
بدأنا في تحديث المراقبة لـ PgBouncer في خدمتنا وقررنا تمشيط كل شيء قليلاً. لجعل كل شيء مناسبًا ، اعتمدنا على أكثر منهجيات مراقبة الأداء شهرة: الاستخدام (الاستخدام ، التشبع ، الأخطاء) بواسطة Brendan Gregg و RED (الطلبات والأخطاء والمدد) من Tom Wilkie.
تحت المشهد هو قصة تحتوي على رسوم بيانية حول كيفية عمل pgbouncer ، وما هي التكوينات التي تعالجها وكيفية استخدام USE / RED لاختيار المقاييس المناسبة لرصدها.
أولا عن الأساليب نفسها
على الرغم من أن هذه الأساليب معروفة تمامًا ( حولها كانت موجودة بالفعل في حبري ، على الرغم من أنها ليست بتفصيل كبير ) ، ولكن ليس أنها منتشرة على نطاق واسع في الممارسة.
استخدم
لكل مورد ، تتبع التخلص والتشبع والأخطاء.
بريندان جريج
هنا ، المورد هو أي مكون مادي منفصل - وحدة المعالجة المركزية ، القرص ، الناقل ، إلخ. ولكن ليس فقط - يمكن أيضًا النظر في أداء بعض موارد البرامج من خلال هذه الطريقة ، ولا سيما الموارد الافتراضية ، مثل الحاويات / مجموعات المجموعات ذات القيود ، فمن المناسب أيضًا مراعاة ذلك.
U - التخلص : إما نسبة مئوية من الوقت (من فاصل المراقبة) عندما كان المورد مشغولاً بعمل مفيد. على سبيل المثال ، يعني تحميل وحدة المعالجة المركزية أو استخدام القرص بنسبة 90٪ أن 90٪ من الوقت قد استغرقه شيء مفيد) أو بالنسبة إلى الموارد مثل الذاكرة ، هذه هي النسبة المئوية للذاكرة المستخدمة.
على أي حال ، يعني إعادة التدوير بنسبة 100٪ أنه لا يمكن استخدام المورد أكثر من الآن. وإما أن يتعثر العمل في انتظار التحرير / الانتقال إلى قائمة الانتظار ، أو ستكون هناك أخطاء. يتم تغطية هذين السيناريوهين من خلال مقاييس الاستخدام المتبقيتين المقابلة:
ق- التشبع ، هو أيضًا التشبع: مقياس لمقدار العمل "المؤجل" / الطابور.
الأخطاء الإلكترونية : نحن ببساطة نحسب عدد الأعطال. تؤثر الأخطاء / الفشل على الأداء ، ولكن قد لا تكون ملحوظة على الفور بسبب استرداد العمليات المعكوسة أو آليات تحمل الخطأ مع أجهزة النسخ الاحتياطي ، إلخ.
أحمر
كان توم ويلكي (الذي يعمل الآن في مختبرات Grafana) محبطًا من منهجية USE ، أو بالأحرى ، ضعف تطبيقه في بعض الحالات وتعارضه مع الممارسة. كيف ، على سبيل المثال ، لقياس تشبع الذاكرة؟ أو كيفية قياس أخطاء ناقل النظام في الممارسة؟
تبين ، لينكس ، حقا تقارير عن الأخطاء.
T. Wilkie
باختصار ، من أجل مراقبة أداء وسلوك الخدمات الصغيرة ، اقترح طريقة أخرى مناسبة: لقياس ثلاثة مؤشرات مرة أخرى:
R - المعدل : عدد الطلبات في الثانية.
الأخطاء الإلكترونية : عدد الطلبات التي أرجعت خطأ.
د - المدة : الوقت المستغرق لمعالجة الطلب. إنه الكمون ، "الكمون" (© Sveta Smirnova :) ، وقت الاستجابة ، إلخ.
بشكل عام ، تعد USE أكثر ملاءمة لرصد الموارد ، و RED للخدمات وعبء العمل / الحمولة.
Pgbouncer
كونها خدمة ، لديها في الوقت نفسه جميع أنواع الحدود والموارد الداخلية. ويمكن قول الشيء نفسه عن Postgres ، التي يمكن للعملاء الوصول إليها من خلال PgBouncer هذا. لذلك ، من أجل المراقبة الكاملة في هذه الحالة ، هناك حاجة إلى كلتا الطريقتين.
لفهم كيفية تطبيق هذه الأساليب على الحارس ، تحتاج إلى فهم تفاصيل جهازه. لا يكفي مراقبته كصندوق أسود - "هل عملية pgbouncer على قيد الحياة" أو "هل المنفذ مفتوح" ، لأن في حالة حدوث مشاكل ، لن يعطي هذا فهمًا لما بالضبط وكيف انكسر وماذا يفعل.
