
اسمي يوري نيفينيتسين ، وأنا منخرط في نظام الإحصاءات الداخلية في OK. أريد أن أتحدث عن كيفية نقلنا لنظام تحليلي من 50 تيرابايت في الوقت الحقيقي ، حيث يتم تسجيل مليارات الأحداث يوميًا ، من Microsoft SQL إلى قاعدة عمود تسمى Druid. وفي نفس الوقت ستتعلم بعض الوصفات لاستخدام
Druid .
لماذا نحتاج إلى إحصائيات؟
نريد أن نعرف كل شيء عن موقعنا ، لذا فإننا لا نسجل فقط سلوك الأقراص والمعالجات ، وما إلى ذلك ، ولكن أيضًا كل إجراء للمستخدم ، وكل تفاعل بين الأنظمة الفرعية وجميع العمليات الداخلية لجميع أنظمتنا تقريبًا. يتم دمج نظام الإحصاء بشكل وثيق في عملية التنمية.
استنادًا إلى البيانات من نظام الإحصائيات ، حدد مدراؤنا الأهداف للفرق ، وتتبع إنجازاتهم والمؤشرات الرئيسية. يقوم المسؤولون والمطورون بمراقبة تشغيل جميع الأنظمة ، والتحقيق في الحوادث والشذوذ. تراقب المراقبة التلقائية باستمرار وفي مرحلة مبكرة تحدد المشاكل ، وتتنبأ بتجاوز الحدود. أيضًا ، يتم إطلاق الميزات والتجارب باستمرار ، ويتم إجراء التحديثات والتغييرات. ونراقب تأثير كل هذه الإجراءات من خلال نظام الإحصاء. إذا رفضت ، فلن نتمكن من إجراء تغييرات على الموقع.
يتم عرض إحصاءاتنا بشكل رئيسي في شكل رسوم بيانية. عادة ، يعرض المخطط عدة أيام في وقت واحد ، بحيث تكون الديناميكيات واضحة. هنا مثال لتجاربي مع درويد. هنا رسم بياني لتحميل البيانات (خطوط / 5 دقائق).
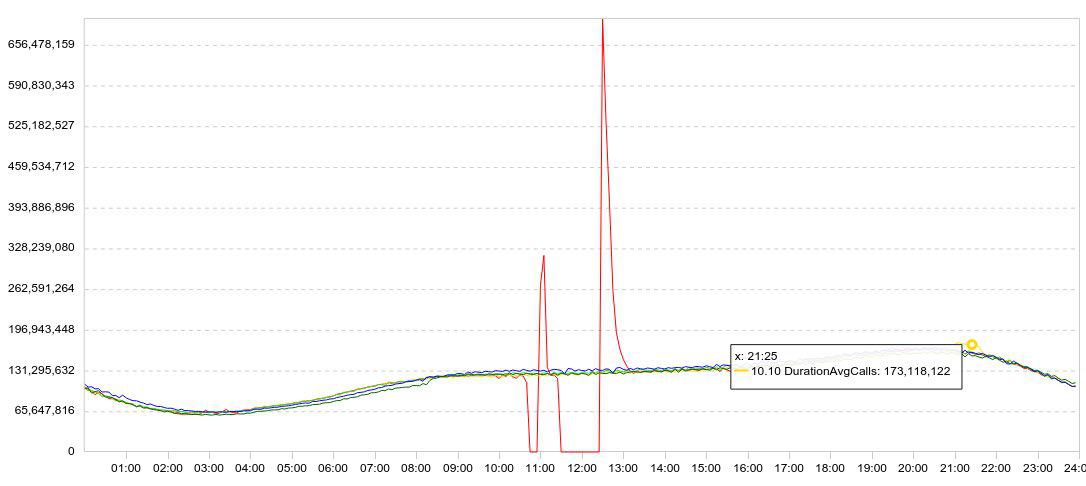
لقد أبطأت عملية التنزيل (تعطل الرسم البياني الأحمر إلى الصفر) ، وانتظرت بعض الوقت ، وأعدت التنزيل ، وشاهدت مدى سرعة Druid في تحميل البيانات المتراكمة (القمم بعد الفشل).
يمكن توسيع أي جدول زمني بأي معلمة ، على سبيل المثال ، حسب المضيف أو الجدول أو العملية ، إلخ. لدينا أيضًا مخططات طويلة المدى مع ديناميكيات سنوية. على سبيل المثال ، فيما يلي رسم بياني للزيادة اليومية في عدد الإدخالات في Druid.
