تواجه جميع المؤسسات التي لها علاقة بالبيانات على الأقل عاجلاً أم آجلاً مشكلة تخزين قواعد البيانات العلائقية وغير المنظمة. ليس من السهل العثور على نهج مناسب وفعال وغير مكلف لهذه المشكلة في نفس الوقت. وللتأكد من أن علماء البيانات يمكنهم العمل بنجاح مع نماذج التعلم الآلي. لقد فعلنا ذلك - وعلى الرغم من أنني اضطررت إلى العبث به ، إلا أن الربح النهائي كان أكثر من المتوقع. سنناقش جميع التفاصيل أدناه.

بمرور الوقت ، تتراكم كميات لا تصدق من بيانات الشركة في أي بنك. يتم تخزين كمية مماثلة فقط في شركات الإنترنت والاتصالات. حدث ذلك بسبب المتطلبات التنظيمية العالية. هذه البيانات لا تكذب - فقد توصل رؤساء المؤسسات المالية منذ فترة طويلة إلى كيفية تحقيق الربح من ذلك.
بدأنا جميعًا بالإبلاغ الإداري والمالي. بناءً على هذه البيانات ، تعلمنا كيفية اتخاذ قرارات العمل. غالبًا ما كانت هناك حاجة للحصول على بيانات من عدة أنظمة معلومات للبنك ، والتي أنشأنا لها قواعد بيانات وأنظمة إبلاغ موحدة. من هذا شكلت تدريجيا ما يسمى الآن مستودع البيانات. سرعان ما بدأت أنظمتنا الأخرى تعمل على أساس هذا التخزين:
- CRM التحليلي ، مما يسمح بتقديم منتجات أكثر ملاءمة للعميل ؛
- نواقل القروض التي تساعدك على اتخاذ قرار بشأن القرض بسرعة وبدقة ؛
- تقوم أنظمة الولاء باحتساب نقاط استرداد النقود أو المكافآت وفقًا لميكانيكا التعقيد المتفاوت.
يتم حل جميع هذه المهام عن طريق التطبيقات التحليلية التي تستخدم نماذج التعلم الآلي. لمزيد من المعلومات التي يمكن أن تأخذها النماذج من المستودع ، ستعمل بشكل أكثر دقة. حاجتهم إلى البيانات تتزايد باطراد.
حول هذا الوضع وصلنا إلى عامين أو ثلاثة أعوام. في ذلك الوقت ، كان لدينا مساحة تخزين تعتمد على MPP Teradata DBMS باستخدام أداة SAS Data Integration Studio ELT. قمنا ببناء هذا المخزن منذ عام 2011 مع شركة Glowbyte Consulting. تم دمج أكثر من 15 نظامًا مصرفيًا كبيرًا فيه ، وفي الوقت نفسه ، تم تجميع بيانات كافية لتنفيذ وتطوير التطبيقات التحليلية. بالمناسبة ، في ذلك الوقت ، بدأ حجم البيانات في الطبقات الرئيسية من المتجر ، بسبب العديد من المهام المختلفة ، في النمو بشكل غير خطي ، وأصبحت تحليلات العملاء المتقدمة واحدة من الاتجاهات الرئيسية لتطوير البنك. نعم ، وكان علماء بياناتنا حريصين على دعمها. بشكل عام ، لبناء منصة أبحاث البيانات ، تشكلت النجوم كما يجب.
التخطيط لحل
هنا من الضروري أن أشرح: البرمجيات والخوادم الصناعية متعة باهظة الثمن حتى بالنسبة لبنك كبير. لا تستطيع كل منظمة تخزين كمية كبيرة من البيانات في أفضل نظام MPMS DBMS. عليك دائمًا الاختيار بين السعر والسرعة والموثوقية والحجم.
لتحقيق أقصى استفادة من الفرص المتاحة ، قررنا القيام بذلك:
- يجب ترك تحميل ELT والجزء الأكثر طلبًا من البيانات التاريخية للقرص المضغوط على Teradata DBMS ؛
- شحن القصة الكاملة إلى Hadoop ، مما يسمح لك بتخزين المعلومات أرخص بكثير.
في ذلك الوقت ، أصبح النظام البيئي Hadoop ليس فقط عصريًا ، ولكن أيضًا موثوقًا بما فيه الكفاية ، وملائمًا لاستخدام الشركات. كان من الضروري اختيار مجموعة توزيع. يمكنك بناء خاصتك أو استخدام Apache Hadoop المفتوح. ولكن من بين حلول المؤسسات القائمة على Hadoop ، أثبتت التوزيعات الجاهزة من البائعين الآخرين - Cloudera و Hortonworks - أنهم أكثر من ذلك. لذلك ، قررنا أيضًا استخدام التوزيع الجاهز.
