في الشركة ، يُطلق على فريقنا لمكافحة هجمات DDoS اسم "قطرات الحزم". بينما تقوم جميع الفرق الأخرى بأشياء رائعة مع مرور حركة المرور عبر شبكتنا ، لدينا متعة في إيجاد طرق جديدة للتخلص منها.
 الصورة: Brian Evans ، CC BY-SA 2.0
الصورة: Brian Evans ، CC BY-SA 2.0القدرة على إسقاط الحزم بسرعة مهمة جدًا في معارضة هجمات DDoS.
يمكن تنفيذ الحزم المتساقطة التي تصل إلى خوادمنا على عدة مستويات. كل طريقة لها إيجابياتها وسلبياتها. تحت القطع ، ننظر إلى كل شيء اختبرناه.
ملاحظة المترجم: في إخراج بعض الأوامر المقدمة ، تمت إزالة المسافات الزائدة للحفاظ على سهولة القراءة.
موقع الاختبار
من أجل تسهيل مقارنة الطرق ، سنزودك بعدد قليل من الأرقام ، ومع ذلك ، لا تأخذها بشكل حرفي للغاية ، وذلك بسبب مصطنعة الاختبارات. سنستخدم إحدى بطاقات شبكة Intel 10Gb / s الخاصة بنا. خصائص الخادم المتبقية ليست مهمة للغاية ، لأننا نريد التركيز على قيود نظام التشغيل ، وليس الأجهزة.
ستبدو اختباراتنا على النحو التالي:
- نقوم بإنشاء عدد كبير من حزم UDP الصغيرة ، تصل قيمتها إلى 14 مليون حزمة في الثانية ؛
- يتم توجيه كل حركة المرور هذه إلى قلب معالج واحد للخادم المحدد ؛
- نقيس عدد الحزم التي تتم معالجتها بواسطة النواة على قلب معالج واحد.
يتم إنشاء حركة مرور اصطناعية بطريقة لإنشاء أقصى حمل: يتم استخدام عنوان IP عشوائي ومنفذ المرسل. هذا ما يبدو عليه في tcpdump:
$ tcpdump -ni vlan100 -c 10 -t udp and dst port 1234 IP 198.18.40.55.32059 > 198.18.0.12.1234: UDP, length 16 IP 198.18.51.16.30852 > 198.18.0.12.1234: UDP, length 16 IP 198.18.35.51.61823 > 198.18.0.12.1234: UDP, length 16 IP 198.18.44.42.30344 > 198.18.0.12.1234: UDP, length 16 IP 198.18.106.227.38592 > 198.18.0.12.1234: UDP, length 16 IP 198.18.48.67.19533 > 198.18.0.12.1234: UDP, length 16 IP 198.18.49.38.40566 > 198.18.0.12.1234: UDP, length 16 IP 198.18.50.73.22989 > 198.18.0.12.1234: UDP, length 16 IP 198.18.43.204.37895 > 198.18.0.12.1234: UDP, length 16 IP 198.18.104.128.1543 > 198.18.0.12.1234: UDP, length 16
على الخادم المحدد ، ستصبح جميع الحزم في قائمة انتظار RX واحدة ، وبالتالي ، ستتم معالجتها بواسطة قلب واحد. نحقق ذلك من خلال التحكم في تدفق الأجهزة:
ethtool -N ext0 flow-type udp4 dst-ip 198.18.0.12 dst-port 1234 action 2
اختبار الأداء عملية معقدة. عندما قمنا بإعداد الاختبارات ، لاحظنا أن وجود مآخذ الخام النشطة يؤثر سلبًا على الأداء ، لذلك قبل تشغيل الاختبارات ، تحتاج إلى التأكد من عدم تشغيل
tcpdump . هناك طريقة سهلة للتحقق من العمليات السيئة:
$ ss -A raw,packet_raw -l -p|cat Netid State Recv-Q Send-Q Local Address:Port p_raw UNCONN 525157 0 *:vlan100 users:(("tcpdump",pid=23683,fd=3))
وأخيرًا ، نقوم بإيقاف تشغيل Intel Turbo Boost على خادمنا:
echo 1 | sudo tee /sys/devices/system/cpu/intel_pstate/no_turbo
على الرغم من حقيقة أن Turbo Boost هو شيء رائع ويزيد من الإنتاجية بنسبة 20 ٪ على الأقل ، فإنه يفسد بشكل كبير الانحراف المعياري في اختباراتنا. مع تشغيل التربو ، يصل الانحراف إلى ± 1.5٪ ، بينما بدون 0.25٪ فقط.