ما الذي يفعله بشكل عام شكل PgBouncer من وجهة نظر العميل:
- يربط العميل
- [العميل يقدم طلبًا - يتلقى ردًا] × عدد المرات التي يحتاجها
لقد رسمت هنا رسمًا تخطيطيًا لحالات العميل المقابلة من وجهة نظر PgBoucer:

في عملية تسجيل الدخول ، يمكن أن يحدث التخويل محليًا (الملفات والشهادات وحتى PAM و hba من الإصدارات الجديدة) ، وعن بُعد - أي في قاعدة البيانات نفسها التي يتم محاولة الاتصال بها. وبالتالي ، فإن حالة تسجيل الدخول لديها حالة فرعية إضافية. دعنا نسميها Executing للإشارة إلى أن auth_query في قاعدة البيانات في الوقت الحالي:
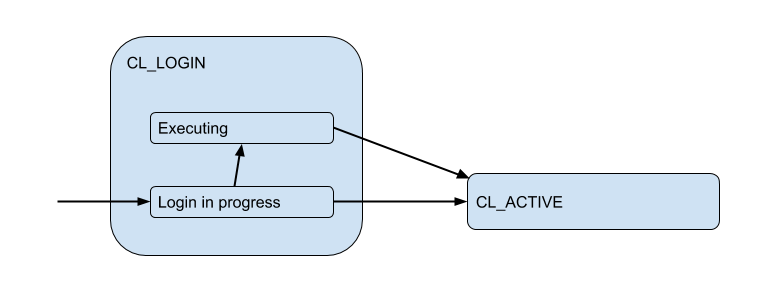
لكن اتصالات العملاء هذه تتطابق فعليًا مع اتصالات الواجهة الخلفية / المنبع التي يفتحها PgBouncer داخل التجمع ويحمل عددًا محدودًا. ويعطون مثل هذا الاتصال للعميل فقط للوقت - طوال مدة الجلسة أو المعاملة أو الطلب ، اعتمادًا على نوع التجمع (الذي يحدده إعداد pool_mode ). في معظم الأحيان ، يتم استخدام تجميع المعاملات (سنناقشه بشكل أساسي لاحقًا) - عندما يتم إصدار الاتصال للعميل لمعاملة واحدة ، وبقية الوقت غير متصل العميل بالخادم في الواقع. وهكذا ، تخبرنا الحالة "النشطة" للعميل بالقليل ، وسنقسمها إلى ركائز:
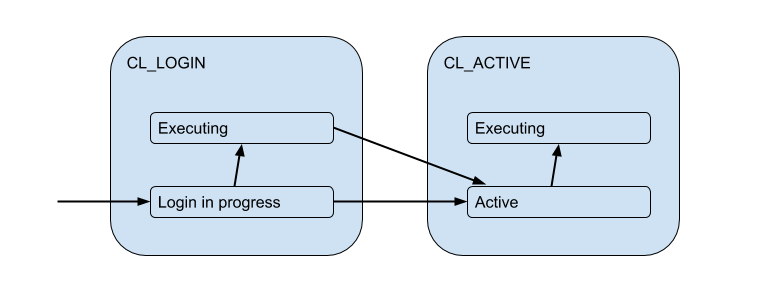
يقع كل عميل من هذا النوع في مجموعة الاتصال الخاصة به ، والتي سيتم إصدارها للاستخدام من خلال الاتصال الحقيقي بـ Postgres. هذه هي المهمة الرئيسية لـ PgBouncer - للحد من عدد الاتصالات بـ Postgres.
نظرًا لاتصالات الخادم المحدودة ، قد ينشأ موقف عندما يحتاج العميل إلى تلبية الطلب مباشرة ، ولكن لا يوجد اتصال مجاني الآن. ثم يتم وضع العميل في قائمة الانتظار ويذهب اتصاله إلى حالة CL_WAITING . وبالتالي ، يجب استكمال مخطط الحالة:
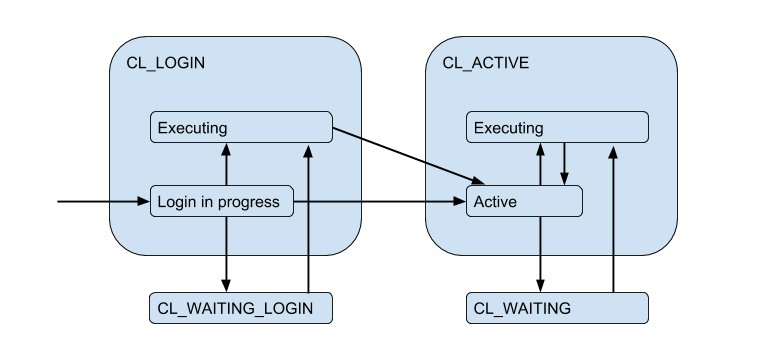
نظرًا لأن هذا يمكن أن يحدث في الحالة التي يقوم فيها العميل بتسجيل الدخول فقط ويحتاج إلى تنفيذ طلب ترخيص ، CL_WAITING_LOGIN أيضًا حالة CL_WAITING_LOGIN .
إذا نظرنا الآن من الجانب الخلفي - من جانب اتصالات الخادم ، فحينئذٍ ، يكونون في مثل هذه الحالات: عندما يحدث التفويض فورًا بعد الاتصال - SV_LOGIN ، الذي تم إصداره (وربما) استخدامه من قبل العميل - SV_ACTIVE ، أو بحرية - SV_IDLE .
