مرحبا يا هبر! أقدم لكم ترجمة مقال "
اكتشاف السخرية بالشبكات العصبية التلافيفية العميقة " للفيس سارافيا.
يعد الكشف عن السخرية من المشكلات الرئيسية في معالجة اللغة الطبيعية. يعد الكشف عن السخرية أمرًا مهمًا في مجالات أخرى ، مثل الحوسبة العاطفية وتحليل المزاج ، حيث قد يعكس ذلك قطبية الجملة.
توضح هذه المقالة كيفية اكتشاف السخرية ، كما توفر ارتباطًا إلى
كاشف السخرية للشبكة العصبية .
يمكن اعتبار السخرية تعبيرًا عن السخرية أو السخرية. أمثلة على السخرية: "أعمل 40 ساعة في الأسبوع لأبقى فقيراً" ، أو "إذا كان المريض يريد أن يعيش حقًا ، فإن الأطباء عاجزون".
لفهم واكتشاف السخرية ، من المهم فهم الحقائق المرتبطة بالحدث. هذا يكشف عن تناقض بين القطبية الموضوعية (عادة ما تكون سلبية) والخصائص الساخرة التي ينقلها المؤلف (عادة إيجابية).
تأمل في المثال: "أحب ألم الفراق".
من الصعب فهم المعنى إذا كان هناك سخرية في هذا البيان. في هذا المثال ، "أحب الألم" يعطي معرفة بالمشاعر التي عبر عنها المؤلف (في هذه الحالة ، إيجابي) ، و "فراق" يصف الشعور المتناقض (سلبي).
المشاكل الأخرى الموجودة في فهم العبارات الساخرة هي إشارة إلى العديد من الأحداث والحاجة إلى استخراج عدد كبير من الحقائق والفطرة السليمة والمنطق المنطقي.
نموذج
غالبًا ما يكون "تحول المزاج" موجودًا في الاتصال حيث يوجد سخرية. وبالتالي ، يُقترح أولاً إعداد نموذج للمزاج (استنادًا إلى CNN) لاستخراج علامات المزاج. يختار النموذج المعالم المحلية في الطبقات الأولى ، والتي يتم تحويلها بعد ذلك إلى معالم عالمية في مستويات أعلى. التعبيرات الساخرة خاصة بالمستخدم - بعض المستخدمين يستخدمون السخرية أكثر من الآخرين.
في النموذج المقترح للكشف عن السخرية ، يتم استخدام السمات الشخصية وعلامات المزاج والعلامات القائمة على العواطف. مجموعة من الكواشف هي إطار مصمم لكشف السخرية. يتم دراسة كل مجموعة من السمات من خلال نماذج منفصلة تم تدريبها مسبقًا.
إطار CNN
تعد شبكات CNN فعالة في نمذجة التسلسل الهرمي للميزات المحلية لإبراز الميزات العالمية ، وهو أمر ضروري لدراسة السياق. يتم تقديم بيانات الإدخال في شكل ناقلات كلمة. للمعالجة الأولية لبيانات الإدخال ، يتم استخدام word2vec من Google. يتم الحصول على معلمات المتجهات في مرحلة التدريب. ثم يتم تطبيق الحد الأقصى للاتحاد على خرائط الوظائف لإنشاء وظائف. بعد الطبقة المستعبدة بالكامل ، هناك طبقة softmax للحصول على التنبؤ النهائي.
يظهر الشكل المعماري في الشكل أدناه.
