حان الوقت لتجديد البنك الخنزير لتقارير جيدة باللغة الروسية حول تعلم الآلة! لن يتم تجديد البنك أصبع نفسه!
هذه المرة سوف
نتعرف على قصة
أندريه بويروف الرائعة حول التعرف على المشهد. أندري هو باحث في رؤية الكمبيوتر يعمل في مجال رؤية الماكينات في Mail.Ru Group.
يعد التعرف على المشهد أحد المجالات المستخدمة على نطاق واسع في رؤية الماكينة. هذه المهمة أكثر تعقيدًا من التعرف على الأشياء التي تمت دراستها: المشهد هو مفهوم أكثر تعقيدًا وأقل رسمية ، من الصعب التمييز بين الميزات. تأتي مهمة التعرف على المعالم السياحية من التعرف على المشهد: تحتاج إلى تسليط الضوء على الأماكن المعروفة في الصورة ، مما يضمن مستوى منخفض من الإيجابيات الزائفة.
هذه
30 دقيقة من الفيديو من مؤتمر Smart Data 2017. الفيديو مناسب للمشاهدة في المنزل وأثناء التنقل. بالنسبة لأولئك الذين ليسوا على استعداد للجلوس كثيرًا على الشاشة ، أو الذين يفضلون إدراك المعلومات في شكل نص ، نطبق فك تشفير النص الكامل ، المصمم في شكل habrosta.
أفعل رؤية الجهاز في Mail.ru. اليوم سأتحدث عن كيفية استخدامنا للتعلم العميق للتعرف على صور المشاهد والمعالم السياحية.
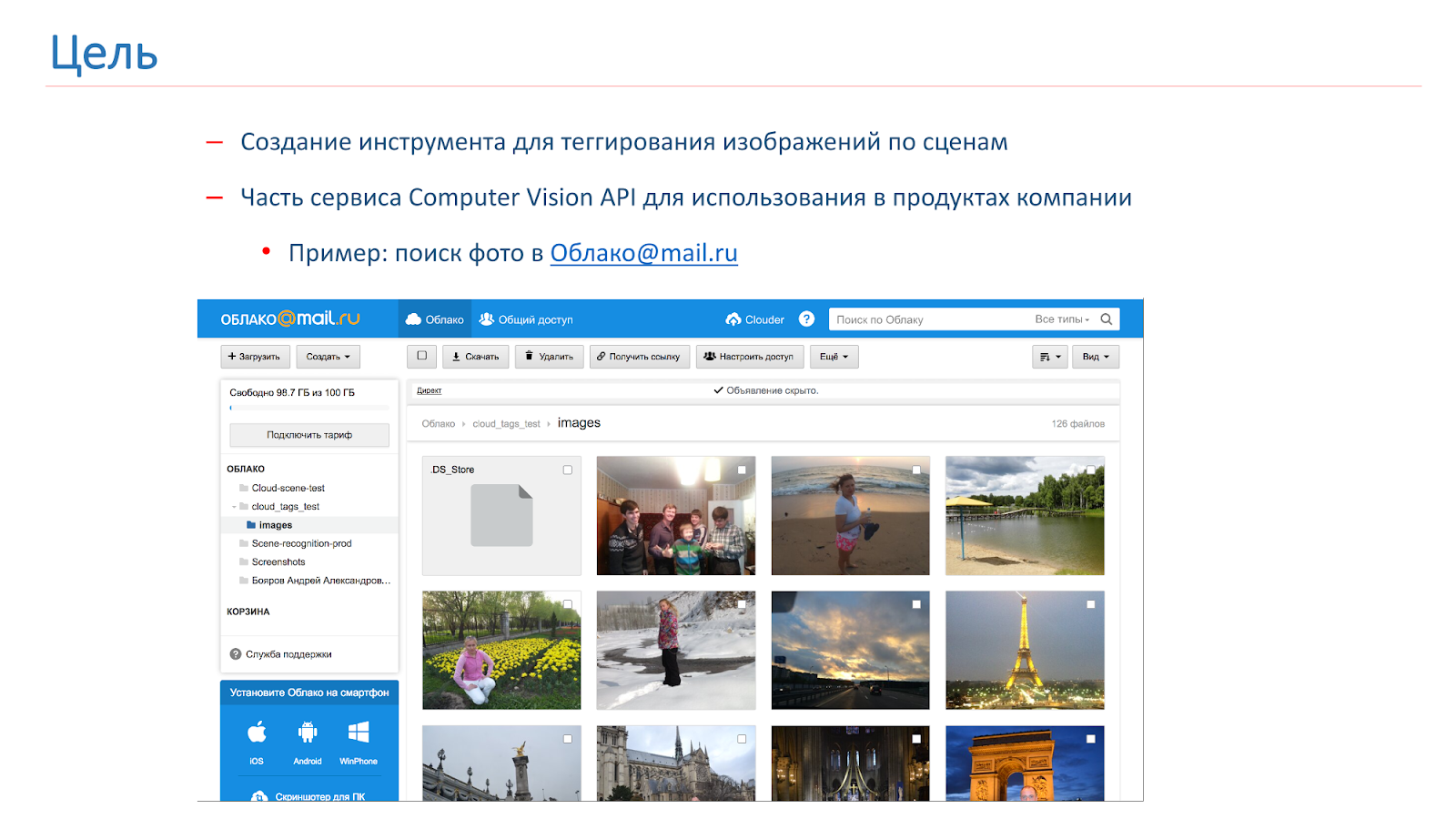
نشأت الشركة عن الحاجة إلى وضع العلامات والبحث بواسطة صور المستخدم ، ولهذا قررنا إنشاء واجهة برمجة تطبيقات Computer Vision الخاصة بنا ، والتي سيكون جزءًا منها أداة لوضع علامات على المشهد. نتيجة لهذه الأداة ، نريد الحصول على شيء مثل ذلك الموضح في الصورة أدناه: يقدم المستخدم طلبًا ، على سبيل المثال ، "كاتدرائية" ، ويتلقى جميع صوره مع الكاتدرائيات.
في مجتمع رؤية الكمبيوتر ، تمت دراسة موضوع التعرف على الأشياء في الصور جيدًا. هناك
مسابقة ImageNet المعروفة التي عقدت لعدة سنوات والجزء الرئيسي منها هو التعرف على الأشياء.
نحن في الأساس بحاجة إلى توطين بعض الكائنات وتصنيفها. مع المشاهد ، تكون المهمة أكثر تعقيدًا إلى حد ما ، لأن المشهد كائن أكثر تعقيدًا ، ويتكون من عدد كبير من الكائنات الأخرى والسياق الذي يوحدها ، لذلك تختلف المهام.

