"أجرى فريقCloudflare للتو تغييرات أدت إلى تحسن كبير في أداء شبكتنا ، خاصة بالنسبة إلى أبطأ الطلبات. كم أسرع؟ نحن نقدر أننا نقوم بحفظ الإنترنت حوالي 54 عامًا من الوقت في اليوم ، والتي كانت ستنفق لانتظار تحميل المواقع " . - ماثيو برينس
سقسقة ، 28 يونيو 2018
تستخدم 10 ملايين موقع وتطبيقات وواجهة برمجة تطبيقات Cloudflare لتسريع تنزيلات المحتوى للمستخدمين. في ذروة النشاط ، نقوم بمعالجة أكثر من 10 مليون طلب في الثانية في 151 مركز بيانات. على مر السنين ، قمنا بإجراء العديد من التغييرات على نسختنا من Nginx للتعامل مع النمو. تتناول هذه المقالة أحد هذه التغييرات.
كيف يعمل Nginx
Nginx هو أحد البرامج التي تستخدم حلقات معالجة الأحداث لحل
مشكلة C10K . في كل مرة يصل حدث شبكة (اتصال أو طلب أو إشعار جديد لإرسال كمية أكبر من البيانات ، وما إلى ذلك) ، يستيقظ Nginx ، ويعالج الحدث ، ثم يعود إلى وظيفة أخرى (قد يكون هذا معالجة أحداث أخرى). عند وصول حدث ، تكون البيانات الخاصة به جاهزة ، مما يسمح لك بمعالجة العديد من الطلبات المتزامنة بكفاءة دون توقف.
num_events = epoll_wait(epfd, events, events_len, -1); // events is list of active events // handle event[0]: incoming request GET http://example.com/ // handle event[1]: send out response to GET http://cloudflare.com/
على سبيل المثال ، إليك ما قد يبدو عليه جزء من التعليمات البرمجية لقراءة البيانات من واصف الملف:
// we got a read event on fd while (buf_len > 0) { ssize_t n = read(fd, buf, buf_len); if (n < 0) { if (errno == EWOULDBLOCK || errno == EAGAIN) { // try later when we get a read event again } if (errno == EINTR) { continue; } return total; } buf_len -= n; buf += n; total += n; }
إذا كان fd مأخذ شبكة ، فسيتم إرجاع وحدات البايت المتلقاة بالفعل. ستعيد المكالمة الأخيرة
EWOULDBLOCK . هذا يعني أن المخزن المؤقت للقراءة المحلية قد انتهى ولا يجب عليك القراءة من هذا المقبس حتى تظهر البيانات.
يختلف القرص I / O عن الشبكة
إذا كان fd ملفًا عاديًا على Linux ، فلن
EWOULDBLOCK و
EAGAIN أبدًا ، وتنتظر عملية القراءة دائمًا قراءة المخزن المؤقت بأكمله ، حتى إذا تم فتح الملف باستخدام
O_NONBLOCK . كما هو مكتوب في الدليل
المفتوح (2) :
يرجى ملاحظة أن هذه العلامة غير صالحة للملفات العادية وحظر الأجهزة.
بمعنى آخر ، يتم تقليل الرمز أعلاه بشكل أساسي إلى هذا:
if (read(fd, buf, buf_len) > 0) { return buf_len; }
إذا كان المعالج بحاجة إلى القراءة من القرص ، فإنه يحجب حلقة الحدث حتى تكتمل القراءة ، وتنتظر معالجات الأحداث اللاحقة.
يعد هذا أمرًا طبيعيًا بالنسبة لمعظم المهام ، نظرًا لأن القراءة من أحد الأقراص عادةً ما تكون سريعة جدًا ويمكن توقعها أكثر بكثير من انتظار حزمة من الشبكة. خاصة الآن أن كل شخص لديه SSD ، وجميع مخابئنا موجودة على SSDs. في محركات الأقراص ذات الحالة الثابتة الحديثة ، تأخير بسيط جدًا ، عادةً في عشرات الميكروثانية. بالإضافة إلى ذلك ، يمكنك تشغيل Nginx مع العديد من عمليات سير العمل بحيث لا يمنع معالج الأحداث البطيء الطلبات في العمليات الأخرى. في معظم الأحيان يمكنك الاعتماد على Nginx لمعالجة الطلبات بسرعة وكفاءة.
