منذ بعض الوقت ، ظهر رابط على خلاصتي على Facebook إلى كتاب Andrew Ng's Learning Learning Yearning ، والذي يمكن ترجمته على أنه شغف التعلم الآلي أو العطش الآلي للتعلم.

لا يحتاج الأشخاص المهتمون بتعلم الآلة أو العمل في هذا المجال إلى تقديم أندرو. بالنسبة للمبتدئين ، يكفي القول أنه نجم عالمي المستوى في مجال الذكاء الاصطناعي. عالم ، مهندس ، رائد أعمال ، أحد مؤسسي Coursera . وهو مؤلف مقدمة ممتازة لتعلم الآلة والدورات التي تشكل تخصص التعلم العميق .
لدي احترام عميق لأندرو ، فقد أخذت دوراته ، لذلك قررت على الفور قراءة الكتاب المنشور. اتضح أن الكتاب لم يكتب بعد وينشر في أجزاء ، كما كتبه المؤلف. بشكل عام ، هذا ليس حتى كتابًا ، ولكن مسودة كتاب مستقبلي (ما إذا كان سيتم نشره في شكل ورقي غير معروف). ثم جاءت الفكرة لترجمة الفصول التي تم نشرها. يُترجم حاليًا 14 فصلاً (هذا هو المقتطف الأول المنشور من الكتاب). أخطط لمواصلة هذا العمل وترجمة الكتاب بأكمله. سوف أنشر فصولاً مترجمة في مدونتي عن حبري.
في وقت كتابة هذه السطور ، نشر المؤلف 52 فصلاً من أصل 56 تصورًا (وصل إشعار جاهزية 52 فصلاً إلى بريدي في 4 يوليو). يمكن تنزيل جميع الفصول المتاحة حاليًا هنا أو العثور عليها على الإنترنت بنفسك.
قبل نشر ترجمتي ، بحثت عن ترجمات أخرى ، وجدت هذه الترجمة ، المنشورة أيضًا على حبري. صحيح ، تمت ترجمة الفصول السبعة الأولى فقط. لا أستطيع أن أحكم على الترجمة التي هي أفضل. لا أنا ولا إلياسافونوف (كما أشعر من القراءة) هم مترجمون محترفون. أنا أحب بعض الأجزاء أكثر ، إليا بعض. في مقدمة إيليا ، يمكنك قراءة تفاصيل مثيرة للاهتمام حول الكتاب ، والتي حذفتها.
أنشر ترجمي دون تدقيق ، "من الفرن" ، أخطط للعودة إلى بعض الأماكن وتصحيحها (وهذا ينطبق بشكل خاص على الارتباك مع مجموعات بيانات القطار / التطوير / الاختبار). سأكون ممتنا إذا ما تم إبداء التعليقات على النمط والأخطاء وما إلى ذلك ، بالإضافة إلى المعلومات المتعلقة بنص المؤلف.
جميع الصور أصلية (من أندرو إيون) ، بدونها سيكون الكتاب أكثر مللاً.
لذلك ، بالنسبة للكتاب:
الفصل 1. لماذا نحتاج إلى استراتيجية التعلم الآلي؟
يعتبر التعلم الآلي في قلب التطبيقات المهمة التي لا تعد ولا تحصى ، بما في ذلك بحث الويب والبريد الإلكتروني لمكافحة البريد العشوائي والتعرف على الكلام وتوصيات المنتجات وغيرها. أفترض أنك أو فريقك تعمل على تطبيقات التعلم الآلي. وأنك تريد تسريع تقدمك في هذا العمل. هذا الكتاب سيساعدك على القيام بذلك.
مثال: إنشاء بدء تشغيل التعرف على صور القطط
لنفترض أنك تعمل في شركة ناشئة تعالج مجموعة لا نهائية من صور القط لمحبي القطط.

تستخدم شبكة عصبية لبناء نظام رؤية للكمبيوتر للتعرف على القطط في الصور الفوتوغرافية.
ولكن لسوء الحظ ، فإن جودة خوارزمية التعلم الخاصة بك لا تزال غير جيدة بما فيه الكفاية والضغط الهائل عليك هو تحسين كاشف القط.
ماذا تفعل
لدى فريقك العديد من الأفكار ، مثل:
- احصل على المزيد من البيانات: اجمع المزيد من صور القطط.
- اجمع مجموعة بيانات غير متجانسة. على سبيل المثال ، صور القطط في أوضاع غير عادية ؛ صور القطط ذات التلوين غير المعتاد ؛ صور مع إعدادات الكاميرا المختلفة ؛ ...
- قم بتدريب الخوارزمية لفترة أطول عن طريق زيادة عدد تكرارات هبوط التدرج
- حاول زيادة الشبكة العصبية ، مع الكثير من الطبقات / الخلايا العصبية / المعلمات المخفية.
- حاول تقليل الشبكة العصبية.
- حاول إضافة تسوية (مثل تسوية L2)
- تغيير بنية الشبكة العصبية (وظيفة التنشيط ، وعدد الخلايا العصبية المخفية ، وما إلى ذلك)
- ...
إذا اخترت بنجاح بين هذه الاتجاهات المحتملة ، فسوف تبني منصة رائدة لمعالجة صور القطط وتقود شركتك إلى النجاح. إذا كان اختيارك غير ناجح ، فقد تفقد أشهرًا من العمل دون جدوى.
ماذا تفعل؟
سيخبرك هذا الكتاب كيف.
تحتوي معظم مهام تعلُّم الآلة على تلميحات يمكن أن تخبرك بما قد يكون من المفيد أن تجربه وما هو غير المجرب. إذا تعلمت قراءة هذه النصائح ، يمكنك توفير شهور وسنوات من التطوير.