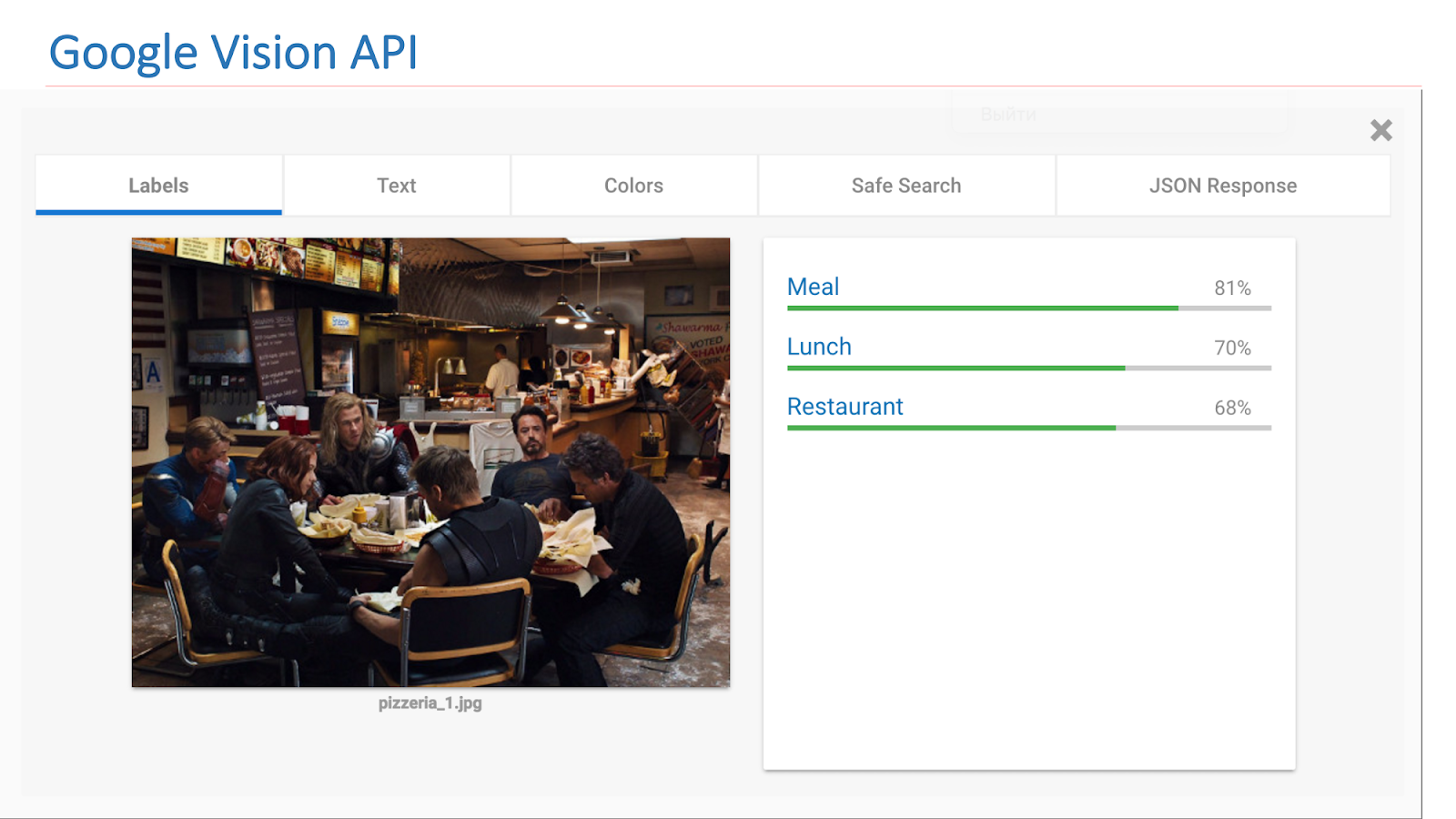
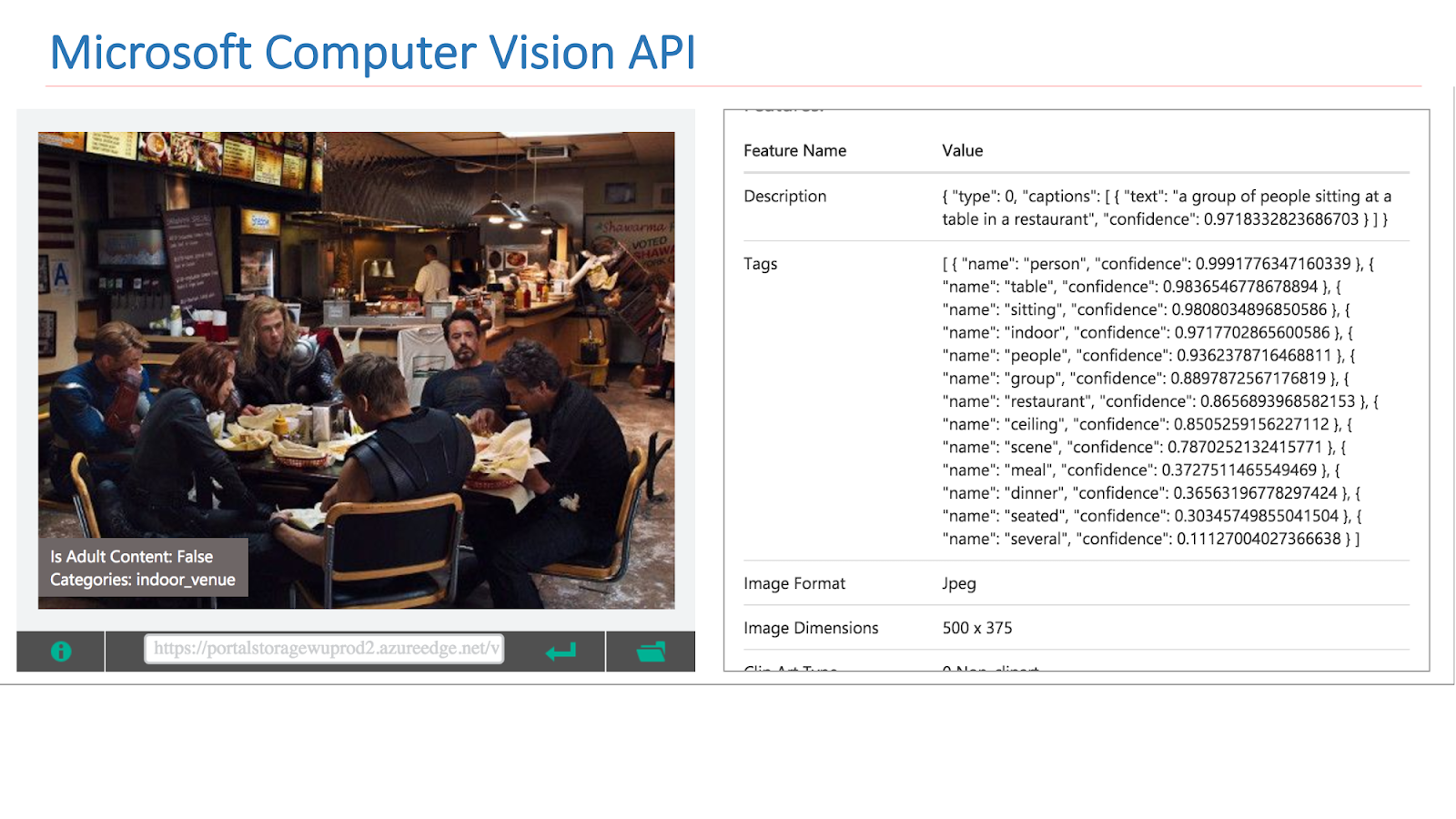
تتوفر على الإنترنت خدمات من شركات أخرى تنفذ مثل هذه الوظائف. على وجه الخصوص ، هذه هي Google Vision API أو Microsoft Computer Vision API ، والتي يمكنها العثور على مشاهد في الصور.
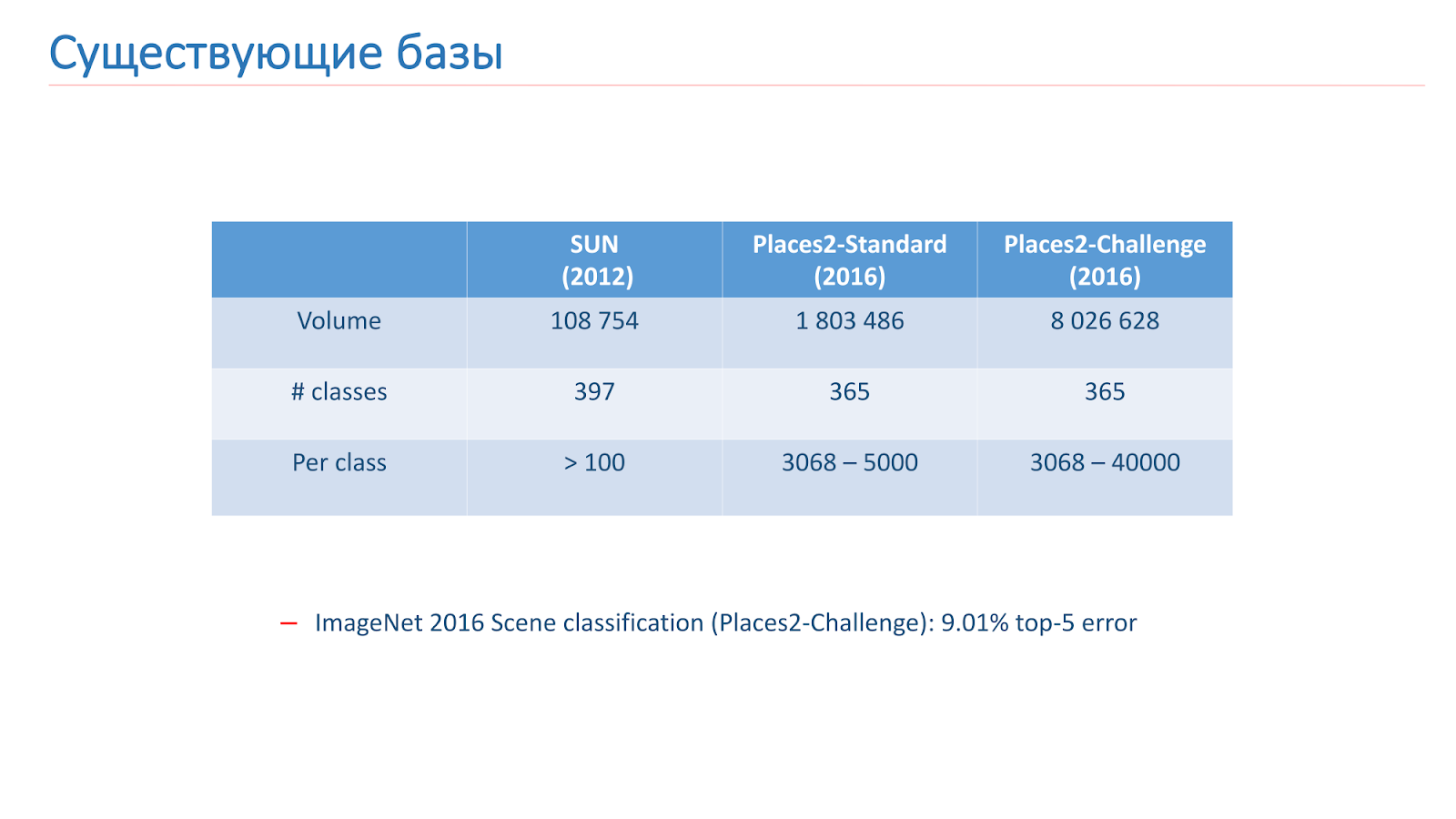
لقد حللنا هذه المشكلة بمساعدة التعلم الآلي ، لذلك نحتاج إلى البيانات. هناك قاعدتان رئيسيتان للتعرف على المشهد في الوصول المفتوح الآن. ظهر أولها في عام 2013 - هذه هي
قاعدة SUN من جامعة برينستون. تتكون هذه القاعدة من مئات الآلاف من الصور و 397 فئة.
القاعدة الثانية التي تدربنا عليها هي
قاعدة Places2 من MIT. ظهرت في 2013 في نسختين. الأول هو Places2-Standart ، قاعدة أكثر توازناً مع 1.8 مليون صورة و 365 فئة. الخيار الثاني - Places2-Challenge ، يحتوي على ثمانية ملايين صورة و 365 فئة ، ولكن عدد الصور بين الفئات غير متوازن. في مسابقة ImageNet لعام 2016 ، تضمن قسم التعرف على المشهد تحدي الأماكن 2 ، وأظهر الفائز أفضل نتيجة
لخطأ أعلى 5 تصنيفات بحوالي 9٪.
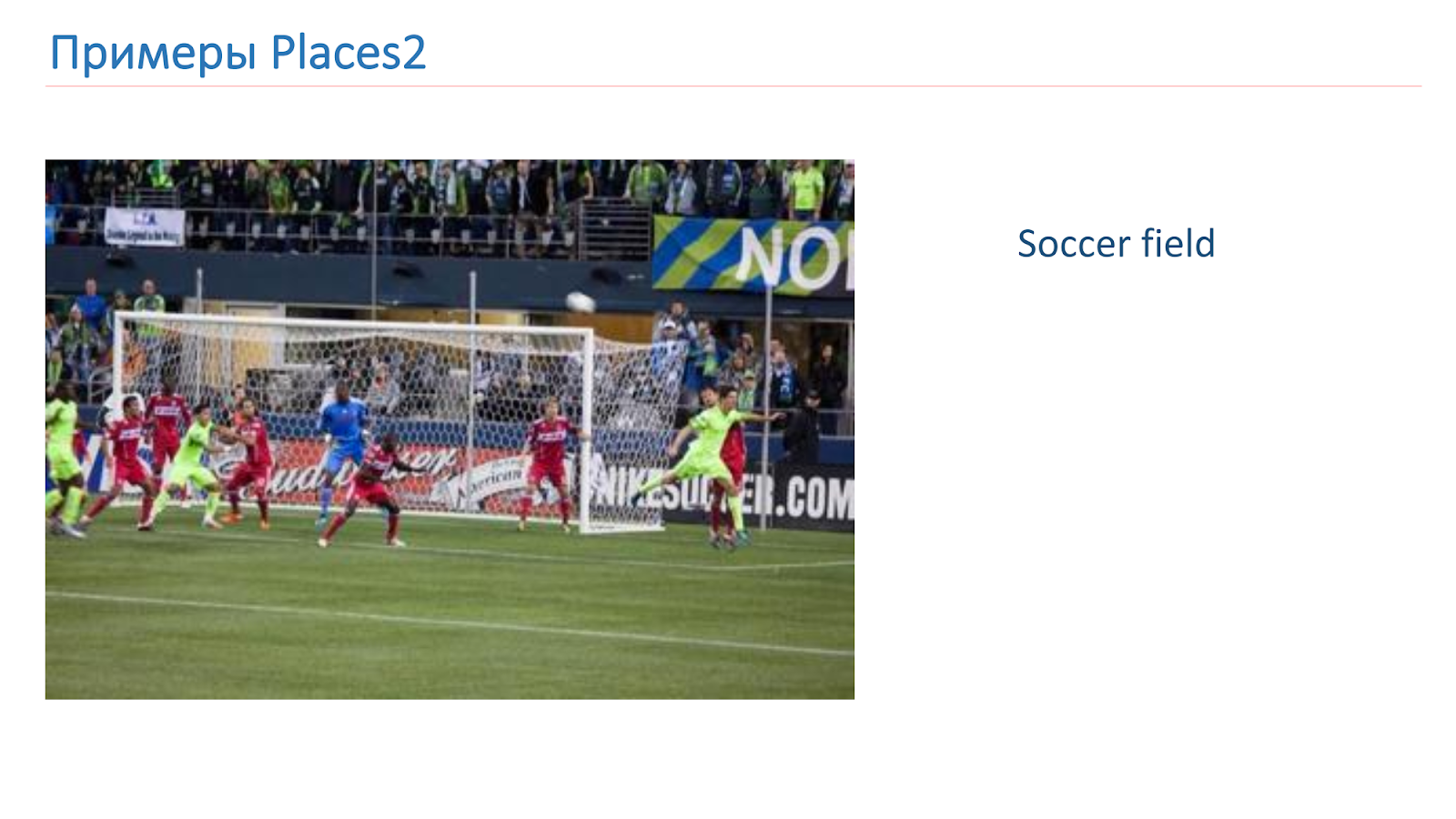
تدربنا على أساس الأماكن 2. هنا مثال للصورة من هناك: إنه الوادي ، المدرج ، المطبخ ، ملعب كرة القدم. هذه أشياء معقدة تمامًا مختلفة يجب أن نتعلم التعرف عليها.

