إذا كنت مغرمًا بتقنيات الشبكات العصبية لفترة طويلة ، فربما تكون قد صادفت رأيًا اختتمته لفترة وجيزة في السؤال البلاغي: "كيف تشرح لشخص ما عندما ترى الشبكة العصبية أنها مصابة بالسرطان؟" وإذا كانت هذه الأفكار في أفضل الأحوال تجعلك تشك في استخدام الشبكات العصبية في مناطق
مسؤولة بما فيه الكفاية ، فقد تفقد في كل الأحوال اهتمامك.
لقد صادفت أفضل خيار - لقد قبلت بهدوء هذا القيد ، ودون تفكير كبير ، واصلت استخدام تقنيات الشبكات العصبية في مجال رؤية الكمبيوتر.
التحدي
في الآونة الأخيرة ، تقع على عاتقي مهمة - لإنشاء كاشف قابل للتطبيق للعواطف بسرعة. تم تحديد الشروط بوضوح تام - شخص في المقدمة بدقة تبلغ 100 × 100. بحثًا عن مجموعة بيانات منتهية ، أمضيت بضع ساعات وأدركت أنه لا يوجد شيء عملي يناسبني. أو حتى "لأغراض البحث" كان من الصعب للغاية الوصول إلى مجموعة البيانات. تم العثور على المخرج بسرعة - لأخذ عشرات الأفلام الروائية وتشغيلها ببساطة من خلال سلسلة Haar لتفريغ جميع الوجوه. خلال الليل ، تم تلقي أكثر من 30 صورة (!). علاوة على ذلك ، تم فرز الصور المستلمة حسب 5 عواطف رئيسية (سعيد ، حزين ، محايد ، غاضب ، متفاجئ). بالطبع ، بعيدًا عن جميع الصور المناسبة ، ونتيجة لذلك ، سقطت 400-500 صور وجه في كل فئة.
ثم بدأ كل شيء بموضوع شرح نتائج الشبكات العصبية. حتى مع زيادة البيانات المخصصة عالية الجودة بما فيه الكفاية ، بدت مجموعة البيانات هذه غير كافية بشكل واضح. عند تدريب شبكة على أساس كتل Resnet ، تم الحصول على الأرقام التالية للمقاييس:
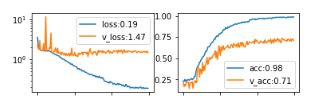
إعادة التدريب على خلفية عدد غير كاف من الأمثلة ، ولكن بسبب ضيق الوقت كان من الملح التأكد من أن الشبكة تعمل على الأقل إلى حد ما بشكل مرضٍ ولا تعتمد على ، على سبيل المثال ، تحديد العواطف.
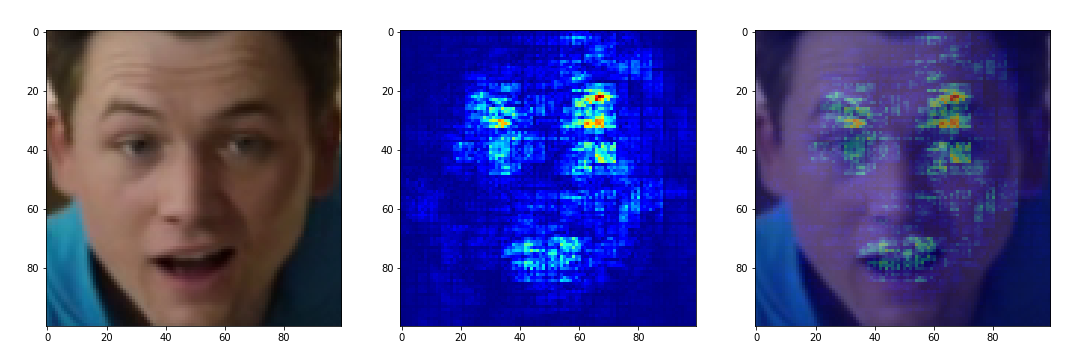
اعتدت أن أعمل مع أدوات مثل Lime و Keras-Vis ، ولكن هنا يمكن أن يصبحوا حجرًا فلسفيًا يحول الصندوق الأسود إلى شيء أكثر شفافية. جوهر كلتا الأداتين هو نفسه تقريبًا - لتحديد مناطق الصورة المصدر التي تقدم أكبر مساهمة في الحل النهائي للشبكة. من أجل الاختبار ، قمت بتصوير مقطع فيديو يقلد العديد من المشاعر. بعد أن أفرغت تعابير الوجه المطابقة للعواطف المختلفة ، قمت بتشغيل الأدوات المذكورة أعلاه عليها
تم الحصول على النتائج التالية من الجير:

لسوء الحظ ، حتى مع تغيير المعلمات المختلفة للوظائف ، لم يتمكن Lime من الحصول على ما يكفي من العرض المقروء من قبل الإنسان. لسبب ما ، يؤثر النصف الأيمن من الوجه على الانتماء إلى الطبقة "الغاضبة". الشيء الوحيد "السعيد" هو المنطقة المنطقية للفم والدمامل النموذجية للابتسامة.