نظرًا لأن مهمتنا الرئيسية كانت لا تزال تخزين البيانات الضخمة المنظمة ، في مجموعة Hadoop كنا مهتمين بالحلول التي كانت قريبة قدر الإمكان من SQL DBMSs الكلاسيكية. القادة هنا هم إمبالا وهيف. تطور Cloudera وتدمج حلول Impala و Hortonworks - Hive.
من أجل دراسة متعمقة ، قمنا بتنظيم اختبار الحمل لكل من DBMSs ، مع مراعاة تحميل الملف الشخصي لنا. يجب أن أقول أن محركات معالجة البيانات في Impala و Hive مختلفة بشكل كبير - تقدم Hive بشكل عام العديد من الخيارات المختلفة. ومع ذلك ، وقع الاختيار على إمبالا - وبالتالي ، التوزيع من Cloudera.
ما أعجبني في إمبالا
- سرعة عالية في تنفيذ الاستفسارات التحليلية بسبب نهج بديل فيما يتعلق بـ MapReduce. لا يتم طي النتائج المتوسطة للحسابات في HDFS ، مما يسرع معالجة البيانات بشكل كبير.
- عمل فعال مع تخزين بيانات الباركيه في الباركيه . بالنسبة للمهام التحليلية ، غالبًا ما يتم استخدام ما يسمى بالجداول العريضة مع العديد من الأعمدة. نادرًا ما يتم استخدام جميع الأعمدة - تسمح لك القدرة على جمع الأعمدة الضرورية فقط من HDFS بحفظ ذاكرة الوصول العشوائي وتسريع الطلب بشكل كبير.
- حل أنيق مع فلاتر وقت التشغيل التي تشمل تصفية التفتح. كل من Hive و Impala محدودان بشكل كبير في استخدامهما للمؤشرات الشائعة في DBMSs الكلاسيكية نظرًا لطبيعة نظام تخزين ملفات HDFS. لذلك ، لتحسين تنفيذ استعلام SQL ، يجب أن يستخدم محرك DBMS بشكل فعال التقسيم المتاح حتى عندما لا يتم تحديده صراحة في شروط الاستعلام. بالإضافة إلى ذلك ، يحتاج إلى محاولة التنبؤ بالحد الأدنى من البيانات من HDFS الذي يجب رفعه للمعالجة المضمونة لجميع الصفوف. في إمبالا ، يعمل هذا بشكل جيد للغاية.
- تستخدم إمبالا LLVM ، مترجم الآلة الافتراضية مع تعليمات تشبه RISC ، لإنشاء كود تنفيذ استعلام SQL الأمثل.
- يتم دعم واجهات ODBC و JDBC. هذا يسمح لك بدمج بيانات إمبالا مع الأدوات والتطبيقات التحليلية خارج الصندوق تقريبًا.
- من الممكن استخدام Kudu للتحايل على بعض قيود HDFS ، وعلى وجه الخصوص ، كتابة تركيبات UPDATE و DELETE في استعلامات SQL.
سكوب وبقية العمارة
الأداة التالية الأكثر أهمية على مكدس Hadoop كانت Sqoop بالنسبة لنا. يسمح لك بنقل البيانات بين DBMS العلائقية (كنا مهتمين بالطبع بـ Teradata) و HDFS في مجموعة Hadoop بتنسيقات مختلفة ، بما في ذلك باركيه. في الاختبارات ، أظهر Sqoop مرونة وأداء عاليين ، لذلك قررنا استخدامه - بدلاً من تطوير أدواتنا الخاصة لالتقاط البيانات من خلال ODBC / JDBC وحفظها على HDFS.
بالنسبة لنماذج التدريب والمهام ذات الصلة بعلوم البيانات ، والتي تعتبر أكثر ملاءمة للتنفيذ مباشرة على مجموعة Hadoop ، استخدمنا Apache
Spark . في مجالها ، أصبح حلًا قياسيًا - وهناك سبب:
- مكتبات Spark ML للتعلم الآلي
- دعم لأربع لغات برمجة (Scala ، Java ، Python ، R) ؛
- التكامل مع الأدوات التحليلية ؛
- توفر معالجة البيانات في الذاكرة أداءً ممتازًا.
