لسنوات عديدة ، استضافت Mail.ru بطولات التعلم الآلي ، في كل مرة تكون المهمة ممتعة بطريقتها الخاصة ومعقدة بطريقتها الخاصة. هذه هي المرة الرابعة التي أشارك فيها في المسابقات ، فأنا حقًا أحب المنصة والتنظيم ، وقد بدأت مسيرتي نحو تعلُم الآلة التنافسي مع معسكرات التدريب ، ولكنني تمكنت من الحصول على المركز الأول للمرة الأولى. في المقالة ، سأخبرك بكيفية إظهار نتيجة مستقرة دون إعادة التدريب إما على لوحة الصدارة العامة أو على عينات متأخرة ، إذا كان جزء الاختبار مختلفًا بشكل كبير عن الجزء التدريبي من البيانات.
التحدي
النص الكامل للمهمة متاح على
الرابط ←. باختصار: هناك 10 غيغابايت من البيانات ، حيث يحتوي كل سطر على ثلاثة أنواع من "مفتاح: عداد" ، فئة معينة ، طابع زمني محدد ومعرف المستخدم. يمكن أن تتوافق الإدخالات المتعددة مع مستخدم واحد. مطلوب لتحديد الفئة التي ينتمي إليها المستخدم ، الأول أو الثاني. مقياس الجودة للنموذج هو ROC-AUC ، وهو مكتوب بشكل جيد على المدونة بواسطة ألكسندر دياكونوف
[1] .
إدخال ملف مثال
00000d2994b6df9239901389031acaac 5 {"809001":2,"848545":2,"565828":1,"490363":1} {"85789":1,"238490":1,"32285":1,"103987":1,"16507":2,"6477":1,"92797":2} {} 39
الحل
أول فكرة تنبثق من عالم بيانات نجح في تنزيل مجموعة بيانات هي تحويل أعمدة json إلى مصفوفة متفرقة. عند هذه النقطة ، واجه العديد من المشاركين مشاكل مع نقص ذاكرة الوصول العشوائي. عند نشر عمود واحد في الثعبان ، كان استهلاك الذاكرة أعلى من ذلك المتاح على كمبيوتر محمول متوسط.
بعض الإحصائيات الجافة. عدد المفاتيح الفريدة في كل عمود هو 2053602 ، 20275 ، 1057788. علاوة على ذلك ، في جزء القطار وفي جزء الاختبار لا يوجد سوى 493866 و 20268 و 141931. 427994 مستخدمًا فريدًا في القطار و 181024 في جزء الاختبار. ما يقرب من 4 ٪ من الدرجة 1 في الجزء التدريبي.
كما ترون ، لدينا الكثير من العلامات ، واستخدامها كلها طريقة واضحة للتأهب في القطار ، لأنه ، على سبيل المثال ، تستخدم أشجار القرار مجموعات من العلامات ، وهناك مجموعات أكثر تميزًا لمثل هذا العدد الكبير من اللافتات وكلها تقريبًا موجودة فقط في جزء التدريب البيانات أو في الاختبار. ومع ذلك ، كان أحد النماذج الأساسية التي أتيحت لي هو lightgbm مع colsample ~ 0.1 وتسوية صارمة للغاية. ومع ذلك ، على الرغم من المعايير الهائلة للتنظيم ، فقد أظهرت نتائج غير مستقرة في القطاعين العام والخاص ، كما اتضح بعد نهاية المسابقة.
قد يكون الفكر الثاني للشخص الذي قرر المشاركة في هذه المسابقة هو جمع القطار والاختبار وتجميع المعلومات حسب المعرّفات. على سبيل المثال ، المبلغ. أو كحد أقصى. وهنا اتضح شيئان مثيران للاهتمام للغاية توصل إليهما Mail.ru. أولاً ، يمكن تصنيف الاختبار بدقة عالية جدًا. حتى وفقًا للإحصاءات حول عدد إدخالات cuid وعدد المفاتيح الفريدة في json ، يتجاوز الاختبار بشكل كبير القطار. أعطى المصنف الأساسي 0.9+ roc-auc في التعرف على الاختبار. ثانيًا ، العدادات لا معنى لها ، أصبحت جميع النماذج تقريبًا أفضل من التبديل من العدادات إلى العلامات الثنائية للنموذج: لا يوجد / لا يوجد مفتاح. حتى الأشجار ، التي لا ينبغي أن تكون أسوأ من الناحية النظرية من حقيقة أنه بدلاً من الوحدة هناك عدد معين ، يبدو أنه تم إعادة تدريبها على العدادات.