2. كيفية استخدام هذا الكتاب لمساعدة فريقك على العمل
بعد الانتهاء من قراءة هذا الكتاب ، سيكون لديك فهم عميق لكيفية اختيار الاتجاه الفني لمشروع التعلم الآلي.
ولكن قد لا يكون واضحًا لزملائك في الفريق لماذا توصي باتجاه معين. ربما تريد أن يستخدم فريقك مقياسًا من معلمة واحدة في تقييم جودة الخوارزمية ، لكن الزملاء ليسوا متأكدين من أن هذه فكرة جيدة. كيف تقنعهم؟
لهذا السبب قمت باختصار الفصول: بحيث يمكنك طباعتها وإعطاء زملائك صفحة أو صفحتين تحتوي على المواد التي تحتاجها لتعريف الفريق بها.
يمكن أن يكون للتغييرات الصغيرة في تحديد الأولويات تأثير كبير على إنتاجية فريقك. للمساعدة في هذه التغييرات الصغيرة ، آمل أن تتمكن من أن تصبح بطل فريقك!

3. الخلفية والملاحظات
إذا أكملت دورة تعلم الآلة ، مثل دورة التعلم الآلي MOOC في Coursera ، أو إذا كانت لديك خبرة في تعليم الخوارزميات مع المعلم ، فلن يكون من الصعب عليك فهم هذا النص.
أفترض أنك على دراية بـ "تدريب المعلمين": تعلم وظيفة تربط x بـ y باستخدام أمثلة تدريب مصنفة (x، y). تشمل خوارزميات التعلم مع المعلم الانحدار الخطي والانحدار اللوجستي والشبكات العصبية وغيرها. اليوم ، هناك العديد من الأشكال والأساليب للتعلم الآلي ، ولكن معظم النهج ذات الأهمية العملية مستمدة من خوارزميات الفصل "التعلم مع المعلم".
سوف أشير غالبًا إلى الشبكات العصبية (إلى "التعلم العميق"). ما عليك سوى الأفكار الأساسية حول ماهية فهم هذا النص.
