اليوم ، إحدى العقبات الرئيسية أمام إدخال التعلم الآلي في الأعمال التجارية هي عدم توافق مقاييس ML والمؤشرات التي تعمل معها الإدارة العليا. يتوقع المحلل زيادة الأرباح؟ ولكن عليك أن تفهم في أي الحالات سيصبح التعلم الآلي هو سبب الزيادة ، وفي أي عوامل أخرى. للأسف ، في كثير من الأحيان لا يؤدي التحسن في مقاييس ML إلى نمو الأرباح. بالإضافة إلى ذلك ، في بعض الأحيان يكون تعقيد البيانات لدرجة أنه حتى المطورين ذوي الخبرة يمكنهم اختيار مقاييس غير صحيحة لا يمكن توجيهها.
دعونا نلقي نظرة على مقاييس ML ومتى تكون مناسبة للاستخدام. سنحلل الأخطاء الشائعة ، بالإضافة إلى التحدث عن الخيارات المتاحة لتحديد المشكلة التي قد تكون مناسبة لتعلم الآلة والأعمال.
مقاييس ML: لماذا يوجد الكثير؟
مقاييس تعلُم الآلة محددة للغاية وغالبًا ما تكون مضللة ، حيث تُظهر
وجهًا جيدًا في لعبة سيئة ، وهي نتيجة جيدة للنماذج السيئة. لاختبار النماذج وتحسينها ، تحتاج إلى اختيار مقياس يعكس جودة النموذج بشكل مناسب وكيفية قياسه. عادة ، يتم استخدام مجموعة بيانات اختبار منفصلة لتقييم جودة النموذج. وكما تعلم ، فإن اختيار المقياس الصحيح مهمة صعبة.
ما المهام التي يتم حلها غالبًا بمساعدة التعلم الآلي؟ بادئ ذي بدء ، هذا هو الانحدار والتصنيف والتجميع. الأولين هما ما يسمى التدريب مع المعلم: هناك مجموعة من البيانات المصنفة ، بناءً على بعض الخبرة ، تحتاج إلى توقع القيمة المحددة. الانحدار هو توقع لبعض القيمة: على سبيل المثال ، كم سيشتري العميل ، ومقاومة التآكل للمواد ، وعدد الكيلومترات التي ستقطعها السيارة قبل الانهيار الأول.
التجميع هو تعريف بنية البيانات من خلال إبراز المجموعات (على سبيل المثال ، فئات العملاء) ، وليس لدينا افتراضات حول هذه المجموعات. لن نعتبر هذا النوع من المشاكل.
تعمل خوارزميات التعلم الآلي على تحسين القياس الرياضي (عن طريق حساب دالة الخسارة) - الفرق بين توقع النموذج والقيمة الحقيقية. ولكن إذا كان المقياس هو مجموع الانحرافات ، فعندما يكون بنفس عدد الانحرافات في كلا الاتجاهين ، فسيكون هذا المجموع صفراً ، ولن نعرف ببساطة ما إذا كان هناك خطأ. لذلك ، عادة ما يستخدمون المتوسط المطلق (مجموع القيم المطلقة للانحرافات) أو متوسط الخطأ التربيعي (مجموع مربعات الانحرافات عن القيمة الحقيقية). في بعض الأحيان تكون الصيغة معقدة: خذ اللوغاريتم أو استخرج الجذر التربيعي لهذه المبالغ. بفضل هذه المقاييس ، يمكنك تقييم ديناميكيات جودة حسابات النموذج ، ولكن لهذا تحتاج إلى مقارنة النتيجة بشيء ما.
لن يكون هذا صعبًا إذا كان هناك بالفعل نموذج مدمج لمقارنة النتائج به. ولكن ماذا لو كانت المرة الأولى التي أنشأت فيها نموذجًا؟ في هذه الحالة ، غالبًا ما يتم استخدام معامل التحديد ، أو R2. يتم التعبير عن معامل التحديد على النحو التالي:
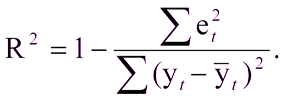
أين:
R ^ 2 - معامل التحديد ،
e
t ^ 2 هو متوسط الخطأ المربع ،
y
t هي القيمة الصحيحة ،
y
t مع الغلاف هو متوسط القيمة.