استخدام PgBouncer
وهكذا نأتي إلى (الإصدار الساذج) استخدام تجمع معين:
Pool utiliz = /
يحتوي PgBouncer على قاعدة بيانات أداة مساعدة pgbouncer خاصة حيث يوجد أمر SHOW POOLS الذي يعرض الحالة الحالية لاتصالات كل تجمع:

هناك 4 اتصالات عميل مفتوحة وكلها cl_active . من أصل 5 اتصالات خادم - 4 sv_active وواحد في الحالة الجديدة sv_used .
ما هو sv_used حقا حول إعدادات pgbouncer مختلفة لا علاقة لها بالرصدلذا لا يعني sv_used "يتم استخدام الاتصال" ، كما قد تعتقد ، ولكن "تم استخدام الاتصال مرة واحدة ولم يتم استخدامه لفترة طويلة". والحقيقة هي أن PgBouncer يستخدم اتصالات الخادم في وضع LIFO بشكل افتراضي - أي أولاً ، يتم استخدام الاتصالات التي تم إصدارها حديثًا ، ثم الاتصالات التي تم استخدامها مؤخرًا ، وما إلى ذلك. تنتقل تدريجيًا إلى مركبات مستخدمة لفترة طويلة. وبناءً على ذلك ، فإن اتصالات الخادم من أسفل هذا المكدس يمكن أن "تسوء". ويجب التحقق من مدى حيويتها قبل الاستخدام ، والتي تتم باستخدام server_check_query ، أثناء الفحص ، سيتم التحقق من الحالة.
تقول الوثائق أن LIFO ممكّن افتراضيًا ، مثل ثم "يحصل عدد قليل من الاتصالات على أكبر قدر من العمل. وهذا يعطي أفضل أداء عندما يكون هناك خادم واحد يخدم قاعدة البيانات خلف pgbouncer" ، أي كما لو كان في الحالة الأكثر شيوعًا. أعتقد أن تعزيز الأداء المحتمل يرجع إلى التوفير في تبديل الأداء بين عمليات الواجهة الخلفية المتعددة. لكنه لم يعمل بشكل موثوق ، لأنه تفاصيل التنفيذ هذه موجودة منذ أكثر من 12 عامًا وتتجاوز تاريخ الالتزام في github وعمق اهتمامي =)
لذلك ، بدا الأمر غريبًا وغير server_check_delay مع الحقائق الحالية بأن القيمة الافتراضية لإعداد server_check_delay ، والتي تحدد أن الخادم لم يتم استخدامه لفترة طويلة ويجب التحقق منه قبل إعطائه للعميل ، 30 ثانية. هذا على الرغم من حقيقة أنه يتم تمكين tcp_keepalive بشكل افتراضي في نفس الوقت مع الإعدادات الافتراضية - ابدأ في التحقق من اتصال البقاء على قيد الحياة مع العينات بعد ساعتين من خمولها.
اتضح أنه في حالة الاندفاع / الطفرة لاتصالات العميل التي تريد القيام بشيء ما على الخادم ، يتم تقديم تأخير إضافي على server_check_query ، والذي ، على الرغم من " SELECT 1; قد يستغرق حوالي 100 ميكروثانية ، وإذا server_check_query = ';' ثم يمكنك حفظ ~ 30 ميكروثانية =)
لكن الافتراض بأن العمل في عدد قليل من الاتصالات = في العديد من عمليات postgres الخلفية "الرئيسية" سيكون أكثر كفاءة ، يبدو لي مشكوكًا فيه. معلومات ذاكرة التخزين المؤقت لعملية عامل عامل postgres (meta) حول كل جدول تم الوصول إليه في هذا الاتصال. إذا كان لديك عدد كبير من الجداول ، فيمكن أن تنمو هذه إعادة التخزين كثيرًا وتستهلك الكثير من الذاكرة ، حتى تبديل صفحات عملية 0_o. للتغلب على هذا ، استخدم إعداد server_lifetime (الافتراضي هو ساعة واحدة) ، حيث سيتم إغلاق اتصال الخادم للتدوير. ولكن من ناحية أخرى ، هناك إعداد server_round_robin الذي server_round_robin وضع استخدام الاتصالات من LIFO إلى FIFO ، مما ينشر طلبات العملاء على اتصالات الخادم بشكل متساوٍ.