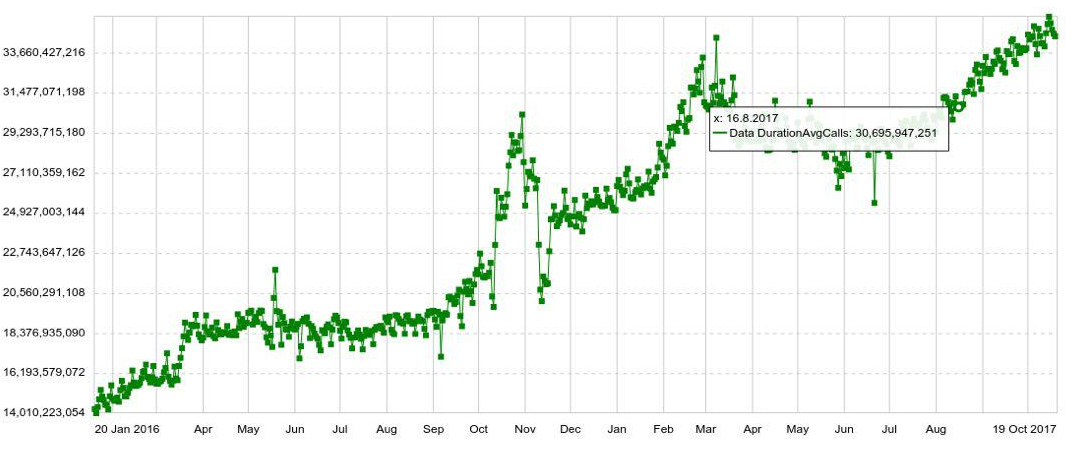
يمكننا أيضًا الجمع بين العديد من الرسوم البيانية على لوحات منفصلة (لوحات العدادات) ، والتي تبين أنها مريحة للغاية. وحتى إذا كان المستخدم بحاجة إلى رؤية بضع مئات من الرسوم البيانية ، فإنه لا يزال يفتحها بشكل فردي ، ولكن في اللوحة ، مما يزيد من الحمل على النظام.
المشكلة
بينما كان حجم البيانات صغيرًا ، تعاملنا مع SQL بشكل جيد. ولكن مع نمو حجم البيانات ، تباطأ إنتاج الرسم البياني. وفي النهاية ، بدأت الإحصاءات في ساعة الذروة بالتأخر بمقدار نصف ساعة ، وبلغ متوسط وقت الاستجابة للرسم البياني 6 ثوانٍ. أي أن شخصًا تلقى الجدول في ثانيتين ، وشخص في 10-20 ، وشخص في دقيقة واحدة. (يمكنك أن تقرأ عن تطور النظام في SQL
هنا )
عندما تحقق في شذوذ أو حادثة ، تحتاج عادةً إلى فتح ورؤية اثني عشر رسمًا بيانيًا ، كل منها يتبع الرسم البياني السابق ، لا يمكن فتحها في نفس الوقت. اضطررت إلى الانتظار 10 مرات لمدة 10-20 ثانية. كانت مزعجة للغاية.
الهجرة
لا يزال بإمكانك الضغط على شيء ما خارج النظام ، وإضافة خوادم ... ولكن في نفس الوقت تقريبًا ، قامت Microsoft بتغيير سياسة الترخيص الخاصة بها. إذا واصلنا استخدام SQL Server ، فسيتعين علينا التخلي عن ملايين الدولارات. لذلك ، قرروا الهجرة.
كانت المتطلبات على النحو التالي:
- يجب ألا تتأخر الإحصائيات (أكثر من دقيقتين).
- يجب أن يفتح المخطط في مدة لا تزيد عن ثانيتين.
- يجب أن تفتح اللوحة بأكملها في مدة لا تزيد عن 10 ثوانٍ.
- يجب أن يكون النظام متسامحًا مع الأخطاء وقادرًا على النجاة من فقدان مركز البيانات.
- يجب أن يكون النظام قابلاً للتطوير بسهولة.
- يجب أن يكون النظام سهل التعديل ، لذلك أردنا أن يكون في Java.
كل هذا عرض علينا فقط من قبل درويد. يحتوي أيضًا على تجميع أولي ، والذي يسمح لك بحفظ المزيد من الحجم ، والفهرسة أثناء إدخال البيانات. يدعم Druid جميع أنواع الاستفسارات المطلوبة لإحصاءاتنا. لذلك ، يبدو أنه يمكننا بسهولة استبدال Druid بـ SQL Server.
بالطبع ، نظرنا ليس فقط درويد لدور مرشح لهذه الخطوة. فكرتي الأولى كانت استبدال Microsoft SQL Server بـ PostgreSQL. ومع ذلك ، فإن هذا لن يحل سوى مشكلة التكاليف المالية ، ولكنه لن يساعد في إمكانية الوصول والتوسع.
قمنا أيضًا بتحليل Influx ، ولكن اتضح أن الجزء المسؤول عن التوفر العالي وقابلية التوسع مغلق. بروميثيوس ، مع كل الاحترام الواجب لأدائه ، هو أكثر ملاءمة للمراقبة ولا يمكن أن يتباهى إما بالتوافر العالي أو قابلية التوسع البسيطة. OpenTSDB هو أيضا أكثر ملاءمة للرصد ، وليس لديه فهارس لجميع المجالات. لم نفكر في Click House ، لأنه في ذلك الوقت لم يكن هناك.
ضع درويد. تم ترحيل تيرابايت من البيانات. وبعد التبديل مباشرة من SQL Server إلى Druid ، تمت زيادة عدد مرات عرض الرسم البياني 5 مرات. ثم بدأوا في تشغيل إحصاءات "ثقيلة" ، كانوا يخشون من تشغيلها في وقت سابق ، لأن بالكاد تعامل SQL معها.