إذا لم تكن على دراية بالمفاهيم المذكورة هنا ، شاهد فيديو الأسابيع الثلاثة الأولى من دورة التعلم الآلي في Coursera http://ml-class.org/
4. شريط التقدم في التعلم الآلي
توجد العديد من الأفكار للتعلم العميق (الشبكات العصبية) منذ عقود. لماذا ارتفعت هذه الأفكار اليوم فقط؟
أكبر محركين للتقدم الأخير هما:
- توفر البيانات اليوم ، يقضي الأشخاص الكثير من الوقت مع أجهزة الكمبيوتر (أجهزة الكمبيوتر المحمولة والأجهزة المحمولة). يولد نشاطهم الرقمي كميات هائلة من البيانات التي يمكن أن نطعمها لخوارزميات التعلم لدينا.
- القوة الحاسوبية قبل بضع سنوات فقط أصبح من الممكن تدريب الشبكات العصبية ذات الحجم الكبير بما يكفي ، مما يتيح لك الحصول على فوائد استخدام مجموعات البيانات الضخمة التي كانت لدينا.
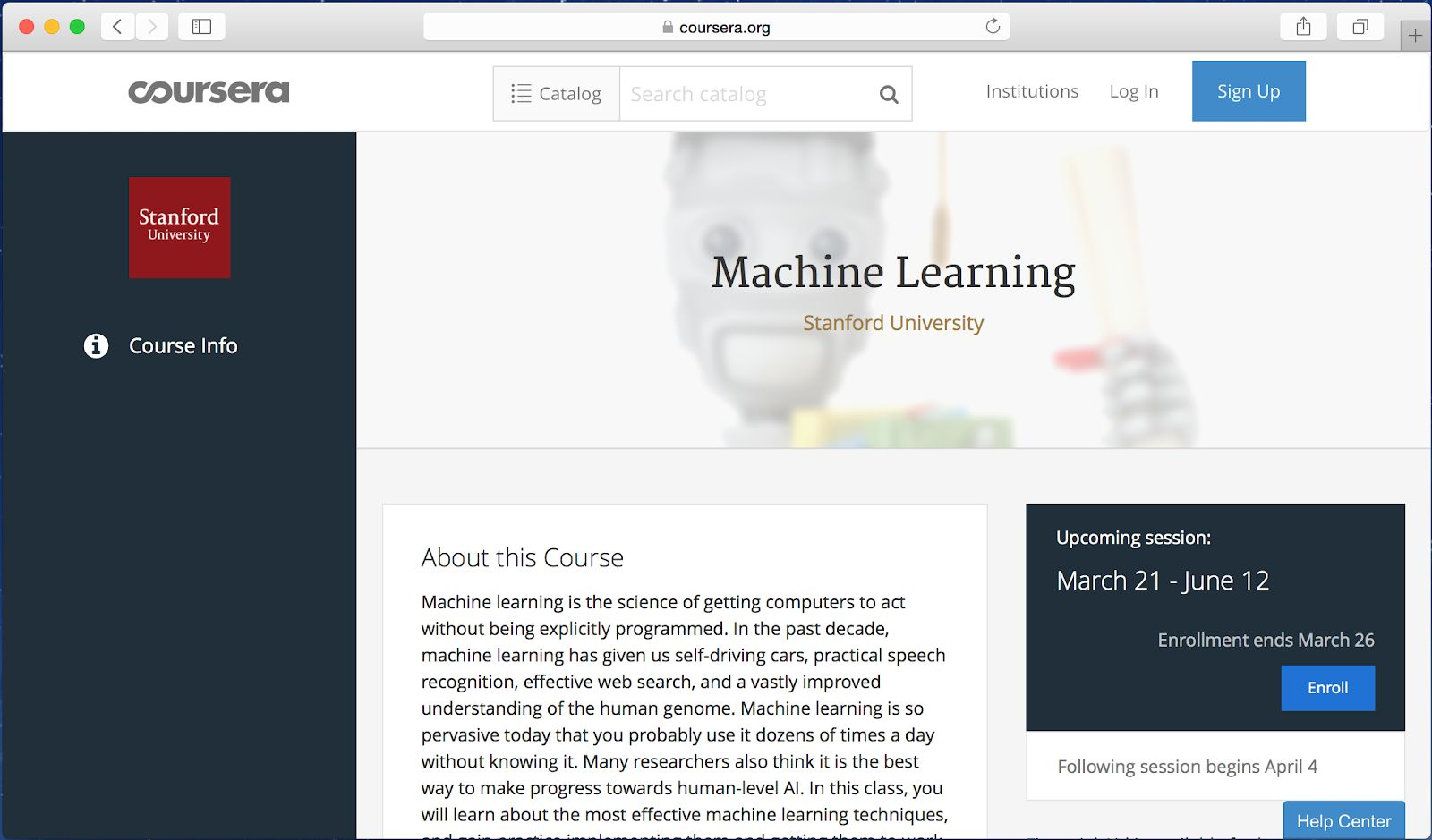
سأوضح ، حتى لو جمعت الكثير من البيانات ، عادةً ما يكون منحنى نمو دقة خوارزميات التعلم القديمة ، مثل الانحدار اللوجستي "مسطحًا". هذا يعني أن منحنى التعلم "مسطح" وأن جودة التنبؤ بالخوارزمية تتوقف عن النمو على الرغم من حقيقة أنك تعطيها المزيد من البيانات للتدريب.
يبدو أن الخوارزميات القديمة لا تعرف ما يجب فعله بكل هذه البيانات المتاحة لنا الآن.
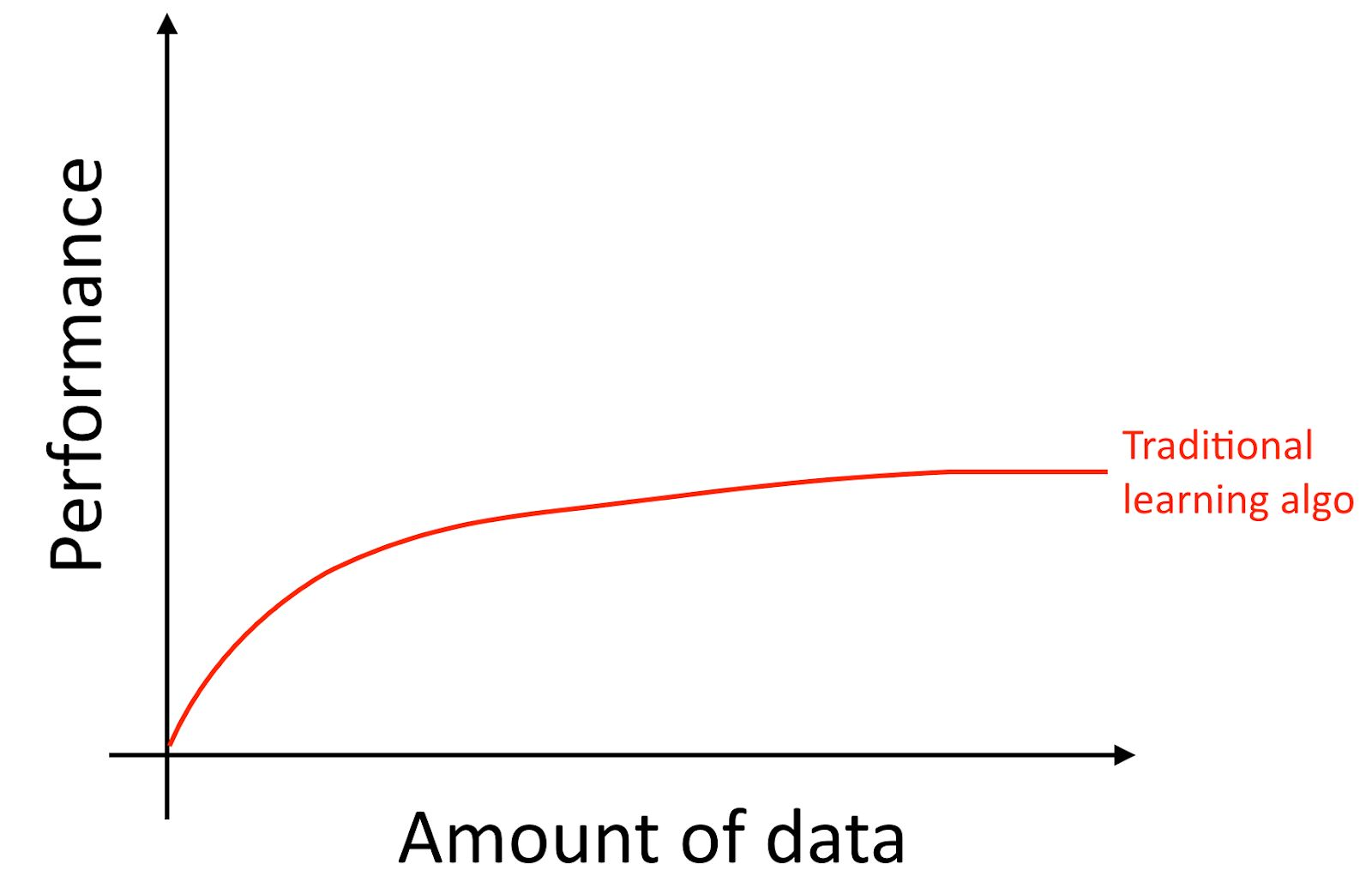
إذا قمت بتدريب شبكة عصبية صغيرة (NN) على نفس مهمة "التعلم مع المعلم" ، فقد تحصل على نتيجة أفضل قليلاً من "الخوارزميات القديمة".