تجاوزت النتائج في لوحة الصدارة العامة إلى حد كبير تلك المتعلقة بالتحقق المتبادل. يبدو أن هذا يرجع إلى حقيقة أنه كان من الأسهل للنموذج بناء ترتيب سجلين في الاختبار منه في القطار ، لأن عددًا أكبر من العلامات أعطى المزيد من المصطلحات للترتيب.
في هذه المرحلة ، أصبح من الواضح تمامًا أن التحقق في هذه المسابقة ليس شيئًا بسيطًا ولا معلومات عامة أو سير ذاتية لمشاركين آخرين ، والتي يمكن خداعها في إغراء في الدردشة الرسمية
[2] . لماذا حدث ذلك؟ يبدو أن القطار والاختبار يفصل بينهما الوقت ، وهو ما أكده المنظمون فيما بعد.
سوف ينصح أي عضو متمرس في Kaggle فورًا بالتحقق من الخصومة
[3] ، ولكنه ليس بهذه البساطة. على الرغم من حقيقة أن دقة المصنف للقطار والاختبار قريبة من 1 بواسطة metro roc-auc ، لا يوجد العديد من الإدخالات المماثلة في القطار. حاولت تلخيص العينات المجمعة cuid مع الهدف نفسه لزيادة عدد السجلات التي تحتوي على عدد كبير من المفاتيح الفريدة في json ، لكن هذا تسبب في عيوب في التحقق المتبادل وفي الأماكن العامة ، وكنت خائفة من استخدام مثل هذه النماذج.
هناك طريقتان: ابحث عن القيم الأبدية مع التعلم غير الخاضع للرقابة أو حاول أن تأخذ ميزات أكثر أهمية للاختبار. لقد ذهبت في كلا الاتجاهين ، باستخدام TruncatedSVD للميزات غير الخاضعة للرقابة واختيار الميزات حسب التردد في الاختبار.
ومع ذلك ، فإن الخطوة الأولى ، قمت بعمل ترميز تلقائي عميق ، لكنني كنت مخطئًا ، مع أخذ نفس المصفوفة مرتين ، لم أتمكن من إصلاح الخطأ واستخدام المجموعة الكاملة من العلامات: لم يتناسب موتر الإدخال مع ذاكرة GPU بأي حجم كثيف. لقد وجدت خطأ وفي وقت لاحق لم أحاول ترميز الميزات.
لقد ولدت SVD بكل الطرق التي كانت مبدعة: في مجموعة البيانات الأصلية مع cat_feature والتجميع اللاحق بواسطة cuid. لكل عمود على حدة. بواسطة tf-idf على json كحقيبة كلمات
[4] (لم يساعد).
من أجل تنوع أكبر ، حاولت تحديد عدد صغير من الميزات في القطار ، باستخدام A-NOVA لجزء القطار من كل حظيرة في التحقق المتقاطع.
النماذج
النماذج الأساسية الرئيسية: lightgbm ، wabbit ، wgbit ، xgboost ، SGD. بالإضافة إلى ذلك ، استخدمت العديد من بنيات الشبكات العصبية. نصح دميتري نيكيتكو ، الذي كان في المقام الأول من
لوحة الصدارة العامة ، باستخدام
HashEmbeddings ،
أظهر هذا النموذج بعد بعض المعايير المختارة نتيجة جيدة وحسّن المجموعة.
نموذج آخر للشبكة العصبية مع البحث عن التفاعلات (نمط آلة عامل التجهيز) بين أعمدة البيانات 3-4-5 (ثلاثة مدخلات يسرى) ، إحصائيات رقمية (4 مدخلات) ، مصفوفة SVD (5 مدخلات).