الآن Druid من 12 عقدة (40 نواة ، 196 غيغابايت من ذاكرة الوصول العشوائي) يأخذ 500 ألف حدث في الثانية لكل ساعة ذروة ، في حين أن هناك هامش أمان كبير (العمود MAX: ما يقرب من خمس مرات هامش وحدة المعالجة المركزية).
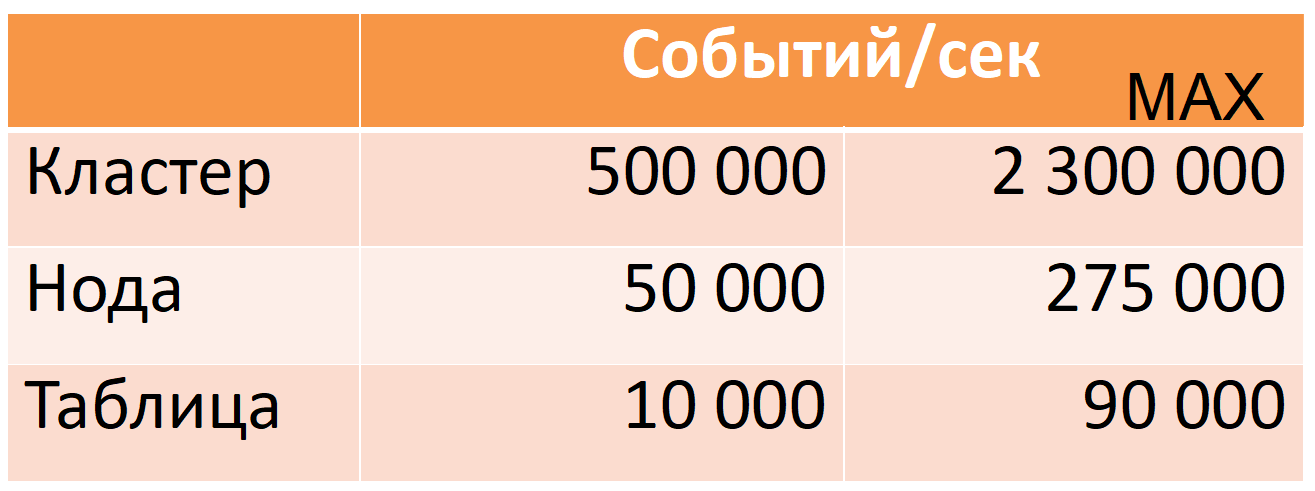
تستند هذه الأرقام إلى بيانات الإنتاج. سأخبرك كيف حققنا ذلك ، ولكن أولاً سأصف درويد بمزيد من التفاصيل.
الكاهن
هذا هو نظام الأزمنة الموزعة عمود OLAP. لا تحتوي وثائقه على المفاهيم المعتادة لعالم SQL لجدول (مصدر البيانات بدلاً من ذلك) أو سلسلة (حدث بدلاً من ذلك) ، لكنني سأستخدمها لسهولة الوصف.
يعتمد Druid على عدة افتراضات للبيانات (القيود):
- يحتوي كل خط بيانات على طابع زمني ينمو بشكل رتيب (في غضون فترة 10 دقائق افتراضيًا).
- لا تتغير البيانات ، إدراج فقط (عملية التحديث لا).
هذا يسمح لك بقص البيانات إلى ما يسمى شرائح الوقت. المقطع هو "قسم" غير قابل للتجزئة وغير قابل للتجزئة لجدول واحد لفترة معينة من الزمن. يتم تنفيذ جميع عمليات البيانات ، وجميع الاستعلامات قطعة تلو الأخرى.
كل جزء مكتفي ذاتيًا: بالإضافة إلى الجدول الرئيسي ، المكتوب في شكل عمودي ، فإنه يحتوي أيضًا على أدلة وفهارس ضرورية لتنفيذ الاستعلام. يمكننا القول أن المقطع عبارة عن قاعدة بيانات صغيرة للقراءة فقط في العمود (سيتم تقديم وصف أكثر تفصيلاً لجهاز المقطع أدناه).
وهذا بدوره يؤدي إلى "التوزيع": القدرة على تقسيم كمية كبيرة من البيانات إلى شرائح صغيرة من أجل إجراء حسابات متوازية (على جهاز واحد وعلى العديد في وقت واحد).
إذا كنت بحاجة إلى "ترقية" سطر واحد على الأقل ، فسيتعين عليك إعادة تحميل الجزء بالكامل مرة أخرى. هذا ممكن وكل شيء جاهز لذلك. يحتوي كل مقطع على إصدار ، وسيحل الجزء الذي يحتوي على إصدار أحدث محل المقطع بالإصدار القديم تلقائيًا (ومع ذلك ، إذا كان التحديث مطلوبًا بشكل منتظم ، فمن الجدير إعادة تقييم ما إذا كان Druid مناسبًا لهذه الحالة).