قبل الدراسة ، قمنا بتكييف الأسس التي لدينا لتناسب احتياجاتنا. هناك خدعة للتعرف على الكائنات عند تجربة النماذج على قواعد CIFAR-10 و CIFAR-100 الصغيرة بدلاً من ImageNet ، وعندها فقط يتم تدريب أفضلها على ImageNet.
قررنا أن نسير بنفس الطريقة ، وأخذنا قاعدة بيانات SUN ، وخفضناها ، وحصلنا على 89 فئة ، و 50 ألف صورة في القطار و 10 آلاف صورة عند التحقق. نتيجة لذلك ، قبل التدريب على Places2 ، قمنا بإعداد تجارب واختبار نماذجنا بناءً على SUN. لا يستغرق التدريب على ذلك سوى 6-10 ساعات ، على عكس عدة أيام على الأماكن 2 ، مما سمح بإجراء المزيد من التجارب وجعلها أكثر فعالية.
نظرنا أيضًا إلى قاعدة بيانات Places2 نفسها وأدركنا أننا لسنا بحاجة إلى بعض الفئات. إما بسبب اعتبارات الإنتاج ، أو بسبب قلة البيانات عنها ، قمنا بقطع فئات مثل ، على سبيل المثال ، قناة ، بيت شجرة ، باب حظيرة.

ونتيجة لذلك ، بعد كل التلاعبات ، حصلنا على قاعدة بيانات Places2 ، التي تحتوي على 314 فئة ونصف مليون صورة (في نسختها القياسية) ، في إصدار التحدي حوالي 7.5 مليون صورة. بنينا التدريب على هذه القواعد.
بالإضافة إلى ذلك ، عند عرض الفئات المتبقية ، اكتشفنا أن هناك الكثير منها للإنتاج ، وهي مفصلة للغاية. ولهذا ، قمنا بتطبيق آلية رسم خرائط المشهد عندما يتم دمج بعض الفئات في واحدة مشتركة. على سبيل المثال ، قمنا بربط كل شيء مرتبط بالغابات بغابة ، وكل شيء مرتبط بالمستشفيات - في مستشفى ، بفنادق - في فندق.
نستخدم تعيين المشهد فقط للاختبار وللمستخدم النهائي ، لأنه أكثر ملاءمة. في التدريب ، نستخدم جميع فئات 314 القياسية. أطلقنا على القاعدة الناتجة الأماكن Sift.
النُهج والحلول
الآن فكر في الأساليب التي استخدمناها لحل هذه المشكلة. في الواقع ، ترتبط هذه المهام بالنهج الكلاسيكي - الشبكات العصبية التلافيفية العميقة.
تُظهر الصورة أدناه إحدى الشبكات الكلاسيكية الأولى ، لكنها تحتوي بالفعل على كتل البناء الرئيسية المستخدمة في الشبكات الحديثة.

هذه طبقات تلافيفية ، هذه طبقات سحب ، طبقات متصلة بالكامل. من أجل تحديد الهندسة المعمارية ، قمنا بفحص قمم المسابقات ImageNet و Places2.

يمكننا أن نقول أن البنايات الرئيسية الرئيسية يمكن تقسيمها إلى عائلتين: التأسيس وعائلة ResNet (الشبكة المتبقية). في سياق التجارب ، اكتشفنا أن عائلة ResNet أكثر ملاءمة لمهمتنا ، وقمنا بإجراء التجربة التالية على هذه العائلة.

ResNet هي شبكة عميقة تتكون من عدد كبير من الكتل المتبقية. هذا هو لبنه الأساسي ، والذي يتكون من عدة طبقات مع الأوزان واتصال الاختصار. نتيجة لهذا التصميم ، تتعرف هذه الوحدة على مدى اختلاف إشارة الإدخال x عن الإخراج f (x). ونتيجة لذلك ، يمكننا بناء شبكات من هذه الكتل ، وأثناء التدريب ، يمكن للشبكة في الطبقات الأخيرة أن تجعل الأوزان قريبة من الصفر.
وبالتالي ، يمكننا القول أن الشبكة نفسها تقرر مدى العمق الذي تحتاجه لحل بعض المهام. بفضل هذه البنية ، من الممكن بناء شبكات ذات عمق كبير جدًا مع عدد كبير جدًا من الطبقات. احتوى الفائز في ImageNet 2014 على 22 طبقة فقط ، وتجاوزت ResNet هذه النتيجة وتضمنت بالفعل 152 طبقة.
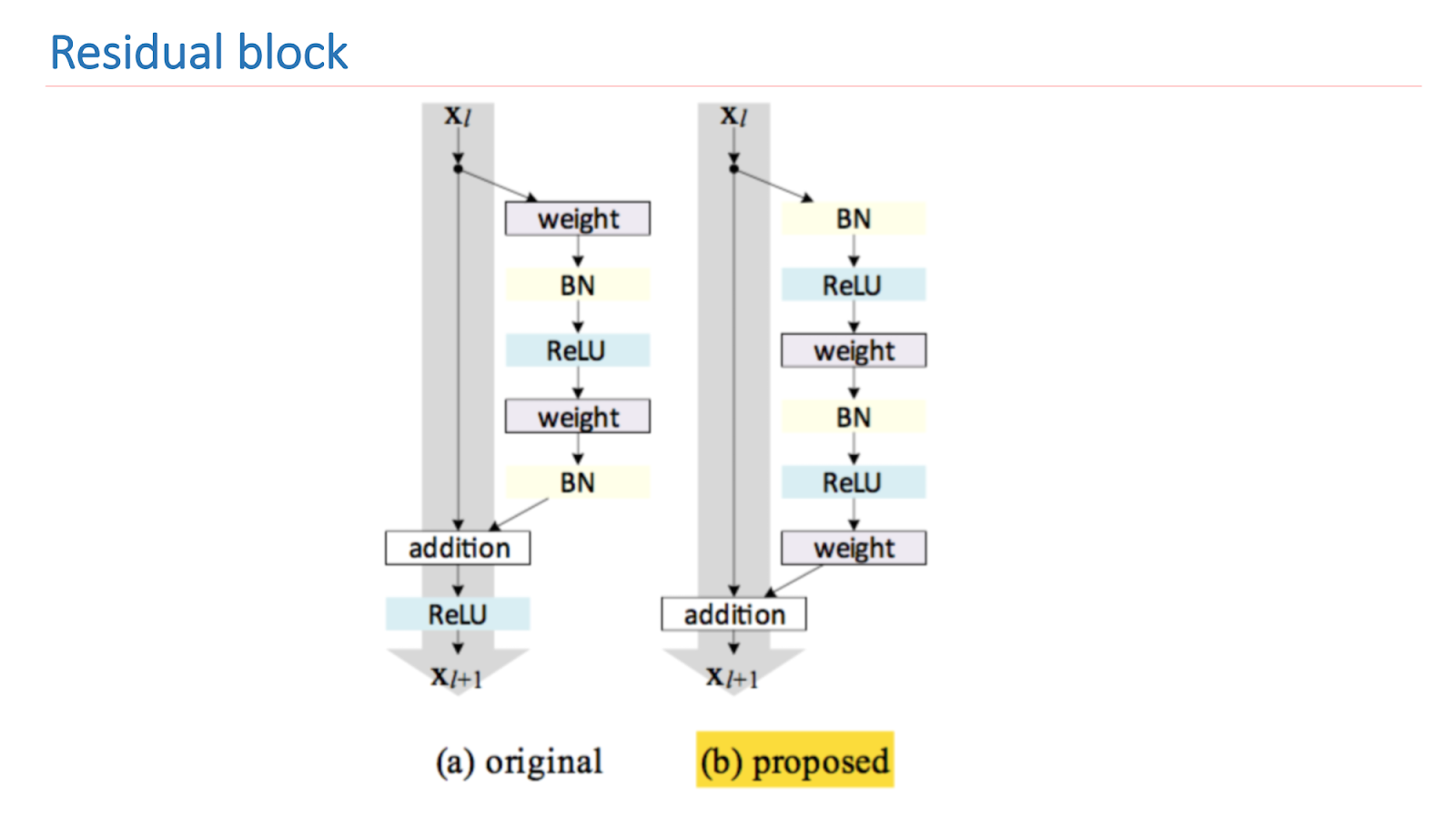
البحث الأساسي لـ ResNet هو تحسين وبناء كتلة متبقية بشكل صحيح. توضح الصورة أدناه إصدارًا صوتيًا تجريبيًا ورياضيًا يعطي أفضل نتيجة. يتيح لك بناء الكتلة هذا التعامل مع إحدى المشاكل الأساسية للتعلم العميق - التدرج المتلاشي.
لتدريب شبكاتنا ، استخدمنا إطار Torch المكتوب بلغة Lua بسبب مرونته وسرعته ، وبالنسبة لـ ResNet ، فقد حرصنا على
تنفيذ ResNet من Facebook . للتحقق من جودة الشبكة ، استخدمنا ثلاثة اختبارات.
أول اختبار Val للأماكن هو التحقق من صحة العديد من مجموعات Places Sift. الاختبار الثاني هو الأماكن Sift باستخدام رسم خرائط المشهد ، والثالث هو اختبار السحابة الأقرب إلى حالة القتال. صور للموظفين مأخوذة من السحابة ويتم تمييزها يدويًا. في الصورة أدناه هناك مثالان لمثل هذه الصور.