تم شراء خادم Oracle Big Data Appliance كنظام أساسي للأجهزة. بدأنا بست عقد في دائرة منتجة مع وحدة معالجة مركزية 2 × 24 وذاكرة 256 جيجابايت لكل منها. يحتوي التكوين الحالي على 18 من نفس العقد مع ذاكرة موسعة تصل إلى 512 جيجابايت.
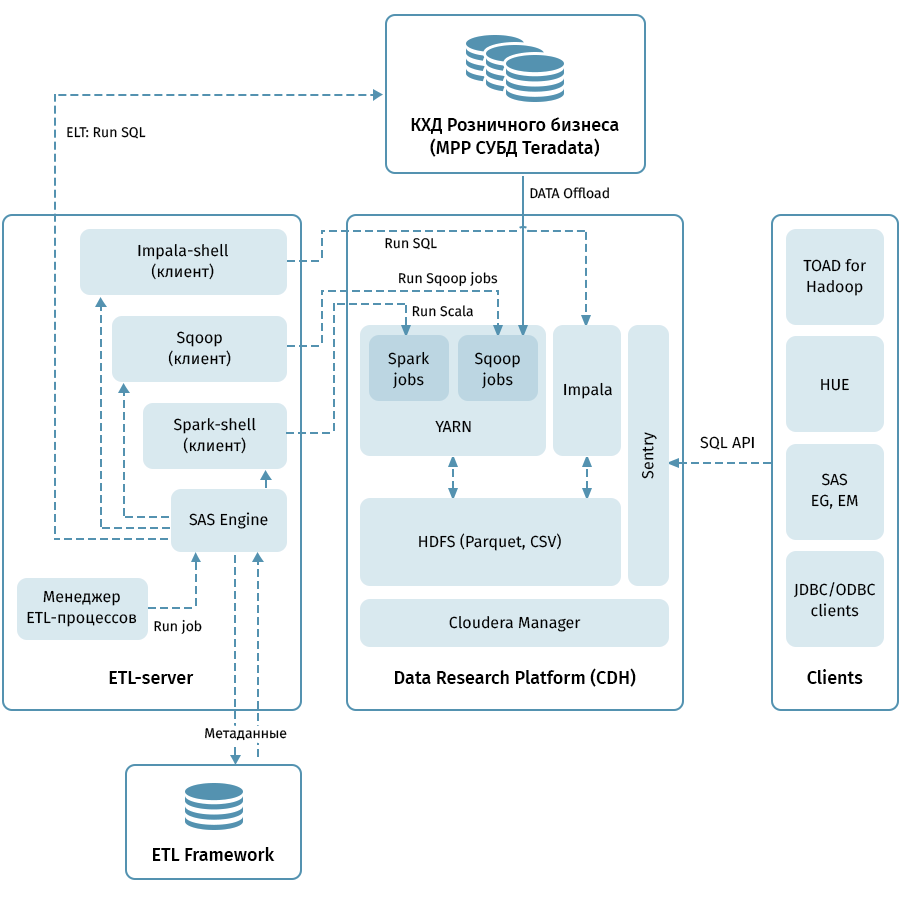
يوضح الرسم البياني بنية المستوى الأعلى لمنصة أبحاث البيانات والأنظمة ذات الصلة. الرابط المركزي هو كتلة Hadoop على أساس توزيع Cloudera (CDH). يتم استخدامه لكل من الاستلام مع Sqoop وتخزين بيانات QCD بتنسيق HDFS - في تنسيق الباركيه ، مما يسمح باستخدام برامج الترميز للضغط ، على سبيل المثال ، Snappy. تقوم المجموعة أيضًا بمعالجة البيانات: يتم استخدام Impala للتحولات الشبيهة بـ ELT ، Spark - لمهام علوم البيانات. يستخدم الحارس لتبادل الوصول إلى البيانات.
يحتوي Impala على واجهات لجميع أدوات تحليلات المؤسسة الحديثة تقريبًا. بالإضافة إلى ذلك ، يمكن ربط أدوات تعسفية تدعم واجهات ODBC / JDBC كعملاء. للعمل مع SQL ، نعتبر Hue و TOAD لـ Hadoop العملاء الرئيسيين.
يتم استخدام نظام فرعي ETL يتكون من أدوات SAS (خادم بيانات التعريف واستوديو تكامل البيانات) وإطار عمل ETL المكتوب على أساس SAS ونصوص برمجية باستخدام قاعدة بيانات لتخزين البيانات الوصفية لعمليات ETL للتحكم في جميع التدفقات المشار إليها بواسطة الأسهم في الرسم التخطيطي. . مسترشداً بالقواعد المحددة في البيانات الوصفية ، يطلق النظام الفرعي ETL عمليات معالجة البيانات على كل من QCD وعلى منصة أبحاث البيانات. ونتيجة لذلك ، لدينا نظام شامل لرصد وإدارة تدفقات البيانات بغض النظر عن البيئة المستخدمة (Teradata ، Impala ، Spark ، إلخ ، إذا لزم الأمر).