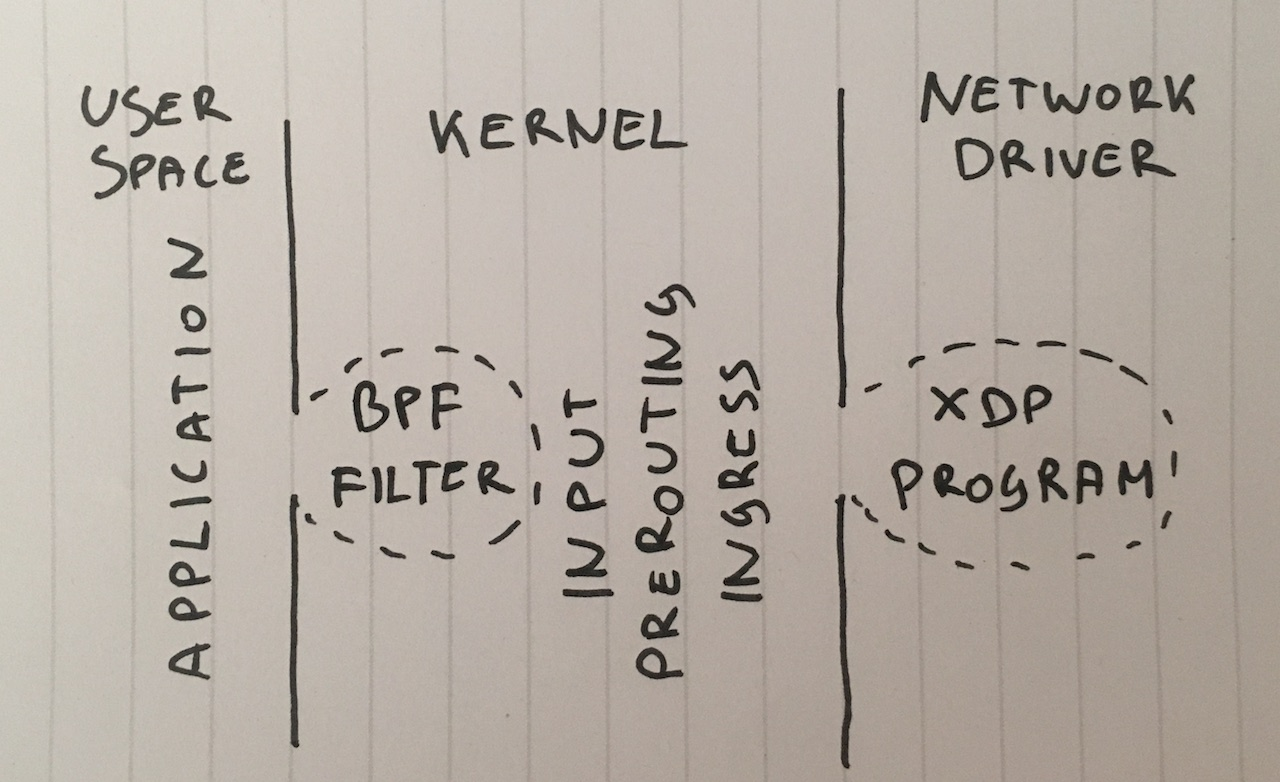
الخطوة 1. إسقاط الحزم في التطبيق
لنبدأ بفكرة تسليم جميع الحزم إلى التطبيق وتجاهلها هناك. لصدق التجربة ، تأكد من أن iptables لا تؤثر على الأداء بأي شكل من الأشكال:
iptables -I PREROUTING -t mangle -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT iptables -I INPUT -t filter -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
التطبيق عبارة عن دورة بسيطة يتم فيها التخلص من البيانات المستلمة على الفور:
s = socket.socket(AF_INET, SOCK_DGRAM) s.bind(("0.0.0.0", 1234)) while True: s.recvmmsg([...])