SHOW POOLS أخذ المقاييس SHOW POOLS من SHOW POOLS (من قبل بعض مصدري بروميثيوس) يمكننا رسم هذه الحالات:
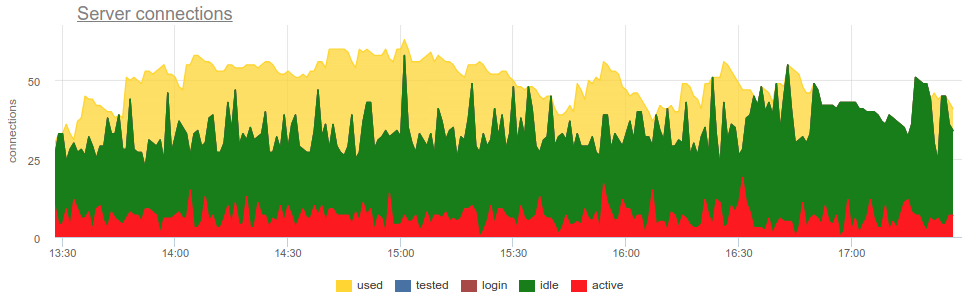
ولكن للوصول إلى التخلص ، عليك الإجابة على بعض الأسئلة:
- ما هو حجم البركة؟
- كيفية حساب عدد المركبات المستخدمة؟ في النكات أو في الوقت ، في المتوسط أو في الذروة؟
حجم التجمع
كل شيء معقد هنا ، كما في الحياة. في المجموع ، هناك بالفعل خمسة حدود للإعدادات في pbbouncer!
- يمكن تعيين
pool_size لكل قاعدة بيانات. يتم إنشاء تجمع منفصل لكل زوج DB / مستخدم ، أي من أي مستخدم إضافي ، يمكنك إنشاء backends pool_size آخر / عمال Postgres. لأن إذا لم pool_size تعيين pool_size ، فإنها تقع في default_pool_size ، والتي يتم تعيينها افتراضيًا على 20 ، ثم يتبين أن كل مستخدم لديه الحق في الاتصال بقاعدة البيانات (ويعمل من خلال pgbouncer) يمكنه إنشاء 20 عملية Postgres ، والتي يبدو أنها ليست كثيرة. ولكن إذا كان لديك العديد من المستخدمين المختلفين لقواعد البيانات أو قواعد البيانات نفسها ، ولم يتم تسجيل التجمعات مع مستخدم ثابت ، أي سيتم إنشاؤها على الطاير (ثم يتم حذفها بواسطة autodb_idle_timeout ) ، فقد يكون ذلك خطيرًا =)
قد يكون من المفيد ترك default_pool_size صغيرًا فقط لكل رجل إطفاء.
max_db_connections - مطلوب فقط لتقييد العدد الإجمالي للاتصالات بقاعدة بيانات واحدة ، لأن خلاف ذلك يمكن للعملاء الذين يتصرفون بشكل سيئ إنشاء العديد من عمليات backends / postgres. وبشكل افتراضي هنا - غير محدود ¯_ (ツ) _ / ¯
ربما يجب عليك تغيير max_db_connections الافتراضية ، على سبيل المثال ، يمكنك التركيز على max_connections الخاصة بك في Postgres (افتراضيًا 100). ولكن إذا كان لديك العديد من PgBouncers ...
pool_size - في الواقع ، إذا pool_size استخدام pool_size بالكامل ، فيمكن لـ PgBouncer فتح العديد من الاتصالات الأخرى بالقاعدة. كما أفهمها ، يتم ذلك للتعامل مع زيادة في الحمل. سنعود إلى هذا.max_user_connections - هذا ، على العكس ، هو حد الاتصالات من مستخدم واحد إلى جميع قواعد البيانات ، أي ذات صلة إذا كان لديك العديد من قواعد البيانات وتندرج تحت نفس المستخدمين.max_client_conn - عدد اتصالات العملاء التي سيقبلها PgBouncer في المجموع. الافتراضي ، كالعادة ، له معنى غريب للغاية - 100. هذا هو ، من المفترض أنه إذا تعطل أكثر من 100 عميل فجأة ، فإنهم يحتاجون فقط إلى reset بصمت على مستوى TCP وإعادة reset (حسنًا ، في السجلات ، يجب أن أعترف ، سيكون هذا "لا مزيد من الاتصالات المسموح بها (max_client_conn)").
قد يكون من المفيد إنشاء max_client_conn >> SUM ( pool_size' ) ، على سبيل المثال ، 10 مرات أكثر.