هنا ، نعني بـ "NN الصغيرة" شبكة عصبية بها عدد صغير من الخلايا / الطبقات / المعلمات المخفية. أخيرًا ، إذا بدأت في تدريب شبكات عصبية أكبر وأكبر ، يمكنك الحصول على جودة أعلى من أي وقت مضى.
ملاحظة المؤلف : يوضح هذا الرسم البياني أن الشبكات العصبية تعمل بشكل أفضل في وضع مجموعة البيانات الصغيرة. هذا التأثير أقل استقرارًا من تأثير الشبكات العصبية التي تعمل جيدًا في وضع مجموعة البيانات الضخمة. في وضع البيانات الصغيرة ، اعتمادًا على كيفية معالجة الميزات (اعتمادًا على جودة هندسة الميزات) ، يمكن أن تعمل الخوارزميات التقليدية بشكل أفضل وأسوأ من الشبكات العصبية. على سبيل المثال ، إذا كان لديك 20 مثالًا للتدريب ، فلا يهم حقًا إذا كنت تستخدم الانحدار اللوجستي أو الشبكة العصبية ؛ إعداد الميزة له تأثير أكبر من اختيار الخوارزمية. ومع ذلك ، إذا كان لديك مليون مثال تدريبي ، فإنني أفضل شبكة عصبية.

وبالتالي ، تحصل على أفضل جودة للخوارزمية عندما (i) تقوم بتدريب شبكة عصبية كبيرة جدًا ، وفي هذه الحالة تكون على المنحنى الأخضر في الصورة أعلاه ؛ (ii) لديك كمية هائلة من البيانات تحت تصرفك.
العديد من التفاصيل الأخرى ، مثل بنية الشبكة العصبية مهمة أيضًا ، وتم إنشاء العديد من الحلول المبتكرة في هذا المجال. لكن الطريقة الأكثر موثوقية لتحسين جودة الخوارزمية اليوم لا تزال (1) زيادة حجم الشبكة العصبية المدربة (2) الحصول على المزيد من البيانات للتدريب.
عملية استيفاء الشرطين (1) و (2) عمليًا معقدة بشكل مدهش. يناقش هذا الكتاب بالتفصيل تفاصيله. نبدأ باستراتيجيات عامة مفيدة بنفس القدر لكل من الخوارزميات التقليدية والشبكات العصبية ، ثم ندرس أحدث الاستراتيجيات المستخدمة في تصميم وتطوير أنظمة التعلم العميق.
5. إنشاء عينات للتدريب واختبار الخوارزميات
دعنا نعود إلى مثال صور القط لدينا أعلاه: لقد أطلقت تطبيقًا للجوّال ويقوم المستخدمون بتحميل عدد كبير من الصور المختلفة على تطبيقك. تريد العثور تلقائيًا على صور القطط.
يتلقى فريقك تدريبًا كبيرًا عن طريق تنزيل صور القطط (أمثلة إيجابية) والصور التي لا توجد بها قطط (أمثلة سلبية) من مواقع ويب مختلفة. لقد قطعوا مجموعة البيانات إلى تدريب واختبار بنسبة 70٪ إلى 30٪. باستخدام هذه البيانات ، قاموا ببناء خوارزمية تجد القطط التي تعمل بشكل جيد في كل من بيانات التدريب والاختبار.
ومع ذلك ، عندما أدخلت هذا المصنف في تطبيق محمول ، وجدت أن جودته سيئة للغاية!

ماذا حدث
تكتشف فجأة أن الصور التي يقوم المستخدمون بتحميلها إلى تطبيق الهاتف المحمول لديك تبدو مختلفة تمامًا عن الصور من مواقع الويب التي تشكل مجموعة بيانات التدريب: يقوم المستخدمون بتحميل الصور التي تم التقاطها بكاميرات الهاتف المحمول ، والتي عادةً ما تكون دقة أقل ، أقل حدة ومصنوعة في الإضاءة المنخفضة. بعد التدريب على عينات التدريب / الاختبار التي تم جمعها من الصور من مواقع الويب ، لم تتمكن الخوارزمية من تعميم النتائج نوعيًا على التوزيع الفعلي للبيانات ذات الصلة بتطبيقك (الصور التي تم التقاطها بكاميرات الهاتف المحمول).
قبل ظهور العصر الحديث للبيانات الضخمة ، كانت القاعدة العامة للتعلم الآلي هي تقسيم البيانات إلى بيانات تعليمية واختبارية بنسبة 70٪ إلى 30٪. على الرغم من حقيقة أن هذا النهج لا يزال يعمل ، إلا أنه سيكون فكرة سيئة لاستخدامه في المزيد والمزيد من التطبيقات حيث يختلف توزيع عينة التدريب (الصور من مواقع الويب في المثال الذي نوقش أعلاه) عن توزيع البيانات التي سيتم استخدامها في القتال وضع التطبيق الخاص بك (صور من كاميرا الهواتف المحمولة).
التعريفات التالية شائعة الاستخدام:
- مجموعة التدريب - عينة من البيانات التي تستخدم لتدريب الخوارزمية
- أخذ عينات التحقق (مجموعة (تطوير)) - عينات بيانات تُستخدم لتحديد المعلمات ، وتحديد الميزات واتخاذ قرارات أخرى تتعلق بتدريب الخوارزمية. كما يشار إليها أحيانًا بمجموعة التحقق من الصحة المتقاطعة.