لقد قمنا بالفعل بإعداد
الكود وتشغيل:
$ ./dropping-packets/recvmmsg-loop packets=171261 bytes=1940176
يسمح هذا الحل للنواة بأخذ 175 ألف حزمة فقط من قائمة انتظار الأجهزة ، كما تم قياسها بواسطة أداة
mmwatch بنا :
$ mmwatch 'ethtool -S ext0|grep rx_2' rx2_packets: 174.0k/s
من الناحية الفنية ، تصل 14 مليون حزمة في الثانية إلى الخادم ، ومع ذلك ، لا يمكن لمعالج واحد أن يتعامل مع مثل هذا الحجم. يؤكد
mpstat هذا:
$ watch 'mpstat -u -I SUM -P ALL 1 1|egrep -v Aver' 01:32:05 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 01:32:06 PM 0 0.00 0.00 0.00 2.94 0.00 3.92 0.00 0.00 0.00 93.14 01:32:06 PM 1 2.17 0.00 27.17 0.00 0.00 0.00 0.00 0.00 0.00 70.65 01:32:06 PM 2 0.00 0.00 0.00 0.00 0.00 100.00 0.00 0.00 0.00 0.00 01:32:06 PM 3 0.95 0.00 1.90 0.95 0.00 3.81 0.00 0.00 0.00 92.38
كما نرى ، فإن التطبيق ليس اختناق: وحدة المعالجة المركزية # 1 تستخدم بنسبة 27.17٪ + 2.17٪ ، بينما تستغرق معالجة المقاطعة 100٪ على وحدة المعالجة المركزية # 2.
recvmessagge(2) استخدام
recvmessagge(2) دورًا مهمًا. بعد اكتشاف
ثغرة Spectre ، أصبحت مكالمات النظام أكثر تكلفة بسبب
KPTI و
retpoline المستخدم في kernel
$ tail -n +1 /sys/devices/system/cpu/vulnerabilities/* ==> /sys/devices/system/cpu/vulnerabilities/meltdown <== Mitigation: PTI ==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <== Mitigation: __user pointer sanitization ==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <== Mitigation: Full generic retpoline, IBPB, IBRS_FW
الخطوة 2. قتل conntrack
لقد قمنا على وجه التحديد بمثل هذا الحمل مع IP مختلف ومنفذ المرسل من أجل تحميل conntrack قدر الإمكان. يميل عدد الإدخالات في conntrack أثناء الاختبار إلى أقصى حد ممكن ويمكننا التحقق من ذلك:
$ conntrack -C 2095202 $ sysctl net.netfilter.nf_conntrack_max net.netfilter.nf_conntrack_max = 2097152
علاوة على ذلك ، في
dmesg يمكنك أيضًا رؤية صرخات conntrack:
[4029612.456673] nf_conntrack: nf_conntrack: table full, dropping packet [4029612.465787] nf_conntrack: nf_conntrack: table full, dropping packet [4029617.175957] net_ratelimit: 5731 callbacks suppressed
لذا دعنا نطفئه:
iptables -t raw -I PREROUTING -d 198.18.0.12 -p udp -m udp --dport 1234 -j NOTRACK
وأعد الاختبارات:
$ ./dropping-packets/recvmmsg-loop packets=331008 bytes=5296128
هذا سمح لنا بالوصول إلى علامة 333 ألف علبة في الثانية. مرحى!
ملاحظة: باستخدام SO_BUSY_POLL يمكننا تحقيق ما يصل إلى 470 ألف في الثانية ، ومع ذلك ، هذا موضوع منشور منفصل.
الخطوة 3. Berkeley Batch Filter
دعنا ننتقل. لماذا نحتاج إلى توصيل الحزم إلى التطبيق؟ على الرغم من أن هذا ليس حلاً شائعًا ، إلا أنه يمكننا ربط عامل تصفية حزم Berkeley الكلاسيكي بالمقبس من خلال استدعاء
setsockopt(SO_ATTACH_FILTER) وتكوين عامل التصفية لإسقاط الحزم مرة أخرى في kernel.
قم بإعداد
الكود وتشغيل:
$ ./bpf-drop packets=0 bytes=0
باستخدام مرشح الحزم (توفر مرشحات Berkeley الكلاسيكية والمتقدمة أداء مشابهًا تقريبًا) ، نحصل على حوالي 512 ألف حزمة في الثانية. علاوة على ذلك ، فإن إسقاط حزمة أثناء مقاطعة يحرر المعالج من الاضطرار إلى تنبيه التطبيق.