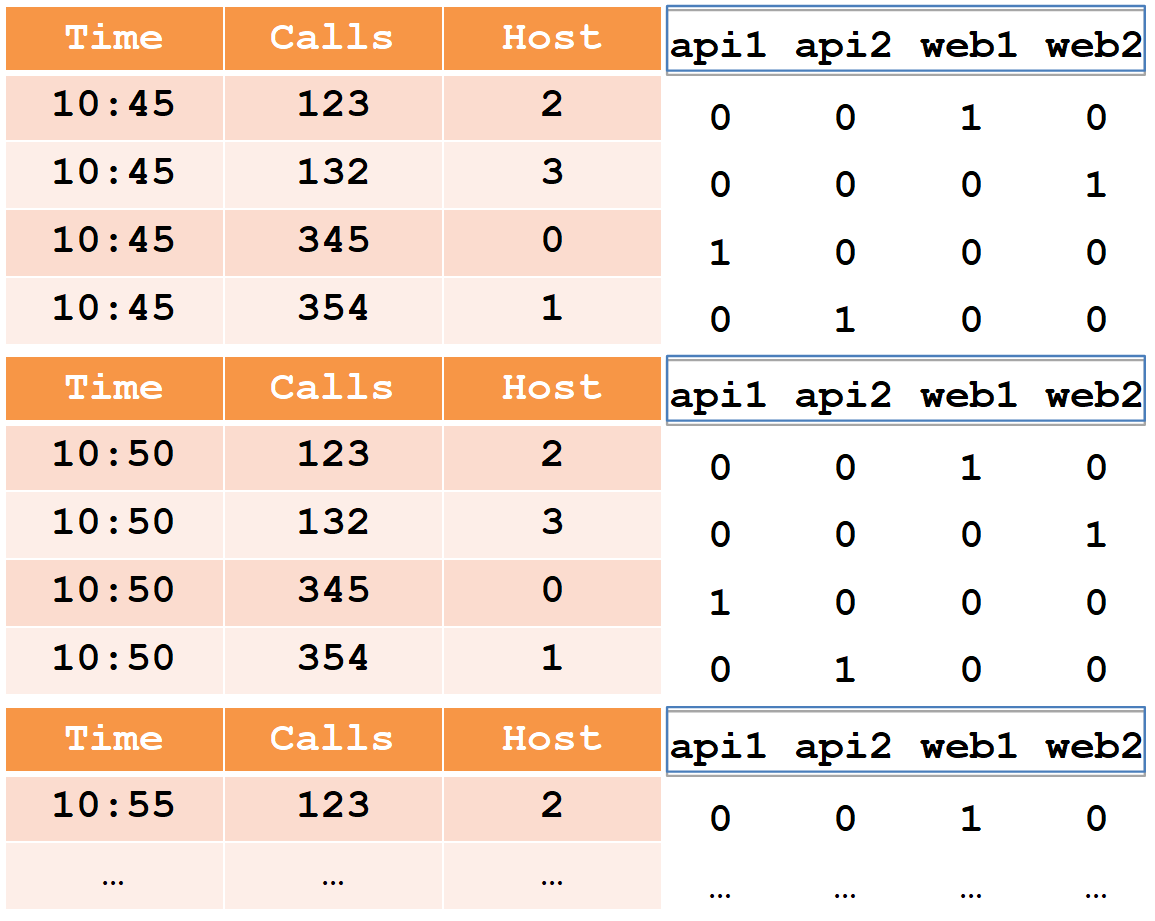
لوصف شريحة الجهاز ، نعتبر مثالًا بسيطًا في الشكل المجدول المعتاد:
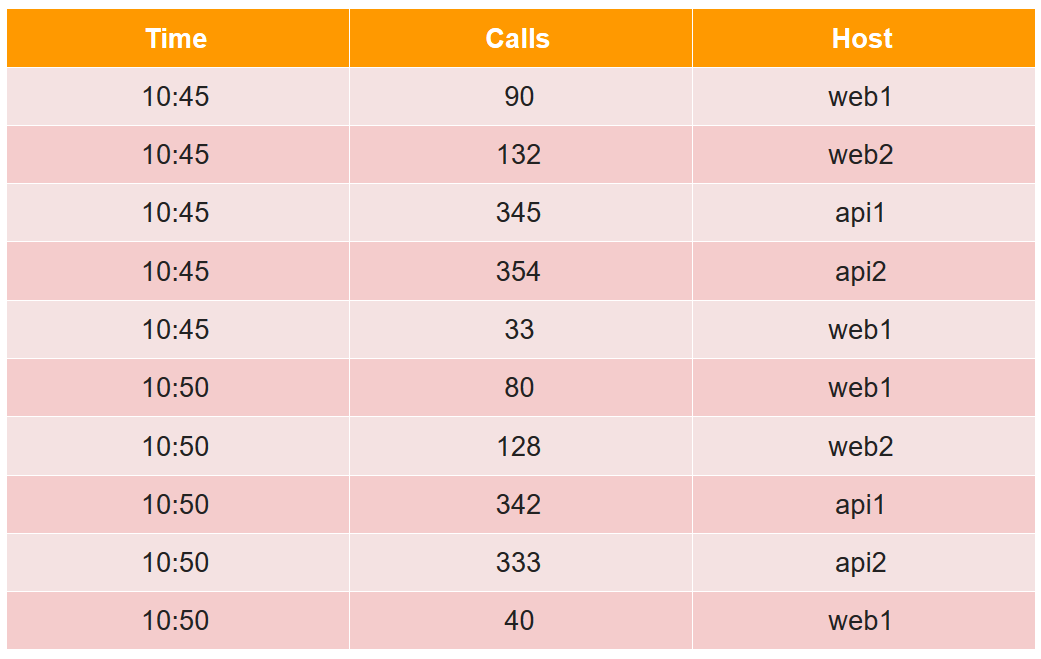
في هذا الجدول ، عدد المكالمات في خمس دقائق من أربعة مضيفين (لاحظ أنه بالنسبة لمضيف web1 هناك خطان في كل فترة خمس دقائق).