بدأنا في قياس وتدريب الشبكات ومقارنتها ببعضها البعض. الأول هو ResNet-152 القياسي ، والذي يأتي مع Places2 ، والثاني هو ResNet-50 ، الذي قمنا بتدريبه على ImageNet ودربناه على قاعدتنا ، وكانت النتيجة أفضل بالفعل. ثم أخذوا ResNet-200 ، وتدربوا أيضًا على ImageNet ، وأظهروا أفضل نتيجة في النهاية.

فيما يلي أمثلة للعمل. هذا هو معيار ResNet-152. المتنبأ بها هي تلك التسميات الأصلية التي تعطيها الشبكة. Lables المعينة هي التسميات التي جاءت بعد Scene Mapping. يمكن ملاحظة أن النتيجة ليست جيدة جدًا. أي أنها تبدو وكأنها تعطي شيئًا بشأن القضية ، ولكن ليس بشكل جيد للغاية.

المثال التالي هو تشغيل ResNet-200. بالفعل كافية للغاية.

تحسين ResNet
قررنا محاولة تحسين شبكتنا ، وفي البداية حاولنا فقط زيادة عمق الشبكة ، ولكن بعد ذلك أصبح التدريب أكثر صعوبة. هذه مشكلة معروفة ، في العام الماضي تم نشر العديد من المقالات حول هذا الموضوع ، والتي تقول أن ResNet ، في الواقع ، هي مجموعة من عدد كبير من الشبكات العادية من أعماق مختلفة.
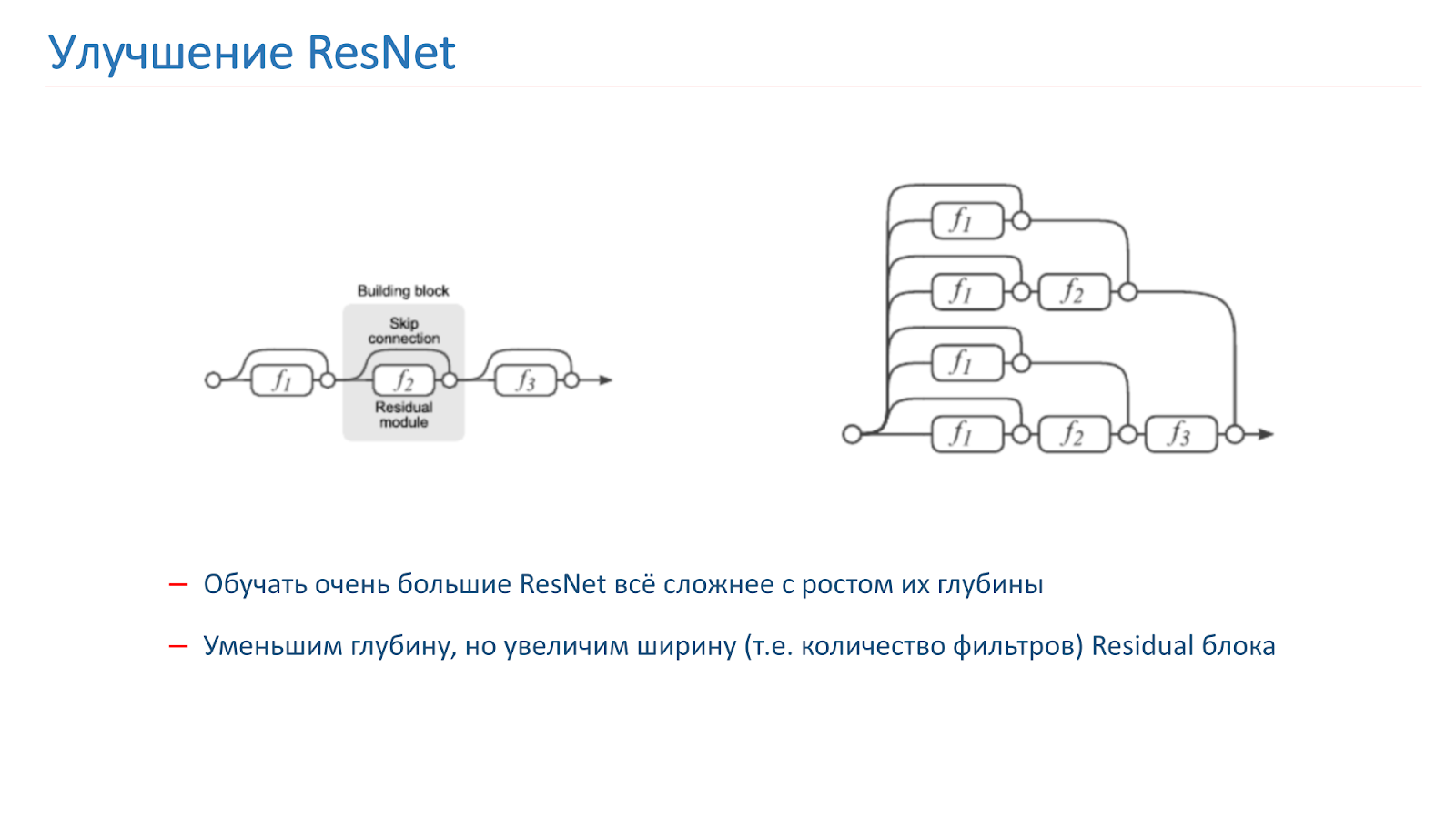
تساهم كتل الدقة ، التي تقع في نهاية الشبكة ، مساهمة صغيرة في تشكيل النتيجة النهائية. يبدو أكثر واعدة لزيادة ليس عمق الشبكة ، ولكن عرضه ، أي عدد المرشحات داخل كتلة الدقة.
يتم تنفيذ هذه الفكرة من قبل شبكة واسعة المتبقية ، والتي ظهرت في عام 2016. انتهى بنا الأمر باستخدام WRN-50-2 ، وهو ResNet-50 المعتاد مع ضعف عدد المرشحات في الالتواء الداخلي 3x3.

تظهر الشبكة على ImageNet نتائج مماثلة مع ResNet-200 ، التي استخدمناها بالفعل ، ولكن الأهم أنها أسرع مرتين تقريبًا. فيما يلي تطبيقان للكتلة المتبقية على Torch ؛ يتم تمييز المعلمة المضاعفة بشكل ساطع. هذا هو عدد الفلاتر في الالتواء الداخلي.