الخطوة 4. iptables DROP بعد التوجيه
يمكننا الآن إسقاط الحزم عن طريق إضافة القاعدة التالية إلى iptables في سلسلة INPUT:
iptables -I INPUT -d 198.18.0.12 -p udp --dport 1234 -j DROP
دعني أذكرك بأننا قمنا بالفعل بتعطيل التواصل مع قاعدة
-j NOTRACK . تعطينا هاتين القاعدتين 608 آلاف حزمة في الثانية.
دعونا نلقي نظرة على الأرقام في iptables:
$ mmwatch 'iptables -L -v -n -x | head' Chain INPUT (policy DROP 0 packets, 0 bytes) pkts bytes target prot opt in out source destination 605.9k/s 26.7m/s DROP udp -- * * 0.0.0.0/0 198.18.0.12 udp dpt:1234
حسنا ، ليس سيئا ، ولكن يمكننا أن نفعل أفضل.
الخطوة 5. iptabes إسقاط في PREROUTING
تقنية أسرع هي إسقاط الحزم قبل التوجيه باستخدام هذه القاعدة:
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j DROP
هذا يسمح لنا بإسقاط 1.688 مليون حزمة كبيرة في الثانية.
في الواقع ، هذه قفزة مفاجئة قليلاً في الأداء. ما زلت لا أفهم الأسباب ، ربما يكون التوجيه معقدًا ، أو ربما مجرد خطأ في تكوين الخادم.
على أي حال ، تكون iptables الأولية أسرع بكثير.
الخطوة 6. nftables DROP
أصبحت الأداة المساعدة iptables قديمة بعض الشيء. تم استبدالها ب nftables. تحقق من
شرح هذا الفيديو لماذا nftables هو الأعلى. يعد Nftables أن يكون أسرع من الشيب iptables لمجموعة متنوعة من الأسباب ، بما في ذلك الشائعات بأن retpolines تبطئ iptables كثيرًا.
لكن مقالنا لا يزال لا يتعلق بمقارنة iptables و nftables ، لذا دعنا نجرب أسرع ما يمكنني فعله:
nft add table netdev filter nft -- add chain netdev filter input { type filter hook ingress device vlan100 priority -500 \; policy accept \; } nft add rule netdev filter input ip daddr 198.18.0.0/24 udp dport 1234 counter drop nft add rule netdev filter input ip6 daddr fd00::/64 udp dport 1234 counter drop
يمكن رؤية العدادات على النحو التالي:
$ mmwatch 'nft --handle list chain netdev filter input' table netdev filter { chain input { type filter hook ingress device vlan100 priority -500; policy accept; ip daddr 198.18.0.0/24 udp dport 1234 counter packets 1.6m/s bytes 69.6m/s drop
أظهر خطاف إدخال nftables قيمًا لحوالي 1.53 مليون حزمة. هذا أقل بقليل من سلسلة PREROUTING في iptables. ولكن هناك غموض في هذا: نظريًا ، فإن خطاف nftables يذهب في وقت أبكر من PROTOUTING iptables ، وبالتالي ، يجب معالجته بشكل أسرع.
في اختبارنا ، nftables أبطأ قليلاً من iptables ، لكن nftables أكثر برودة على أي حال. : ص
الخطوة 7. tc DROP
بشكل غير متوقع إلى حد ما ، يحدث ربط tc (التحكم في حركة المرور) قبل iptables PREROUTING. يسمح لنا tc باختيار الحزم وفقًا لمعايير بسيطة ، وبالطبع إسقاطها. بناء الجملة غير عادي بعض الشيء ، لذلك نقترح استخدام
هذا البرنامج النصي للتكوين. ونحتاج إلى قاعدة معقدة إلى حد ما تبدو كما يلي:
tc qdisc add dev vlan100 ingress tc filter add dev vlan100 parent ffff: prio 4 protocol ip u32 match ip protocol 17 0xff match ip dport 1234 0xffff match ip dst 198.18.0.0/24 flowid 1:1 action drop tc filter add dev vlan100 parent ffff: protocol ipv6 u32 match ip6 dport 1234 0xffff match ip6 dst fd00::/64 flowid 1:1 action drop
ويمكننا التحقق من ذلك عمليًا:
$ mmwatch 'tc -s filter show dev vlan100 ingress' filter parent ffff: protocol ip pref 4 u32 filter parent ffff: protocol ip pref 4 u32 fh 800: ht divisor 1 filter parent ffff: protocol ip pref 4 u32 fh 800::800 order 2048 key ht 800 bkt 0 flowid 1:1 (rule hit 1.8m/s success 1.8m/s) match 00110000/00ff0000 at 8 (success 1.8m/s ) match 000004d2/0000ffff at 20 (success 1.8m/s ) match c612000c/ffffffff at 16 (success 1.8m/s ) action order 1: gact action drop random type none pass val 0 index 1 ref 1 bind 1 installed 1.0/s sec Action statistics: Sent 79.7m/s bytes 1.8m/s pkt (dropped 1.8m/s, overlimits 0 requeues 0)
سمح لنا ربط tc بإسقاط ما يصل إلى 1.8 مليون حزمة في الثانية على قلب واحد. هذا رائع!