- عينة اختبار - عينة تستخدم لتقييم جودة الخوارزمية ، بينما لا يتم استخدامها لتعليم الخوارزمية أو المعلمات المستخدمة في هذا التدريب.
ملاحظة المترجم: يستخدم أندرو إيون مفهوم مجموعة التطوير أو مجموعة التطوير ، في المصطلحات الروسية وفي اللغة الروسية لتعلم الآلة ، لا يحدث مثل هذا المصطلح. تبدو "عينة التصميم" أو "عينة التصميم" (الترجمة المباشرة للكلمات الإنجليزية) مرهقة. لذلك ، سأستمر في استخدام عبارة "التحقق من الصحة" كترجمة لمجموعة dev.
ملحوظة للمترجم 2: اقترحت DArtN ترجمة مجموعة dev على أنها "أخذ عينات التصحيح" ؛ أعتقد أن هذه فكرة جيدة جدًا ، لكنني استخدمت بالفعل مصطلح "أخذ عينات التحقق" على حجم كبير من النص ، ومن الصعب الآن استبدالها. في الإنصاف ، ألاحظ أن مصطلح "عينة التحقق" له ميزة واحدة - يتم استخدام هذه العينة لتقييم جودة الخوارزمية (لتقييم جودة الخوارزمية المدربة في عينة التدريب) ، وبالتالي ، بمعنى ما ، هي "اختبار" ، مصطلح "التحقق من الصحة" في يتضمن هذا الجانب. يركز صفة "التصحيح" على ضبط المعلمات. ولكن بشكل عام ، هذا مصطلح جيد جدًا (خاصة من وجهة نظر اللغة الروسية) وإذا ما فكرت في وقت سابق ، فسأستخدمه بدلاً من مصطلح "عينة التحقق".
اختر عينات للتحقق والاختبار بحيث تعكس (باستثناء اختيار (تعديل) المعلمات) البيانات التي تتوقع تلقيها في المستقبل وتريد أن تعمل الخوارزمية عليها بشكل جيد.
بمعنى آخر ، يجب ألا تكون العينة الاختبارية 30٪ فقط من البيانات المتاحة ، خاصةً إذا كنت تتوقع أن البيانات القادمة في المستقبل (صور من الهواتف المحمولة) ستختلف في طبيعتها عن مجموعة التدريب الخاصة بك (الصور المأخوذة من الويب مواقع).
إذا لم تكن قد قمت بتشغيل تطبيق الهاتف المحمول الخاص بك حتى الآن ، فقد لا يكون لديك مستخدمون ، ونتيجة لذلك ، قد لا تتوفر بيانات تعكس بيانات القتال التي يجب أن تتعامل معها الخوارزمية. ولكن يمكنك محاولة تقريبها. على سبيل المثال ، اطلب من أصدقائك التقاط صور للقطط باستخدام الهواتف المحمولة وإرسالها إليك. بعد تشغيل تطبيقك ، ستتمكن من تحديث عينات التحقق والاختبار الخاصة بك باستخدام بيانات المستخدم الحالية.
إذا لم تتمكن من الحصول على بيانات تقارب البيانات التي سيقوم المستخدمون بتحميلها ، فربما يمكنك محاولة بدء استخدام الصور من مواقع الويب. ولكن يجب أن تدرك أن هذا ينطوي على خطر ألا يعمل النظام بشكل جيد مع بيانات القتال (قدرته العامة على التعميم لن تكون كافية بالنسبة لهم).
يتطلب تطوير عينات التحقق والاختبار نهجًا جادًا وتفكيرًا شاملاً. لا تفترض في البداية أن توزيع مجموعة التدريب الخاصة بك يجب أن يتطابق تمامًا مع توزيع مجموعة الاختبار. حاول اختيار حالات الاختبار بطريقة تعكس توزيع البيانات التي تريد أن تعمل عليها الخوارزمية بشكل جيد في النهاية ، وليس البيانات التي كانت تحت تصرفك عند إنشاء عينة التدريب.
6. يجب أن يكون لعينات التحقق والاختبار نفس التوزيع

لنفترض أن بيانات تطبيق صور قطتك مقسمة إلى أربع مناطق تتوافق مع أكبر أسواقك: (1) الولايات المتحدة الأمريكية ، (2) الصين ، (3) الهند ، (4) مناطق أخرى.
لنفترض أننا شكلنا عينة تحقق من البيانات التي تم الحصول عليها من الأسواق الأمريكية والهندية ، واختبارًا مستندًا إلى البيانات الصينية وغيرها. وبعبارة أخرى ، يمكننا تخصيص مقطعين بشكل عشوائي للحصول على عينة التحقق ، واثنين آخرين للحصول على عينة اختبار. صحيح؟
بعد تحديد عينات التحقق والاختبار ، سيركز فريقك على تحسين تشغيل الخوارزمية في عينة التحقق. وبالتالي ، يجب أن تعكس عينة التحقق المهام الأكثر أهمية التي يجب حلها - يجب أن تعمل الخوارزمية بشكل جيد على جميع الأجزاء الجغرافية الأربعة ، وليس اثنين فقط.
المشكلة الثانية الناشئة عن التوزيعات المختلفة لعينات التحقق والاختبار هي أنه من المحتمل أن يقوم فريقك بتطوير شيء يعمل بشكل جيد في عينة التحقق فقط ليكتشف أنه ينتج جودة رديئة في عينة الاختبار. لقد رأيت الكثير من خيبات الأمل وأهدرت الجهود بسبب ذلك. تجنب حدوث ذلك لك.