بالإضافة إلى SHOW POOLS خدمة pgbudo-base pgbouncer أيضًا SHOW DATABASES ، الذي يوضح الحدود المطبقة فعليًا على تجمع معين:

اتصالات الخادم
مرة أخرى - كيفية قياس عدد المركبات المستخدمة؟
في النكات في المتوسط / في الذروة / في الوقت المناسب؟
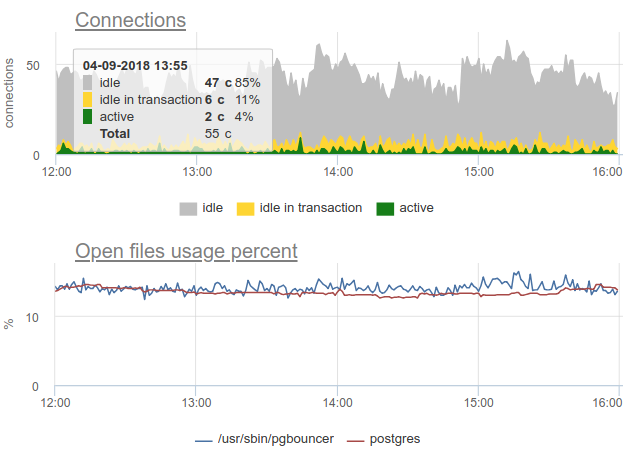
في الممارسة العملية ، من الصعب جدًا مراقبة استخدام حمامات السباحة بواسطة الحارس بأدوات واسعة الانتشار ، مثل يوفر pgbouncer نفسه صورة مؤقتة فقط ، وكثيرًا ما لا يقوم بالمسح ، لا يزال هناك احتمال وجود صورة خاطئة بسبب أخذ العينات. في ما يلي مثال حقيقي عندما تتوقف صورة كل من المركبات المفتوحة والمستخدمة بشكل أساسي ، اعتمادًا على الوقت الذي عمل فيه المصدر - في بداية الدقيقة أو في النهاية:
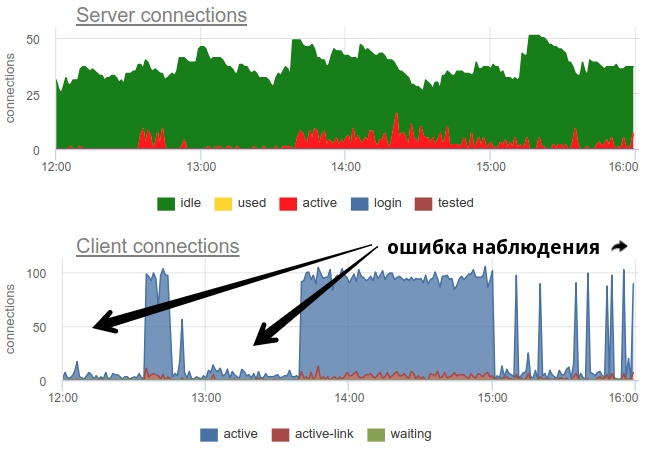
هنا جميع التغييرات في تحميل / استخدام الاتصالات هي مجرد خيال ، قطعة أثرية لإعادة تشغيل جامع الإحصائيات. هنا يمكنك رؤية الرسوم البيانية للاتصال في Postgres خلال هذا الوقت وأوصاف ملف الحارس و PG - لا توجد تغييرات:
العودة إلى قضية التخلص. قررنا استخدام نهج مشترك في خدمتنا - نقوم SHOW POOLS مرة واحدة في الثانية ، ومرة في الدقيقة نقدم كلاً من متوسط وأقصى عدد من الاتصالات في كل فئة:
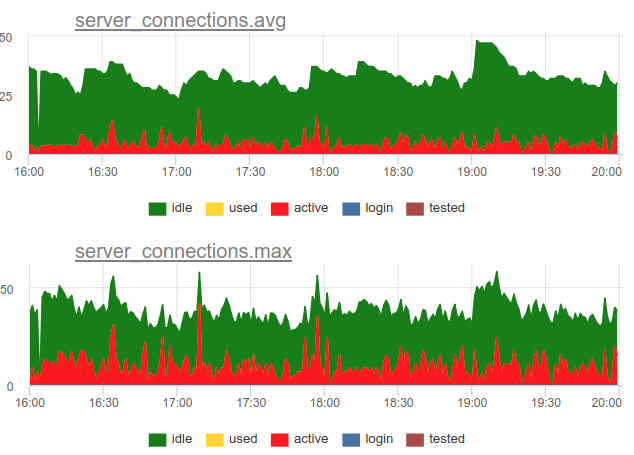
وإذا قسمنا عدد اتصالات الحالة النشطة هذه حسب حجم التجمع ، نحصل على متوسط الاستخدام الأقصى لهذه المجموعة ويمكننا التنبيه إذا كان قريبًا من 100٪.
بالإضافة إلى ذلك ، يحتوي PgBouncer على أمر SHOW STATS الذي سيعرض إحصائيات الاستخدام لكل قاعدة بيانات تم إنشاء وكيل لها:

نحن مهتمون أكثر بالعمود total_query_time - الوقت الذي تقضيه كل الاتصالات في عملية تنفيذ الاستعلامات في postgres. ومن الإصدار 1.8 هناك أيضًا المقياس total_xact_time - الوقت المستغرق في المعاملات. استنادًا إلى هذه المقاييس ، يمكننا بناء الاستفادة من وقت اتصال الخادم ؛ لا يخضع هذا المؤشر ، على عكس الحالات المحسوبة من حالات الاتصال ، لمشاكل أخذ العينات ، لأن total_..._time عدادات total_..._time تراكمية ولا تمر بأي شيء:

قارن
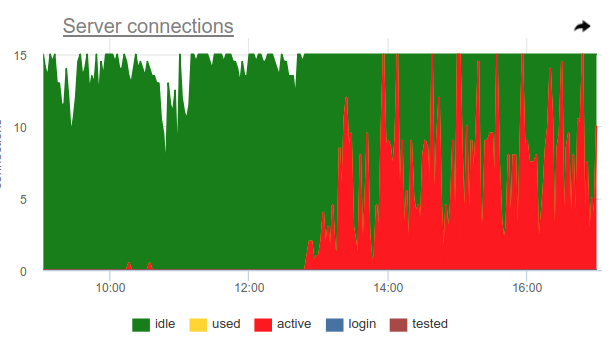
يمكن ملاحظة أن أخذ العينات لا يظهر جميع لحظات الاستخدام العالي ~ 100٪ ، وعروض وقت الاستعلام.