ولكن يمكننا القيام بذلك بشكل أسرع ...
الخطوة 8. XDP_DROP
وأخيرًا ، أقوى سلاح لدينا: XDP -
eXpress Data Path . باستخدام XDP ، يمكننا تشغيل كود Berkley Packet Filter (eBPF) الموسع مباشرة في سياق برنامج تشغيل الشبكة ، والأهم من ذلك ، حتى قبل تخصيص ذاكرة لـ
skbuff ، مما يعدنا بزيادة السرعة.
عادة ، يتكون مشروع XDP من جزأين:
- كود eBPF للتحميل
- أداة تحميل التشغيل التي تضع التعليمات البرمجية في واجهة الشبكة الصحيحة
تعد كتابة برنامج bootloader مهمة صعبة ، لذا فقط استخدم
شريحة iproute2 الجديدة وقم بتحميل الشفرة بأمر بسيط:
ip link set dev ext0 xdp obj xdp-drop-ebpf.o
تا دام!
الكود
المصدري لبرنامج eBPF القابل للتنزيل متاح هنا . يبحث البرنامج في خصائص حزم IP مثل بروتوكول UDP والشبكة الفرعية للمرسل ومنفذ الوجهة:
if (h_proto == htons(ETH_P_IP)) { if (iph->protocol == IPPROTO_UDP && (htonl(iph->daddr) & 0xFFFFFF00) == 0xC6120000 // 198.18.0.0/24 && udph->dest == htons(1234)) { return XDP_DROP; } }