أداء SSD: ليس دائمًا كما وعد
كما كنت قد خمنت ، فإن هذه الافتراضات الوردية ليست صحيحة دائمًا. إذا كانت كل قراءة تستغرق دائمًا 50 μs ، فإن قراءة 0.19 ميجابايت في كتل من 4 كيلوبايت (ونقرأها في كتل أكبر) ستستغرق 2 مللي ثانية فقط. لكن الاختبارات أظهرت أن الوقت للبايت الأول يكون أحيانًا أسوأ بكثير ، خاصة في المئين 99 و 999. وبعبارة أخرى ، فإن أبطأ قراءة من كل 100 (أو 1000) قراءة غالبًا ما تستغرق وقتًا أطول.
محركات الأقراص ذات الحالة الصلبة سريعة جدًا ، ولكنها معروفة بتعقيدها. لديهم أجهزة كمبيوتر داخل قائمة الانتظار هذه وإعادة ترتيب I / O ، وكذلك أداء مهام خلفية مختلفة ، مثل جمع القمامة وإلغاء التجزئة. من وقت لآخر ، تتباطأ الطلبات بشكل ملحوظ. أطلق زميلي
إيفان بوبروف العديد من معايير I / O وسجلت تأخيرات في القراءة تصل إلى ثانية واحدة. علاوة على ذلك ، فإن بعض محركات الأقراص ذات الحالة الثابتة لدينا تتمتع بمثل هذه الارتفاعات في الأداء أكثر من غيرها. في المستقبل سنأخذ هذا المؤشر في الاعتبار عند شراء SSD ، لكننا الآن بحاجة إلى تطوير حل للمعدات الموجودة.
توزيع تحميل موحد مع SO_REUSEPORT
من الصعب تجنب استجابة بطيئة واحدة لكل 1000 طلب ، ولكن ما لا نريده حقًا هو حظر الطلبات الـ 1000 المتبقية لمدة ثانية كاملة. من الناحية المفاهيمية ، تستطيع Nginx معالجة العديد من الطلبات بالتوازي ، ولكنها تبدأ معالج أحداث واحد فقط في كل مرة. لذا أضفت مقياسًا خاصًا:
gettimeofday(&start, NULL); num_events = epoll_wait(epfd, events, events_len, -1); // events is list of active events // handle event[0]: incoming request GET http://example.com/ gettimeofday(&event_start_handle, NULL); // handle event[1]: send out response to GET http://cloudflare.com/ timersub(&event_start_handle, &start, &event_loop_blocked);
تجاوزت النسبة المئوية 99 (p99)
event_loop_blocked 50٪ من TTFB. بمعنى آخر ، نصف الوقت الذي تتم فيه خدمة الطلب هو نتيجة حظر دورة معالجة الحدث بطلبات أخرى.
event_loop_blocked يقيس نصف القفل فقط (لأنه لا
epoll_wait() قياس المكالمات المعلقة لـ
epoll_wait() ) ، وبالتالي فإن النسبة الفعلية للوقت المحظور أعلى بكثير.
تقوم كل من أجهزتنا بتشغيل Nginx مع 15 سير عمل ، أي أن الإدخال / الإخراج البطيء لن يمنع أكثر من 6٪ من الطلبات. لكن الأحداث ليست موزعة بالتساوي: العامل الرئيسي يتلقى 11٪ من الطلبات.
يمكن
SO_REUSEPORT حل مشكلة التوزيع غير المتكافئ. كتب Marek Maikovsky في وقت سابق عن
عيب هذا النهج في سياق حالات Nginx الأخرى ، ولكن هنا يمكنك تجاهله بشكل أساسي: الاتصالات الأولية في ذاكرة التخزين المؤقت متينة ، بحيث يمكنك تجاهل زيادة طفيفة في التأخير عند فتح الاتصال. هذا التغيير في التكوين وحده مع تفعيل
SO_REUSEPORT يحسن الذروة p99 بنسبة 33٪.