الوحدة ناقص نسبة الخطأ المربع التربيعي للنموذج إلى الخطأ التربيعي المتوسط لمتوسط قيمة عينة الاختبار.أي أن معامل التحديد يسمح لنا بتقييم تحسين التنبؤ بواسطة النموذج.
في بعض الأحيان يحدث أن خطأ في اتجاه ما لا يعادل خطأ في اتجاه آخر. على سبيل المثال ، إذا توقع نموذج طلبًا للبضائع في مستودع أحد المستودعات ، فمن الممكن تمامًا ارتكاب خطأ وطلب المزيد قليلاً ، وستنتظر البضائع في المستودع لوقتها. وإذا ارتكب النموذج خطأ في الاتجاه الآخر وأمر أقل ، فقد تخسر عملاء. في مثل هذه الحالات ، يتم استخدام الخطأ الكمي: يتم أخذ الانحرافات الإيجابية والسلبية عن القيمة الحقيقية في الاعتبار مع أوزان مختلفة.
في مشكلة التصنيف ، يوزع نموذج التعلم الآلي الكائنات في فئتين: يترك المستخدم الموقع أو لا يغادر ، والجزء معيب أو لا ، وما إلى ذلك. غالبًا ما يتم تقدير دقة التنبؤ كنسبة لعدد الفئات المحددة بشكل صحيح إلى العدد الإجمالي للتنبؤات. ومع ذلك ، نادرًا ما يمكن اعتبار هذه الخاصية معلمة مناسبة.
 التين. 1. مصفوفة خطأ لمشكلة التنبؤ بإرجاع العميلمثال
التين. 1. مصفوفة خطأ لمشكلة التنبؤ بإرجاع العميلمثال : إذا تقدم 7 أشخاص من أصل 100 مؤمن بطلب للحصول على تعويض ، فإن النموذج الذي يتنبأ بغياب حدث مؤمن عليه سيكون بدقة 93٪ دون أي قوة تنبؤية.
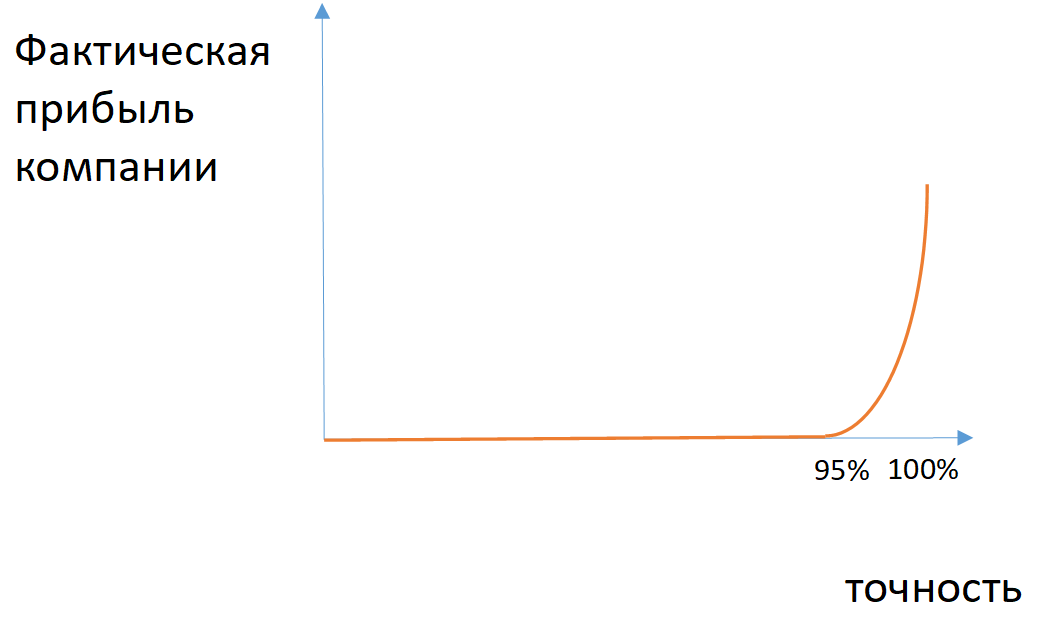 التين. 2. مثال على اعتماد الربح الفعلي للشركة على دقة النموذج في حالة الفئات غير المتوازنة
التين. 2. مثال على اعتماد الربح الفعلي للشركة على دقة النموذج في حالة الفئات غير المتوازنةبالنسبة لبعض المهام ، يمكنك تطبيق مقاييس الاكتمال (عدد العناصر المحددة بشكل صحيح للفئة بين جميع كائنات هذه الفئة) والدقة (عدد الكائنات المحددة بشكل صحيح للفئة بين جميع الكائنات التي خصصها النموذج لهذه الفئة). إذا كان من الضروري مراعاة كل من الاكتمال والدقة ، فقم بتطبيق المتوسط التوافقي بين هذه القيم (قياس F1).