تنقسم جميع خلايا البيانات من وجهة نظر الكاهن إلى ثلاثة أنواع:
- الطابع الزمني - الطابع الزمني UTC بالمللي ثانية (في المثال هو الوقت).
- المقاييس هي ما تحتاج إلى حسابه (sum ، min ، max ، count ، ...) ، وتحتاج إلى معرفتها مسبقًا لكل جدول (في المثال ، هذا هو Calls ، وسنقوم بحساب المجموع).
- الأبعاد - هذا ما يمكنك تجميعه وتصفيته (لا تحتاج إلى معرفتها مسبقًا ويمكن تغييرها بسرعة) (في هذا المثال ، هذا هو المضيف).
عند الإدراج ، يتم تجميع جميع الصفوف حسب المجموعة الكاملة للأبعاد + الطابع الزمني ، وإذا تطابقوا مع كل من المقاييس ، يتم تطبيق وظيفة التجميع "الخاصة به" (نتيجة لذلك ، لا توجد صفوف بنفس مجموعة الأبعاد + الطابع الزمني). وبالتالي ، سيبدو مثالنا بعد الإدراج في الكاهن على النحو التالي:

سيتم كتابة الطابع الزمني وجميع المقاييس (في حالتنا ، الوقت والمكالمات) كمصفوفات لأرقام من النوع الطويل (يتم أيضًا دعم التعويم والمضاعفة). لكل من الأبعاد (في حالتنا هو Host) ، سيتم إنشاء قاموس - مجموعة مرتبة من السلاسل (مع أسماء المضيف). سيتم كتابة عمود المضيف نفسه كمصفوفة int ، مما يشير إلى الأرقام في القاموس.
يرجى ملاحظة أنه بعد الإدراج في الكتيب ، تم تجميع أزواج من الخطوط لمضيف web1 بنفس الطابع الزمني ، وتم تسجيل المبلغ الإجمالي في المكالمات (من المستحيل استخراج البيانات الأولية من الكاهن).
الفهارس مطلوبة للتصفية السريعة للبيانات ، لأنه يمكن أن يكون هناك ملايين الصفوف وآلاف المضيفين. الفهارس هي صور نقطية ، واحدة لكل سطر في القاموس.

تشير الوحدات إلى أرقام الأسطر التي يشارك فيها هذا المضيف. لتصفية مضيفين ، تحتاج إلى أخذ صورتين نقطيتين ، ودمجهما من خلال OR ، وتحديد أرقام الأسطر في وحدات الصورة النقطية الناتجة.
يتكون الكاهن من العديد من المكونات.
أولاً ، لديها العديد من التبعيات الخارجية.

- التخزين هناك ، يقوم Druid ببساطة بتخزين الأجزاء في شكل مضغوط. يمكن أن يكون دليل محلي ، HDFS ، Amazon S3. يتم استخدام المساحة فقط هنا ، ولا يتم إجراء أي حسابات.
- ميتا: قاعدة بيانات لمعلومات ميتا. تخزن قاعدة البيانات هذه خريطة البيانات الكاملة: أي الأجزاء ذات الصلة ، والتي هي قديمة ، والمسار في التخزين.
- باستخدام ZooKeeper ، يقوم النظام بالاكتشاف ويعلن عن العقد الكهنوتية والأجزاء المتاحة للاستعلام.
- ذاكرة التخزين المؤقت للطلبات المنفذة ، يمكن أن تكون ذاكرة التخزين المؤقت أو ذاكرة التخزين المؤقت المحلية في كومة جافا.
ثانياً ، يتكون درويد نفسه من عدة أنواع من المكونات.
- تقوم عُقد الوقت الفعلي بتحميل دفق البيانات الجديدة بالترتيب الذي يتم تلقيها فيه وتخدم الطلبات الخاصة به.
- تحتوي العقد التاريخية على الكتلة الكاملة للبيانات وتخدم الطلبات الخاصة بها. عندما نقول أن لدينا 300 تيرابايت ، فإننا نعني العقد التاريخية.
- الوسيط هو المسؤول عن توزيع الحسابات بين العقد التاريخية والحقيقية.
- المنسق هو المسؤول عن تخصيص الأجزاء عبر العقد التاريخية والنسخ المتماثل.
- خدمة الفهرسة ، والتي تتيح لك (إعادة) تحميل البيانات على دفعات ، على سبيل المثال ، "لترقية" جزء من البيانات.
دفق البيانات
 تشير الأسهم الغامقة إلى تدفق البيانات ، وتشير الأسهم الرفيعة إلى تدفق البيانات الوصفية.