نقل القراءة () إلى تجمع مؤشر ترابط: ليس رمز نقطي فضي
الحل هو جعل قراءة () غير مانع. في الواقع يتم
تنفيذ هذه الوظيفة
في Nginx العادي ! باستخدام التكوين التالي ، يتم تنفيذ القراءة () والكتابة () في تجمع مؤشرات الترابط ولا يحظران حلقة الحدث:
aio threads; aio_write on;
لكننا اختبرنا هذا التكوين وبدلاً من تحسين وقت الاستجابة بمقدار 33 مرة ، لاحظنا تغييرًا طفيفًا فقط في p99 ، والفرق داخل هامش الخطأ. كانت النتيجة محبطة للغاية ، لذلك قمنا بتأجيل هذا الخيار مؤقتًا.
هناك عدة أسباب لعدم حصولنا على تحسينات كبيرة ، مثل مطوري Nginx. في الاختبار ، استخدموا 200 اتصالًا متزامنًا لطلب ملفات 4 ميجا بايت إلى محرك الأقراص الصلبة. لدى Winchesters وقت استجابة I / O أكثر ، لذا فإن التحسين له تأثير أكبر.
بالإضافة إلى ذلك ، نحن معنيين بشكل رئيسي بأداء p99 (و p999). تحسين متوسط التأخير لا يحل بالضرورة مشكلة ذروة الانبعاث.
أخيرًا ، في بيئتنا ، تكون أحجام الملفات النموذجية أصغر كثيرًا. 90٪ من نتائج ذاكرة التخزين المؤقت لدينا أقل من 60 كيلوبايت. كلما كانت الملفات أصغر ، كانت حالات الحظر أقل (عادةً ما نقرأ الملف بأكمله في قراءتين).
دعونا نلقي نظرة على القرص I / O عند الاصطدام في ذاكرة التخزين المؤقت:
// https://example.com 0xCAFEBEEF fd = open("/cache/prefix/dir/EF/BE/CAFEBEEF", O_RDONLY); // 32 // , "aio threads" read(fd, buf, 32*1024);
لا يتم قراءة 32K دائمًا. إذا كانت الرؤوس صغيرة ، فأنت بحاجة إلى قراءة 4 كيلوبايت فقط (لا نستخدم الإدخال / الإخراج مباشرة ، لذا فإن النواة تقرب إلى 4 كيلوبايت).
open() يبدو غير ضار ، ولكنه يتطلب موارد في الواقع. كحد أدنى ، يجب أن تتحقق النواة مما إذا كان الملف موجودًا وما إذا كانت عملية الاستدعاء لها إذن لفتحه. يحتاج إلى العثور على inode لـ
/cache/prefix/dir/EF/BE/CAFEBEEF ، ولهذا سيتعين عليه البحث عن
CAFEBEEF في
/cache/prefix/dir/EF/BE/ . باختصار ، في أسوأ الأحوال ، تقوم النواة بإجراء هذا البحث:
/cache /cache/prefix /cache/prefix/dir /cache/prefix/dir/EF /cache/prefix/dir/EF/BE /cache/prefix/dir/EF/BE/CAFEBEEF
هذه هي 6 قراءات منفصلة تنتجها
open() ، مقارنة
read() واحدة
read() ! لحسن الحظ ، في معظم الحالات ، يقع البحث في
ذاكرة التخزين المؤقت للأسنان ولا يصل إلى SSD. ولكن من الواضح أن معالجة
read() في تجمع مؤشر ترابط ليست سوى نصف الصورة.