يجب بناء برنامج XDP باستخدام clang الحديث ، والذي يمكن أن يولد BPF bytecode. بعد ذلك ، يمكننا تنزيل واختبار وظائف برنامج BFP:
$ ip link show dev ext0 4: ext0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdp qdisc fq state UP mode DEFAULT group default qlen 1000 link/ether 24:8a:07:8a:59:8e brd ff:ff:ff:ff:ff:ff prog/xdp id 5 tag aedc195cc0471f51 jited
ثم انظر الإحصائيات في
ethtool :
$ mmwatch 'ethtool -S ext0|egrep "rx"|egrep -v ": 0"|egrep -v "cache|csum"' rx_out_of_buffer: 4.4m/s rx_xdp_drop: 10.1m/s rx2_xdp_drop: 10.1m/s
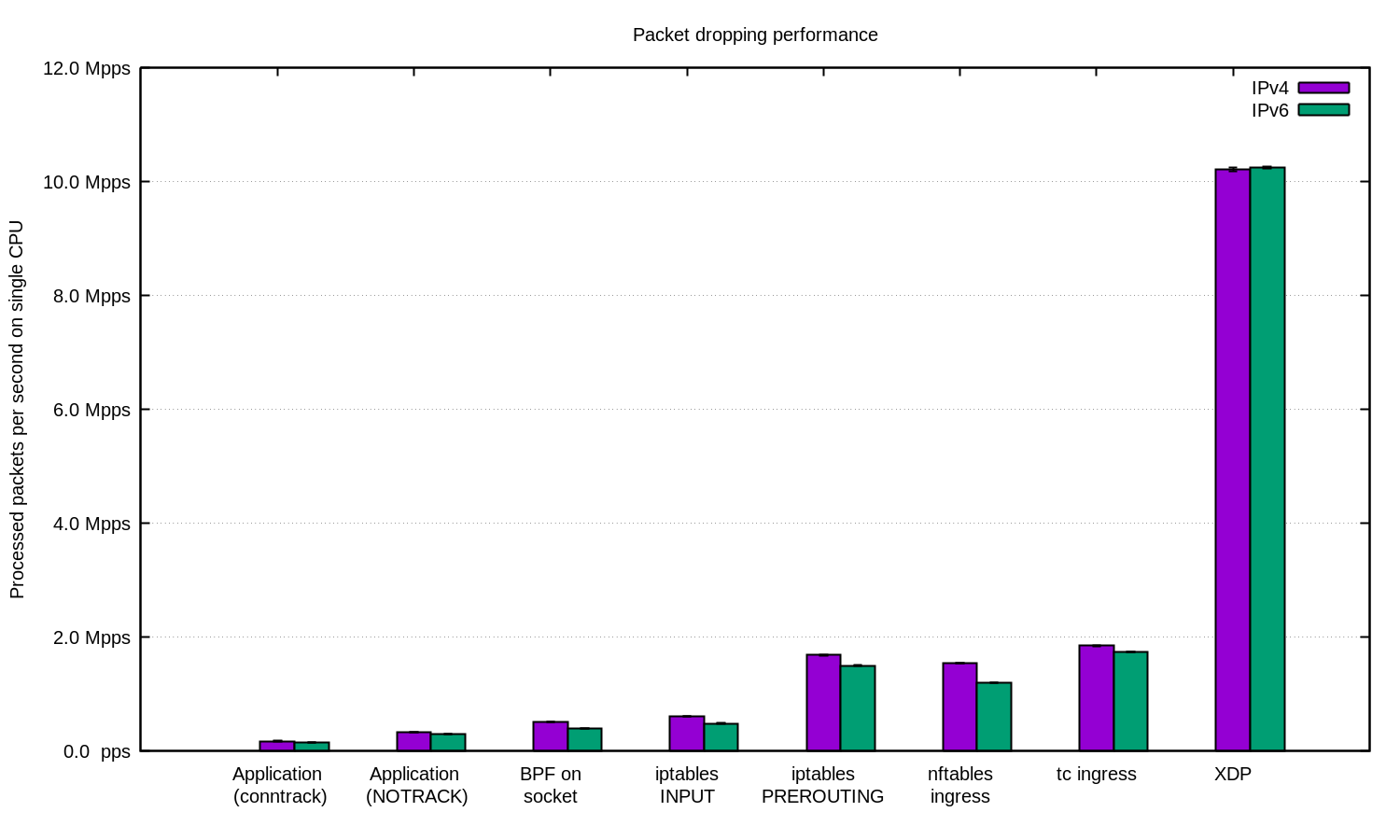
يو هوو! مع XDP ، يمكننا إسقاط ما يصل إلى 10 مليون حزمة في الثانية!
 الصورة: أندرو فيلر ، CC BY-SA 2.0
الصورة: أندرو فيلر ، CC BY-SA 2.0الاستنتاجات
كررنا التجربة لـ IPv4 و IPv6 وأعدنا هذا الرسم التخطيطي:
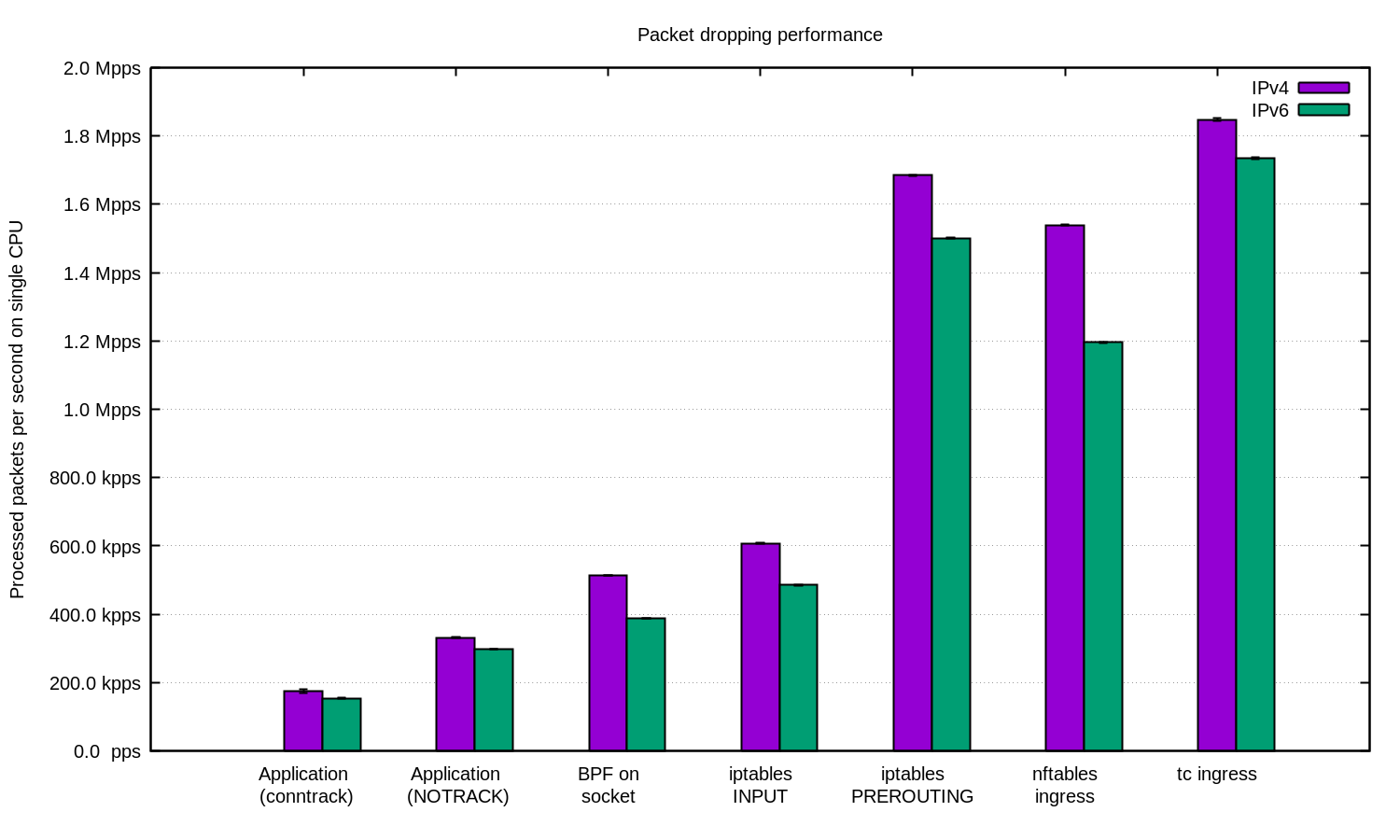
بشكل عام ، يمكن القول أن إعدادنا لـ IPv6 أبطأ قليلاً. ولكن بما أن حزم IPv6 أكبر إلى حد ما ، فمن المتوقع أن يكون الفرق في السرعة.
لدى Linux طرق عديدة لتصفية الحزم ، لكل منها سرعته وتعقيده.