باستخدام هذه المقاييس ، يمكنك تقييم التصنيفات المنجزة. ومع ذلك ، تتنبأ العديد من النماذج باحتمالية علاقة النموذج بفئة معينة. من وجهة النظر هذه ، من الممكن تغيير عتبة الاحتمالية فيما يتعلق بتخصيص العناصر لفئة أو فئة أخرى (على سبيل المثال ، إذا غادر العميل باحتمال 60٪ ، فيمكن اعتباره متبقيًا). إذا لم يتم تعيين عتبة معينة ، فعندئذٍ لتقييم فعالية النموذج ، من الممكن إنشاء رسم بياني لاعتماد المقاييس على قيم العتبة المختلفة (
منحنى ROC أو منحنى PR ) ، مع أخذ المساحة تحت المنحنى المحدد كمقياس.
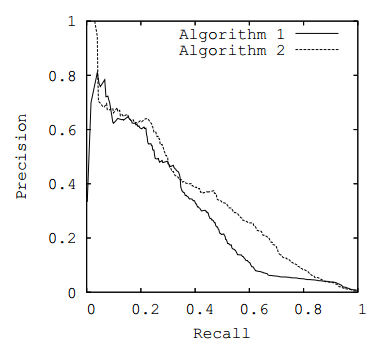 التين. 3. منحنى العلاقات العامة
التين. 3. منحنى العلاقات العامةمقاييس الأعمال
من الناحية المجازية ، فإن مقاييس الأعمال هي فيلة: لا يمكن تجاهلها ، وفي أحد هذه "الفيل" يمكن أن يصلح عدد كبير من "الببغاوات" لتعلم الآلة. تعتمد الإجابة على السؤال أي مقاييس ML على زيادة الأرباح على التحسين. في الواقع ، ترتبط مقاييس الأعمال بطريقة ما بزيادة الأرباح ، ولكننا لم نتمكن أبدًا من ربط الأرباح بها مباشرةً. تُستخدم المقاييس المتوسطة بشكل شائع ، على سبيل المثال:
- مدة البضاعة في المخزن وعدد طلبات البضاعة عندما لا تكون متاحة ؛
- مقدار المال الذي على وشك أن يغادره العملاء ؛
- كمية المواد التي يتم حفظها في عملية التصنيع.
عندما يتعلق الأمر بتحسين الأعمال باستخدام التعلم الآلي ، فإن إنشاء نموذجين يكون دائمًا ضمنياً: التنبئي والتحسين.
الأول أكثر تعقيدًا ، والثاني يستخدم نتائجه. تجبرنا الأخطاء في نموذج التنبؤ على وضع هامش أكبر في نموذج التحسين ، وبالتالي يتم تقليل الكمية المحسنة.
مثال : كلما انخفضت دقة التنبؤ بسلوك العملاء أو احتمالية حدوث عيوب صناعية ، قل عدد العملاء الذين يمكنهم الاحتفاظ بهم وأقل كمية المواد المحفوظة.
نادرًا ما يتم الحصول على المقاييس المقبولة عمومًا لنجاح الأعمال (EBITDA ، وما إلى ذلك) عند تحديد مهام ML. عادةً ما يتعين عليك دراسة التفاصيل بعمق وتطبيق المقاييس المقبولة في المجال الذي نقدم فيه التعلم الآلي (متوسط الشيك والحضور وما إلى ذلك).