على سبيل المثال ، افترض أن فريقك قد طور نظامًا يعمل بشكل جيد على عينة تم التحقق من صحتها ، ولكنه لا يعمل على اختبار واحد. إذا تم الحصول على عينات التحقق والاختبار الخاصة بك من نفس التوزيع ، يمكنك [الحصول على تشخيص واضح جدًا لذلك] يمكنك بسهولة تشخيص الخطأ الذي حدث: إعادة تدريب الخوارزمية على عينة التحقق. .
, .
- , . , .
- , , . . .
. , — . , , , .
, , , ( ). , , , . — , . , , , , . .
7. ?
, . , 90.0% 90.1%, , , 100 , 0.1%.
: . ( ), .
— , , -, , , 0.01% , . , 10000, , .
? . 30% . , , 100 10000 . , , , , , . / , , .
8.
: ( ), , , . , 97% , 90%, .
(precision) (recall), . . . :
, .
: (precision) () , , . (recall) () , , . , .
, , , , . . , (accuracy) , .
, , . , . F1 , , .
: F1 , . https://en.wikipedia.org/wiki/F1_score , « » , 2/((1/Precision)+(1/Recall)).
, . .
, , : (i) , (ii) , (iii) (iv) . . , . .
9.
.
, . :
, , [] — 0.5*[] , .
: -, , «». , 100 . , . (satisficing) — , , 100 . .
N , ( - , ), , , N-1 . . . , . (N-) , . , , , .
, , « », ( , ). , Amazon Echo «Alexa»; Apple Siri «Hey Siri»; Android «Okay, Google»; Baidu «Hello Baidu». false-positive — , , false-negative — . false-negative ( ) false positive 24 ( ).
.
10
, . - . , :
- ,
- ( )
- , . ( !) , .
. , . : , , .
, , . , - , , . ! , 95.0% 95.1%, 0.1% () . 0.1%- . , , ( ) , , .
11 عندما تحتاج إلى تغيير عينات ومقاييس التحقق والاختبار (مجموعات التطوير / الاختبار)
عندما يبدأ مشروع جديد ، أحاول تحديد عينات التحقق والاختبار بسرعة والتي ستحدد هدفًا واضحًا للفريق.
عادةً ما أطلب من فريقي الحصول على عينات التحقق والاختبار الأولية والمقياس الأولي بشكل أسرع من أسبوع واحد من بداية المشروع ، نادرًا ما يكون أطول. من الأفضل أخذ شيء غير كامل والمضي قدمًا بسرعة بدلاً من التفكير في أفضل حل لفترة طويلة. ومع ذلك ، فإن فترة الأسبوع هذه ليست مناسبة للتطبيقات الناضجة. على سبيل المثال ، يعد مرشح مكافحة البريد العشوائي أحد تطبيقات التعلم العميق الناضجة. لاحظت فرقًا تعمل على أنظمة ناضجة بالفعل وتقضي شهورًا في الحصول على عينات أفضل للاختبار والتطوير.
إذا قررت لاحقًا أنه لم يتم تحديد اختيارات التطوير / الاختبار الأولية أو المقياس الأصلي بشكل صحيح ، فقم ببذل كل الجهد لتغييرها بسرعة. على سبيل المثال ، إذا كان نموذج التطوير + المقياس الخاص بك يصنف المصنف A أعلى من المصنف B ، وتعتقد أنت وفريقك أن المصنف B أفضل بشكل موضوعي لمنتجك ، فقد يكون هذا علامة على أنك بحاجة إلى تغيير dev / test مجموعات البيانات أو في تغيير المقاييس لتقييم الجودة.
هناك ثلاثة أسباب رئيسية محتملة بسبب تصنيف عينة التحقق أو مقياس تقييم الجودة بشكل غير صحيح للمُصنِّف أ أعلاه المصنف ب:
1. يختلف التوزيع الفعلي المطلوب تحسينه عن عينات المطورين / الاختبار
تخيل أن مجموعات بيانات التطوير / الاختبار الأصلية تحتوي في الغالب على صور القطط البالغة. تبدأ في توزيع تطبيق قطتك وتجد أن المستخدمين يقومون بتحميل صور قطط أكثر بكثير مما كنت تتوقع. وبالتالي ، فإن توزيع dev / test ليس تمثيليًا ؛ فهو لا يعكس التوزيع الفعلي للكائنات التي تحتاج إلى تحسين جودة التعرف عليها. في هذه الحالة ، قم بتحديث اختيارات dev / test الخاصة بك لجعلها أكثر تمثيلاً.

2. تتراجع عن تحديد التحقق من الصحة (dev dev)
إن عملية التطور المتعدد للأفكار ، على مجموعة التحقق (مجموعة ديف) تجعل الخوارزمية تتراجع تدريجيًا عنها. عند الانتهاء من التطوير ، تقوم بتقييم جودة النظام الخاص بك على عينة اختبار. إذا وجدت أن جودة الخوارزمية الخاصة بك في مجموعة التحقق (مجموعة ديف) أفضل بكثير من مجموعة الاختبار (مجموعة الاختبار) ، فهذا يشير إلى أنك تدربت على عينة التحقق. في هذه الحالة ، تحتاج إلى الحصول على عينة جديدة للتحقق.
إذا كنت بحاجة إلى تتبع تقدم فريقك ، فيمكنك أيضًا تقييم جودة نظامك بانتظام ، على سبيل المثال ، أسبوعيًا أو شهريًا ، باستخدام تقييم جودة الخوارزمية في عينة اختبار. ومع ذلك ، لا تستخدم مجموعة الاختبار لاتخاذ أي قرارات بشأن الخوارزمية ، بما في ذلك ما إذا كان يجب الرجوع إلى الإصدار السابق من النظام الذي تم اختباره الأسبوع الماضي. إذا بدأت في استخدام عينة الاختبار لتغيير الخوارزمية ، فستبدأ في إعادة التدريب على عينة الاختبار ولا يمكنك الاعتماد عليها للحصول على تقييم موضوعي لجودة الخوارزمية (والتي تحتاج إليها إذا نشرت مقالات بحثية ، أو ربما تستخدم هذه المقاييس لاتخاذ قرارات عمل مهمة).
