
اليوم ، يصعب تصور تطوير برامج عالية الجودة دون استخدام
طرق تحليل الكود الثابتة . يمكن تضمين التحليل الثابت لرمز البرنامج في بيئة التطوير (من خلال الطرق القياسية أو باستخدام المكونات الإضافية) ، ويمكن إجراؤه بواسطة برامج متخصصة قبل وضع الشفرة في التشغيل التجاري ، أو "يدويًا" بواسطة خبير عادي أو خارجي.
غالبًا ما يقال أن
تحليل الشفرة الديناميكية أو
اختبارات الاختراق يمكن أن تحل محل التحليل الثابت ، لأن طرق التحقق هذه ستكشف عن مشاكل حقيقية ولن تكون هناك نتائج إيجابية خاطئة. ومع ذلك ، هذه نقطة خلافية ، لأن التحليل الديناميكي ، على عكس التحليل الثابت ، لا يتحقق من جميع التعليمات البرمجية ، ولكنه يتحقق فقط من مقاومة البرنامج لمجموعة من الهجمات التي تحاكي أفعال المهاجم. قد يكون المهاجم أكثر إبداعًا من المدقق ، بغض النظر عمن يقوم بالتحقق: شخص أو آلة.
لن يكتمل التحليل الديناميكي إلا إذا تم إجراؤه على تغطية اختبار كاملة ، وهي مهمة صعبة عند تطبيقها على تطبيقات حقيقية. إن إثبات اكتمال تغطية الاختبار هو مشكلة غير قابلة للحل خوارزميًا.
يعتبر التحليل الإلزامي الإلزامي لشفرة البرنامج من الخطوات الضرورية عند تشغيل البرنامج مع متطلبات متزايدة لأمن المعلومات.
في الوقت الحالي ، هناك العديد من أجهزة تحليل الشفرة الثابتة المختلفة في السوق ، ويظهر المزيد والمزيد من المحللين الجدد باستمرار. من الناحية العملية ، هناك حالات يتم فيها استخدام العديد من أجهزة التحليل الثابتة معًا لتحسين جودة التحقق ، حيث يبحث المحللون المختلفون عن عيوب مختلفة.
لماذا لا يوجد محلل استاتيكي عالمي يمكنه فحص أي كود بشكل كامل والعثور على جميع العيوب الموجودة فيه بدون نتائج إيجابية خاطئة وفي نفس الوقت يعمل بسرعة ولا يتطلب الكثير من الموارد (وقت وحدة المعالجة المركزية والذاكرة)؟
قليلا عن هندسة التحليلات الثابتة