هذه هي القياسات في اختبارات ResNet-200 ImageNet. في البداية أخذنا WRN-22-6 ، أظهر نتيجة أسوأ. ثم أخذوا WRN-50-2-ImageNet ، ودربوه ، وأخذوا WRN-50-2 ، ودربوا على ImageNet ، ودربوه على تحدي الأماكن 2 ، وأظهر أفضل نتيجة.
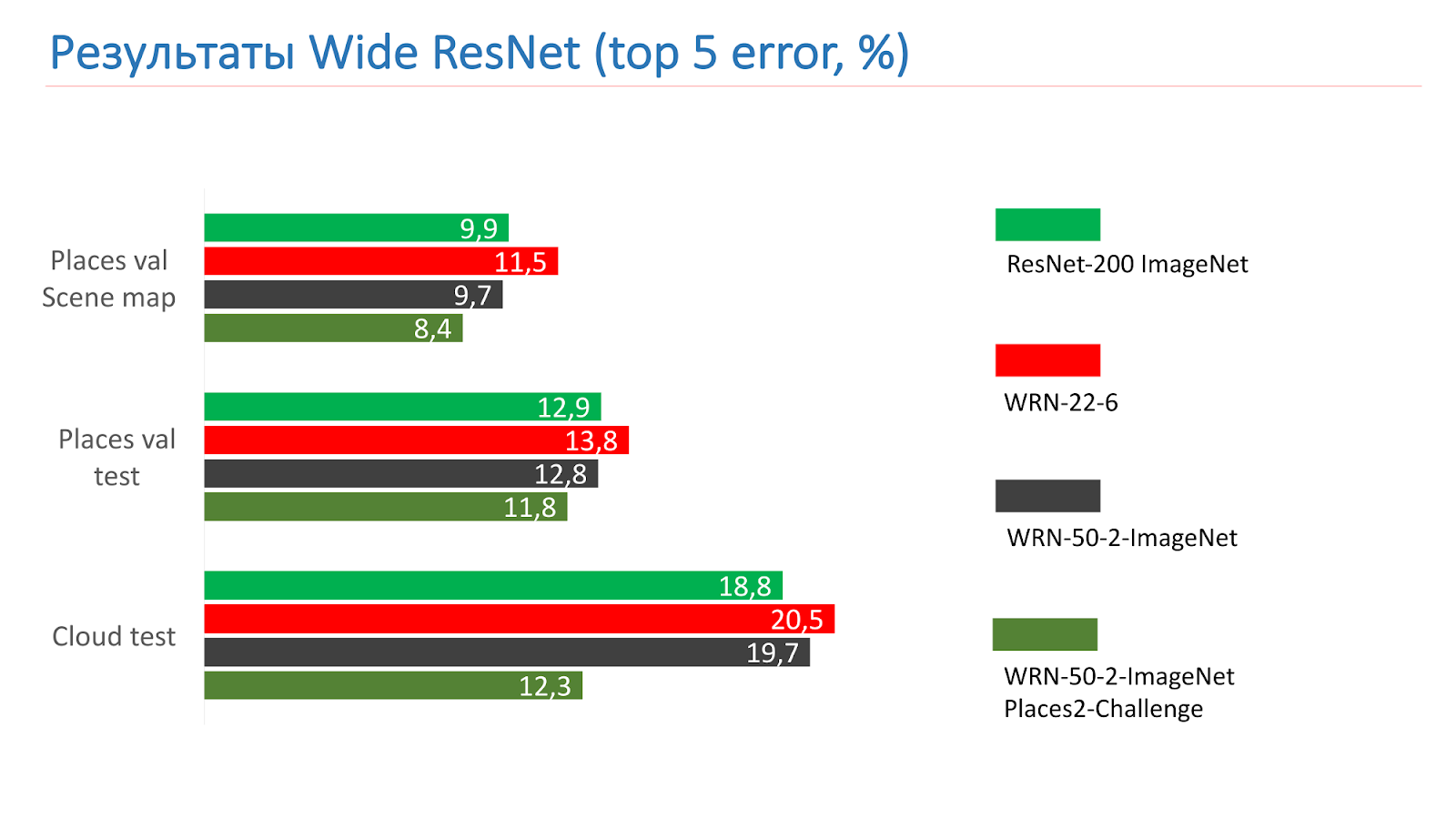
فيما يلي مثال على WRN-50-2 - وهي نتيجة كافية في صورنا التي رأيتها بالفعل.

وهذا مثال على العمل في الصور القتالية بنجاح أيضًا.

بالطبع ، لا توجد أعمال ناجحة للغاية. لم يتم التعرف على جسر ألكسندر الثالث في باريس كجسر.

تحسين النموذج
فكرنا في كيفية تحسين هذا النموذج. تستمر عائلة ResNet في التحسن ، مع ظهور مقالات جديدة. على وجه الخصوص ، في عام 2016 تم نشر مقال مثير للاهتمام PyramidNet ، والذي أظهر نتائج واعدة على CIFAR-10/100 و ImageNet.
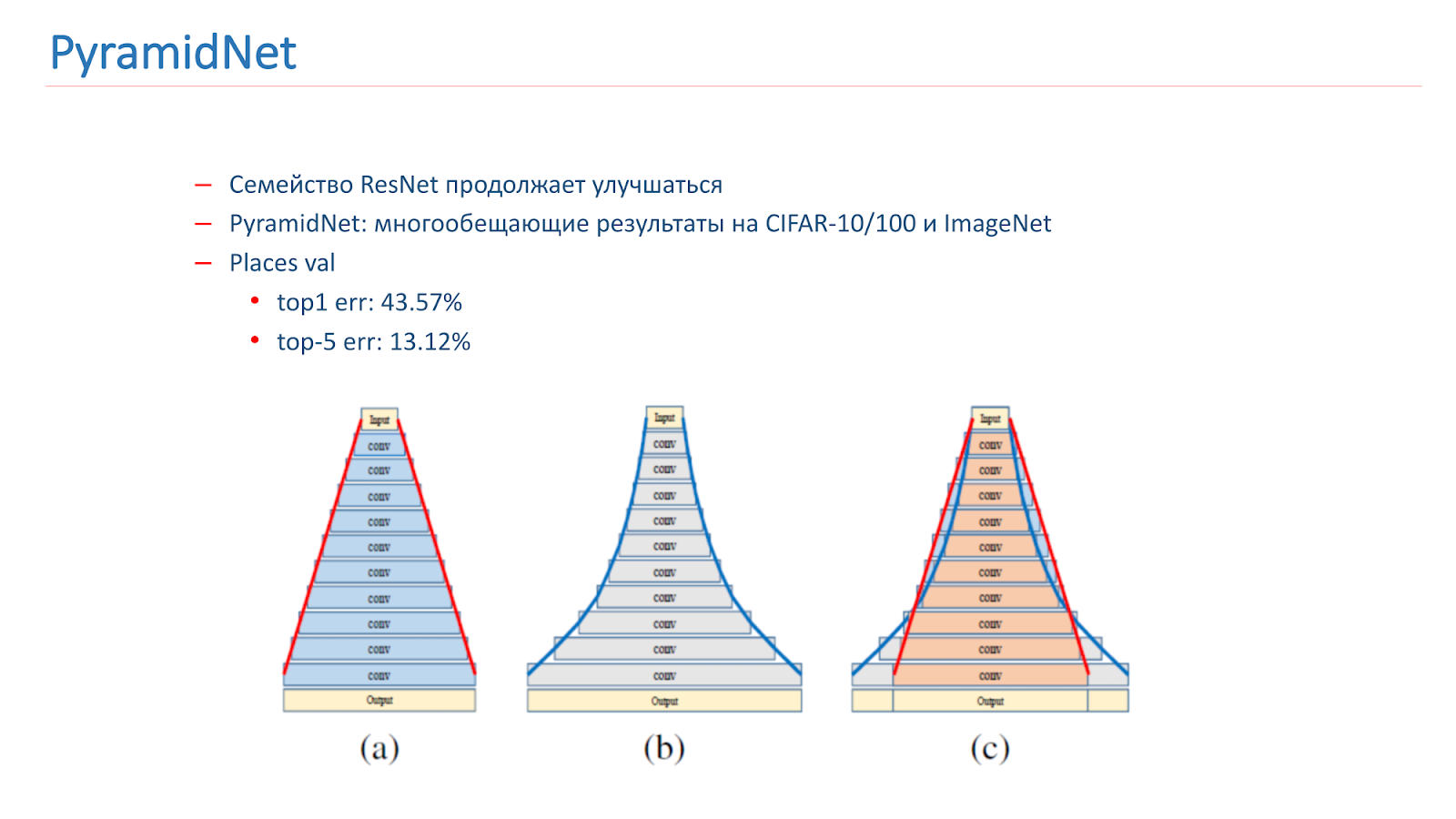
الفكرة ليست زيادة عرض الكتلة المتبقية بشكل حاد ، ولكن القيام بذلك تدريجيًا. لقد قمنا بتدريب العديد من الخيارات لهذه الشبكة ، ولكن للأسف ، أظهرت النتائج أسوأ قليلاً من نموذجنا القتالي.
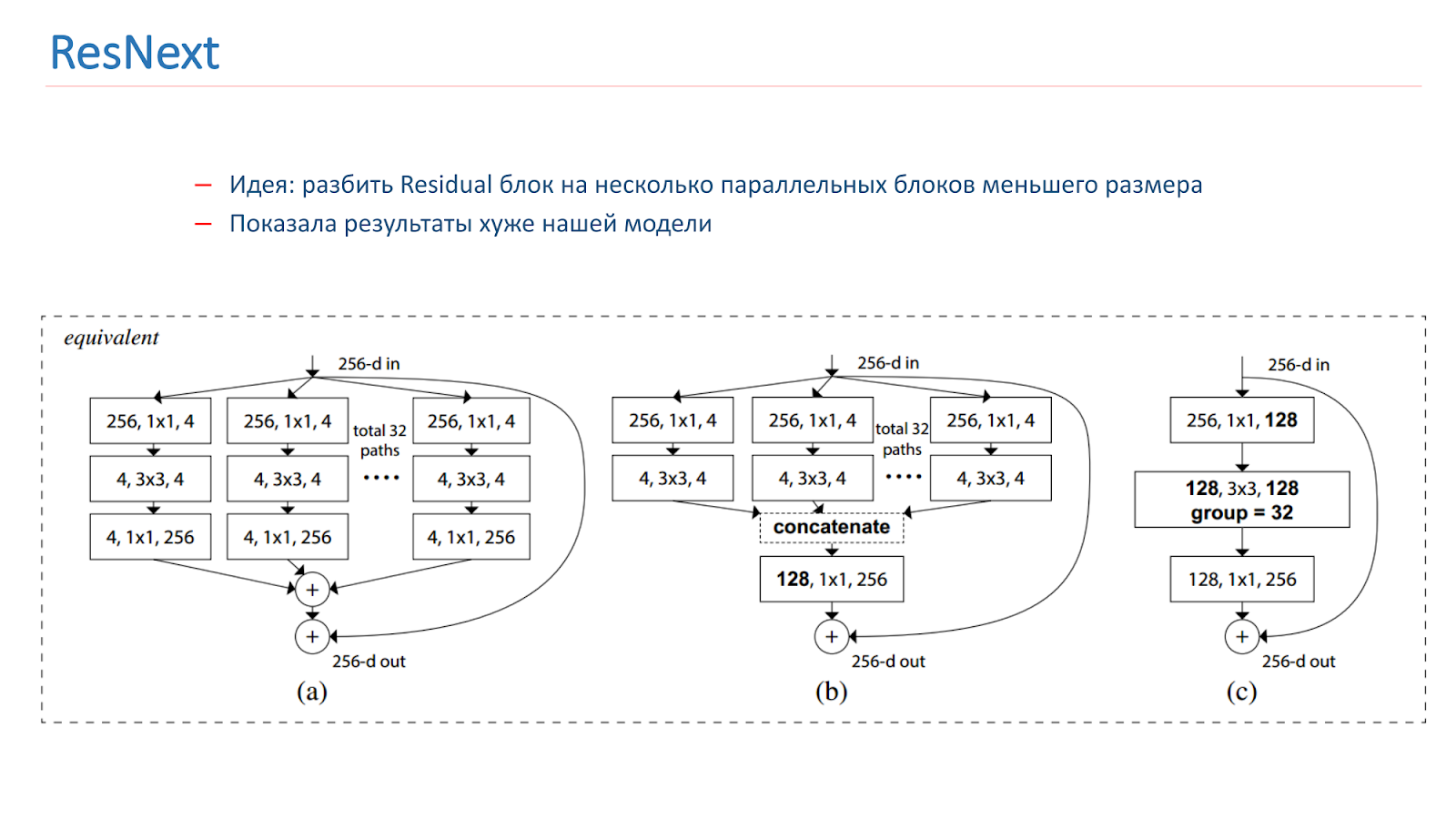
في ربيع عام 2018 ، تم إصدار نموذج ResNext ، وهو أيضًا فكرة واعدة: لتقسيم الكتلة المتبقية إلى عدة كتل متوازية ذات حجم أصغر وعرض أصغر. هذا مشابه لفكرة التأسيس ، جربناها أيضًا. ولكن ، للأسف ، أظهرت نتائج أسوأ من نموذجنا.
لقد جربنا أيضًا العديد من الأساليب "الإبداعية" لتحسين نماذجنا. على وجه الخصوص ، حاولنا استخدام تعيين تنشيط الفصل (CAM) ، أي أن هذه هي الكائنات التي تنظر إليها الشبكة عند تصنيف الصورة.