علاوة على ذلك ، تم تشغيل جميع الصور نفسها من خلال Keras-Vis و bingo:
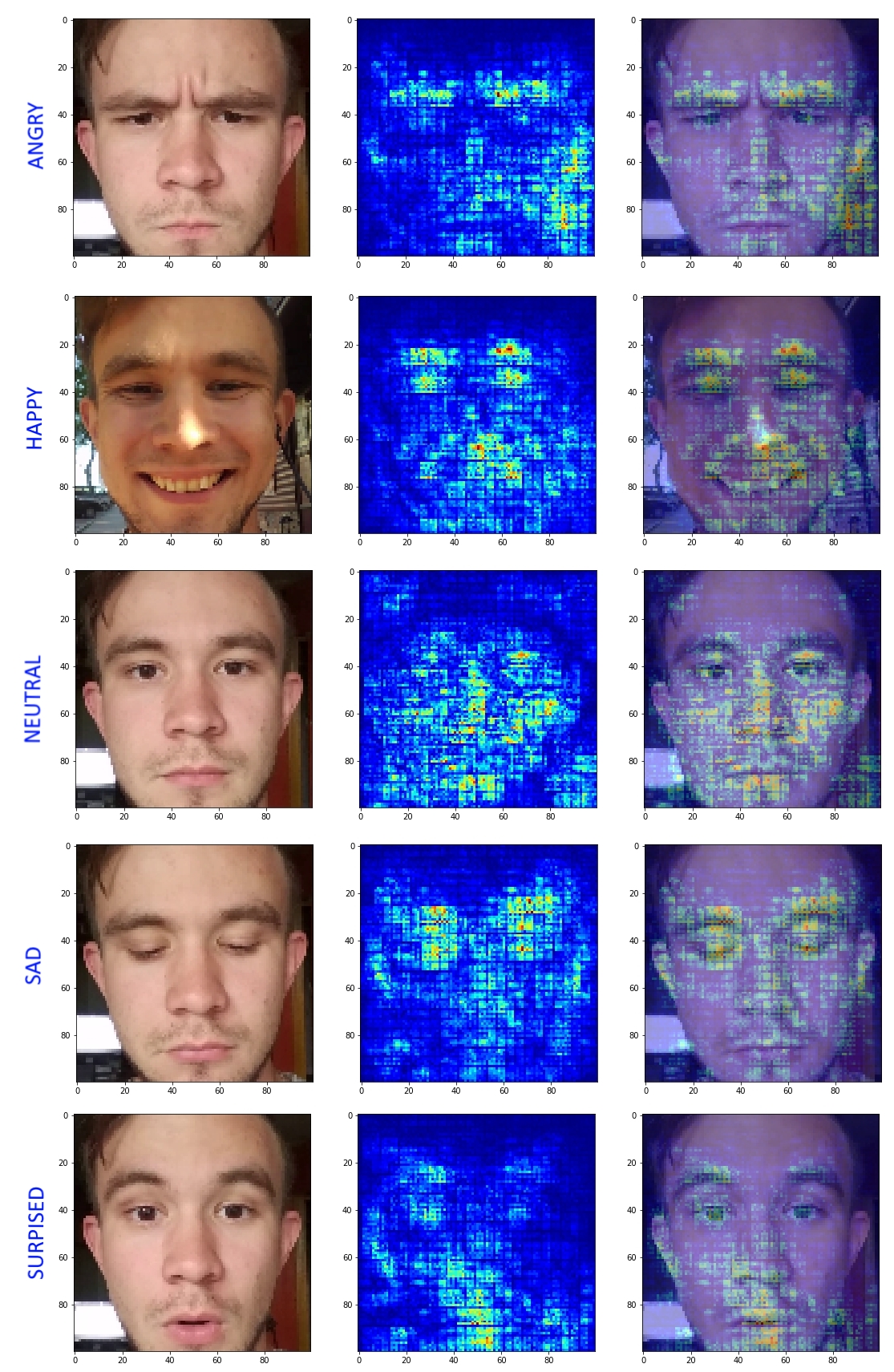
السعيد يبحث عن مكان العيون وشكل الفم. يركز Sad على تدلى الحاجبين والجفون. يحاول المحايد أن ينظر إلى الوجه بأكمله ككل وفي الزوايا السفلية البريئة من الصورة. يركز "غاضب" منطقيًا على الحواجب المتغيرة ، لكنه ينسى شكل الفم ولسبب ما يبحث عن ميزات في الزاوية اليمنى السفلية. و "المفاجأة" تنظر إلى شكل الفم والجفن الأيسر (!) الجفن المرتفع - لقد حان الوقت لبدء التعرف على الشكل الصحيح أيضًا.
وقد أسرت النتائج وجعلت من الممكن رؤية نقاط القوة والضعف في الشبكة الناتجة. بعد أن شعرت بضعف في تصنيف فصول المفاجأة والغاضبين ، وجدت القوة لزيادة العينة قليلاً وإضافة انخفاض أكثر للتسرب. في التكرار التالي ، تم الحصول على النتائج التالية:

يُلاحظ أن مناطق التنشيط كانت أكثر توطينًا. اختفى انتباه الشبكة للخلفية في حالة "غاضب". بالطبع ، لا تزال الشبكة تعاني من عيوبها ، وتنسى الحاجب من جانب واحد وما إلى ذلك. لكن هذا النهج جعل من الممكن فهم ما ولماذا يفعل النموذج الناتج بشكل أفضل. هذا النهج مثالي في الحالات التي يكون لدينا فيها شكوك حول التقارب الصحيح للشبكة.
الاستنتاجات
تبقى الشبكات العصبية مجرد حل لمشكلة التحسين المعقدة. ولكن حتى أبسط بطاقات انتباه الشبكة تجلب بعض الشفافية إلى هذه الغابة. يمكن استخدام هذا النهج جنبًا إلى جنب مع التوجيه المعتاد لوظيفة الخسارة ، والذي سيسمح بالحصول على شبكات واعية أكثر.
إذا تذكرنا السؤال البلاغي من بداية المقال ، فيمكننا القول أن استخدام بطاقات الانتباه إلى جانب الاستجابة النهائية للشبكة يحمل بالفعل تفسيرًا واضحًا محددًا كان يفتقر إليه.
تصور وتصور وتصور مرة أخرى!