الجواب على هذا السؤال يكمن في هندسة التحليلات الثابتة. يتم بناء جميع المحللات الساكنة تقريبًا بطريقة أو بأخرى على مبدأ المجمعين ، أي في عملهم هناك مراحل من تحويل شفرة المصدر - نفس تلك التي يقوم بها المترجم.
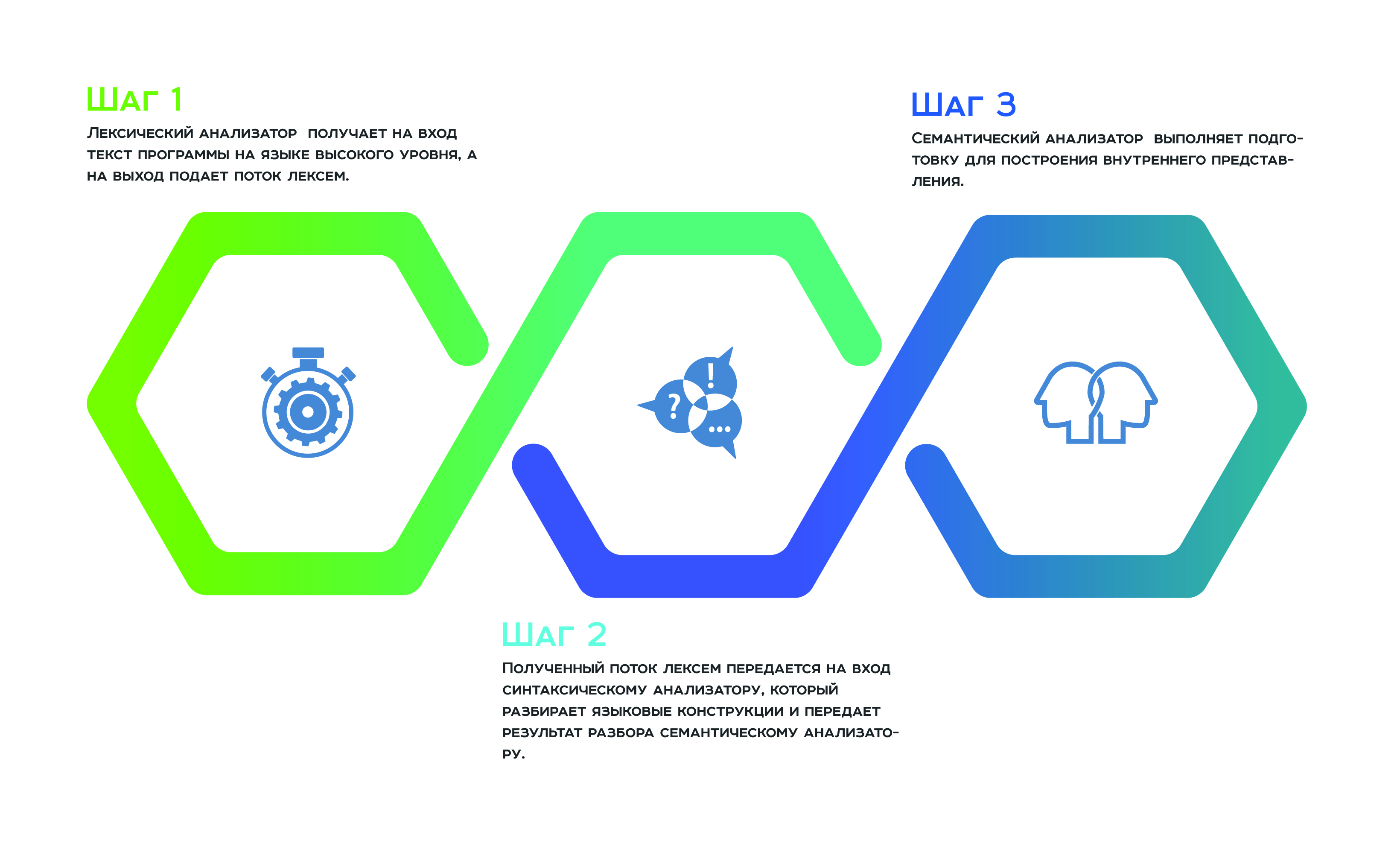
يبدأ كل شيء
بتحليل معجمي ، والذي يتلقى نص البرنامج بلغة عالية المستوى كمدخل ، وتدفق من الرموز المميزة إلى الإخراج. بعد ذلك ، يتم نقل دفق الرمز المميز المستلم إلى المدخلات
إلى المحلل اللغوي ، الذي يوزع تركيبات اللغة ويمرر نتيجة التحليل إلى
المحلل الدلالي ، والذي ، نتيجة لعمله ، يستعد لبناء التمثيل الداخلي. هذا التمثيل الداخلي هو ميزة لكل محلل ثابت. تعتمد كفاءة المحلل على مدى نجاحه.
يدعي العديد من الشركات المصنعة للمحللين الثابتين استخدام تمثيل داخلي عالمي لجميع لغات البرمجة التي يدعمها المحلل. وبالتالي ، يمكنهم تحليل رمز البرنامج الذي تم تطويره بعدة لغات ككل ، وليس كمكونات منفصلة. يسمح "النهج الشمولي" للتحليل بتجنب إغفال العيوب التي تنشأ عند التفاعل بين المكونات الفردية لمنتج البرنامج.
هذا صحيح من الناحية النظرية ، ولكن من الناحية العملية ، فإن التمثيل الداخلي الشامل لجميع لغات البرمجة أمر صعب وغير فعال. كل لغة برمجة خاصة. عادة ما تكون المنظر الداخلي عبارة عن شجرة تخزن قممها سماتها. من خلال اجتياز هذه الشجرة ، يقوم المحلل بجمع وتحويل المعلومات. لذلك ، يجب أن يحتوي كل قمة للشجرة على مجموعة موحدة من السمات. نظرًا لأن كل لغة فريدة من نوعها ، لا يمكن دعم توحيد السمات إلا من خلال تكرار المكونات. كلما زادت لغات البرمجة غير المتجانسة ، زادت المكونات غير المتجانسة في خصائص كل قمة ، وبالتالي ، فإن التمثيل الداخلي غير فعال من الذاكرة. يؤثر عدد كبير من الخصائص غير المتجانسة أيضًا على تعقيد مشوا الأشجار ، مما يعني أنه يؤدي إلى عدم الكفاءة في الأداء.