كانت فكرتنا أن مثيلات المشهد نفسه يجب أن تحتوي على نفس الكائنات أو ما شابه مثل فئة CAM. حاولنا استخدام هذا النهج. في البداية أخذوا شبكتين. الأول هو تدريب ImageNet ، والثاني هو نموذجنا ، الذي نريد تحسينه.

نأخذ الصورة ، ونعمل من خلال الشبكة 2 ، ونضيف CAM للطبقة ، ثم نطعمها لمدخلات الشبكة 1. تشغيل عبر الشبكة 1 ، وإضافة النتائج إلى وظيفة فقدان الشبكة 2 ، ومتابعة ذلك مع وظائف فقدان جديدة.
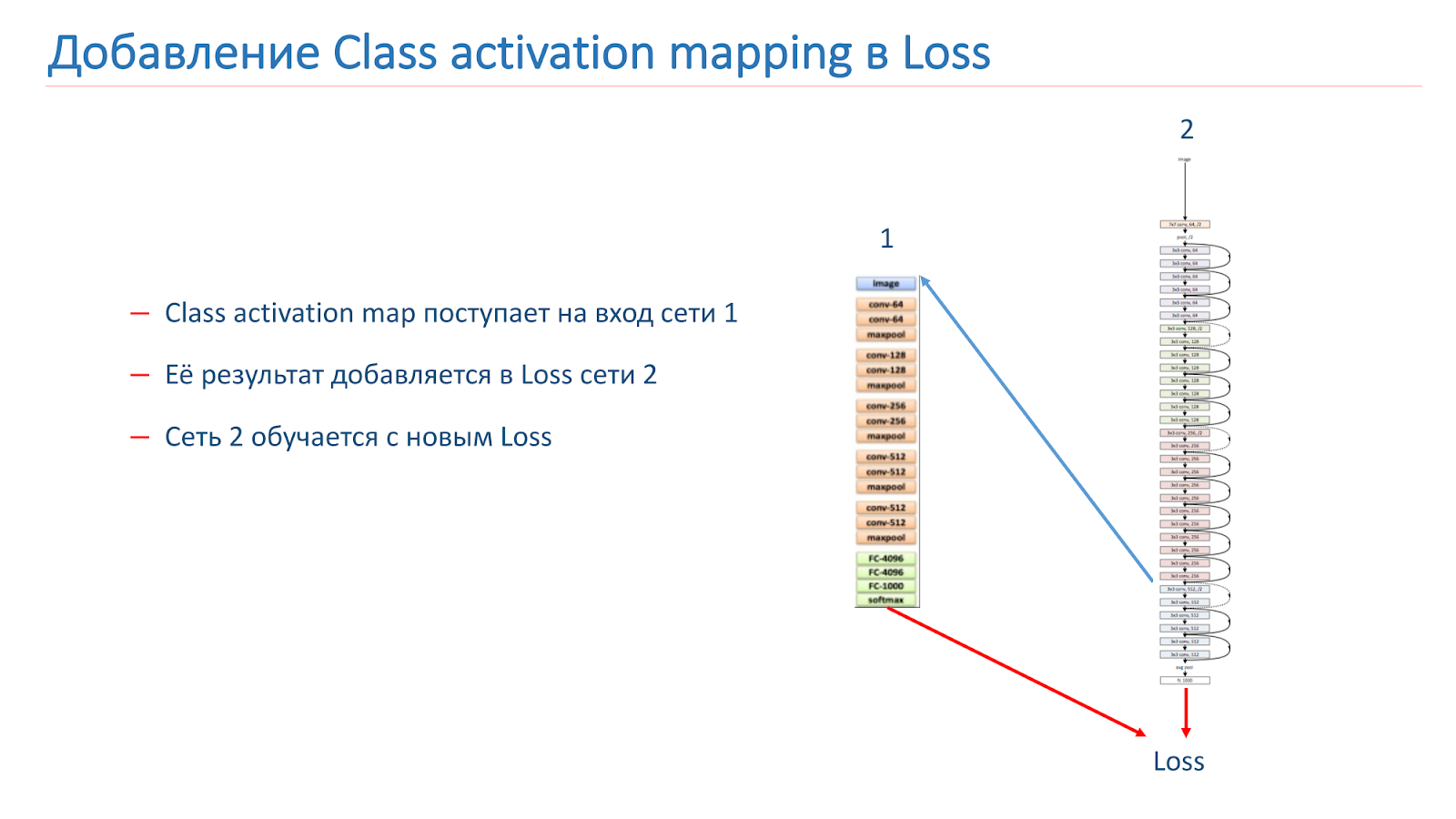
الخيار الثاني هو أننا ندير الصورة من خلال الشبكة 2 ، ونأخذ الكام ، ونغذيها لإدخال الشبكة 1 ، ثم على هذه البيانات نقوم ببساطة بتدريب الشبكة 1 ونستخدم المجموعة من نتائج الشبكة 1 والشبكة 2.
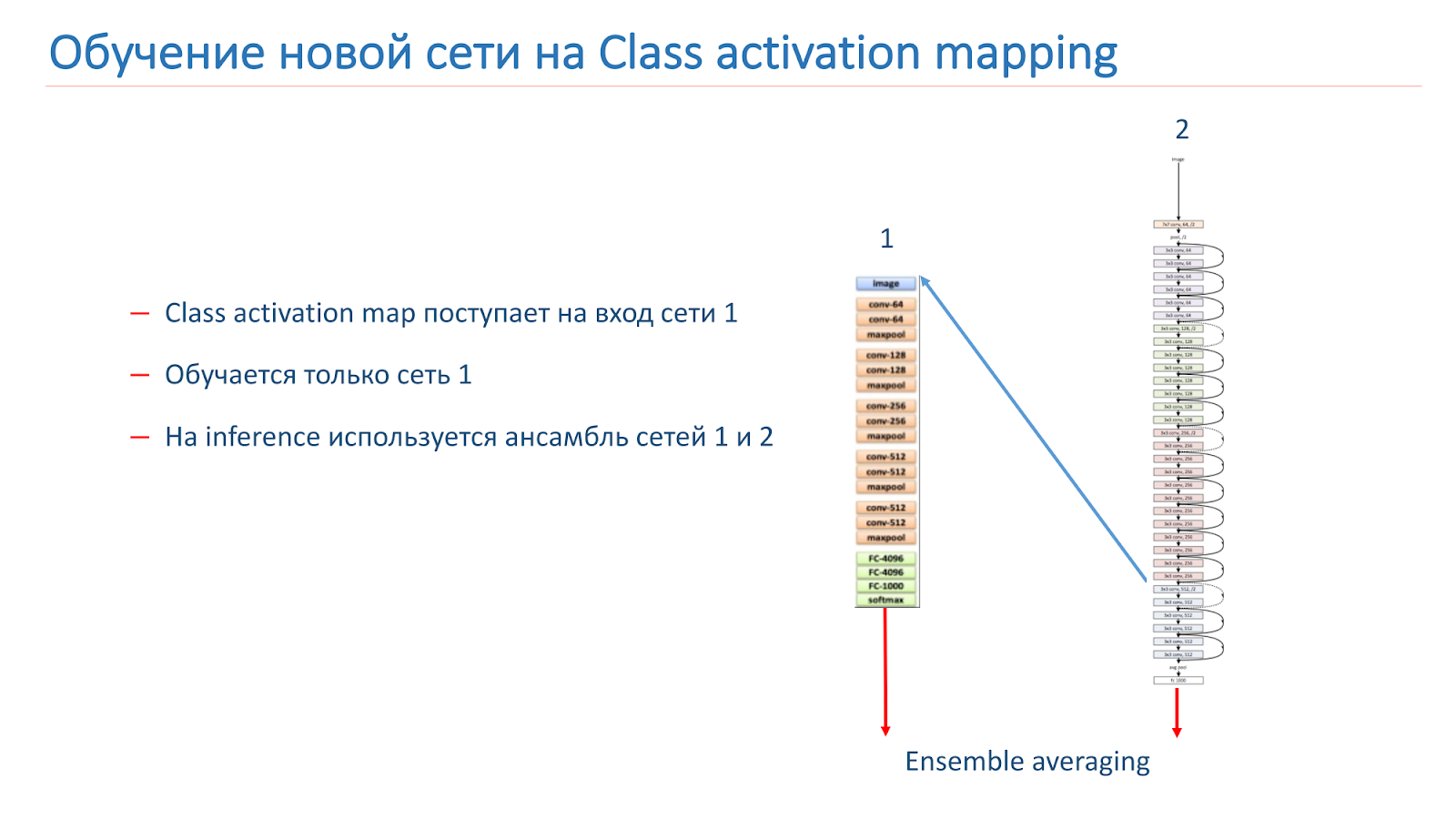
لقد أعدنا تدريب نموذجنا على WRN-50-2 ، حيث إن الشبكة 1 استخدمنا ResNet-50 ImageNet ، ولكن لم يكن من الممكن زيادة جودة نموذجنا بشكل أو بآخر.
لكننا نواصل البحث حول كيفية تحسين نتائجنا: نحن ندرب بنى CNN الجديدة ، ولا سيما عائلة ResNet. نحن نحاول تجربة CAM ونأخذ في الاعتبار طرقًا مختلفة مع معالجة أكثر ذكاءً لصقات الصورة - يبدو لنا أن هذا النهج واعد جدًا.
التعرف على المعالم