تشير الأسهم الغامقة إلى تدفق البيانات ، وتشير الأسهم الرفيعة إلى تدفق البيانات الوصفية.تأخذ عقدة Realtime البيانات والفهارس والقطع إلى أجزاء حسب الوقت ، على سبيل المثال ، حسب اليوم.
يكتب كل جزء جديد من العقدة في الوقت الحقيقي إلى التخزين ويترك نسخة لخدمة الطلبات لها. ثم يسجل البيانات الوصفية التي ظهرت قطعة جديدة في المستودع على طول مسار كهذا.
يتلقى المنسق هذه المعلومات ، ويعيد قراءة قاعدة البيانات الوصفية بشكل دوري. عندما يجد مقطعًا جديدًا ، (من خلال ZooKeeper) يأمر عدة عُقد تاريخية لتنزيل هذا الجزء. يتم تنزيلها ويعلن (من خلال ZooKeeper) أن لديهم شريحة جديدة. عندما تتلقى عقدة في الوقت الفعلي هذه الرسالة (عبر ZooKeeper) ، فإنها تحذف نسختها لإفساح المجال للبيانات الجديدة.
معالجة الطلب

تشارك ثلاثة أنواع من العقد في معالجة الطلب: وسيط ، في الوقت الفعلي ، وتاريخي. يأتي الطلب إلى الوسيط ، الذي يعرف في أي عقد تقع فيه الأجزاء. يوزع الطلب عن طريق العقد التاريخية (وفي الوقت الحقيقي) التي تخزن المقاطع المطلوبة. تتوازى العقد التاريخية أيضًا مع الحسابات قدر الإمكان ، وترسل النتائج إلى الوسيط ، ويعطيها للعميل. من خلال دمج هذا المخطط مع تخزين بيانات العمود ، يمكن لـ Druid معالجة كميات كبيرة من المعلومات بسرعة كبيرة.
توفر عالية
كما تتذكر ، يحتوي Druid في قائمة التبعيات على قاعدة لبيانات التعريف ، والتي يمكن أن تكون MySQL أو PostgreSQL. تم ذكر Apache Derby أيضًا ، ولكن لا يمكن استخدام هذا المنتج للإنتاج ، فقط من أجل التطوير (كما أفهمها ، يتم استخدام derby في شكل مضمن ، حتى لا ترفع mysql / pgsql في بيئة العذراء).
ماذا سيحدث إذا فشلت هذه القاعدة (و / أو التخزين و / أو المنسق)؟ لا تستطيع العقدة في الوقت الحقيقي كتابة البيانات الوصفية (و / أو المقاطع). عندها لن يتمكن المنسق من إعادة قراءتها ولن يعثر على مقطع جديد. لن تقوم العقدة التاريخية بتنزيلها ، ولن تحذف العقدة في الوقت الحقيقي نسختها ، ولكنها ستستمر في تنزيل أحدث البيانات. نتيجة لذلك ، ستبدأ البيانات في التراكم في العقد في الوقت الحقيقي. هذا لا يمكن أن يستمر إلى ما لا نهاية. ومع ذلك ، من المعروف ما هي الموارد المتاحة على عقد الوقت الحقيقي ، ونوع تدفق البيانات لدينا. لذلك ، لدينا مقدار يمكن التنبؤ به من الوقت الذي يمكننا من خلاله إصلاح القاعدة الفاشلة (و / أو التخزين و / أو المنسق).
نظرًا لأن mysql / pgsql المدعوم لا يضمن توفرًا عاليًا خارج الصندوق ، فقد قررنا تشغيله بأمان واستخدمنا حلنا (الجاهز) الخاص بنا استنادًا إلى كاساندرا ، نظرًا لأنه خارج الصندوق يوفر توفرًا عاليًا (يمكنك قراءة المزيد عنه
هنا ).
بالإضافة إلى ذلك ، قمنا بوضع اللمسات الأخيرة على العقد في الوقت الحقيقي بطريقة تراكم مفرط ، يتم حذف أقدم البيانات ، مما يوفر مساحة لأخرى جديدة. هذا مهم جدًا بالنسبة إلينا ، لأن الموقف الذي لا يمكننا فيه رفع القاعدة الفاشلة (و / أو التخزين و / أو المنسق) لفترة طويلة وجمع الكثير من البيانات هو على الأرجح نتيجة لحادث كبير. وفي هذه اللحظة ، تكون أحدث البيانات هي الأكثر أهمية.
درويد وحديقة الحيوان
مع ZooKeeper ، كل شيء أفضل وأسوأ. أفضل لأن ZooKeeper نفسه يتحمل الأخطاء ، لديه نسخ متماثل خارج الصندوق. يبدو أنه يمكن أن يحدث؟
بشكل عام ، هذا الفصل لم يعد ذي صلة. وهذه ليست قصة نجاح ، هذا ألم قرر (نحن وكاهن الكاهن الجديد) إزالة جميع البيانات تقريبًا من ZooKeeper ، والآن تطلب العقد الكهنوتية مباشرة من بعضها البعض عبر HTTP.