تحويلات التحسين للمحللات الساكنة
لكي يعمل المحلل الساكن بكفاءة في الذاكرة والوقت ، يجب أن يكون لديك تمثيل داخلي عالمي مضغوط ، ويمكن تحقيق ذلك من خلال حقيقة أن التمثيل الداخلي مقسم إلى عدة أشجار ، كل منها مصمم للغات البرمجة ذات الصلة.
لا يقتصر عمل التحسين على تقسيم التمثيل الداخلي إلى لغات البرمجة ذات الصلة. علاوة على ذلك ، يستخدم المصنعون العديد من تحويلات التحسين - كما هو الحال في تقنيات الترجمة ، على وجه الخصوص ،
تحويلات التحسين للدورات . والحقيقة هي أن الهدف من التحليل الثابت بشكل مثالي هو تنفيذ تعزيز البيانات في البرنامج من أجل تقييم تحولها أثناء تنفيذ البرنامج. لذلك ، يجب أن تكون البيانات "متقدمة" خلال كل دورة من الدورة. لذلك ، إذا قمت بحفظ هذه المنعطفات للغاية وجعلتها أصغر بكثير ، فسوف نحصل على فوائد كبيرة في الذاكرة والأداء. ولهذا الغرض يتم استخدام مثل هذه التحولات بنشاط والتي ، مع بعض الاحتمالات ، تقوم باستكمال تحويل البيانات إلى جميع دورات الدورة بأقل عدد من التمريرات.
يمكنك أيضًا التوفير في الفروع عن طريق حساب احتمالية انتقال البرنامج إلى فرع واحد أو آخر. إذا كان احتمال المرور على طول الفرع أقل من هذا ، فلن يتم النظر في فرع البرنامج هذا.
من الواضح أن كل من هذه التحولات "يفقد" العيوب التي يجب أن يكتشفها المحلل ، ولكن هذا "رسم" لكفاءة الذاكرة والأداء.
ما الذي يبحث عنه محلل الكود الثابت؟
بشكل مشروط ، يمكن تقسيم العيوب التي تهتم بطريقة ما بالمتسللين ، وبالتالي ، المدققين ، إلى المجموعات التالية:
- أخطاء التحقق
- أخطاء تسرب المعلومات ،
- أخطاء المصادقة.
تحدث
أخطاء التحقق نتيجة لحقيقة عدم التحقق من صحة بيانات الإدخال بشكل صحيح. يمكن للمهاجم التسلل كمدخلات غير ما يتوقعه البرنامج ، وبالتالي الحصول على وصول غير مصرح به إلى عنصر التحكم. أكثر أخطاء التحقق من صحة البيانات شيوعًا هي عمليات الحقن و
XSS . بدلاً من البيانات الصالحة ، يرسل المهاجم إلى إدخال البرنامج بيانات معدة خصيصًا تحمل برنامجًا صغيرًا. يتم تنفيذ هذا البرنامج ، بعد معالجته. قد تكون نتيجة تنفيذه نقل السيطرة إلى برنامج آخر ، وفساد البيانات وأكثر من ذلك بكثير. أيضًا ، نتيجة لأخطاء التحقق ، يمكن استبدال الموقع الذي يعمل معه المستخدم. يمكن الكشف عن أخطاء التحقق نوعيًا من خلال طرق تحليل التعليمات البرمجية الثابتة.
أخطاء
تسرب المعلومات هي أخطاء تتعلق بحقيقة أن المعلومات الحساسة من المستخدم نتيجة للمعالجة تم اعتراضها وإرسالها إلى المهاجم. يمكن أن يكون العكس هو الصحيح: يتم اعتراض المعلومات الحساسة المخزنة في النظام وإرسالها إلى المهاجم أثناء انتقالها إلى المستخدم.