للحماية من DDoS ، من المعقول تمامًا إعطاء حزم للتطبيق ومعالجتها هناك. يمكن أن يُظهر التطبيق المضبوط جيدًا نتائج جيدة.
بالنسبة لهجمات DDoS باستخدام عنوان IP عشوائي أو مخادع ، قد يكون من المفيد تعطيل الاتصال من أجل الحصول على زيادة طفيفة في السرعة ، ولكن كن حذرًا: فهناك هجمات يكون التواصل ضدها مفيدًا جدًا.
في حالات أخرى ، من المنطقي إضافة جدار حماية Linux كإحدى طرق التخفيف من هجوم DDoS. في بعض الحالات ، من الأفضل استخدام جدول "-t raw PREROUTING" ، لأنه أسرع بكثير من جدول التصفية.
بالنسبة للحالات الأكثر تقدمًا ، نستخدم دائمًا XDP. ونعم ، هذا شيء قوي للغاية. هنا رسم بياني على النحو الوارد أعلاه ، فقط مع XDP:
إذا كنت ترغب في تكرار التجربة ، فإليك
README ، حيث قمنا بتوثيق كل شيء .
نحن في CloudFlare نستخدم ... كل هذه التقنيات تقريبًا. يتم دمج بعض الحيل في مساحة المستخدم في تطبيقاتنا. تم العثور على تقنية iptables في
Gatebot . أخيرًا ، نستبدل الحل الأساسي الخاص بنا بـ XDP.
شكرا جزيلا ل
Jesper Dangaard Brouer لمساعدتهم.