التشبع و PgBouncer
لماذا تحتاج إلى مراقبة التشبع ، بسبب الاستخدام العالي فمن الواضح بالفعل أن كل شيء سيئ؟
تكمن المشكلة في أنه بغض النظر عن كيفية قياس الاستخدام ، لا يمكن حتى للعدادات المتراكمة إظهار استخدام الموارد المحلية بنسبة 100٪ إذا كان يحدث فقط على فترات قصيرة جدًا. على سبيل المثال ، لديك أي تيجان أو عمليات متزامنة أخرى يمكن أن تبدأ في نفس الوقت في إجراء استعلامات لقاعدة البيانات في الأمر. إذا كانت هذه الطلبات قصيرة ، فقد يكون الاستخدام ، المقاس على مقاييس الدقائق وحتى الثواني ، منخفضًا ، ولكن في نفس الوقت ، في وقت ما ، اضطرت هذه الطلبات إلى الانتظار في طابور التنفيذ. هذا مشابه لحالة عدم استخدام 100٪ لوحدة المعالجة المركزية ومتوسط الحمل المرتفع - مثل وقت المعالج لا يزال موجودًا ، ولكن مع ذلك هناك العديد من العمليات في انتظار التنفيذ.
كيف يمكن مراقبة هذا الموقف - حسنًا ، مرة أخرى ، يمكننا ببساطة حساب عدد العملاء في حالة cl_waiting وفقًا cl_waiting . في الوضع العادي ، هناك صفر ، وأكثر من صفر يعني تجاوز هذا التجمع:
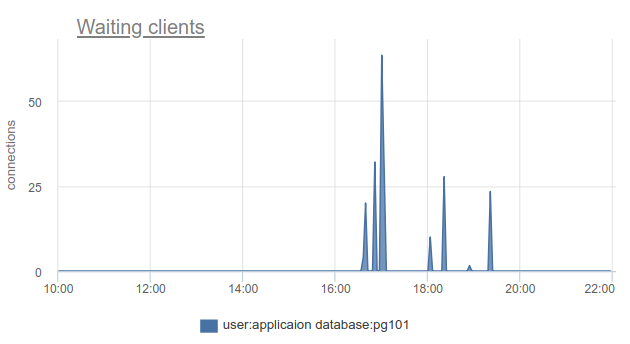
لا تزال هناك مشكلة تتمثل في أنه لا يمكن أخذ عينات من SHOW POOLS ، وفي حالة تيجان متزامنة أو شيء من هذا القبيل ، يمكننا ببساطة تخطي وعدم رؤية هؤلاء العملاء المنتظرين.
يمكنك استخدام هذه الخدعة ، pgbouncer نفسها يمكن أن تكتشف استخدام 100٪ للمجمع وفتح تجمع النسخ الاحتياطي. هناك إعدادان مسؤولان عن هذا: reserve_pool_size - لحجمه ، كما قلت ، و reserve_pool_timeout - عدد الثواني التي يجب أن waiting بعض العملاء قبل استخدام تجمع النسخ الاحتياطي. وبالتالي ، إذا رأينا على الرسم البياني لاتصالات الخادم أن عدد الاتصالات المفتوحة لـ Postgres أكبر من pool_size ، فحينئذٍ كان هناك تشبع في التجمع ، كما يلي:

من الواضح أن شيئًا مثل التيجان مرة واحدة في الساعة يجعل الكثير من الطلبات ويحتل المسبح تمامًا. وعلى الرغم من أننا لا نرى اللحظة التي تتجاوز فيها الاتصالات active حد pool_size ، لا يزال pgbouncer مضطرًا لفتح اتصالات إضافية.
أيضًا على هذا الرسم البياني ، تعمل إعدادات server_idle_timeout بوضوح - بعد مقدار التوقف عن الاحتفاظ وإغلاق الاتصالات غير المستخدمة. بشكل افتراضي ، هذه هي 10 دقائق ، والتي نراها على الرسم البياني - بعد القمم active في تمام الساعة 5:00 ، الساعة 6:00 ، إلخ. (وفقًا لكرون 0 * * * * ) ، يتم تعليق الاتصالات idle + used 10 دقائق أخرى وتغلق.