من خلال أشعل النار للنجوم
يبدو أن تفريغ QCD أمر بسيط. عند المدخلات والمخرجات ، DBMS العلائقية ، خذ البيانات وتجاوزها من خلال Sqoop. إذا حكمنا من خلال الوصف أعلاه ، فإن كل شيء سار بسلاسة جدًا معنا ، ولكن ، بالطبع ، لم يكن ذلك بدون مغامرات ، وربما يكون هذا هو الجزء الأكثر إثارة للاهتمام في المشروع بأكمله.

مع حجمنا ، لا يمكننا أن نأمل في نقل جميع البيانات بالكامل يوميًا. وبناءً على ذلك ، كان من الضروري من كل مرفق تخزين معرفة كيفية التمييز بين الزيادة الموثوقة ، وهو ليس من السهل دائمًا عندما تتغير البيانات الخاصة بتواريخ العمل التاريخية في الجدول. لحل هذه المشكلة ، نظمنا الكائنات اعتمادًا على طرق تحميل التاريخ والحفاظ عليه. ثم ، لكل نوع ، تم تحديد المسند الصحيح لـ Sqoop وطريقة التحميل في جهاز الاستقبال. وأخيرًا ، كتبوا تعليمات لمطوري الأشياء الجديدة.
Sqoop هي أداة عالية الجودة للغاية ، لكنها ليست موثوقة تمامًا في جميع الحالات ومجموعات الأنظمة. في مجلداتنا ، لم يعمل الموصل إلى Teradata على النحو الأمثل. لقد استفدنا من كود سكوب المفتوح المصدر وأدخلنا تغييرات على مكتبات الموصلات. زيادة استقرار الاتصال عند نقل البيانات.
لسبب ما ، عندما يتصل Sqoop بـ Teradata ، لا يتم تحويل المسندات بشكل صحيح تمامًا إلى شروط WHERE. وبسبب هذا ، يحاول Sqoop أحيانًا سحب طاولة ضخمة وتصفيتها لاحقًا. فشلنا في تصحيح الموصل هنا ، ولكننا وجدنا طريقة أخرى: قم بإنشاء جدول مؤقت بالقوة مع المسند المفروض لكل كائن غير محمل واطلب من Sqoop ملءه بشكل زائد.
تحتوي جميع MPP ، و Teradata على وجه الخصوص ، على ميزة تتعلق بتخزين البيانات المتوازي وتنفيذ التعليمات. إذا لم تؤخذ هذه الميزة في الاعتبار ، فقد يتبين أنه سيتم تولي جميع الأعمال من خلال عقدة منطقية واحدة من المجموعة ، مما سيجعل تنفيذ الاستعلام أبطأ بكثير ، مرة واحدة في 100-200. بالطبع ، لم نتمكن من السماح بذلك ، لذلك قمنا بكتابة محرك خاص يستخدم البيانات الوصفية ETL لجداول QCD وتحديد الدرجة المثلى من موازاة مهام Sqoop.
تعد التاريخية في التخزين مسألة دقيقة ، خاصة إذا كنت تستخدم
SCD2 ، في حين أن Impala لا يدعم التحديث
والحذف . بالطبع ، نريد أن تبدو الجداول التاريخية في منصة أبحاث البيانات كما هي تمامًا في Teradata. يمكن تحقيق ذلك من خلال الجمع بين تلقي الزيادة من خلال Sqoop ، وتسليط الضوء على مفاتيح الأعمال المحدثة وحذف الأقسام في Impala. حتى لا يضطر كل مطور إلى كتابة هذا المنطق المتقن ، قمنا بتعبئته في مكتبة خاصة (على "لودر" ETL العامية).
أخيرا - سؤال مع أنواع البيانات. إن Impala مجاني تمامًا لكتابة التحويل ، لذلك واجهنا بعض الصعوبات فقط في أنواع TIMESTAMP و CHAR / VARCHAR. بالنسبة إلى الوقت ، قررنا تخزين البيانات بتنسيق Impala بتنسيق النص (STRING) YYYY-MM-DD HH: MM: SS. هذا النهج ، كما اتضح ، يجعل من الممكن استخدام وظائف تحويل التاريخ والوقت. بالنسبة لبيانات السلسلة ذات الطول المحدد ، اتضح أن التخزين بتنسيق STRING في Impala ليس أقل شأنا منها ، لذلك استخدمناها أيضًا.
