بطريقة أو بأخرى. وتوصلنا إلى كيفية.
في هرم التحليل ، يتم بناء الجملة على قمة علم الصرف ، بناءً على العلامات المورفولوجية. هنا مثال كتابي لغوي ل. Shcherby في هذا الصدد:
"Gloky cuzdra shteko budlanula bokra والفتى الصغير ذو الشعر المجعد."تحليل هذا الاقتراح لا يسبب مشاكل. لماذا؟ لأننا ، بصفتنا علامة UDPipe ، ننظر إلى نهاية الكلمة ونفهم أي جزء من الكلام يشير إليه وشكله. تتناقض القصة مع "ترجمة" كذريعة مع حدسنا تمامًا ، ولكن اتضح أنها منطقية في الوقت الذي نحاول فيه فعل الشيء نفسه بكلمات غير مألوفة. قد يفكر الشخص بنفس الطريقة.
سنقوم بتقييم UDPipe tagger بشكل منفصل. إذا لم يكن ذلك مناسبًا لنا ، فسنأخذ علامة أخرى - ثم ننشئ تحليلًا فوق ترميز صرفي آخر.
وضع العلامات من نص عادي (درجة CoNLL17 F1)- أشكال الذهب: 301639 ،
- upostag: 98.15٪ ،
- xpostag: 99.89٪ ،
- الأعمال: 93.97٪ ،
- alltags: 93.44٪ ،
- الليمه: 96.68٪
جودة مورفولوجيا UDPipe 2.0 ليست سيئة. لكن للغة الروسية أفضل بشكل ملحوظ. يحقق محلل Mystem (
تطوير Yandex ) نتائج أفضل في تحديد أجزاء الكلام من UDPipe. , python-, , Mystem. ,
.
UDPipe. . , Mystem . , « » «» — «», «». . , «», (), , . :
- « » —
- « » — ..
- « - » — (- )
في مثل هذه الحالات ، يمنح Mystem السلسلة بأمانة:
m.analyze(" ")
[{'analysis': [{'lex': '', 'gr': 'PART='}], 'text': ''},
{'text': ' '},
{'analysis': [{'lex': '', 'gr': 'S,,=(,|,|,)'}],
'text': ''},
{'text': '\n'}]
ولكن لا يمكننا إرسال سلسلة الأنابيب بالكامل إلى UDPipe ، ولكن يجب علينا تحديد بعض العلامات الأفضل. كيف تختارها؟ إذا لم تلمس أي شيء ، أود أن أغتنم الأولى ، ربما ستعمل. ولكن يتم تصنيف العلامات أبجديًا وفقًا للأسماء الإنجليزية ، لذلك سيكون خيارنا قريبًا من العشوائي ، وستفقد بعض التحليلات فرصة أن تكون الأولى.
هناك محلل يمكن أن يعطي الخيار الأفضل - Pymorphy2. ولكن مع تحليل مورفولوجيا ، فهو أسوأ. بالإضافة إلى ذلك ، يعطي أفضل كلمة خارج السياق. ستعطي Pymorphy2 تحليلاً واحدًا فقط لـ "لا يوجد مخرج" و "انظر المخرج" و "المخرج". لن يكون الأمر عشوائيًا ، ولكنه في الواقع الأفضل في الاحتمال ، والذي تم اعتباره في pymorphy2 في مجموعة منفصلة من النصوص. ولكن سيتم ضمان نسبة معينة من التحليل غير الصحيح للنصوص القتالية ، وذلك ببساطة لأنها قد تحتوي على عبارات ذات أشكال حقيقية مختلفة: "أرى المخرج" و "جاء المخرجون إلى الاجتماع" و "لا يوجد مخرج". الاحتمال غير السياقي للتحليل لا يناسبنا.
كيفية الحصول على أفضل مجموعة من العلامات السياقية؟ باستخدام محلل
RNNMorph . قليل من الناس سمعوا عنه ، ولكن في العام الماضي فاز في المنافسة بين المحللين الصرفيين ، التي عقدت كجزء من مؤتمر الحوار.
لدى RNNMorph مشكلتها الخاصة: ليس لديها رمز مميز. إذا كان بإمكان النظام ترميز النص الخام ، فإن RNNMorph يتطلب قائمة من الرموز المميزة عند الإدخال. للوصول إلى الصيغة ، ستحتاج أولاً إلى استخدام بعض الرموز المميزة الخارجية ، ثم إعطاء النتيجة لـ RNNMorph ثم فقط تغذية التشكيل الناتج إلى محلل النحو.