لدينا نموذج جيد للتعرف على المشاهد ، لكننا نريد الآن معرفة بعض الأماكن الشهيرة ، أي المعالم السياحية. بالإضافة إلى ذلك ، غالبًا ما يلتقط المستخدمون صورًا لهم أو يلتقطون صورًا على خلفيتهم.
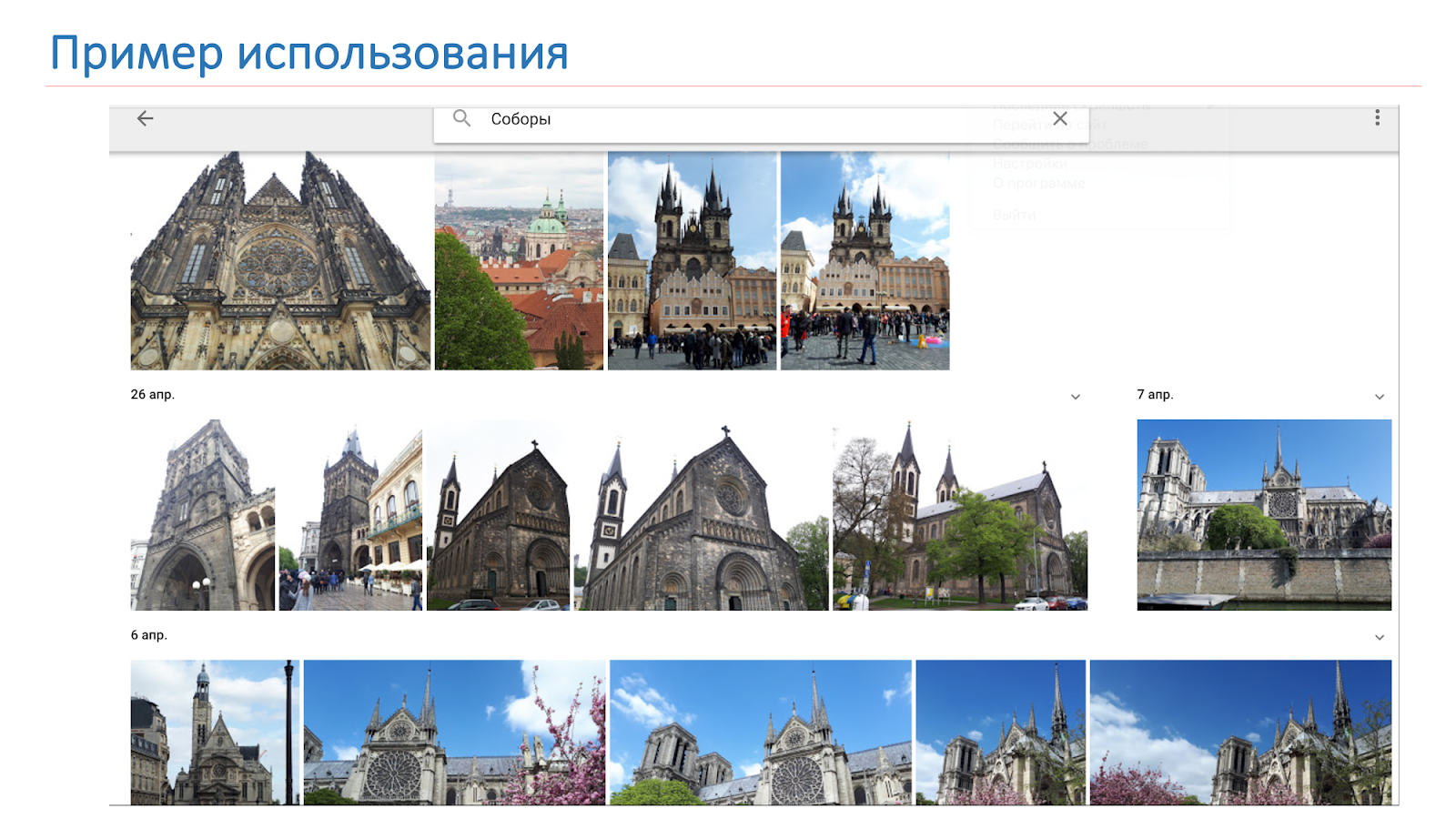
نريد أن تكون النتيجة ليست الكاتدرائيات فقط ، كما في الصورة على الشريحة ، ولكن النظام يقول: "هناك نوتردام دي باريس والكاتدرائيات في براغ".
عندما حللنا هذه المشكلة ، واجهنا بعض الصعوبات.
- لا توجد دراسات حول هذا الموضوع عمليًا ولا توجد بيانات جاهزة في المجال العام.
- عدد صغير من الصور "النظيفة" في المجال العام لكل عنصر جذب.
- ليس من الواضح تمامًا ما هو معلم من المباني. على سبيل المثال ، منزل به أبراج على Sq. ليو تولستوي في بطرسبورغ ، TripAdvisor لا يأخذ في الاعتبار عوامل الجذب ، ولكن Google تعتبره.
بدأنا بجمع قاعدة بيانات وتجميع قائمة تضم 100 مدينة ، ثم استخدمنا واجهة برمجة تطبيقات أماكن Google لتنزيل بيانات JSON للحصول على نقاط اهتمام من هذه المدن.
تم تصفية البيانات وتحليلها ، ووفقًا للقائمة قمنا بتنزيل 20 صورة من بحث Google لكل معلم جذب. الرقم 20 مأخوذ من اعتبارات تجريبية. ونتيجة لذلك ، حصلنا على قاعدة من 2827 معلم جذب وحوالي 56 ألف صورة. هذه هي القاعدة التي قمنا بتدريب نموذجنا عليها. للتحقق من صحة نموذجنا ، استخدمنا اختبارين.
اختبار السحابة - هذه صور من موظفينا ، مصنفة يدويًا. يحتوي على 200 صورة في 15 مدينة و 10 آلاف صورة بدون عوامل جذب. والثاني هو اختبار البحث. تم بناؤه باستخدام بحث Mail.ru ، الذي يحتوي على 3 إلى 10 صور لكل معلم جذب ، ولكن ، للأسف ، هذا الاختبار متسخ.
قمنا بتدريب النماذج الأولى ، لكنهم أظهروا نتائج ضعيفة في اختبار السحابة في الصور القتالية.
هنا مثال للصورة التي تدربنا عليها ، ومثال للتصوير القتالي. المشكلة في الناس هي أنهم غالبًا ما يتم تصويرهم على خلفية المشاهد. في تلك الصور التي حصلنا عليها من البحث ، لم يكن هناك أشخاص.
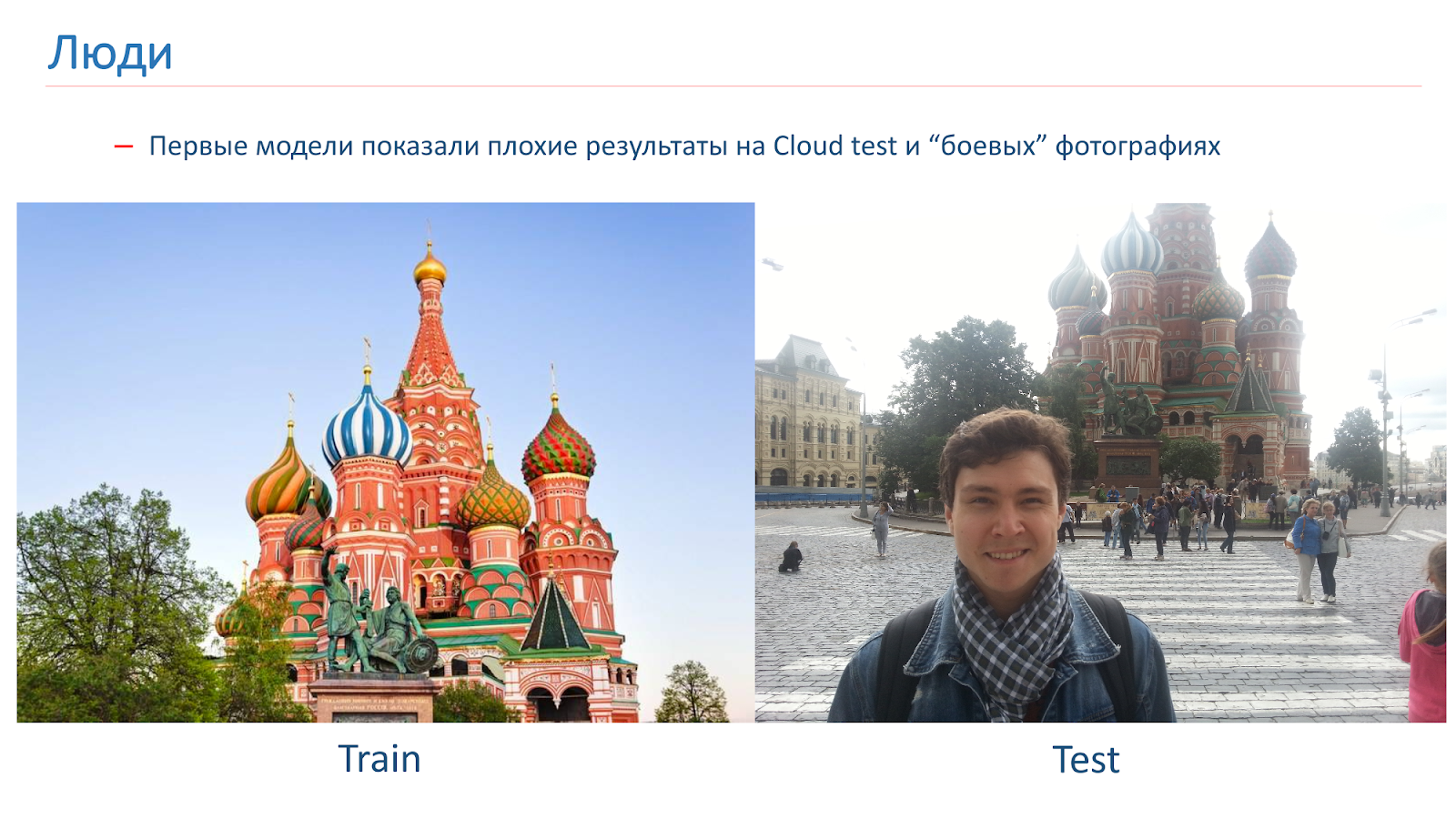
لمكافحة هذا ، أضفنا زيادة "بشرية" أثناء التدريب. أي استخدمنا طرقًا قياسية: التدوير العشوائي ، القطع العشوائي لجزء من الصورة ، وما إلى ذلك. ولكن أيضًا في عملية التعلم ، أضفنا أشخاصًا بشكل عشوائي إلى بعض الصور.