صعوبات الترجمة
ومن المفارقات ، أنه من الأنسب تحسين النماذج باستخدام المقاييس التي يصعب على ممثلي الأعمال فهمها. كيف ترتبط المنطقة تحت منحنى ROC في نموذج الدرجة اللونية للتعليقات بحجم إيرادات محدد؟ من وجهة النظر هذه ، تواجه الأعمال مهمتين: كيفية القياس وكيفية تعظيم تأثير إدخال التعلم الآلي؟
المهمة الأولى أسهل في الحل إذا كان لديك بيانات استرجاعية وفي نفس الوقت يمكن تسوية العوامل الأخرى أو قياسها. ثم لا شيء يمنعك من مقارنة القيم التي تم الحصول عليها مع بيانات بأثر رجعي مماثلة. ولكن هناك تعقيد واحد: يجب أن تكون العينة ممثلة وفي نفس الوقت مماثلة للعينة التي نختبر بها النموذج.
مثال : تحتاج إلى العثور على العملاء الأكثر تشابهًا لمعرفة ما إذا كان متوسط الشيك قد زاد. ولكن في الوقت نفسه ، يجب أن تكون عينة العملاء كبيرة بما يكفي لتجنب العواصف بسبب السلوك غير المعتاد. يمكن حل هذه المشكلة عن طريق إنشاء مجموعة كبيرة بما فيه الكفاية من العملاء المتشابهين واستخدامها للتحقق من نتيجة جهودهم.
ومع ذلك ، يمكنك أن تسأل: كيفية ترجمة المقياس المحدد إلى دالة فقدان (التي يقلّلها النموذج) للتعلم الآلي. لا يمكن حل هذه المهمة على الفور: سيتعين على مطوري النموذج الخوض في عمليات الأعمال بعمق. ولكن إذا كنت تستخدم مقياسًا يعتمد على العمل عند تدريب النموذج ، فإن جودة النماذج تنمو على الفور. لنفترض ، أنه إذا كان النموذج يتنبأ بما سيغادره العملاء ، فعند دور مقياس الأعمال ، يمكنك استخدام رسم بياني حيث يتم رسم عدد العملاء الذين يغادرون ، وفقًا للنموذج ، على أحد المحاور ، ويتم رسم المبلغ الإجمالي للأموال لهؤلاء العملاء على المحور الآخر. بمساعدة مثل هذا الجدول الزمني ، يمكن للعميل التجاري اختيار نقطة مناسبة له والعمل معها. إذا ، باستخدام التحويلات الخطية ، قمنا بتقليل الرسم البياني إلى منحنى PR (الدقة على محور واحد ، والاكتمال الثاني) ، ثم يمكننا تحسين المنطقة تحت هذا المنحنى في وقت واحد مع مقياس الأعمال.
 التين. 4. منحنى تأثير المال
التين. 4. منحنى تأثير المالالخلاصة
قبل تحديد مهمة تعلُّم الآلة وإنشاء نموذج ، عليك اختيار مقياس معقول. إذا كنت ستقوم بتحسين النموذج ، فيمكنك استخدام أحد المقاييس القياسية كدالة خطأ. تأكد من التنسيق مع العميل للمقياس المحدد وأوزانه ومعلمات أخرى ، وتحويل مقاييس الأعمال إلى نماذج ML. من حيث المدة ، يمكن مقارنة ذلك بتطوير النموذج نفسه ، ولكن بدون هذا لا معنى لبدء العمل. إذا قمت بإشراك علماء الرياضيات في دراسة العمليات التجارية ، فيمكنك تقليل احتمال حدوث أخطاء في المقاييس بشكل كبير. التحسين الفعال للنموذج مستحيل بدون فهم مجال الموضوع وتحديد المهمة بشكل مشترك على مستوى الأعمال والإحصاءات. وبعد كل الحسابات ، ستكون قادرًا على تقييم الربح (أو المدخرات) ، اعتمادًا على كل تحسين للنموذج.
Nikolay Knyazev ( iRumata ) ، رئيس مجموعة تعلُم الآلة ، Jet Infosystems