لدى ZooKeeper نوعين من المهلات. مهلة الاتصال هي مهلة بسيطة للشبكة ، وبعدها يعيد العميل الاتصال بـ ZooKeeper ويحاول استعادة جلسته. ومهلة الجلسة ، وبعد ذلك يتم حذف الجلسة ويتم أيضًا حذف جميع البيانات
المؤقتة التي تم إنشاؤها خلال هذه الجلسة (بواسطة ZooKeeper نفسه) ، والتي يتم إبلاغها لجميع عملاء ZooKeeper الآخرين.
بناءً على هذا ، الاكتشاف في عمل الكاهن: عند بدء التشغيل ، تنشئ كل عقدة جلسة جديدة في ZooKeeper وتسجل بيانات
سريعة الزوال عن نفسها: المضيف: المنفذ ، نوع العقدة (وسيط / الوقت الحقيقي / التاريخية / ...) ، الطابع الزمني للاتصال ، إلخ. ... تتلقى العقد الكهنوتية الأخرى إشعارات من ZooKeeper وقراءة هذه البيانات ، حتى يتعلموا أن عقدة كاهن جديدة قد ارتفعت وما هو نوع العقدة. إذا سقطت أي عقدة كاذبة بعد انتهاء مهلة جلستها ، فسيتم حذف البيانات المتعلقة بها بواسطة ZooKeeper ، وستعرف العقد الكهربية الأخرى عنها. حتى يتعرفوا عليه بشكل أسرع ، نفضل وضع مهلة جلسة صغيرة.
عندما ترتفع عقدة حقيقية أو تاريخية ، فإنها ، بالإضافة إلى البيانات المتعلقة بها ، تكتب أيضًا إلى ZooKeeper قائمة بالمقاطع التي تحتوي عليها (هذه أيضًا بيانات
سريعة الزوال ). علاوة على ذلك ، يتم إنشاء مقاطع في الوقت الفعلي والعقد التاريخية يتم حذف العقد الجديدة والقديمة ، وتعكس كل عقدة ذلك في قائمتها في ZooKeeper. يمكن أن تكون هذه القائمة كبيرة ، لذلك يتم تقسيمها إلى أجزاء بحيث لا يتم استبدال القائمة بأكملها ، ولكن فقط الجزء المعدل.
يقوم الوسيط بدوره ، عندما يرى عقدة جديدة في الوقت الفعلي أو عقدة تاريخية ، بطرح قائمة الأجزاء الخاصة به من ZooKeeper من أجل توزيع الطلبات على هذه العقدة. تقرأ عُقد الوقت الفعلي هذه القائمة لإزالة نسختها من المقطع الذي ظهر على العقدة التاريخية. نظرًا لأن القائمة مقسمة إلى أجزاء ويتم استبدالها في أجزاء ، سيخبرك ZooKeeper بالجزء الذي تم تغييره ، سيتم إعادة قراءته فقط.
كما قلت ، يمكن أن تكون هذه القائمة طويلة. عندما يكون هناك الكثير من البيانات في ZooKeeper ، فقد تبين أنها لم تعد مستقرة. في حالتنا ، بدأت المشاكل الواضحة عندما وصل عدد الأجزاء إلى حوالي 7 ملايين ، ثم احتلت لقطة ZooKeeper 6 جيجابايت.
ماذا يحدث إذا فقدت العقدة الكاذبة الاتصال بـ ZooKeeper؟
يعمل Druid مع ZooKeeper بطريقة أنه في حالة انتهاء مهلة الجلسة ، تقوم كل عقدة بإنشاء جلسة جديدة وكتابة جميع بياناتها هناك وإعادة قراءة بيانات العقد الأخرى. نظرًا لوجود الكثير من البيانات ، تقلع حركة المرور على ZooKeeper. يمكن أن يؤدي ذلك إلى انقضاء مهلة على العقد الأخرى للكاهن ، ثم يبدأون أيضًا في إعادة الكتابة وإعادة القراءة. وبالتالي ، تنمو حركة المرور مثل الانهيار الجليدي حتى النقطة التي يفقد فيها ZooKeeper التزامن بين حالاته ويبدأ في دفع اللقطات ذهابًا وإيابًا.
ماذا يرى المستخدم في هذه اللحظة؟
عندما يفقد وسيط اتصاله مع ZooKeeper (وتحدث مهلة جلسة) ، فإنه لم يعد يعرف الأجزاء التي تقع عليها العقد التاريخية. ويعطي إجابات فارغة. أي إذا كان ZooKeeper معطلاً ، فإن Druid لا يعمل. من المستحيل تمامًا "علاجها" ، ولكن من الممكن نشر القش في بعض الأماكن.
أولاً ، يمكنك حذف البيانات من ZooKeeper. لا بأس إذا ضاعوا: Druid ببساطة سوف يستبدلهم. إذا كانت المشكلة مع ZooKeeper قد بدأت بالفعل ، فمن أجل حلها الأسرع ، فمن المستحسن تعطيل ZooKeeper وحذف البيانات ورفعها فارغة ، ولا تنتظر حتى تحل نفسها.