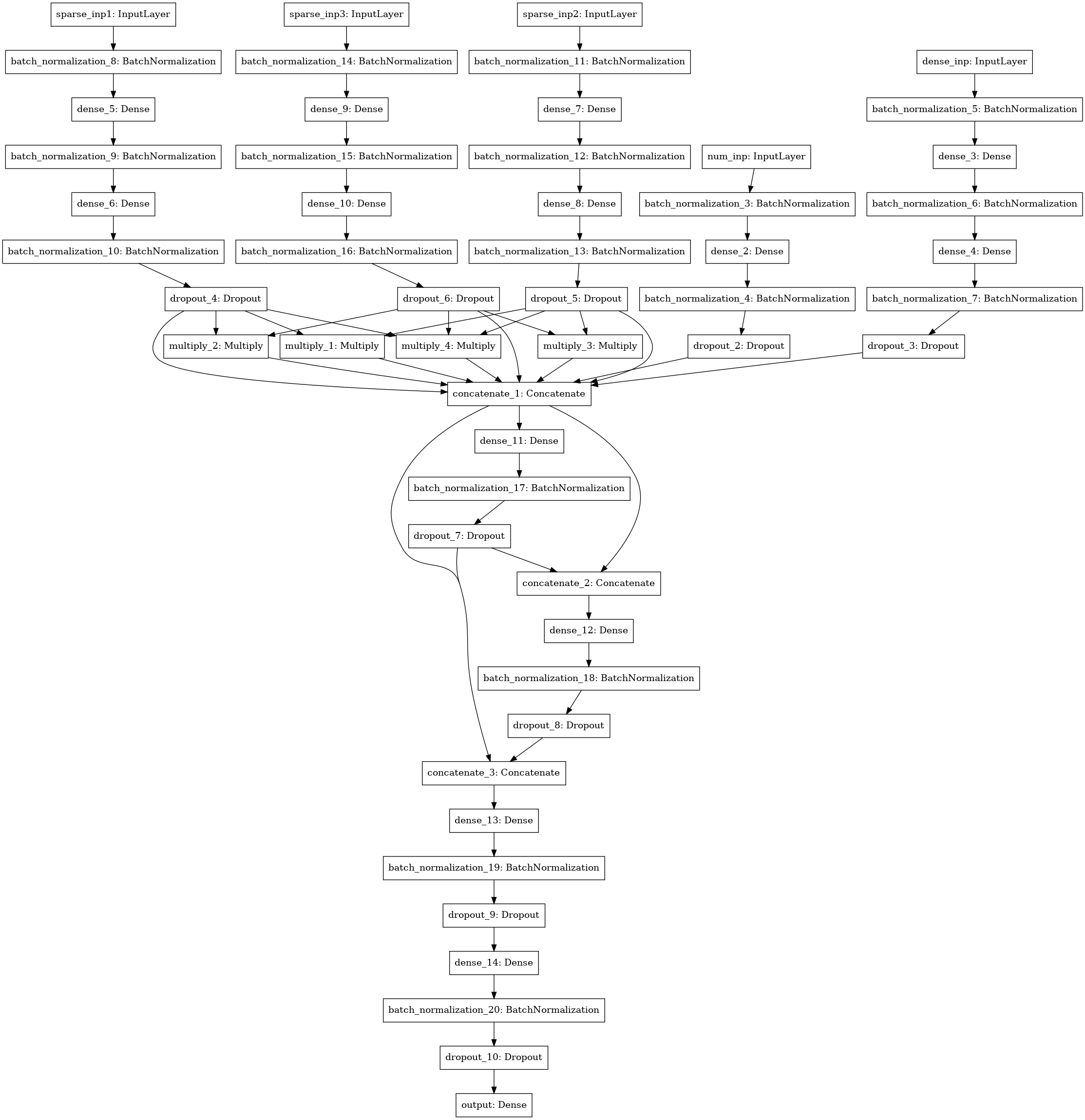
فرقة
أحصيت جميع النماذج عن طريق الطيات ، ومتوسط توقعات الاختبار من النماذج المدربة على طيات مختلفة. تم استخدام تنبؤات القطار للتكديس. تم عرض أفضل نتيجة بواسطة مكدس المستوى 1 باستخدام xgboost على تنبؤات النماذج الأساسية و 250 سمة من كل عمود json ، تم اختيارها وفقًا للتردد الذي اجتمعت فيه السمة في الاختبار.
قضيت حوالي 30 ساعة من وقتي في الحل ، معتمدين على خادم يحتوي على 4 نواة i7 ، و 64 غيغابايت من ذاكرة الوصول العشوائي ، وواحد GTX 1080. ونتيجة لذلك ، تبين أن حلّي مستقر تمامًا وانتقلت من المركز الثالث في لوحة الصدارة العامة إلى أول حل خاص.
يتوفر جزء كبير من الشفرة على bitbucket في شكل أجهزة كمبيوتر محمولة
[5] .
أريد أن أشكر Mail.ru على المسابقات الشيقة والمشاركين الآخرين على التواصل المثير للاهتمام في المجموعة!
[1]
ROC-AUC على مدونة ألكسندروف دياكونوف[2]
مسؤول الدردشة ML BootCamp الرسمية[3]
التحقق من الخصومة[4]
حقيبة كلمات[5]
كود المصدر لمعظم الموديلات