فيما يلي الخيارات المتاحة لدينا. لن نرفض تحليل pymorphy2 الذي لا سياق له في الوقت الحالي على الحالات القابلة للنقاش في النظام - فجأة لن يتخلف كثيرًا عن RNNMorph. على الرغم من أننا إذا
قارناها فقط على مستوى جودة الترميز المورفولوجي (بيانات من
MorphoRuEval-2017 ) ، فإن الخسارة كبيرة - حوالي 15 ٪ ، إذا أخذنا الدقة وفقًا للكلمات.
بعد ذلك ، نحتاج إلى تحويل إخراج Mystem إلى التنسيق الذي يفهمه UDPipe - conllu. ومرة أخرى هذه مشكلة ، حتى اثنين. تقنية بحتة - لا تتطابق الخطوط. والمفاهيمية - ليس من الواضح دائمًا كيفية مقارنتها. في مواجهة ترميزين مختلفين لبيانات اللغة ، من شبه المؤكد أنك ستواجه مشكلة مطابقة العلامات ، انظر الأمثلة أدناه. قد تختلف إجابات السؤال "أي علامة موجودة هنا" ، وربما تعتمد الإجابة الصحيحة على المهمة. بسبب هذا التضارب ، فإن مطابقة أنظمة الترميز ليست مهمة سهلة في حد ذاتها.
كيف يتم التحويل؟ توجد
حزمة russian_tagsets _
حزمة لبايثون يمكنها تحويل صيغ مختلفة. لا توجد ترجمة من تنسيق إصدار Mystem إلى Conllu ، والتي يتم قبولها في التبعيات العالمية ، ولكن هناك ترجمة ل conllu ، على سبيل المثال ، من تنسيق الترميز الخاص بالجسم الوطني للغة الروسية (والعكس صحيح). مؤلف الحزمة (بالمناسبة ، هو مؤلف pymorphy2) كتب شيئًا رائعًا مباشرة في الوثائق: "إذا لم تتمكن من استخدام هذه الحزمة ، فلا تستخدمها." لم يفعل ذلك لأن مبرمج krivorukov (هو مبرمج ممتاز!) ، ولكن لأنه إذا كنت بحاجة إلى تحويل واحد إلى آخر ، فأنت تخاطر بالحصول على مشاكل بسبب التناقض اللغوي في اصطلاحات الترميز.
هنا مثال. تم تدريس المدرسة "فئة الحالة" (البرد ، ضروري). يقول البعض أنها ظرف ، والبعض الآخر صفة. تحتاج إلى تحويل هذا ، وتضيف بعض القواعد ، ولكن لا تزال لا تحقق مراسلات لا لبس فيها بين تنسيق وآخر.
مثال آخر: تعهد (إما أن يفعل شخص ما شيئًا أو يفعل شيئًا مع شخص ما). "بتيا قتل شخص ما" أو "قتل بيتيا". "Vasya تلتقط الصور" - "Vasya تلتقط الصور" (أي في الواقع ، "Vasya يتم تصويره"). هناك أيضًا ضمان وسطي في SynTagRus - لن نتعمق حتى في ما هو ولماذا. ولكن في النظام ليس كذلك. إذا كنت بحاجة إلى إحضار شكل إلى آخر بطريقة أو بأخرى ، فهذا طريق مسدود.
لقد أخذنا بصراحة إلى حد ما نصيحة مؤلف حزمة russian_tagsets - لم نستخدم تطويرها ، لأننا لم نجد الزوج المطلوب في قائمة تنسيقات المراسلات. نتيجة لذلك ، كتبنا محولنا المخصص من Mystem إلى Conllu واستمر.