من الصعب اكتشاف نقاط الضعف هذه مثل أخطاء التحقق من الصحة. يتطلب الكشف عن هذا النوع من الأخطاء تتبع الإحصائيات في تقدم البيانات وتحويلها عبر رمز البرنامج. وهذا يتطلب تنفيذ طرق مثل
التحليل العريض وتحليل البيانات التفسيرية . تعتمد دقة التحليل إلى حد كبير على مدى جودة تطوير هذه الأساليب ، أي تقليل الإيجابيات الزائفة والأخطاء الفائتة.
تلعب مكتبة قواعد الكشف عن العيوب ، على وجه الخصوص ، تنسيق وصف هذه القواعد ، دورًا مهمًا في دقة المحلل الثابت. كل هذا ميزة تنافسية لكل محلل ومحمي بعناية من المنافسين.
أخطاء المصادقة هي
الأخطاء الأكثر إثارة للاهتمام للمهاجم ، حيث يصعب اكتشافها لأنها تنشأ عند تقاطع المكونات ويصعب إضفاء الطابع الرسمي عليها. يستغل المهاجمون هذا النوع من الأخطاء لتصعيد حقوق الوصول. لا يتم اكتشاف أخطاء المصادقة تلقائيًا ، نظرًا لأنه ليس من الواضح ما الذي تبحث عنه - هذه أخطاء في منطق بناء البرنامج.
أخطاء الذاكرة
يصعب اكتشافها لأن التحديد الدقيق يتطلب حل نظام معادلات مرهق ، وهو مكلف في الذاكرة والأداء. لذلك ، يتم تقليل نظام المعادلات ، مما يعني فقدان الدقة.
تتضمن أخطاء الذاكرة النموذجية
الاستخدام بعد الاستخدام ،
والمزدوج ،
والإشارة الخالية من المؤشرات ، وأصنافها ، على سبيل المثال ،
القراءة خارج الحدود والقراءة والكتابة خارج الحدود .
عندما فشل المحلل التالي في اكتشاف تسرب للذاكرة ، يمكنك سماع أن مثل هذه العيوب يصعب استغلالها. يجب أن يكون المهاجم مؤهلاً تأهيلاً عالياً وأن يطبق الكثير من المهارة ، أولاً ، لمعرفة وجود مثل هذا العيب في التعليمات البرمجية ، وثانياً ، للقيام باستغلال. حسنًا ، تستمر الحجة: "هل أنت متأكد من أن منتج البرنامج الخاص بك مثير للاهتمام لمعلم من هذا المستوى؟" ... ومع ذلك ، يعرف التاريخ الحالات التي تم فيها استغلال أخطاء الذاكرة بنجاح وتسببت في تلف كبير. كأمثلة ، يمكنك الاستشهاد بمواقف معروفة مثل:
- CVE-2014-0160 - خطأ في مكتبة opensl - تتطلب تسوية محتملة للمفاتيح الخاصة إعادة إصدار جميع الشهادات وإعادة إنشاء كلمة المرور.
- CVE-2015-2712 - خلل في تنفيذ شبيبة في موزيلا فايرفوكس - التحقق من الحدود.
- CVE-2010-1117 - استخدم بعد مجانًا في Internet Explorer - قابل للاستغلال عن بُعد.
- CVE-2018-4913 - استخدم بعد مجانًا في Acrobat Reader - تنفيذ التعليمات البرمجية.
أيضًا ، يحب المهاجمون استغلال العيوب المرتبطة بالتزامن غير الصحيح للخيوط أو العمليات. يصعب تحديد مثل هذه العيوب في الإحصائيات ، لأن محاكاة حالة الآلة بدون مفهوم "الوقت" ليست مهمة سهلة. يشير هذا إلى أخطاء مثل
حالة السباق . واليوم ، يتم استخدام التزامن في كل مكان ، حتى في التطبيقات الصغيرة جدًا.
تلخيص ما سبق ، تجدر الإشارة إلى أن محلل ثابت مفيد في عملية التطوير ، إذا تم استخدامه بشكل صحيح. أثناء التشغيل ، من الضروري فهم ما يمكن توقعه منه وما يجب القيام به مع تلك العيوب التي لا يمكن للمحلل الساكن التعرف عليها من حيث المبدأ. إذا قالوا إن هناك حاجة إلى محلل ثابت أثناء عملية التطوير ، فهذا يعني أنهم ببساطة لا يعرفون كيفية تشغيله.
كيفية تشغيل المحلل الثابت بشكل صحيح ، للعمل بشكل صحيح وفعال مع المعلومات التي يوفرها ، اقرأ في مدونتنا.