ساعدنا هذا النهج على حل المشكلة مع الناس والحصول على نموذج جودة مقبول.
نماذج مشهد ضبط دقيق
كيف قمنا بتدريب النموذج: هناك بعض قواعد التدريب ، لكنها صغيرة جدًا. لكننا نعلم أن الجذب السياحي هو حالة خاصة للمشهد. ولدينا نموذج مشهد جيد جدًا. قررنا تدريبها على المشاهد. للقيام بذلك ، أضفنا العديد من طبقات BN المتصلة بالكامل أعلى الشبكة ، وقمنا بتدريبها والكتل الثلاثة المتبقية المتبقية. تم تجميد بقية الشبكة.

بالإضافة إلى ذلك ، بالنسبة للتدريب ، نستخدم وظيفة فقدان المركز غير القياسية. أثناء التدريب ، يحاول فقدان المركز "تفكيك" ممثلين من فئات مختلفة في مجموعات مختلفة ، كما هو موضح في الصورة.

في التدريب ، أضفنا فئة أخرى "ليس جاذبية سياحية". وفقدان المركز لم يطبق على هذه الفئة. على وظيفة الخسارة المختلطة هذه ، تم إجراء التدريب.
بعد تدريبنا على الشبكة ، نقطع آخر طبقة تصنيف منها ، وعندما تمر الصورة عبر الشبكة ، تتحول إلى ناقل رقمي يسمى التضمين.
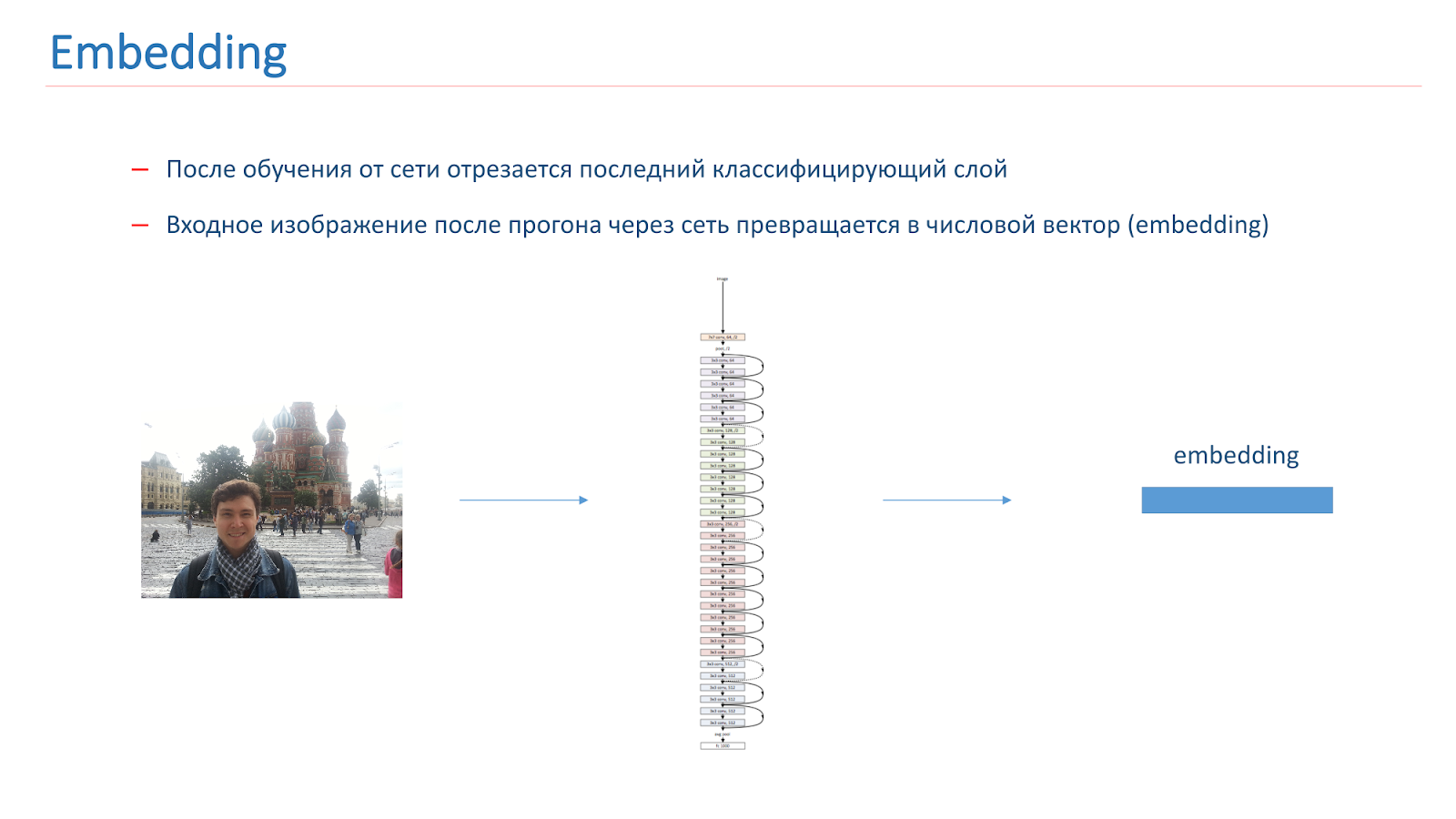
لمزيد من بناء نظام التعرف التاريخي ، قمنا ببناء ناقلات مرجعية لكل فئة. أخذنا كل فئة من عوامل الجذب من الجمهور وقمنا بتشغيل الصور عبر الشبكة. حصلوا على التضمين وأخذوا ناقلاتهم الوسطى ، والتي كانت تسمى ناقل المرجع الطبقي.

لتحديد المعالم في الصورة ، نقوم بتشغيل صورة الإدخال عبر الشبكة ، ويقارن التضمين مع المتجه المرجعي لكل فئة. إذا كانت نتيجة المقارنة أقل من العتبة ، فنحن نعتقد أنه لا توجد نقطة اهتمام بالصورة. خلاف ذلك ، نحن نأخذ الفصل بأعلى قيمة مقارنة.
نتائج الاختبار
- في الاختبار السحابي ، كانت دقة المشاهد 0.616 ، وليس المشاهد - 0.981
- تم الحصول على متوسط دقة 0.669 في اختبار البحث ، وكان متوسط الاكتمال 0.576.
على Search ، لم يحصلوا على نتائج جيدة جدًا ، ولكن هذا يفسر حقيقة أن الأول "قذر" تمامًا ، والثاني يحتوي على ميزات - من بين مناطق الجذب هناك حدائق نباتية مختلفة متشابهة في جميع المدن.
كانت هناك فكرة للتعرف على المشهد لتدريب الشبكة أولاً ، والتي ستحدد قناع المشهد ، أي إزالة الكائنات من المقدمة منها ، ثم إدخالها في النموذج نفسه ، الذي يتعرف على مشاهد الصورة بدون هذه المناطق ، حيث يتم إعاقة الخلفية. ولكن ليس من الواضح ما الذي يجب إزالته بالضبط من الطبقة الأمامية ، ما هو القناع المطلوب.
سيكون الأمر معقدًا وذكيًا إلى حد ما ، لأنه لا يفهم الجميع الأشياء التي تنتمي إلى المشهد وأيها غير ضروري. على سبيل المثال ، قد تكون هناك حاجة للأشخاص في المطعم. هذا قرار غير تافه ، حاولنا القيام بشيء مماثل ، لكنه لم يعط نتائج جيدة.
هنا مثال للعمل في الصور القتالية.
أمثلة على العمل الناجح:


لكن الوظيفة الفاشلة: لم يتم العثور على مشاهد. المشكلة الرئيسية لنموذجنا في الوقت الحالي ليست أن الشبكة تربك المشاهد ، ولكنها لا تجدها في الصورة.

في المستقبل ، نخطط لجمع قاعدة لعدد أكبر من المدن ، والعثور على طرق جديدة لتدريب الشبكة لهذه المهمة ، وتحديد إمكانيات زيادة عدد الفصول دون إعادة تدريب الشبكة.
الاستنتاجات
نحن اليوم:
- نظرنا في مجموعات البيانات المتاحة للتعرف على المشهد ؛
- رأينا أن الشبكة الواسعة المتبقية هي أفضل نموذج ؛
- ناقش المزيد من الاحتمالات لزيادة جودة هذا النموذج ؛
- نظرنا في مهمة التعرف على المشاهد ، ما هي الصعوبات التي تنشأ ؛
- وصفنا خوارزمية جمع القاعدة وطرق التدريس للنموذج للتعرف على عوامل الجذب.
أستطيع أن أقول إن المهام مثيرة للاهتمام ، ولكن لم تتم دراستها إلا قليلاً في المجتمع. من المثير للاهتمام التعامل معها ، لأنه يمكنك تطبيق مناهج غير قياسية لا يتم تطبيقها في التعرف المعتاد على الأشياء.دقيقة من الدعاية. إذا أعجبك هذا التقرير من مؤتمر SmartData ، يرجى ملاحظة أنه سيتم عقد SmartData 2018 في سان بطرسبرج في 15 أكتوبر ، وهو مؤتمر لأولئك المنغمسين في عالم التعلم الآلي والتحليل ومعالجة البيانات. سيحتوي البرنامج على الكثير من الأشياء المثيرة للاهتمام ، يحتوي الموقع بالفعل على المتحدثين والتقارير الأولى.