نقوم بتوصيل أداة تمييز الطرف الثالث ومحلل UDPipe
بعد كل المغامرات ، أخذنا ثلاث خوارزميات تم وصفها أعلاه:
- UDPipe الأساسي
- Mym مع علامة توضيح من pymorphy2
- RNNMorph
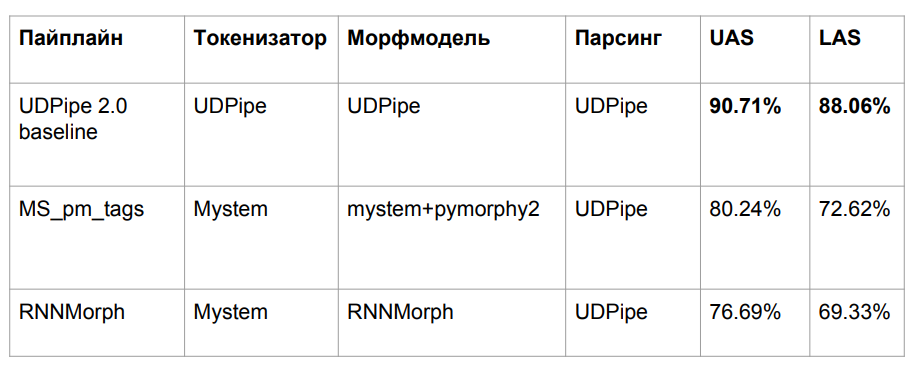
خسرنا في الجودة لسبب واضح جدا. أخذنا نموذج UDPipe المدرب على مورفولوجيا واحد ، لكننا انزلنا عن مورفولوجيا أخرى عند المدخلات. المشكلة الكلاسيكية لعدم تطابق البيانات بين القطار والاختبار هي نتيجة لانخفاض الجودة.
لقد حاولنا محاذاة أدوات وضع العلامات المورفولوجية التلقائية الخاصة بنا مع ترميز SynTagRus ، الذي تم وضع علامة يدويًا عليه. لم ننجح ، لذلك ، في حالة التدريب SynTagRus ، سنستبدل جميع العلامات المورفولوجية اليدوية بتلك التي تم الحصول عليها من Mystem و pymorphy2 في حالة واحدة ومن RNNMorph في حالة أخرى. في حالة تم التحقق منها تم تمييزها يدويًا ، فإننا مضطرون لتغيير العلامات اليدوية إلى تلقائية ، لأن "في المعركة" لن نحصل أبدًا على علامات يدوية.
ونتيجة لذلك ، قمنا بتدريب محلل UDPipe (المحلل اللغوي فقط) بنفس المعلمات الزائدة كخط الأساس. ما كان مسؤولاً عن بناء الجملة - معرف الرأس ، الذي يعتمد عليه نوع الاتصال - غادرنا ، غيرنا كل شيء آخر.
النتائج
علاوة على ذلك ، سأقوم بمقارنتنا مع Syntaxnet وخوارزميات أخرى. كشف منظمو المهام المشتركة لـ CoNLL عن قسم SynTagRus (تدريب / تطوير / اختبار 80/10/10). أخذنا في البداية قطارًا آخر (قطار / اختبار 70/30) ، لذلك لا تتزامن البيانات دائمًا معنا ، على الرغم من تلقيها في نفس الحالة. بالإضافة إلى ذلك ، أخذنا الإصدار الأخير (اعتبارًا من فبراير إلى مارس) من مستودع SynTagRus - يختلف هذا الإصدار قليلاً عن الإصدار في المسابقة. يتم تقديم البيانات المتعلقة بما لم يتم الإقلاع منه في المقالات حيث كان الانقسام هو نفسه كما هو الحال في المنافسة - يتم تمييز هذه الخوارزميات بعلامة نجمة في الجدول.
فيما يلي النتائج النهائية:
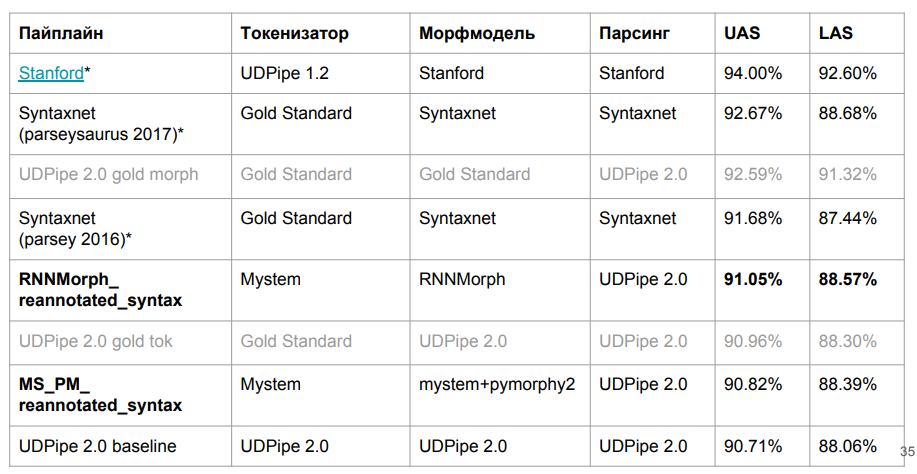
تبين أن RNNMorph أفضل - ليس بالمعنى المطلق ، ولكن في دور الأداة المساعدة للحصول على مقياس مشترك وفقًا لنتائج التحليل (مقارنة بـ Mystem + pymorphy2). أي أنه كلما كان التشكل أفضل ، كان التركيب أفضل ، ولكن الفصل "النحوي" أقل بكثير من التشكل المورفولوجي. لاحظ أيضًا أننا لم نبتعد كثيرًا عن النموذج الأساسي ، مما يعني أنه في علم الصرف لم يكن هناك بالقدر الذي كنا نتوقعه.