عادة ، لتنظيم Data Lake ، يقومون بنسخ بيانات المصدر بتنسيقات شبه منظمة في منطقة مرحلة خاصة في Hadoop ، وبعد ذلك يقوم Hive أو Impala بإعداد نظام إزالة التسلسل لهذه البيانات لاستخدامها في استعلامات SQL. ذهبنا بنفس الطريقة. من المهم ملاحظة أنه ليس كل شيء وليس من المنطقي دائمًا سحبه إلى مستودع البيانات ، نظرًا لأن تطوير عمليات نسخ الملفات وتثبيت المخطط أرخص بكثير من تحميل سمات الأعمال في نموذج QCD باستخدام عمليات ETL. عندما لا يزال من غير الواضح كم ، وإلى أي مدى وبأي تواتر تحتاج البيانات المصدر ، فإن Data Lake في النهج الموصوف هو حل بسيط ورخيص. الآن نقوم بالتحميل بانتظام إلى Data Lake بشكل أساسي المصادر التي تولد أحداث المستخدم: بيانات تحليل التطبيق ، والسجلات وسيناريوهات الانتقال لـ Avaya auto dialer وجهاز الرد الآلي ، ومعاملات البطاقة.
مجموعة أدوات المحللين
لم ننسى هدفًا آخر للمشروع بأكمله - لتمكين المحللين من استخدام كل هذه الثروة. فيما يلي المبادئ الأساسية التي وجهتنا هنا:
- راحة الأداة في الاستخدام والدعم
- قابلية التطبيق في مهام علوم البيانات
- أقصى إمكانية لاستخدام موارد الحوسبة لمجموعة Hadoop ، بدلاً من خوادم التطبيقات أو كمبيوتر الباحث
وهذا ما توقفنا عنده:
- Python + اناكوندا. البيئة المستخدمة هي iPython / Jupyter
- R + Shiny. يعمل الباحث في إصدار سطح المكتب أو الويب من R Studio ، ويستخدم Shiny لتطوير تطبيقات الويب التي تم صقلها باستخدام الخوارزميات المطورة في R.
- سبارك للعمل مع البيانات ، يتم استخدام واجهات Python (pyspark) و R ، والتي تم تكوينها في بيئات التطوير المحددة في الفقرات السابقة. تسمح لك كلتا الواجهتين باستخدام مكتبة Spark ML ، مما يجعل من الممكن تدريب نماذج ML على مجموعة Hadoop / Spark.
- يمكن الوصول إلى بيانات Impala من خلال Hue و Spark ومن بيئات التطوير باستخدام واجهة ODBC القياسية والمكتبات الخاصة مثل implyr
حاليًا ، تحتوي Data Lake على حوالي 100 تيرابايت من البيانات من تخزين التجزئة ، بالإضافة إلى حوالي 50 تيرابايت من عدد من مصادر OLTP. يتم تحديث البحيرة يوميًا بشكل تدريجي. في المستقبل ، سنعمل على زيادة راحة المستخدم ، وتقديم تحميل ELT على Impala ، وزيادة عدد المصادر التي يتم تحميلها إلى Data Lake ، وتوسيع فرص التحليلات المتقدمة.
في الختام ، أود أن أقدم بعض النصائح العامة للزملاء الذين بدأوا للتو رحلتهم في إنشاء مستودعات كبيرة:
- استخدم أفضل الممارسات. إذا لم يكن لدينا نظام فرعي ETL ، وبيانات تعريف ، وتخزين إصدار ، وبنية مفهومة ، لما كنا نتقن هذه المهمة. أفضل الممارسات تدفع لأنفسهم ، وإن لم يكن على الفور.
- تذكر كمية البيانات. يمكن للبيانات الضخمة أن تخلق صعوبات فنية في أماكن غير متوقعة للغاية.
- ترقبوا التقنيات الجديدة. تظهر الحلول الجديدة في كثير من الأحيان ، ليست جميعها مفيدة ، ولكن في بعض الأحيان يتم العثور على جواهر حقيقية.
- جرب أكثر. لا تثق في الأوصاف التسويقية للحلول فقط - جربها بنفسك.
بالمناسبة ، يمكنك أن تقرأ كيف استخدم محللونا التعلم الآلي والبيانات المصرفية للعمل مع مخاطر الائتمان في منشور منفصل.