الوتر النهائي: مفتوح () لا يحجب في تجمعات الخيوط
لذلك ، قمنا بإجراء تغيير على Nginx بحيث يتم تنفيذ
open() الغالب داخل تجمع سلاسل الرسائل ولا يمنع حلقة الحدث. وهنا نتيجة عدم فتح () وقراءة () في نفس الوقت:
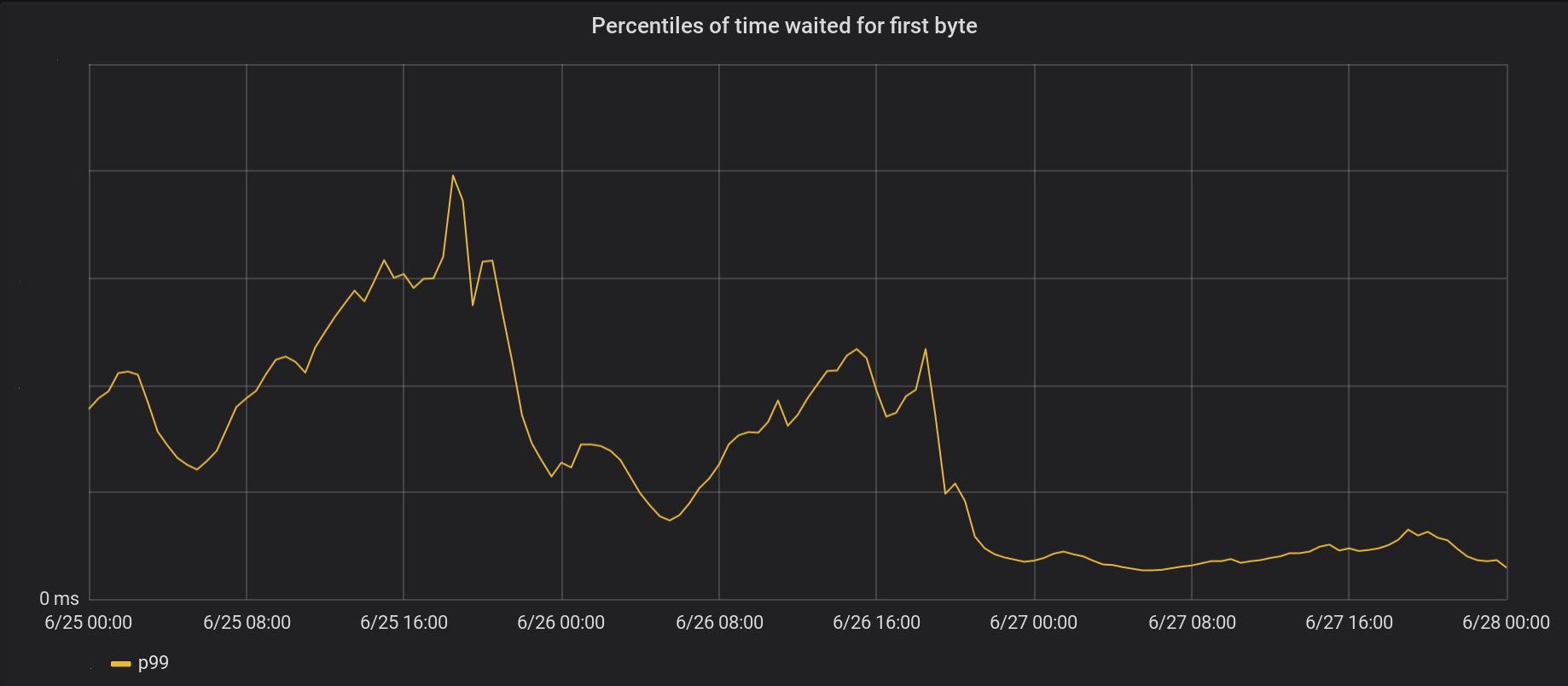
في 26 حزيران (يونيو) ، أجرينا تغييرات على أكثر 5 مراكز بيانات ازدحامًا ، وفي اليوم التالي - إلى جميع مراكز البيانات الأخرى البالغ عددها 146 مركزًا حول العالم. انخفض إجمالي الذروة p99 TTFB بنسبة 6 مرات. في الواقع ، إذا قمنا بتلخيص كل الوقت من معالجة 8 ملايين طلب في الثانية ، فإننا نوفر الإنترنت 54 عامًا من الانتظار كل يوم.
لم تتخلص سلسلة الأحداث لدينا بالكامل بعد من الأقفال. على وجه الخصوص ، لا يزال يحدث الحظر في المرة الأولى التي يتم فيها تخزين الملف مؤقتًا (سواء
open(O_CREAT) وإعادة
rename() ) أو عند تحديث إعادة التحقق. لكن مثل هذه الحالات نادرة مقارنة بوصول ذاكرة التخزين المؤقت. في المستقبل ، سننظر في إمكانية نقل هذه العناصر خارج حلقة معالجة الحدث لزيادة تحسين عامل التأخير p99.
الخلاصة
يعد Nginx نظامًا أساسيًا قويًا ، ولكن يمكن أن يكون توسيع أحمال Linux / I عالية للغاية مهمة شاقة. يقوم Nginx القياسي بإلغاء تحميل القراءة في سلاسل منفصلة ، ولكن على نطاقنا غالبًا ما نحتاج إلى المضي قدمًا خطوة أخرى.