أتساءل كم يكمن على علم الصرف على الإطلاق؟ هل من الممكن تحقيق تحسن جوهري في المحلل اللغوي بسبب الشكل المثالي؟ للإجابة على هذا السؤال ، قمنا بقيادة UDPipe 2.0 على الترميز والمورفولوجيا التي تمت معايرتها بشكل مثالي (باستخدام معيار الترميز اليدوي القياسي). حصلنا على هامش معين (انظر السطر حول Gold Morph في الجدول ؛ اتضح + 1.54٪ من RNNMorph_reannotated_syntax) مما كان لدينا ، بما في ذلك من وجهة نظر تحديد نوع الاتصال بشكل صحيح. إذا كتب شخص ما على الإطلاق محللًا مورفولوجيًا مثاليًا تمامًا للغة الروسية ، فمن المحتمل أن النتائج التي نحصل عليها باستخدام المحلل النحوي المجرد ستنمو أيضًا. ونحن نفهم تقريبًا السقف (على الأقل السقف لهذه الهندسة المعمارية ولمجموعة المعلمات التي استخدمناها لـ UDPipe - وهو معروض في الصف الثالث من الجدول أعلاه).
ومن المثير للاهتمام أننا وصلنا تقريبًا إلى إصدار Syntaxnet في مقياس LAS. من الواضح أن لدينا بيانات مختلفة قليلاً ، ولكن من حيث المبدأ لا تزال قابلة للمقارنة. الرمز المميز ل Syntaxnet هو "ذهب" ، وبالنسبة لنا - من Mystem. لقد كتبنا الغلاف المذكور أعلاه لـ Mystem ، لكن التحليل لا يزال يحدث تلقائيًا ؛ ربما مخطئ أيضا النظام في مكان ما. من سطر جدول "UDPipe 2.0 gold tok" ، يمكن ملاحظة أنه إذا أخذت UDPipe الافتراضي ورمز الذهب ، فستظل تفقد Syntaxnet-2017 قليلاً. لكنها تعمل بشكل أسرع.
ما لم يصله أحد هو
محلل ستانفورد . تم تصميمه بنفس طريقة Syntaxnet ، لذا فهو يعمل لفترة طويلة. في UDPipe ، نذهب على طول المكدس. تتميز هندسة محلل ستانفورد و Syntaxnet بمفهوم مختلف: أولاً يقومون بإنشاء رسم بياني موجه كامل ، ثم تعمل الخوارزمية على ترك الهيكل العظمي (الحد الأدنى من شجرة الامتداد) التي ستكون على الأرجح. للقيام بذلك ، يذهب من خلال مجموعات ، وهذا البحث لم يعد خطيًا ، لأنك ستتحول إلى كلمة واحدة أكثر من مرة. على الرغم من حقيقة أنه لفترة طويلة ، من وجهة نظر العلوم البحتة ، على الأقل بالنسبة للغة الروسية ، فهي بنية أكثر كفاءة. حاولنا رفع هذا التطور الأكاديمي لمدة يومين - للأسف ، لم ينجح ذلك. ولكن بناءً على هندستها ، من الواضح أنها لا تعمل بسرعة.
أما بالنسبة لمنهجنا - على الرغم من أننا لم نرتفع رسميًا تقريبًا بواسطة المقاييس ، إلا أن كل شيء الآن على ما يرام مع "الأم".