إذا كنت تعيش في طليعة التقدم وقمت بتحديث PgBouncer على مدى الأشهر التسعة الماضية ، يمكنك العثور في عمود SHOW STATS total_wait_time ، الذي يظهر أفضل تشبع ، لأن تراكم الوقت الذي يقضيه العملاء في حالة waiting تراكمي. على سبيل المثال ، هنا - ظهرت waiting في الساعة 16:30:
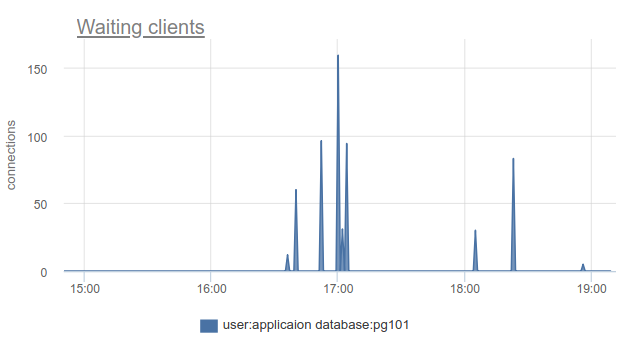
ويمكن رؤية average query time ، والذي يمكن مقارنته ويؤثر بشكل واضح على average query time ، من 15:15 إلى 19 تقريبًا:

ومع ذلك ، لا تزال مراقبة حالة اتصالات العملاء مفيدة للغاية ، لأنه يسمح لك باكتشاف ليس فقط حقيقة أن جميع الاتصالات بقاعدة البيانات هذه قد تم إنفاقها ويجب على العملاء الانتظار ، ولكن أيضًا لأن SHOW POOLS مقسمة إلى تجمعات منفصلة من قبل المستخدمين ، و SHOW STATS لا ، يسمح لك بمعرفة العملاء الذين استخدموا جميع الاتصالات إلى القاعدة المحددة - وفقًا لعمود sv_active الخاص sv_active المقابل. أو بالمقياس
sum_by(user, database, metric(name="pgbouncer.clients.count", state="active-link")):
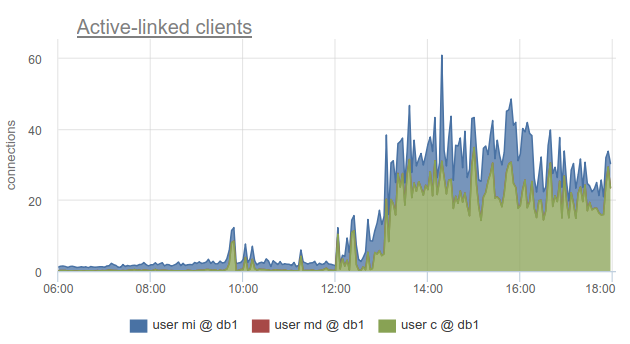
ذهبنا في okmeter إلى أبعد من ذلك وأضفنا تفصيلًا للاتصالات التي تستخدمها عناوين IP للعملاء الذين قاموا بفتحها واستخدامها. يسمح لك هذا بفهم أي مثيلات التطبيق تتصرف بشكل مختلف تمامًا:

هنا نرى IPs من kubernetes محددة من المداخن التي نحتاج إلى التعامل معها.
أخطاء
لا يوجد شيء صعب بشكل خاص هنا: يكتب pgbouncer السجلات التي يبلغ فيها عن الأخطاء إذا تم الوصول إلى حد اتصالات العميل ، ومهلة الاتصال بالخادم ، إلخ. لم نصل بعد إلى سجلات pgbouncer أنفسنا :(
أحمر لـ PgBouncer
في حين أن USE تركز بشكل أكبر على الأداء ، بمعنى الاختناقات ، فإن RED ، في رأيي ، أكثر حول خصائص حركة المرور الواردة والصادرة بشكل عام ، وليس حول الاختناقات. أي أن RED يجيب على السؤال - هل كل شيء يعمل بشكل جيد ، وإذا لم يكن كذلك ، فإن USE سيساعد على فهم ما هي المشكلة.
المتطلبات
يبدو أن كل شيء بسيط للغاية بالنسبة لقاعدة بيانات SQL ولجذب الوكيل / الاتصال في قاعدة البيانات هذه - يقوم العملاء بتنفيذ عبارات SQL ، وهي الطلبات. من SHOW STATS نأخذ total_requests مشتقاتها الزمنية
rate(metric(name="pgbouncer.total_requests", database: "*"))

ولكن في الواقع هناك طرق سحب مختلفة ، والأكثر شيوعًا هي المعاملات. وحدة العمل لهذا الوضع هي معاملة وليس استعلام. وفقًا لذلك ، بدءًا من الإصدار 1.8 ، يوفر Pgbouner بالفعل إحصائين آخرين - total_query_count ، بدلاً من total_requests ، و total_xact_count - عدد المعاملات المكتملة.
الآن يمكن وصف عبء العمل ليس فقط من حيث عدد الطلبات / المعاملات المكتملة ، ولكن ، على سبيل المثال ، يمكنك إلقاء نظرة على متوسط عدد الطلبات لكل معاملة في قواعد بيانات مختلفة ، وتقسيم واحد إلى آخر
rate(metric(name="total_requests", database="*")) / rate(metric(name="total_xact", database="*"))

هنا نرى تغييرات واضحة في ملف تعريف التحميل ، والتي قد تكون سبب التغيير في الأداء. وإذا نظرت فقط إلى معدل المعاملات أو الطلبات ، فقد لا ترى ذلك.