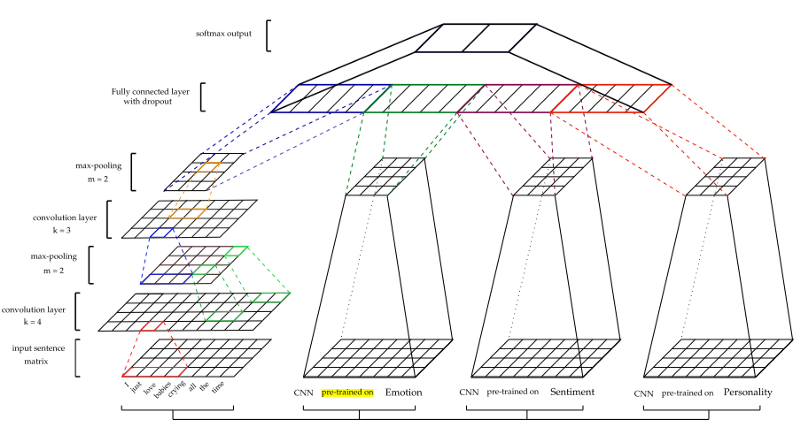
للحصول على ميزات أخرى - المزاج (S) ، والعاطفة (E) ، والشخصية (P) - تخضع نماذج CNN للتدريب الأولي وتستخدم لاستخراج السمات من مجموعات بيانات السخرية. لتدريب كل نموذج ، تم استخدام مجموعات بيانات التدريب المختلفة. (لمزيد من التفاصيل انظر الوثيقة)
تم اختبار مصنفين - مصنف CNN (CNN) والخصائص المستخرجة لـ CNN التي تم تمريرها إلى مصنف SVM (CNN-SVM).
يتم أيضًا تصنيف مصنف أساسي منفصل (B) ، يتكون فقط من نموذج CNN بدون تضمين نماذج أخرى (على سبيل المثال ، العواطف والحالات المزاجية).
التجارب
البيانات. تم الحصول على مجموعات بيانات متوازنة وغير متوازنة من (Ptacek et al.، 2014) وجهاز
الكشف عن السخرية . تتم إزالة أسماء المستخدمين وعناوين URL وعلامات التجزئة ، ثم يتم تطبيق رمز مميز NLTK على Twitter.
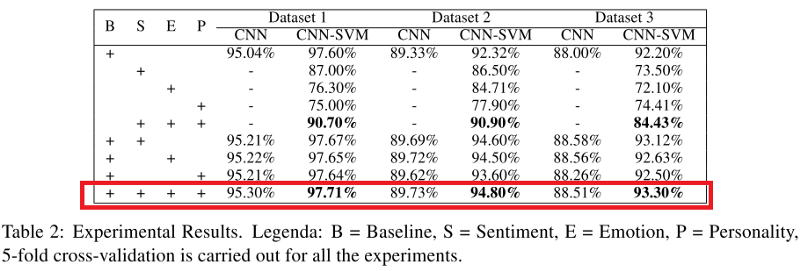
مقاييس كل من CNN و CNN-SVM المصنف المطبق على جميع مجموعات البيانات موضحة في الجدول أدناه. قد تلاحظ أنه عندما يجمع نموذج (على وجه الخصوص ، CNN-SVM) بين علامات السخرية وعلامات العواطف والمشاعر وسمات الشخصية ، فإنه يفوق جميع النماذج الأخرى ، باستثناء النموذج الأساسي (B).
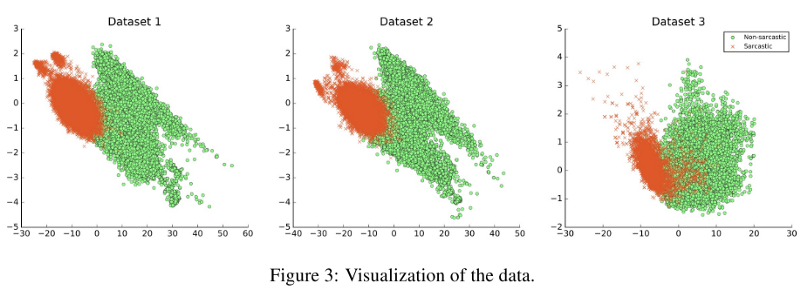
تم اختبار إمكانات تعميم النماذج ، وكان الاستنتاج الرئيسي هو أنه إذا كانت مجموعات البيانات مختلفة في طبيعتها ، فقد أثر ذلك بشكل كبير على النتيجة ، كما هو موضح في الشكل أدناه. على سبيل المثال ، تم إجراء التدريب على مجموعة البيانات 1 واختبارها على مجموعة البيانات 2 ؛ كانت درجة F1 للنموذج 33.05٪.