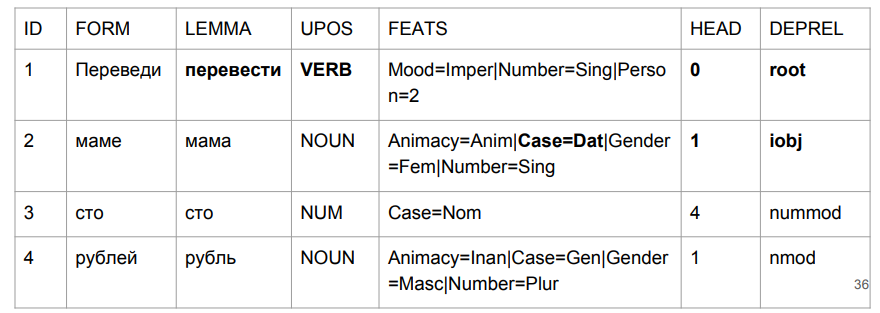
في عبارة "ترجمة مائة روبل إلى أمي" ، فإن "ترجمة" هي فعلًا فعل في الحالة المزاجية الحتمية. حصلت "أمي" على قضيتها الأصلية. وأهم شيء بالنسبة لنا هو تسمية (iobj) ، كائن غير مباشر (وجهة). على الرغم من أن النمو في الأرقام لا يكاد يذكر ، فقد تعاملنا بشكل جيد مع المشكلة التي بدأت بها المهمة.
مسار المكافأة: علامات الترقيم
إذا عدنا إلى البيانات الحقيقية ، اتضح أن بناء الجملة يعتمد على علامات الترقيم. خذ عبارة "لا يمكنك تنفيذ الرحمة". ما لا يمكن فعله بالضبط - "لتنفيذ" أو "رحمة" - يعتمد على موقف الفاصلة. حتى إذا وضعنا اللغوي لترميز البيانات ، فسوف يحتاج إلى علامات الترقيم كأداة مساعدة. لا يستطيع الاستغناء عنها.
لنأخذ عبارتي "Peter hello" و "Peter hello" ونلقي نظرة على تحليلهما بواسطة نموذج خط الأساس UDPipe. نترك المشاكل التي ، وفقا لهذا النموذج ، ثم:
1) "بيتيا" اسم أنثوي ؛
2) "Petya" هو (بالحكم على مجموعة العلامات) الشكل الأولي ، ولكن في نفس الوقت ، من المفترض أن lemma ليس "Petya".
هذه هي الطريقة التي تتغير بها النتيجة بفاصلة ، بمساعدتها نحصل على شيء مشابه للحقيقة.
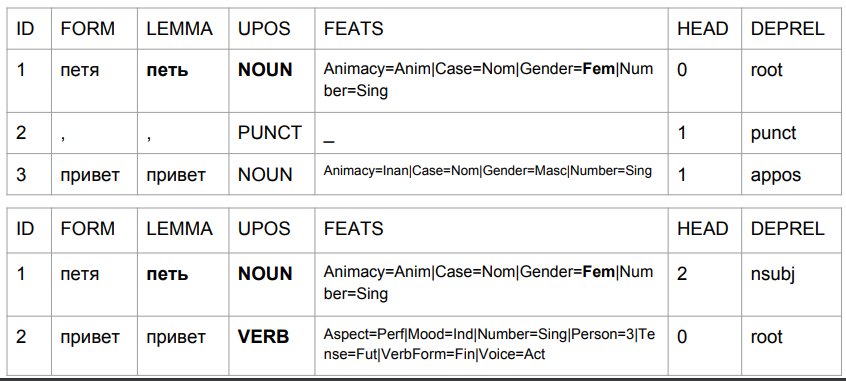
في الحالة الثانية ، "بيتيا" هو موضوع ، و "مرحبًا" هو فعل. العودة إلى توقع شكل الكلمة بناءً على الأحرف الأربعة الأخيرة. في تفسير الخوارزمية ، هذه ليست "تحيات بتيا" ، ولكن "تحيات بتيا". اكتب "Petya sings" أو "Petya will come." التحليل مفهوم تمامًا: في روسيا ، لا يمكن أن تكون هناك فاصلة بين الموضوع والمسند. لذلك ، إذا كانت الفاصلة ، هذه هي الكلمة "مرحبًا" ، وإذا لم تكن هناك فاصلة ، فقد تكون شيئًا مثل "Petya Privet".
سنواجه هذا في الإنتاج في كثير من الأحيان ، لأن المدقق الإملائي سيصحح الإملاء ، ولكن ليس علامات الترقيم. لجعل الأمور أسوأ ، قد يقوم المستخدم بتعيين فواصل بشكل غير صحيح ، وسوف تأخذها الخوارزمية في الاعتبار عند فهم اللغة الطبيعية. ما هي الحلول الممكنة هنا؟ نرى خيارين.
الخيار الأول هو القيام بذلك كما يفعلون أحيانًا عند ترجمة الكلام إلى نص. في البداية ، لا يوجد علامات ترقيم في مثل هذا النص ، لذلك يتم استعادته من خلال النموذج. الناتج مادة مختصة نسبيًا من حيث قواعد اللغة الروسية ، مما يساعد المحلل اللغوي على العمل بشكل صحيح.