نحن الآن بصدد زيادة مهلة الجلسة. ماذا يحدث في هذه الحالة؟
لنفترض أن العقدة التاريخية لم يتم إعادة تشغيلها بشكل صحيح ولم تحذف الجلسة القديمة من ZooKeeper ، أثناء إنشاء واحدة جديدة وكتابة مجموعة من البيانات هناك. بينما لا تزال الجلسة القديمة على قيد الحياة ولم تنتهي المهلة ، يتم تخزين نسختين من البيانات في ZooKeeper. إذا تم إعادة تشغيل العديد من هذه العقد على الفور ، فسيتم تكرار الكثير من البيانات. لذلك ، تحتاج إلى الاحتفاظ بموارد ذاكرة لـ ZooKeeper حتى لا تنفد ولا يتوقف ZooKeeper عن العمل. لماذا لا يمكن حذف بيانات الجلسة القديمة؟
لنفس السبب ، من الضروري إكمال تشغيل العقد التاريخية بشكل صحيح ، حيث أنها تحذف بياناتها من ZooKeeper في هذه اللحظة ، ويمكنها القيام بذلك لفترة طويلة. يستغرق الانتهاء من العقد التاريخية حوالي نصف ساعة.
تحتوي العقد التاريخية على ميزة أخرى. عند البدء ، ينظرون إلى الأجزاء المخزنة عليها ، ثم تتم كتابة المعلومات حول هذا الأمر إلى ZooKeeper. وبما أن البيانات تنتشر بشكل متساوٍ تقريبًا عبر العقد التاريخية ، إذا قمت بتشغيلها في نفس الوقت ، فستبدأ في الكتابة إلى ZooKeeper في نفس الوقت تقريبًا. هذا يزيد مرة أخرى من احتمالية نمو حركة المرور التي تشبه الموجة والمهلة. لذلك ، تحتاج إلى تشغيل العقد التاريخية بالتتابع من أجل نشر جلسات التسجيل في ZooKeeper في الوقت المناسب.
قمنا أيضًا بإجراء تحسينين إضافيين:
- لقد أعدنا برمجة العمل مع ZooKeeper قليلاً حتى تتم قراءة العقد التي تحتاج إليها فقط من Druid. realtime, , . , . , .
- , ZooKeeper, , . ZooKeeper 6 2 ( ).
8 ; .
Druid
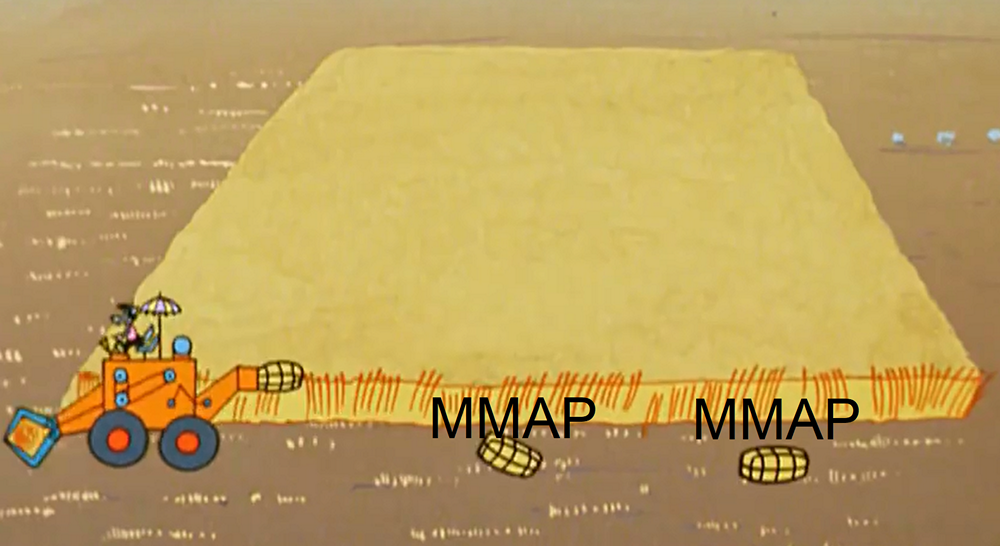
realtime , . - ( , , ). , MMAP ( ). . .
-, realtime- , JVM , .

. : 1) 2) . , . , , . , , , . ( , , ).
, realtime- , , .. , , , ( ).
, . , , .
, Druid . , , , .
, . , (web%, api%).
- Druid — . .
- , .
- Druid , , : , , , .
- Druid , , calls.
, 5 % , 95 % — .
, , realtime- .
, ( 10:45) . - , -. , ( 10:50) , -. وهكذا دواليك. , , «calls», «time» «host» .
-. , «» . , , . ( 95% ) , : , . 100 , 1000.
? , . , realtime , . (.. historical realtime-), .
, : . , , . 100 . , . .
. 80% , , , . . . , selector, . , .
, , , . , . , 8 . Druid. , , Druid, . , . :

, , . . , , . . 27 . , 27 , 27 .
, . 27 , 9, 9 , .
.

— : , , . — : , , . — : , , . — , . , . , 27. 9, . ( 95% ) 9 . 27 .
14 . . , 14 . 14 . . , , 10 , . .
, 2 . 11 , 74 . , . 74 ? , .
Druid . , , , . , , . , , . , , .
, Druid . , ( ) , . 5 : , . . ( java), . Druid , .
الملخص
, , SQL Server, Microsoft.
, / .
, , .
20 , , 18 .
one-cloud (
https://habr.com/company/odnoklassniki/blog/346868/ ), .