3. يقيم المقياس شيئًا مختلفًا عما يجب تحسينه لأغراض المشروع
لنفترض أن تطبيقك للقطط هو مقياس التصنيف. يصنف هذا المقياس حاليًا المصنف A كمصنف متفوق B. ولكن لنفترض أنك جربت كلا الخوارزميات ووجدت أن الصور الإباحية العشوائية تنزلق من خلال المصنف A. على الرغم من أن المصنف A أكثر دقة ، إلا أن الانطباع الضعيف الذي خلفته الصور الإباحية العشوائية يجعل جودته غير مرضية. ما الخطأ الذي فعلته؟
في هذه الحالة ، لا يمكن للمقياس الذي يقيم جودة الخوارزميات تحديد أن الخوارزمية B أفضل في الواقع من الخوارزمية A لمنتجك. وبالتالي ، لم يعد بإمكانك الوثوق بالمقياس لتحديد أفضل خوارزمية. حان الوقت لتغيير مقياس تقييم الجودة. على سبيل المثال ، يمكنك تغيير المقياس من خلال إدخال عقوبة شديدة على الخوارزمية لتخطي صورة إباحية. أوصي بشدة باختيار مقياس جديد واستخدام هذا المقياس الجديد لتعيين هدف جديد صراحة للفريق ، بدلاً من الاستمرار في العمل لفترة طويلة جدًا باستخدام مقياس غير موثوق به ، والعودة في كل مرة إلى التحديد اليدوي بين المصنفات.
هذه طرق عامة إلى حد ما لتغيير عينات التطوير / الاختبار أو تغيير مقياس تقييم الجودة أثناء العمل في المشروع. يتيح لك الحصول على عينات ومقاييس التطوير / الاختبار الأصلية البدء في التكرار بسرعة على مشروعك. حتى إذا وجدت أن تحديدات أو مقاييس dev / test المحددة لم تعد توجه فريقك في الاتجاه الصحيح ، فهذا لا يهم حقًا! فقط قم بتغييرها وتأكد من أن فريقك يعرف عن اتجاه جديد.
12 التوصيات: نقوم بإعداد عينات التحقق (التطوير) والاختبار
- حدد نماذج التطوير واختبر من توزيع يعكس البيانات التي تتوقع تلقيها في المستقبل والتي تريد أن تعمل الخوارزمية عليها بشكل جيد. قد لا تتزامن هذه العينات مع توزيع مجموعة بيانات التدريب الخاصة بك.
- حدد مجموعات اختبار مطور البرامج من نفس التوزيع ، إن أمكن
- اختر مقياسًا من معلمة واحدة لتقييم جودة الخوارزميات لتحسين فريقك. إذا كان لديك العديد من الأهداف التي تحتاج إلى تحقيقها في نفس الوقت ، ففكر في دمجها في صيغة واحدة (مثل مقياس خطأ المتوسط المتعدد للمعلمات) أو تحديد مقاييس التقييد والتحسين.
- التعلم الآلي عملية تكرارية للغاية: يمكنك تجربة العديد من الأفكار قبل أن تجد فكرة ترضيك.
- سيساعدك وجود عينات مطور / اختبار ومقياس تقييم جودة ذي معلمة واحدة على تقييم الخوارزميات بسرعة ، وبالتالي تكرارها بشكل أسرع.
- عندما يبدأ تطوير تطبيق جديد ، حاول تثبيت عينات ديف / اختبار بسرعة ومقياس تقييم الجودة ، على سبيل المثال ، لا تنفق أكثر من أسبوع على هذا. بالنسبة للتطبيقات الناضجة ، من الطبيعي أن تستغرق هذه العملية وقتًا أطول بكثير.
- لا ينطبق الأمر التجريبي القديم الجيد لتقسيم عينات التدريب والاختبار بنسبة 70٪ إلى 30٪ على المشكلات التي توجد بها كمية كبيرة من البيانات ؛ يمكن أن تكون عينات التطوير / الاختبار أقل بكثير من 30٪ من جميع البيانات المتاحة.
- إذا لم يعد نموذج التطوير والمقياس يخبر فريقك بالاتجاه الصحيح ، فقم بتغييرهم بسرعة: (1) إذا تم إعادة تدريب الخوارزمية الخاصة بك على مجموعة التحقق (مجموعة dev) ، أضف المزيد من البيانات إليها (في مجموعة dev). (2) إذا كان توزيع البيانات الحقيقية ، فإن جودة الخوارزمية التي تحتاج إلى تحسينها تختلف عن توزيع البيانات في التحقق و (أو) عينات الاختبار (مجموعات dev / test) ، وإنشاء عينات جديدة للاختبار والتطوير (مجموعات dev / test) ، باستخدام بيانات أخرى. (3) إذا لم يعد مقياس تقييم الجودة يقيس ما هو الأكثر أهمية لمشروعك ، فغيّر هذا المقياس.