والفكرة الثانية أكثر جرأة وتتناقض مع دروس اللغة الروسية. إنه ينطوي على العمل بدون علامات ترقيم: إذا كان الإدخال فجأة هو علامات الترقيم ، فسنزيله من هناك. سنقوم أيضًا بإزالة جميع علامات الترقيم على الإطلاق من هيئات التدريب. نفترض أن اللغة الروسية موجودة بدون علامات ترقيم. فقط نقاط للتقسيم إلى جمل.
من الناحية الفنية ، الأمر بسيط جدًا ، لأننا لا نغير العقد النهائية في شجرة البنية. لا يمكن أن يكون لدينا علامة ترقيم أعلى. هذه دائمًا عقدة نهاية ، باستثناء علامة٪ ، والتي لسبب ما في SynTagRus هي قمة الرقم السابق (50 ٪ في SynTagRus تم وضع علامة على أنها٪ - قمة ، و 50 تعتمد).
دعونا نختبر باستخدام نموذج Mystem (+ pymorphy 2).

من المهم للغاية بالنسبة لنا عدم إعطاء نموذج نص الترقيم بدون علامات ترقيم. ولكن إذا قدمنا النص دائمًا بدون علامات ترقيم ، فسنكون في السطر العلوي ونحصل على نتائج مقبولة على الأقل. إذا كان النص بدون علامات ترقيم وكان النموذج يعمل بدون علامات ترقيم ، فعندما يتعلق بعلامات الترقيم المثالية ونموذج علامات الترقيم ، فإن الانخفاض سيكون حوالي 3٪ فقط.
ماذا تفعل حيال ذلك؟ يمكننا الخوض في هذه الأرقام - التي تم الحصول عليها باستخدام النموذج الخالي من علامات الترقيم وتنقية علامات الترقيم. أو اختر نوعًا من المصنف لاستعادة علامات الترقيم. لن نحقق أرقامًا مثالية (تلك التي تحتوي على علامات ترقيم في نموذج علامات الترقيم) ، لأن خوارزمية استرداد علامات الترقيم تعمل مع بعض الأخطاء ، وتم حساب الأرقام "المثالية" على SynTagRus النقي تمامًا. ولكن إذا كنا سنكتب نموذجًا يعيد علامات الترقيم ، فهل سيقدم التقدم تكاليفنا؟ الجواب ليس واضحا بعد.
يمكننا أن نفكر لفترة طويلة في هندسة المحلل اللغوي ، ولكن يجب أن نتذكر أنه في الواقع لا يوجد مجموعة كبيرة من نصوص الويب التي تم تمييزها نحويًا. وجودها سيساعد على حل المشاكل الحقيقية بشكل أفضل. حتى الآن ، نحن ندرس في هيئة نصوص متعلمة ومحررة تمامًا - ونفقد الجودة من خلال إدخال نصوص مخصصة في المعركة ، والتي غالبًا ما تكون أميًا.
الخلاصة
درسنا استخدام العديد من خوارزميات التحليل النحوي بناءً على قواعد التبعية ، كما يتم تطبيقها على اللغة الروسية. اتضح أنه من حيث السرعة والراحة وجودة العمل ، تبين أن UDPipe هو أفضل أداة. يمكن تحسين نموذج خط الأساس الخاص به إذا تم تعيين مراحل الترميز والتحليل الصرفي إلى محللين آخرين من الجهات الخارجية: هذه الحيلة تجعل من الممكن تصحيح السلوك غير الصحيح للمُعلِّم ، ونتيجة لذلك ، المحلل اللغوي في الحالات المهمة للتحليل.
قمنا أيضًا بتحليل مشكلة العلاقة بين علامات الترقيم والتحليل ، وتوصلنا إلى استنتاج مفاده أنه في حالتنا ، من الأفضل إزالة علامات الترقيم قبل التحليل النحوي.
نأمل أن تساعدك نقاط التطبيق التي تمت مناقشتها في مقالتنا على استخدام التحليل النحوي لحل مشاكلك بأكبر قدر ممكن من الكفاءة.
يشكر المؤلف نيكيتا كوزنتسوفا وناتاليا فيليبوفا على المساعدة في إعداد المقال. للمساعدة في الدراسة - أنطون أليكسيف ، نيكيتا كوزنتسوف ، أندريه كوتوزوف ، بوريس أوريخوف وميخائيل بوبوف.