أخطاء RED
من الواضح أن RED و USE يتقاطعان في مراقبة الأخطاء ، ولكن يبدو لي أن الأخطاء في USE تتعلق بشكل أساسي بأخطاء معالجة الطلب بسبب الاستخدام بنسبة 100 ٪ ، أي عندما ترفض الخدمة قبول المزيد من العمل. وأخطاء RED سيكون من الأفضل قياس الأخطاء بدقة من وجهة نظر العميل ، طلبات العميل. أي أنه ليس فقط في الحالة التي يكون فيها التجمع في PgBouncer ممتلئًا أو يعمل حد آخر ، ولكن أيضًا عندما تعمل مهلات الطلب مثل "إلغاء البيان بسبب مهلة البيان" ، فإن عمليات إلغاء وإلغاء المعاملات من قبل العميل نفسه قد نجحت ، إلخ. ه. أعلى مستوى ، أقرب إلى أنواع أخطاء منطق الأعمال.
فترات
هنا مرة أخرى ، total_query_time SHOW STATS مع العدادات التراكمية total_xact_time و total_query_time و total_wait_time على تقسيمها على عدد الطلبات والمعاملات ، على التوالي ، نحصل على متوسط وقت الطلب ومتوسط وقت المعاملة ومتوسط وقت الانتظار لكل معاملة. لقد عرضت بالفعل رسمًا بيانيًا حول الأول والثالث:
ماذا يمكنك أن تحصل على تبرد؟ يذهب المضاد المعروف في العمل مع قاعدة البيانات و Postgres ، على وجه الخصوص ، عندما يفتح التطبيق معاملة ، أو يقدم طلبًا ، ثم يبدأ (لفترة طويلة) لمعالجة نتائجه ، أو الأسوأ - يذهب إلى بعض الخدمات / قاعدة البيانات الأخرى ويقدم الطلبات هناك. طوال هذا الوقت ، يتم تعليق المعاملة في postgres ، ثم تعود الخدمة وتقدم بعض الطلبات الأخرى ، والتحديثات في قاعدة البيانات ، وبعد ذلك فقط تغلق المعاملة. ل postgres هذا غير سارة خاصة ، لأنه العمال pg هي باهظة الثمن. حتى نتمكن من مراقبة متى يكون مثل هذا التطبيق idle in transaction في postgres نفسها - وفقًا لعمود state في pg_stat_activity ، ولكن لا تزال هناك نفس المشكلات الموضحة في أخذ العينات ، لأن pg_stat_activity يعطي الصورة الحالية فقط. في PgBouncer ، يمكننا طرح الوقت الذي يقضيه العملاء في total_query_time من الوقت الذي يقضيه في المعاملات total_xact_time - سيكون هذا وقت total_xact_time . إذا كانت النتيجة لا تزال مقسومة على total_xact_time ، فسيتم تطبيعها: القيمة 1 تقابل الحالة التي يكون فيها العملاء idle in transaction 100٪ من الوقت. ومع هذا التطبيع ، يجعل من السهل فهم مدى سوء كل شيء:
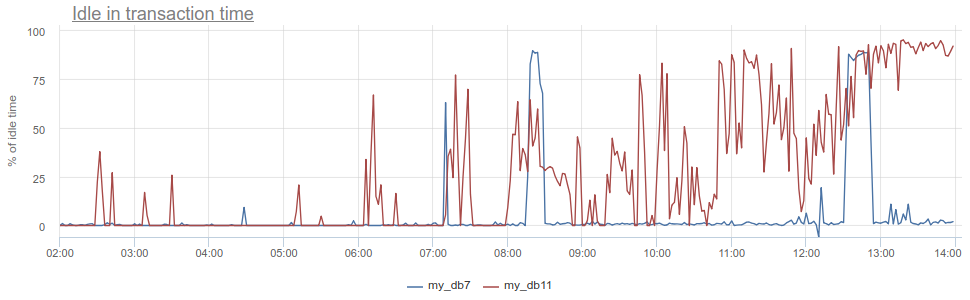
بالإضافة إلى ذلك ، عند الرجوع إلى Duration ، يمكن تقسيم المقياس total_xact_time - total_query_time على عدد المعاملات لمعرفة مقدار متوسط التطبيق الخامل لكل معاملة.
في رأيي ، فإن طرق USE / RED هي الأكثر فائدة في تنظيم المقاييس التي تلتقطها ولماذا. نظرًا لأننا منخرطون في المراقبة بدوام كامل وعلينا إجراء مراقبة للعديد من مكونات البنية التحتية ، فإن هذه الأساليب تساعدنا على أخذ المقاييس الصحيحة ، ووضع الجداول الزمنية والمحفزات المناسبة لعملائنا.
لا يمكن إجراء المراقبة الجيدة على الفور ؛ إنها عملية تكرارية. في okmeter.io لدينا فقط مراقبة مستمرة (هناك الكثير من الأشياء ، ولكن غدا سيكون أفضل وأكثر تفصيلاً :)