13 قم ببناء نظامك الأول بسرعة ثم قم بالترقية بشكل متكرر
تريد إنشاء نظام جديد لمكافحة البريد الإلكتروني العشوائي للبريد الإلكتروني. فريقك لديه عدة أفكار:
- اجمع عينة تدريبية ضخمة تتكون من رسائل البريد الإلكتروني العشوائية. على سبيل المثال ، قم بإعداد خداع: أرسل عن قصد عناوين بريد إلكتروني مزيفة إلى مرسلي البريد العشوائي المعروفين ، حتى تتمكن تلقائيًا من جمع رسائل البريد الإلكتروني العشوائية التي سيرسلونها إلى هذه العناوين
- ضع علامات لفهم المحتوى النصي للرسالة
- لوضع علامات لفهم غلاف الحرف / العنوان ، علامات تظهر من خلال خوادم الإنترنت التي مرت الرسالة
- وهكذا دواليك
على الرغم من أنني عملت بجد على تطبيقات مكافحة البريد الإلكتروني العشوائي ، فسيظل من الصعب بالنسبة لي اختيار أحد هذه المجالات. سيكون الأمر أكثر صعوبة إذا لم تكن خبيرًا في المجال الذي يتم تطوير التطبيق من أجله.
لذلك ، لا تحاول بناء نظام مثالي من البداية. بدلاً من ذلك ، قم ببناء وتدريب نظام بسيط في أسرع وقت ممكن ، ربما في غضون أيام قليلة.
ملاحظة المؤلف: هذه النصيحة موجهة للقراء الذين يرغبون في تطوير تطبيقات الذكاء الاصطناعي ، بدلاً من أولئك الذين يهدفون إلى نشر المقالات الأكاديمية. في وقت لاحق ، سأعود إلى موضوع البحث.
حتى إذا كان النظام البسيط بعيدًا عن نظام "مثالي" يمكنك بناءه ، فسيكون من المفيد دراسة كيفية عمل هذا النظام البسيط: ستجد بسرعة نصائح توضح لك أكثر المجالات الواعدة التي يجب أن تستثمر فيها وقتك. ستوضح لك الفصول القليلة التالية كيفية قراءة هذه النصائح.
14 تحليل الأخطاء: انظر إلى dev مجموعة من الأمثلة للأفكار.

عندما لعبت مع تطبيق قطتك ، لاحظت العديد من الأمثلة التي أخطأ فيها التطبيق الكلاب عن القطط. بعض الكلاب تشبه القطط!
اقترح أحد أعضاء الفريق تقديم برنامج جهة خارجية من شأنه تحسين أداء النظام في صور الكلاب. سيستغرق تنفيذ التغييرات شهرًا ، ويكون عضو الفريق الذي اقترحها متحمسًا. ما القرار الذي يجب عليك اتخاذه؟
قبل الاستثمار لمدة شهر في حل هذه المشكلة ، أوصيك أولاً بتقييم كيفية تحسين حلها لجودة النظام. ثم يمكنك أن تقرر بشكل أكثر عقلانية ما إذا كان الأمر يستحق تحسين شهر من التطوير أو ما إذا كان من الأفضل استخدام هذا الوقت لحل مشاكل أخرى.
على وجه التحديد ، ما يمكن القيام به في هذه الحالة:
- اجمع عينة من 100 مثال من مجموعة المطورين التي صنفها نظامك بشكل غير صحيح. أي الأمثلة التي ارتكب فيها نظامك خطأ.
- ادرس هذه الأمثلة واحسب مقدار صورة الكلب.
تسمى عملية دراسة الأمثلة التي ارتكب عليها المصنف خطأ "تحليل الخطأ". في هذا المثال ، لنفترض أنك وجدت أن 5٪ فقط من الصور التي تم تصنيفها عن طريق الخطأ هي كلاب ، فلا يهم مدى تحسين أداء الخوارزمية على صور الكلاب ، فلن تتمكن من الحصول على جودة أفضل من 5٪ من معدل الخطأ . بمعنى آخر ، 5٪ هي "الحد الأقصى" (مما يعني أعلى رقم ممكن) بقدر ما يمكن أن يساعد التحسين المتوقع. وبالتالي ، إذا كانت دقة نظامك الكلي حاليًا 90٪ (خطأ 10٪) ، فإن هذا التحسين ممكن ، في أحسن الأحوال سيحسن النتيجة إلى دقة 90.5٪ (أو سيكون معدل الخطأ 9.5٪ ، وهو أقل بنسبة 5٪ عن الأصل 10٪ من الأخطاء)
على العكس ، إذا وجدت أن 50٪ من الأخطاء هي كلاب ، فيمكنك أن تكون أكثر ثقة في أن المشروع المقترح لتحسين النظام سيكون له تأثير كبير. يمكن أن تزيد الدقة من 90٪ إلى 95٪ (تقليل الخطأ النسبي 50٪ من 10٪ إلى 5٪)
يسمح لك إجراء التقييم البسيط هذا لتحليل الأخطاء بالتقييم السريع للفوائد المحتملة لتطبيق برنامج تصنيف صور الكلاب التابع لجهة خارجية. يوفر تقييمًا كميًا لتقرير مدى استصواب استثمار الوقت في تنفيذه.
غالبًا ما يساعد تحليل الأخطاء على فهم مدى وعد الاتجاهات المختلفة للعمل المستقبلي. لقد لاحظت أن العديد من المهندسين يترددون في تحليل الأخطاء. غالبًا ما يبدو الأمر أكثر إثارة أن تتسرع في مجرد فكرة بدلاً من معرفة ما إذا كانت الفكرة تستحق الوقت الذي ستستغرقه. هذا خطأ شائع: يمكن أن يؤدي هذا إلى حقيقة أن فريقك سوف يقضي شهرًا فقط لفهمه بعد حقيقة أن النتيجة هي تحسن ضئيل.
التحقق اليدوي من 100 مثال من العينة ، ليس طويلاً. حتى إذا قضيت دقيقة واحدة على الصورة ، سيستغرق الفحص بالكامل أقل من ساعتين. يمكن أن توفر لك هاتان الساعتان شهرًا من الجهد الضائع.
استمرار